NVLink的演进


这篇笔记整理下Nvidia公司的NVLink技术的发展历程,供大家参考。
NVLink是Nvidia开发的一项用于GPU之间点对点高速互联的技术,其旨在突破PCIe互联带宽的限制,实现GPU芯片间低延迟、高带宽的数据互联,使得GPU间更加高效地协同工作。在NVLink技术问世之前(2014年前),GPU之间的互联需要通过PCIe switch来实现,如下图所示。GPU发出的信号需要先传递到PCIe switch, PCIe switch中涉及到数据的处理,CPU会对数据进行分发调度,这些都会引入额外的网络延迟,限制了系统性能。彼时,PCIe协议已经发展到Gen 3, 单通道的速率为8Gb/s, 16通道的总带宽为16GB/s (128Gbps,1 Byte= 8 bits ),随着GPU芯片性能的不断提升,其互联带宽成为瓶颈。
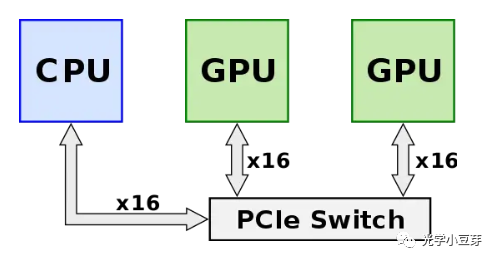
(图片来自https://en.wikichip.org/wiki/nvidia/nvlink)
2014年,NVLink 1.0发布,并应用在P100芯片上,如下图所示。两颗GPU之间有4条NVlink, 每个link中包含8个lane, 每条lane的速率是20Gb/s, 因此整个系统的双向带宽为160GB/s,是PCIe3 x16带宽的5倍。

