关联式容器set和map


一.容器
在C++中容器大致可以分为两种,分别是:序列式容器和关联式容器。
序列式容器:vector,list,deque,forward_lsit都是序列式容器,因为它们的底层都是线性序列的数据结构,存放的是元素本身。
关联式容器:虽然也是用来存储数据的,但是关联式容器中存放的并不是元素本身,而是<key,value>这样的键值对,这样的容器在数据检索的时候效率会更高(插入删除不需要挪动数据,只需要更改指针指向,结构平衡时查找效率为logN)。
关联式容器也有两类,一类是map,multimap和set,multiset这种底层为红黑树的容器,另一类是哈希结构。
二.set的介绍

set的底层是一棵搜索二叉树,搜索二叉树在构建的时候会自动排序,并且不能插入大小相同的值,如果你往树中插入大小相同的值,它会自动给你去重,所以set其实是去重+排序

set有一个模板参数T和一个仿函数以及空间配置器(STL中的容器为了减少扩容时的效率损失都是从内存池中开空间的),表面上set只有一个参数T,但其实set内部存放的是<value,value>这样的键值对
set的大部分成员函数和STL中其他的容器类似,所以就不一一介绍,这里只介绍具有set特性的成员函数
1.insert

第一个插入函数插入的参数是一个value_type的类型,其实这个类型是一个pair被typedef以后的名字

此外观察pair的参数,可以看到set中的key是不可以被修改的,而value是可以修改的。
第二个插入函数实在某个位置插入一个节点,但是这个接口要慎用,因为有可能会破坏到树的结构。
关于pair

pair是一个struct的模板类,里面有两个成员,通常我们将first认为是key而second认为是value,但它们的类型具体是什么则由我们自己决定,,一般我们将pair称之为键值对,SGI-STL种对键值定义如下
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};以前我们定义搜索树时我们的KV结构是由两个变量来代表,map这里使用pair存储就是将两个变量替换成了一个pair模板类,这比使用两个变量来实现的KV结构可以解决更多的问题
2.lower_bound&&upper_bound
lower_bound返回大于等于目标值的迭代器,upper_bound返回大于目标值的迭代器,在set中用于返回目标值的迭代器。(可以将获取到的两个迭代器作为一个迭代器区间用于删除或插入)
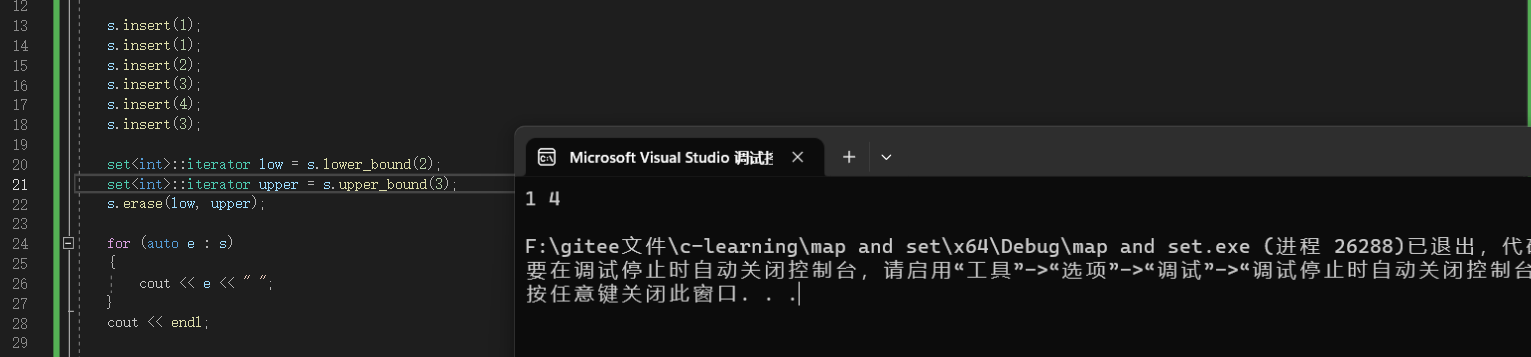
可以看到这个erase将2和3都给删掉了,可以理解为删除的是一个这样的区间:[2,3]
3.find和count
find
find采用的是中序遍历的查找方式,如果找到了就返回这个节点的迭代器,如果没找到就返回set::end;
count
给定一个值,该函数能帮你统计该树种拥有该值的节点有多少个。或许有人会说:set是排序+去重,一个值肯定就一个,这个接口函数是不是没有意义?
其实该函数并不是为了set而创建的,而是为了multiset才创建的。
三. multiset
multiset与set的不同就在于multiset允许键值冗余(可以存在相同的值),因此它只是简单的排序
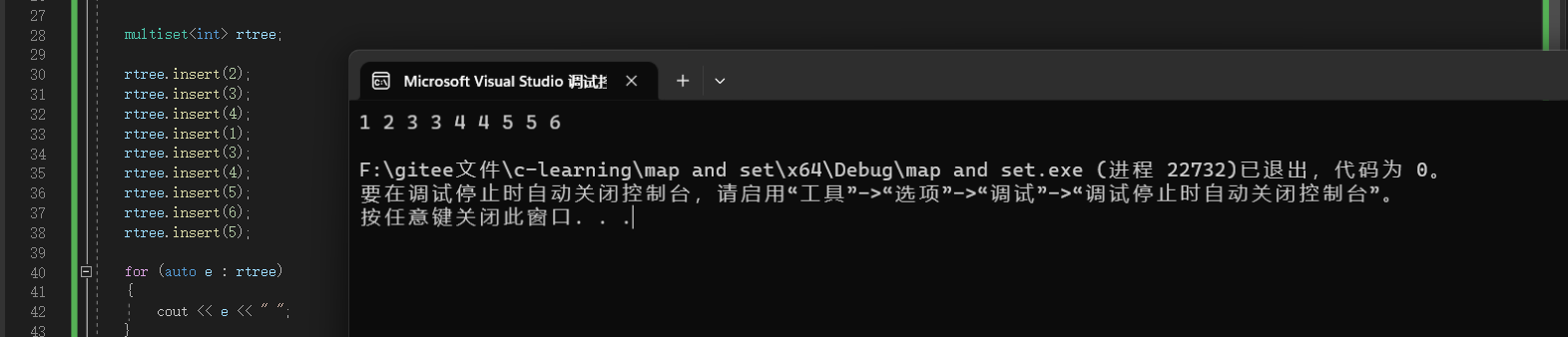
但是因为multiset中会存在相同的值,所以有些接口在set中显得有些鸡肋,但在multiset种却刚刚好,比如count:

count可以统计multiset中某个值出现的次数
此外因为mulitset中允许键值冗余,所以它的find函数找到的是中序遍历中第一次出现的结果

四.map
map是一个平衡搜索二叉树,是KV模型,set虽然也是KV模型,但其实存放的是一个<value,value>的键值对,而map存放的是则是真正的<key,value>键值对
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string, string>dict;
dict.insert(pair<string, string>("一", "one"));
dict.insert(pair<string, string>("二", "two"));//这里在调用pair的构造函数
dict.insert(pair<string, string>("单词", "world"));
dict.insert(make_pair("书", "book"));//这里和上面三个是等价的写法
return 0;
}这里为了简化,使用一个
make_pair函数
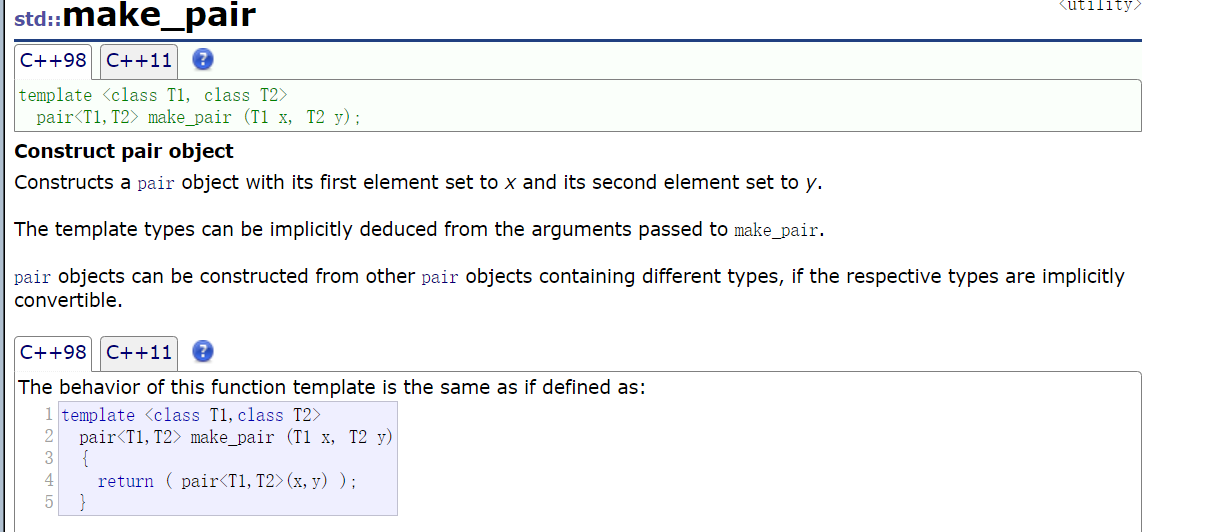
make_pair其实也是在调用pair的构造函数,但它的好处就是它是一个函数模板,可以自动推演,不用我们显示去声明类型。
大部分情况插入键值都是使用make_pair
map的迭代器和list的十分类似,都是通过在类中内嵌一个指针来实现的,所以这里在访问map中的元素时还可以使用->的访问方式(和list类似,这里其实调用了两次->,但是编译器优化成了一个)

