云原生业务的容器排障与思考
原创


业务上云容器排障和思考
1 前言
此前我们部门已经完成了业务上云的目标,而随着业务请求量的激增,上云应用系统也面临着一些复杂的故障和挑战。
下文我就结合最近的容器排障工作,跟大家一起探讨如何优化系统的性能、扩展性和容错能力,为读者提供参考和借鉴,以确保系统的高效运行和可靠交付。
2 业务异常与排障思路
用户反馈出现了一个异常任务,它长时间出于“进行中”的状态;用户上传的源物料大小是568MB左右,预期能够半小时出结果,实际过了6个小时都没有结束任务。

异常任务
2.1 排障思路
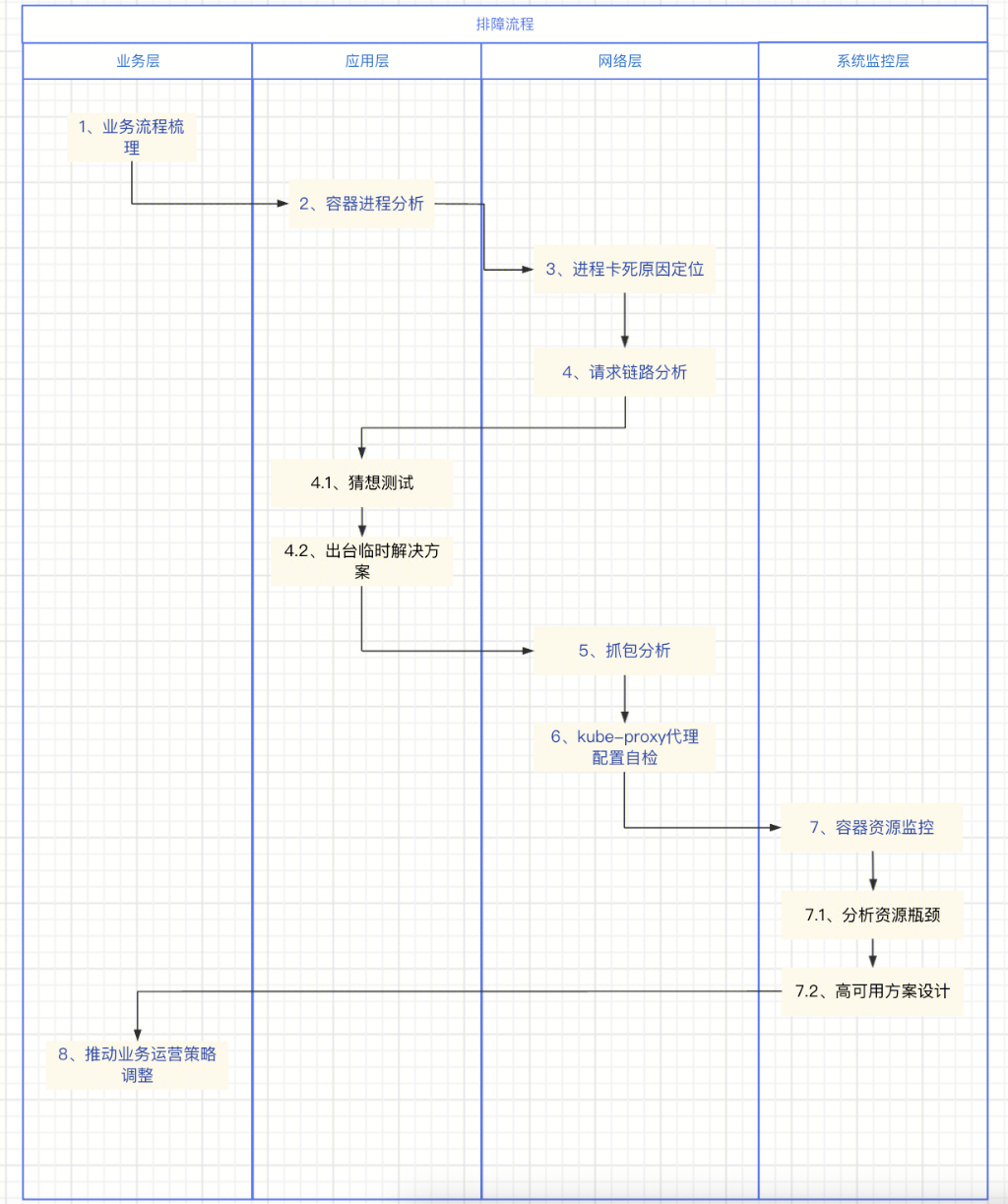
排障思路
最终我们通过上面的排障思路和定位行动,将根本原因定位出来了:排查发现是容器集群资源吃紧,结合云原生组件kubeproxy反向代理机制,两者结合引发所导致。
下面具体列出分析思路和大致流程,一起讨论下。
3 排障定位
3.1 业务流程梳理
3.1.1 任务流程图
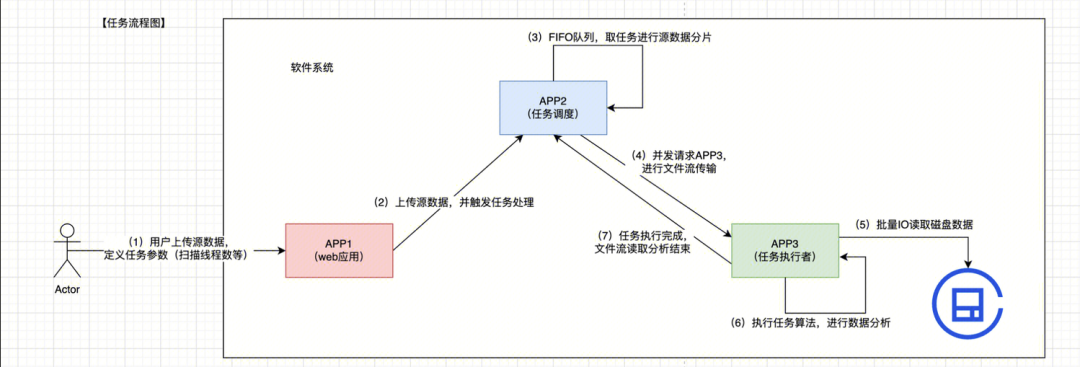
- 用户上传源数据包:用户可以上传自己的任务数据包,并可以配置任务执行的所需资源(比如:执行算法、执行线程数等)
- APP1→ APP2:上传任务数据
- 任务进入APP2内部队列:优先对进入的任务进行数据分片处理
- APP2→ APP3:APP2分片处理完成之后,按照可配置请求线程数T,进行按每批次T个请求,将分片内容传输给APP3
- APP3:从磁盘IO读取开源知识库数据
- APP3:对接收到的分片内容,对数据进行算法分析
- APP3:所有请求携带的分片数据都分析完毕,并且全部正确响应给APP2,宣告:一个任务“完成”
3.1.2 分析
