视觉语言预训练综述


作者:殷炯,张哲东,高宇涵,杨智文,李亮,肖芒,孙垚棋,颜成钢
来源:软件学报
编辑:郑欣欣@一点人工一点智能
00 摘要
近年来深度学习在计算机视觉(CV)和自然语言处理(NLP)等单模态领域都取得了十分优异的性能。随着技术的发展,多模态学习的重要性和必要性已经慢慢展现。
视觉语言学习作为多模态学习的重要部分,得到国内外研究人员的广泛关注。得益于Transformer框架的发展,越来越多的预训练模型被运用到视觉语言多模态学习上,相关任务在性能上得到了质的飞跃。
本文系统地梳理了当前视觉语言预训练模型相关的工作,首先介绍了预训练模型的相关知识,其次从两种不同的角度分析比较预训练模型结构,讨论了常用的视觉语言预训练技术,详细介绍了5类下游预训练任务,最后介绍了常用的图像和视频预训练任务的数据集,并比较和分析了常用预训练模型在不同任务下不同数据集上的性能。
01 内容精选
本文将围绕视觉语言预训练模型展开介绍,并通过以下6个重要方面详细介绍和讨论视觉语言预训练模型的最新进展:首先介绍视觉语言预训练模型的相关知识,包括Transformer框架、模型预训练范式和视觉语言预训练模型常见网络结构;其次介绍3类模型预训练任务,通过这些任务,网络模型可以在无标注的情况下进行跨模态的语义对齐;然后我们将从图像-文本预训练和视频-文本预训练两个方面分别来介绍最新的工作进展;同时我们也将对预训练模型的下游任务进行分类和介绍;接着将介绍广泛使用的图像文本和视频文本的多模态数据集,并比较和分析了常用预训练模型在不同任务下不同数据集上的性能;最后对视觉语言预训练进行总结和展望。视觉语言预训练综述结构框图如下图所示。
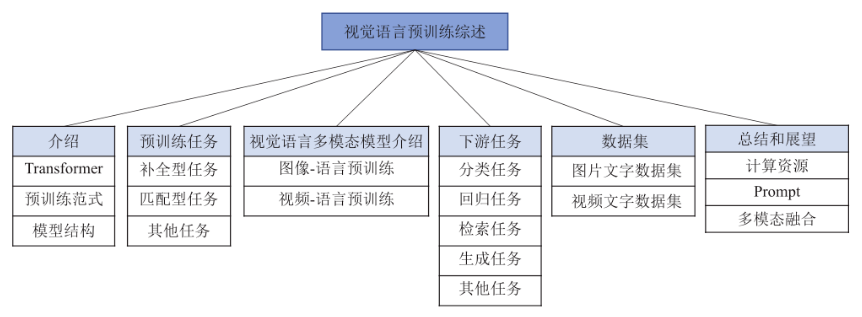
图1 视觉语言预训练综述结构框图
1.1 介绍
预训练范式包括:预训练-微调(pretrain fine-tuning)和预训练-提示(pretrain prompt)。预训练-微调已经成了经典的预训练范式。其做法是:首先以监督或无监督的方式在大型数据集上预训练模型,然后通过微调将预训练的模型在较小的数据集上适应特定的下游任务。这种模式可以避免为不同的任务或数据集从头开始训练新模型。越来越多的实验证明,在较大的数据集上进行预训练有助于学习通用表征,从而提高下游任务的性能。
