人群判存服务是如何实现的
原创

人群判存服务也被称为判定服务,即判断用户是否在指定的人群中。判存服务在业务中的使用也比较广泛,比如运营人员在画像平台上圈选了“游戏高转化”人群,对于人群中的用户需要在客户端上显示游戏入口从而引导用户进入游戏宣传页并下载应用,该需求可以通过人群判存服务来实现。当用户进入到客户端指定页面后可以调用判存服务,传入当前用户UserID并判断是否在“游戏高转化”人群中,客户端根据返回结果控制是否展示游戏入口。
判存服务主要以微服务的形式提供给调用方使用,由于判存结果直接影响运营策略,所以必须保证判存服务的稳定性和可用性。实现判存服务的方案有多种,本节主要介绍3种常见的实现方式:Redis方案、BitMap方案以及适用范围比较小的基于规则的判存方案,下面以UserId人群为例详细介绍3种方案的实现逻辑。
Redis方案
Redis集群在分布式和高并发场景下性能表现优异,比较符合判存服务的使用场景。使用Redis方案的关键在于采用合理的数据结构存储数据,常见的Key和Value设计方式主要有两种。
- 方案一:将人群ID和UserId拼接为Key,Value直接使用string数据结构,数值设置为1,判存功能的实现只需判断某些Key是否存在。该方式实现逻辑简单,由于所有的Key在集群上均匀分布,其降低了出现热点数据的概率,而且Redis集群存储和计算压力比较均衡;该方式的缺点是Redis的Key数量是所有人群下用户量级的总和,需要消耗大量的存储空间。
- 方案二:UserId作为Key,通过hash结构存储UserId所在的所有人群ID。判存功能的实现需要判断UserId作为Key的hash数据中是否存在指定人群ID即可。该方式Redis集群中Key数目等同于全量用户数,不会随着人群数目的增多而增长,相对方案一可以节约大量存储空间;但是因为单个用户所在的人群列表汇总到了hash结构中,人群数据过期时不能使用Redis过期机制剔除数据,需要工程研发自行解决;业务中可能存在热点用户,这可能造成数据热点问题。
