基于Yolov8网络进行目标检测(一)-介绍和预测

基于Yolov8网络进行目标检测(一)-介绍和预测

python与大数据分析
发布于 2023-09-18 15:00:09
发布于 2023-09-18 15:00:09
之前提到过目标检测模型分为两类。一类是two-stage,将物体识别和物体定位分为两个步骤分别完成,这一类的典型代表是R-CNN, fast R-CNN, faster-RCNN家族。他们识别错误率低,漏识别率也较低,但是由于网络结构参数的计算量大,导致其检测速度慢,不能满足实时检测场景。为了解决精度与速度并存的问题,另一类方式出现了,称为one-stage, 典型代表是Yolo, SSD, YoloV2等。此类方法使用基于回归方法的思想,直接在输入图像的多个位置中回归出这个位置的区域框坐标和物体类别,他们识别速度很快,可以达到实时性要求,而且准确率也基本能达到faster R-CNN的水平。
在之前的文章里,介绍了Faster R-CNN的原理和预测使用,在一般的GPU服务器,每帧的解析速率约为0.4秒;再则Faster R-CNN训练自己的数据集,文章比较匮乏和散乱;最后Faster R-CNN目前逐渐被YOLO系列所替代,所以暂时就不在花费时间在上面了。我们把目标调整会YOLO。
当然YOLO,我是看不懂的,在这里只能假装看懂,假装看懂的目的是拿来主义,直接用,或者微调后使用。在这里列了一下YOLO各个版本的发展史。
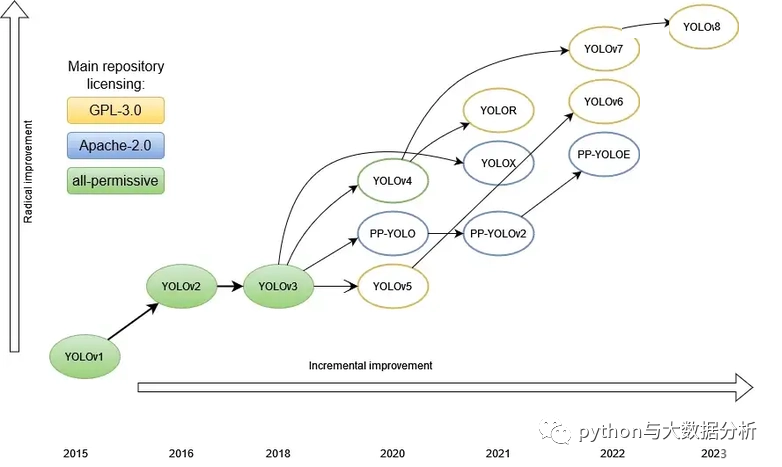
所有的YOLO版本,在结构上,YOLO 模型基本由以下部分组成:
Input ——输入图像被馈送到的输入层
Backbone ——输入图像以特征形式编码的部分,和之前的faster R-CNN有点类似。
Neck ——这是模型的其他部分,用于处理由特征编码的图像
Head(s)——一个或多个产生模型预测的输出层。
以下是各个版本的YOLO版本的继承关系,以及backbone、Neck、Head的变迁

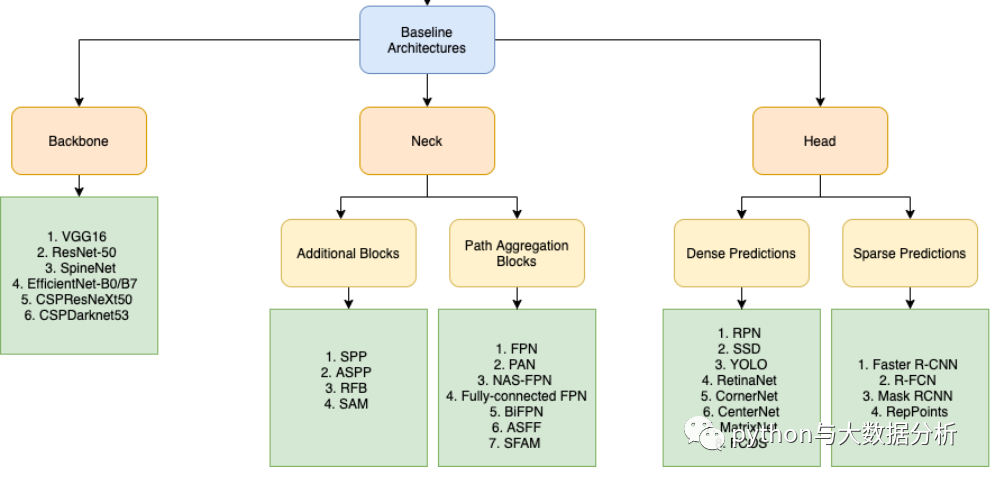