提示学习起源于NLP领域,随着预训练语言模型体量的不断增大,对其进行微调的硬件要求、数据需求和实际代价也在不断上涨。除此之外,丰富多样的下游任务也使得预训练-微调阶段的设计变得繁琐复杂,提示学习就此诞生。在预训练-提示范式中通常使用一个模板来给预训练模型提供一些线索和提示,从而能够更好地利用预训练语言模型中已有的知识,以此完成下游任务。
从两个不同的角度介绍视觉语言预训练模型的体系结构:
(1)从多模态融合的角度对比单流结构与双流结构。
(2)从整体架构设计的角度对比仅编码结构和编码-解码结构。
● 单流与双流的对比,如下图所示。单流结构:单流结构指一种将文本和视觉特征连接到一起,然后输入进单个Transformer模块中。单流结构利用注意力来融合多模态输入,因为对不同的模态都使用了相同形式的参数,其在参数方面更具效率。双流结构:在双流结构中文本和视觉特征没有连接在一起,而是单独输入到两个不同的Transformer模块中。这两个Transformer没有共享参数,为了达到更高的性能,双流结构使用交叉注意力的方式来实现不同模态之间的交互。为了达到更高的效率,处理不同模态信息的Transformer模块之间也可以不存在交叉注意。
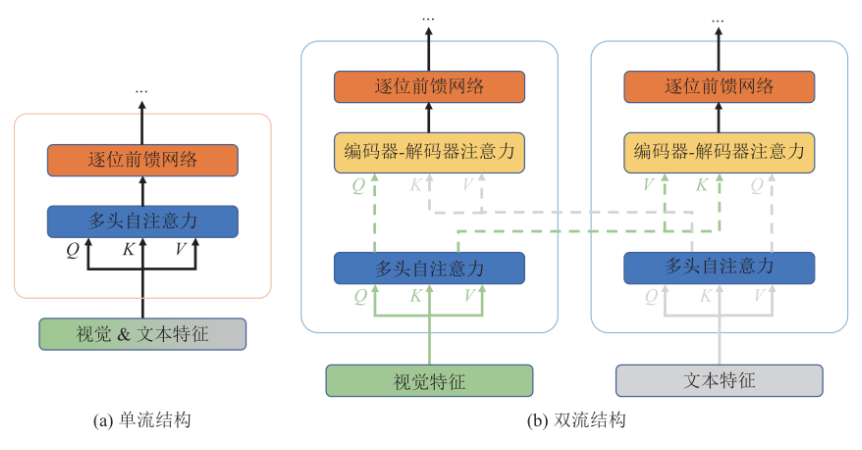
图2 单流结构和双流结构
● 仅编码结构与编码-解码结构。许多视觉语言预训练模型采用仅编码的体系结构,其中跨模态表示被直接输入到输出层以生成最终输出。而其他视觉语言预训练模型使用转换器编码-解码体系结构,在这种体系结构中,交叉模态表示首先被输入解码器,然后再输入输出层。
1.2 预训练任务
我们将预训练任务归纳为3类:补全型、匹配型、其他型。
● 补全型任务通过利用未被掩码的剩余信息来理解模态,从而重建补全被掩码的元素。
● 匹配型任务是将视觉和语言统一到一个共同的潜在空间中来生成一个一般化的视觉-语言表达。
● 其他型任务的内容中包含了其他预训练任务。
1.3 视觉语言多模态模型介绍
视觉和语言是人类感知世界的两个重要方面,因此训练神经网络模型处理多模态信息对于人工智能的发展有着重要的意义。 近年来,许多研究工作通过对其视觉和语言的语义信息实现了各种跨模态任务。其中图像文本预训练和视频文本预训练得到了最广泛的研究。图像-文本预训练模型汇总见表1。视频-文本预训练模型汇总见表2。
