AI 新时代,大模型该如何“绞尽脑汁”?

AI 新时代,大模型该如何“绞尽脑汁”?

OpenMMLab 官方账号
发布于 2023-08-25 11:57:56
发布于 2023-08-25 11:57:56

随着 ChatGPT 的推出,大语言模型(LLMs)逐渐引发了 AI 领域的广泛关注。然而,尽管 LLMs 展现出了令人瞩目的能力,它们在处理一些多步骤推理任务——例如数学应用问题和常识推理方面,仍然面临着显著的挑战。这也使得一些较为复杂的推理数据集,如 GSM8k、MATH 等数据集成了大模型评测榜单的常客。
也正是为了解决 LLMs 在复杂推理方面的不足,研究者们不断致力于开发各种创新技术。在这些尝试中,思维链提示(Chain-of-Thought Prompting)技术受到了特别的关注。这种技术旨在通过引导模型将复杂的多步骤问题分解为更易处理的中间步骤,以此帮助模型更准确地理解和解决问题。实践证明,通过应用思维链提示技术,LLMs 在多种推理任务中,特别是在算术推理方面,已经取得了显著的进步。

什么是思维链?
让我们假设这样一个场景,老师给小明出了一道有挑战的思维推理题:在一个农场的笼子里,总共有鸡和兔子共 36 只,它们的总腿数为 100。求解鸡和兔子各有多少只。
假设小明身边没有纸笔,只能默算,他需要直接给出答案:
鸡有 20 只,兔子有 16 只 ❌ 很遗憾,因为默算中出了差错,小明算错了。
老师给了小明第二次机会,可以用纸笔一步一步地推导出答案,记录中间步骤:
设鸡的数量为 x,兔子的数量为 y。
x + y = 36(总数量为36只)
2x + 4y = 100(总腿数为100只)
从第一个方程解出一个变量,例如 x = 36 - y。
将 x 的值代入第二个方程中:
2(36 - y) + 4y = 100
72 - 2y + 4y = 100
2y = 28
y = 14
将 y 的值代回第一个方程中,得到 x 的值:
x = 36 - 14
x = 22
因此,答案是:
鸡有 22 只,兔子有 14 只。✅在一步步的推理计算下,小明顺利得到了答案,得到了老师的肯定。
同样的,在使用大模型时,也可以像是老师帮助小明一样,提示大模型一步一步的解决复杂问题。那么就出现了最早的思维链——小样本思维链,如下图:
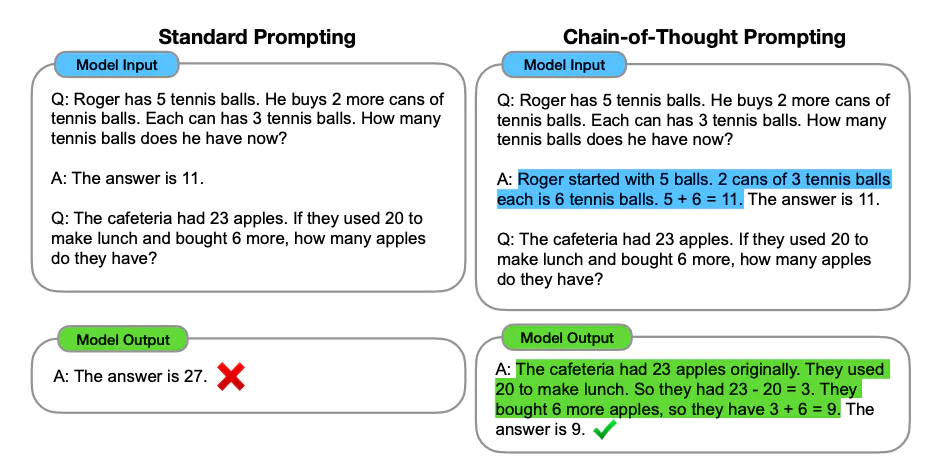
标准 prompt 与 CoT prompt
Few-Shot CoT:拉开思维链的序幕
Chain of Thought Prompting Elicits Reasoning in Large Language Models.