图5-46中展示了两种方案的数据示例以及判存实现逻辑,其中方案一主要使用Redis的exists函数实现判存,方案二主要使用hget函数获取数据并进行判存。
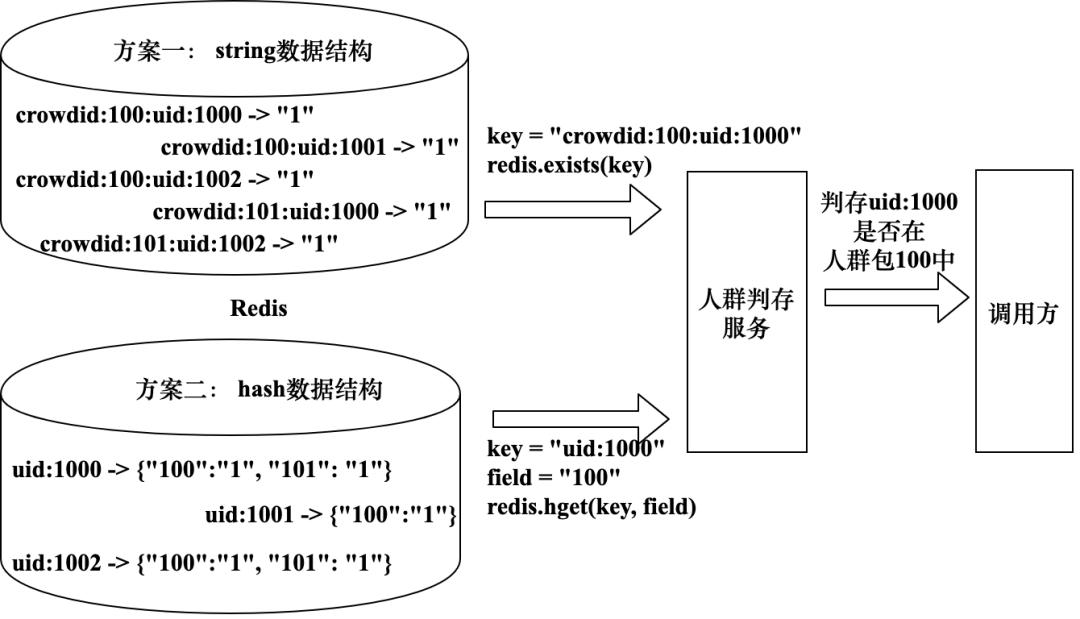
图5-46 通过Redis实现人群判存的两种方案实现逻辑
以方案二为例,如何将人群数据写入Redis支持判存?可以参考标签数据灌入缓存的方式,通过大数据组件或者自研代码的方式读取人群结果表中的数据后写入Redis中,即读取Hive表数据并遍历人群下的每一个UserId,借助Redis函数hset写入Redis集群,其流程如图5-47所示。
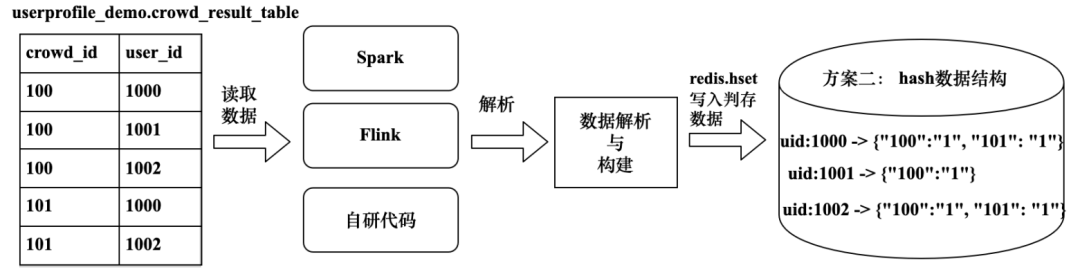
图5-47 人群Hive表数据写入Redis实现逻辑
当自动更新的人群用于判存业务时,判存数据也需要同步更新,判存数据更新的思路可以分为增量更新和全量更新。
图5-48展示了增量更新的实现逻辑。增量更新需要先计算出人群旧版本与新版本之间的数据差异,找出旧版本存在而新版本不存在的用户群1以及旧版本不存在但是新版本存在的用户群2。更新过程采用“先删后添”的思路,首先遍历用户群1中的用户并依次删除掉Redis中的数据;其次遍历用户群2并依次添加数据到Redis中,这一步完成后便实现了人群的增量更新。增量更新的优点是通过计算人群新旧版本的差异数据,降低了最终更新的数据量级;该方式的缺点是判存数据不够精确,因为在数据更新过程中新旧版本数据在某段时间内同时存在。如果业务对判存数据有很高的精确度要求,不适合采用增量更新的思路。
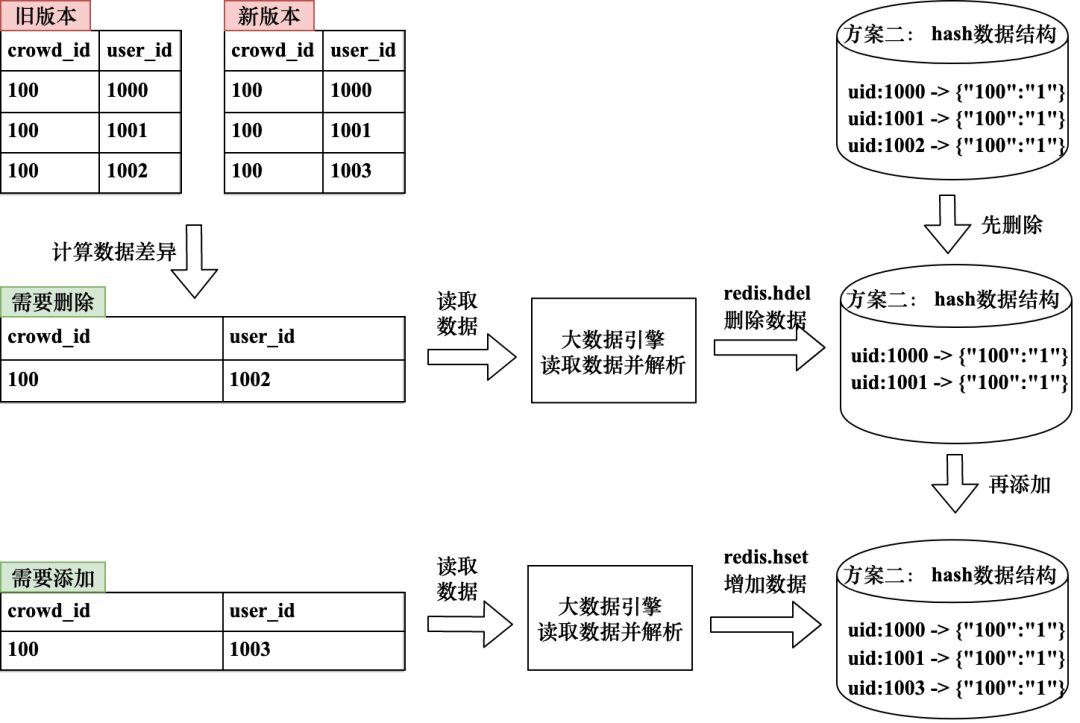
