聊聊Transform模型


概述
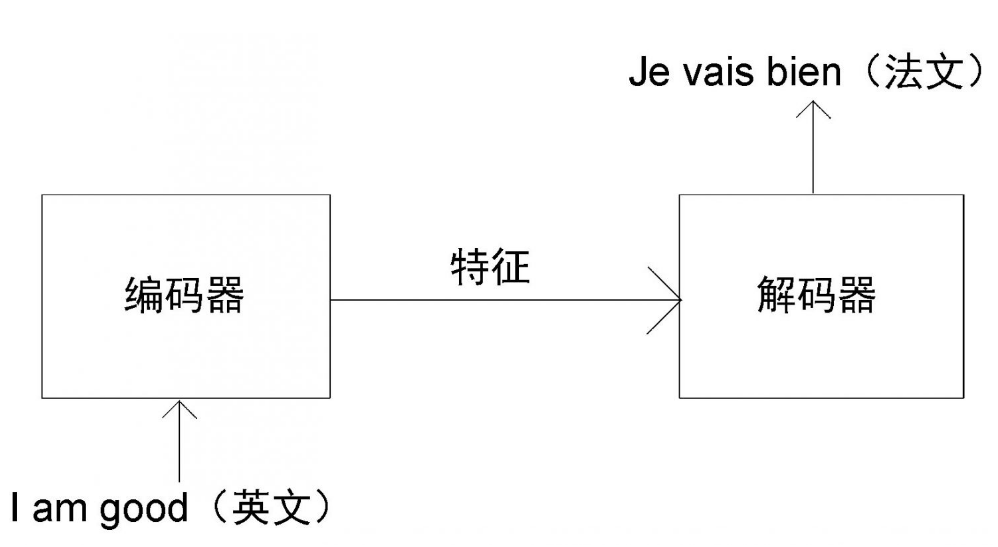
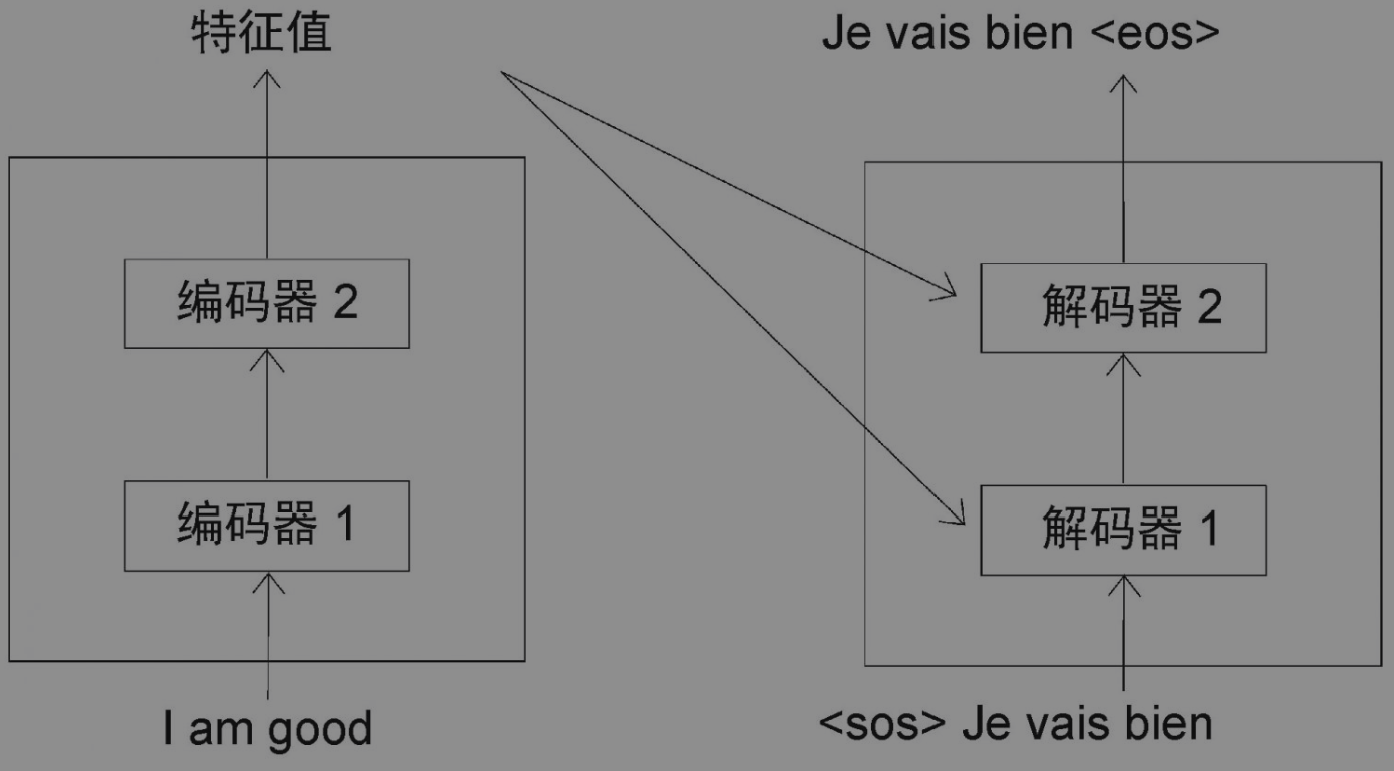
循环神经网络和长短期记忆网络已经广泛应用于时序任务,比如文本预测、机器翻译、文章生成等。然而,它们面临的一大问题就是如何记录长期依赖。 为了解决这个问题,一个名为Transformer的新架构应运而生。从那以后,Transformer被应用到多个自然语言处理方向,到目前为止还未有新的架构能够将其替代。可以说,它的出现是自然语言处理领域的突破,并为新的革命性架构(BERT、GPT-3、T5等)打下了理论基础。 Transformer由编码器和解码器两部分组成。首先,向编码器输入一句话(原句),让其学习这句话的特征,再将特征作为输入传输给解码器。最后,此特征会通过解码器生成输出句(目标句)。 假设我们需要将一个句子从英文翻译为法文。如图所示,首先,我们需要将这个英文句子(原句)输进编码器。编码器将提取英文句子的特征并提供给解码器。最后,解码器通过特征完成法文句子(目标句)的翻译。
具体模型结构如下图。
编码器
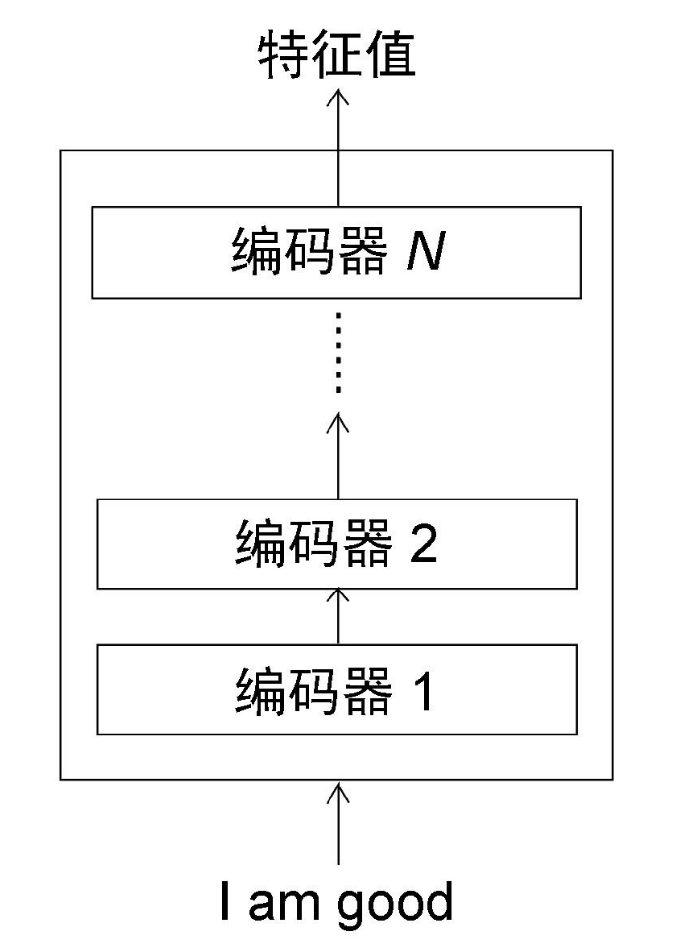
Transformer中的编码器不止一个,而是由一组编码器串联而成。一个编码器的输出作为下一个编码器的输入。在图中有个编码器,每一个编码器都从下方接收数据,再输出给上方。以此类推,原句中的特征会由最后一个编码器输出。编码器模块的主要功能就是提取原句中的特征。
编码器内部又是由多头注意力层与前馈网络层两部分组成。
多头注意力层
引入自注意力机制
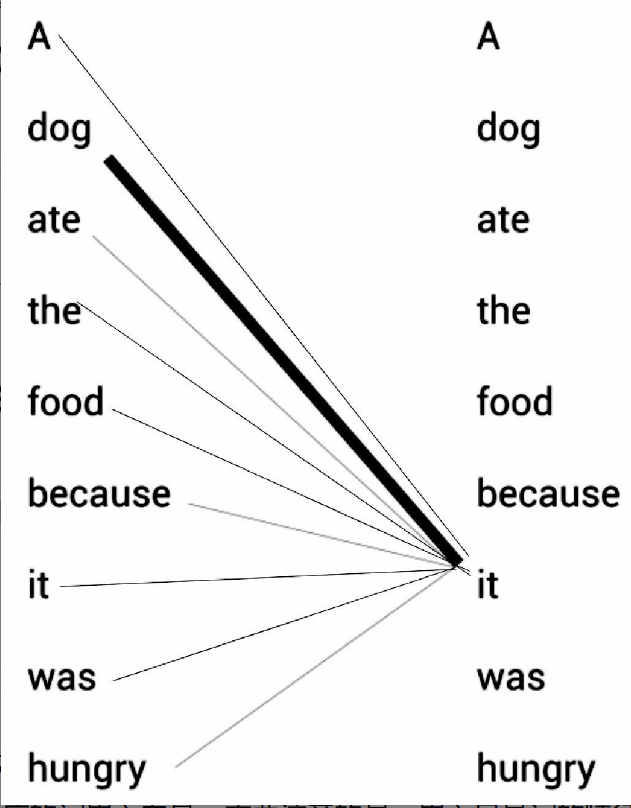
