【天穹OS】虚拟表:支持极速查询的下一代湖仓一体新范式
原创
【天穹OS】虚拟表:支持极速查询的下一代湖仓一体新范式
原创
jhonye
修改于 2023-10-31 16:54:59
修改于 2023-10-31 16:54:59
前言
湖仓一体(Lakehouse)是近年来比较火的大数据概念,它将数据湖(Data Lake)和数据仓库(Data Warehouse)的优势结合起来,为企业提供了更强大、更灵活的数据管理解决方案。Gartner 技术曲线的描绘中,Lakehouse是一项非常重要技术,预计还有2~5年进入平台期,国内是5~10年。
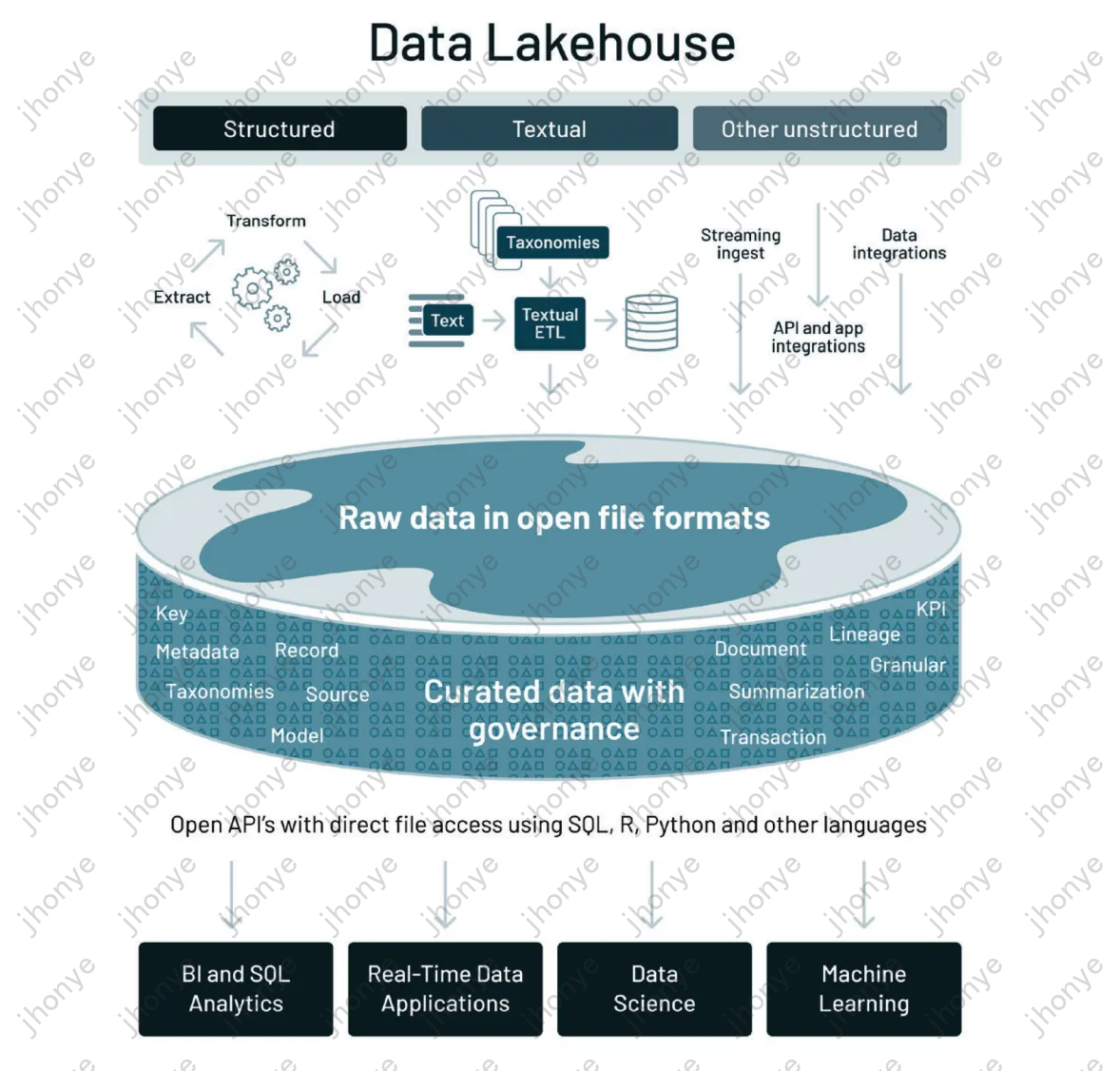
图1 湖仓一体架构
如图1,湖仓一体是想通过一套架构同时满足许多场景的方案,多种数据源被统一治理,通过统一出/入口提供服务支持SQL分析、线上应用、数据科学、机器学习等场景。当今已存在的许多湖仓一体的产品,他们都是非常优秀的架构和技术,下面着重说明一下两大主流湖仓一体方向:
基于数据湖的湖仓一体架构,以DeltaLake为代表 [1]
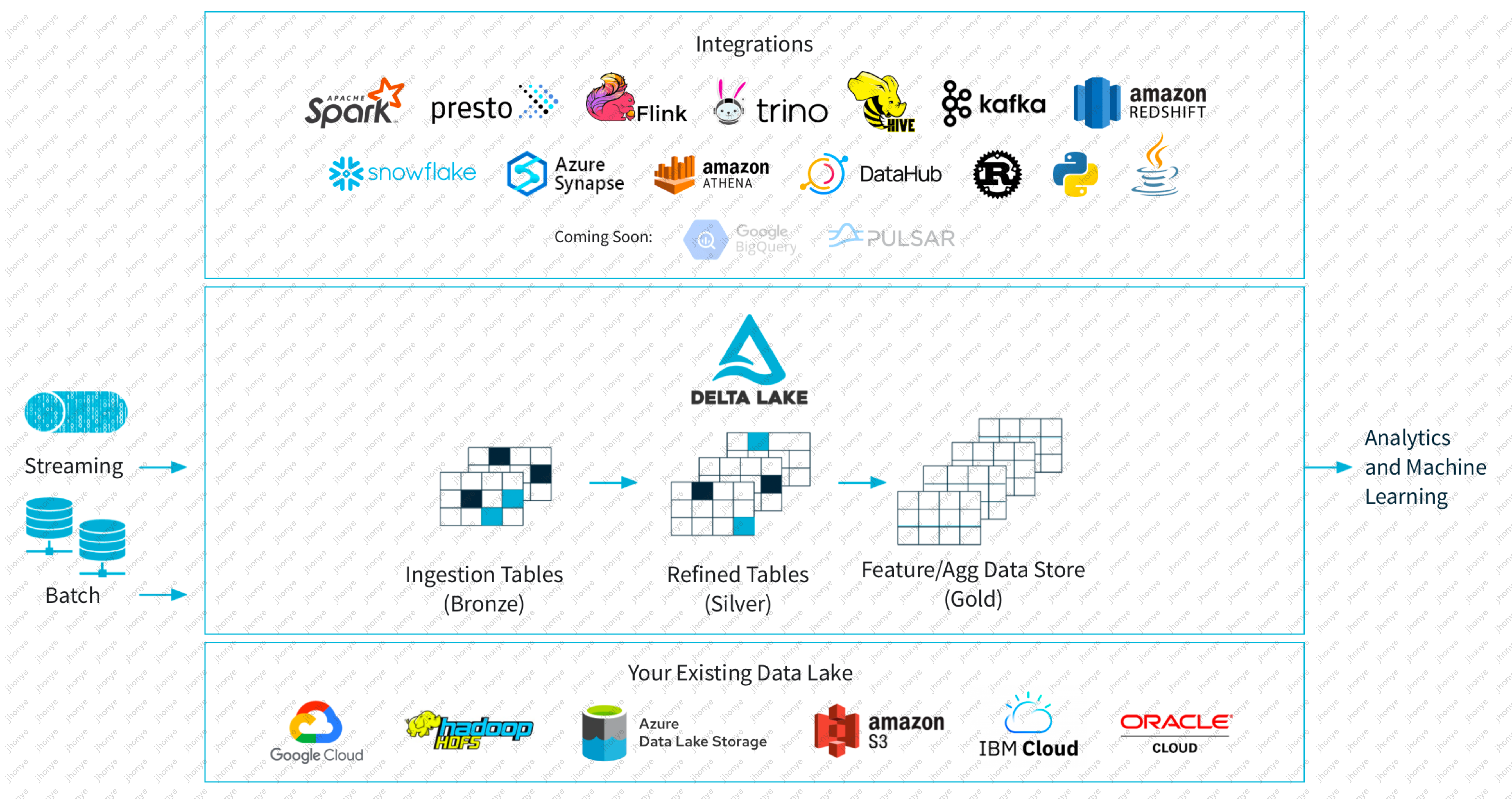
图2 DataLake数据湖架构
如图2,DataLake 作为中央数据湖,汇聚左边流和批的数据源,提供右侧的分析和机器学习能力;目前已经有许多知名云厂商支持了DeltaLake,DeltaLake是一个开放的存储框架,支持对接业界常见的所有计算引擎,例如Spark、Presto等,两者进行组合成类数据库的系统。
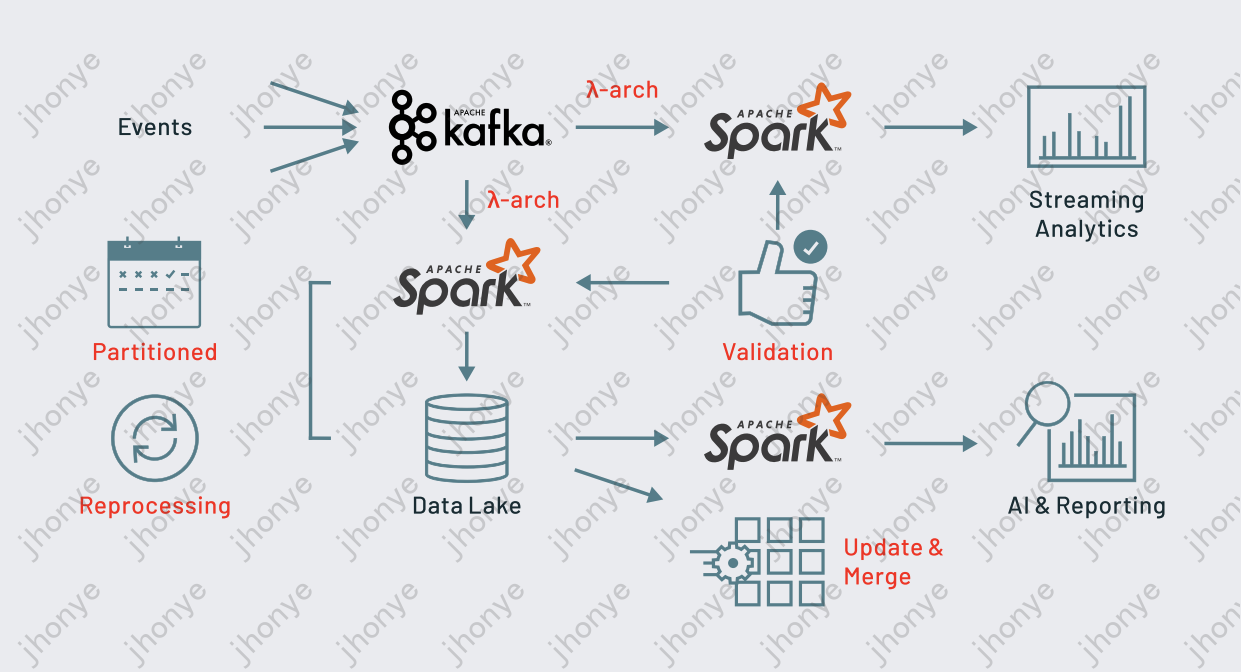
图3 Databricks的湖仓一体架构图
如图3,Databricks 公司的湖仓一体架构图, 流批计算的引擎主要依赖Spark,存储基于DeltaLake;当然Databricks公司不是简单的进行缝合,而是对Spark 进行了大量的优化、开发了C++ Native引擎,且做了大量的融合工作,才达到目前的湖仓一体状态;另外Databricks公司还积极拥抱AI,支持了许多AI的场景,目前估值430亿美元。