既然目前是任务一直执行,说明问题是出在了(3)~(7)步骤上了,那么聚焦于APP2和APP3。
基于他们的请求响应关系,下文将APP2定位成客户端,将APP3定位成服务端。
3.2 容器进程分析
正常的预期现象是:两边容器都有业务进程,并且两边进程频繁进行HTTP通信;当任务执行结束之后,两边进程都将退出被系统销毁。
那么我们首先需要分析两侧容器进程。
3.2.1 查看容器子进程
通过ps -ef,分别在客户端APP2和服务端APP3,打印进程状态。
客户端
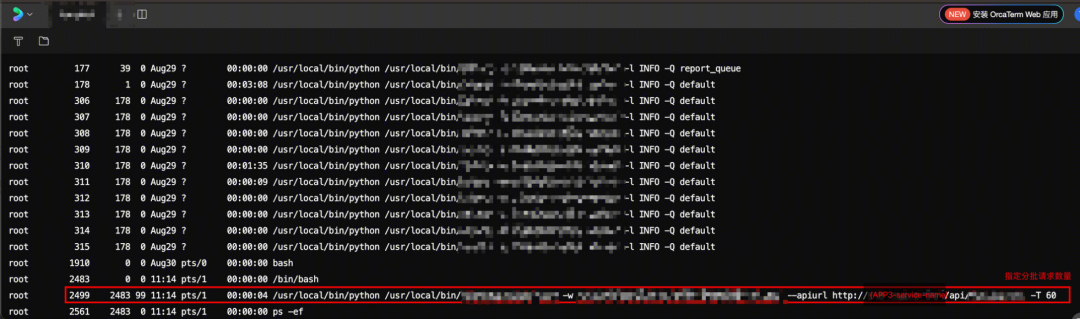
客户端APP2的任务进程:有一个进程存活,说明客户端进程卡住了。
服务端
服务端APP3的任务进程:没有执行中的任务进程了。
3.2.2 分析
定位是客户端APP2的进程卡死,而服务端APP3的进程正常结束了。
3.3 进程卡死原因定位
分析进程卡死的原因,首先是想到日志,然后是网络。
3.3.1 查看容器日志
在云容器的日志看,发现并没有打印相关的ERROR级别日志,说明业务是整体成功的状态,所以我们更加怀疑是环境问题(网络/IO等资源)导致。
3.3.2 容器进程的网络端口状态
通过netstat -ntp| grep PID,分别在APP2和APP3进程关联的网络端口状态。
客户端
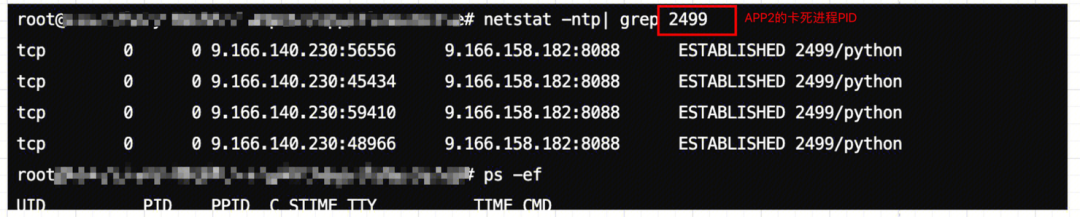
客户端容器进程的网络端口状态
服务端
由于不存在工作进程,所以也查不出关联的网络端口了。
3.3.3 分析
通过网络排查,发现了客户端APP2的进程,存在4个TCP端口一直在监听状态,并没有正常关闭。
3.4 请求链路分析
分别从客户端和服务端角度出发,去定位TCP连接异常监听。
3.4.1 思路
