Pytorch实现15种常用学习率调整策略(自定义学习率衰减)

Pytorch实现15种常用学习率调整策略(自定义学习率衰减)

自学气象人
发布于 2023-09-06 14:24:12
发布于 2023-09-06 14:24:12
本文主要包含以下15种学习率调整策略:
- 1 LambdaLR
- 2 MultiplicativeLR
- 3 StepLR
- 4 MultiStepLR
- 5 ConstantLR
- 6 LinearLR
- 7 ExponentialLR
- 8 CosineAnnealingLR
- 9 CosineAnnealingWarmRestarts
- 10 ReduceLROnPlateau
- 11 CyclicLR
- 12 OneCycleLR
- 13 warm up
- 14 ChainedScheduler
- 15 SequentialLR
1 LambdaLR
以自定义一个函数作为乘法因子控制衰减。
公式:
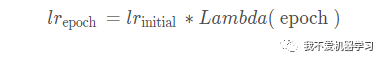
函数:
"""
将每个参数组的学习率设置为初始 lr 乘以给定函数.
当 last_epoch=-1 时,设置 lr 为 初始 lr.
"""
torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda,last_epoch=-1,verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
"""
torch.optim版:
import torch
from torch import nn
from torch.optim.lr_scheduler import LambdaLR
import numpy as np
NUM_EPOCHS = 100
model = nn.Linear(2, 1)
def scheduler_lr(optimizer, scheduler):
lr_history = []
"""optimizer的更新在scheduler更新的前面"""
for epoch in range(NUM_EPOCHS):
optimizer.step() # 更新参数
lr_history.append(optimizer.param_groups[0]['lr'])
scheduler.step() # 调整学习率
return lr_history
"""设置优化器,初始化学习率"""
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
"""设置lr策略"""
lr_lambda = lambda epoch:1.0 if epoch<10 else np.math.exp(0.1*(10-epoch))
scheduler = LambdaLR(optimizer=optimizer,lr_lambda=lr_lambda)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomLambdaLR:
def __init__(self,optimizer,lr_lambda,last_epoch=-1):
self.optimizer = optimizer
self.last_epoch = last_epoch
if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple):
self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups)
else:
self.lr_lambdas = list(lr_lambda)
def get_lr(self):
lr = []
for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs):
lr.append(base_lr * lmbda(self.last_epoch))
return lr
def step(self):
self.base_lrs = [group['initial_lr'] for group in optimizer.param_groups]
self.last_epoch += 1
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomLambdaLR(optimizer2, lr_lambda, last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
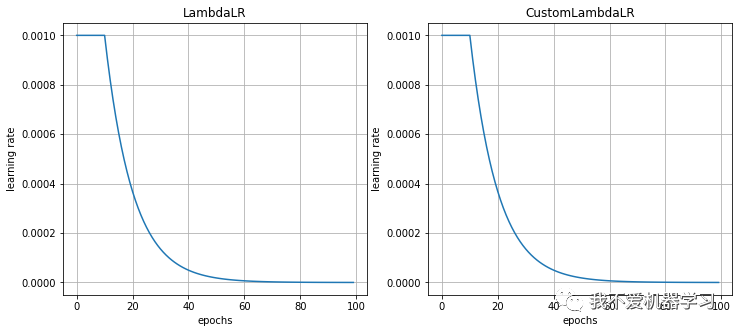
从图中可以看出,epoch小于10时,学习率不变;≥10之后,学习率指数下减。
2 MultiplicativeLR
每组参数的学习率乘以指定函数中给定的因子。当last_epoch=-1时,将初始lr设置为lr。
公式:
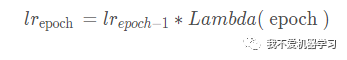
函数:
"""
设置学习率为上一次的学习率乘以给定lr_lambda函数的值。
"""
torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda,last_epoch=-1,verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer..
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
"""
torch.optim版:
from torch.optim.lr_scheduler import MultiplicativeLR
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer,lmbda)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomMultiplicativeLR(CustomLambdaLR):
def __init__(self,optimizer,lr_lambda,last_epoch=-1):
super(CustomMultiplicativeLR, self).__init__(optimizer,lr_lambda,last_epoch)
def get_lr(self):
if self.last_epoch > 0:
return [group['lr'] * lmbda(self.last_epoch)
for lmbda, group in zip(self.lr_lambdas, self.optimizer.param_groups)]
else:
return [group['lr'] for group in self.optimizer.param_groups]
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomMultiplicativeLR(optimizer2, lmbda, 0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
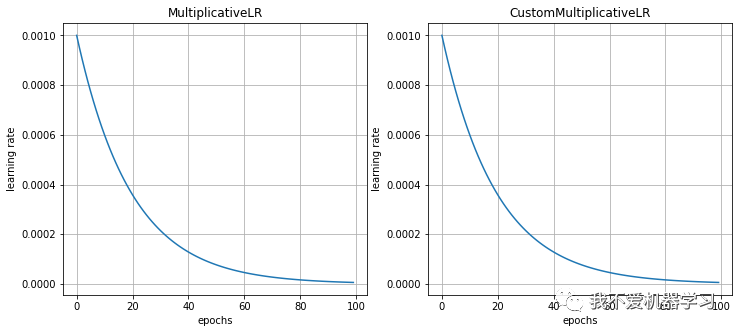
3 StepLR
StepLR则是类似于越阶式的衰减方式,它的衰减是一个断崖式的下落。
在每经过固定的epoch之后,lr 就会乘以一次gamma,即衰减为原来的gamma倍。
公式:
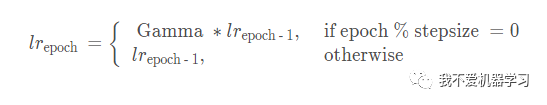
函数:
"""
每一个步长时期,每个参数组的学习速率以伽马衰减。
注,这种衰减可能与这个调度程序外部对学习速率的其他改变同时发生。
"""
torch.optim.lr_scheduler.LambdaLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
step_size (int): Period of learning rate decay.
gamma (float): Multiplicative factor of learning rate decay.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update.Default: ``False``.