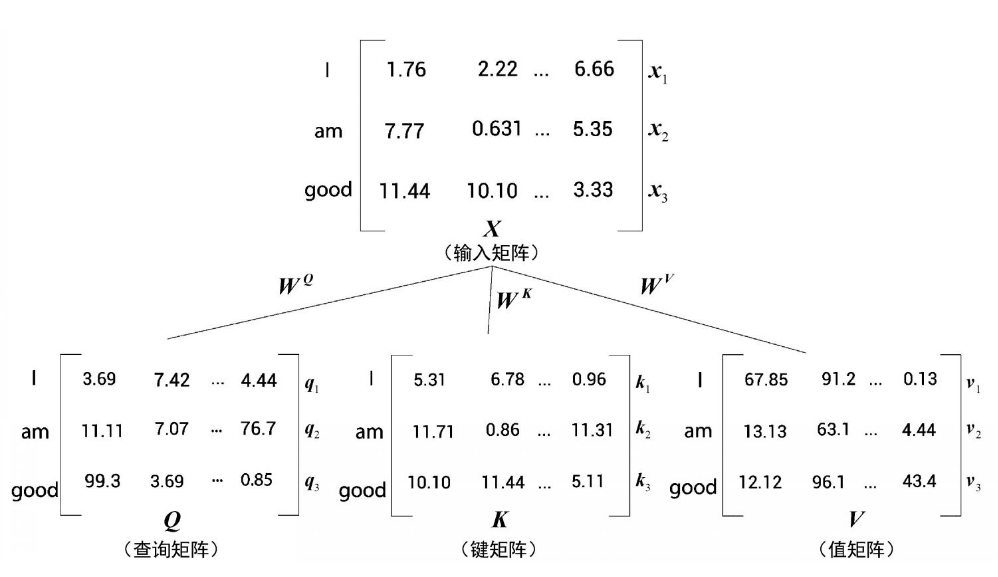
多头注意力层又是依赖于自注意力机制实现。 请看下面的例句: A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿) 例句中的代词it(它)可以指代dog(狗)或者food(食物)。当读这段文字的时候,我们自然而然地认为it指代的是dog,而不是food。但是当计算机模型在面对这两种选择时该如何决定呢?这时,自注意力机制有助于解决这个问题。 模型首先需要计算出单词A的特征值,其次计算dog的特征值,然后计算ate的特征值,以此类推。当计算每个词的特征值时,模型都需要遍历每个词与句子中其他词的关系。模型可以通过词与词之间的关系来更好地理解当前词的意思。 比如,当计算it的特征值时,模型会将it与句子中的其他词一一关联,以便更好地理解它的意思。 如图所示,it的特征值由它本身与句子中其他词的关系计算所得。通过关系连线,模型可以明确知道原句中it所指代的是dog而不是food,这是因为it与dog的关系更紧密,关系连线相较于其他词也更粗。
实现原理
为简单起见,我们假设输入句(原句)为I am good(我很好)。首先,我们将每个词转化为其对应的词嵌入向量。需要注意的是,嵌入只是词的特征向量,这个特征向量也是需要通过训练获得的。单词I的词嵌入向量可以用来表示,相应地,am为,good为,即:
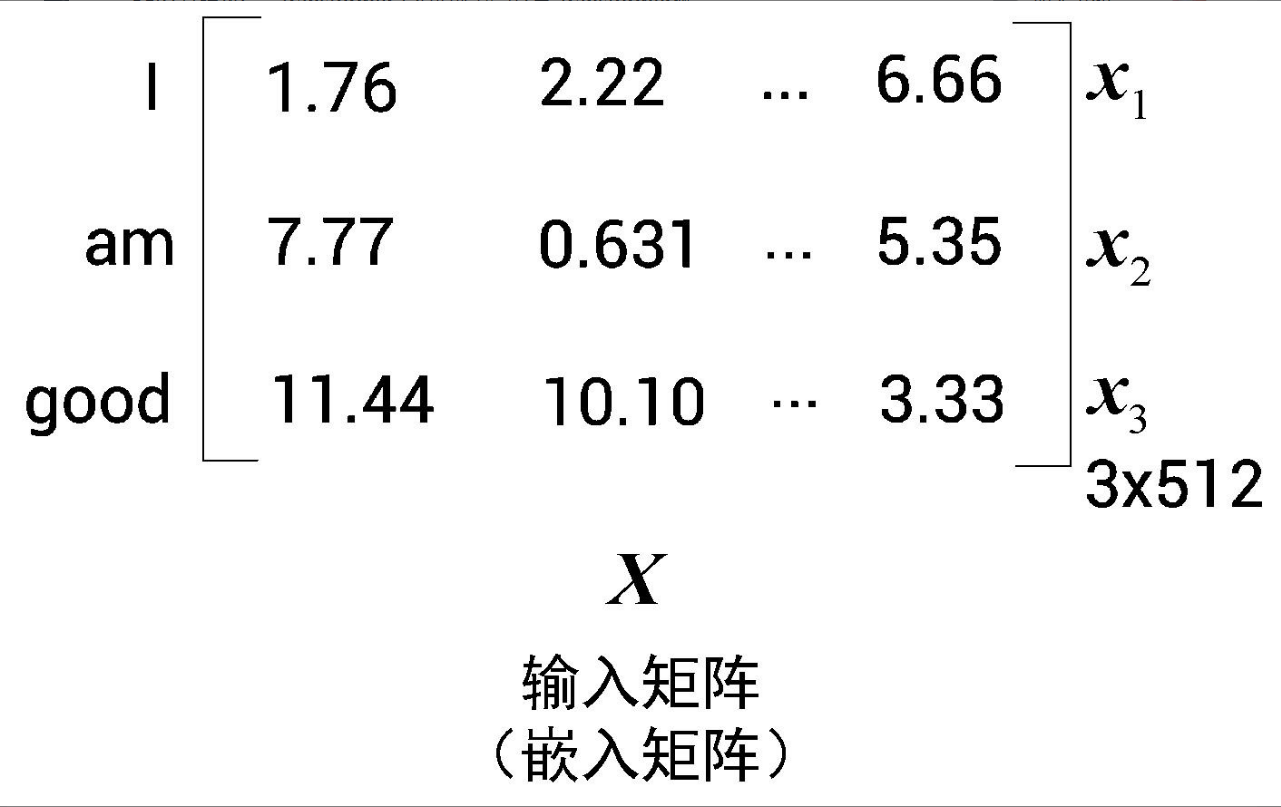
通过输入矩阵X,可以看出,矩阵的第一行表示单词I的词嵌入向量。以此类推,第二行对应单词am的词嵌入向量,第三行对应单词good的词嵌入向量。所以矩阵X的维度为[句子的长度×词嵌入向量维度]。原句的长度为3,假设词嵌入向量维度为512,那么输入矩阵的维度就是[3×512];该矩阵对应的张量表示,可以拆分如下:
a = numpy.array([[1.76, 2.22, ..., 6.66],
[7.77, 0.631,..., 5.35],
[11.44, 10.10,..., 3.33]
])增加额外的三个权重矩阵,分别为
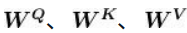
;用输入矩阵X分别乘以
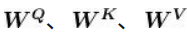
,依次创建出查询矩阵Q、键矩阵K、值矩阵V。 需要注意的是,权重矩阵
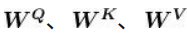
的初始值完全是随机的,但最优值则需要通过训练所得。 将输入矩阵[插图]分别乘以
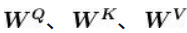
后,我们就可以得出对应的查询矩阵、键矩阵和值矩阵。
Q,K,V三个向量矩阵,代表了对输入序列中的每个位置或词的不同信息。
- Query向量 (Q):
- Query向量是自注意力机制中用于询问其他位置或词信息的向量。
- 每个位置或词都有一个对应的Query向量,该向量用于查询其他位置或词的重要程度,以便计算每个位置或词的注意力权重。
- Key向量 (K):
- Key向量用于标识每个位置或词的重要特征。
- 每个位置或词都有一个对应的Key向量,该向量对应了该位置或词的特征,用于与Query向量比较,以计算注意力权重。
- Value向量 (V):
- Value向量用于存储每个位置或词的信息。