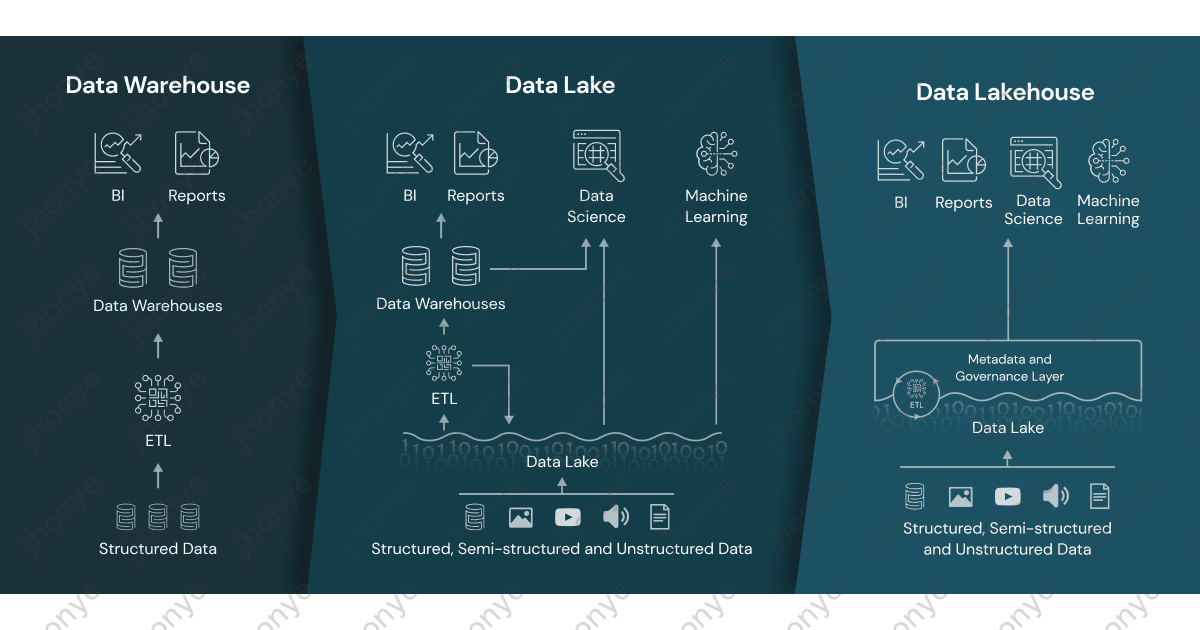
图4 基于数据湖的湖仓一体的演化路径
基于数据湖的湖仓一体是从湖存储演化而来,然后去支持性能更好的数据仓库场景,例如预先数据组织、索引、缓存等。
基于数据仓库的湖仓一体架构,以Snowflake为代表 [2]
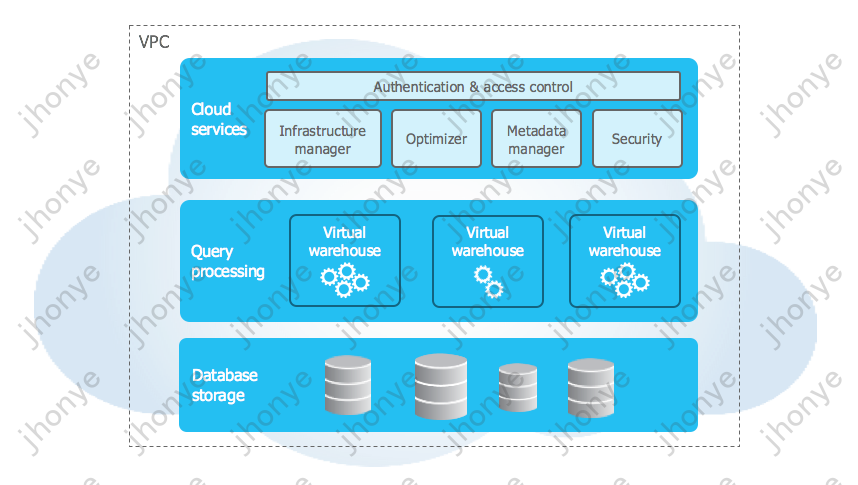
图5 Snowflake 产品架构图
如图5,为Snowflake的架构图,其中 Cloud Services 是常驻的,Query Processing 是弹性的,Database Storage 是近乎无限的。目前业界的许多数据湖/数据仓库都在使用弹性计算资源的方案,在大部分场景下降本提效的效果还是不错的;同时近乎无限的云上存储和对其他多种开源格式的支持,也可以把Snowflake当成数据湖来使用。
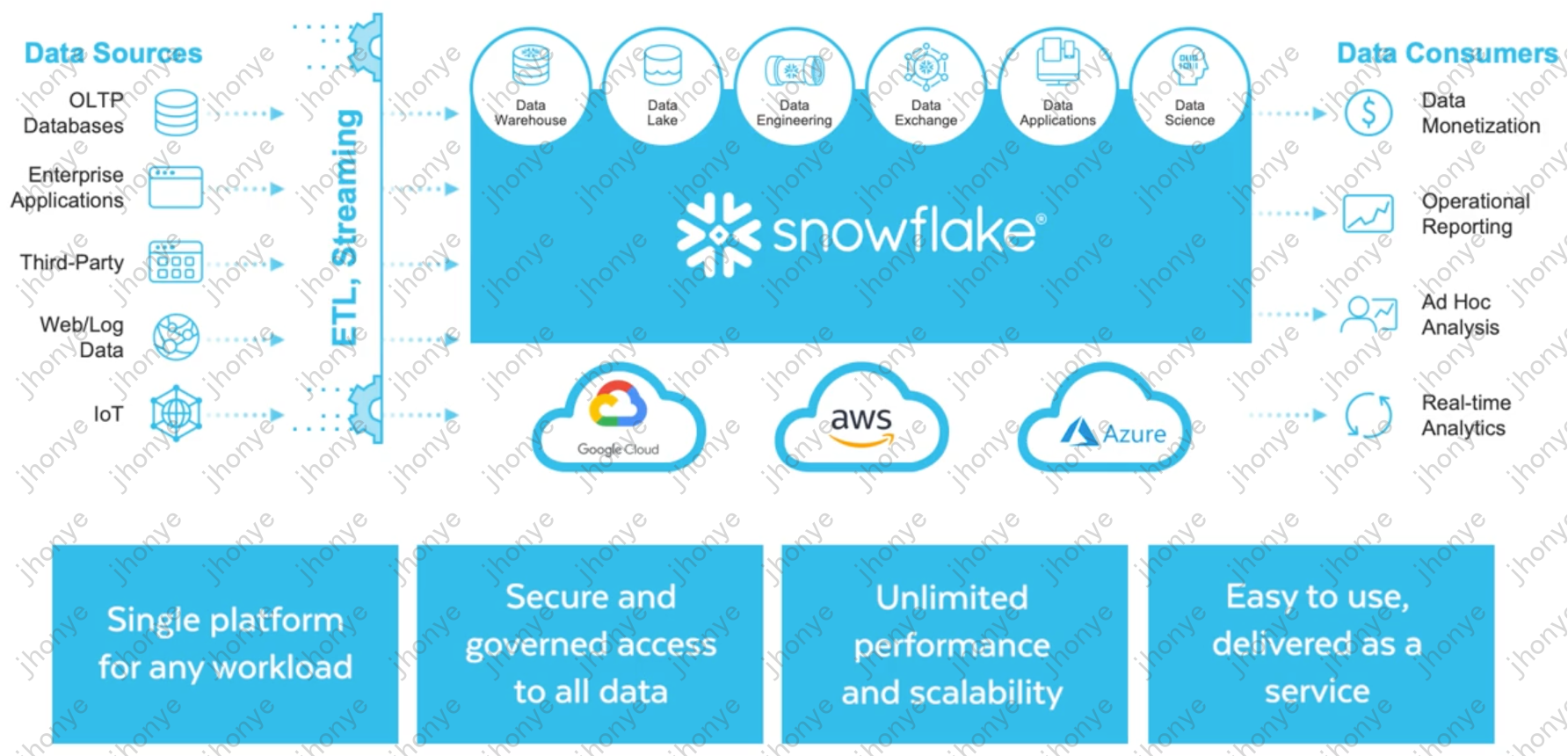
图6 Snowflake湖仓一体架构图
如图6,Snowflake是一个中央数据仓库(湖仓一体),汇聚左侧的数据源,提供右侧的服务能力;支持多个云厂商部署,能力上可支持多种负载和国内提的HSAP类似、性能强悍,整个生态和体系非常完善、用户友好,峰值估值近400亿美元,现今近160亿美元(看来不搞AI在当前不受投资人看好啊)。
基于数据仓库的湖仓一体是从高性能仓优势出发,然后去扩展开放性,支持更多的其他存储格式,为了平衡成本支持存算分离、弹性计算等。
那么下一代的湖仓一体的趋势?
这些年演化下来,许多大数据概念和框架的能力都有许多的外延,对湖仓有困惑的可以看这篇文章:如何理解湖仓一体?[5]
《合久必分,分久必合》是一句古老的谚语,它传达了一个重要的哲学观念:事物的发展往往是循环往复的,合并和分离是不可避免的。大数据发展这些年,架构上也是分分合合,大部分公司都存在较多的“历史债”。上述两个产品是业界TOP、非常优秀的,但是着两个架构还是存在一些场景支持不完善的问题,且“历史债”想要迁移到这些产品上成本也不小。目前这些湖仓一体产品进行持续迭代后他们本身也会出现“历史债”导致架构上没法往更好的方向进行演化,最后又得搞个新的产品,可能又得做一次数据迁移。