"""
torch.optim版:
from torch.optim.lr_scheduler import StepLR
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = StepLR(optimizer=optimizer, step_size=10, gamma=0.9)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomStepLR:
def __init__(self,optimizer,step_size,gamma=0.1,last_epoch=-1):
self.optimizer = optimizer
self.last_epoch = last_epoch
self.step_size = step_size
self.gamma = gamma
def get_lr(self):
if (self.last_epoch == 0) or (self.last_epoch % self.step_size != 0):
return [group['lr'] for group in self.optimizer.param_groups]
return [group['lr'] * self.gamma
for group in self.optimizer.param_groups]
def step(self):
self.last_epoch += 1
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomStepLR(optimizer2, step_size=10, gamma=0.9, last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
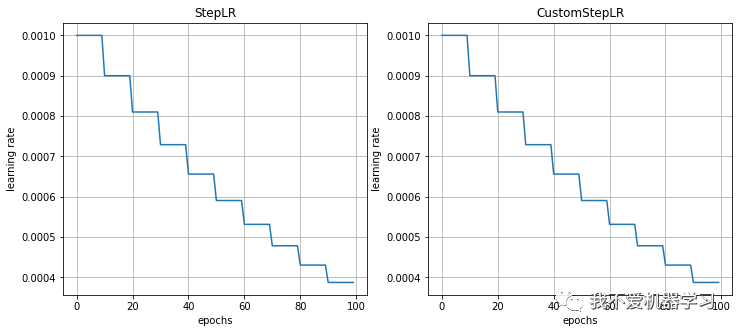
4 MultiStepLR
多步长衰减,可以指定衰减的步长区间。
公式:
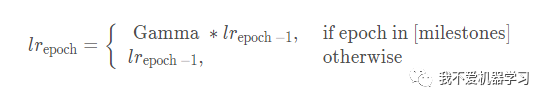
函数:
torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones,
gamma=0.1, last_epoch=-1, verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
milestones (list): List of epoch indices. Must be increasing.
gamma (float): Multiplicative factor of learning rate decay. Default: 0.1.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
"""
torch.optim版:
from torch.optim.lr_scheduler import MultiStepLR
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = MultiStepLR(optimizer=optimizer, milestones=[50, 70, 90], gamma=0.2)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomMultiStepLR(CustomStepLR):
def __init__(self,optimizer,milestones,gamma=0.1,last_epoch=-1):
self.milestones = milestones
super(CustomMultiStepLR,self).__init__(optimizer,step_size=0,gamma=gamma,last_epoch=last_epoch)
def get_lr(self):
if self.last_epoch not in self.milestones:
return [group['lr'] for group in self.optimizer.param_groups]
return [group['lr'] * self.gamma
for group in self.optimizer.param_groups]
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomMultiStepLR(optimizer2,milestones=[50, 70, 90],gamma=0.2,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
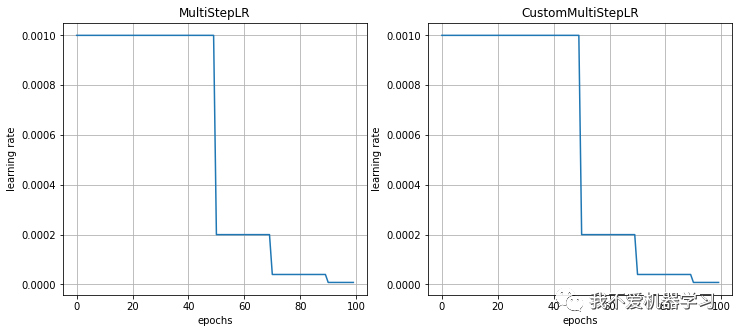
5 ConstantLR
将每个参数组的学习率衰减一个小的常数因子,直到 epoch 的数量达到预定义的milestone:total_iters。
注,这种衰减可能与此调度程序外部对学习率的其他更改同时发生。当 last_epoch=-1 时,设置初始 lr 为 lr。
函数:
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.3333333333333333, total_iters=5, last_epoch=- 1, verbose=False)
""""
Args:
optimizer (Optimizer): Wrapped optimizer.
factor (float): The number we multiply learning rate until the milestone. Default: 1./3.
total_iters (int): The number of steps that the scheduler decays the learning rate.
