解锁 vLLM:大语言模型推理的速度与效率双提升

解锁 vLLM:大语言模型推理的速度与效率双提升

唐国梁Tommy
发布于 2023-10-25 19:05:49
发布于 2023-10-25 19:05:49
1.论文名称: Efficient Memory Management for Large Language Model Serving with PagedAttention
2.论文链接: https://arxiv.org/abs/2309.06180
3.github项目: https://github.com/vllm-project/vllm.git
4.团队: UC Berkeley
目录:
1. LLM推理面临的内存挑战
1.1 大的KV缓存
1.2 复杂的解码算法(decoding)
1.3 未知输入和输出长度的调度(scheduling)
1.4 现有系统中的内存管理问题
2. 解决措施
2.1 分页注意力【PagedAttention】
2.1.1 背景
2.1.2 实现细节
2.1.3 注意力计算中的具体操作
2.2 KV缓存管理器【KV Cache Manager】
2.2.1 虚拟内存的原理
2.2.2 vLLM的应用
2.2.3 GPU worker上的块引擎
2.2.4 KV块管理器
2.2.5 逻辑与物理的分离
2.3 基于分页注意力和vLLM的解码策略【Decoding with PagedAttention and vLLM】
2.3.1 虚拟内存与预留
2.3.2 第一步自回归解码
2.3.3 第二步解码
2.3.4 解码迭代
2.3.5 动态内存管理
2.3.6 物理与逻辑块的映射
2.4 调度与抢占【Scheduling and Preemption】
2.4.1 背景
2.4.2 如何恢复被驱逐的块,并介绍了两种核心技术
(1)交换 Swapping
(2)重计算 Recomputation
2.5 分布式执行【Distributed Execution】
3. 实施
3.1 内核级优化
3.1.1 融合重塑和块写入(Fused reshape and block write)
3.1.2 融合块读取和注意力(Fusing block read and attention)
3.1.3 融合块复制(Fused block copy)
3.2 支持各种解码算法
3.2.1 Fork 方法
3.2.2 Append 方法
3.2.3 Free 方法
1. LLM推理面临的内存挑战
当我们进行微批处理(mini-batch)时,虽然能减少计算浪费并以更灵活的方式批处理请求,但由于GPU内存容量的限制(特别是存储 KV 缓存的空间),仍然限制了可以一起批处理的请求数量,这意味着服务系统的吞吐量受到内存的限制。具体的内存管理挑战有如下三个方面:
1.1 大的KV缓存
随着请求数量的不断增加,KV缓存的大小也在迅速扩大,这在处理大规模数据时尤为明显。以一个含有13B参数的OPT模型为例,每一个token的KV缓存就需要占用800 KB的空间。而OPT模型能生成的token序列最多可达2048个,因此在处理一个请求时,KV缓存所需的内存空间可能高达1.6 GB。这种情况在当前GPU的资源稀缺环境下尤为突出,因为即便是主流GPU的内存容量也只有几十个GB,如果将所有可用内存都分配给KV缓存,那么也仅能处理几十个请求。而且,如果内存管理不够高效,还会进一步降低批处理的大小,导致资源利用率进一步降低。与此同时,GPU的计算速度的增长速度是超过内存容量的,这让我们相信,随着时间的推进,内存的瓶颈问题将变得越来越明显,可能会严重影响数据处理和模型训练的效率。