图5-48 判存数据增量更新实现逻辑
全量更新相比增量更新不再需要计算新旧版本人群数据差异,只需将新版人群当成完整人群再次写入到Redis中。为了区分出新旧版本的人群数据,需要在Redis中保存人群版本信息。以方案一为例,可以在所有的Key中添加人群ID版本信息,这样新版数据写入过程中对老版数据无任何影响;以方案二为例,可以在hash结构的field中添加人群版本信息,其写入过程中也不会影响老版数据的使用。当新版人群数据写入完成后,判存接口的实现中可以通过更改版本信息快速切换到新版数据。全量更新不存在新旧数据同时存在的情况,判存数据的精确度更高;其劣势也比较明显,新版人群数据在写入过程中会使用更多的存储和计算资源。图5-49展示了全量更新的实现逻辑。
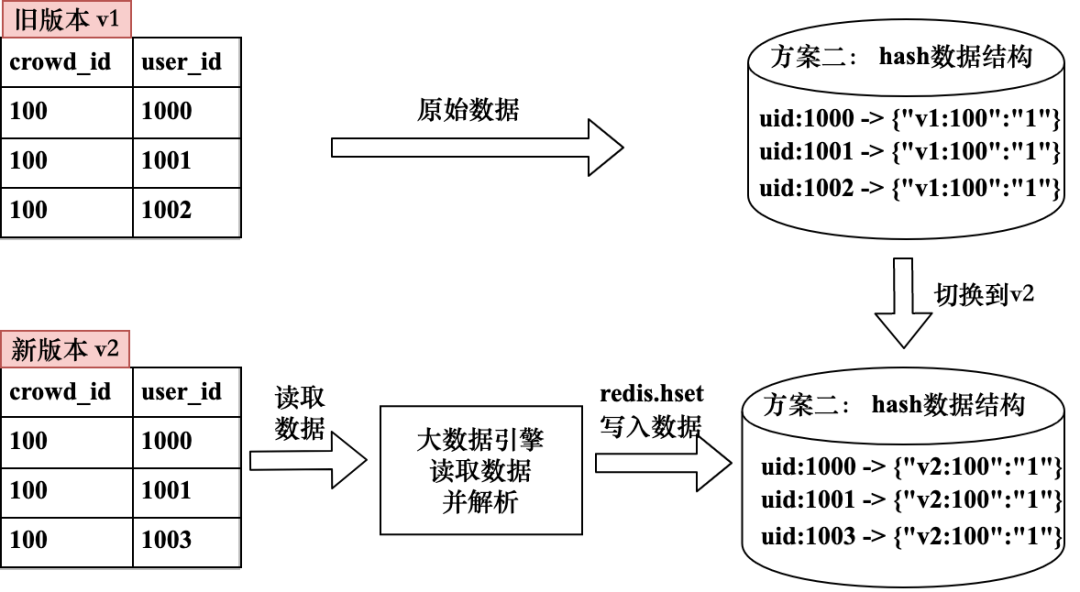
图5-49 判存数据全量更新实现逻辑
使用Redis实现人群判存可以支持各种ID类型的人群,不论是UserId人群还是DeviceId、IMEI人群,其实现方案一致。对于需要支持多种ID类型人群进行判存的业务,Redis是一个不错的选择方案。Redis在业界使用广泛且技术体系成熟,可以通过简单的扩容支持更大规模的判存需求。由于Redis实现人群判存主要基于各种string类型的Key和Value来实现,在存储资源上没有太大优化空间,其资源成本较大。
BitMap方案
Redis方案适用于各种ID类型的人群,如果画像平台只需要支持数字类型ID,比如UserId、手机号等,可以通过BitMap来实现人群判存功能,而且其性能和资源消耗远低于Redis方案。