- 每个位置或词都有一个对应的Value向量,该向量包含了该位置或词的信息,用于根据注意力权重加权求和得到该位置或词的输出。
理解自注意力机制
第一步
要计算一个词的特征值,自注意力机制会使该词与给定句子中的所有词联系起来。还是以I am good这句话为例。为了计算单词I的特征值,我们将单词I与句子中的所有单词一一关联,如图所示。
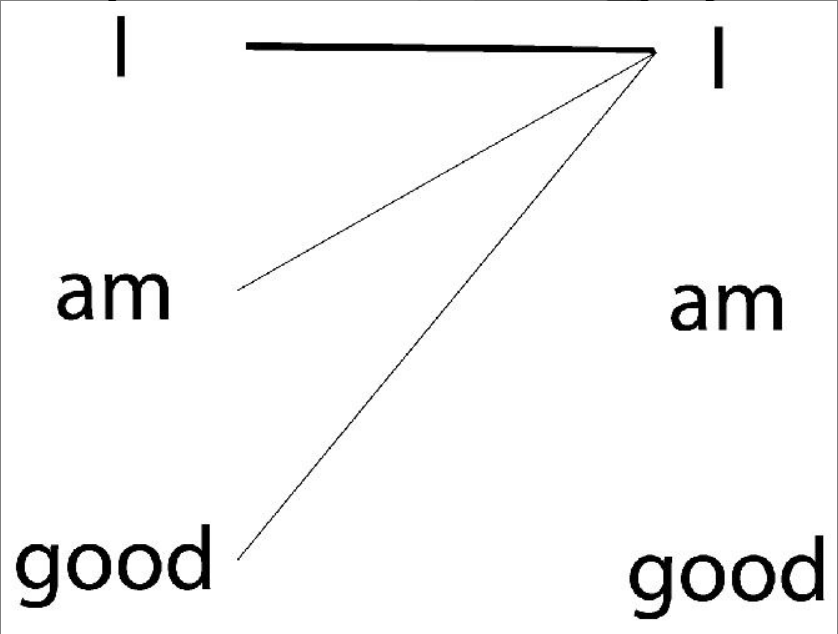
自注意力机制首先要计算查询矩阵Q与键矩阵K的点积:
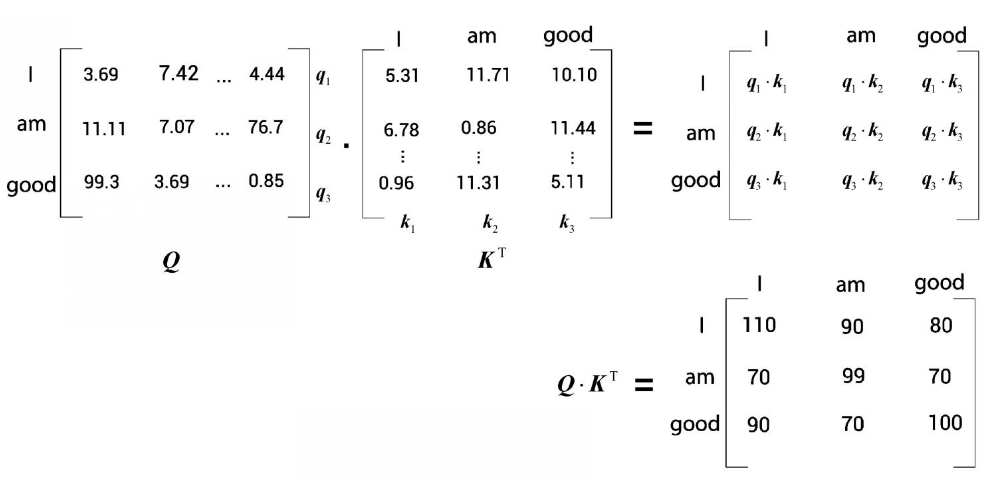
通过计算查询

的点积,可以了解单词I与句子中的所有单词的相似度。 综上所述,计算查询矩阵[插图]与键矩阵[插图]的点积,从而得到相似度分数。这有助于我们了解句子中每个词与所有其他词的相似度。
第二步
自注意力机制的第2步是将
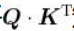
矩阵除以键向量维度的平方根。这样做的目的主要是获得稳定的梯度。
为什么要除以dk(键向量维度的平方根),其实是在做一个标准化以及防止softmax函数梯度消失的处理。 参考:为什么在进行softmax之前需要对attention进行scaled(为什么除以 d_k的平方根)
第三步
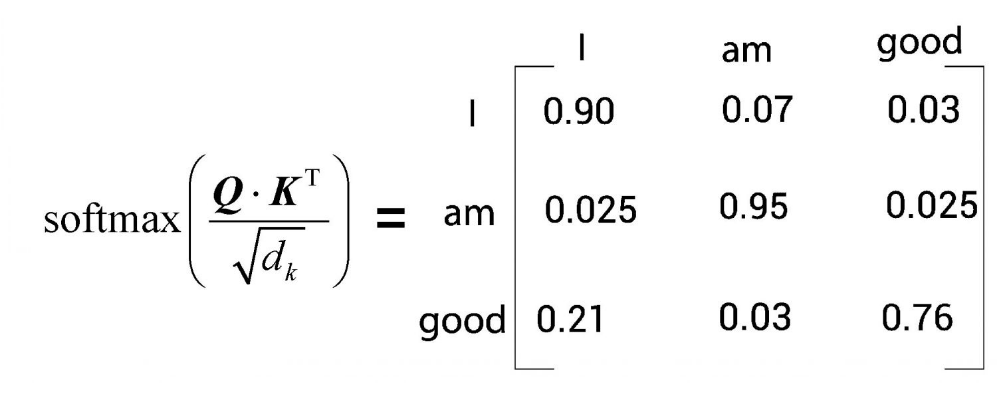
目前所得的相似度分数尚未被归一化,我们需要使用softmax函数对其进行归一化处理。如图所示,应用softmax函数将使数值分布在0到1的范围内,且每一行的所有数之和等于1。
第四步
至此,我们计算了查询矩阵与键矩阵的点积,得到了分数,然后用softmax函数将分数归一化。自注意力机制的最后一步是计算注意力矩阵[插图]。注意力矩阵包含句子中每个单词的注意力值。它可以通过将分数矩阵softmax (
