关于图像配准(Image Registration)的基础知识汇总1.0
原创
关于图像配准(Image Registration)的基础知识汇总1.0
原创
江夏四卯
发布于 2023-09-26 09:15:48
发布于 2023-09-26 09:15:48
图像配准的定义(概念)
(1)图像配准(Image registration)是将同一场景拍摄的不同图像进行对齐的技术,即找到图像之间的点对点映射关系,或者对某种感兴趣的特征建立关联。
以同一场景拍摄而成的两幅图像为例。假如实际的三维世界点P在两幅图像中分别对应着P1和p2两个二维图像点。图像配准要做的就是找到P1和P2的映射关系,或者p1、p2跟P的关系。p1和p2被称为对应点(Correspondence Points)、匹配点(Matching Points)或控制点(Control points)。
(2)图像配准与相关是图像处理研究领域中的一个典型问题和技术难点,其目的在于比较或融合针对同一对象在不同条件下获取的图像,例如图像会来自不同的采集设备,取自不同的时间,不同的拍摄视角等等,有时也需要用到针对不同对象的图像配准问题。
图像配准是使用某种算法,基于某种评估标准,将一张或多张图片(局部)最优映射到目标图片上的方法。
根据不同配准方法,不同评判标准和不同图片类型,有不同类型的图像配准方法。
(3)图像配准是叠加多个来自不同来源、在不同时间和角度拍摄的图像的过程。图像的配准过程试图发现两张图片之间的匹配点并在空间上对齐它们,以最小化所需的误差,即图像之间的统一邻近读的测量。一旦建立了这种对应关系,通常可以通过调节或者处理两张或者多张图片之间的联系来进行研究。可以说,图像配准是计算空间变换的过程,它将一组图像与一个共同的观察参考框架对齐,通常是一组图像中的一个。
图像配准一般有两种方式:ImageToImage以及ImageToMap。前者是将多张图片对齐以整合或融合表示相同对象的匹配像素,而后者是将输入图像扭曲来匹配基准图像的特征信息,同时保证其空间分辨率。
(4)图像配准(Image registration)就是将不同时间、不同传感器(成像设备)或不同条件下(天候、照度、摄像位置和角度等)获取的两幅或多幅图像进行匹配、叠加的过程,它已经被广泛地应用于遥感数据分析、计算机视觉、图像处理等领域。
(5)图像配准:作为图像融合的一个预处理步骤,图像配准是对两幅图像,通过寻找一种空间变换把一幅图像映射到另一幅图像,使得两图中对应于空间同一位置的点一一对应起来,从而达到信息融合的目的。
(6)图像配准是一种寻找同一场景的两幅或多幅图像之间的空间变换关系、并对其中的一幅或多幅图像进行变换的过程。图像配准是所有图像分析任务中最为关键和基础的步骤,是图像拼接、图像重建、目标识别等应用的前提。对于常用的基于特征的图像配准方法,其关键在于如何对特征进行有效的提取,尺度不变特征(Scale Invariant Feature Transform,SIFT)算法能够为我们所提供需要的不变特征。SIFT 特征具有旋转、光照、仿射和尺度等不变性,SIFT 算法是目前特征检测和匹配算法中最为有效的算法。尺度不变特征SIFT 算法可以划分为特征检测、特征描述和特征匹配三个部分。
图像配准是寻找在不同时间点、不同的视角下或由不同传感器拍摄的关于同一场景的两幅图像或多幅图像之间的空间变换关系,并对其中的一幅或多幅进行匹配和叠加的过程。图像配准可简单地理解为一个寻找空间映射的过程,重新排列一幅图像的像素点位置,并与另一幅图像的对应像素点保持空间上的一致性。图像配准是遥感图像处理、目标识别、图像融合、图像拼接、图像重建、机器人视觉等众多图像分析领域中的关键技术之一,是图像处理领域中的研究热点。图像配准可分为基于特征和基于区域的配准,其中基于特征的图像配准方法由于其只对特征进行操作,计算量较少,因此应用较为广泛。基于特征的图像配准方法的基本步骤为特征检测、特征匹配、匹配函数设计和图像的变换及重采样,图像配准操作围绕图像的特征展开。因此,如何提取具有良好不变性的特征成为基于特征的图像配准的关键所在。
原理

图像配准的应用
图像配准在计算机视觉、医学图像处理、材料力学、遥感等领域有广泛应用。
在计算机视觉领域里,配准方法可被用来进行视频分析、模式识别,自动跟踪对象的运动变化。
图像配准在医学图像处理与分析中有众多具有实用价值的应用。随着医学成像设备的进步,对于同一患者,可以采集含有准确解剖信息的图像诸如CT、超声、MRI;同时,也可以采集到含有功能信息的图像诸如SPECT。然而,通过观察不同的图像进行诊断需要凭借空间想象和医生的主观经验。
采用正确的图像配准方法则可以将多种多样的信息准确地融合到同一图像中,使医生更方便更精确地从各个角度观察病灶和结构。同时,通过对不同时刻采集的动态图像的配准,可以定量分析病灶和器官的变化情况,使得医疗诊断、制定手术计划、放射治疗计划更准确可靠。
在材料力学方面,配准通常用来研究力学性质,称为数字图像相关。通过对不同相机不同传感器采集到的信息(形状,温度等)进行融合比较,可以计算得到例如应变场、温度场等数值。通过带入理论模型可以进行参数反向优化等。
其他应用领域:天气预测,地理信息系统,超分辨率,运动追踪,自动控制。
图像配准在目标检测、模型重建、运动估计、特征匹配,肿瘤检测、病变定位、血管造影、地质勘探、航空侦察等领域都有广泛的应用。
图像配准的应用根据图像获取方式主要分为四组:
- 不同视角(多视角分析)——从不同视角获取同一场景图像。其目的是为了获得更大的2D视图或者扫描场景的3D表示。应用示例:遥感-被检区域图像的拼接。计算机视觉-形状恢复(立体形状)。
- 不同时间(多时分析)——从不同时间获取同一场景图像,通常是定期的,可能在不同条件下。其目的是找到和评价连续获得的图像之间场景的改变。应用示例:遥感-全球土地使用监督,景观规划。计算机视觉-安防自动改变检测,运动追踪。医学图像-愈合治疗监督,肿瘤进展监督。
- 不同传感器(多模态分析)——从不同传感器获得同一场景图像。其目的是整合不同来源的信息来获得更复杂更细节的场景表示。应用示例:遥感-不同特征传感器信息融合,如有更好空间分辨率的全色图像,有更好光谱分辨率的彩色/多光谱图像,或与云层和光照无关的雷达图像。研究结果可应用于放射治疗和核医学领域。
- 场景到模型的配准。一个场景的图像和场景的模型配准。模型可以是场景的计算机表示,例如GIS中的地图或数字海拔模型(DEM),有相似内容的另一个场景,'平均'标本等。其目的是在场景/模型中定位获得的图像,并且/或者比较它们。应用示例:遥感-航空或者卫星数据到地图或者其它GIS层的配准。计算机视觉-目标模板匹配实时图像,自动质检。医学图像-病人图像和数字解剖集的比较,标本分类。
传统的配准方法
传统的配准方法是一个迭代优化的过程,首先定义一个相似性度量(如:L2范数,互信息),通过对参数变换或非参变换进行不断迭代优化,使得配准后的源图像与目标图像相似度最大。
自21世纪初以来,图像配准主要使用基于特征的方法。
这些方法有三个步骤:关键点检测keypoint detector和特征描述feature descriptor,特征匹配feature mapping,图像变换。简单的说,我们选择两个图像中的感兴趣点,将参考图像(reference image)与感测图像(sensed image)中的等价感兴趣点进行关联,然后变换感测图像使两个图像对齐。
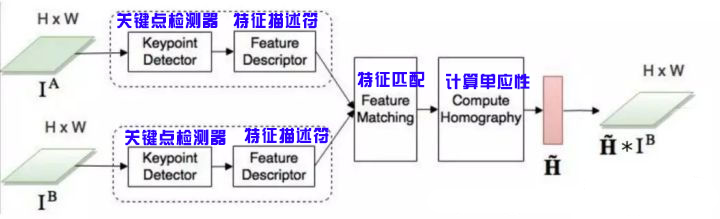
(1)关键点检测
关键点就是感兴趣点,它表示图像中重要或独特的内容(边角,边缘等)。每个关键点由描述符表示,关键点基本特征的特征向量。描述符应该对图像变换(定位,缩放,亮度等)具有鲁棒性。许多算法使用关键点检测和特征描述:
SIFT^4(Scale-invariant feature transform)是用于关键点检测的原始算法,但它不能免费用于商业用途。SIFT特征描述符对于均匀缩放,方向,亮度变化和对仿射失真不变的部分不会发生变化。
SURF^5(Speeded Up Robust Features)是一个受SIFT启发的探测器和描述符。它的优点是非常快。它同样是有专利的。
ORB^6(Oriented FAST and Rotated BRIEF)是一种快速的二进制描述符,它基于 FAST^7(Features from Accelerated Segment Test)关键点检测和 BRIEF^8(Binary robust independent elementary features)描述符的组合。它具有旋转不变性和对噪声的鲁棒性。它由OpenCV实验室开发,是SIFT有效的免费替代品。
AKAZE^9(Accelerated-KAZE)是KAZE^10快速版本。它为非线性尺度空间^11提供了快速的多尺度特征检测和描述方法,具有缩放和旋转不变性。
这里使用AKAZE算法,cv.AKAZE_create()


(2)特征匹配
一旦在一对图像中识别出关键点,我们就需要将两个图像中对应的关键点进行关联或“匹配”。其中一种方法是BFMatcher.knnMatch()。这个方法计算每对关键点之间的描述符的距离,并返回每个关键点的k个最佳匹配中的最小距离。

(3)图像变换
在匹配至少四对关键点之后,我们就可以将一个图像转换为另一个图像,称为图像变换(image warping)。空间中相同平面的两个图像通过单应性变换(Homographies)进行关联。Homographies是具有8个自由参数的几何变换,由3x3矩阵表示图像的整体变换(与局部变换相反)。因此,为了获得变换后的感测图像,需要计算Homographies矩阵。
单应性
图像中的2D点(x,y)(x,y)可以被表示成3D向量的形式(x1,x2,x3)(x1,x2,x3),其中x=x1/x3x=x1/x3,y=x2/x3y=x2/x3。它被叫做点的齐次表达,位于投影平面P^2上。所谓单应就是发生在投影平面P^2上的点和线可逆的映射。其它叫法包括射影变换、投影变换和平面投影变换等。典型地,可以通过图像之间的特征匹配来估计单应矩阵。
单应变换矩阵是一个3*3的矩阵H。这个变换可以被任意乘上一个非零常数,而不改变变换本身。所以它虽然具有9个元素,但是具有8个自由度。这意味这它里面有8个未知参数待求。
为什么9个元素(3*3)却有8个自由度?