最特别的operator[]

表面上看起来平平无奇,接下来我们结合使用来感受它的魅力:
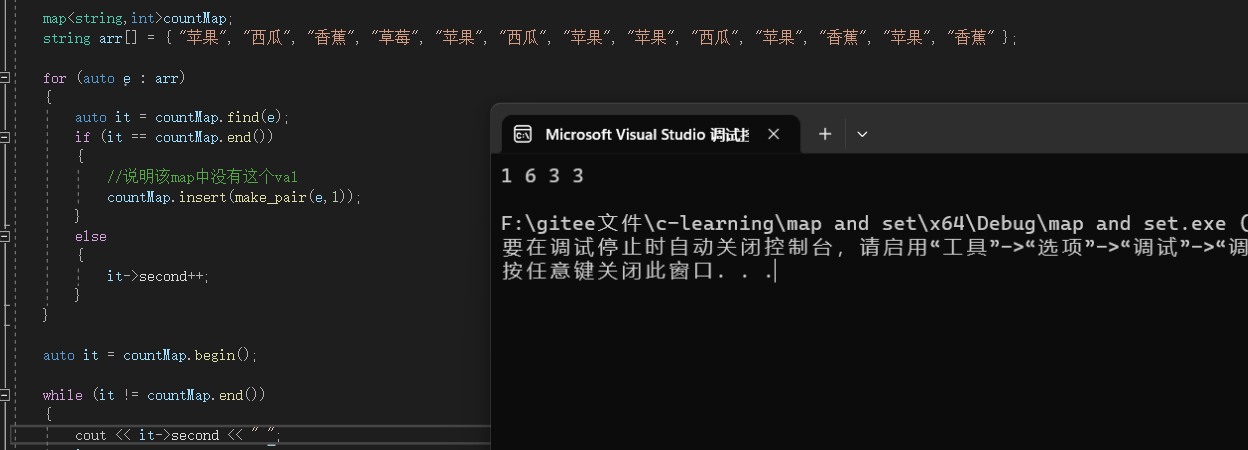
这个就是统计数组中各个元素出现的次数,这种平平无奇的解法相比就没什么需要解释的
除了上面那种老实人解法,如果你灵活使用operator[],可以将上述代码简化