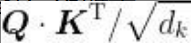
)乘以值矩阵V得出,如图所示。

假设计算结果如下所示:
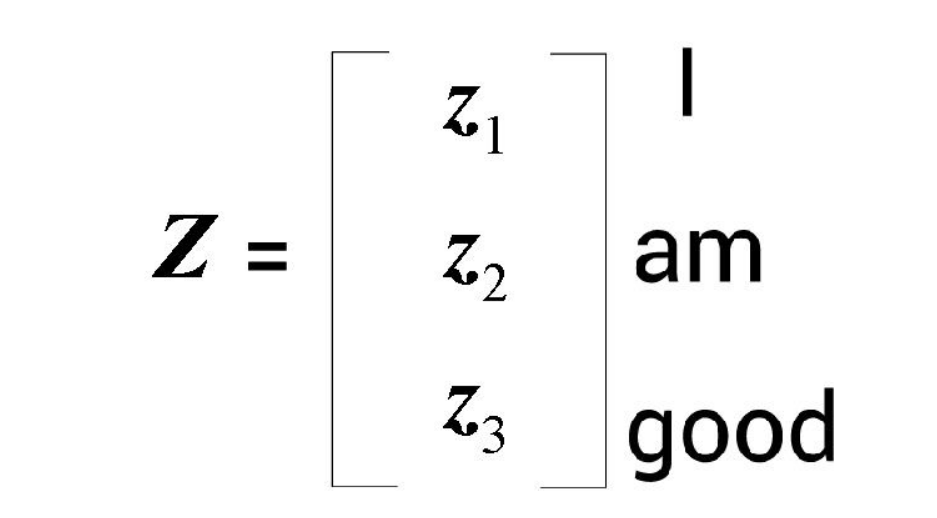
我们回过头去看之前的例句:A dog ate the food because it was hungry(一只狗吃了食物,因为它很饿)。在这里,it这个词表示dog。我们将按照前面的步骤来计算it这个词的自注意力值。假设计算过程如图所示。

可以看出,it这个词的自注意力值包含100%的值向量v2(dog)。这有助于模型理解it这个词实际上指的是dog而不是food。这也再次说明,通过自注意力机制,我们可以了解一个词与句子中所有词的相关程度。 综上所述,注意力矩阵Z由句子中所有单词的自注意力值组成,它的计算公式如下。
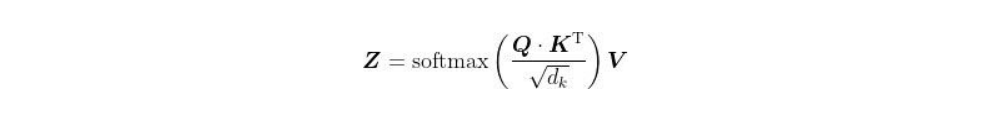
现将自注意力机制的计算步骤总结如下:

自注意力机制的计算流程图如图所示。
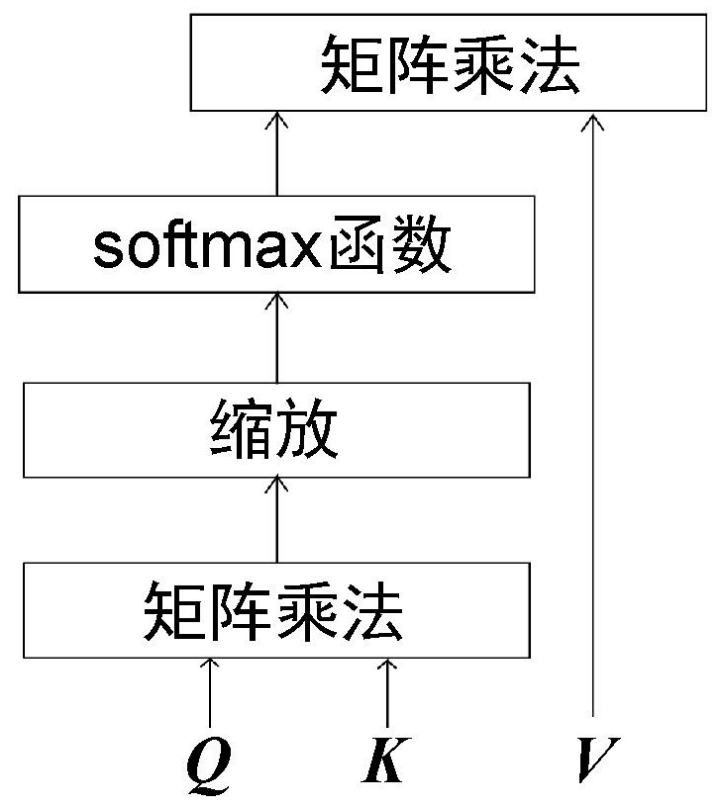
自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用dk对结果进行缩放。总结来说,自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。
多头注意力
如上是单个注意力矩阵的计算流程。使用多头注意力的逻辑是这样的:使用多个注意力矩阵,而非单一的注意力矩阵,可以提高注意力矩阵的准确性。接着上述已计算的Z1注意力矩阵,接下来计算第二个注意力矩阵Z2。