last_epoch (int): The index of the last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
"""
torch.optim版:
from torch.optim.lr_scheduler import ConstantLR
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3)
scheduler = ConstantLR(optimizer=optimizer,factor=1.0/3,total_iters=50)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomConstantLR:
def __init__(self,optimizer,factor,total_iters,last_epoch=-1):
self.optimizer = optimizer
self.factor = factor
self.total_iters = total_iters
self.last_epoch = last_epoch
def get_lr(self):
if self.last_epoch == 0:
return [group['lr'] * self.factor for group in self.optimizer.param_groups]
if (self.last_epoch > self.total_iters or (self.last_epoch != self.total_iters)):
return [group['lr'] for group in self.optimizer.param_groups]
if (self.last_epoch == self.total_iters):
return [group['lr'] * (1.0 / self.factor) for group in self.optimizer.param_groups]
def step(self):
self.last_epoch += 1
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomConstantLR(optimizer2,factor=1.0/3,total_iters=50,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
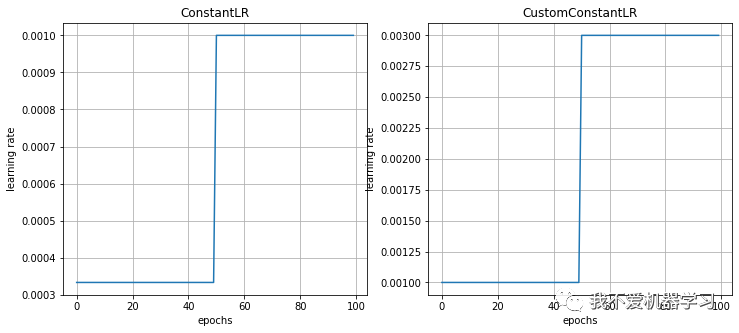
6 LinearLR
通过线性改变小的乘法因子来衰减每个参数组的学习率,直到 epoch 的数量达到预定义的milestone:total_iters。
函数:
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333333333333333, end_factor=1.0, total_iters=5, last_epoch=- 1, verbose=False)
""""
Args:
optimizer (Optimizer): Wrapped optimizer.
start_factor (float): 与第一个epoch相乘.
end_factor (float): 在线性变化结束时乘以学习率.
total_iters (int): 乘法因子达到 1 的迭代次数。
last_epoch (int): The index of the last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update.
"""
torch.optim版:
from torch.optim.lr_scheduler import LinearLR
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3)
scheduler = LinearLR(optimizer=optimizer,start_factor=1.0/3,end_factor=1.0,total_iters=15)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomLinearLR:
def __init__(self,optimizer,start_factor=1.0/3,end_factor=1.0,total_iters=5,last_epoch=-1):
self.optimizer = optimizer
self.start_factor = start_factor
self.end_factor = end_factor
self.total_iters = total_iters
self.last_epoch = last_epoch
def get_lr(self):
if self.last_epoch == 0:
return [group['lr'] * self.start_factor for group in self.optimizer.param_groups]
if (self.last_epoch > self.total_iters):
return [group['lr'] for group in self.optimizer.param_groups]
return [group['lr'] * (1. + (self.end_factor - self.start_factor) /
(self.total_iters * self.start_factor + (self.last_epoch - 1) * (self.end_factor - self.start_factor)))
for group in self.optimizer.param_groups]
def step(self):
self.last_epoch += 1
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomLinearLR(optimizer2,start_factor=1.0/3,end_factor=1.0,total_iters=15,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
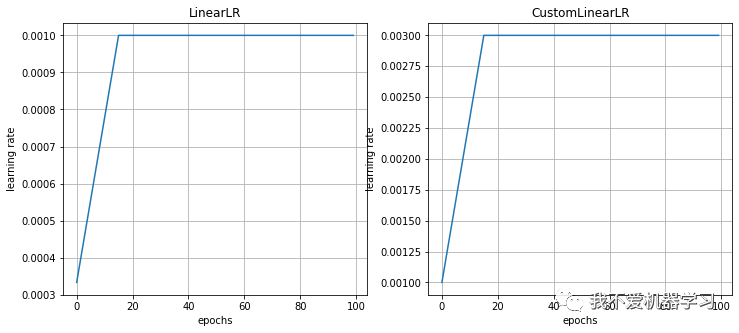
7 ExponentialLR
指数衰减,就是每一个epoch都会衰减的StepLR,其gamma就是对应的底数,epoch就是指数。
公式:
函数:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1, verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
gamma (float): Multiplicative factor of learning rate decay.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
"""
torch.optim版:
from torch.optim.lr_scheduler import ExponentialLR
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = ExponentialLR(optimizer=optimizer, gamma=0.9)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomExponentialLR(CustomStepLR):
def __init__(self,optimizer,gamma=0.1,last_epoch=-1):
super(CustomExponentialLR,self).__init__(optimizer,step_size=0,gamma=gamma,last_epoch=last_epoch)
def get_lr(self):
if self.last_epoch == 0:
return [group['lr'] for group in self.optimizer.param_groups]
return [group['lr'] * self.gamma
for group in self.optimizer.param_groups]
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomExponentialLR(optimizer2,gamma=0.9,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
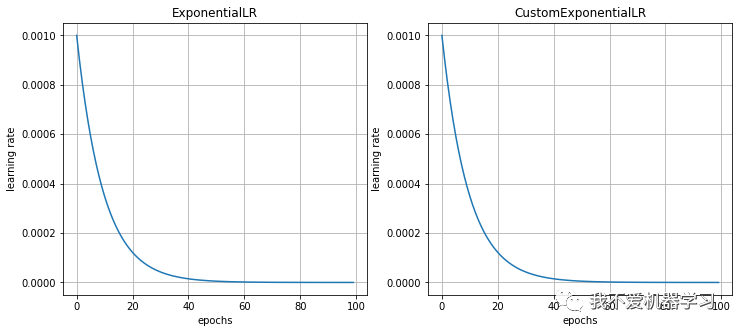
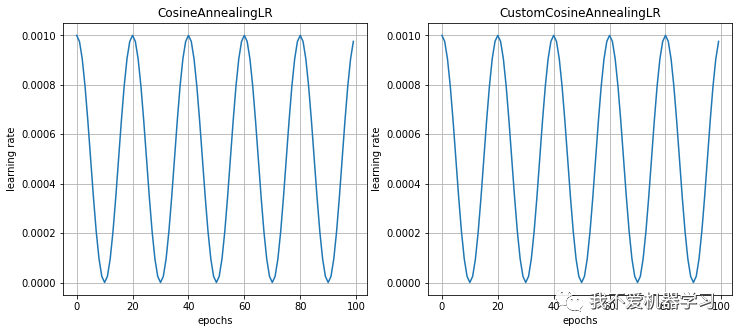
8 CosineAnnealingLR
余弦退火衰减会使学习率产生周期性的变化,其主要参数有两个,一个是 表示周期,一个是 表示学习率的最小值。
公式:
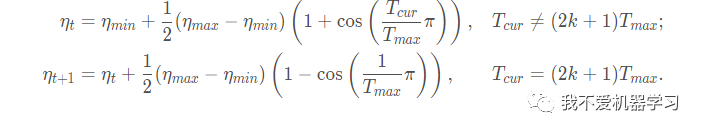
函数:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max,
eta_min=0, last_epoch=-1, verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
T_max (int): Maximum number of iterations.