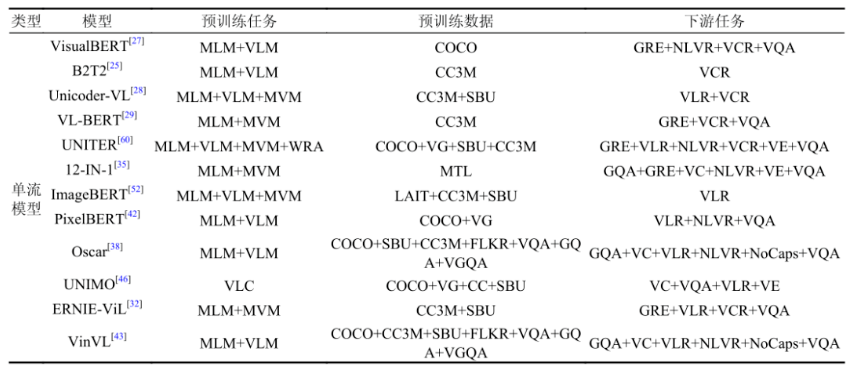
表1 图像-文本预训练模型汇总表
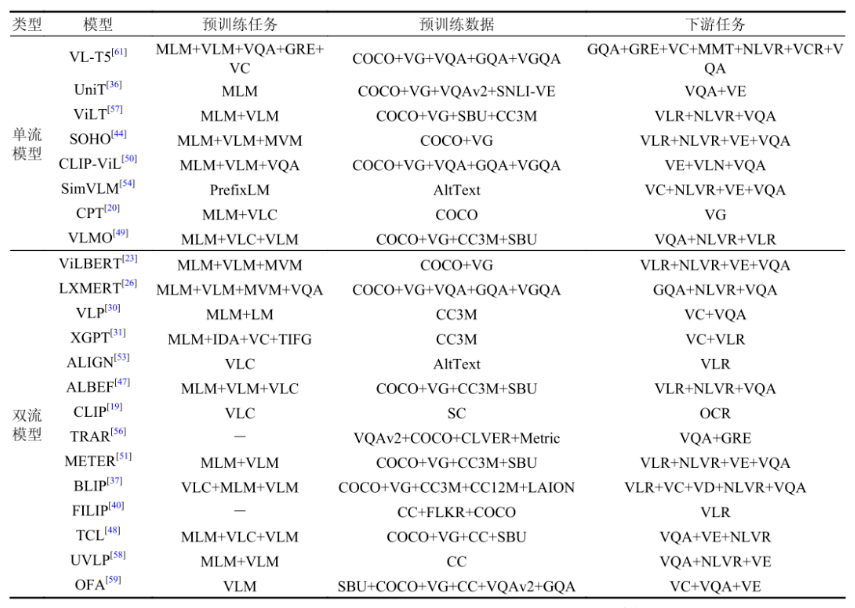
表1 图像-文本预训练模型汇总表(续)
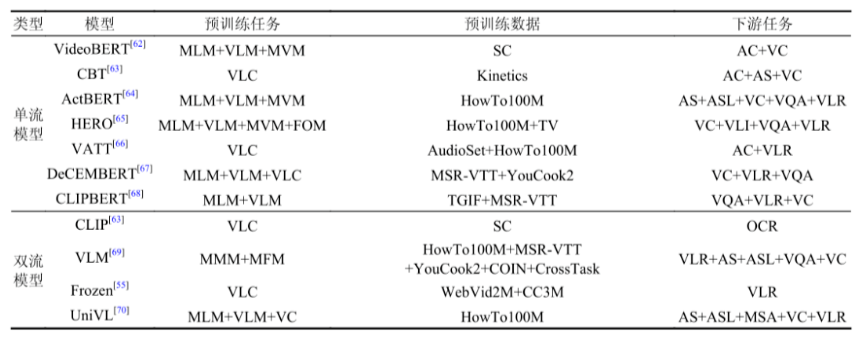
表2 视频-文本预训练模型汇总表
1.4 下游任务
多样化的任务需要视觉和语言的融合知识。我们将介绍此类任务的基本细节和目标,并将其分为4类:分类、检索、生成和其他任务。
● 分类任务。常见视觉语言预训练模型对应分类型下游任务,包括视觉问答(VQA),自然语言视觉推理(NLVR),视觉常识推理(VCR)和视觉推理和组合式问答(GQA)等。
● 检索任务。视觉-语言检索(vision-language retrieval,VLR)。 VLR涉及对视觉(图像或视频)和语言的理解,以及适当的匹配策略。 它包括两个子任务:从视觉到文本和从文本到视觉的检索,其中视觉到文本检索是根据视觉从更大的描述库中获取最重要的相关文本描述, 反之亦然。
● 生成任务。常见视觉语言预训练模型对应生成型下游任务,包括视觉描述(visual captioning,VC)和大规模新物体描述(novel object captioning at scale, NoCaps)等。
● 其他任务。多模态情感分析(multi-modal sentiment analysis,MSA)旨在通过利用多模态信号(如视觉、语言等)来检测其中的情感。多模态机器翻译(multi-modal machine translation,MMT):多模态机器翻译是一项包含翻译和文本生成的双重任务,将文本从一种语言翻译成另一种语言,并加入来自其他模态的额外信息,即图像。视觉语言导航任务(vision-language navigation,VLN)是让智能体跟着自然语言指令进行导航,这个任务需要同时理解自然语言指令与视角中可以看见的图像信息,然后在环境中对自身所处状态做出对应的动作,最终达到目标位置。光学字符识别(optical character recognition,OCR):OCR一般是指检测和识别图像中的文本信息,它包括两个步骤:文字检测(类似于回归任务)和文字识别(类似于分类任务)。 此外,还有一些与视频相关的下游任务,用于评估视频-文本预训练模型,包括动作分类(AC)、动作分割(AS)和动作步骤定位(ASL)。
