票房20亿,豆瓣7.0?Python分析电影《孤注一掷》豆瓣评论数据

票房20亿,豆瓣7.0?Python分析电影《孤注一掷》豆瓣评论数据

松鼠爱吃饼干
发布于 2023-09-02 17:42:38
发布于 2023-09-02 17:42:38
前言
环境使用
- Python 3.8 解释器
- Pycharm 编辑器
所需模块
import parsel >>> pip install parsel
import requests >>> pip install requests
import csv
一. 数据来源分析:
- 明确需求:
- 采集的网站是什么?
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
- 采集的数据是什么? 评论相关数据
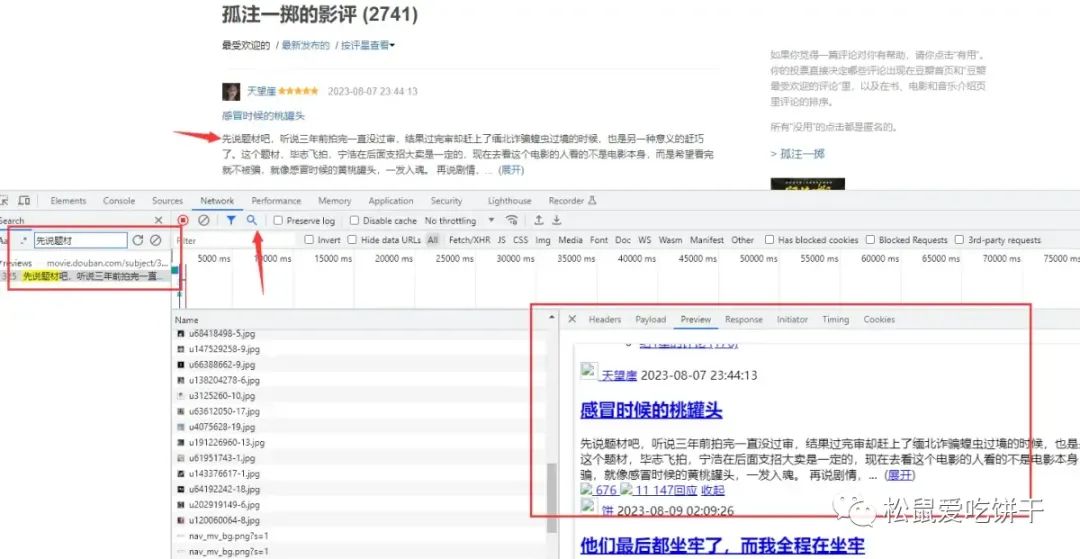
- 抓包分析相关数据来源 通过浏览器自带开发者工具进行抓包分析 <重点>
- 打开开发者工具: F12 或者 鼠标右键点击检查选择network
- 刷新网页: 让本网页的数据内容重新加载一遍
- 关键字搜索: 通过关键字<要的数据>, 搜索查询相对应的数据包
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
二. 代码实现步骤: 基本四大步骤 --> 发送请求,获取数据,解析数据,保存数据
- 发送请求, 模拟浏览器对于url地址发送请求
https://movie.douban.com/subject/35267208/comments?limit=20&status=P&sort=new_score
- 获取数据, 获取服务器返回响应数据 开发者工具 --> response
- 解析数据, 提取我们想要的数据内容 评论相关数据
- 保存数据, 把数据内容保存表格文件里面
评论数据获取
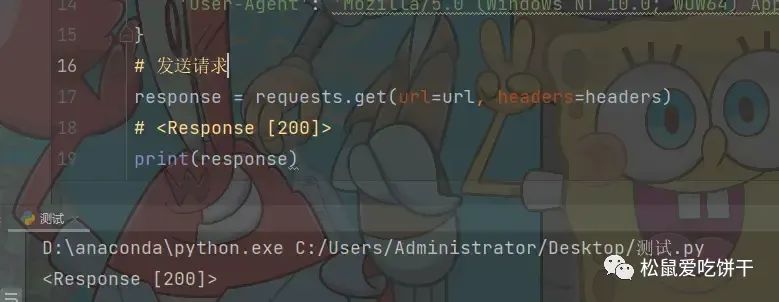
发送请求, 模拟浏览器对于url地址发送请求
返回<Response [200]>表示请求成功
# 请求链接
url = f'https://movie.douban.com/subject/35267224/comments?start=20&limit=20&status=P&sort=new_score'
# 伪装模拟
headers = {
# User-Agent 用户代理, 表示浏览器基本身份标识
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
print(response)
解析数据
解析方法:
- 正则re --> 直接对于字符串数据进行解析
- css选择器 --> 根据标签属性提取数据
- xpath节点提取 --> 根据标签节点提取数据
把获取下来html字符串数据 <response.text>, 转成可解析对象 <Selector xpath=None data='<html lang="zh-CN" class="ua-windows ...'>
提取具体数据内容 .comment-info a --> 定位class类名为comment-info下面a标签 a::text --> 提取a标签里面文本 get() --> 获取第一个标签内容 attr() --> 提取属性
selector = parsel.Selector(response.text)
# 第一次提取, 所有div标签
divs = selector.css('div.comment-item')
# for循环遍历, 把列表里面元素一个一个提取出来
for div in divs:
name = div.css('.comment-info a::text').get() # 昵称
rating = div.css('.rating::attr(title)').get() # 推荐
date = div.css('.comment-time::attr(title)').get() # 时间