初代思维链适用于 Few-Shot prompt,相比标准 Few-Shot prompt,思维链 Few-Shot prompt 仅仅是在答案前添加了推理步骤,如原来的提示样本可能是:
示例问题+答案+实际问题
输入给模型从而直接得到问题答案,而添加过 CoT 的提示样本为:
示例问题+示例推理过程+答案+实际问题
其中的示例推理过程也就是解决原问题的思维链,从而诱导模型在输出答案前先按照示例给出推理步骤,将原问题解析成多个子问题,辅助模型进行“思考”。
不仅无需对模型进行改造也可以大幅度提高模型的推理能力,而且效果可谓是立竿见影,在 PaLM-540B上 甚至有接近三倍的效果提升,相比以往的通过微调提升模型能力的方式,CoT 可谓是为大模型推理的提高打开了新的大门。
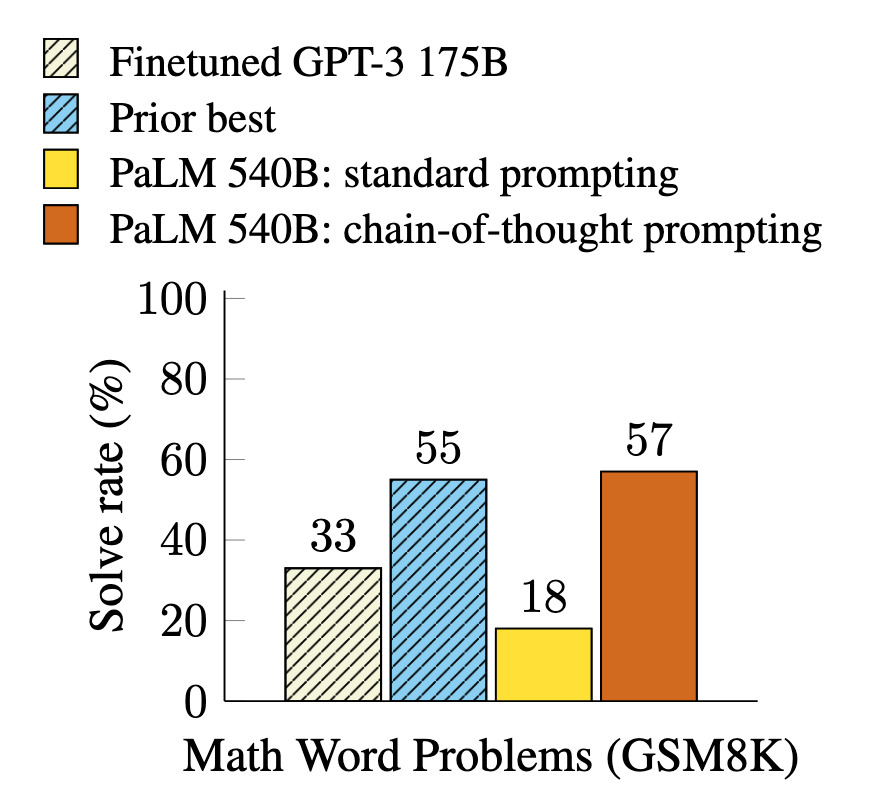
Few-Shot CoT 效果
那么,还有没有更简单的方式来实现思维链呢,有没有 Zero-Shot 版本的思维链实现方式?还真有。
Zero-Shot CoT:简洁而高效
Large Language Models Are Zero-Shot Reasoners
这可能是最简单的 CoT 方法。
只在问题后加上“Let's think step by step"即可轻松实现零样本 CoT prompt,并且此方法无需额外样本,为模型明确了思考的方向(即一步步解决问题),从而增强其问题解决的能力:

Zero-Shot CoT
这是一种简单有效,甚至有点神奇的提升模型推理能力的方式,就像是小明的老师做的一样,提示模型拆解问题再解答。
对同一数据集 MultiArith,论文中尝试了很多类似的提示词,效果不一:

不同的 Zero-Shot CoT 提示词
所以在实践中如果要使用 Zero-Shot CoT 来解决推理问题,针对数据集的特点来尝试多种提示词还是有必要的。
Self-Consistency (SC):多路径推理+投票机制
Self-Consistency Improves Chain of Thought Reasoning in Language Models
SC 方法由谷歌大脑团队,它通过为问题生成多个不同的推理路径,并对每个路径生成的最终答案进行众数投票,从而提高推理的准确性。