前些年基于维度建模、解决数据孤岛的中央数据仓库大热,所有的数据都在往里灌,存储了海量(ZB)的数据;但是现在业界许多公司的中央数据仓库落后主流技术一两代,在需要迭代升级、降本提效的时候却面临而迁移不动的尴尬。然后就算花费巨大的力气迁移到了上述最先进的”中央湖仓一体“,难道以后就不需要升级了?很多时候业务的诉求其实就是够用就行,技术升级、降本提效对于后台人员还是比较有诱惑力的,但是对于前台业务人员很鸡肋,没有足够的“诱惑力”是很难推动他们的。
基于上述考量,我们发现拥抱变化是目前比较好的选择,那么下一代湖仓一体的架构是?近两年出现的Data Fabric概念在海外是比较火的,接下来在国内也会火起来,可以作为我们的参考。通过构建数据虚拟化层[3]将底层异构的计算、存储进行虚拟化,提供统一出/入口;用户的操作流程都在一套系统上,就可以根据业务的优先级随时迁移,数据从低效流动到高效会变得顺畅起来,技术更新迭代的效率也会更高。
深入了解 Data Fabric 请参考文章:下一代大数据技术架构:Data Fabric?
上述两个优秀的湖仓一体架构对比 Data Fabric 架构还缺关键的两个点:
- 融合异构框架的能力:对外部数据源缺乏统一权限、统一数据治理基本没做,SQL兼容较差,只是简单的支持了外部数据源、外表的支持。
- 虚拟化层:结合异构框架未主动采集、生成全局元数据,对用户基本透明,容易出错,手动工作多。
在朝着 Data Fabric 技术架构方向进行演进后,天穹大数据在存储与计算上面也抽象了虚拟化层用于融合异构框架的能力,因为当前我们融合的都是类数据库的引擎,所以我们使用“天穹OS-虚拟表”来统一所有引擎的表。
本文关键词:天穹大数据、天穹OS、Data Fabric、大数据架构、湖仓一体、屏蔽异构、数据虚拟化、数据仓库升级、极速查询、极速报表场景、Benchmark、SSB、TPC-H、OLAP、视图/物化视图、数据集成、联邦查询
什么是天穹OS-虚拟表?