- 从客户端APP2角度看
- 进程假死原因是:4个TCP连接建立之后,TCP端口一直在等待数据响应(即客户端发起HTTP请求一直阻塞)
- 在任务进行中,过程可能发起>8000次请求,最后残留了4个请求异常的TCP连接
- 在3.2.1步骤中发现:客户端进程是通过 service-name 来请求服务端容器
- 从服务端APP3角度看
- 虽然计算工作量会很大,但服务端进程最终正常销毁了
3.4.2 请求链路
由于容器集群是已经部署上云,并且在K8S部署架构下运行,和技术运营的同学一起梳理出以下的请求链路:
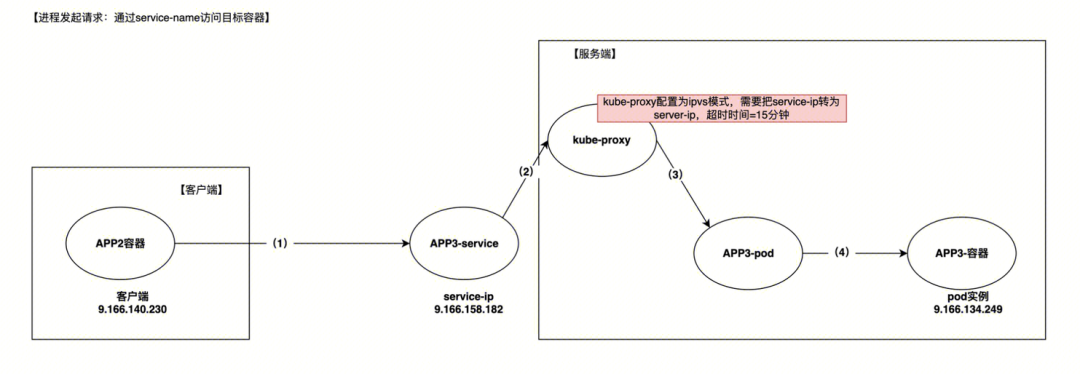
容器请求链路
这里与HTTP普通请求响应的区别:由于service的“从中作梗”,kube-proxy其实是一个代理层负责实现service。
3.4.2.1 kube-proxy
通过kube-proxy的ipvs机制,实现了从 service-ip 到 容器ip的映射,完成一个网络转发代理,最终实现容器之间的通信。
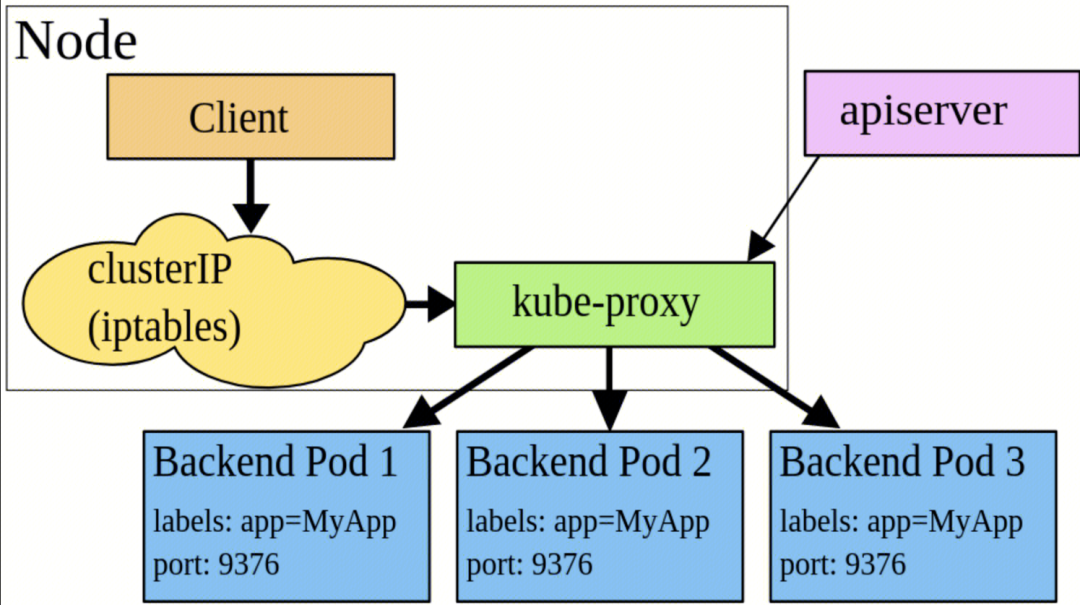
kube-proxy的ipvs机制
3.4.2.2 实际转发请求
请求链路最终经过了以下3个步骤:
- 容器APP2发起的请求时,首先通过service-name找到APP3-service(service是对外暴露pod的一层代理)
- 随后请求经过kube-proxy处理,以实现虚拟 IP 转换(即service-ip到pod实例ip的转换)
- 云上的kube-proxy采用了ipvs代理模式
- 最终实现将流量导向到某一个后端 Pod(即APP3-pod)。
- 流量导向完成后,请求最终会进入pod的一个实例(即APP3-容器)
