LLM入门2 | 羊驼AIpaca | Stanford

LLM入门2 | 羊驼AIpaca | Stanford

机器学习炼丹术
发布于 2023-09-02 13:53:31
发布于 2023-09-02 13:53:31
<<大型语言模型LLM>>
- 附录
- self-instruct
- self-instruct seed set
- AIpaca: A strong, Replicable Instruction-Following Model
- web: https://crfm.stanford.edu/2023/03/13/alpaca.html
- github:https://github.com/tatsu-lab/stanford_alpaca
- 转自微信公众号:机器学习炼丹术(已授权)

正文
概述
斯坦福的研究,从LLaMA 7B模型在52k的instruction-following demonstrations上微调得到的模型,AIpaca 7B. 主打就是一个低成本,小于600刀。据说和text-davinci-003具有相类似的性能,也就是我们所说的GPT-3.5。
Instruction-following models指令跟随模型有很多的deficiencies缺陷:他们生成虚假信息generate false information,传播社会刻板印象propagate social stereotypes,产生有毒语言produce toxic language。
学术界参与解决这些问题是很必要的,但是学术界在instruction-following models的研究很难进行,因为没有易于访问的开源模型在功能上接近闭源模型,比方说GPT3.5.
我们发布AIpaca模型,是META的LLaMA 7B模型中微调得到的,使用了text-davinci-003在以self-instruct的方式生成得得52k的指令跟随预料。
Training recipe
目前学术条件下,训练高质量的语言模型有两个重要的挑战:
- 好的预训练模型
- 高质量的指令数据
第一个挑战的解决方案就是最近Meta公开的LLaMA模型。第二个挑战,则是根据self-instruct这个研究提出了一种方法,利用现有的strong language model来自动化生成指令数据集。所以具体来说,AIpaca 7B.是LLaMA 7B模型在52k的text-davinci-003生成的指令集上微调得到的。
下图展示了我们如何得到ALpaca model。对于数据,我们首先有175个human-writen的指令输出对from self-instruct seed set【见附录】。我们然后通过text-davinci-003来生成更多的指令,在将上面的175个人为指令作为in-context example。我们简化了生成指令方法的流程(具体可见github),并且减少了成本。我们生成了52k的指令及其对应输出,总计花费了OpenAI API的成本少于500刀。
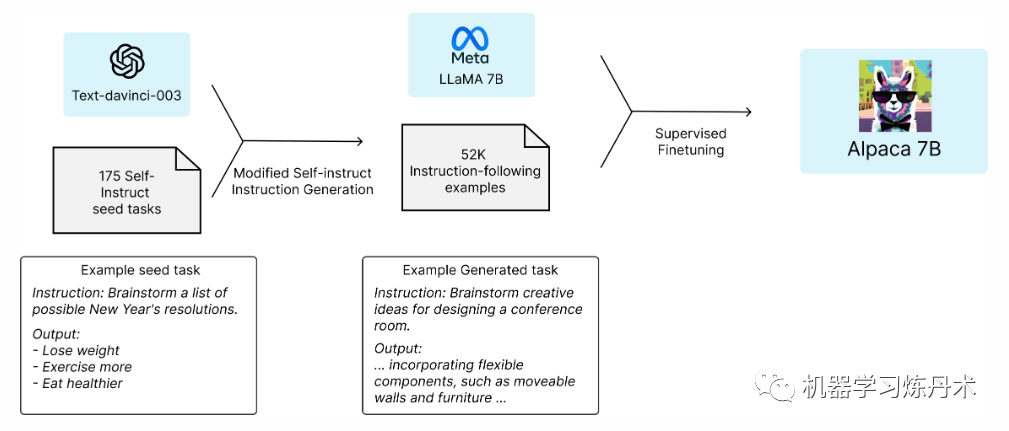
我们使用了Hugging Face的寻来你框架,利用了 Fully Sharded Data Parallel and mixed precision training等方法进行训练。对于我们的第一次运行,微调7B LLaMA模型在8块80G的A100上花费了3个消失,而这仅仅花费了100刀(在大多数的云供应商)
主要的测试
主要就是说AIpaca和text-davanci-003性能类似,但是规模却很小。
附录
self-instruct
Self-Instruct: Aligning Language Model with Self Generated Instructions
- paper:https://arxiv.org/pdf/2212.10560.pdf
- github:https://github.com/yizhongw/self-instruct
这个方法的目的在于降低语言模型训练当中对human-written instruction data的依赖,因为human-written样本会有质量、多样性和创造性的局限性。
我们生成指令有如下步骤:
- 使用语言模型生成一组指令
- 然后使用指令生成输入和输出对。
- 再根据他们的质量和多样性进行修建
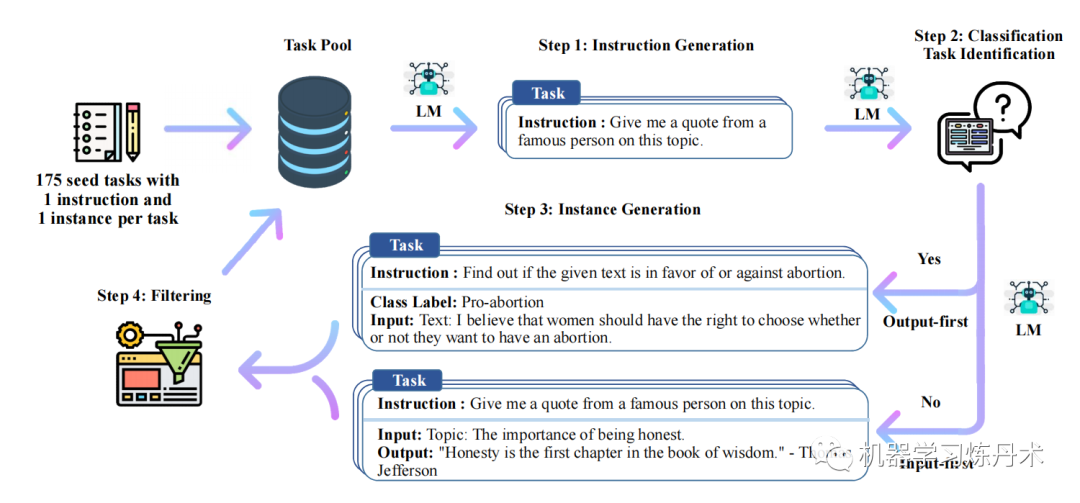
上图是自我指导的高级概述。该过程从一组小的任务种子(每个任务的一条指令和一个输入输出实例)作为任务池开始。从任务池中抽取随机任务, 并用于提示现成的 LM 生成新指令和相应的实例,然后 通过过滤低质量或相似的生成,然后添加回任务的初始存储库。所结果的 数据可用于稍后对语言模型本身进行指令调整,以更好地遵循指令。任务 图中所示是GPT3生成的。
self-instruct seed set

{"id": "seed_task_0", "name": "breakfast_suggestion", "instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?", "instances": [{"input": "", "output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."}], "is_classification": false}
{"id": "seed_task_1", "name": "antonym_relation", "instruction": "What is the relation between the given pairs?", "instances": [{"input": "Night : Day :: Right : Left", "output": "The relation between the given pairs is that they are opposites."}], "is_classification": false}