之前的文章里也介绍过YOLOv5版本训练自己的数据集,YOLOv8是2023年Ultralytics公司推出的基于对象检测模型的YOLO最新系列,它能够提供截至目前最先进的对象检测性能。借助于以前的YOLO模型版本支持技术,YOLOv8模型运行得更快、更准确,同时为执行任务的训练模型提供了统一的框架,这包括:
目标检测
实例分割
图像分类
YOLOv8的模型结构如下:
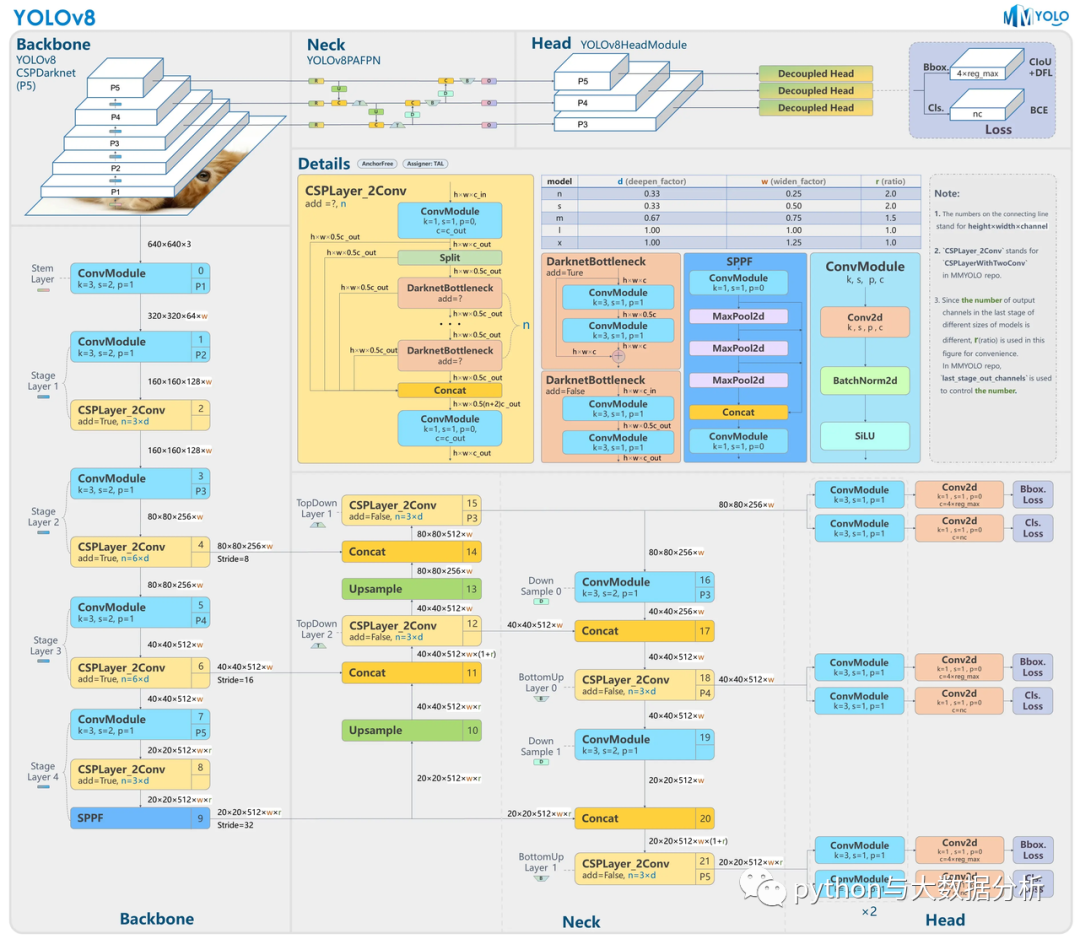

YOLOv8这次发行中共附带了以下预训练模型:YOLOv8 模型的每个类别中有五个模型用于检测、分割和分类。YOLOv8 Nano 是最快和最小的,而 YOLOv8 Extra Large (YOLOv8x) 是其中最准确但最慢的。
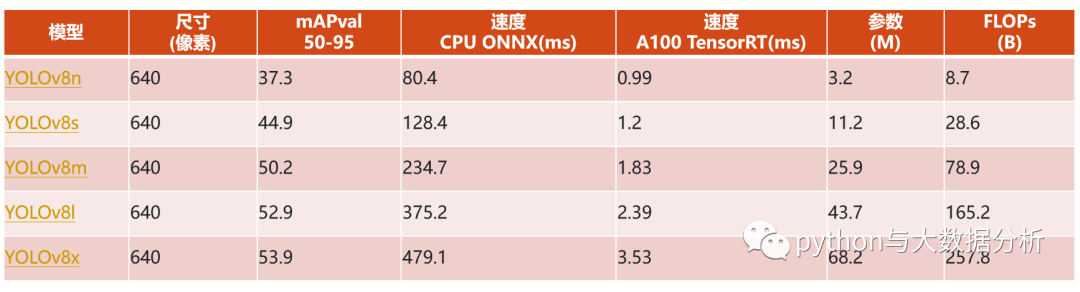
在图像分辨率为640的COCO检测数据集上训练的对象检测检查点。
在图像分辨率为640的COCO分割数据集上训练的实例分割检查点。
在图像分辨率为224的ImageNet数据集上预处理的图像分类模型。
不得不说,YOLOv8较之前的文档完善了很多,里面介绍了使用方法、各个版本、数据集、指引等,官网可以见:https://docs.ultralytics.com/modes/
下面直接运行一下代码看看
from ultralytics import YOLO
from PIL import Image
# 直接加载预训练模型
model = YOLO('yolov8n.pt')
# Run batched inference on a list of images
results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
# Process results list
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
可以看到返回结果还是非常简单明了的
0: 640x640 2 persons, 1 cell phone, 1: 640x640 1 person, 1 motorcycle, 1 baseball glove, 281.4ms
Speed: 5.8ms preprocess, 140.7ms inference, 2.2ms postprocess per image at shape (1, 3, 640, 640)
image 1/1 D:\PycharmProjects\ObjectDetectionProject\im3.jpg: 480x640 8 persons, 1 bottle, 5 chairs, 1 dining table, 1 refrigerator, 123.2ms
Speed: 2.4ms preprocess, 123.2ms inference, 3.5ms postprocess per image at shape (1, 3, 480, 640)
再运行一下第二段代码,对于一张图如何展示其标注框和标注内容
results = model('im3.jpg') # results list
# Show the results
for r in results:
im_array = r.plot() # plot a BGR numpy array of predictions
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image
im.show() # show image
im.save('results.jpg') # save image
运行结果如下,除了检测到了人还检测到了瓶子和座椅,准确率还是挺高的。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-13 01:25,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 python与大数据分析 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号