同样,我们可以计算出h个注意力矩阵,将它们串联起来。然后,将结果乘以一个新的权重矩阵W,得出最终的注意力矩阵,如下所示。

如此设计,就形成了多头注意力层。
位置编码
还是以I am good(我很好)为例。在RNN模型中,句子是逐字送入学习网络的。换言之,首先把I作为输入,接下来是am,以此类推。通过逐字地接受输入,学习网络就能完全理解整个句子。然而,Transformer网络并不遵循递归循环的模式,而是并行输入有助于缩短训练时间,同时有利于学习长期依赖。 如果把输入矩阵X直接传给Transformer,那么模型是无法理解词序的。因此,需要添加一些表明词序(词的位置)的信息,以便神经网络能够理解句子的含义。所以,我们不能将输入矩阵直接传给Transformer。这里引入了一种叫作位置编码的技术,以达到上述目的。顾名思义,位置编码是指词在句子中的位置(词序)的编码。 位置编码矩阵[插图]的维度与输入矩阵[插图]的维度相同。在将输入矩阵直接传给Transformer之前,我们将使其包含位置编码。我们只需将位置编码矩阵P添加到输入矩阵X中,再将其作为输入送入神经网络,如图所示。这样一来,输入矩阵不仅有词的嵌入值,还有词在句子中的位置信息。

位置编码矩阵究竟是如何计算的呢?如下所示,Transformer论文“Attention Is All You Need”的作者使用了正弦函数来计算位置编码:
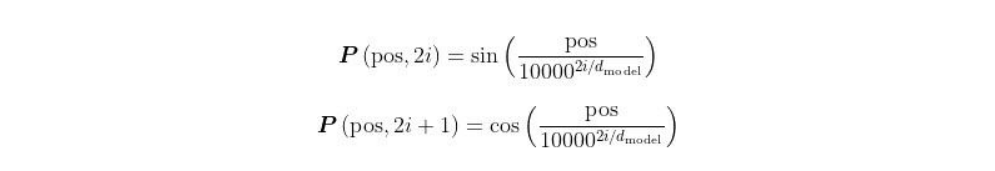
在上面的等式中,pos表示该词在句子中的位置,i表示在输入矩阵中的位置。
前馈网络层