一共只有8个k待求解。
单应性变换
单应性变换其实就是一个平面到另一个平面的变换关系。

点表示两幅图像中的相同物理点,我们称之为对应点。这里显示了四种不同颜色的四个对应点 - 红色,绿色,黄色和橙色。 一个Homography是一个变换(3×3矩阵),将一个图像中的点映射到另一个图像中的对应点。
下面的例子中使用了AKAZE的OpenCV实现:
import numpy as np
import cv2 as cv
img = cv.imread('image.jpg')
gray= cv.cvtColor(img, cv.COLOR_BGR2GRAY)
akaze = cv.AKAZE_create()
kp, descriptor = akaze.detectAndCompute(gray, None)
img=cv.drawKeypoints(gray, kp, img)
cv.imwrite('keypoints.jpg', img)特征匹配
一旦在一对图像中识别出关键点,我们就需要将两个图像中对应的关键点进行关联或“匹配”。其中一种方法是BFMatcher.knnMatch()。这个方法计算每对关键点之间的描述符的距离,并返回每个关键点的k个最佳匹配中的最小距离。
然后我们设定比率来保持正确率。实际上,为了使匹配更可靠,匹配的关键点需要比最近的错误匹配更靠近。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('image1.jpg', cv.IMREAD_GRAYSCALE) # referenceImage
img2 = cv.imread('image2.jpg', cv.IMREAD_GRAYSCALE) # sensedImage
# Initiate AKAZE detector
akaze = cv.AKAZE_create()
# Find the keypoints and descriptors with SIFT
kp1, des1 = akaze.detectAndCompute(img1, None)
kp2, des2 = akaze.detectAndCompute(img2, None)
# BFMatcher with default params
bf = cv.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# Apply ratio test
good_matches = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good_matches.append([m])
# Draw matches
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good_matches,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv.imwrite('matches.jpg', img3)
OpenCV中关于特征匹配方法的实现:
图像变换
在匹配至少四对关键点之后,我们就可以将一个图像转换为另一个图像,称为图像变换^12(image warping)。空间中相同平面的两个图像通过单应性变换^13(Homographies)进行关联。Homographies是具有8个自由参数的几何变换,由3x3矩阵表示图像的整体变换(与局部变换相反)。因此,为了获得变换后的感测图像,需要计算Homographies矩阵。
为了得到最佳的变换,我们需要使用RANSAC算法检测异常值并去除。它内置在OpenCV的findHomography方法中。同时也存在RANSAC算法的替代方案,例如LMEDS:Least-Median鲁棒方法。
# Select good matched keypoints
ref_matched_kpts = np.float32([kp1[m[0].queryIdx].pt for m in good_matches]).reshape(-1,1,2)
sensed_matched_kpts = np.float32([kp2[m[0].trainIdx].pt for m in good_matches]).reshape(-1,1,2)
# Compute homography
H, status = cv.findHomography(ref_matched_kpts, sensed_matched_kpts, cv.RANSAC,5.0)
# Warp image
warped_image = cv.warpPerspective(img1, H, (img1.shape[1]+img2.shape[1], img1.shape[0]))
cv.imwrite('warped.jpg', warped_image)
深度学习方法
目前大多数关于图像配准的研究涉及深度学习。在过去的几年中,深度学习使计算机视觉任务具有先进的性能,如图像分类,物体检测和分割。
特征提取
深度学习用于图像配准的第一种方式是用于特征提取。卷积神经网络设法获得越来越复杂的图像特征并进行学习。2014年以来,研究人员将这些网络应用于特征提取的步骤,而不是使用SIFT或类似算法。
2014年,Dosovitskiy等人提出了一种通用的特征提取方法,使用未标记的数据训练卷积神经网络。这些特征的通用性使转换具有鲁棒性。这些特征或描述符的性能优于SIFT描述符以匹配任务。
2018年,Yang等人开发了一种基于相同思想的非刚性配准方法。他们使用预训练的VGG网络层来生成一个特征描述符,同时保留卷积信息和局部特征。这些描述符的性能也优于类似SIFT的探测器,特别是在SIFT包含许多异常值或无法匹配足够数量特征点的情况下。
有监督学习的配准
(1)标签是什么?
既然是有监督学习,那么他的标签是什么?
两个图像之间变形场。什么是变形场?就是相同像素点,这一对图像相互差了多少,即物体三维/二维空间内的位移矢量的空间分布状况。
(2)如何获取标签?
① 利用传统的经典配准方法进行配准,得到的变形场作为标签;
② 对原始图像进行模拟变形,将原始图像作为固定图像,变形图像作为移动图像,模拟变形场作为标签。
图像配准系统包括四个部分(图像配准基本步骤)
特征检测(Feature Detection)
这里的特征指的是广义的特征,包括图像灰度、色度特征;角点、边缘、轮廓等结构性特征;频域信息、小波系数等。
特征匹配(Feature Matching)
即使用特征描述算子(即特征向量)和相似性策略对特征进行匹配。
变换模型参数估算(Transform Model Estimation)
变换模型又称映射模型(Mapping Model),即将输入图像向参考图像映射的坐标变换函数。
图像重采样与变换(Image Resampling and Transformations)
这一步就是我们由输入图像经变换模型向参考图像进行对齐的过程。变换后图像的坐标将不再是整数,这就涉及到重采样与插值的技术。
图像配准步骤
基于特征的图像配准步骤可大致分为如下四步:特征检测、特征匹配、变换模型估计和图像的变换和重采样。
1) 特征检测:特征检测是从参考图像和待配准图像中提取显著性的特征,这些特征是图像属性的典型代表。显著性特征可以是区域特征(如森林、湖泊、田野),也可以是线特征(如区域边界、海岸线、道路、河流)或者点特征(区域角点、线分界点、曲线上的拐点)。这些显著性特征具有可区分性、分布在整个图像之上,并且能同时在参考图像和待配准中稳定检测到。图像特征是图像中具有代表性的属性,是人类提取出的图像典型表示。图像特征应满足以下特性:
a) 差异性:图像特征是图像的准确表示,不同类型的图像应当具有不同类型的特征,因此图像特征之间必须具备一定的差异性。
b) 同类性:图像配准在具备差异性也应当具有同类性,即相同类型的图像具有相同类型的特征,进而相同类型的图像可以通过特征建立联系。
c) 独立性:同一幅图像所检测到特征之间应当相互独立,即某个特征的存在不是以其他特征的存在为条件的。
对于图像上具备以上条件的特征,若其经历一个或多个空间变换之后仍然是图像的特征,则这样的图像特征称为图像的不变特征。图像的不变特征最能反映图像的本质内容,它是原图像和变换图像之间建立联系的纽带,是求解图像之间空间变换模型和参数的基础。图像不变特征不会随着图像的外部条件而变化,即不随视角、光照、噪声、尺度、遮挡和模糊等情况而发生变化。因此,图像特征检测的目标就是尽可能多的检测稳定的图像不变特征。由于图像不变特征的重要性,得到很多国内外科研机构的重视,像加拿大的英属哥伦比亚大学智能计算实验室、芬兰的Oulu 大学机器视觉小组、英国牛津大学机器人研究小组和国内的中科院自动化所NLPR 实验室等。
特征包括:点特征、线特征、面特征。
点特征:最常用的一种图像特征,包括物体边缘点、角点、线交叉点等;根据各特征点的兴趣值将特征点分成几个等级。对不同目的,特征点的提取应有所不同。点特征提取方法有:
Harris算法:受信号处理中相关函数的启发,给出与自相关函数相联系的矩阵M,M矩阵的特征值就是自相关函数的一阶曲率,如果两个曲率值都高,那么就认为该点是角点,此方法对图像旋转、亮度变化、视角变化和噪声的影响具有较好的鲁棒性。
Susan算法:Susan算法使用一个圆形的模板在图像上滑动,将位于圆形模板中心的待检测的像素点称为核心点。假设图像为非纹理,核心点的领域被划分为两个区域:其一为亮度值等于(或相似于)核心点亮度的区域,称为核值相似区,其二为亮度值不相似于核心点亮度的区域。
Harris-Laplace:Harris算子能最稳定地在图像旋转、光照变化、透视变换条件下提取二维平面特征点,但在三维尺度空间中,Harris探测子的重复探测性能不好,不同尺度Harris特征点存在位置误差,Harris探测子不具有尺度和仿射不变性。而三维尺度空间中最稳定高效的特征尺度探测算子是归一化的Laplace算子。结合Harris和Laplace的优点提出Harris-Laplace算子。 Harris-Laplace特征点具有尺度和旋转不变的特性,且对光照变换和小范围视角变换具有稳定性。
SIFT特征点提取:使用DoG filter来建立尺度空间,在尺度空间上提取极值点。
SURF特征点提取:基于Hessian矩阵,它依靠Hessian矩阵行列式的局部最大值定位兴趣点位置。对于图像I中某点X在尺度空间上Hessian矩阵定义为:
其中L_xx(X,σ)表示高斯二阶偏导在X处与图像I的卷积。
FAST特征点提取:FAST是对SUSAN角点提取的简化,通过比较一个圆上16个像素点与中心像素点的灰度对比情况来判断中心像素点是否为特征点。
Moravec算子、Forstner算子...