eta_min (float): Minimum learning rate. Default: 0.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
https://arxiv.org/abs/1608.03983
"""
torch.optim版:
from torch.optim.lr_scheduler import CosineAnnealingLR
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = CosineAnnealingLR(optimizer=optimizer, T_max=10, eta_min=1e-6)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
import math
class CustomCosineAnnealingLR:
def __init__(self,optimizer,T_max,eta_min,last_epoch=-1):
self.optimizer = optimizer
self.last_epoch = last_epoch
self.T_max = T_max
self.eta_min = eta_min
def get_lr(self):
if self.last_epoch == 0:
return [group['lr'] for group in self.optimizer.param_groups]
elif (self.last_epoch - 1 - self.T_max) % (2 * self.T_max) == 0:
return [group['lr'] + (base_lr - self.eta_min) *
(1 - math.cos(math.pi / self.T_max)) / 2
for base_lr, group in
zip(self.base_lrs, self.optimizer.param_groups)]
return [(1 + math.cos(math.pi * self.last_epoch / self.T_max)) /
(1 + math.cos(math.pi * (self.last_epoch - 1) / self.T_max)) *
(group['lr'] - self.eta_min) + self.eta_min
for group in self.optimizer.param_groups]
def step(self):
self.base_lrs = [group['initial_lr'] for group in optimizer.param_groups]
self.last_epoch += 1
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomCosineAnnealingLR(optimizer=optimizer2, T_max=10, eta_min=1e-6,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
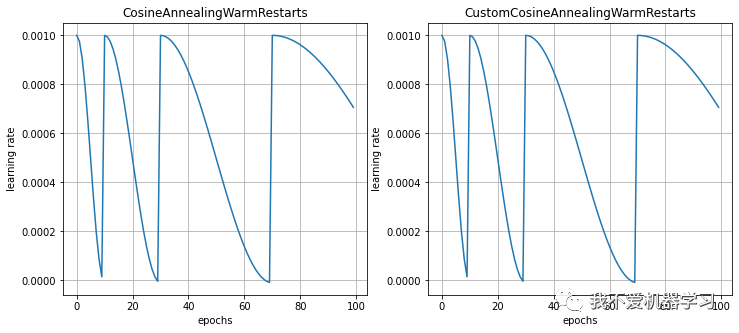
9 CosineAnnealingWarmRestarts
使用余弦退火调度设置每个参数组的学习率,其中:
设置为初始 lr,
是自上次重启以来的 epoch 数 ,
是 SGDR 中两次热重启之间的 epoch 数。
公式:
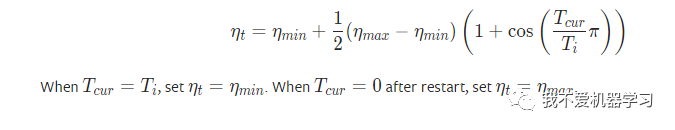
函数:
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0,
T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
"""
Args:
optimizer (Optimizer): Wrapped optimizer.
T_0 (int): Number of iterations for the first restart.
T_mult (int, optional): A factor increases :math:`T_{i}` after a restart. Default: 1.
eta_min (float, optional): Minimum learning rate. Default: 0.