1.2 复杂的解码算法(decoding)
LLM服务提供了多种解码算法供用户选择,每种算法对内存管理的复杂性都存在不同的影响。以多个随机样本请求为例,当用户从单个输入提示中请求多个随机样本时,可以通过共享prompt部分的KV缓存来最小化内存的使用。然而,在自回归生成阶段,由于不同样本结果及其相关的上下文和位置依赖关系,保持KV缓存的独立是必要的,以避免数据混淆或错误的生成。
解码算法的不同选择会直接影响到KV缓存共享的程度。例如,在使用较为复杂的解码算法如beam search时,不同的request beams可以共享更大部分的KV缓存,同时,这种共享模式还会随着解码过程的进行而发生变化。这样的设计允许在保证生成质量的同时,尽可能地降低内存使用,从而在一定程度上缓解了内存管理的复杂性,优化了系统的性能表现。通过合理的内存管理和解码算法选择,可以在满足用户需求的同时,保持系统运行的高效和稳定。
1.3 未知输入和输出长度的调度(scheduling)
LLM服务的请求在输入和输出长度上的可变性提出了对内存管理系统的特殊要求,即需要能够适应不同长度的提示。随着请求输出长度的增加,所需的KV缓存的内存也会相应增加,这可能会消耗掉针对新请求或现有提示的进行中生成的可用内存。因此,系统需要进行相应的调度决策以应对这种情况。例如,可以从GPU内存中删除或交换某些请求的KV缓存,以释放内存空间来处理新的请求或继续现有的生成任务。这样的调度决策有助于确保内存资源的有效利用,同时保持LLM服务的高效运行,满足不同长度请求的处理需求。
1.4 现有系统中的内存管理问题
在当前的深度学习框架中,通常要求将张量(tensors)存储在连续的内存区域中。依此,过去的LLM服务系统也采取了相似的做法,将一个请求的KV缓存作为一个连续的张量进行存储。由于从LLM得到的输出长度具有不确定性,这些系统通常会根据一个请求可能的最大序列长度为其静态分配一块内存,而不考虑请求的实际输入或最终的输出长度。这种预分配的策略导致了三个主要的内存浪费来源:
(1) 未来tokens的预留slots:系统预先为可能生成的tokens保留了内存,尽管最终可能不需要所有这些内存。
(2) 内部碎片化:由于为潜在的最大序列长度预留了过多的空间,导致内部的内存浪费。
(3) 外部碎片化:由于采用了如buddy allocator这样的内存分配器,会产生外部碎片化的问题。这些外部碎片化的内存将永远不会被用于生成的tokens,这点在服务请求之前就已经知晓。
尽管这些预留的内存最终可能会被使用,但是为整个请求的持续时间预留这些空间,特别是当预留的空间很大时,占据了本可以用于处理其他请求的宝贵空间。