1.5 数据集
数据集是深度学习的基础,任何研究都离不开数据,任何优秀的工作都得益于优秀的数据集。相关数据集及其数据见下表。
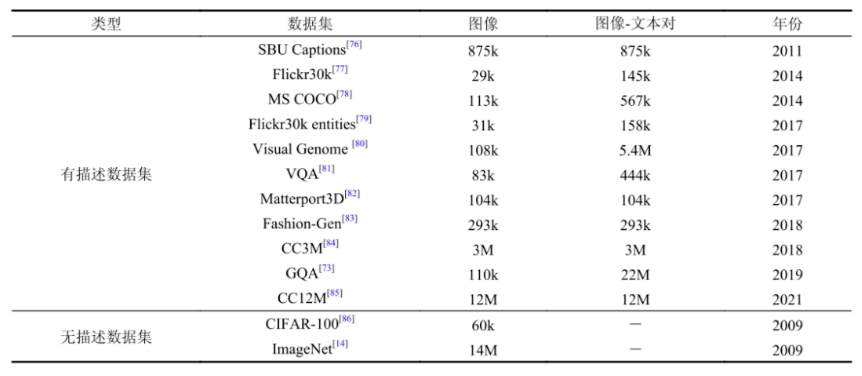
表6 图像文本数据集

表7 视频-文本数据集
1.6 总结和展望
在本文中,首先我们介绍了视觉语言预训练模型的相关知识,包括Transformer框架、预训练范式和视觉语言预训练模型常见网络结构;其次我们介绍了3类模型预训练任务,通过这些任务,网络模型可以在无标注的情况下进行跨模态的语义对齐;然后我们从图像-文本预训练和视频-文本预训练两个方面分别介绍了最新的工作进展,并介绍了预训练模型的下游任务;最后我们介绍了广泛使用的图像文本和视频文本的多模态数据集,并比较和分析了常用预训练模型在不同任务下不同数据集上的性能。视觉语言预训练在飞速发展的同时也取得了许多非常不错的成果,未来视觉语言预训练模型的发展方向可以借鉴如下。
● 计算资源。目前视觉语言预训练工作仍然需要极大的算力资源做支撑。 2019年以来,视觉语言预训练工作大部分都是产自于工业界,需要使用数十上百张显卡进行训练,导致部分研究人员没有足够的计算资源对其展开研究,而且难以对这些大规模工作进行验证。 如何在资源受限的情况下进行视觉语言预训练研究,是一个很有研究价值的问题。
● Prompt。预训练-提示范式在NLP领域引起了一波研究热潮,我们在第1.2.2节已经对其进行了介绍。提示相对于微调的优势在于:1)计算代价低。 2)节省空间。 目前已有少数工作对其进行展开了研究,诸如CLIP,CPT等,并且取得了不错的效果。 预训练-提示范式目前还在探索阶段,未来将会有更多更有意义的工作出现。
● 多模态融合。之前大多数的多模态预训练工作都是强调视觉和语言这两个模态进行建模,但是忽略了其他模态(比如音频等)信息。 其他模态信息往往也对跨模态学习有着重要的意义,因此研究更多模态信息建模的工作是具有研究价值和挑战性的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-18,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号