last_epoch (int, optional): The index of last epoch. Default: -1.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
https://arxiv.org/abs/1608.03983
"""
torch.optim版:
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = CosineAnnealingWarmRestarts(optimizer=optimizer, T_0=10, T_mult=2, eta_min=-1e-5)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomCosineAnnealingWarmRestarts:
def __init__(self,optimizer,T_0,T_mult=1,eta_min=0,last_epoch=-1):
self.optimizer = optimizer
self.last_epoch = last_epoch
self.T_0 = T_0
self.T_i = T_0
self.T_mult = T_mult
self.eta_min = eta_min
self.T_cur = last_epoch
def get_lr(self):
return [self.eta_min + (base_lr - self.eta_min) * (1 + math.cos(math.pi * self.T_cur / self.T_i)) / 2
for base_lr in self.base_lrs]
def step(self):
self.base_lrs = [group['initial_lr'] for group in optimizer.param_groups]
if self.last_epoch < 0:
epoch = 0
else:
epoch = self.last_epoch + 1
self.T_cur = self.T_cur + 1
if self.T_cur >= self.T_i:
self.T_cur = self.T_cur - self.T_i
self.T_i = self.T_i * self.T_mult
else:
if epoch >= self.T_0:
if self.T_mult == 1:
self.T_cur = epoch % self.T_0
else:
n = int(math.log((epoch / self.T_0 * (self.T_mult - 1) + 1), self.T_mult))
self.T_cur = epoch - self.T_0 * (self.T_mult ** n - 1) / (self.T_mult - 1)
self.T_i = self.T_0 * self.T_mult ** (n)
else:
self.T_i = self.T_0
self.T_cur = epoch
self.last_epoch = math.floor(epoch)
lrs = self.get_lr()
for param, lr in zip(self.optimizer.param_groups, lrs):
param['lr'] = lr
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomCosineAnnealingWarmRestarts(optimizer=optimizer2,T_0=10,T_mult=2,eta_min=-1e-5,last_epoch=0)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
10 ReduceLROnPlateau
当指标停止改进时降低学习率。一旦学习停滞,模型通常会受益于将学习率降低 2-10 倍。该调度程序读取一个指标数量,如果“patience”的 epoch 数量没有改善,则学习率会降低。
函数:
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',
factor=0.1, patience=10, threshold=0.0001,
threshold_mode='rel', cooldown=0, min_lr=0,
eps=1e-08, verbose=False)
"""
Args:
optimizer (Optimizer):优化器
mode (str):'min'模式检测metric是否不再减小,'max'模式检测metric是否不再增大;Default: 'min'.
factor (float): r 学习率每次降低多少. new_lr = lr * factor. Default: 0.1.
patience (int): 容忍网络的性能不提升的次数,高于这个次数就降低学习率. Default: 10.
threshold (float): 测量新最佳值的阈值,仅关注重大变化. Default: 1e-4.
threshold_mode (str): 有rel和abs两种阈值计算模式.
rel规则:
dynamic_threshold = best * ( 1 + threshold ) in 'max' mode;
best * ( 1 - threshold ) in `min` mode.
abs规则:
dynamic_threshold = best + threshold in `max` mode ;
best - threshold in `min` mode.
cooldown (int): 减少lr后恢复正常操作之前要等待的时期数. Default: 0.
min_lr (float or list): 学习率的下限. Default: 0.
eps (float): 适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。. Default: 1e-8.
verbose (bool): If `True`, prints a message to stdout for each update. Default: `False`.
"""
torch.optim版:
from torch.optim.lr_scheduler import ReduceLROnPlateau
def scheduler_lr_reduce(optimizer, scheduler):
lr_history = []
"""optimizer的更新在scheduler更新的前面"""
for epoch in range(NUM_EPOCHS):
optimizer.step() # 更新参数
lr_history.append(optimizer.param_groups[0]['lr'])
val_loss = 0.1
scheduler.step(val_loss) # 调整学习率
return lr_history
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer=optimizer,mode='min',factor=0.5, min_lr=-1e-7, patience=10)
lr_history = scheduler_lr_reduce(optimizer, scheduler)
自定义版:
from torch._six import inf
class CustomReduceLROnPlateau:
def __init__(self,optimizer,mode='min', factor=0.1, patience=10,
threshold=1e-4, threshold_mode='rel', cooldown=0,
min_lr=0, eps=1e-8, verbose=False):
self.optimizer = optimizer
self.factor = factor
if not isinstance(min_lr, list) and not isinstance(min_lr, tuple):
self.min_lrs = [min_lr] * len(optimizer.param_groups)
else:
self.min_lrs = list(min_lr)
self.patience = patience
self.cooldown = cooldown
self.cooldown_counter = 0
self.mode = mode
self.threshold = threshold
self.threshold_mode = threshold_mode
self.best = None
self.num_bad_epochs = None
self.mode_worse = None # the worse value for the chosen mode
self.eps = eps
self.verbose = verbose
self.last_epoch = 0
self._init_is_better(mode=mode, threshold=threshold,threshold_mode=threshold_mode)
self._reset()
def _reset(self):
"""Resets num_bad_epochs counter and cooldown counter."""
self.best = self.mode_worse
self.cooldown_counter = 0
self.num_bad_epochs = 0
def _init_is_better(self, mode, threshold, threshold_mode):
if mode not in {'min', 'max'}:
raise ValueError('mode ' + mode + ' is unknown!')
if threshold_mode not in {'rel', 'abs'}:
raise ValueError('threshold mode ' + threshold_mode + ' is unknown!')
if mode == 'min':
self.mode_worse = inf
else: # mode == 'max':
self.mode_worse = -inf
self.mode = mode
self.threshold = threshold
self.threshold_mode = threshold_mode
@property
def in_cooldown(self):
return self.cooldown_counter > 0
def is_better(self, a, best):
if self.mode == 'min' and self.threshold_mode == 'rel':
rel_epsilon = 1. - self.threshold
return a < best * rel_epsilon
elif self.mode == 'min' and self.threshold_mode == 'abs':
return a < best - self.threshold
elif self.mode == 'max' and self.threshold_mode == 'rel':
rel_epsilon = self.threshold + 1.