(图片来自https://en.wikichip.org/wiki/nvidia/nvlink)
单个NVLink内部含有16对差分线,对应两个方向各8条lane的信道,如下图所示,差分对的两端为PHY,内部包含SerDes。
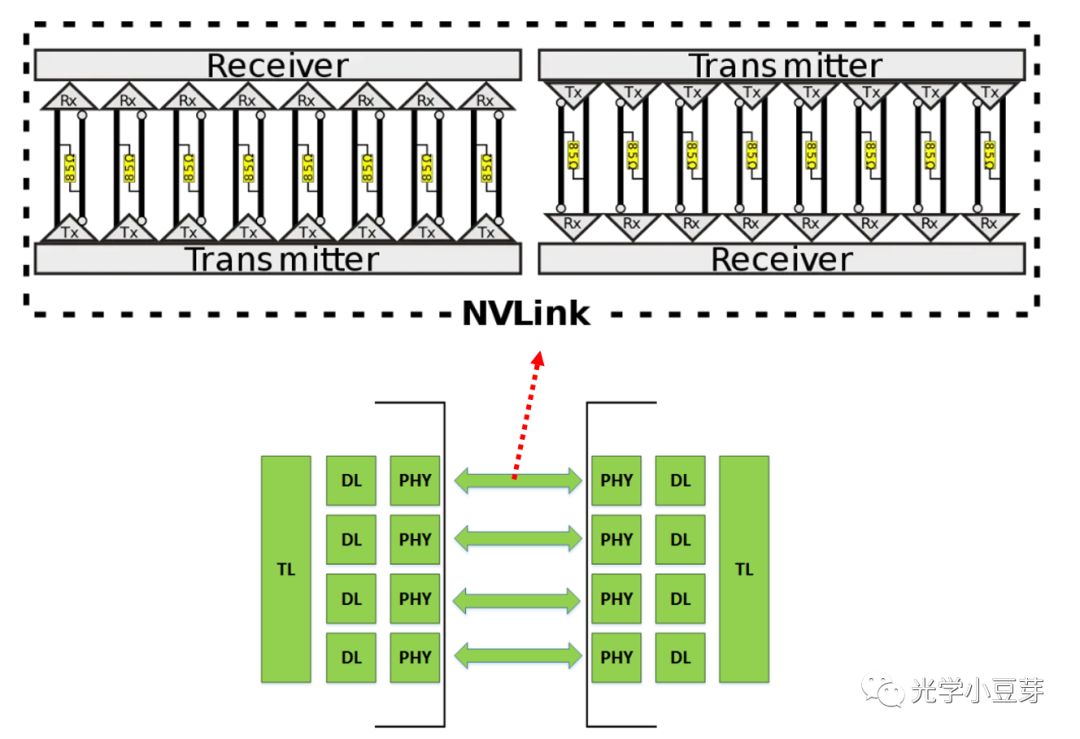
(图片来自https://www.nextplatform.com/2016/05/04/nvlink-takes-gpu-acceleration-next-level/)
基于NVLink 1.0,可以形成4个GPU的平面mesh结构,两两之间形成点对点直连,而8个GPU则对应cube-mesh,进而可以组成DGX-1服务器,这也对应常见的8卡配置,如下图所示,需要注意的是,此时8个GPU并没有形成all-to-all连接。
(图片来自https://developer.nvidia.com/blog/dgx-1-fastest-deep-learning-system/)
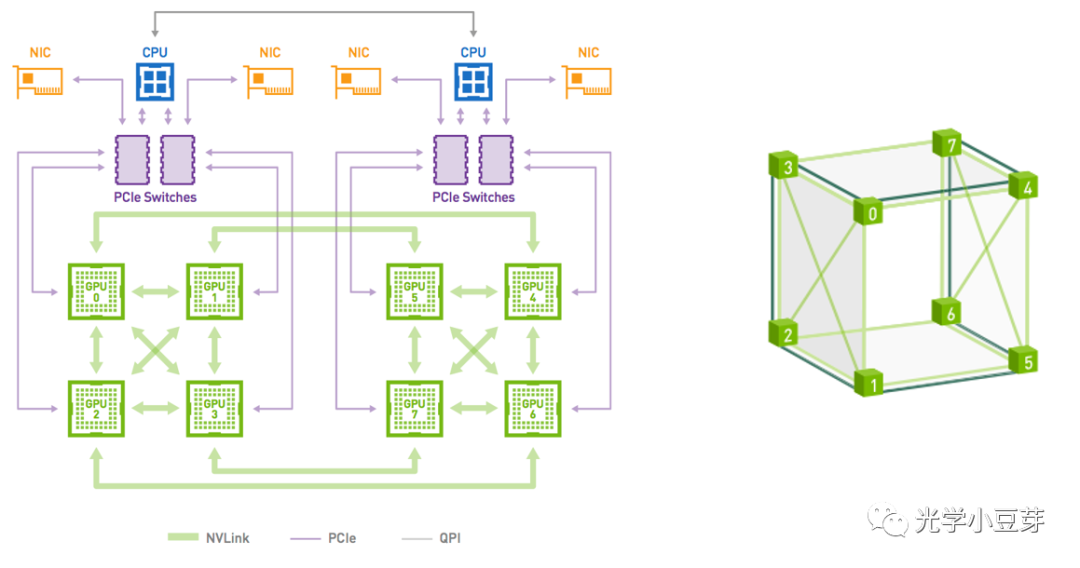
2017年,Nvidia推出了第二代NVLink技术。两颗GPU V100之间含6条NVLink, 每个link中包含8个lane, 每条lane的速率提升到25Gb/s, 整个系统的双向带宽变为300GB/s,带宽是NVLink 1.0的近2倍。与此同时,为了实现8颗GPU之间的all-to-all互联,Nvidia推出了NVSwitch技术。