天穹OS-虚拟表是 Data Fabric 大数据架构虚拟化层的一种具体实现方式,以下简称虚拟表。
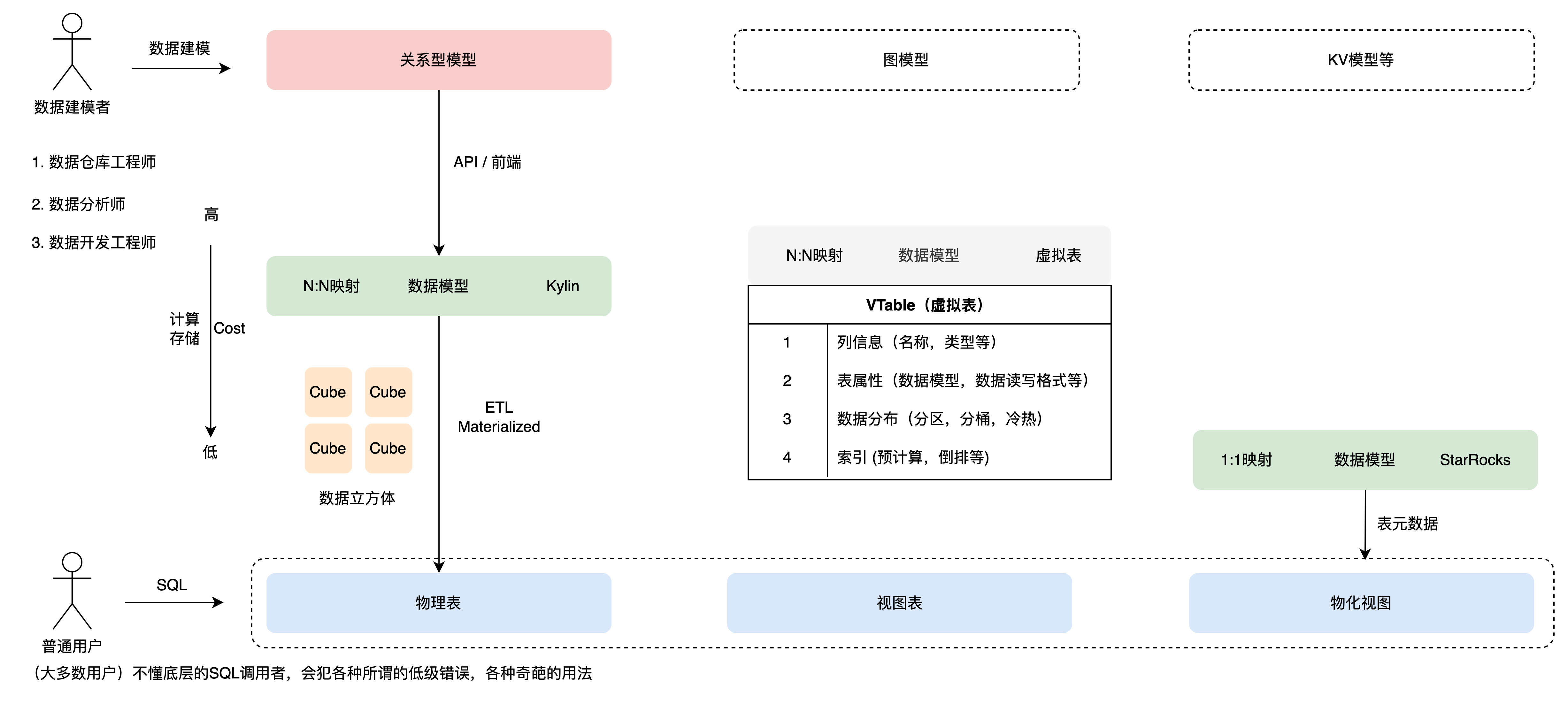
图7 数据模型角度认识虚拟表
如图7,业界有许多产品定义数据模型用于描述数据属性、关系,目前实现的虚拟表也是相似逻辑。
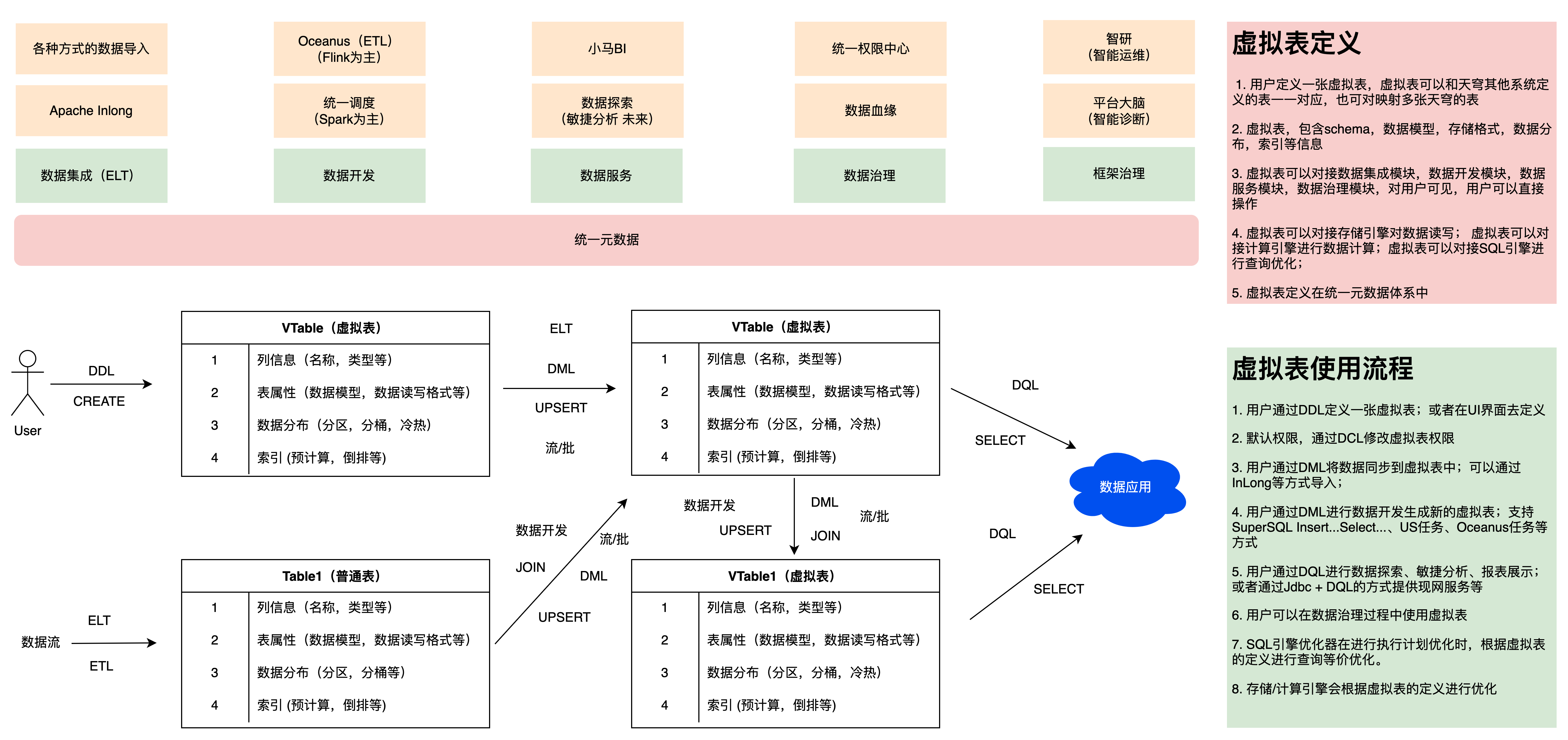
图8 虚拟表在天穹大数据的定义和流程
如图8,用户可以像使用天穹数据仓库表的方式使用虚拟表,虚拟表屏蔽异构计算和异构存储,提供统一的SQL查询出/入口。
用户当前可以把虚拟表当成天穹数据仓库的一种新的表模型来使用,当前需要用户在建表时指定VIRTUAL关键字。我们通过分析用户的SQL发现,用户对自己的查询稳定性是有明确预期的,举例以下几个用户平衡性能与成本后的业务场景:
- 如果需要99分位的查询响应都在毫秒级,则会直接使用OLAP引擎(StarRocks、Hemers等)。(异构 + 极高成本)
- 如果需要99分位的查询响应都在10s以内,则会选用 Presto + Alluxio预加热模式 等架构。(同构 + 高成本)
- 如果用户对于查询的响应时长不太关心,则会使用Automatic模式,进行自适应查询。(高性能 + 低成本)
- 如果用户对查询的响应时长有点需求,则会指定Presto模式,使用弹性Presto集群进行查询。(高性能 + 中成本)
- 如果是一些ETL等长耗时作业,则会直接指定Spark进行计算。(高稳定性 + 低成本)
所以当前需要让用户通过在DDL时指定对应的表模型来满足具体的需求,例如想要极致的查询性能就选择默认虚拟表,想要低成本就选择天穹数据仓库原生的表,想要达到高性能兼具低成本就选择自适应冷热虚拟表(后续支持);后续演化我们会在上面进一步抽象、完善虚拟表的能力,达到完全自适应平衡性能和成本。
优势:抽象出虚拟表层,让用户不用关心底层的异构系统,专注于自己的业务,后台自适应提效,以达到降本提效的目的。
创新点: 屏蔽底层 + 统一语义 + 一体化 + 数据库化 + 自适应优化。
已申请专利:《一种基于虚拟表在数据仓库系统上用于屏蔽异构差异和查询加速的方法》、《一种通过融合SQL引擎和元数据映射进行异构冷热存储加速查询的方法》
虚拟表当前的性能如何?