虽然有人提出使用压缩(compaction)作为解决碎片化问题的一个可能方案,但在一个对性能敏感的LLM服务系统中实施压缩是不切实际的,因为KV缓存的大小非常大。即便采用了压缩,每个请求预分配的块空间也会阻止现有内存管理系统中针对解码算法的内存共享,从而可能对系统的效率和性能产生负面影响。在这种情况下,可能需要探讨更加灵活和高效的内存管理和分配策略,以便在保证LLM服务性能的同时,最大限度地减少内存的浪费。
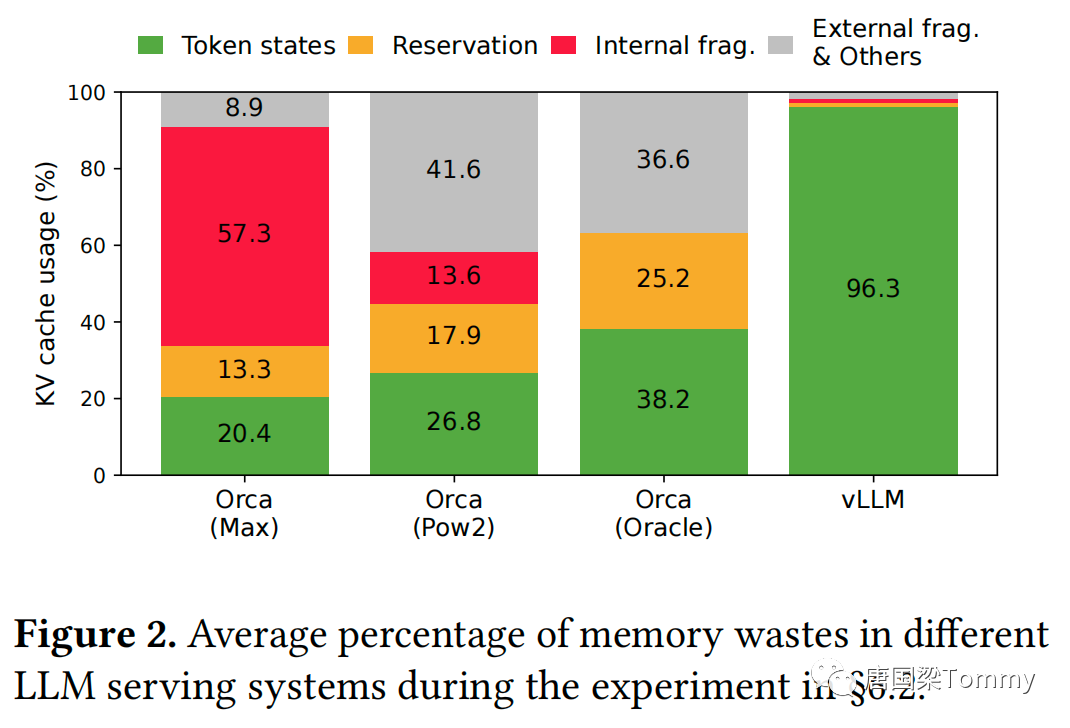
这个图表(Figure-2)显示了不同的LLM服务系统在实验中的内存浪费的平均百分比。
(1) 颜色解释:
- 绿色:Token状态。这是实际用于存储token状态的内存部分。
- 橙色:预留。这是预先保留但未使用的内存部分。
- 红色:内部碎片。这是由于内存分配造成的未使用的内存部分。
- 灰色:外部碎片与其他。这是由于系统其他部分引起的未使用的内存。
(2) 系统对比:
- Orca (Max):在这个配置中,Token状态占用了20.4%的内存,预留了57.3%,内部碎片是13.3%,而外部碎片与其他占用了8.9%。
- Orca (Pow2):在这个配置中,Token状态占用了26.8%的内存,预留了17.9%,内部碎片是13.6%,而外部碎片与其他占用了41.6%。
- Orca (Oracle):在这个配置中,Token状态占用了38.2%的内存,预留了25.2%,内部碎片是36.6%。
- vLLM:vLLM系统在Token状态上使用了96.3%的内存,几乎没有其他浪费。这显示了vLLM在内存管理上的高效性。
(3) 结论:
从图中可以看出,vLLM系统在内存使用上非常高效,几乎所有的内存都用于Token状态,而浪费非常少。相比之下,Orca系统(无论是Max、Pow2还是Oracle配置)都有不同程度的内存浪费,尤其是预留和碎片化。
2. 解决措施
vLLM这个系统采用一个集中式的调度器来协调分布式的GPU工作节点。其中的KV缓存管理器能够以“分页”的方式有效地管理KV缓存,这正是得益于PagedAttention算法。具体来说,KV缓存管理器通过中央调度器发送的指令来管理GPU工作节点上的物理KV缓存内存。

这是vLLM系统的概览图。现在,让我们一步步理解这个图:
(1) Scheduler (调度器)
一个中央组件,负责协调系统中的其他组件。从图中可以看到,它直接与各个Worker进行交互。
(2) KV Cache Manager (键值缓存管理器)
此管理器控制键值缓存,它的设计允许以分页的方式管理内存。它有两个表现形式的“块表”(Block tables)。
(3) CPU Block Allocator & GPU Block Allocator (CPU块分配器 & GPU块分配器)
这两个组件分别负责为CPU和GPU分配内存块。这种分块的分配方式可能是为了优化内存使用和提高整体系统的效率。
(4) Workers (工作节点)
每个工作节点都由以下部分组成:
- Cache Engine (缓存引擎):可能用于快速存取数据,使模型运行更加高效。
- Model Shard (模型分片):这表明模型被分成了多个分片,每个工作节点只处理其中的一个分片。这是一种常见的方法来分布式地处理大型模型,因为它允许多个GPU同时工作,每个GPU只处理模型的一部分。
从这个系统概览中,我们可以得到以下几点关键认识:
- vLLM系统利用了分布式处理来处理大型语言模型。 - 它有一个集中的调度器来协调各个组件。 - 该系统使用了分页的方式来管理内存,为了优化内存使用。 - 通过将模型分片到多个工作节点上,系统可以并行处理任务。
2.1 分页注意力【PagedAttention】
2.1.1 背景
传统的注意力算法往往要求在连续的内存空间中存储键和值,但PagedAttention允许在非连续的内存空间中存储连续的键和值。
2.1.2 实现细节
(1)PagedAttention将每个序列的KV缓存分割成多个KV块。
(2)每个块包含固定数量tokens的键和值向量,这个固定的数量被称为KV块大小(𝐵)。
(3)公式部分给出了如何将传统的注意力计算转换为基于块的计算:
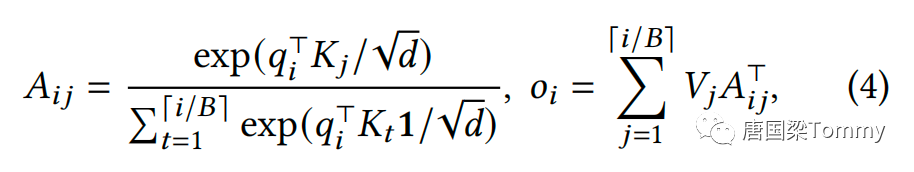
这个公式描述了如何计算给定query和一组键值块之间的注意力输出。
公式中的参数解释:
A_ij : 注意力分数
q_i_T : 第i个token的查询向量的转置
K_j : 第j个KV块的键向量
O_i : 最终注意力输出
V_j : 第j个KV块的值向量
i/B : B可能表示的是块大小或KV块中的tokens数量,整数除法i/B是用来确定给定的查询token i 对应于哪一个KV块。它本质上将序列划分为大小为B的多个块,并确定 i 落在哪个块内。2.1.3 注意力计算中的具体操作
PagedAttention内核分别识别并获取不同的KV块,以下是一个示例:
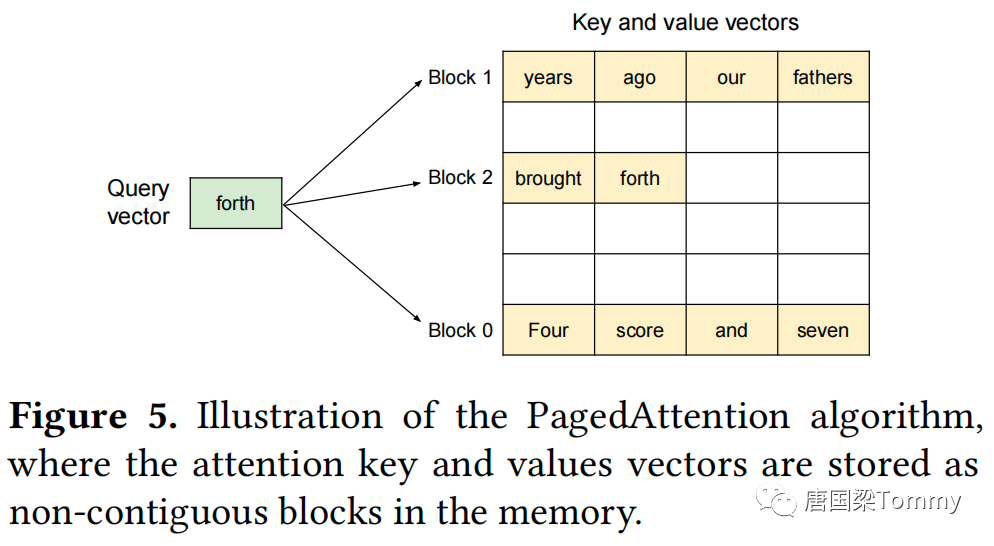
图中的例子解释了PagedAttention的工作方式:key和value向量分散在三个块中,这三个块在物理内存上不是连续的。每次,内核都会将query向量与一个块中的key向量相乘(例如,用于计算块0的“Four score and seven”)以计算注意力分数。之后,它再将该注意力分数与块中的value向量相乘,以得出最终的注意力输出。
2.2 KV缓存管理器【KV Cache Manager】
vLLM通过借鉴虚拟内存的原理,采用固定大小的块和动态映射的方式,有效地管理了内存,减少了内存浪费。
2.2.1 虚拟内存的原理
操作系统将内存分为固定大小的pages,并将用户程序的逻辑pages映射到物理pages。连续的逻辑pages可能对应于不连续的物理内存pages,这使得用户程序可以像连续内存一样访问内存。此外,不需要事先完全预留物理内存空间,这使得操作系统可以根据需要动态分配物理pages。
2.2.2 vLLM的应用
vLLM借鉴了虚拟内存的原理来管理LLM服务中的KV缓存。借助PagedAttention,我们将KV缓存组织为固定大小的KV块,就像虚拟内存中的pages一样。请求的KV缓存表示为一系列的逻辑KV块,随着新的tokens及其KV缓存的生成,从左到右进行填充。最后一个KV块的未填充位置为未来的生成保留。
2.2.3 GPU worker上的块引擎
在GPU worker上,块引擎(block engine)分配一个连续的GPU DRAM块,并将其划分为物理KV块(这也在CPU RAM上进行交换)。
2.2.4 KV块管理器
KV块管理器还维护块表(block tables)——每个请求的逻辑和物理KV块之间的映射。每个块表条目记录了逻辑块的相应物理块和已填充位置的数量。