3.4.3 分析
上面在3.3.3步骤 也分析到了,客户端的连接(客户端APP2→APP3-service)是一直建立的,而服务端的连接(APP3-service→APP3-容器)是关闭了的。
那么我们判断问题是在了kube-proxy代理这个环节上。
3.4.4 猜想验证
因为恢复业务使用一直是当务之急,所以基于请求链路的理解,我们大胆测试了一下:改为通过pod-ip/port直连通信的方式,客户端进程能否正常结束呢?
随后验证:该方案是可行的,此时的客户端和服务端进程都正常结束了。
3.4.4.1 临时解决方案
通过pod-ip/port直连的方式,同时技术运营同学也辅助了pod重启之后的pod-ip动态刷新的工作,确保临时方案的可用性。
至此,我们优先恢复了业务的正常使用。
3.4.5 根本问题
但kube-proxy的流量代理问题,仍旧没定位清晰;未来容器服务,如果要继续做高可用部署,依旧是离不开这个组件的,所以继续盘它。
通过3.4.3步骤 分析,最终定位到问题出在了kube-proxy代理这个环节上,所以决定在客户端和服务端两侧进行抓包。
3.5 抓包分析网络
通过tcpdump,我们分别在客户端和服务端里,实现了流量抓包(虽然日志非常大,幸好容器分配到的磁盘空间足够,事后也有清理),随后是下载出来用wireshark分析网络情况。
期间过程有点繁琐,因为要顺序性的启动抓包进程、客户端服务端进程复现、以及文件权限申请等细节,这里不对抓包过程展开。
3.5.1 网络分析
最终是复现了问题,并对残留的几个TCP连接进行了抓包分析,这里针对其中一个异常的TCP连接(客户端的进程残留一个TCP连接port=40422)分析。
3.5.1.1 连接建立点
客户端

客户端-连接建立