前馈网络由两个有ReLU激活函数的全连接层(Full Connection FC层)组成。前馈网络的参数在句子的不同位置上是相同的,但在不同的编码器模块上是不同的。
叠加和归一组件
同时连接一个子层的输入与输出。
- 同时连接多头注意力的输入与输出
- 同时连接前馈网络层的输入和输出
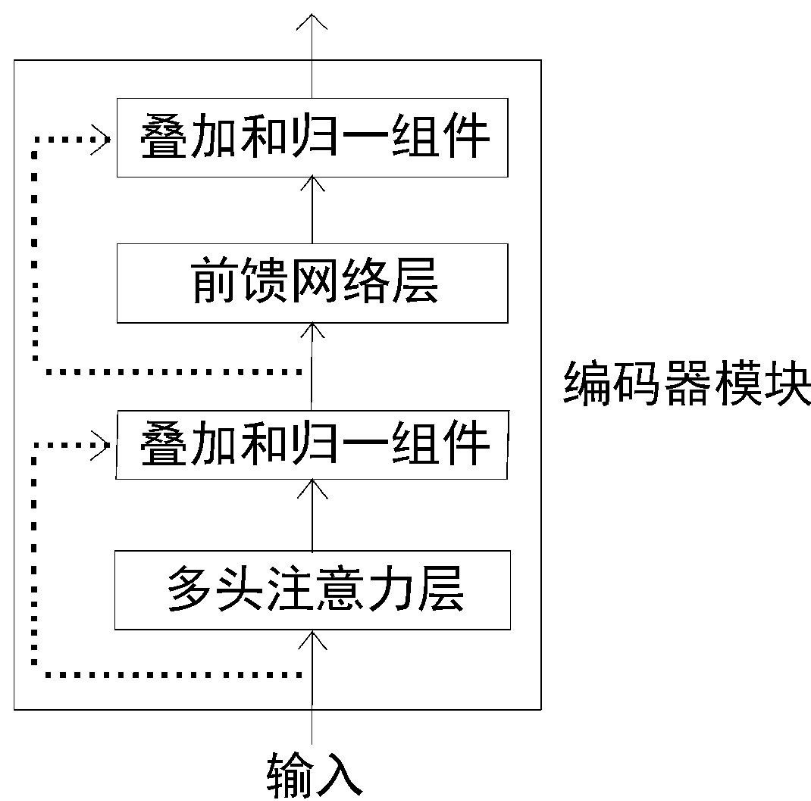
叠加和归一组件,包含一个残差连接层与层的归一化。层的归一化可以防止每层的值剧烈变化,从而提高模型的训练速度。
残差连接层
残差网络,主要是引入了一种称为“跳跃连接”的结构。所谓“跳跃连接”是指将前面层的输出通过一条“快速通道”直接传递到当前层之后。也就是说,当前层的输入不仅来自前一 层,还包含了前面层未修改的信息。 这种结构的效果是,每一层只需要学习输入和输出的差异部分,也就是“残差”。
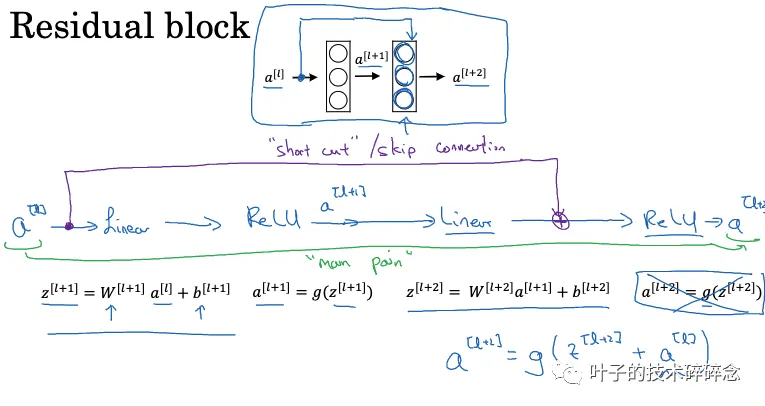
在编码器模块中,残差连接层的作用可以概括为以下几点:
- 梯度传播:
- 残差连接使得梯度可以更容易地传播回较早的层,尤其在深度网络中。梯度可以通过跳跃连接传播到前面的层,减轻了梯度消失或梯度爆炸的影响。
- 模型收敛速度:
- 残差连接加速了模型的收敛速度,特别是对于深层网络。通过跳过层间的非线性变换,模型可以更快地逼近目标函数。
- 模型简化和训练稳定性:
- 残差连接简化了模型,使其更易于训练和调试。它允许每个模块集中学习残差,而不是必须直接拟合目标映射,这有助于减轻优化难度。
- 避免信息丢失:
- 残差连接确保了原始信息不会在网络中丢失。即使网络中的变换丢失了某些特征,残差连接仍可以恢复这些特征,从而有助于网络学习到更好的特征表示。
层的归一化
