YOLOv8改进:基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显 | CVPR 2023 BiFormer
原创
YOLOv8改进:基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显 | CVPR 2023 BiFormer
原创
AI小怪兽
发布于 2023-10-21 10:39:53
发布于 2023-10-21 10:39:53
1.BiFormer介绍

论文:https://arxiv.org/pdf/2303.08810.pdf
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
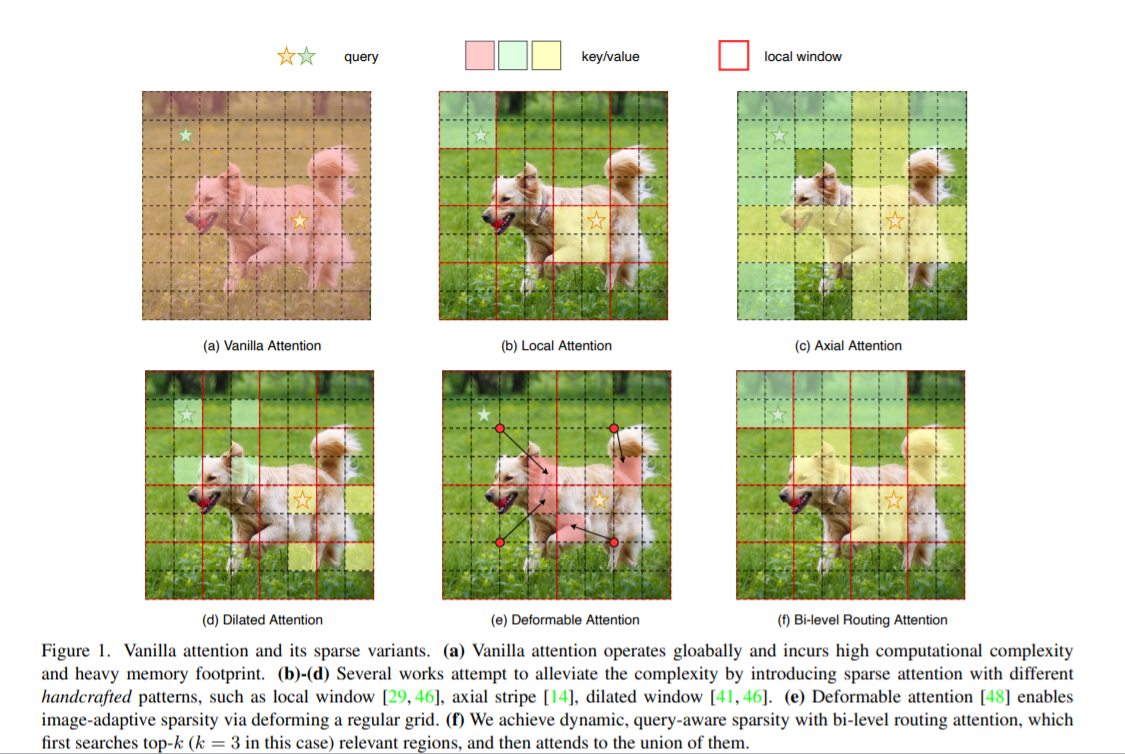
其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。
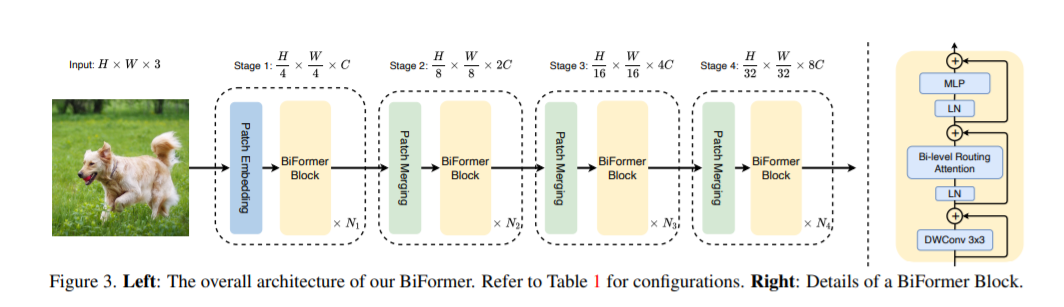
基于BRA模块,本文构建了一种新颖的通用视觉转换器BiFormer。如上图所示,其遵循大多数的vision transformer架构设计,也是采用四级金字塔结构,即下采样32倍。
具体来说,BiFormer在第一阶段使用重叠块嵌入,在第二到第四阶段使用块合并模块来降低输入空间分辨率,同时增加通道数,然后是采用连续的BiFormer块做特征变换。需要注意的是,在每个块的开始均是使用 的深度卷积来隐式编码相对位置信息。随后依次应用BRA模块和扩展率为 的 2 层 多层感知机(Multi-Layer Perceptron, MLP)模块,分别用于交叉位置关系建模和每个位置嵌

本文方法对小目标检测效果比较好。可能是因为BRA模块是基于稀疏采样而不是下采样,一来可以保留细粒度的细节信息,二来同样可以达到节省计算量的目的。
理论参考知乎:CVPR'2023 即插即用系列! | BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构 - 知乎
2.基于Yolov8的BiFormer实现
2.1
C2f_BiLevelRoutingAttention、C3_BiLevelRoutingAttention、BiFormer加入modules.py中
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, num_heads=8, n_win=7, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel='ada_avgpool', kv_downsample_mode='identity',
topk=4, param_attention="qkv", param_routing=False, diff_routing=False, soft_routing=False,
side_dwconv=5,
auto_pad=True):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads == 0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv // 2,
groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
# assert self.kv_downsample_ratio is not None
# assert self.kv_downsample_kenel is not None
# TODO: fracpool
# 1. kernel size should be input size dependent
# 2. there is a random factor, need to avoid independent sampling for k and v
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
# TODO: need to consider the case where k != v so that need two downsample modules
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
# softmax for local attention
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad = auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
#print(N)
# print(H)
# print(W)
# print(self.n_win)
assert H % self.n_win == 0 and W % self.n_win == 0 #
###################################################
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
#################qkv projection###################
# q: (n, p^2, w, w, c_qk)
# kv: (n, p^2, w, w, c_qk+c_v)
# NOTE: separte kv if there were memory leak issue caused by gather
q, kv = self.qkv(x)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean(
[2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win,
i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
############ gather q dependent k/v #################
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)
# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)
######### do attention as normal ####################
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c',
m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
# param-free multihead attention
attn_weight = (
q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H // self.n_win, w=W // self.n_win)
out = out + lepe
# output linear
out = self.wo(out)
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return out原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号