NVSwitch 1.0含有18个port, 每个port的带宽为50GB/s, 整体带宽为900GB/s。每个NVSwitch预留了两个port, 用于连接CPU。使用6个NVSwitch即可实现8颗GPU V100的all-to-all连接,如下图所示。
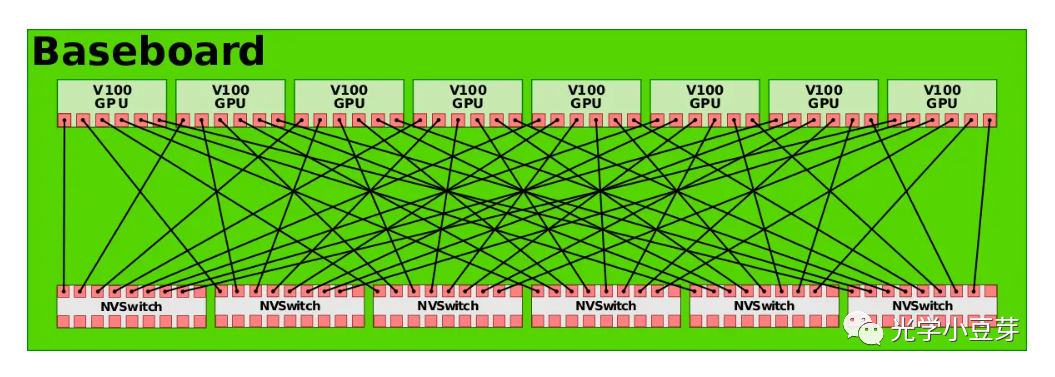
(图片来自https://en.wikichip.org/wiki/nvidia/nvswitch)
DGX-2系统则采用两个上图中的板子构建而成,如下图所示,实现了16颗GPU芯片的all-to-all连接。
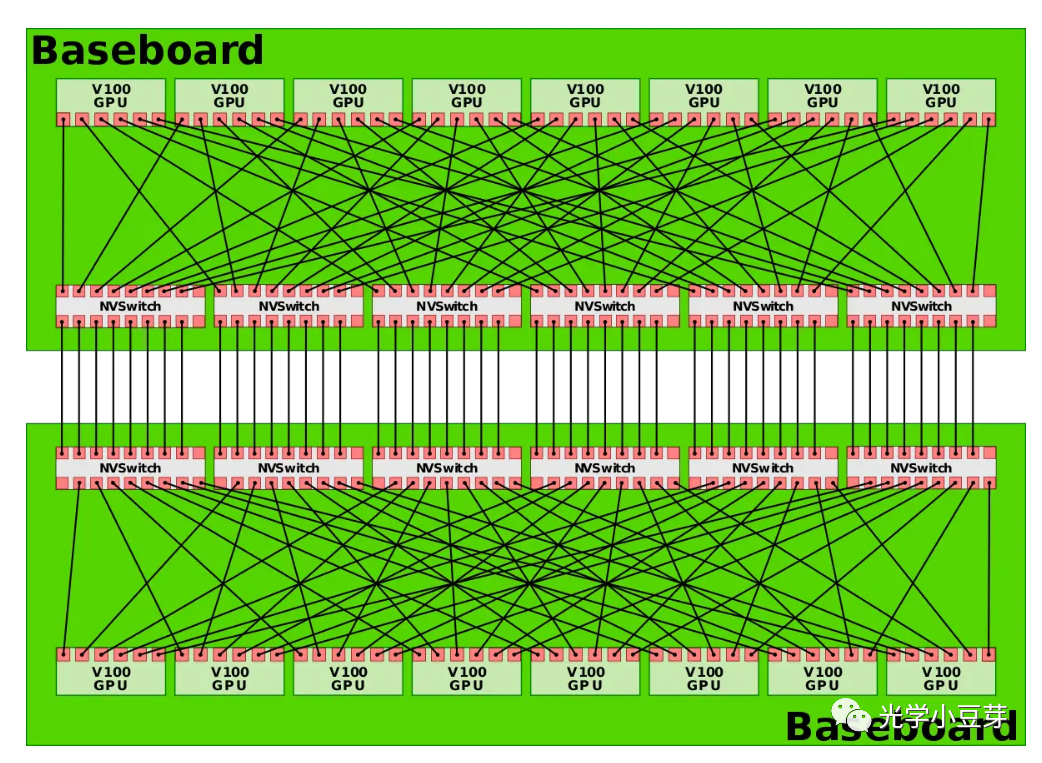
(图片来自https://en.wikichip.org/wiki/nvidia/nvswitch)
2020年,NVLink 3.0技术诞生,两颗GPU A100芯片之间存在12条NVLink, 每条NVLink含有4条lane, 单条lane的速率为50Gb/s, 因此整个系统的双向带宽提升到600GB/s,总带宽相比NVLink 2.0提升了1倍。由于NVLink的数目增加了,NVSwitch的port数目也相应增加到36个,每个port的速率为50GB/s。由8颗GPU A100与4个NVSwitch组成了DGX A100, 如下图所示。