2.2.5 逻辑与物理的分离
分离逻辑和物理KV块允许vLLM动态增长KV缓存内存,而无需事先为所有位置预留,这消除了现有系统中的大部分内存浪费。
2.3 基于分页注意力和vLLM的解码策略【Decoding with PagedAttention and vLLM】
论文中这一段解释了vLLM如何在单个输入序列的解码过程中执行PagedAttention并管理内存,详细描述了vLLM在解码迭代中的全局工作流程和内存管理策略。
2.3.1 虚拟内存与预留
vLLM通过采用类似于操作系统中虚拟内存的概念,避免了在初始阶段为可能生成的最大序列长度预留内存的需求。在这种模式下,vLLM仅预留了必要的KV块以容纳在prompt计算期间生成的KV缓存,而不是预留固定或最大数量的内存资源。在预填充的步骤中,vLLM利用常规的自注意力算法生成了prompts和第一个输出token的KV缓存。随后,vLLM将前4个tokens的KV缓存存储在逻辑块0中,而将后面3个tokens的KV缓存存储在逻辑块1中。这样做的好处是,剩余的slot被保留,用于随后的自回归生成阶段,从而实现了内存的动态管理和优化。通过这种方式,vLLM能够根据实际的需求动态地管理和分配内存资源,而不是静态地预留大量可能不会被完全利用的内存。这不仅能够提高内存的利用率,还能在一定程度上提高系统的性能和响应速度。
2.3.2 第一步自回归解码
vLLM使用PagedAttention算法在物理块7和1上生成新token,由于最后一个逻辑块中还有一个可用的slot,新生成的KV缓存被存储在那里,并更新块表中的 #filled 记录。
2.3.3 第二步解码
由于最后一个逻辑块已满,vLLM在一个新的逻辑块中存储新生成的KV缓存。vLLM为其分配一个新的物理块(物理块3)并在块表中存储这个映射。
2.3.4 解码迭代
在每次解码迭代中,vLLM开始的步骤是选择一组候选序列进行批处理,并为新需要的逻辑块分配物理块。随后,vLLM将当前迭代的所有输入tokens(包括prompt阶段请求的所有tokens和生成阶段请求的最新tokens)连接成一个序列,然后将这个序列输入到LLM。
在LLM的计算过程中,vLLM利用PagedAttention内核来访问以逻辑KV块形式存储的先前KV缓存,同时将新生成的KV缓存保存到物理KV块中。通过在KV块中存储多个tokens,PagedAttention内核能够并行处理更多位置上的KV缓存,这有助于提高硬件的利用率和减少计算延迟,从而加速了解码过程。
然而,这种方法也带来了一个挑战,即更大的块大小可能会增加内存碎片问题。虽然并行处理可以提高效率,但较大的块大小可能意味着更多的内存空间被预留或锁定,从而可能影响到内存的有效利用。
2.3.5 动态内存管理
vLLM通过动态地为逻辑块分配新的物理块,随着更多tokens及其KV缓存的生成,优化了内存的利用。在这种机制下,所有的块都是从左到右填充的,仅当所有之前的块都已满时,才会分配一个新的物理块。这种设计帮助将一个请求的所有内存浪费限制在一个块内,从而可以更有效地利用所有的内存。