如下图中,SC 方法往往会针对一个问题生成多次 CoT 结果,k 次 CoT 相当于让模型生成k次推理+答案,最后在答案中取众数(如下图中 k取 3,得到推理路径和答案:18、18、26,取众数投票得 18):
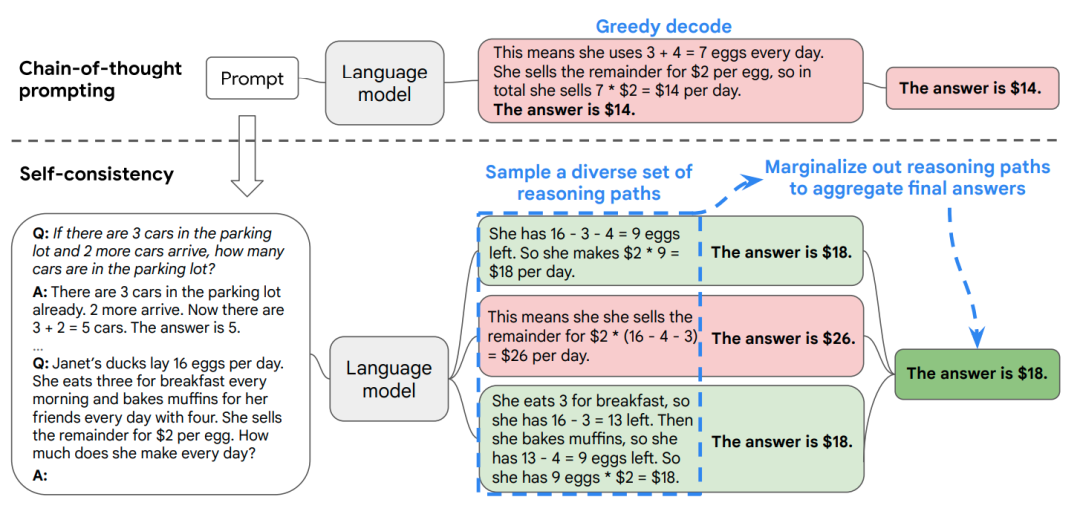
Self-Consistency 多路径采样与投票机制
这种方法在复杂推理任务中表现出色,但相比普通 CoT 方法需要更多的时间和资源,那么是采样越多次效果就越好吗?

采样路径数与效果关系,来自原论文
根据论文实验,在多个推理数据集上 SC 方法在采样次数 k 在 20~40 次时提升效果放缓,40 次时多数数据集趋于饱和,然而采样 40 次需要极大的资源消耗,所以具体使用 SC 方法时需要根据需求和资源来选择适合的采样次数,从而得到效果提升和资源占用的平衡。
Tree-of-Thoughts (ToT):多维度思考,全面解决问题
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
ToT 方法与传统的 CoT 方法不同,其允许模型交叉考虑多种不同的推理路径通,通过对多段推理过程进行评估,以及在必要时进行前瞻或回溯以做出全局选择,形成了树形的推理结构,如下图右所示:
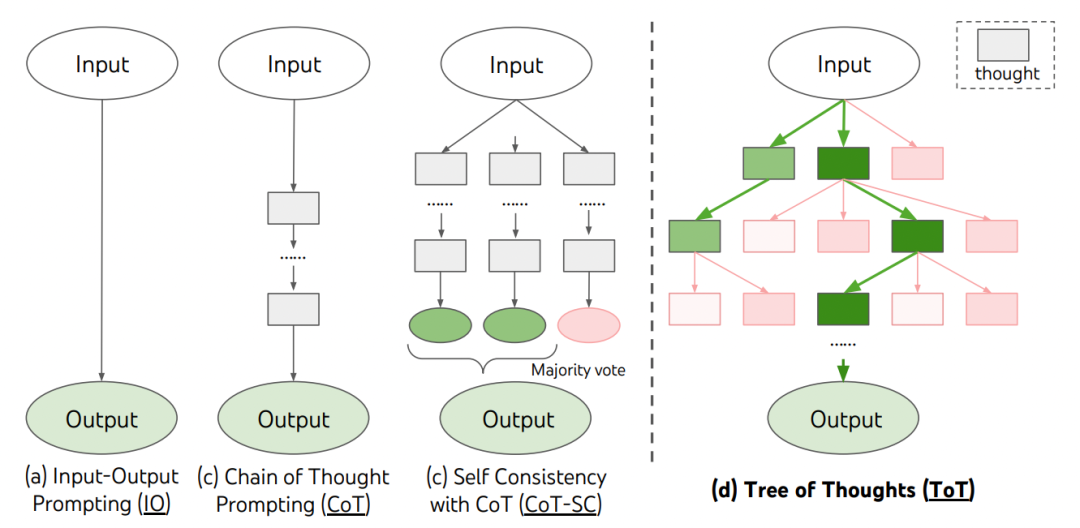
Tree-of-Thoughts 对比
具体的,主要分为下面的四个阶段:
1. 问题分解 (Thought Decomposition)
根据问题的特点,将问题分解成多个中间步骤。每个步骤可以是短语、算式或写作计划,这取决于问题的性质。
2. 推理过程生成 (Thought Generation)
假设解决问题需要k个步骤,有两种方法生成每步的推理内容:
- 独立采样:对于每个状态,模型会独立地从 CoT 提示中完整抽取 k 个推理内容,不依赖于其他的推理内容。
- 顺序生成:顺序地使用“提示”来逐步引导推理内容生成,每个推理内容都可能依赖于前一个推理内容。
3. 启发式评估 (Heuristic Evaluation)
使用启发式方法评估每个生成的推理内容对问题解决的贡献,这种自我评估基于语言模型的自我反馈,如设计Prompt让模型对多个生成结果进行打分。
4. 搜索算法 (Search Algorithm)