线特征:图像中最明显的线段特征,如道路河流的边缘,目标的轮廓线等。线特征的提取一般分两步进行:首先采用某种算法提取出图像中明显的线段信息,然后用限制条件帅选出满足条件的线段作为线特征。线特征提取方法有:
Robert、Sobel、Prewitt、Kirsch、Gauss-Laplace、Canny...
面特征:指利用图像中明显的区域信息作为特征。在实际的应用中最后可能也是利用区域的重心或圆的圆心点等作为特征。面特征提取方法有:
Mser:使用不同的阈值对图像进行二值化,这个过程中,所有阈值图像上形成的连接区域都是极小值区域,在阈值图像的变化过程中,形成了一系列嵌套的极值区域组。在每组嵌套区域里,有一类性质较为稳定的区域,这类区域在较大阈值范围内具有较小的变化,被定义为“最稳定极值区域”。
2)特征匹配:检测到的参考图像和待配准图像上的特征可以通过相邻区域的图像强度均值、特征的空间分布或者代表特征的描述子进行匹配。特征匹配的关键一方面在于特征检测提供的特征,另一方面就在于匹配策略的选择。特征匹配要考虑采用何种参量进行相似性度量,以及何时达到最佳匹配。常用的相似性度量参量有基于区域的归一化互相关、互信息和基于特征的不变特征、金字塔和小波等。
特征匹配分两步:特征描述、利用相似度准则进行特征匹配。
特征描述:现有的主要特征描述子:SIFT特征描述子、SUFR特征描述子、对比度直方图、DAISY特征描述子,矩方法。
SIFT特征描述子:基于图像梯度分布的特征描述子,特点:抗干扰性好,但位数高,计算复杂度大。
SURF特征描述子:将特征点的周围区域分成几个子区域,用每个子区域内像素点的X,Y方向的偏导和及其绝对值的和组成特征点的描述子。特点:有较好的抗亮度变化能力,但该描述子要求使用积分图像,限定了其应用范围。
对比度直方图:将特征点周围区域的像素点与特征点的对比度形成直方图来描述该特征点。特点:该方法比基于梯度的描述子要快,但描述力比基于梯度的要略微弱一点。
DAISY特征描述子:受SIFT算法和GLOH算法启发,将梯度加权和用几个高斯方向偏导滤波器与原图像进行积分代替。特点:该描述子有和SIFT特征算子相似的优点,但是速度比SIFT特征算子要快。
矩方法:Hu矩,zernike矩。
利用相似度准则进行特征匹配:常用的相似性测度准则有如欧氏距离、马氏距离、Hausdorff距离等。
3)变换模型估计:变换模型估计是根据匹配的特征对来估计变换模型。在有些情况下,特征匹配的同时就已经估计出变换模型,因此第二步和第三步也可以放在一起。变换模型估计就是要选择匹配函数的类型及其参数估计。
刚体变换模型
仿射变换模型
投影变换模型
非线性变换模型
4)图形的变换和重采样:图像的变换和重采样是在得到变换模型后,对待配准图像进行变换和赋值,赋值方法有前向变换法和后向变换法。前向变换法是从参考图像上的像素点坐标出发,计算配准后像素点坐标位置,并将该像素点的灰度值作为新像素点处的灰度值;后向变换法是从配准后图像上的像素点坐标出发,计算参考图像上对应的像素点坐标,并将参考图像上该点的灰度值作为变换之前像素点处的灰度值。由于前向变换法可能产生没有赋值的像素点,或者出现多个像素点对应一个像素点的情况,并且实现较后向变换法困难,因此多采用后向变换法。后向变换法需要采用灰度插值法,常用的插值方法有最近邻插值、双线性插值和立方卷积插值等。(涉及输入图像变换后所得点坐标不一定为整数素数,则应进行插值处理。)
步骤
要做图像配准你必须得考虑3个问题,分别是配准时所用到的空间变换模型、配准的相似性测度准则以及空间变换矩阵的寻优方式。
①、空间变化模型
空间变化模型是指的这两幅要配准的图像之间的映射模型,比如只有旋转、平移这些操作,那就是刚体变换模型,又比如有缩放操作,甚至X方向和Y方向缩放的幅度都还不一样,那就是仿射变换或者非线性变换模型。总之你要做配准,先要确定这两幅图像之间是一种什么样的映射模型。2D平面变换的基本集合有,平移,欧氏,相似,仿射,投影这五种变换。
②配准的相似度测量准则
配准的相似性测量准则。在你确定了变换模型后,接下去要做什么?当然是确定模型里的参数了,而要确定这些参数(不同的变换模型参数个数是不一样的,像刚体变换有x平移、y平移和旋转角度sita三个参数,仿射变换有6个参数)你得告诉程序什么参数是最好的,或者说是正确的。那么判断什么参数是正确的一个准则就是我们说的配准的相似性测度准则,也就是告诉程序在某组参数下是配准的程度是多少,显然使得配准程度最好的那组参数就是我们要找的参数。最基本的方法是误差平方和测量准则。
③空间变换矩阵的寻优方式
空间变换矩阵的寻优方式。因为大多数情况下,模型中的参数不是靠解出来的,而是要靠“尝试-判断”这种方式去寻找,空间变换矩阵的寻优说白了也就是怎么对这些参数进行寻优,找出使得配准程度最好的那一组参数的过程。一般情况下,配准问题都会转化为求解相似性测度最优值的问题,在计算方法中通常需要采用合适的迭代优化算法,诸如梯度下降法、牛顿法、遗传算法等等,如果你对这些算法都不了解,没办法,你只有用最笨的遍历式搜索方法了,也就是以某一个步距,搜索所有的参数组合方式,然后找出使得按照相似性测度准则配准程度最高的那一组参数。
图像配准四个方面、五个步骤:
图像配准技术包括四个方面:变换模型、特征空间、相似性测度、搜索空间和搜索策略。依据这四个特性,图像配准的步骤一般可分为以下五个步骤:
根据实际应用场合选取适当的变换模型;
选取合适的特征空间,或者是基于灰度的或者是基于特征的;
根据变换模型的参数配置以及所选用的特征,确定参数可能变化的范围,并选用最优的搜索策略;
应用相似性测度在搜索空间中按照优化准则进行搜索,寻找最大相关点,从而求解出变换模型中的未知参数;
将待配准图像按照变换模型逐像素一一对应到参考图像中,实现图像间的匹配。
其中,如何选取合适的特征进行匹配是配准的关键所在。
一些常用的配准方法
1.基于像素的方法
采用一种互相关统计的方法,涉及到查找图像中模式的位置与方向,是相似性与匹配度的度量。比如,二维归一化一组互相关函数,评估参考图像与感知图像之间的每个平移的相似性,其中参考图像与感知图像比起来很小,如果参考图像适合,则互相关达到最大值。这种方法的主要缺点是图片的自相似性【图像的自相似性是指相邻或者不相邻的图像块很相似】带来的相似性度量最大值平坦度以及高处理复杂性。
2.点映射法
采用特征提取算法得到的图片特征,从输入的原始数据中提取大量信息,过滤掉冗余信息,在检测到每个图像的特征后,它们必须被匹配。拐角、相交线、等高线上的最大曲率点、具有最大曲率的窗口中心以及封闭边界区域的重心,都是所谓的控制点。点映射法主要有三个阶段:提取特征→找到特征点→空间映射。该方法的缺点是窗口内容的特殊性,包含缺乏关键信息的平滑区域的窗口可能被错误地与参考图片中的其他平滑区域匹配。
3.基于轮廓的方法
为了产生图像的轮廓,计算给定颜色集合的均值,然后在分割过程中将图像的每个RGB像素分类为在特定范围内的颜色或者不在特定范围内的颜色。点的轨迹是一个半径等于阈值的球体,位于球体内部和表面的每个点都满足规定的颜色要求,然后对图像中的点根据是否在范围内进行二值处理,得到了一个二值分割图像。再通过一个高斯滤波器用于消除分割过程后的噪声,获得图像的轮廓,但是这种方法运行速度非常的慢。
除了上述方法外,还有使用互信息的多模态图像配准、频域图像配准以及使用遗传算法进行的图像配准等等。
图像配准传统算法总结
图像配准是图像处理研究领域中的一个典型问题和技术难点,其目的在于比较或融合针对同一对象在不同条件下获取的图像,例如图像会来自不同的采集设备,取自不同的时间,不同的拍摄视角等等,有时也需要用到针对不同对象的图像配准问题。具体地说,对于一组图像数据集中的两幅图像,通过寻找一种空间变换把一幅图像映射到另一幅图像,使得两图中对应于空间同一位置的点一一对应起来,从而达到信息融合的目的。
图像配准方法分类
图像配准分类:
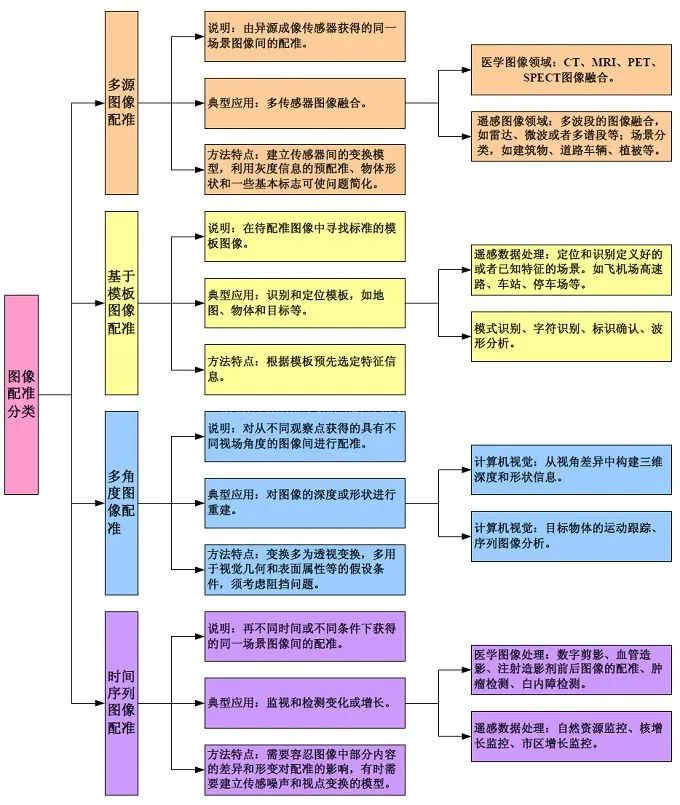
根据问题特点的分类:
1. Registration Quality: 配准性质
根据数据或特征确定的配准类型。
如自然图像配准,医学图像配准,遥感图像配准等。
2. 图像采集方式
① Multi-view Analysis: 多视图配准
同一物体在同一场景不同视角下的图像配准。
从多个视角捕获相似对象或场景的图像,以便获得扫描对象或场景的更好表示。如使用图像拼接,从2D图像重建3D模型等。
②Multi-temporal Analysis: 多时相配准
同一物体在同一场景同视角不同时间的图像配准。如运动追踪,肿瘤生长情况跟踪等。
③Multi-modal Analysis: 多模态配准
多模配准常见于医学图像领域,故以多模医学图像配准为例。
由于医学成像设备可以提供关于患者不同信息不同形式的图像(计算机断层扫描CT,核磁共振MRI,正电子发射断层成像PET,功能核磁共振fMRI等)。
基于单种或多种模态图像的配准,可划分为单模态(Single-modality)和多模态(Multi-modality)。
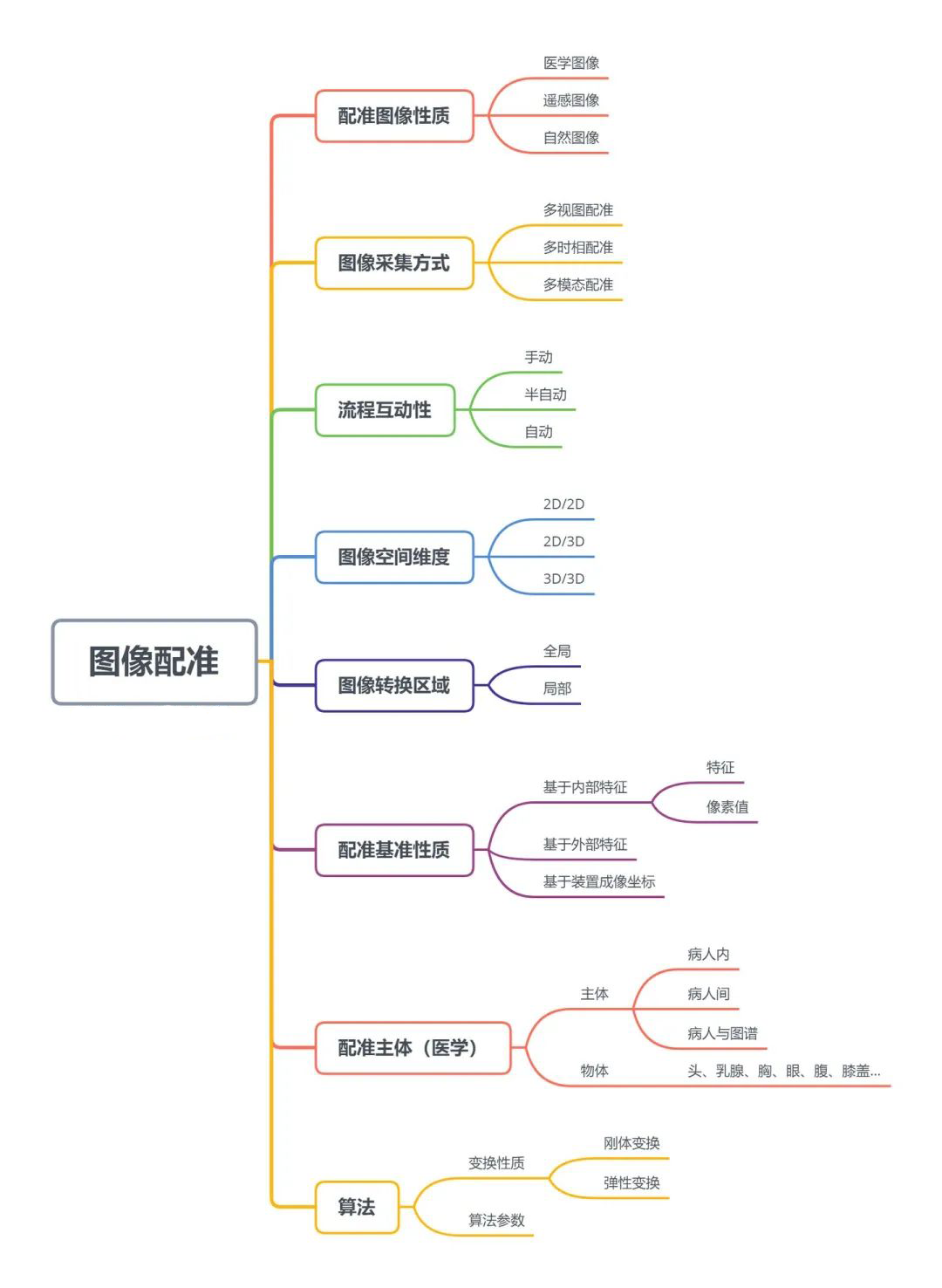
3. Interaction: 配准流程互动性
手动,半自动或自动
4. Dimensionality: 图像空间维数
若仅考虑空间维数,可以划分为2D/2D, 2D/3D, 3D/3D等。若考虑时间序列因素,还存在对在不同时刻提取的两幅图像进行配准的问题。
5. Domain of transformation: 图像转换区域(全局/局部配准)
6. Nature of Registration basis: 配准基准的性质
根据算法所基于的特征及相似性测度。
①基于内部特征的配准
内部特征指的是从图像内部本身提取的信息。
基于特征(feature-based):在几何上有特别意义的可以定位的特征点集(比如不连续点,图形的转折点,线交叉点等),或者用分割的方法提取出感兴趣的部分的轮廓(曲线或曲面),以作为用来比较的特征空间。在医学图像上可以是具有解剖意义的点。
基于像素值(intensity-based):利用整幅图像的像素或体素来构成特征空间。根据像素值的统计信息来计算相似性测度又可划分为最小二乘法,傅里叶法,互相关法,互信息法等等。
②基于外部特征的配准
在医学图像中,通过在患者身上固定标记物或向体内注入显影物质以获得在图像上的确定的标记点,称为外部特征点。
③基于不同装置成像坐标的配准
7. Subject of Registration: 配准主体
以医学图像配准为例,可分为 Intra-subject (图像来自于同一病人),Inter-subjective (来自不同的病人)和 Atlas (病人数据和图谱的配准)三种。
Object of Registration 配准物体:头、乳腺、胸、眼、腹、膝盖 等…
8. Type of transformation: 变换性质
根据用于将浮动图像空间与参考图像空间相关联的变换模型对图像配准算法进行分类。对图像进行空间变换可以分为刚体变换(rigid)和非刚体变换(non- rigid, deformable)。
第一类变换模型是线性变换,包括旋转,缩放,平移和其他仿射变换。线性变换本质上是全局的,因此,它们无法模拟图像之间的局部几何差异。
第二类变换模型允许“弹性”或“非刚性”变换。这些变换能够局部地扭曲浮动图像使其与参考图像对准。非刚性变换包括径向基函数(薄板或曲面样条函数,多重二次曲面函数和紧支撑变换),物理连续模型(粘性流体)和大变形模型(微分同胚)。
变换模型通常是参数化的例如,可以通过单个参数(变换向量)来描述整个图像的变换。这些模型称为参数模型。另一方面,非参数模型不遵循任何参数化,允许每个图像元素任意移位。
9. Parameters of Registration: 算法参数
当比较特征采用特征点集的形式时,可以通过联立方程组来找到变换的解。
但一般情况下,配准问题都会转化为求解相似性测度最优值的问题,在计算方法中通常需要采用合适的迭代优化算法,诸如梯度下降法、牛顿法、Powell法、遗传算法等。
根据算法本质的分类:
1.基于灰度的图像配准
基于灰度信息的图像配准方法一般不需要对图像进行复杂的预先处理,而是利用图像本身具有灰度的一些统计信息来度量图像的相似程度。主要特点是实现简单,但应用范围较窄,不能直接用于校正图像的非线性形变,在最优变换的搜索过程中往往需要巨大的运算量。经过几十年的发展,人们提出了许多基于灰度信息的图像配准方法,大致可以分为三类:互相关法(也称模板匹配法)、序贯相似度检测匹配法、交互信息法。
2.基于特征的图像配准
共同之处
基于特征的匹配方法的共同之处是首先要对待配准图像进行预处理,也就是图像分割和特征提取的过程,再利用提取得到的特征完成两幅图像特征之间的匹配,通过特征的匹配关系建立图像之间的配准映射关系。由于图像中有很多种可以利用的特征,因而产生了多种基于特征的方法。常用到的图像特征有:特征点(包括角点、高曲率点等)直线段、边缘、轮廓、闭合区域、特征结构以及统计特征如矩不变量、重心等等。
点
是配准中常用到的图像特征之一,其中主要应用的是图像中的角点,图像中的角点在计算机视觉模式识别以及图像配准领域都有非常广泛的应用。基于角点的图像配准的主要思路是首先在两幅图像中分别提取角点,再以不同的方法建立两幅图像中角点的相互关联,从而确立同名角点,最后以同名角点作为控制点,确定图像之间的配准变换。由于角点的提取已经有了相当多的方法可循,因此基于角点的方法最困难的问题就是怎样建立两幅图像之间同名点的关联。已报道的解决点匹配问题的方法包括松弛法、相对距离直方图聚集束检测法、Hausdorff距离及相关方法等等。这些方法都对检测到的角点要求比较苛刻,比如有求同样多的数目,简单的变换关系等等,因而不能适应普遍的配准应用。
匹配质量
基于图像配准的原理、步骤和方法,以及如何确定图像配准的准则,知道影像匹配的速度、精度和可靠性是评价匹配质量好坏的三个重要指标。如何尽可能提高匹配质量、特别在精度和可靠性满足的前提下进一步提高影像匹配速度,一直是计算机视觉、模式识别等领域研究的课题。
具体的图像配准算法是基于这两点的混合或者变体的算法。
图像匹配与图像配准的区别:
图像匹配(image matching)
通过对影像内容、特征、结构、关系、纹理及灰度等的对应关系,相似性和一致性分析,寻求相同影像目标的方法。影像相关是利用互相关函数,评价两块影像的相似性以确定同名点。即首先取出以待定点为中心的小区域中的影像信号,然后取出其在另一影像中相应区域的影像信号,计算二者的相关函数,以相关函数最大值对应的相应区域中心点为同名点。同名点的确定是以匹配测度为基础的,因此定义匹配测度是影像匹配最首要的任务,基于不同的理论或不同的思想可以定义各种不同的匹配测度,因而形成了各种影像匹配方法及相应的实现算法。常见的基于像方灰度的影像匹配算法有相关函数法、协方差函数法、相关系数法、差平方和法、差绝对值和法、最小二乘法等,基于物方的影像匹配算法有铅垂线轨迹法(VLL,Vertical Line Locus),另外还有基于像方特征的跨接法影像匹配,金字塔多级影像匹配, SIFT等等。
图像配准(Image Registration)
图像配准就是将不同时间、不同传感器(成像设备)或不同条件下(天候、照度、摄像位置和角度等)获取的两幅或多幅图像进行匹配、叠加的过程,配准技术的流程如下:首先对两幅图像进行特征提取得到特征点;通过进行相似性度量找到匹配的特征点对;然后通过匹配的特征点对得到图像空间坐标变换参数:最后由坐标变换参数进行图像配准。而特征提取是配准技术中的关键,准确的特征提取为特征匹配的成功进行提供了保障。因此,寻求具有良好不变性和准确性的特征提取方法,对于匹配精度至关重要。基于特征的图像配准首先提取图像信息的特征,然后以这些特征为模型进行配准。特征提取的结果是一含有特征的表和对图像的描述,每个特征由一组属性表示,对属性的进一步描述包括边缘的定向和弧度、区域的大小等。局部特征之间存在着相互关系,如几何关系、辐射度量关系、拓扑关系等。可以用这些局部特征之间的关系描述全局特征。通常基于局部特征配准大多都是基于点、线或边缘的,而全局特征的配准则是利用局部特征之间的关系进行配准的方法。基于互信息的图像配准是用两幅图像的联合概率分布与完全独立时的概率分布的广义距离来估计互信息,并作为多模态医学图像配准的测度。当两幅基于共同的解剖结构的图像达到最佳配准时,它们的对应像素的灰度互信息应为最大。由于基于互信息的配准对噪声比较敏感,首先,通过滤波和分割等方法对图像进行预处理。然后进行采样、变换、插值、优化从而达到配准的目的。