客户端目标是service-ip,三次握手完成,连接建立是在12:03:06。
服务端
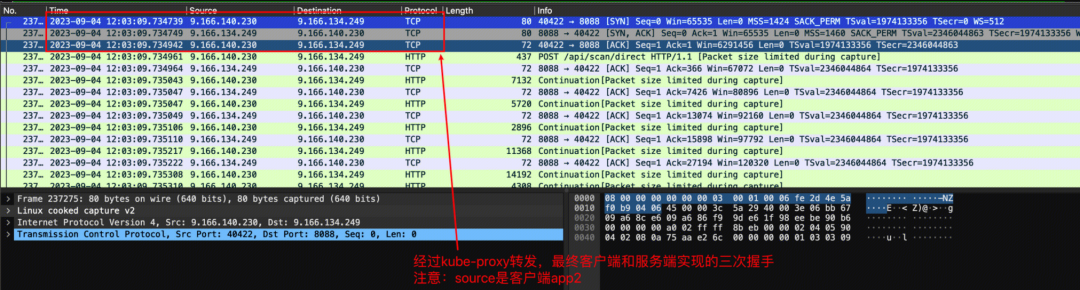
服务端-连接建立
经过kube-proxy代理到具体的pod实例,服务端跟客户端,三次握手完成,连接建立是在12:03:09。
3.5.1.2 故障异常点
客户端
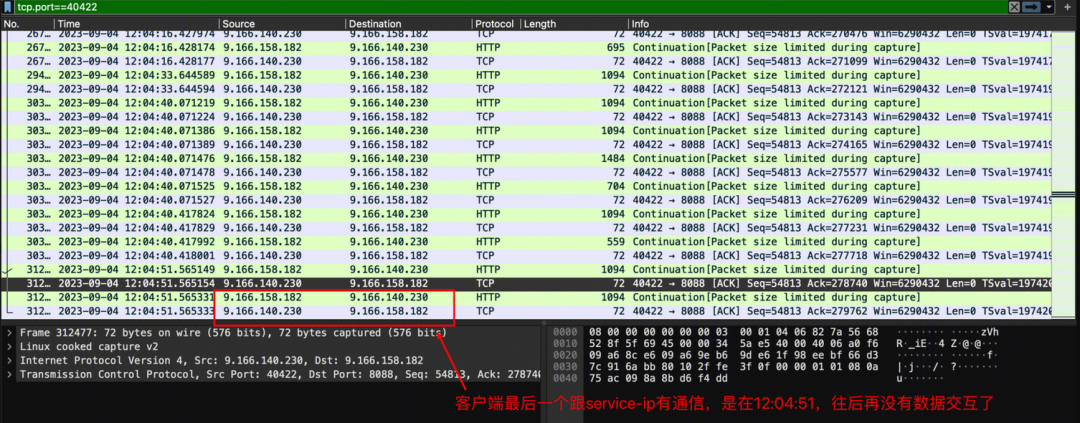
客户端-故障异常点
客户端最后一次跟service-ip连接通信,在12:04:51。
服务端
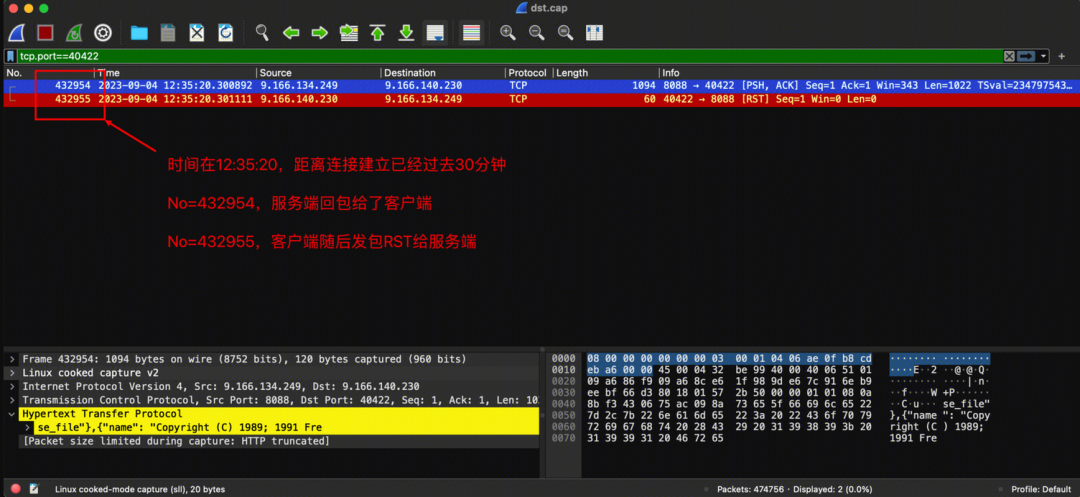
服务端-故障异常点
- 中间出现了30分钟的间隔
- 服务端最后一次回包是在12:35:20,是回给客户端的
- 随后,由于客户端检测到连接中存在问题,给服务端发了RST报文。
3.5.2 分析
通过网络抓包分析得到:
- 客户端是和service建立连接的,而非直接和服务端
- 30分钟之后,服务端回了一个包给客户端
- 服务端是可以直接回包给客户端的,但客户端显然不认识服务端的数据包,并发起了断开连接申请(RST包),随后服务端TCP正常关闭了。
- 最终出现了“案发现场”:客户端和service的连接残留了,而服务端TCP正常关闭。
3.6 kube-proxy代理配置自检
目前摸到的线索是:服务端回了一个包给客户端,并造成了“案发现场”。于是我们找了云同学协助查看问题,最终判断是kube-proxy的代理会话超时机制作用导致。
3.6.1 kube-proxy会话保活机制
kube-proxy存在会话保活机制:会记录客户端与服务端的连接,有效时间是15分钟。
当ipvs会话保持超时后,连接记录就没了。
- 连接记录什么作用?