以UserId人群为例,使用BitMap实现人群判存的思路比较简单。图5-50展示了基于BitMap实现判存的实现逻辑,首先在所有的服务机器中定时加载需要支持判存的人群BitMap到内存中;其次处理判存请求时只需要调用BitMap自带的contains函数判断指定UserId是否存在即可,函数返回true代表人群中包含该用户,返回false代表不包含。对于自动更新类人群,图中展示的BitMap定时加载器可以定时轮询并拉取人群数据,当人群数据有变动时直接更新内存中老版本的人群BitMap即可,相比Redis方案中人群更新效率更高;对于已经过期的人群也可以直接在内存中删除人群BitMap数据,相对Redis的数据过期处理更加简便。
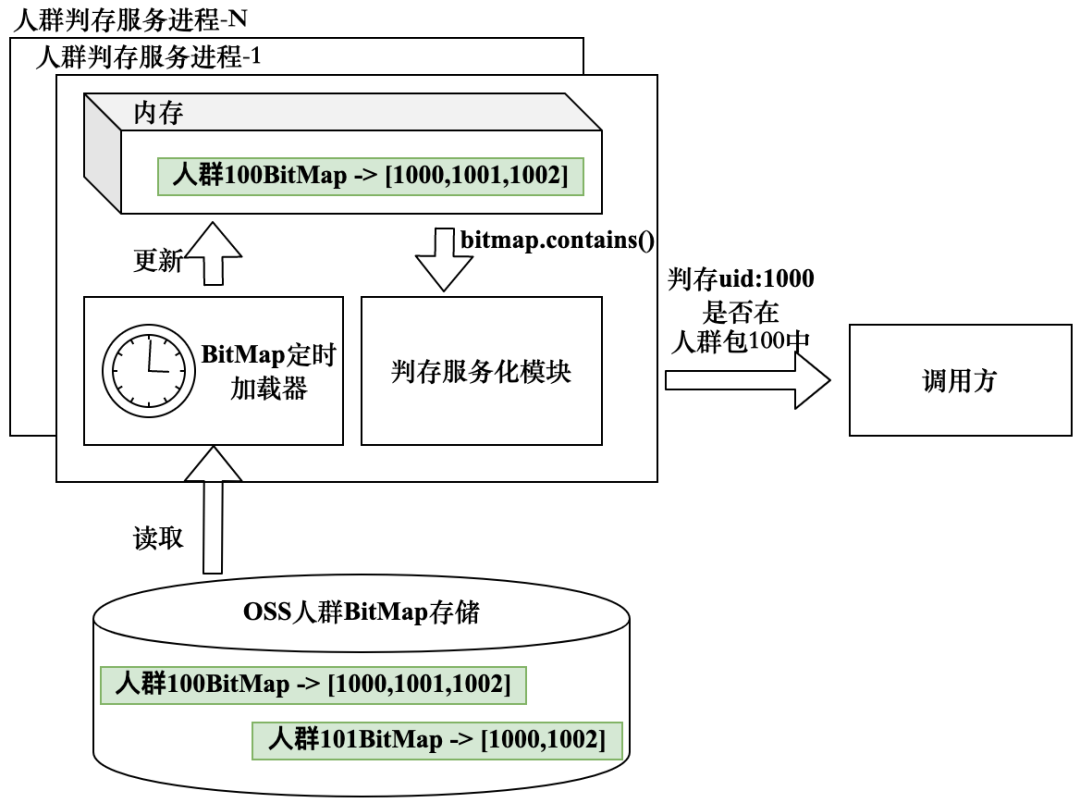
图5-50 基于BitMap实现人群判存实现逻辑
基于BitMap实现判存服务能否支持非数字类型的ID?以DeviceId为例,在本章介绍规则圈选时提到可以通过编码的形式将所有DeviceId映射到数字ID,在人群圈选过程中通过该数字ID替代真实的DeviceId。当DeviceId的人群BitMap用于判存服务中时,需要将请求中传入的DeviceId转换为数字ID之后再进行判存,其实现逻辑如图5-51所示。由于判存过程中多了一次ID转换服务请求,这增加了判存服务接口响应时间。
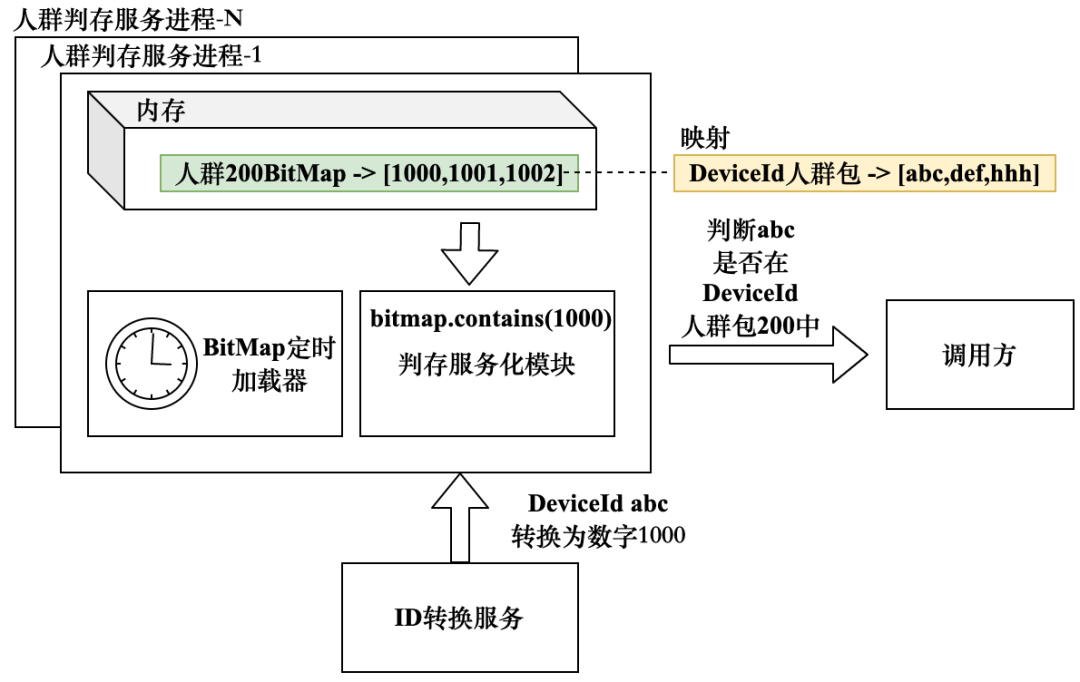
图5-51 BitMap支持DeviceId人群判存实现逻辑
Redis中也支持BitMap数据结构,可以将人群ID作为Key,人群下的所有UserId构建的BitMap作为Value,但是Redis原生BitMap函数在高并发请求下性能较差,不适合直接用于判存场景。
综上可知,使用BitMap实现人群判存相对Redis方案人群加载更快、人群更新更加便捷。由于人群数据存储在内存中,判存的实现相对Redis方案少了一次网络请求,所以其在判存接口性能上也优于Redis方案。因为BitMap存储在内存中支持判存服务,当进程重启时需要再次加载所有数据到内存中,当人群数目较多时从数据加载到就绪需要挺长的时间,相对于成熟的Redis方案其维护成本较高。