几种基于灰度的图像匹配算法:
平均绝对差算法(MAD)、绝对误差和算法(SAD)、误差平方和算法(SSD)、平均误差平方和算法(MSD)、归一化积相关算法(NCC)、序贯相似性检测算法(SSDA)、hadamard变换算法(SATD)。
MAD算法:
平均绝对差算法(Mean Absolute Differences,简称MAD算法),它是Leese在1971年提出的一种匹配算法。是模式识别中常用方法,该算法的思想简单,具有较高的匹配精度,广泛用于图像匹配。
设S(x,y)是大小为mxn的搜索图像,T(x,y)是MxN的模板图像,分别如下图(a)、(b)所示,我们的目的是:在(a)中找到与(b)匹配的区域(黄框所示)。
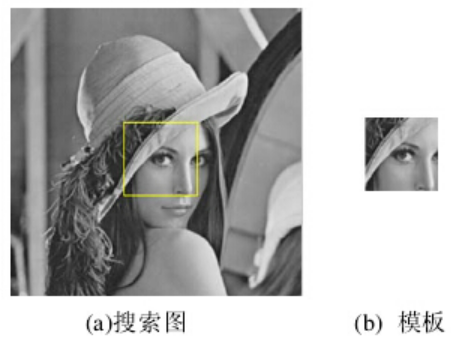
算法思路
在搜索图S中,以(i,j)为左上角,取MxN大小的子图,计算其与模板的相似度;遍历整个搜索图,在所有能够取到的子图中,找到与模板图最相似的子图作为最终匹配结果。
MAD算法的相似性测度公式如下。显然,平均绝对差D(i,j)越小,表明越相似,故只需找到最小的D(i,j)即可确定能匹配的子图位置:
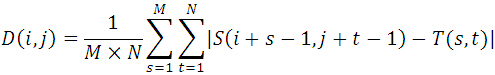
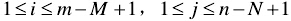
算法评价:
优点:
①思路简单,容易理解(子图与模板图对应位置上,灰度值之差的绝对值总和,再求平均,实质:是计算的是子图与模板图的L1距离的平均值)。
②运算过程简单,匹配精度高。
缺点:
①运算量偏大。
②对噪声非常敏感。
SAD算法
介绍
绝对误差和算法(Sum of Absolute Differences,简称SAD算法)。实际上,SAD算法与MAD算法思想几乎是完全一致,只是其相似度测量公式有一点改动(计算的是子图与模板图的L1距离)。
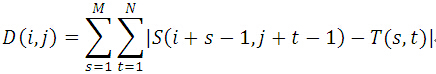
SSD算法
误差平方和算法(Sum of Squared Differences,简称SSD算法),也叫差方和算法。实际上,SSD算法与SAD算法如出一辙,只是其相似度测量公式有一点改动(计算的是子图与模板图的L2距离)。
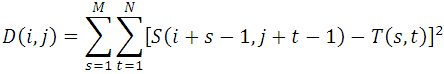
MSD算法
平均误差平方和算法(Mean Square Differences,简称MSD算法),也称均方差算法。实际上,MSD之余SSD,等同于MAD之余SAD(计算的是子图与模板图的L2距离的平均值)。
NCC算法
归一化积相关算法(Normalized Cross Correlation,简称NCC算法),与上面算法相似,依然是利用子图与模板图的灰度,通过归一化的相关性度量公式来计算二者之间的匹配程度。
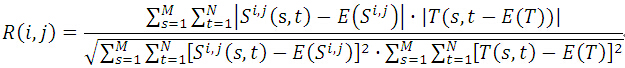
E(S^i,j)、E(T)分别表示(i,j)处子图、模板的平均灰度值。
SSDA算法
序贯相似性检测算法(Sequential Similiarity Detection Algorithm,简称SSDA算法),它是由Barnea和Sliverman于1972年,在文章《A class of algorithms for fast digital image registration》中提出的一种匹配算法,是对传统模板匹配算法的改进,比MAD算法快几十到几百倍。
与上述算法假设相同:S(x,y)是mxn的搜索图,T(x,y)是MxN的模板图,S_i,j是搜索图中的一个子图(左上角起始位置为(i,j))。
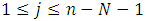
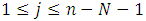
SSDA算法描述如下:
①定义绝对误差:
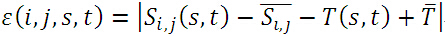
带有上划线的分别表示子图、模板的均值:
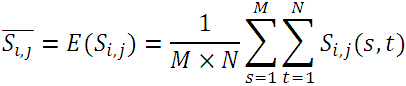
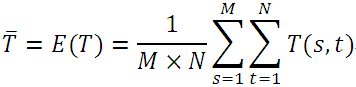
实际上,绝对误差就是子图与模板图各自去掉其均值后,对应位置之差的绝对值。
②设定阈值Th;
③在模板图中随机选取不重复的像素点,计算与当前子图的绝对误差,将误差累加,当误差累加值超过了Th时,记下累加次数H,所有子图的累加次数H用一个表R(i,j)来表示。SSDA检测定义为:
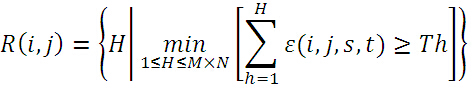
下图给出了A、B、C三点的误差累计增长曲线,其中A、B两点偏离模板,误差增长得快;C点增长缓慢,说明很可能是匹配点(图中Tk相当于上述的Th,即阈值;I(i,j)相当于上述R(i,j),即累加次数)。
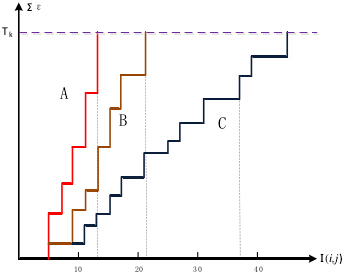
④在计算过程中,随机点的累加误差和超过了阈值(记录累加次数H)后,则放弃当前子图转而对下一个子图进行计算。遍历完所有子图后,选取最大R值所对应的(i,j)子图作为匹配图像【若R存在多个最大值(一般不存在),则取累加误差最小的作为匹配图像】。
由于随机点累加值超过阈值Th后便结束当前子图的计算,所以不需要计算子图所有像素,大大提高了算法速度;为进一步提高速度,可以先进行粗配准,即:隔行、隔离的选取子图,用上述算法进行粗糙的定位,然后再对定位到的子图,用同样的方法求其8个邻域子图的最大R值作为最终配准图像。这样可以有效的减少子图个数,减少计算量,提高计算速度。
SATD算法
hadamard变换算法(Sum of Absolute Transformed Difference,简称SATD算法),它是经hadamard变换再对绝对值求和算法。hadamard变换等价于把原图像Q矩阵左右分别乘以一个hadamard变换矩阵H。其中,hardamard变换矩阵H的元素都是1或-1,是一个正交矩阵,可以由MATLAB中的hadamard(n)函数生成,n代表n阶方阵。
SATD算法就是将模板与子图做差后得到的矩阵Q,再对矩阵Q求其hadamard变换(左右同时乘以H,即HQH),对变换都得矩阵求其元素的绝对值之和即SATD值,作为相似度的判别依据。对所有子图都进行如上的变换后,找到SATD值最小的子图,便是最佳匹配。
基于特征点的配准定位方法:
椭圆区域为SIFT特征匹配区域,椭圆的中心位置代表了关键点在图像中的二维坐标位置,椭圆的长轴代表了关键点的尺度,椭圆的方向代表了该关键点的方向。

图像对的匹配点数随着阈值的增加而逐渐减少,但是匹配点更加稳定。SIFT特征是图像的局部特征,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配,并可通过选择适合的阈值,寻找可靠、稳定的特征匹配点。
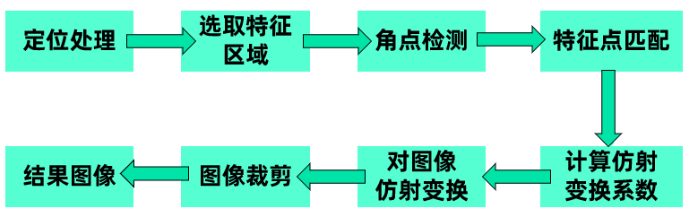
基于图像矩的配准定位方法:
对基准图像和待配准图像进行特征提取预处理,采用质心主轴法完成两幅图像特征之间的匹配,建立图像之间的配准映射关系,利用仿射变换对待配准图像进行图像变换实现图像配准定位。
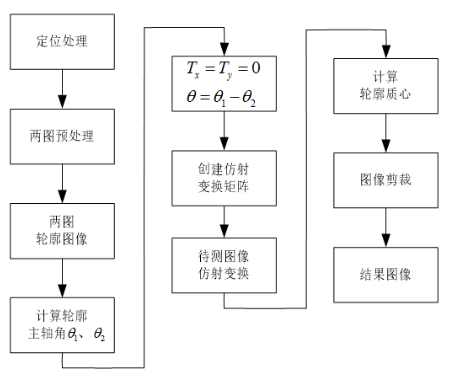