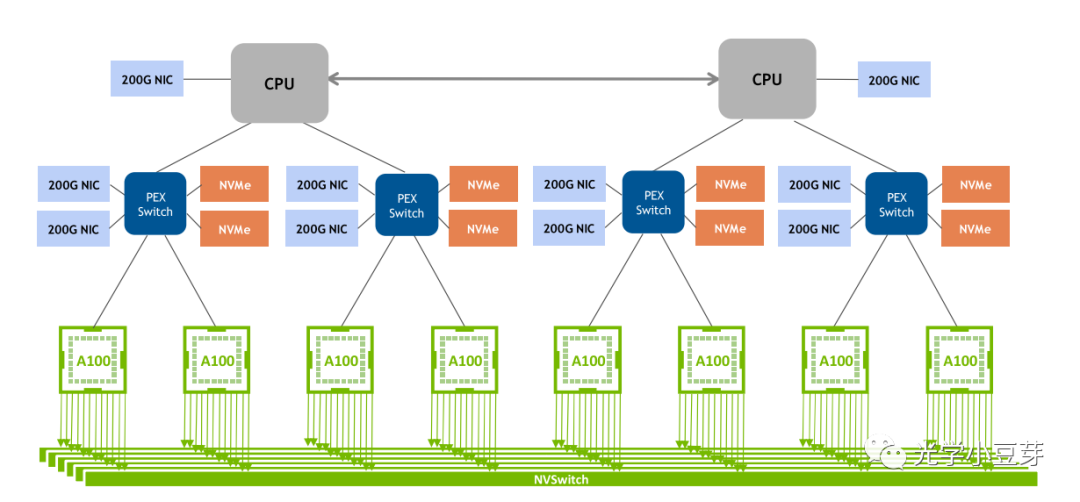
(图片来自http://www.eventdrive.co.kr/2020/azwell/DGX_A100_Azwellplus.pdf)
2022年,NVLink技术升级到第四代,两个GPU H100芯片间通过18条NVLink互联,每条link中含2条lane, 每条lane支持100Gb/s PAM4的速率,因此双向总带宽提升到900GB/s。NVSwitch也升级到第三代,每个NVSwitch支持64个port,每个port的速率为50GB/s。DGX H100由8颗H100芯片与4颗NVSwitch芯片构成,如下图所示。图中每个NVSwitch的另一侧与多个800G OSFP光模块相连。以左侧第一个NVSwitch为例,其与GPU相连侧的单向总带宽为4Tbps (20NVLink*200Gbps),与光模块相连侧的总带宽为也为4Tbps (5*800Gbps),两者大小相等, 是非阻塞(non-blocking)网络。需要注意的是,光模块中的带宽是单向带宽,而在AI芯片中一般习惯使用双向带宽。
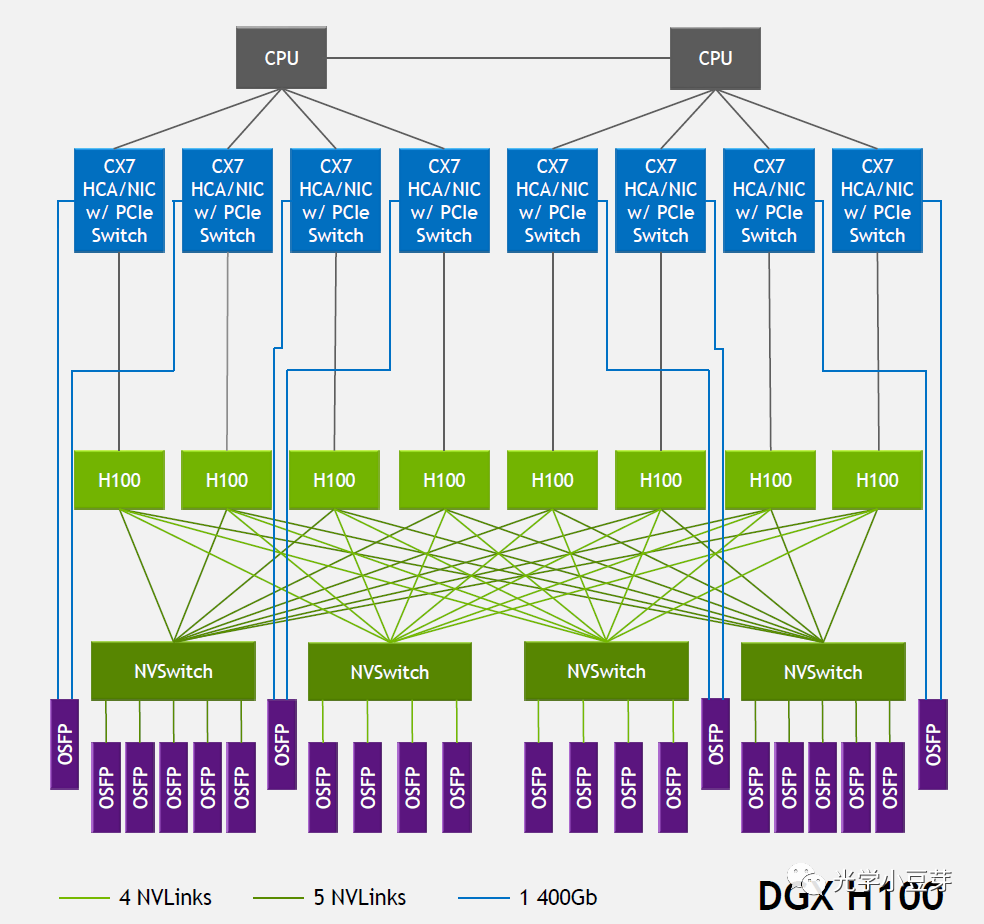
(图片来自https://blog.apnic.net/2023/08/10/large-language-models-the-hardware-connection/)