return a > best * rel_epsilon
else: # mode == 'max' and epsilon_mode == 'abs':
return a > best + self.threshold
def _reduce_lr(self, epoch):
for i, param_group in enumerate(self.optimizer.param_groups):
old_lr = float(param_group['lr'])
new_lr = max(old_lr * self.factor, self.min_lrs[i])
if old_lr - new_lr > self.eps:
param_group['lr'] = new_lr
if self.verbose:
epoch_str = ("%.2f" if isinstance(epoch, float) else
"%.5d") % epoch
print('Epoch {}: reducing learning rate'
' of group {} to {:.4e}.'.format(epoch_str, i, new_lr))
def step(self, metrics):
# convert `metrics` to float, in case it's a zero-dim Tensor
current = float(metrics)
self.last_epoch += 1
if self.is_better(current, self.best):
self.best = current
self.num_bad_epochs = 0
else:
self.num_bad_epochs += 1
if self.in_cooldown:
self.cooldown_counter -= 1
self.num_bad_epochs = 0 # ignore any bad epochs in cooldown
if self.num_bad_epochs > self.patience:
self._reduce_lr(self.last_epoch)
self.cooldown_counter = self.cooldown
self.num_bad_epochs = 0
self._last_lr = [group['lr'] for group in self.optimizer.param_groups]
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = CustomReduceLROnPlateau(optimizer=optimizer2,mode='min',factor=0.5,min_lr=-1e-7,patience=10)
lr_history2 = scheduler_lr_reduce(optimizer2, scheduler2)
对比:
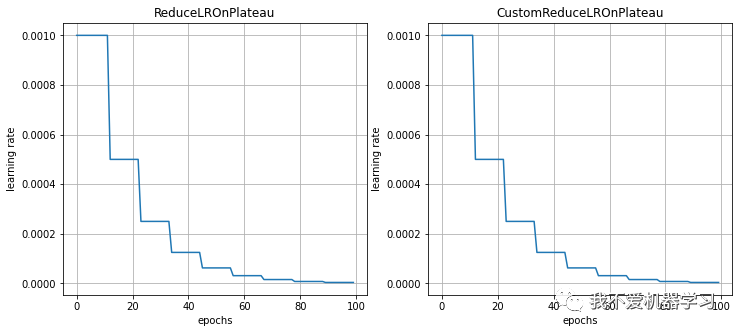
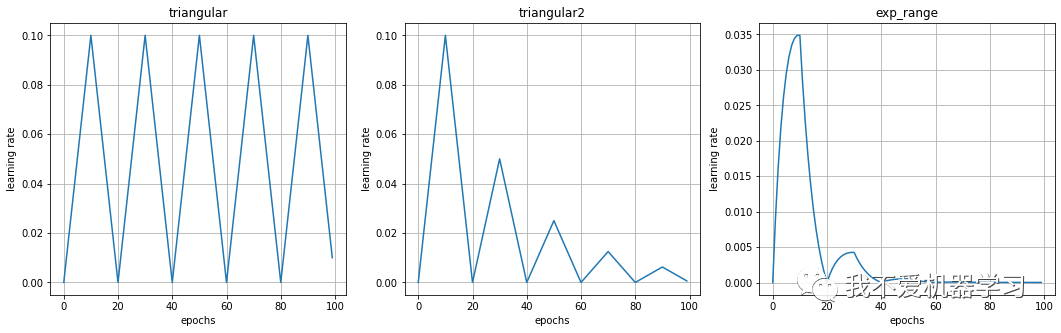
11 CyclicLR
根据循环学习率策略 (CLR) 设置每个参数组的学习率。该策略以恒定频率循环两个边界之间的学习率。两个边界之间的距离可以在每次迭代或每个周期的基础上进行缩放。
循环学习率策略在每batch之后改变学习率。step 应该在一个批次用于训练后调用。
此类具有三个内置策略:
riangular:没有振幅缩放的基本三角形循环。triangular2:一个基本的三角循环,每个循环将初始幅度缩放一半。exp_range:在每个循环迭代中通过 gamma**(cycle iteration)循环迭代来缩放初始幅度的循环。
函数:
torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000,
step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle',
cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=- 1, verbose=False)
"""
Args:
optimizer (Optimizer): 优化器.
base_lr (float or list): 循环中学习率的下边界.
max_lr (float or list): 循环中学习率的上边界.
step_size_up (int): N习率上升的步数. Default: 2000
step_size_down (int): 学习率下降的步数. Default: None
mode (str): {triangular, triangular2, exp_range}中的一个.
gamma (float):{triangular, triangular2, exp_range}中的一个。
scale_fn (function): 自定义的scaling policy,通过只包含有1个参数的lambda函数定义.0 <= scale_fn(x) <= 1 for all x >= 0. 如果定义了scale_fn, 则忽略 mode参数.
scale_mode (str): 两种模式cycle和iterations决定scale_fn函数以何种方式作用.
cycle_momentum (bool): 如果为True,则动量与'base_momentum'和'max_momentum'之间的学习率成反比. Default: True
base_momentum (float or list):初始动量,即每个参数组的循环中的下边界。
max_momentum (float or list): 每个参数组的循环中的上动量边界. 定义了循环振幅=(max_momentum - base_momentum).