- 能够让客户端发包时,发给service-ip的数据包,定位到服务端ip,然后转发给服务端
- 能够让服务端回包时,发给客户端的数据包,以service-ip的名义,转发给客户端
3.6.2 分析
梳理请求链路,我们得到以下的“客户端-Service-服务端”三方通信流程图:
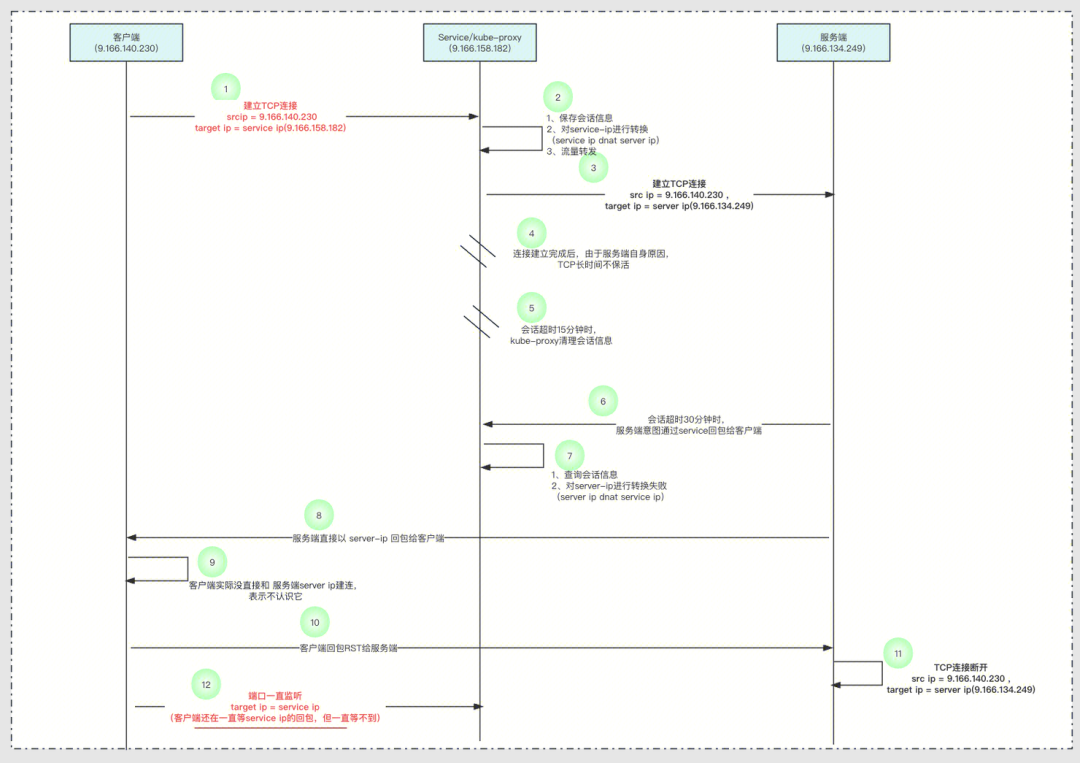
三方通信-请求链路
针对“服务端回了一个包给客户端,并造成了“案发现场”,从上面关注两个时间点:
- 在第15分钟时候,kube-proxy清理会话
- 在第30分钟时候,服务端回了一个包给客户端:
- 但服务端回包给客户端时,不再是通过service-ip的“头衔加持”(因为会话记录清理了,会导致服务端的回包无法转换为原来的service ip),而是以服务器的名义,直接丢数据包给客户端了;
- 客户端此时不认识服务端的(在k8s的service机制下,客户端是对服务端信息无感知的,因为一直和客户端接头的是service);所以,回了一个RST数据包给服务端;
- 服务端接收到RST数据包之后,它是认识客户端的,因此主动关闭了自己一侧的TCP端口;【这解释了:服务端进程正常关闭TCP端口】
- 而客户端则一直在苦等,原来和自己接头的service-ip的回包,但它永远等不到了【这解析了:客户端一直没能正常关闭TCP端口】
3.6.3 结论
至此,我们已经找到了故障的根本原因:
- 因为客户端和服务端连接创建之后,该请求一直被搁置着,没有得到及时保活,导致kube-proxy清理了会话记录;