首先来看一下文档中对该函数的说明
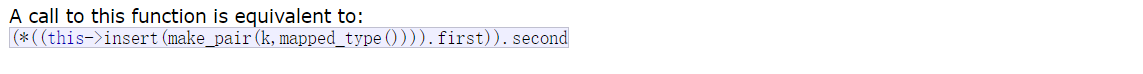
其实operator[]调用的还是insert,所以要把这个理解了,首先要理解insert
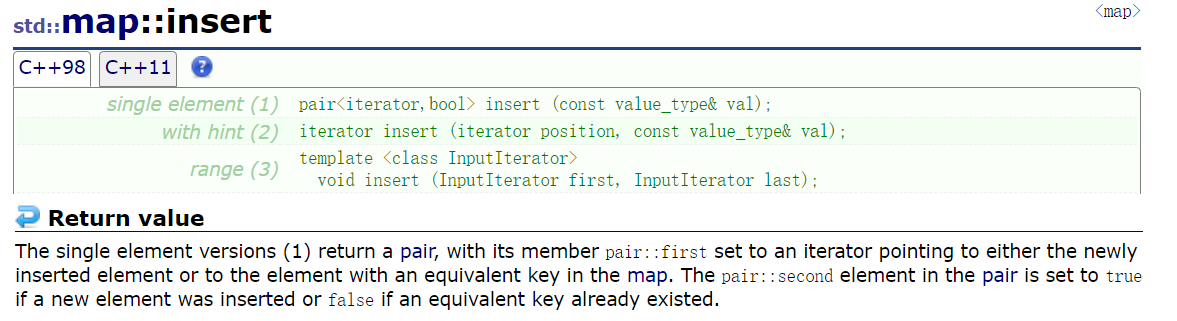
在之前的搜索树和set中因为不允许键值冗余所以插入的返回值就是一个bool值,这里却给了一个迭代器,文档中对返回值这样说:如果不存在这个元素,那么返回的迭代器是新插入的元素的迭代器,second是true,如果该元素已经存在,那么就返回该元素的迭代器,second被设置为false。也就是说,insert还可以充当find来使用;
而operator[]只给了一个key,但是如果map中没有该元素则要求我们插入,那么插入的时候value就会插入类型的匿名对象(如果类型是int,那么匿名对象就是0,指针就是空指针,string就是空串);
对operator[]的整体理解📕:
Value& operator[] (const Key& k)
{
pair<iterator,bool> ret=insert(make_pair(k,Value() ) );
return ret.first->second;
//如果该值存在,返回pair中的first,如果不存在,先插入在返回first;然后再去取pair的second,因为返回的是别名,所以可以修改
}所以countMap[e]++;大致分为这几步:
1.调用insert,如果该值已经存在,插入失败并返回该节点的迭代器,不存在就插入在返回迭代器
2.根据迭代器获取pair的first,再由first获取到second
3.因为operator[]只给了key,因此value(ret.first->second;)给的是默认值,如果该值不存在,则second是0;最后再对second做++操作
也就是说operator[]兼具三重功能:1.插入 2.查找 3.修改at的功能和[]一样,区别在于用at找不到key将不会发生插入新节点,而是抛出异常。
此后你在面临插入元素时有了更多的写法:

四.multimap,因为允许键值冗余,所以它没有operator[],它的find返回的是中序遍历第一次遇到的节点
五.两个练习题
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2 输出: [“i”, “love”] 解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。 注意,按字母顺序 “i” 在 “love” 之前。
解题思路
该题使用map这类KV模型作为存储容器是最好不过了;只是有一点要注意:题目要求如果次数相同就要按字母字典序排列,所以该题不能使用sort(除非定义仿函数重置比较规则0,因为sort底层使用的是快速排序来实现的,而快速排序是一种不稳定的排序;
这里选用使用仿函数重置比较规则以后使用sort的解法
struct Compare
{
bool operator()(const pair<int,string>& a,const pair<int,string>& b)
{
return a.first>b.first || (a.first==b.first&&a.second<b.second);
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
vector<string> word;
map<string,int> countMap;
for(const auto& str : words)
{
countMap[str]++;
}
vector<pair<int,string>> v;
for(auto& kv : countMap)
{
v.push_back(make_pair(kv.second,kv.first));//dataMap的first是string,second是int
}
sort(v.begin(),v.end(),Compare());
for(int i=0;i<k;++i)
{
word.push_back(v[i].second);
}
return word;
}
};给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]解题思路
输出结果要求每个元素都是唯一的,但是给定的两个数组中有可能出现重复的值,所以可以先使用set做容器存放给定的两个nums数组,不但能排序还可以去重,最后再遍历数组找相同。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(),nums1.end());//nums1排序+去重
set<int> s2(nums2.begin(),nums2.end());//nums2排序+去重
vector<int> ret;
for(auto& e : s1)
{
if(s2.find(e)!=s2.end())//在s2中查找s1的元素
{
ret.push_back(e);
}
}
return ret;
}
};当然你也可以先将数组去重+排序,然后使用双指针求解
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号