对基准图像和待配准图像分别进行图像处理,经过阈值分割、中值滤波、轮廓提取、轮廓跟踪得到两幅图像的连续完整轮廓;分别针对两个轮廓图像计算出其目标轮廓的主轴,两主轴的夹角即为图像的旋转角。
图像配准算法分类:
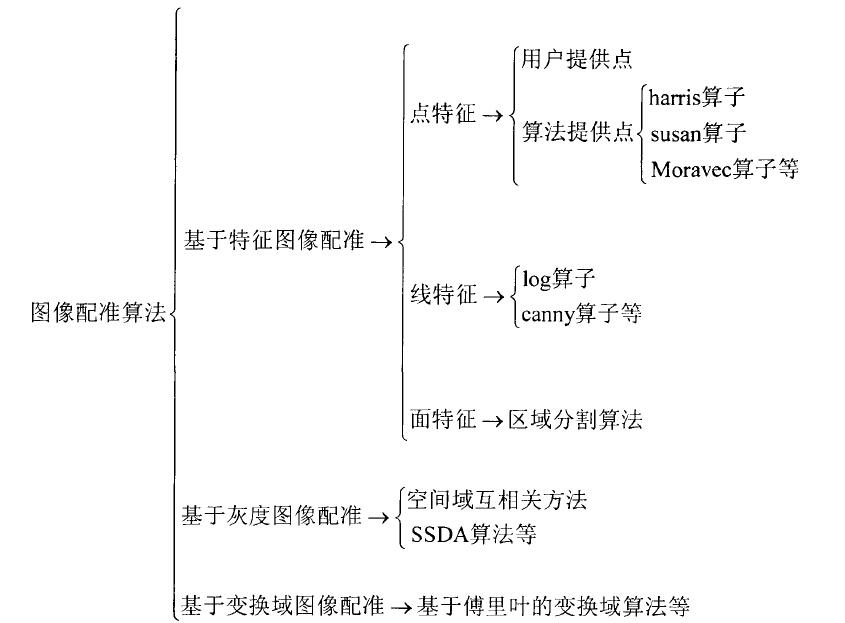
基于特征
首先提取图像的特征,再生成特征描述子,最后根据描述子的相似程度对两幅图像的特征之间进行匹配。图像的特征主要可以分为点、线(边缘)、区域(面)等特征,也可以分为局部特征和全局特征。区域(面)特征提取比较麻烦、耗时,因此主要用点特征和边缘特征。
点特征:
- Harris
- Moravec
- KLT
- Harr-like
- HOG
- LBP
- SIFT
- SURF
- BRIEF
- SUSAN
- FAST
- CENSUS
- FREAK
- BRISK
- ORB
- 光流法
- A-KAZE
边缘特征:
- LoG算子
- Robert算子
- Sobel算子
- Prewitt算子
- Canny算子
基于灰度和模板
这类方法直接采用相关运算等方式计算相关值来寻求最佳匹配位置,模板匹配(BlockingMatching)是根据已知模板图像到另一幅图像中寻找与模板图像相似的子图像。基于灰度的匹配算法也称作相关匹配算法,用空间二维滑动模板进行匹配,不同匹配算法主要体现在相关准则的选择方面。
常用算法:
- 平均绝对差算法(MAD)
- 绝对误差和算法(SAD)
- 误差平方和算法(SSD)
- 平均误差平方和算法(MSD)
- 归一化积相关算法(NCC)
- 序贯相似性检测算法(SSDA)
- hadamard变换算法(SATD)
- 局部灰度值编码算法
- PIU
基于域变换
- 采用相位相关(傅里叶-梅林变换) 18 代码19
- 沃尔什变换
- 小波
图像配准的方法大致分为三类:
一类是基于灰度和模板的,这类方法直接采用相关运算等方式计算相关值来寻求最佳匹配位置,方法简单较为死板,一般效果不会太好。
第二类是基于特征的匹配方法,如sift、surf点特征,或者向量特征等等,适应性较强。
第三类是基于域变换的方法,采用相位相关(傅里叶-梅林变换)或者沃尔什变换、小波等方法,在新的域下进行配准。
根据不同的配准指标,这些方法可以归纳为以下三类。
点标记或基准标记法,标记两幅图像之间相同标志物的位置,然后计算它们之间的转换关系。这些标志物可以是内部基准标记物或外部皮肤标记物。理想情况下,三对对应的标记就足以计算两个三维图像的刚性变换,特别注意,它们不要在一条直线上。均方根误差通常被称为“目标配准误差”。“目标配准误差”有时可以作为一个度量来最小化两组点之间的实际距离,而不仅仅是基准标记的质心之间的距离。
基于特征的刚性配准,除基准标点以外的特征也可以用于刚性配准。这些特征的例子包括线、曲线、点云或曲面。一般来说,这些特征可以由计算机自动提取,或由人类手动提取。通常情况下,它要求配准能够在一定程度上容忍特征提取误差。配准算法直接应用于这些特征。由于对应关系未知,通常需要进行迭代优化来同时估计特征对应关系和变换。最流行的算法是迭代最近点(ICP)算法,该算法被广泛应用于配准两组点或曲面。在一些应用中,据报道它可以产生准确和稳健的结果。
基于图像强度值的配准方法。配准度量是由两幅图像之间的相似度计算出来的。该方法不需要预分割或预描述相应的结构,因此可以是完全自动化的,通常比基于特征的配准方法更鲁棒。一些常用的配准相似性度量包括强度平方差(SSD)、互相关系数(CC),比率图像均匀性和基于信息理论的指标,如联合熵和库贝-莱布勒(KL)距离。
这些度量值大多直接应用于整个图像,这通常被称为全局度量值。为了实现更准确的配准,一些研究人员也提出了他们的局部度量,使用与全局指标相同的度量,但描述一个感兴趣的区域(ROI),而不是整个图像域。典型的例子包括模板匹配和重要区域特征匹配。
图像配准的方式
图像配准的方式可以概括为相对配准和绝对配准两种:相对配准是指选择多图像中的一张图像作为参考图像,将其它的相关图像与之配准,其坐标系统是任意的。绝对配准是指先定义一个控制网格,所有的图像相对于这个网格来进行配准,也就是分别完成各分量图像的几何校正来实现坐标系的统一。本文主要研究大幅面多图像的相对配准,因此如何确定多图像之间的配准函数映射关系是图像配准的关键。通常通过一个适当的多项式来拟合两图像之间的平移、旋转和仿射变换,由此将图像配准函数映射关系转化为如何确定多项式的系数,最终转化为如何确定配准控制点(RCP)。
图像配准方法
根据如何确定RCP的方法和图像配准中利用的图像信息区别可将图像配准方法分为三个主要类别:基于灰度信息法、变换域法和基于特征法,其中基于特征法又可以根据所用的特征属性的不同而细分为若干类别。以下将根据这一分类原则来讨论已经报道的各种图像配准方法和原理。
配准的变换模型
图像之间的空间变换关系可以通过空间变换模型来进行表示,而空间变换模型又可以采用空间几何变换函数进行描述。图像之间的空间变换大致可以分为全局变换和局部变换。所谓全局变换,是指两幅图像上的所有像素点满足相同的变换关系,即两幅图像中的观测目标存在整体的运动关系。对于存在全局变换的两幅或多幅图像,它们之间的变换关系明确,可以采用统一的变换函数进行表示。全局变换是物体之间最基本也是最常见的变换,如物体的平移、旋转和缩放等。所谓局部变换,是指两幅图像上的像素点不存在相同的变换关系,即观测目标之间只存在局部的运动关系。在局部运动情况下,使用任一个函数均不能将两幅图像之间的关系准确表示。因此,需要采用多个不同的函数来表示两幅图像中不同部分的空间变换关系。局部变换是物体多个局部的全局变换复合而成,如人体或动物的动作所产生的局部运动等。常见的空间变换关系主要有刚体变换、相似变换、仿射变换、投影变换及非线性变换等。
尺度空间
图像尺度空间是在图像处理模型中引入连续变化的尺度参数对图像进行处理,获得一系列的子图像,并从这些子图像的信息中获取图像的本质特性。在传统的不变尺度图像处理技术的基础上,采用尺度连续变化的多尺度分析技术,通过所建立的尺度空间能够更加准确的获取所需要的图像特征。因而,多尺度分析技术在图像分析、识别和理解等领域有着重要的应用前景和实际价值。
经过高斯变换得到的尺度空间称为高斯尺度空间,高斯尺度空间的概念是由Witkin最早提出的,并经Koenderink等人的研究工作得到进一步的发展。Koenderink证明了高斯核函数是线性核函数,而Lindeberg又证明了高斯核函数是唯一的线性核函数。
如前所述,图像的特征检测与图像的尺度有着密切的关系。对于特定的图像特征,是在特定的尺度范围上表现出来的,即在某个尺度范围上检测到的特征,在另外的尺度范围上却无法检测到。因此,在对图像进行特征检测时,有必要引入图像的尺度空间表示,通过图像的尺度空间表示来检测图像特征。图像的尺度空间表示可以有效地检测到所需要的图像特征,进而获取图像的本质内容。采用多尺度分析的方法对图像进行尺度空间表示获得了广泛的应用,像常见的金字塔分析方法、小波分析方法和四叉树分析方法等都属于多尺度分析范畴。对输入的图像采用多尺度分析,也就是对输入图像附加了可变的尺度参数,形成一系列的子图像即图像尺度空间表示。
由图像尺度空间知,大尺度情况下能够很好的消除误检,但是特征的定位精度不高;小尺度情况下能够准确地进行特征定位,但是误检的风险明显变大。因此,可以先在大尺度情况下对特征进行检测,再在小尺度情况下对特征进行定位。通过图像的多尺度分析方法可以更加有效地对图像特征进行检测,得到图像的多尺度信息,进而获取图像的本质内容。
图像的尺度选择以及微分比较函数:图像尺度空间是通过一簇不同分辨率的图像进行表示的,不同分辨率的图像是通过高斯核函数得到的。通过在不同尺度上采用微分等适当的函数处理,可以在不同的分辨率上对边缘、角点等图像特征进行表示。在一般情况下,空间微分的幅度会随着尺度增加而减小。然而,在尺度不变模式下,总希望幅值在尺度变化下保持不变。因此,为了保持尺度不变性,微分函数必须对观测尺度进行归一化处理。