- 当服务端处理超时时,因为会话记录被清理,回包出现异常,没有经过service回包给了客户端;
- 客户端一直等待的service回包用于等不到,所以就一直监听着(对业务来说,就是进程假死)
调整kube-proxy的会话超时时间是不实际的,因为基础组件改动是一个全局的影响;
所以自然引出最后一个问题:为什么服务端会来不及处理请求,以至于不能及时保活。
3.7 容器资源监控
对于为什么服务端会来不及处理请求,以至于不能及时保活;我们想到的是两个原因:
- 服务端计算能力有限,导致已有请求处理慢,新增请求一直阻塞(前者是跟容器资源配置息息相关,该项是可以优化的)
- 请求的超时时间设置的太长,给了服务端处理超时的机会(这是由产品能力决定的,为了确保服务端计算充分完整并响应,该项调整空间不大)
基于对服务端计算能力的评估,只能是跟容器资源限制有关系,于是查看了服务端APP3的CPU/内存/网络/IO的相关监控。
3.7.1 CPU监控
只关注APP3,因为计算量集中在这个服务。
监控显示:CPU整体负载很低,在任务进行中时,CPU使用量才略微升高,而后下去了(约等于不工作,说明APP2的确完成了计算量的工作了)。
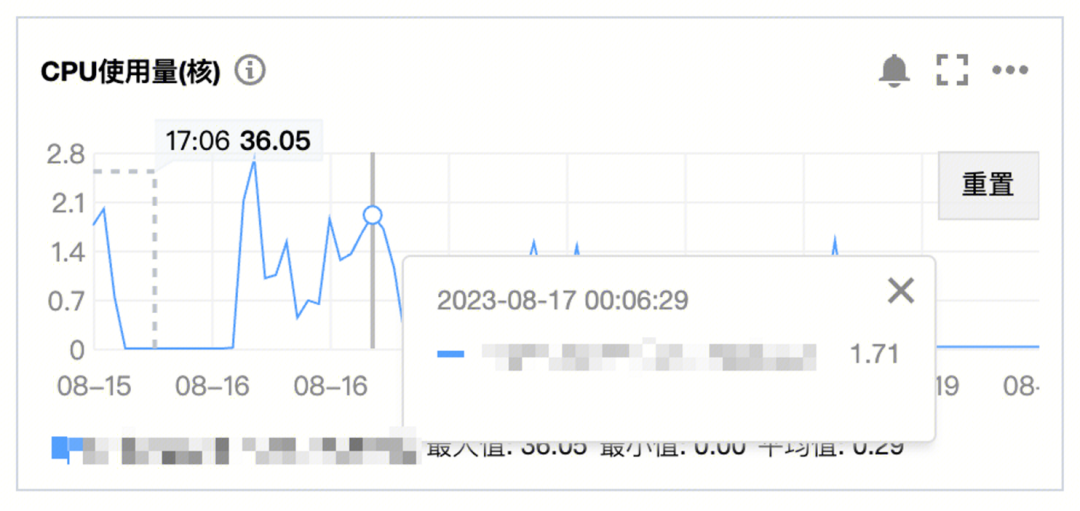
CPU
3.7.2 内存监控
监控显示:APP3在数据分析过程里,内存一直飙高,但经过一段时间后,量就降下去了。
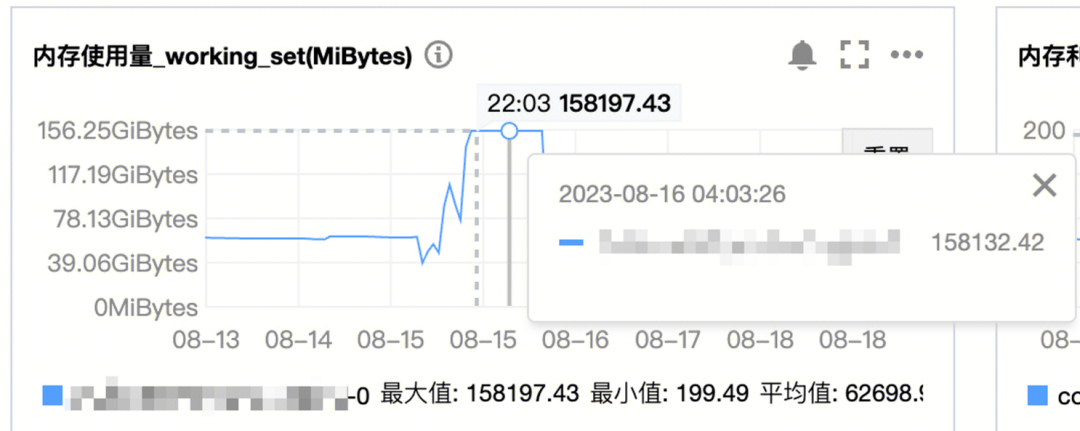
内存
3.7.3 IO监控