无特殊调参,媲美主流OLAP引擎
SSB Benchmark
数据准备:
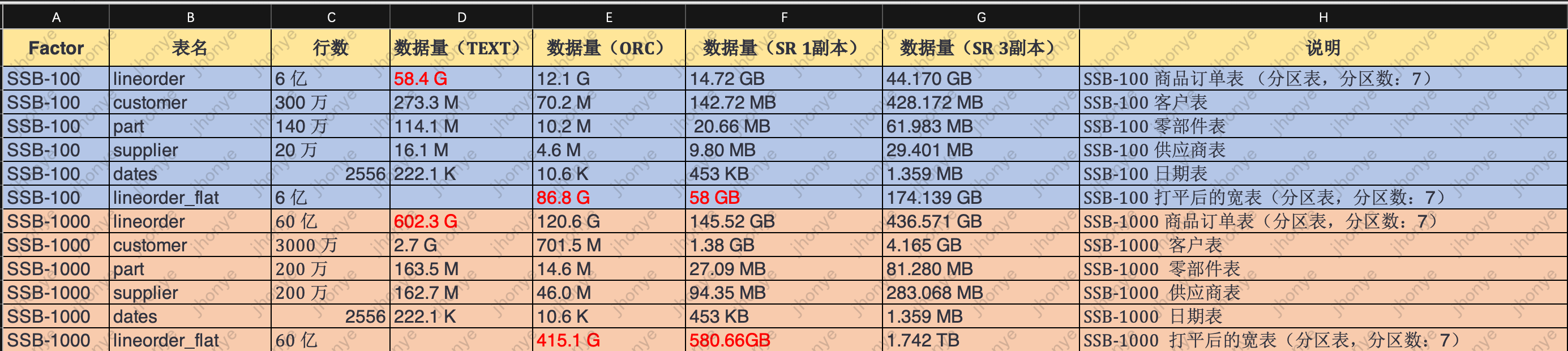
图9 SSB 6亿/60亿数据量
6亿宽表测试数据:

图10 6亿大宽表标准测试数据
说明:
- 在虚拟表集群负载较低时,单表查询性能和社区主流OLAP查询响应差不多。
- 高并发、高负载情况下,虚拟表的响应在2秒以内。
- 以上数据说明虚拟表轻松应对查询数据量在6亿级别的报表场景。
60亿宽表测试数据:
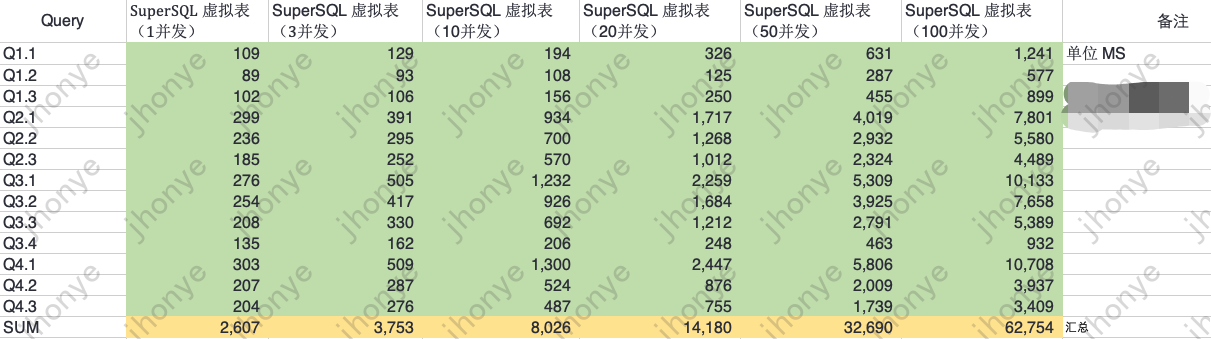
图11 60亿大宽表标准测试数据
说明:
- 在虚拟表集群负载较低时,数据量翻10倍(60亿)的单表查询性能基本都在300ms以下。
- 高并发、高负载的情况下,60亿的查询响应在平均6s以内。
- 以上数据说明虚拟表也足以应对查询数据量在60亿级别的报表场景。
6亿星型模型(多表JOIN)测试数据:
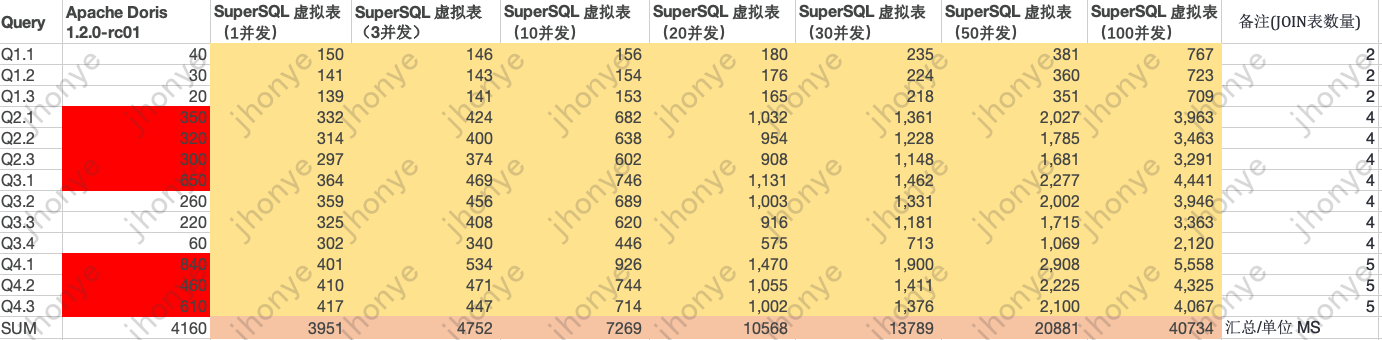
图12 6亿 星型模型标准测试数据
说明:
- 在虚拟表集群负载较低时,星型模型多表JOIN查询都在毫秒级,和主流OLAP有来有回。
- 高并发、高负载的情况下,星型模型多表JOIN查询在平均4s以内。
- 以上数据说明虚拟表轻松应对查询数据量在6亿级别的敏捷分析、Adhoc、数据集市查询分析等场景。
60亿星型模型(多表JOIN)测试数据:
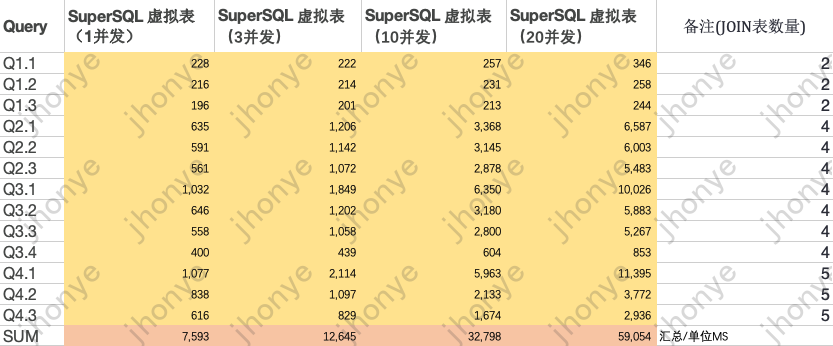