下面给出一些常用的微分比较函数,它们都已经进行了尺度归一化:
什么是尺度空间
我们精确表示的物体都是通过一定的尺度反应的,现实世界的物体也总是通过不同尺度的观察而得到不同的变化。尺度空间理论早在1962年提出,主要思想是通过对原始图像进行尺度变换,获得图像多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取等。尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。尺度越大图像越模糊。
基于特征的图像配准通用流程:
图像配准流程图:
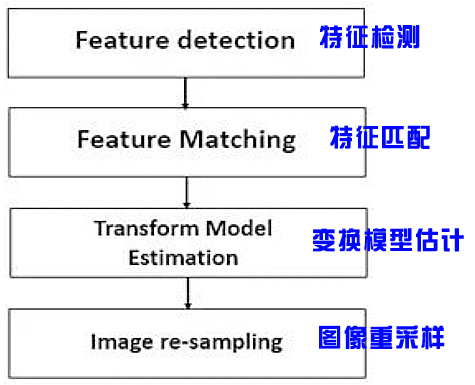
1.Feature detection: 特征检测
特征检测是图像配准过程的一项重要任务。根据问题的复杂性,通常分为手动或自动检测,但通常优先选择自动特征检测。
封闭边界,边缘,轮廓,线交点,角点,以及它们的代表点如重心或线末端(统称为控制点)可以作为特征。由特殊对象组成的这些特征必须易于检测,即特征将是物理上可解释和可识别的。
参考图像必须与浮动图像共享足够多的共同特征集合,而不受到任何未知遮挡或意外改变的影响。用于检测的算法应该足够稳健,以便能够在场景的所有投影中检测相同的特征而不受任何特定图像变形或退化的影响。
2.Feature matching: 特征匹配
该步骤基本建立在对待配准图像与在参考图像中检测到的特征之间的对应关系上。
除了特征之间的空间关系之外,还采用不同的特征描述符( feature descriptor)和相似性度量来确定配准的准确性。
必须合理地配置特征描述符,使得它们在任何退化时仍保持不变,与此同时,它们需要不受噪声影响且能适当区分不同的特征。
3.Transform model estimation: 图像变换模型的评估
为配准浮动图像与参考图像,需要估计映射函数的参数。使用从前一步骤获得的对应特征来计算这些参数。
映射函数的选择,取决于图像采集过程和预期图像变形的先验知识。在没有任何先验信息的情况下,必须确保模型的灵活性。
4.Image transformation/re-sampling: 图像变换
对浮动图像使用映射进行图像变换来配准。
图像特征的检测与描述
图像特征的分辨需要经过图像特征的检测和描述两个步骤。图像特征检测是在图像上对特征进行区分,图像特征描述则是对特征进行表达。
图像检测:有些算子将图像特征的检测和描述合二为一,即算子的前半部分是检测,算子的后半部分是描述,如SIFT算子及其变种。图像特征检测根据检测的特征类型可以分为基于特征点、基于blob块和基于区域的特征检测。图像特征检测一个重要的起点是Moravec所提出的角点概念,他于1981年提出了采用Moravec角点进行视频匹配;Harris和Stephens于1988年提出Harris算子,改善了Moravec算子对小的图像变化和边缘保持的有效性;针对Harris算子对尺度敏感问题,Kristian和Lowe分别提出Harris-Laplacian算子和SIFT算子;Matas等在2002年提出最大稳定极值区域(Maximally StableExtremal Regions,MSER)的仿射不变区域检测方法;Mikolajczyk和Schmid在2004年将Harris角点检测子结合尺度空间理论并构造仿射区域,得到具有尺度不变性的Harris-Affine检测子和仿射不变性的Hessian-Affine检测子;Tuytelaars于2004 年提出利用图像边缘和利用灰度检测仿射区域的基于边界区域(Edge-based Regions,EBR)检测子和基于强度区域(Intensity-based Regions,IBR)检测子;受信息论的的启发,Kadir和Brady于2004年提出寻找显著性特征的显著性区域(Salient Regions,SR)检测子。
图像描述:特征描述是对检测到的特征进行表达,是进行特征匹配的准备工作。图像特征描述的方法大体上可以分为三类:基于邻域分布的特征描述方法、基于滤波器的特征描述方法和基于不变矩的特征描述方法。
误差评价标准
图像配准的评价是一个较为复杂的问题,其原因是没有统一的标准,不同的图像类型可能需要不同的方法进行评价。对于不同视角下的同一场景的配准,评价的准则就是重复率、不变性和特征点的数目。在分类识别应用中,对重复率的定义和测量较为困难,只能通过对微小变化的鲁棒性进行度量。图像配准的误差源于图像特征检测时的定位误差、图像匹配时的匹配误差和图像变换时的变换误差,其中影响最大的是特征检测时的定位误差,该误差将对后续的匹配精度和变换精度产生直接的影响。因此,本文在评价算法性能时,采用了Cordelia Schmid的重复率(Repeatability)作为算法误差的衡量标准。对于同一场景在不同的拍摄情况下获得的多幅图像,重复率明确表示在这些图像上所检测到的兴趣点的几何稳定性。对于其中的两幅图像,重复率是在这两幅图像均出现的特征点占所有特征点的比例。
图像配准准离岸评估标准
单模图像配准常使用 相关性(Correlation Coefficient, CC)来衡量效果;而多模图像配准常使用 互信息(Mutual Information, MI)衡量。
1. 相关性
相关性本质上是一种相似性度量,它可以了解浮动图像和参考图像的相似程度。如果两个图像完全相同,则相关性等于1;而如果两个图像完全不相关,则相关性值等于0;若相关性值等于-1,表示图像完全反相关,这意味着一个图像是另一个的负面。通过使用相关性作为评价标准,单模态配准可获得满意的结果。
对于同一物体由于图像获取条件的差异或物体自身发生的小的改变而产生的图像序列,采用使图像间相似性最大化的原理实现图像间的配准,即通过优化两幅图像间相似性准则来估计变换参数,,主要是刚体的平移和旋转。相关性主要限于单模图像配准,特别是对一系列图像进行比较,从中发现由疾病引起的微小改变。
它表示为:
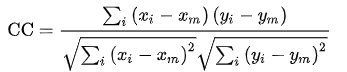
x_i , y_i 分别为浮动图像和参考图像第 i 个像素的强度;
x_m , y_m 为 浮动图像和参考图像的平均强度。
2. 互信息
互信息是确定两个图像中相应体素的图像强度之间相似度的另一个度量。当两个图像准确对齐时,互信息最大化。互信息的值是非负且对称。其范围从零开始,可以变化到高值。高互信息值表示不确定性的大幅降低,而零互信息值清楚地表明这两个变量是独立的。
由于该方法不需要对两种成像模式中图像强度间关系的性质作任何假设,也不需要对图像作分割或任何预处理,所以被广泛地用于CT/MR、PET/MR等多种配准工作。最大互信息法几乎可以用在任何不同模式图像的配准,特别是当其中一个图像的数据部分缺损时也能得到很好的配准效果。
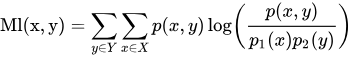
p(x, y) 为 联合分布函数;p_1(x) , p_2(y) 为边际分布函数。
也常使用图像分割领域的DICE loss5,熵相关系数(Entropy Corrleation Coefficient,ECC)等指标进行评估。
利用OpenCV进行图像配准
我们用网上已有的最基础的代码进行最简单的配准体验,需要使用opencv库以及imutils库,具体代码与实验结果如下:
import numpy as np
import imutils
import cv2
# 读取图像,并灰度化
img_align = cv2.imread("../dataset/Registration/image-1.jpg")
img_temp = cv2.imread("../dataset/Registration/image.jpg")
img1 = cv2.cvtColor(img_align, cv2.COLOR_RGB2GRAY)