这种内存管理策略不仅有助于减少内存浪费,还通过允许更多的请求适应于内存中的批处理,提高了系统的吞吐量。每个请求的处理变得更为高效,因为现有的内存资源得到了更好的利用。当一个请求完成其生成过程后,其占用的KV块可以被释放,从而为其他请求的KV缓存提供存储空间。
这种动态分配和释放物理块的机制,为LLM服务中的内存管理提供了一种有效的解决方案。
2.3.6 物理与逻辑块的映射
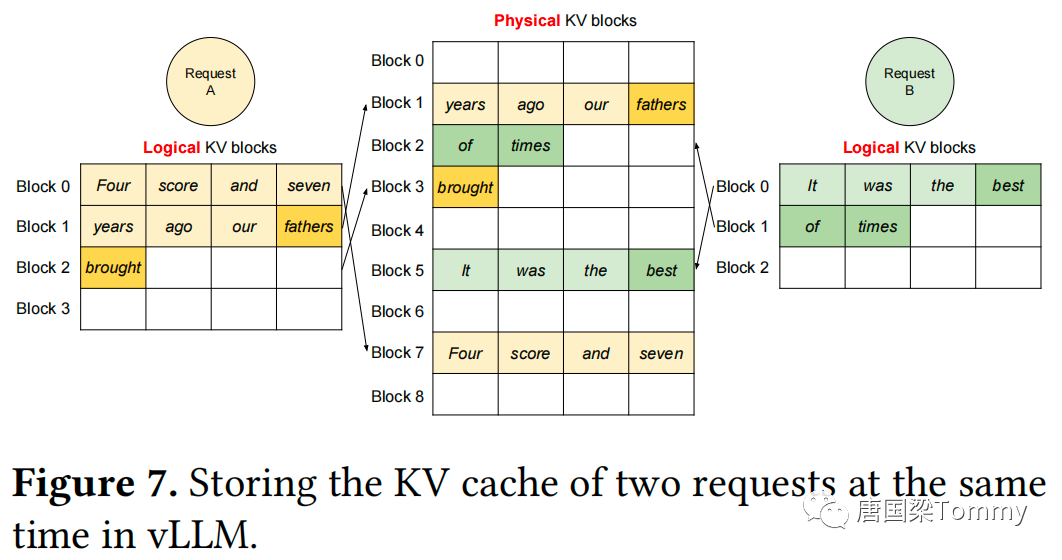
在图7中,给出了vLLM为两个序列管理内存的示例。两个序列的逻辑块被映射到由GPU workers中的块引擎(block engine)预留的不同的物理块上。两个序列的相邻逻辑块在物理GPU内存中不需要是连续的,两个序列都可以有效地利用物理块的空间。
图-7展示了如何在vLLM系统中同时为两个请求存储KV缓存。
Request A:
(1) 逻辑KV块:
- 块0: 包含"Four score and seven"
- 块1: 包含"years ago our fathers"
- 块2: 只有一个词,即"brought"
- 块3: 目前为空
(2) 物理KV块:
- 这些逻辑块的内容被映射到物理块中,与其位置不一定一致。
- 例如,逻辑块0的内容"Four score and seven"被映射到物理块7中。
- 逻辑块1的内容"years ago our fathers"映射到物理块1中。
- 逻辑块2的内容"brought"映射到物理块3中。
Request B:
(1) 逻辑KV块:
- 块0: 包含"It was the best"
- 块1: 包含"of times"
- 块2: 目前为空
(2) 物理KV块:
- 逻辑块0的内容"It was the best"被映射到物理块5中。
- 逻辑块1的内容"of times"映射到物理块2中。
这种映射策略使得两个逻辑块的邻近块在物理GPU内存中不必是连续的。因此,物理块的空间可以被两个序列有效地使用,从而实现了高效的内存管理。
2.4 调度与抢占【Scheduling and Preemption】
2.4.1 背景
(1)超出容量的处理
当系统收到的请求超过其处理能力时,需要进行优先处理或者抢占部分请求。vLLM采取了先来先服务first-come-first-serve (FCFS)的策略,这意味着早先到达的请求会被优先处理,而后到达的请求在需要的情况下会被先行抢占。
(2)LLM的独特挑战
每个LLM的请求都有自己独特的输入提示,这些提示在长度上可能差异很大。这造成了输出长度的不确定性,因为模型的回答会基于这些不同长度的输入提示。当请求和输出数量增加,可能会耗尽存储空间。
(3)驱逐策略 eviction policies
为了释放存储空间,系统需要决定哪些数据块应该被移除。这里采用了一个特殊的策略:要么移除整个序列的所有数据块,要么不移除任何块。这种策略考虑到了整个序列的数据块是一起被访问的。
(4)序列组 sequence group
vLLM还有一个特点是它可以将多个序列组合为一个组,并一起进行调度。这意味着,如果需要抢占或重新调度,整个组的所有序列都会受到影响。
2.4.2 如何恢复被驱逐的块,并介绍了两种核心技术
(1) 交换 Swapping
① 概念:
交换是大多数虚拟内存实现使用的经典技术。当内存不足时,被驱逐的pages会被复制到硬盘上的交换空间。在vLLM中,被驱逐的块会被复制到CPU的内存中。
② 实现:
- CPU块分配器:
除了GPU块分配器,vLLM还包括一个CPU块分配器,用于管理被交换到CPU RAM的物理块。
- 驱逐策略: 当vLLM没有足够的空闲物理块用于新的tokens时,它会选择一组序列进行驱逐,并将它们的KV缓存传输到CPU。
- 停止接受新请求:
一旦抢占了一个序列并驱逐了其块,vLLM会停止接受新的请求,直到所有被抢占的序列完成。
- 请求完成后:
完成的请求的块会从内存中释放,被抢占的序列的块会被带回来,以继续处理该序列。
③ CPU RAM 的交换空间大小
此设计确保交换到CPU RAM的块数量永远不会超过GPU RAM中的总物理块数量。因此,CPU RAM上的交换空间大小受GPU内存的限制。
(2)重计算 Recomputation
① 概念
在这种方法中,当被抢占的序列被重新调度时,需要简单地重新计算KV缓存。
② 优势
重新计算的延迟可以比原始延迟低得多,因为在解码时生成的tokens可以与原始的用户提示连接作为新的提示,它们在所有位置的KV缓存可以在一个提示阶段迭代中生成。
③ 性能考虑
交换和重新计算的性能取决于CPU RAM和GPU内存之间的带宽以及GPU的计算能力。
2.5 分布式执行【Distributed Execution】
由于许多大型语言模型(LLMs)的参数大小超过了单个GPU的容量,因此需要在分布式的GPU上对它们进行分区,并采用模型并行的方式执行。为了满足这种分布式执行的需求,vLLM采用了广泛应用的Megatron-LM风格的Transformers上的张量模型并行策略。该策略使用单程序多数据(SPMD)执行调度,将线性层分区来执行块状矩阵乘法,并通过all-reduce操作来不断同步各GPU间的中间结果。
具体来说,注意力操作符被分割在注意力头维度上,每个SPMD进程处理多头注意力中的一部分注意力头。尽管在模型并行执行时,每个模型分片仍然处理相同的输入tokens,因此需要为相同的位置提供KV缓存。为了实现这一目标,vLLM在集中调度程序中设置了一个独立的KV缓存管理器。不同的GPU workers共享这个管理器,以及逻辑块到物理块的映射,从而保证了各GPU间的数据一致性和协同工作。
在每个步骤中,调度器首先为批处理中的每个请求准备输入tokens ID的消息,以及每个请求的块表,然后将这些控制消息广播给各GPU workers。接着,GPU workers开始根据输入tokens ID执行模型。在处理注意力层时,GPU workers根据控制消息中的块表读取相应的KV缓存,并在执行过程中通过all-reduce通信原语同步中间结果,无需调度器的额外协调。最后,GPU workers将此次迭代生成的tokens发送回调度器。
这种公共映射和集中式的KV缓存管理机制允许GPU workers使用调度器为每个输入请求提供的物理块来执行模型,确保了模型并行执行时的高效和协调,同时也为处理大型语言模型提供了一个有效的分布式执行框架。通过这种方式,vLLM能够在多GPU环境中有效地管理内存和执行模型,进一步提高了大型语言模型服务的性能和吞吐量。
3. 实施