根据生成和评估推理内容的方法,选择适当的搜索算法。例如,可以使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来系统地探索思考树,并进行前瞻和回溯。
以 24 点游戏为例,该游戏要求判断给定的 4 个整数值能否通过+、-、×、÷操作得到结果 24,用 ToT 解决时,可以:
1. 分成三个步骤解决,每个步骤为一个中间算式,如给定4 9 10 13 ,用如下三个步骤可以解决,每次运算一次:
- 13 - 9 = 4 (left: 4 4 10);
- 10 - 4 = 6 (left: 4 6);
- 4 * 6 = 24 (left: 24)
2. 在每个步骤中,采用下图(a)中的 few-shot prompt 过程让模型生成多个候选者;
3. 对于每个步骤中的候选者,用(b)中的过程同样用模型来做评估,如评价该候选者剩余数10 13 13是否能运算得到 24 点impossible,下一步将从得分较高的候选者出发;
4. 对每个步骤都执行 2、3 来生成中间算式以及评估;
5. 进行 BFS 搜索,采样出可行的解法路径(绿色部分)。
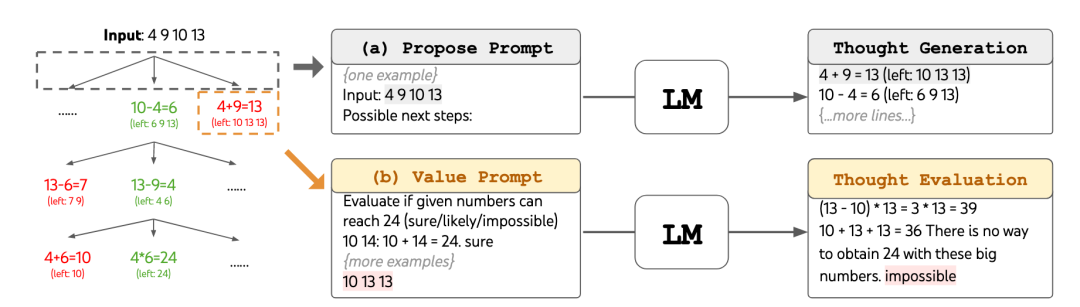
用 ToT 解决 24 点问题
对于 ToT 效果,同样以 24 点游戏为例,在 GPT-4 模型为基座模型的情况下,其效果要远高好于一般的 CoT 方法,如 SC 和 Few-Shot CoT 在该任务上只有不到 10% 的准确率,而 ToT 可以达到 74%:
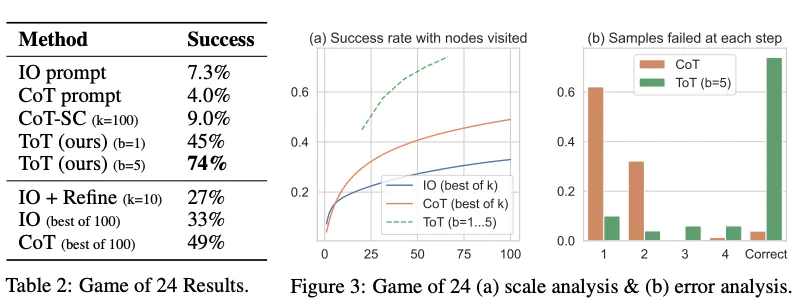
但对于任务的易用性来讲,使用 ToT 方法需要能熟悉任务并把任务进行合理拆解成有限步骤,同时也需要根据任务的每个步骤设计相应的生成和评价方法,最后使用 DFS 或者 BFS 来采样得到解决,同样也需要能较好跟随 Prompt 指令的基座模型,比如论文作者用的 GPT-4。如果能满足以上条件,ToT 会是你解决复杂问题的一把利刃。
如何让你的模型变得更强
OpenCompass 是上海人工智能实验室推出的大模型一站式评测平台,OpenCompass 目前已经支持上述从 Zero-Shot CoT 到 Tree-of-Thoughts 等一系列 CoT 技术。
依托于 OpenCompass 丰富的评测能力,可以一键进行 20+ 开源大模型 及 OpenAI API 模型在 50+ 个数据集约 30 万题上的多种 CoT 评测,如下方是一个使用 OpenCompass 测试 GSM8k 数据集的样例 :