img2 = cv2.cvtColor(img_temp, cv2.COLOR_RGB2GRAY)
height, width = img2.shape
# 获取关键点和描述符,用于匹配模板文件
# ORB_create设置的数值越大,关键点的数量就越多
k = 1000
orb_detector = cv2.ORB_create(k)
kp1, d1 = orb_detector.detectAndCompute(img1, None)
kp2, d2 = orb_detector.detectAndCompute(img2, None)
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = matcher.match(d1, d2)
# matches.sorted(key = lambda x: x.distance)
matches = matches[:int(len(matches) * 0.9)]
no_of_matches = len(matches)
p1 = np.zeros((no_of_matches, 2))
p2 = np.zeros((no_of_matches, 2))
for i in range(len(matches)):
p1[i, :] = kp1[matches[i].queryIdx].pt
p2[i, :] = kp2[matches[i].trainIdx].pt
# 为结果图像的验证创建单应性
homography, mask = cv2.findHomography(p1, p2, cv2.RANSAC)
# 配准图像
transformed_img = cv2.warpPerspective(img_align, homography, (width, height))
matchedVis = cv2.drawMatches(img1, kp1, img2, kp2, matches, None)
matchedVis = imutils.resize(matchedVis, width=1000)
cv2.imwrite('../dataset/Registration/result{}.jpeg'.format(k), matchedVis)
cv2.waitKey(0)基于卷积神经网络特征的图像匹配
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,在图像处理领域得到了广泛的应用。图像匹配是指在一幅图像库中,找到与输入图像最相似的图像。基于CNN特征的图像匹配方法,是利用卷积神经网络提取图像特征,再利用这些特征进行图像匹配。这种方法比传统的手工设计特征的方法更加准确、鲁棒性更高。
基于CNN特征的图像匹配的研究步骤:
- 数据准备:准备训练集和测试集。训练集应包含多个类别的图像,并且每个类别包含多张图像。测试集应包含需要进行匹配的图像和对应的标签。
- CNN特征提取:使用预训练好的CNN模型(如VGG、ResNet等)提取每张图像的特征向量。可以使用CNN模型的卷积层或全连接层的输出作为特征向量,也可以使用池化层的输出。通常,使用最后一层卷积层的输出作为特征向量效果较好。
- 特征匹配:将特征向量输入到匹配算法中,进行特征匹配。常用的匹配算法有欧几里得距离、余弦距离等。在匹配时,可以选择最近邻匹配(Nearest Neighbor,NN)或基于特征向量的查找方法。
- 评估性能:使用评价指标(如准确率、召回率、F1-score等)评估图像匹配的性能。
基于CNN特征的图像匹配方法在图像搜索、人脸识别、图像检索等领域得到了广泛的应用。由于卷积神经网络能够自动学习特征,相较于传统方法,基于CNN特征的图像匹配方法更加精确、鲁棒性更高。
基于FCN和互信息的图像配准技术
针对传统配准方法在进行三维多模态图像配准时存在收敛速度较慢、容易陷入极值等问题,提出一种基于全卷积神经网络(Fully Convolutional Networks,FCN)和互信息的配准方法。利用FCN模型提取二维图像深层特征并进行粗配准;将得到的配准结果作为互信息算法的初始搜索点,从而使搜索范围缩小至全局最优解附近;利用互信息算法对参数进一步微调优化,得到最优三维配准结果。实验结果表明,在进行CT-MR图像配准时,所提方法不仅可以大幅度提升配准速度,还能有效避免局部收敛的情况,具有更高的准确性。
互信息是最常见的基于灰度配准方法之一。在互信息图像配准中,使用较多的优化算法如下图所示。

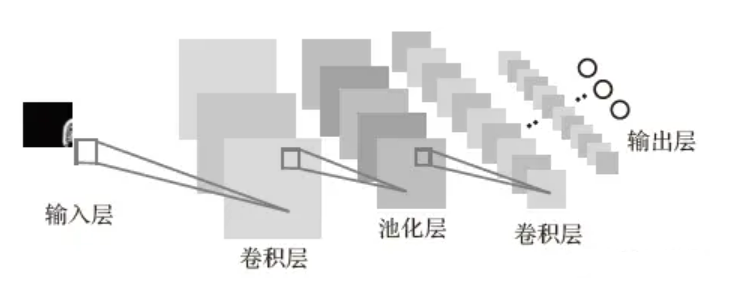
全卷积神经网络(FCN)
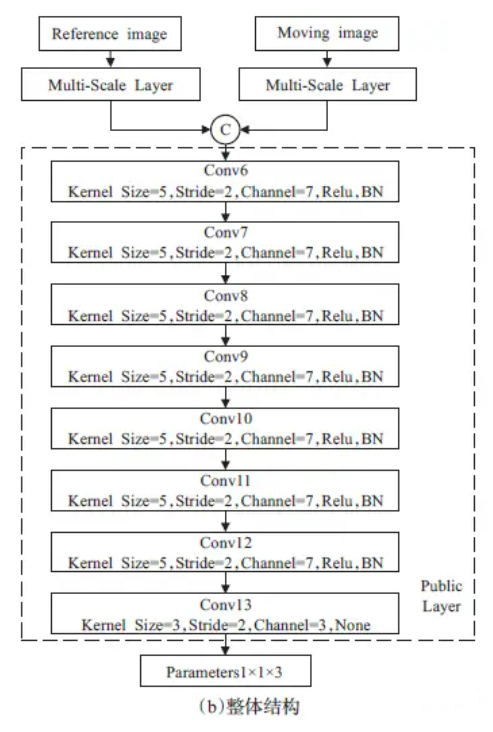
全卷积神经网络(Fully ConvolutionalNetworks,FCN)。FCN 是在CNN 上的发展和延伸,两者最大的区别是FCN 将卷积层替代了全连接层(如图1 所示),正是这种差异,使得FCN能够避免全连接层线性变换导致图像空间位置信息丢失,进一步丰富特征的学习。同时,由于卷积层权值共享的特性,FCN有效减少了网络训练参数的数目,能够提升模型训练的速度,FCN的网络结构如下图所示。
FCN模型的构建
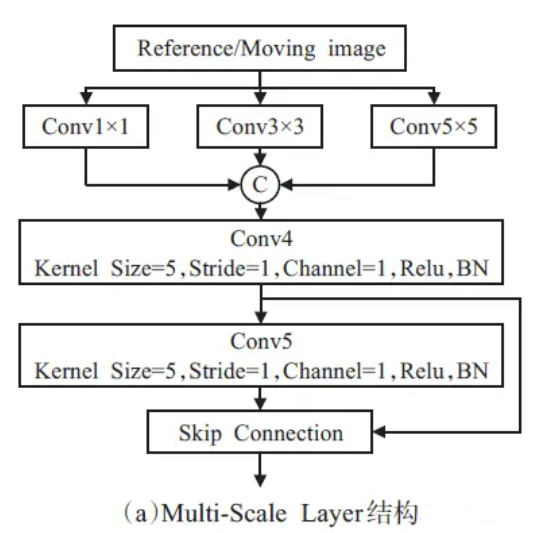
整个模型由两部分组成,即参考图像和浮动图像各自的多尺度特征提取器Multi-Scale Layer(下图的a部分),以及通过Concatenate 级联合并(图中为字母C表示)后的公共特征提取器Public Layer。
算法流程
文章采用FCN和互信息的混合优化算法实现三维图像配准任务。利用FCN获得的配准结果作为互信息搜索算法的起始点,通过进一步搜索优化得到更高精度的配准参数,整个配准流程如下图所示。
实验结果评估标准
相似性系数(DSC)
相似性系数用于度量实际配准结果与理论配准结果的重合度,公式如下图所示。
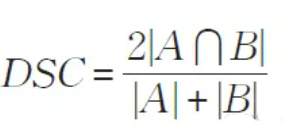
A和B分别表示通过本文方法配准后的浮动图像以及通过标签参数配准后的浮动图像。
相关系数(CC)
相关系数数学计算公式如下图所示:
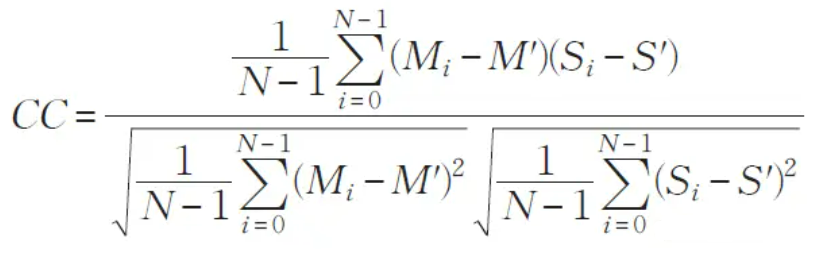
其中,N 代表图像中像素点的个数,Mi表示浮动图像的灰度值,Si 表示参考图像的灰度值,M'、S'分别表示浮动图像和参考图像的平均灰度值。相似性系数(DSC)、互信息(MI) 以及相关系数(CC)指标都是值越高代表配准效果越好。
互信息
互信息(Mutual Information)是衡量随机变量之间相互依赖程度的度量。假设存在一个随机变量X和另一个随机变量Y,那么它们的互信息如下图所示。
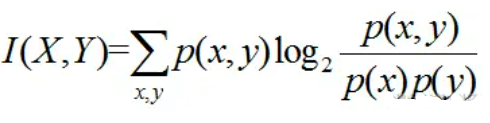
配准时间
即算法运行的时间。
参考资料:
如何完成图像处理经典难题之图像配准?快来get这篇图像配准综述 (qq.com)
【整理】图像配准( Image Registrition )相关知识_117瓶果粒橙的博客-CSDN博客
【计算机视觉】图像配准(Image Registration) - 小金乌会发光-Z&M - 博客园 (cnblogs.com)
基于卷积神经网络特征的图像匹配研究-掘金 (juejin.cn)
基于FCN和互信息的医学图像配准技术研究(学习笔记) - 掘金 (juejin.cn)
图像配准(Image Registration)简介-CSDN博客
【整理】图像配准( Image Registrition )相关知识-CSDN博客
机器视觉(九):图像配准_liutangplease的博客-CSDN博客
【图像配准】基于灰度的模板匹配算法(一):MAD、SAD、SSD、MSD、NCC、SSDA、SATD算法_灰度匹配-CSDN博客
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号