vLLM是一个端到端的服务系统,它的构建包括一个基于FastAPI的前端和一个基于GPU的推理引擎。通过扩展OpenAI API接口,前端允许用户为每个请求定制采样参数,例如最大序列长度和beam width k,从而提供了一种灵活且用户友好的方式来控制模型的生成过程。
在实现上,vLLM引擎由8.5K行Python代码和2K行C++/CUDA代码构成。其中,控制相关的组件如调度器和块管理器是在Python中开发的,而一些关键操作的自定义内核,例如PagedAttention,则是在C++/CUDA中开发的。这种分工使得vLLM能够充分利用Python的灵活性以及C++/CUDA在性能优化和GPU计算方面的优势。
为了实现模型执行器,vLLM使用了PyTorch和Transformers库来实现了几种流行的大型语言模型(LLM),如GPT、OPT和LLaMA。这些库提供了丰富的API和工具,使得开发和实现这些复杂的模型成为可能。
在处理跨分布式GPU workers的张量通信时,vLLM选择使用NCCL(NVIDIA Collective Communications Library)来实现。NCCL是专为解决分布式和多GPU计算环境中的通信问题而设计的库,它为张量的集合操作提供了高效的实现,从而能够在多GPU环境中实现高效的数据通信和同步。
通过这种设计和实现,vLLM提供了一个高效、可扩展和易于使用的服务系统,能够满足用户在处理大型语言模型时的需求,同时也为未来的开发和优化提供了一个稳定的基础。
3.1 内核级优化
3.1.1 融合重塑和块写入(Fused reshape and block write)
在每个 Transformer 层,新的 KV 缓存被分割成块,重塑为优化的内存布局,然后保存在块表指定的位置。为了最小化内核启动开销,我们将它们融合成一个单一的内核。
3.1.2 融合块读取和注意力(Fusing block read and attention)
我们修改了 FasterTransformer 中的注意力内核,根据块表读取 KV 缓存,并即时执行注意力操作。
为确保内存访问合并,我们为每个块分配一个 GPU warp。此外,我们增加了对请求批次中的变量序列长度的支持。
3.1.3 融合块复制(Fused block copy)
由 copy-on-write 机制发出的块复制操作可能在不连续的块上操作。如果我们使用cudaMemcpyAsync API,这可能导致大量小数据移动的调用。为了减少这种开销,我们实现了一个内核,将不同块的复制操作批量到一个单一的内核启动中。
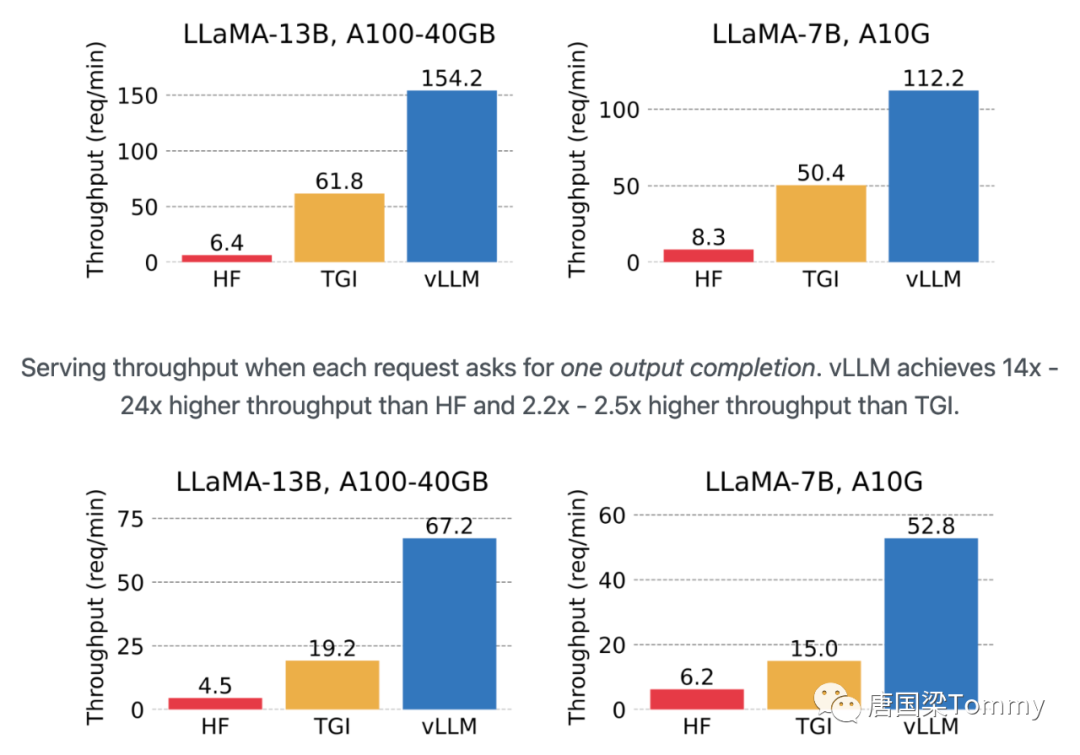
3.2 支持各种解码算法
3.2.1 Fork 方法
从现有的序列创建一个新的序列
3.2.2 Append 方法
将新的tokens添加到序列中
3.2.3 Free 方法
删除序列
在并行采样中,vLLM使用fork方法从单一输入序列创建多个输出序列。然后,它在每次迭代中使用append方法向这些序列添加新的tokens,并使用free方法删除满足停止条件的序列。vLLM也在beam search和prefix sharing中采用了相同的策略。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号