图13 60亿 星型模型标准测试数据
说明:
- 在虚拟表集群负载较低时,数据量翻10倍(60亿)星型模型多表JOIN查询都在毫秒级。
- 中并发、高负载的情况下,数据量翻10倍(60亿)星型模型多表JOIN查询在平均5s以内。
- 以上数据说明虚拟表也足以应对查询数据量在60亿级别的敏捷分析、Adhoc、数据集市查询分析等场景。
TPC-H Benchmark
数据准备:
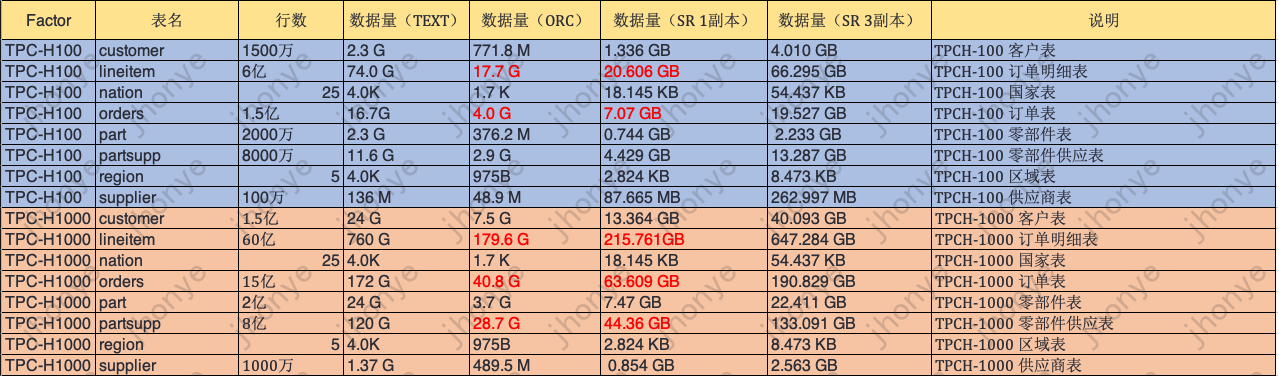
图14 TPC-H 6亿/60亿测试数据量
6亿测试数据:
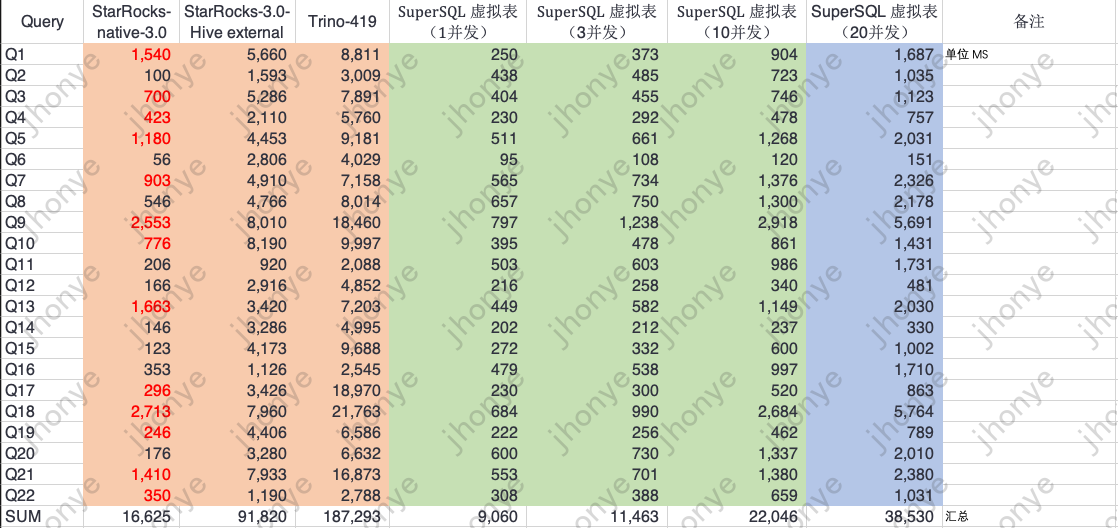
图15 TPC-H 6亿标准测试数据
说明:
- 多表JOIN查询差不多在毫秒级,和主流OLAP有来有回,比StarRocks/Trino直接查询湖数据效果好很多。
- 以上数据说明虚拟表轻松应对查询数据量在6亿级别的敏捷分析、Adhoc、数据集市查询分析等场景。
60亿测试数据:
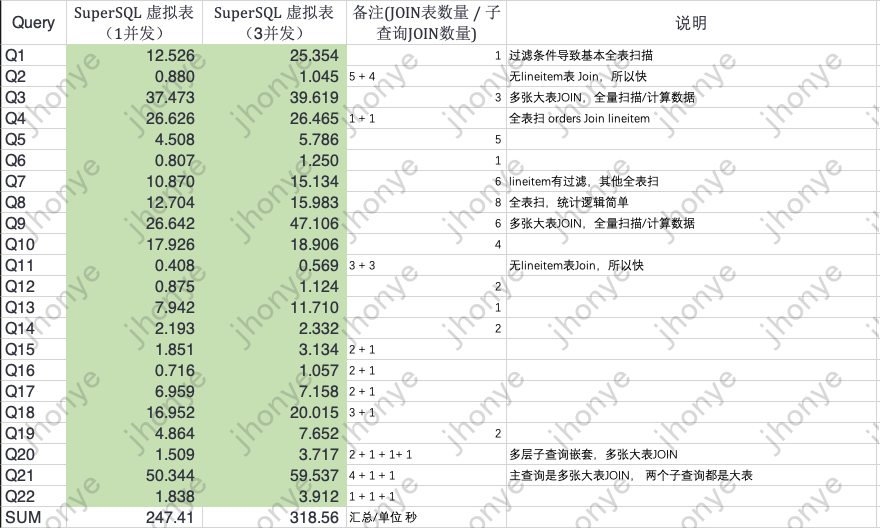
图16 TPC-H 60亿标准测试数据
说明:
- 在数据量翻10倍(60亿)复杂多表JOIN查询差不多可在1min内返回,但集群压力较大,开始影响其他查询。
- 以上数据说明虚拟表不建议进行大数据量的复杂多表JOIN查询,不建议进行ETL任务场景。
根据上述数据总结,虚拟表可媲美主流OLAP引擎
什么场景下使用虚拟表收益高?
