LoRA: 大模型快速训练的秘诀


本文是四两拨千斤,训练大模型的PEFT方法的最后一小节,感兴趣读者可以阅读完整版。
LoRA
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 核心思路是对模型参数做低秩分解,仅训练分解后的参数,模型部署也需额外保存低秩参数,计算时加上低秩参数部分。
LoRA的提出在上述PEFT方法之后,来自微软的研究者认为,现有的Adapter Tuning和Prefix Tuning这两种方法均有缺点:
- Adapter Layers Introduce Inference Latency: 虽然Adapter后续又有很多变种,但无论如何额外添加的Adapter层都会拖慢推理速度
- Directly Optimizing the Prompt is Hard: 应用Prefix-Finetuning时,直接优化prompt非常困难,而且其效果也不是随着训练参数的增加而单调递增
Aghajanyan等研究者在论文Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning提出了关于大模型的一个核心观察点:预训练模型存在一个低秩的“内在维度”(intrinsic dimension)使得其在被随机映射到一个更小的子空间时仍然可以高效学习。基于这种想法,作者假设预训练模型在转换到下游模型过程中也有一个内在维度,提出了下面的方法。
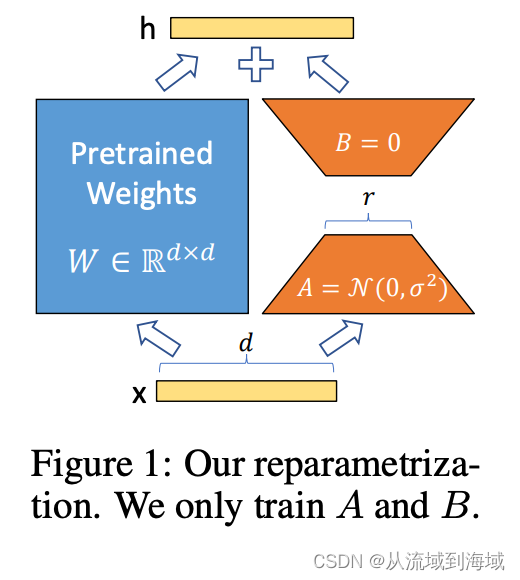
图中的A,B均为可训练参数,参数A=正态分布,B=0是初始化参数的方法
对于预训练模型权重
,引入一个低秩部分
来限制其更新,即:
,其中
,
,但秩
,训练时
被冻结不参与梯度更新,仅有
和
为可训练参数,修改后的前向传播可表示为:
这意味着增加的部分
和原始部分可以并行计算,没有引入任何推理时延。
总结下来,LoRA拥有以下优点:
- A Generalization of Full Fine-tuning LoRA是一个更通用的finetuning方法,可以仅训练预训练模型参数的一小部分,它不需要在模型适配过程中累积梯度来更新全秩参数。这意味着当应用在全部权重矩阵和偏差项上应用LoRA更新时,通过设置LoRA的秩
为预训练权重的秩,基本能够还原全量finetuning同等水平的表征能力。换句话讲,随着我们增大
增加可训练参数的数量,使用LoRA方式训练基本可以收敛到训练原始模型。与之形成对比的是,采用adapter的一系列方法仅能收敛到MLP,而基于prefix的方法不能不处理长输入序列。
- No Additional Inference Latency 可以按照
来存储和执行推理,迁移到其他任务时,可以减去
,再加上新任务的
,仅需一个占用少量存储的快捷操作即可迁移到新任务。这保证了和采用构建的finetuning方法相比,单任务及多任务都没有引入额外的推理时延。
作者通过实践发现,LoRA实际产生的最大的益处是节省内存和存储消耗,通过设置
能够将一个使用Adam训练的大型transformer的VRAM(即显存)占用最大减少
。具体而言,在GPT-3 175B上,VRAM消耗从1.2TB降低到350GB,在仅采用query和value矩阵映射矩阵的条件下,检查点的大小被降低了10000倍(从350GB到35MB)。假设我们需要100个转化模型,使用LoRA仅需保存
大小的空间,而全量Finetuning则需要
的存储空间。这使得训练需要的GPU数量变少且减少了I/O瓶颈的次数,并且在任务间切换时,仅需在VRAM实时切换LoRA权重而不需要花费大量时间切换全量参数。除此之外,由于不需要计算大多数参数的梯度,训练速度也提升了25%。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-07-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号