# 此SC版gsm8k测试配置可以在:
# opencompass.configs.datasets.gsm8k.gsm8k_gen_a3e34a.py 中找到。
gsm8k_infer_cfg = dict(
inferencer=dict(
type=SCInferencer, # 替换 GenInferencer 为 SCInferencer
# 设置采样参数以确保模型生成不同的输出,目前适用于从HuggingFace加载的模型。
generation_kwargs=dict(do_sample=True, temperature=0.7, top_k=40),
sc_size = SAMPLE_SIZE # 采样的SC路径数
)
)
gsm8k_eval_cfg = dict(sc_size=SAMPLE_SIZE)在实现方法的同时,OpenCompass 也添加了些新的特性,如目前 ToT 官方 Repo 只支持 OpenAI api 模型的使用,OpenCompass 将其扩充到常见的开源大模型,可方便地在不同量级及类型的大模型上调试客制化与经典数据集。
下面是使用 OpenCompass 得到的 SC 和 ToT 评测结果对比:
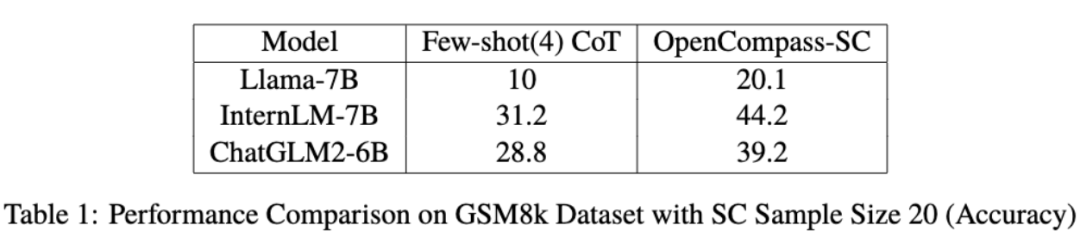

OpenCompass 旨在整合 CoT 这一强大工具,以更好地助力社群全面挖掘大型语言模型中潜藏的巨大潜能,期望这些创新方法能进一步加速大型语言模型在复杂任务中的研究与应用。随着更多的人员投入使用和研究,相信未来的 AI 技术必将更加聪明、高效并实用。
OpenCompass 项目地址:
https://github.com/internLM/OpenCompass/
CoT 教程:https://opencompass.readthedocs.io/zh_CN/latest/prompt/chain_of_thought.html
大模型评测榜单:
https://opencompass.org.cn/leaderboard-llm
欢迎大家在 OpenCompass 提交评测申请。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号