适合场景1:数据仓库ADS层,报表场景,线上服务等
数据可视化是数据分析和决策过程中不可或缺的一环,它使数据变得更具意义和洞察力,帮助人们更好地理解和利用数据的价值。业界现在做数据可视化的产品非常多,其中BI报表是最常用的工具,业界主流的BI报表产品有小马 BI(内网BI产品)、 腾讯云 BI、阿里云 Quick BI、帆软报表 、Tableau 等,他们都支持配置数据源连接、报表展示、简单的计算等功能。
用户在对接报表时,由于传统数据仓库的查询响应、稳定性等原因,会将数据预处理后导入到StarRocks、Mysql等框架中,然后选择对应的驱动进行对接。由于报表展示的性能等原因,一般不会展示/计算过多的数据,基于这些数据的二次计算也会比较快,使用体验还是可以的。
但是上述流程上还是存在一些问题的,首先用户需要申请一个Mysql实例或者申请一个StarRocks集群,其次用户还要管理数据导入导出的任务列表,最后还得配置到报表应用中保证整个流程正确;这些流程看起来资源成本、管理成本、使用成本都是比较高的。
那么有什么解法呢?当前小马BI 已支持配置SuperSQL(天穹大数据数据仓库统一入口)作为数据源来对接TDW的表数据,用户就无需将天穹数据仓库的表数据进行预处理后导入StarRocks、Mysql等数据(仓)库中。不过还是存在一些限制的,例如暂不支持分区数大于10的查询,原因是SuperSQL使用的是 presto/spark + 天穹数据仓库存储 的方式提供查询服务,如果扫描太多的数据可能会导致报表响应太慢,而且天穹数据仓库存储一般是共享使用的可能会导致一些时候查询响应的时间超过用户的预期。
以上,虚拟表在报表场景的作用还是很明显的,用户可以使用小马BI 对接天穹数据仓库虚拟表,直接享受毫秒级的查询响应性能,无需数据倒来倒去,也不太受数据量影响(60亿/1TB数据量的查询也可以在毫秒级返回);如果数据不在虚拟表中,可以通过SQL(Insert into ... select ...)的方式将数据导入虚拟表,方便、前期和后续的维护效率也都大大提升。线上服务同理。
适合场景2: 数据仓库 DW 层,数据开发、Adhoc、敏捷分析等
业界数据仓库的架构普遍是基于分层设计的,数据会在开始阶段集成到ODS层,然后通过将数据进行预处理后导入到DW层(ETL),DW层可以根据业务的复杂度进行细分,最后到ADS层对外提供服务。数据集市这个概念可以横跨DW层到ADS层,非数据开发的用户一般都是根据自己的业务使用对应的数据集市进行分析、查询。
数据开发人员在判定某个数据集市或者某个数据模型会经常被查询或有查询响应快的需求,则会ETL到其他OLAP引擎中,例如Kylin预计算、Clickhouse宽表查询、StarRocks Adhoc等。但是这些异构的引擎引起的问题是比较多的,例如数据一致性、查询SQL无法兼容、集群资源申请、管理成本高等问题。
那么有什么解法呢?虚拟表。首先虚拟表的星型模型的多表关联查询性能优秀,6亿场景基本都是毫秒级;其次虚拟表与TDW是一体的用户无需进行特殊维护,可以像使用天穹数据仓库表一样使用虚拟表;最后SQL的兼容性更好,满足用户一条SQL查询所有数据。
当然如果你的数据小于60亿条/1TB,数据集成、生产、分析、应用等全流程都可以在虚拟表上操作,后续我们会通过自适应冷热的方案对成本和性能进行平衡,满足用户的全场景需求。
支持的场景3:冷热自适应
当前虚拟表虽然在性能上是非常优秀的,但是成本也是比较高的,对于大部分用户来说还是需要平衡性能和成本的。
那么有什么解法呢?存算分离 + 弹性计算 + 自适应冷热。
用户需要频繁查询的数据是一直在变动的,一般情况下都是近30天的情况;所以后续虚拟表会支持将用户不经常查询或者需要进行主动降冷的数据移动到更便宜的存储中,等到需要查询时可以主动Cache或者移动到热存储中应对查询,当然如果对查询性能没有需求也可以直接查询。
后续虚拟表会去支持其他表模型,例如类似Iceberg的数据湖表,虽然查询性能会比当前虚拟表差一些,但是性价比更高、存储更便宜、计算更加弹性。其实数据组织方式的升级比计算能力的提升有更好的效果,内网有个业务迁移到Iceberg数据湖存储后降本几千万。
支持的场景4: 天穹数据仓库升级
天穹数据仓库在这么多年以来支持公司内各个BG的业务,取得了非常好的业务成果。前期为了支持从Oracle转移过来的用户,开发了大量的特性,但是由于数据技术的巨大进步和国家倡导的去IOE,其中许多工作都变成历史债了。目前天穹大数据在积极的协助用户进行THive升级,在用户SQL不变的情况下,进行存储成本降低、查询性能提升。
前文讲过没有足够的“诱惑力”让用户进行升级是非常难,迁移导致的数据链路出错、业务停摆、冗余资源等问题是比较严重的。另外如场景3说明,仅在SQL和计算上兼容是不够的,数据组织方式的升级也是势在必行。如果我们可以将计算、存储层进行虚拟化,只让用户操作虚拟表,用户通过日积月累的方式一张张表进行改动和自适应升级,那么就可以在较长的时间进行慢慢迁移,业务不受影响的前提下,持续的进行降本提效。
支持的场景5: 智能物化视图
预计算在大数据领域一直都有被关注,因为随着数据量的提升,许多场景下查询性能不太能满足用户的需求。主流的预计算方案有ETL、物化视图、Cube、StarTree等,其中其中物化视图、Cube、StarTree都是支持在SQL引擎层进行改写加速的,能力范围物化视图 > Cube > StarTree。
上述提到物化视图的SQL改写能力,但是用户的SQL还是很难被改写进行提效的,因为物化视图的创建和改写之间的关系是需要长时间习得的,不是普通用户可以简单上手。而且预计算的存储膨胀率也是很夸张的,一张表创建10张物化视图,这张表极限情况下存储成本可以翻10倍。最后用户在评估后手动淘汰掉一些利用率低的物化视图,管理成本也是很高的。
那么有什么解法呢?虚拟表后续功能会支持获取用户的历史SQL流水,然后推荐出一些基于该虚拟表且性价比高的物化视图,内网已经支持了物化视图推荐功能;然后自适应的淘汰利用率、性价比低的物化视图;且支持实时更新,保证物化视图与基表的一致性。
未来目标场景
我们希望用户可以简单、易用、高效的使用天穹大数据,对接 SuperSQL + 虚拟表 就可以满足各类查询负载,且自适应平衡性能和成本。
虚拟表如何使用?