area = div.css('.comment-location::text').get() # 地区
votes = div.css('.votes::text').get() # 有用
short = div.css('.short::text').get().replace('\n', '') # 评论
# 数据存字典里面
dit = {
'昵称': name,
'推荐': rating,
'时间': date,
'地区': area,
'有用': votes,
'评论': short,
}
# 写入数据
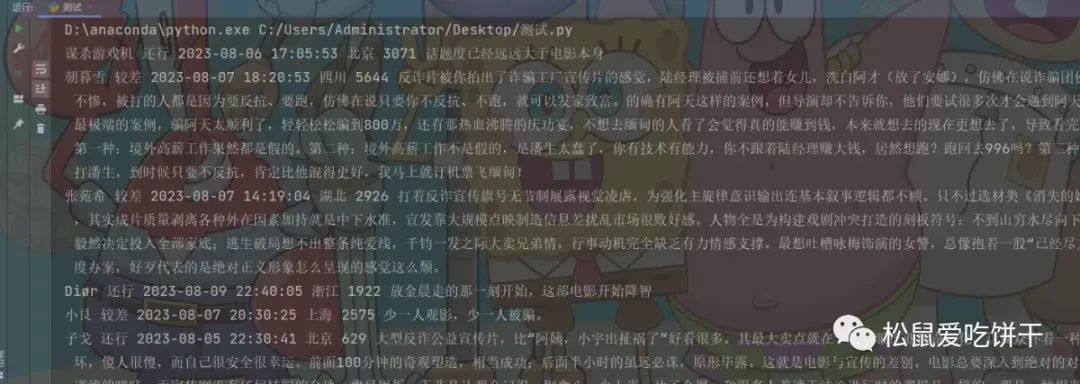
print(name, rating, date, area, votes, short)
保存数据
data.csv --> 文件名 mode=a --> 保存方式 追加保存 encoding='utf-8' --> 编码格式 newline --> 换行符 f --> 文件对象
f = open('data10.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'昵称',
'推荐',
'时间',
'地区',
'有用',
'评论',
])
# 写入表头
csv_writer.writeheader()
分析评论数据
导入模块
import pandas as pd
import jieba
import wordcloud
读取数据
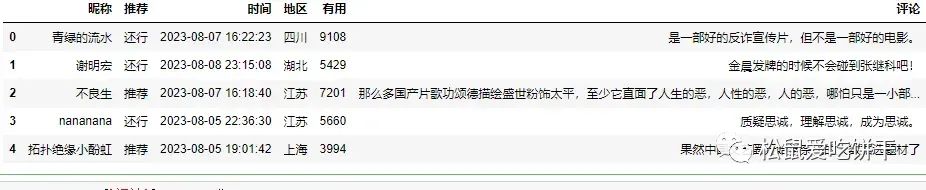
df = pd.read_csv('data10.csv')
df.head()
推荐分布
import pyecharts.options as opts
from pyecharts.charts import Pie
data_pair = [list(z) for z in zip(evaluate_type, evaluate_num)]
data_pair.sort(key=lambda x: x[1])
c = (
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
series_name="豆瓣影评",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="推荐分布",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
c.render_notebook()
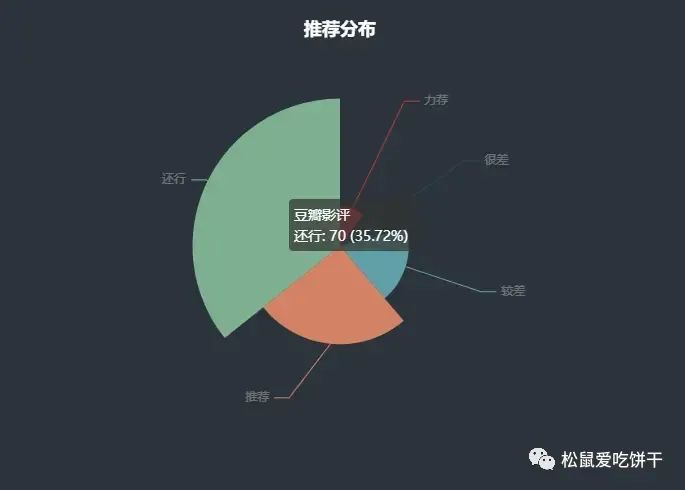
地区分布
import pyecharts.options as opts
from pyecharts.charts import Pie
data_pair = [list(z) for z in zip(area_type, area_num)]
data_pair.sort(key=lambda x: x[1])
d = (
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
series_name="豆瓣影评",
data_pair=data_pair,
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title="地区分布",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff"),
),
legend_opts=opts.LegendOpts(is_show=False),
)
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"),
)
)
d.render_notebook()
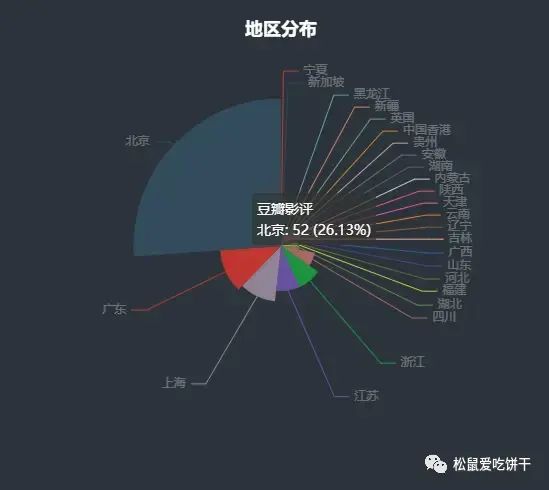
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号