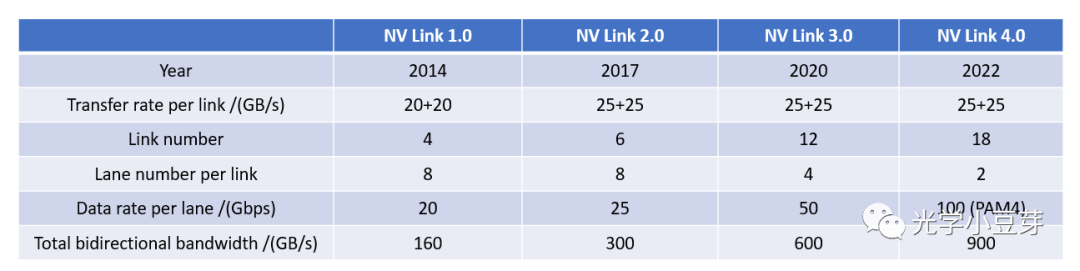
下表整理了每一代NVLink的指标参数。
而PCIe每一代的参数如下表所示,

从单条lane的速率来看,NVLink整体比同一时期的PCIe的指标高1倍左右,而总带宽的优势更是明显,NVLink是PCIe总带宽的5倍左右。一直在超越,从未停止。
NVLink经过近十年的发展,已经成为Nvidia GPU芯片中的一个核心技术,是其生态系统中的重要一环,有效解决了GPU芯片之间高带宽、低延迟的数据互联难题,改变了传统的计算架构。但由于该技术是Nvidia独有,其它AI芯片公司只能采用PCIe或者其它互联协议。与此同时,Nvidia正在探索利用光互连实现GPU之间的连接,如下图所示,硅光芯片与GPU共封装在一起,两颗GPU芯片间通过光纤连接。
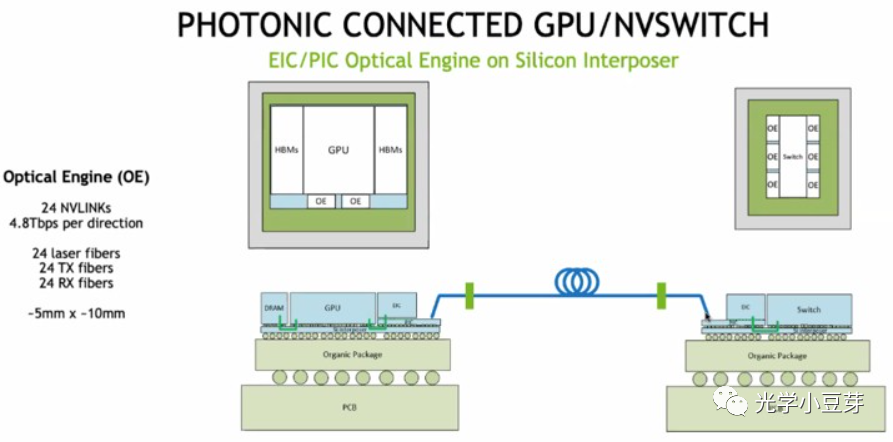
(https://www.nextplatform.com/2022/08/17/nvidia-shows-what-optically-linked-gpu-systems-might-look-like/)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-23 15:58,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号