建表语法 (DDL):
use test;
CREATE VIRTUAL TABLE IF NOT EXISTS `ssb_lineorder_flat` (
`LO_ORDERDATE` INT COMMENT "",
`LO_ORDERKEY` BIGINT COMMENT "",
`LO_LINENUMBER` INT COMMENT "",
`LO_CUSTKEY` INT COMMENT "",
`LO_PARTKEY` INT COMMENT "",
`LO_SUPPKEY` INT COMMENT "",
`LO_ORDERPRIORITY` STRING COMMENT "",
`LO_SHIPPRIORITY` INT COMMENT "",
`LO_QUANTITY` INT COMMENT "",
`LO_EXTENDEDPRICE` INT COMMENT "",
`LO_ORDTOTALPRICE` INT COMMENT "",
`LO_DISCOUNT` INT COMMENT "",
`LO_REVENUE` INT COMMENT "",
`LO_SUPPLYCOST` INT COMMENT "",
`LO_TAX` INT COMMENT "",
`LO_COMMITDATE` INT COMMENT "",
`LO_SHIPMODE` STRING COMMENT "",
`C_NAME` STRING COMMENT "",
`C_ADDRESS` STRING COMMENT "",
`C_CITY` STRING COMMENT "",
`C_NATION` STRING COMMENT "",
`C_REGION` STRING COMMENT "",
`C_PHONE` STRING COMMENT "",
`C_MKTSEGMENT` STRING COMMENT "",
`S_NAME` STRING COMMENT "",
`S_ADDRESS` STRING COMMENT "",
`S_CITY` STRING COMMENT "",
`S_NATION` STRING COMMENT "",
`S_REGION` STRING COMMENT "",
`S_PHONE` STRING COMMENT "",
`P_NAME` STRING COMMENT "",
`P_MFGR` STRING COMMENT "",
`P_CATEGORY` STRING COMMENT "",
`P_BRAND` STRING COMMENT "",
`P_COLOR` STRING COMMENT "",
`P_TYPE` STRING COMMENT "",
`P_SIZE` INT COMMENT "",
`P_CONTAINER` STRING COMMENT ""
)
PARTITION BY RANGE(`LO_ORDERDATE`)
(
PARTITION p1 VALUES LESS THAN (19930101),
PARTITION p2 VALUES LESS THAN (19940101),
PARTITION p3 VALUES LESS THAN (19950101),
PARTITION p4 VALUES LESS THAN (19960101),
PARTITION p5 VALUES LESS THAN (19970101),
PARTITION p6 VALUES LESS THAN (19980101),
PARTITION p7 VALUES LESS THAN (19990101)
)
CLUSTERED BY(`LO_ORDERKEY`) SORTED BY(`LO_ORDERDATE`,`LO_ORDERKEY`) INTO 120 BUCKETS;分区操作语法 (DDL):
use test;
alter table test.ssb_lineorder_flat add partition par_name4 VALUES IN (20230804);
alter table test.ssb_lineorder_flat add partition part_20230103 VALUES LESS THAN (20230103);
alter table test.depts01 drop partition (par_name4);
alter table test.depts02 drop partition (part_20230103);写入语法(DML):
use test;
-- insert into 虚拟表 select from 天穹数据仓库表(多表/ETL场景)
INSERT OVERWRITE ssb_lineorder_flat SELECT * FROM benchmark_ssb_lineorder_flat_raw;
INSERT OVERWRITE ssb_lineorder_flat
SELECT `LO_ORDERDATE` , `LO_ORDERKEY` , `LO_LINENUMBER` , `LO_CUSTKEY` , `LO_PARTKEY` , `LO_SUPPKEY` , `LO_ORDERPRIORITY` , `LO_SHIPPRIORITY` , `LO_QUANTITY` , `LO_EXTENDEDPRICE` , `LO_ORDTOTALPRICE` , `LO_DISCOUNT` , `LO_REVENUE` , `LO_SUPPLYCOST` , `LO_TAX` , `LO_COMMITDATE` , `LO_SHIPMODE` , `C_NAME` , `C_ADDRESS` , `C_CITY` , `C_NATION` , `C_REGION` , `C_PHONE` , `C_MKTSEGMENT` , `S_NAME` , `S_ADDRESS` , `S_CITY` , `S_NATION` , `S_REGION` , `S_PHONE` , `P_NAME` , `P_MFGR` , `P_CATEGORY` , `P_BRAND` , `P_COLOR` , `P_TYPE` , `P_SIZE` , `P_CONTAINER`
FROM (
SELECT lo_orderkey,lo_linenumber,lo_custkey,lo_partkey,lo_suppkey,lo_orderdate,lo_orderpriority,lo_shippriority,lo_quantity,lo_extendedprice,lo_ordtotalprice,lo_discount,lo_revenue,lo_supplycost,lo_tax,lo_commitdate,lo_shipmode
FROM benchmark_ssb_lineorder_1000_raw
) l
INNER JOIN benchmark_ssb_customer_1000_raw c ON (c.C_CUSTKEY = l.LO_CUSTKEY)
INNER JOIN benchmark_ssb_supplier_1000_raw s ON (s.S_SUPPKEY = l.LO_SUPPKEY)
INNER JOIN benchmark_ssb_part_1000_raw p ON (p.P_PARTKEY = l.LO_PARTKEY);查询语法 (DQL):
use test;
--Q1.1
SELECT sum(lo_extendedprice * lo_discount) AS `revenue`
FROM ssb_lineorder_flat
WHERE lo_orderdate >= '19930101' and lo_orderdate <= '19931231'
AND lo_discount BETWEEN 1 AND 3 AND lo_quantity < 25;
--Q1.2
SELECT sum(lo_extendedprice * lo_discount) AS revenue
FROM ssb_lineorder_flat
WHERE lo_orderdate >= '19940101' and lo_orderdate <= '19940131'
AND lo_discount BETWEEN 4 AND 6 AND lo_quantity BETWEEN 26 AND 35;
--Q1.3
SELECT sum(lo_extendedprice * lo_discount) AS revenue
FROM ssb_lineorder_flat
WHERE weekofyear(lo_orderdate) = 6
AND lo_orderdate >= '19940101' and lo_orderdate <= '19941231'
AND lo_discount BETWEEN 5 AND 7 AND lo_quantity BETWEEN 26 AND 35;
--Q2.1
SELECT sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q2.2
SELECT
sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_brand >= 'MFGR#2221' AND p_brand <= 'MFGR#2228' AND s_region = 'ASIA'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q2.3
SELECT sum(lo_revenue), year(lo_orderdate) AS year_col, p_brand
FROM ssb_lineorder_flat
WHERE p_brand = 'MFGR#2239' AND s_region = 'EUROPE'
GROUP BY year(lo_orderdate), p_brand
ORDER BY year(lo_orderdate), p_brand;
--Q3.1
SELECT
c_nation,
s_nation,
year(lo_orderdate) AS year_col,
sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_region = 'ASIA' AND s_region = 'ASIA' AND lo_orderdate >= '19920101'
AND lo_orderdate <= '19971231'
GROUP BY c_nation, s_nation, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.2
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_nation = 'UNITED STATES' AND s_nation = 'UNITED STATES'
AND lo_orderdate >= '19920101' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.3
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_city in ( 'UNITED KI1' ,'UNITED KI5') AND s_city in ('UNITED KI1', 'UNITED KI5')
AND lo_orderdate >= '19920101' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q3.4
SELECT c_city, s_city, year(lo_orderdate) AS year_col, sum(lo_revenue) AS revenue
FROM ssb_lineorder_flat
WHERE c_city in ('UNITED KI1', 'UNITED KI5') AND s_city in ('UNITED KI1', 'UNITED KI5')
AND lo_orderdate >= '19971201' AND lo_orderdate <= '19971231'
GROUP BY c_city, s_city, year(lo_orderdate)
ORDER BY year(lo_orderdate) ASC, revenue DESC;
--Q4.1
SELECT year(lo_orderdate) AS year_col, c_nation, sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE c_region = 'AMERICA' AND s_region = 'AMERICA' AND p_mfgr in ('MFGR#1', 'MFGR#2')
GROUP BY year(lo_orderdate), c_nation
ORDER BY year(lo_orderdate) ASC, c_nation ASC;
--Q4.2
SELECT year(lo_orderdate) AS year_col,
s_nation, p_category, sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE c_region = 'AMERICA' AND s_region = 'AMERICA'
AND lo_orderdate >= '19970101' and lo_orderdate <= '19981231'
AND p_mfgr in ( 'MFGR#1' , 'MFGR#2')
GROUP BY year(lo_orderdate), s_nation, p_category
ORDER BY year(lo_orderdate) ASC, s_nation ASC, p_category ASC;
--Q4.3
SELECT year(lo_orderdate) AS year_col, s_city, p_brand,
sum(lo_revenue - lo_supplycost) AS profit
FROM ssb_lineorder_flat
WHERE s_nation = 'UNITED STATES'
AND lo_orderdate >= '19970101' and lo_orderdate <= '19981231'
AND p_category = 'MFGR#14'
GROUP BY year(lo_orderdate), s_city, p_brand
ORDER BY year(lo_orderdate) ASC, s_city ASC, p_brand ASC; 综述
本文讲述了天穹大数据如何基于 Data Fabric 架构方法论去建构下一代大数据架构的第一阶段,通过实现虚拟表来屏蔽底层异构来满足业务需求,达到降低用户使用成本提高使用效率的目的。开篇两个主流的湖仓一体架构是当前都比较火热且优秀的,但天穹大数据当前的业务场景是非常复杂的,可在许多业务场景上使用他们,但还有许多场景无法满足需求,即我们需要一套能力更泛化的湖仓一体满足降本提效的需求,即天穹OS-虚拟表。
虚拟表短期想达到的目标:
- 支持天穹数据仓库极速查询场景
- 一条 SQL 查询天穹数据仓库所有数据,无数据孤岛、体验一体化
- 根据用户指定的成本提供查询体验(速度、稳定性、一致性等)
- 天穹数据仓库无痛升级
参考
[3] 数据虚拟化 Wikipedia 链接
[4] 数据虚拟化产品 denodo 链接
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号