last_epoch (int): The index of the last batch.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
https://arxiv.org/abs/1506.01186
https://github.com/bckenstler/CLR
"""
torch.optim版:
from torch.optim.lr_scheduler import CyclicLR
lr_histories = []
titles = ['triangular','triangular2','exp_range']
for mode in titles:
optimizer = torch.optim.SGD(model.parameters(), lr=0)
scheduler = CyclicLR(optimizer=optimizer,base_lr=1e-5, max_lr=1e-1, step_size_up=10, mode=mode, gamma=0.9)
lr_histories.append(scheduler_lr(optimizer, scheduler))
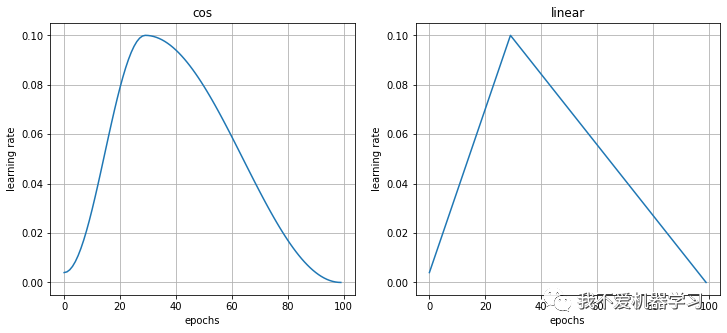
12 OneCycleLR
根据 1cycle learning rate policy 设置每个参数组的学习率。
1cycle 策略将学习率从初始学习率退火到某个最大学习率,然后从该最大学习率退火到某个远低于初始学习率的最小学习率。
1cycle learning rate policy 在每batch之后改变学习率。step 应该在一个批次被用于训练之后被调用。
循环中的步骤总数可以通过以下两种方式之一确定(按优先顺序列出):
- 明确提供了 total_steps 的值。
- 提供了多个epochs和每个epochs的步数(steps_per_epoch)。在这种情况下,总步数由 total_steps = epochs * steps_per_epoch 推断。
必须为 total_steps 提供一个值,或者为 epochs 和 steps_per_epoch 提供一个值。
函数:
torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None,
steps_per_epoch=None, pct_start=0.3, anneal_strategy='cos',
cycle_momentum=True, base_momentum=0.85,
max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0,
three_phase=False, last_epoch=- 1,
verbose=False)
"""
Args:
optimizer (Optimizer): 优化器.
max_lr (float or list): 最大学习率.
total_steps (int): 迭代次数.
epochs (int): 用于训练的epoch数
steps_per_epoch (int): 每个epoch的步数.
pct_start (float): 学习率上升部分占比. Default: 0.3
anneal_strategy (str): {'cos', 'linear'} 退火策略. Default: 'cos'
cycle_momentum (bool): 如果为True,则动量与'base_momentum'和'max_momentum'之间的学习率成反比.
base_momentum (float or list): L循环中的动量下界.
max_momentum (float or list): 循环中的动量上界. cycle amplitude (max_momentum - base_momentum).
div_factor (float): 确定初始学习率. initial_lr = max_lr/div_factor Default: 25
final_div_factor (float): 确定最小学习率. min_lr = initial_lr/final_div_factor Default: 1e4
three_phase (bool): If ``True``,则根据'final_div_factor'消除学习率,而不是根据'pct_start'指示的步骤对称)。
last_epoch (int): The index of the last batch.
verbose (bool): If ``True``, prints a message to stdout for each update. Default: ``False``.
https://arxiv.org/abs/1708.07120
"""
torch.optim版:
from torch.optim.lr_scheduler import OneCycleLR
lr_histories = []
titles = ['cos','linear']
for mode in titles:
optimizer = torch.optim.SGD(model.parameters(), lr=0)
scheduler = OneCycleLR(optimizer=optimizer, max_lr=1e-1,epochs=10, steps_per_epoch=10,anneal_strategy=mode)
lr_histories.append(scheduler_lr(optimizer, scheduler))
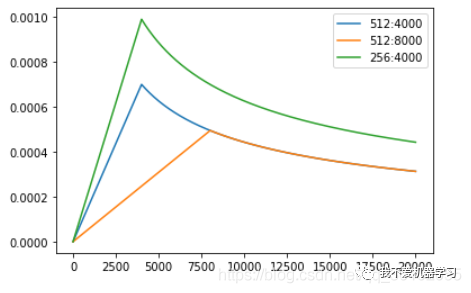
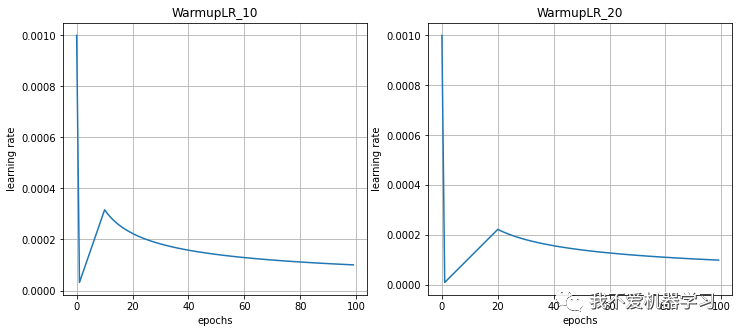
13 warm up
warm up衰减策略与上述的策略有些不同,它是先从一个极低的学习率开始增加,增加到某一个值后再逐渐减少。
这样训练模型更加稳定,因为在刚开始时模型的参数都是随机初始化的,此时如果学习率应该取小一点,这样就不会使模型一下子跑偏。
随着训练的增加,逐渐的模型对数据比较熟悉,此时可以增大学习率加快收敛速度。
最后随着参数逐渐收敛,在学习率增大到某个数值后开始衰减。
公式:
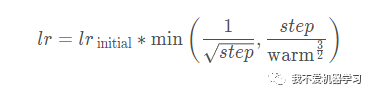
式中,lr_initial 是初始学习率,step是步数,也就是step了几次,这里也可以换成 epoch。warm 表示热身的步数也就是前面增长的步数。
自定义版:
class WarmupLR:
def __init__(self, optimizer, num_warm) -> None:
self.optimizer = optimizer
self.num_warm = num_warm
self.lr = [group['lr'] for group in self.optimizer.param_groups]
self.num_step = 0
def __compute(self, lr) -> float:
return lr * min(self.num_step ** (-0.5), self.num_step * self.num_warm ** (-1.5))
def step(self) -> None:
self.num_step += 1
lr = [self.__compute(lr) for lr in self.lr]
for i, group in enumerate(self.optimizer.param_groups):