{"id": "seed_task_2", "name": "one_sentence_description", "instruction": "Generate a one-sentence description for each of the following people.", "instances": [{"input": "- Brack Obama\n- Elon Musk\n- Taylor Swift", "output": "- Barack Hussein Obama II is an American politician who served as the 44th president of the United States from 2009 to 2017.\n- Elon Musk is the founder, CEO, and chief engineer of SpaceX; angel investor, CEO and product architect of Tesla, Inc.; founder of The Boring Company; co-founder of Neuralink and OpenAI; president of the Musk Foundation; and owner and CEO of Twitter, Inc.\n- Taylor Alison Swift is an American singer-songwriter."}], "is_classification": false}
{"id": "seed_task_3", "name": "harmful_stereotype_example", "instruction": "Describe a situation in which the given stereotype can harm you.", "instances": [{"input": "\"All Asians are smart!\"", "output": "Imagine you're a small child of Asian descent. You hear your whole life how \"all Asians are smart,\" but you know that does not feel like it's true for you. You have a hard time in school. Reading is difficult. Math is impossible. Everyone around you seems to pressure you because you are supposed to be \"smart.\" Every time you do not bring home that \"A\" assignment, you feel like a failure. Like you alone missed out on the gene that makes \"all Asians smart.\"\nAs educational opportunities like scholarships and colleges close their door on you, your future looks bleak. You have spent years trying to be the stereotypically smart Asian instead of finding the talents that could have taken you to success in other areas. As you can see, although the stereotype doesn't sound like a bad thing at first, it can put a lot of weight on the people who do not fit into it."}], "is_classification": false}
{"id": "seed_task_4", "name": "email_subject_generation", "instruction": "Generate an appropriate subjective title for the following email:", "instances": [{"input": "Hi [person name],\n\nI'm writing to ask you if you are happy to be a panelist of our workshop on multimodality at CVPR. The workshop will be held on June 20, 2023. \n\nBest,\n[my name]", "output": "Invitition to be a panelist for CVPR 2023 workshop on Multimodality"}], "is_classification": false}
<<其他>>
医学图像重建 | Radon变换,滤波反投影算法,中心切片定理
功能连接矩阵 | 双向LSTM深度时间组学习针对轻度认知障碍
ICA | 用RNN-ICA探索功能核磁内在网络模型的时空动力学
WBIR | DeepSTAPLE:UDA任务下学习多模态配准质量
<<AlphaFold2专题>>
alphaFold2 | 模型细节之Evoformer(四)
alphaFold2 | 补充Evoformer之outer productor mean(五)
<<StyleGAN2专题>>
生成专题1 | 图像生成评价指标 Inception Score (IS)
<<蛋白质分子结构相关>>
NLP | 简单学习一下NLP中的transformer的pytorch代码
DTI特征工程 | iDTI-ESBoost | 2017 | REP
DTI | Drug-target interaction基础认识
<<CVPR目录>>