基于规则的判存
基于Redis和BitMap实现人群判存功能的前提是人群需要创建完成,前者将人群数据存储在Redis中,后者将人群BitMap存储在内存中,两个方案都会使用到额外的计算和存储资源。基于规则判断实现人群判存不需要真正创建人群,其主要依赖标签查询服务来实现。以北京市男性用户为例,前两种方案需要先实际圈选出人群,如果用户判存结果为真则代表其属于北京市男性用户;基于规则的判存只需要查询用户的常住省和性别标签值,如果结果中省份是北京市且性别是男性,那同样代表该用户属于北京市男性用户,即判存结果为真,其实现流程如图5-52所示。由此可见,基于规则的判存实现方案依赖标签查询服务,也就限制了其仅适用规则人群判存。

图5-52 基于规则判存的实现逻辑
为了实现基于规则的判存,首先需要记录用户设定的判存规则表达式,比如"province == '北京市' && gender == '男' ",其次借助标签查询获取用户的标签值,最后通过表达式引擎判断结果是否为真。Java语言常用的表达式引擎有MVEL和Aviator。MVEL是一款功能强大的表达式解析器,支持获取对象属性及方法、支持复杂的if else语句,其性能优越但是资源消耗较大;Avaitor虽然支持的功能不如MVEL完善,但其定位是一个高性能、轻量级的Java语言实现的表达式求值引擎。其他引擎一般都是通过解释的方法执行,MVEL和Aviator可以直接将表达式编译成Java字节码并交给JVM执行。下面给出了使用MVEL和Avaitor实现判存逻辑的核心代码。
long userId = 100l;
String expression = "province == '北京市' && gender == '男'";
Map<String, Object> map = Maps.newHashMap();
// getLabelValue函数用于查询用户标签
map.put("province", getLabelValue(userId, "province"));
map.put("gender", getLabelValue(userId, "gender"));
// 通过MVEL实现表达式判断
Boolean mvelResult = (Boolean) MVEL.eval(expression, map);
if (mvelResult) {
// 判存结果是“是”
} else {
// 判存结果是“否”
}
// 通过Aviator实现表达式判断
Expression compiledExp = AviatorEvaluator.compile(expression);
Boolean aviatorResult = (Boolean) compiledExp.execute(map);
if (aviatorResult) {
// 判存结果是“是”
} else {
// 判存结果是“否”
}
基于规则的判存虽然不再需要实际创建人群,但是在判存过程中需要使用标签查询服务,如果判存涉及大量的标签,为了实现规则判存需要支持大量标签的查询服务,这无疑增加了标签查询功能的资源消耗。基于规则的判存只适用于规则人群,当其他类型人群也需要支持判存时依旧需要引入其他技术实现方案,基于这一点考虑,判存功能的实现应该找一个更普适的技术方案。
本文节选自《用户画像:平台构建与业务实践》,转载请注明出处。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号