group['lr'] = lr[i]
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler = WarmupLR(optimizer=optimizer, num_warm=10)
lr_history = scheduler_lr(optimizer, scheduler)
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
scheduler2 = WarmupLR(optimizer=optimizer2, num_warm=20)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
14 ChainedScheduler
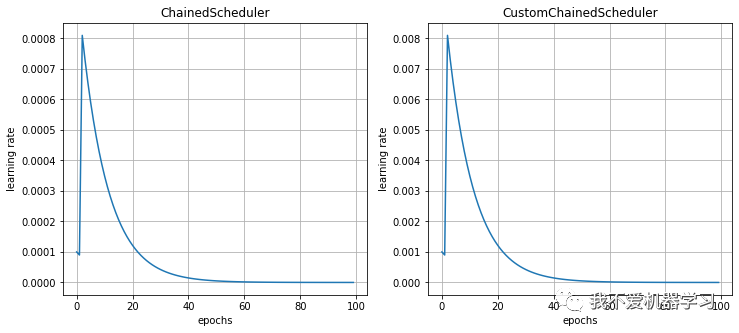
学习率调度器的链表。它需要一个可链式学习的列表,并在每次调用时连续 step()。
函数:
torch.optim.lr_scheduler.ChainedScheduler(schedulers)
""""
schedulers (list) – List of chained schedulers.
"""
torch.optim版:
from torch.optim.lr_scheduler import ChainedScheduler
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3)
schedulers = [ConstantLR(optimizer,factor=0.1, total_iters=2),
ExponentialLR(optimizer,gamma=0.9)]
scheduler = ChainedScheduler(schedulers)
lr_history = scheduler_lr(optimizer, scheduler)
自定义版:
class CustomChainedScheduler:
def __init__(self,schedulers):
self.schedulers = schedulers
self.optimizer = schedulers[0].optimizer
self._last_lr = [group['lr'] for group in self.schedulers[-1].optimizer.param_groups]
def step(self):
for scheduler in self.schedulers:
scheduler.step()
self._last_lr = [group['lr'] for group in self.schedulers[-1].optimizer.param_groups]
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
schedulers = [CustomConstantLR(optimizer2,factor=0.1,total_iters=2,last_epoch=0),
CustomExponentialLR(optimizer2,gamma=0.9,last_epoch=0)]
scheduler2 = CustomChainedScheduler(schedulers)
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
15 SequentialLR
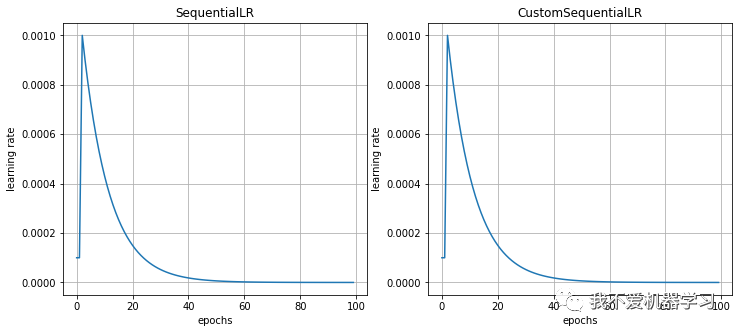
接收期望在优化过程中按顺序调用的调度程序列表和提供准确间隔以反映在给定时期应该调用哪个调度程序的 milestone points 。
函数:
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=- 1, verbose=False)
""""
Args:
optimizer (Optimizer): Wrapped optimizer.
schedulers (list): List of chained schedulers.
milestones (list): List of integers that reflects milestone points.
last_epoch (int): The index of last epoch. Default: -1.
verbose (bool): Does nothing.
"""
torch.optim版:
from torch.optim.lr_scheduler import SequentialLR
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3)
schedulers = [ConstantLR(optimizer,factor=0.1,total_iters=2),
ExponentialLR(optimizer,gamma=0.9)]
scheduler = SequentialLR(optimizer,schedulers,milestones=[2])
lr_history = scheduler_lr(optimizer,scheduler)
自定义版:
from bisect import bisect_right
class CustomSequentialLR:
def __init__(self,optimizer, schedulers, milestones, last_epoch=-1):
self.schedulers = schedulers
self.milestones = milestones
self.last_epoch = last_epoch + 1
self.optimizer = optimizer
def step(self):
self.last_epoch += 1
idx = bisect_right(self.milestones, self.last_epoch)
if idx > 0 and self.milestones[idx - 1] == self.last_epoch:
self.schedulers[idx].step(0)
else:
self.schedulers[idx].step()
optimizer2 = torch.optim.SGD(model.parameters(), lr=1e-3)
schedulers = [ConstantLR(optimizer2,factor=0.1,total_iters=2),
ExponentialLR(optimizer2,gamma=0.9)]
scheduler2 = CustomSequentialLR(optimizer2,schedulers,milestones=[2])
lr_history2 = scheduler_lr(optimizer2, scheduler2)
对比:
完整代码:
https://github.com/mengjizhiyou/Pytorch_LearningRateScheduler
参考:
https://blog.csdn.net/qq_36102055/article/details/119321243
https://github.com/amahiner7/LearningRateScheduler_Pytorch
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号