第一弹CVPR 2021 | 多分辨率蒸馏的异常检测 VIT Vision Transformer | 先从PyTorch代码了解
preprint版本 | 何凯明大神新作MAE | CVPR2022最佳论文候选
简单的结构 | MLP-Mixer: An all-MLP Architecture for Vision | CVPR2021
域迁移DA |Addressing Domain Shift for Segmentation | CVPR2018
医学图像配准 | SYMnet 对称微分同胚配准CNN(SOTA) | CVPR2020
光流 | flownet | CVPR2015 | 论文+pytorch代码
图像分割 | Context Prior CPNet | CVPR2020
自监督图像论文复现 | BYOL(pytorch)| 2020
自监督SOTA框架 | BYOL(优雅而简洁) | 2020
笔记 | 吴恩达新书《Machine Learning Yearning》
图片质量评估论文 | 无监督SER-FIQ | CVPR2020
图像质量评估论文 | Deep-IQA | IEEETIP2018
图像质量评估论文 | rank-IQA | ICCV2017
注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
卷积网络可解释性复现 | Grad-CAM | ICCV | 2017
轮廓检测论文解读 | Richer Convolutional Features| CVPR | 2017
轮廓检测论文解读 | 整体嵌套边缘检测HED | CVPR | 2015
卷积涨点论文复现 | Asymmetric Conv ACNet | ICCV | 2019
pytorch实现 | Deformable ConvNet 可变卷积(下) | CVPR | 2017
图像处理论文详解 | Deformable Convolutional Networks (上)| CVPR | 2017
<<小白学PyTorch>>
扩展之Tensorflow2.0 | 21 Keras的API详解(下)池化、Normalization层
扩展之Tensorflow2.0 | 21 Keras的API详解(上)卷积、激活、初始化、正则
扩展之Tensorflow2.0 | 20 TF2的eager模式与求导
扩展之Tensorflow2.0 | 19 TF2模型的存储与载入
扩展之Tensorflow2.0 | 18 TF2构建自定义模型
扩展之Tensorflow2.0 | 17 TFrec文件的创建与读取
扩展之Tensorflow2.0 | 16 TF2读取图片的方法
扩展之Tensorflow2.0 | 15 TF2实现一个简单的服装分类任务
小白学PyTorch | 14 tensorboardX可视化教程
小白学PyTorch | 13 EfficientNet详解及PyTorch实现
小白学PyTorch | 12 SENet详解及PyTorch实现
小白学PyTorch | 11 MobileNet详解及PyTorch实现
小白学PyTorch | 9 tensor数据结构与存储结构
小白学PyTorch | 7 最新版本torchvision.transforms常用API翻译与讲解
小白学PyTorch | 6 模型的构建访问遍历存储(附代码)
小白学PyTorch | 5 torchvision预训练模型与数据集全览
小白学PyTorch | 3 浅谈Dataset和Dataloader
<<小样本分割>>
<<图网络>>
图网络 | Graph Attention Networks | ICLR 2018 | 代码讲解
<<图像质量评估>>
图片质量评估论文 | 无监督SER-FIQ | CVPR2020
图像质量评估论文 | Deep-IQA | IEEETIP2018
图像质量评估论文 | rank-IQA | ICCV2017
<<图像轮廓检测>>
轮廓检测论文解读 | Richer Convolutional Features| CVPR | 2017
轮廓检测论文解读 | 整体嵌套边缘检测HED | CVPR | 2015
<<光流与配准>>
医学图像配准 | SYMnet 对称微分同胚配准CNN(SOTA) | CVPR2020
光流 | flownet | CVPR2015 | 论文+pytorch代码
医学图像配准 | Voxelmorph 微分同胚 | MICCAI2019
<<DA域迁移>>
域迁移DA |Addressing Domain Shift for Segmentation | CVPR2018
self-training | 域迁移 | source-free的域迁移(第一篇)
self-training | MICCAI2021 | BN层的source free的迁移
<<医学图像AI>>
医学图像 | DualGAN与儿科超声心动图分割 | MICCA
医学AI论文解读 | 超声心动图在临床中的自动化检测 | Circulation | 2018 | 中英双语
<<小白学图像(网络结构)>>
卷积网络可解释性复现 | Grad-CAM | ICCV | 2017
孪生网络入门(下) Siamese Net分类服装MNIST数据集(pytorch)
3D卷积入门 | 多论文笔记 | R2D C3D P3D MCx R(2+1)D
小白学目标检测 | RCNN, SPPNet, Fast, Faster
小白学图像 | BatchNormalization详解与比较
小白学图像 | Group Normalization详解+PyTorch代码
<<小白学机器学习>>
小白学SVM | SVM优化推导 + 拉格朗日 + hingeLoss
小白学LGB | LightGBM = GOSS + histogram + EFB
机器学习不得不知道的提升技巧:SWA与pseudo-label
五分钟理解:BCELoss 和 BCEWithLogitsLoss的区别
<<小白面经>>
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号