监控显示:APP3在数据分析过程里,IO带宽一直打满,达到了280MBps,但经过一段时间后,监控就降下去了。
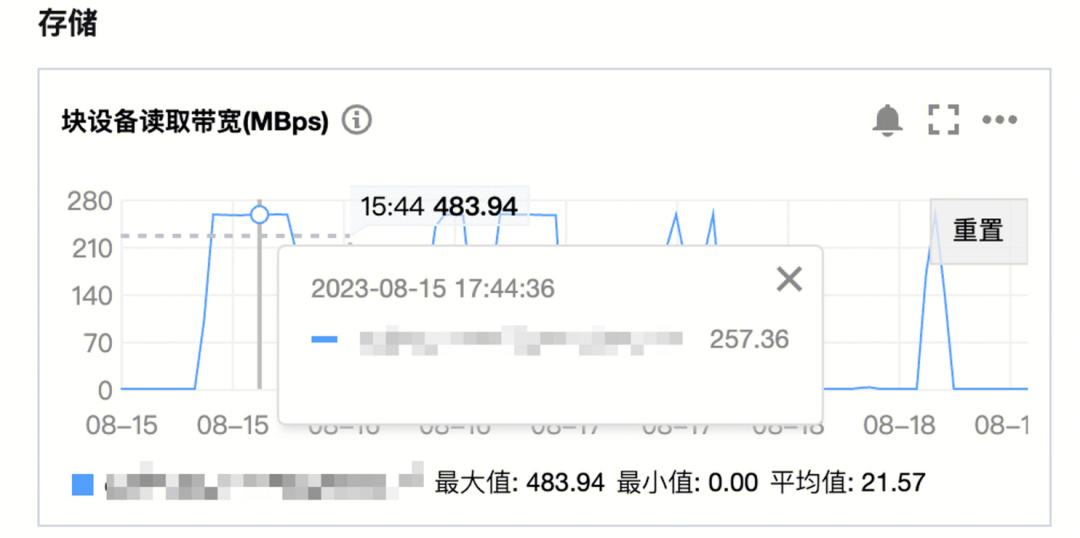
IO
因为我们用的是云存储规格是SSD,也算是到了性能瓶颈了。
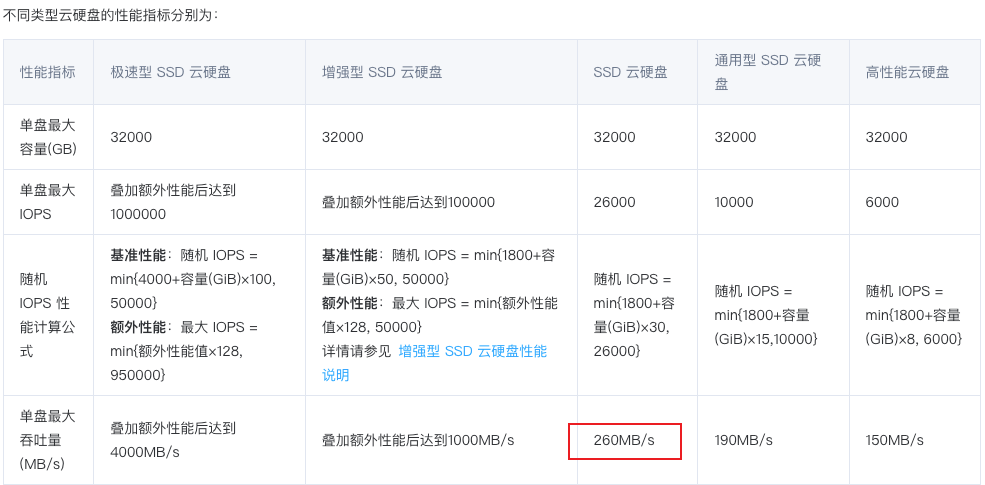
云硬盘规格
3.7.4 分析
从资源监控看资源吃紧是客观存在的:
- 尤其是IO资源一直打满,内存也非常吃紧,暴露了容器的计算瓶颈在于资源;
- 而CPU资源一直上不去,也是受限于资源利用率已经非常高了;
4 运营策略调整和思考
结合公司的降本增效大背景,通过无限制的投入资源去优化体验,片面去追求更大的内存和更快的磁盘IO是不现实的。
这次独特的Bug排查,也是由于业务流量徒增而导致,所以我们决定利用好已有的条件去克服困难:
- 分析流量增长原因:首先我们找到了用户团队并了解清楚工具使用频率和,承诺通过两种方法协助业务团队:
- 对于周期性业务调用压力:调整为分散式任务,以时间换空间,避免短期内的资源高峰,降低系统的负载压力。
- 确实无法分散式,我们会通过合理配置并发任务数和并发线程数,可以提高任务的执行效率,减少资源浪费,协助业务快速完成项目任务;
- 优化技术架构:在资源有限的情况下,通过优化技术架构提高系统的性能和稳定性。
- 后续对容器集群的高可用架构进行优化
- 升级容器算法,提速服务端计算能力
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号