指的是层归一化(Layer Normalization)或批归一化(Batch Normalization),用于对模型的中间表示进行归一化,有助于加速训练、提高模型的稳定性和泛化能力。 具体来说,归一化层的作用如下:
- 加速训练:
- 归一化可以加速神经网络的训练过程。通过将每个特征的分布归一化为均值为0和方差为1,避免了特征值过大或过小,有助于梯度传播更顺利,加快了模型的收敛速度。
- 提高模型稳定性:
- 归一化可以增强模型对输入数据分布的稳定性,使得模型对输入的小变化不敏感,有助于模型更稳定地处理不同的输入数据。
- 避免梯度消失或梯度爆炸:
- 归一化有助于避免梯度消失或梯度爆炸问题。特别是对于深层网络,梯度消失或梯度爆炸很常见,而归一化可以一定程度上缓解这些问题。
- 提高泛化能力:
- 归一化有助于模型更好地泛化到未见过的数据上,减少了模型对数据分布的敏感度,从而提高了模型的泛化能力。
解码器
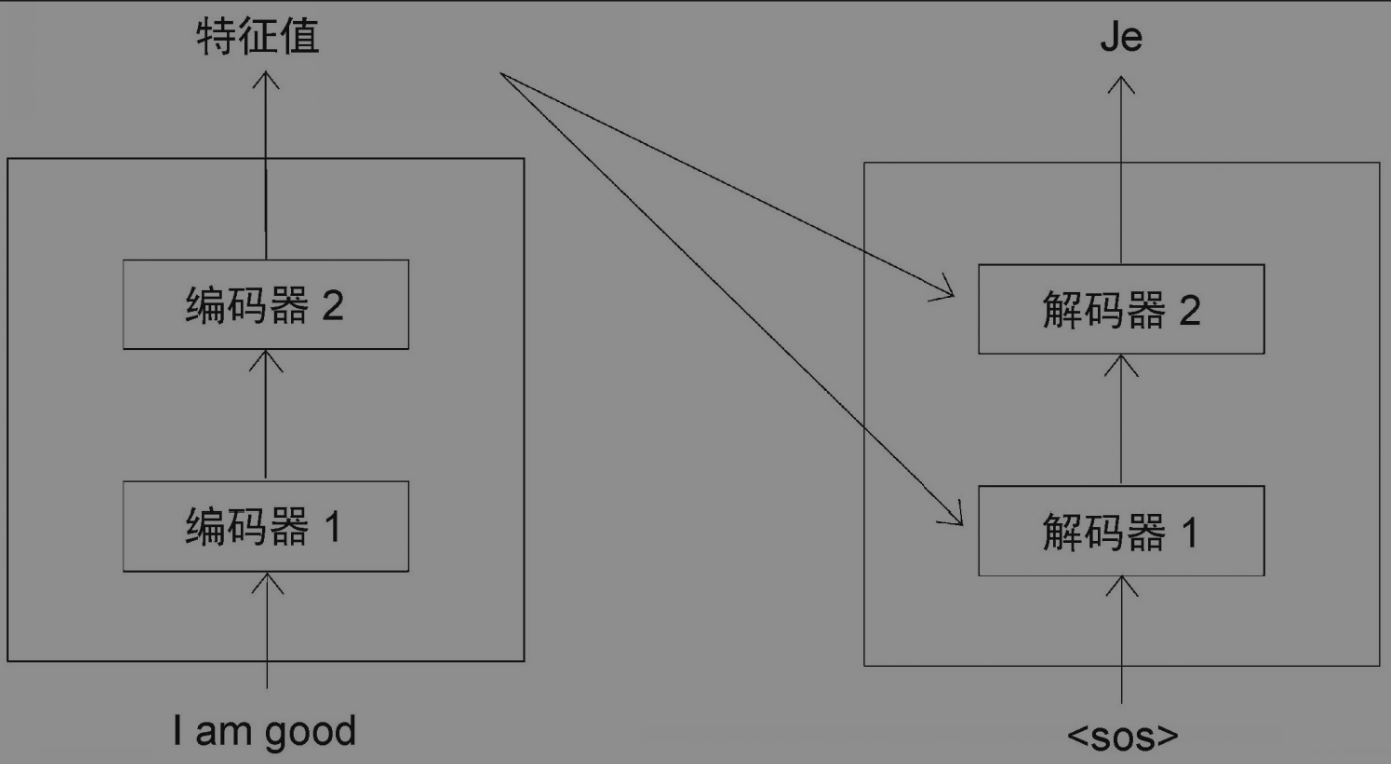
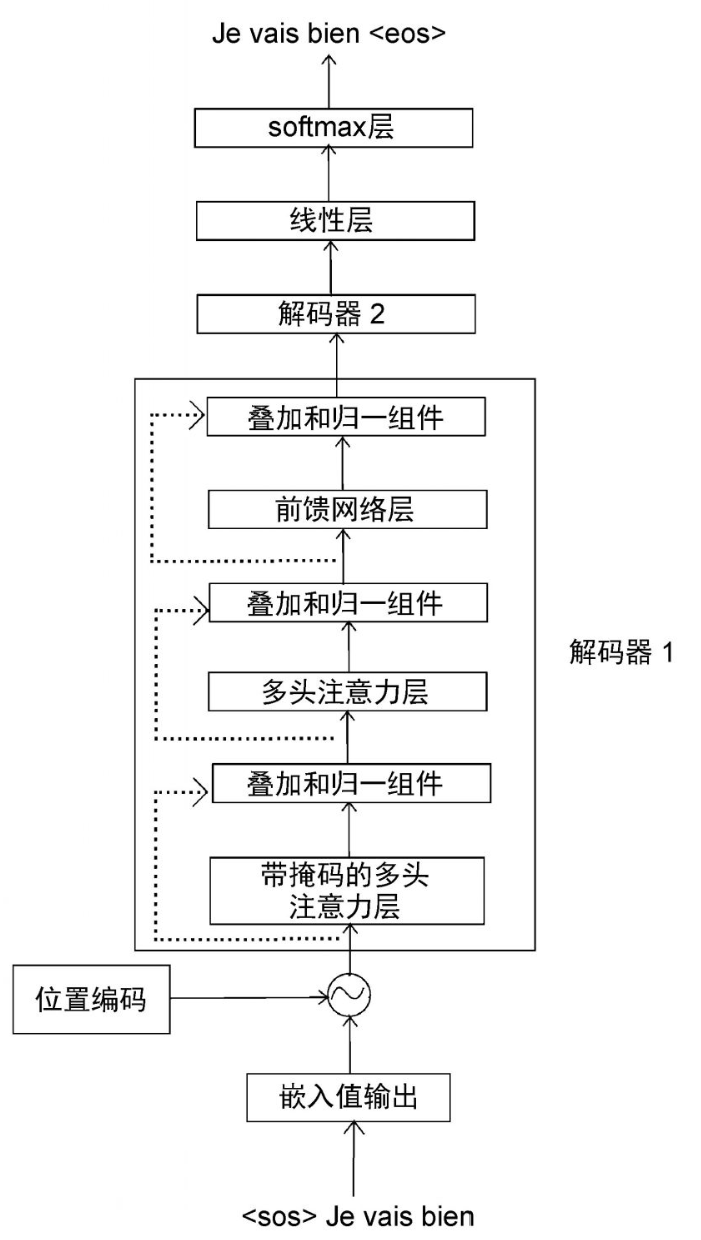
编码器计算了原句的特征值,解码器将特征值作为输入,最终生成目标。在每一步中,解码器将上一步新生成的单词与输入的词结合起来,并预测下一个单词。在解码器中,需要将输入转换为嵌入矩阵,为其添加位置编码,然后再送入解码器。 当t=1时(t表示时间步),解码器的输入是,这表示句子的开始。解码器收到作为输入,生成目标句中的第一个词,即Je,如图所示。
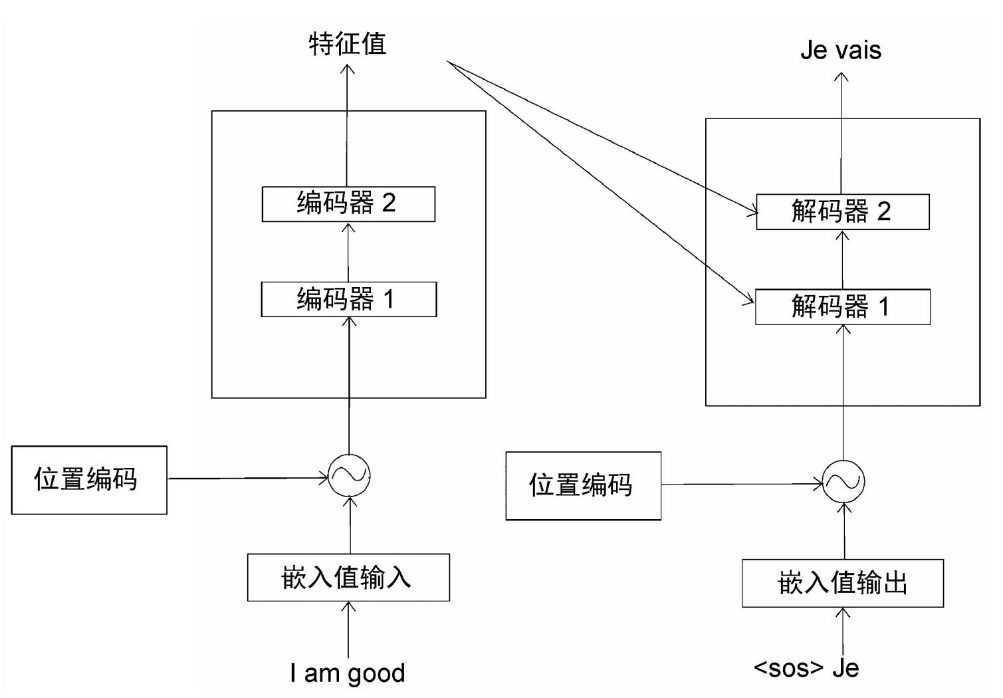
如图所示,假设在时间步t=2,我们将输入转换为嵌入(我们称之为嵌入值输出,因为这里计算的是解码器在以前的步骤中生成的词的嵌入),将位置编码加入其中,然后将其送入解码器。
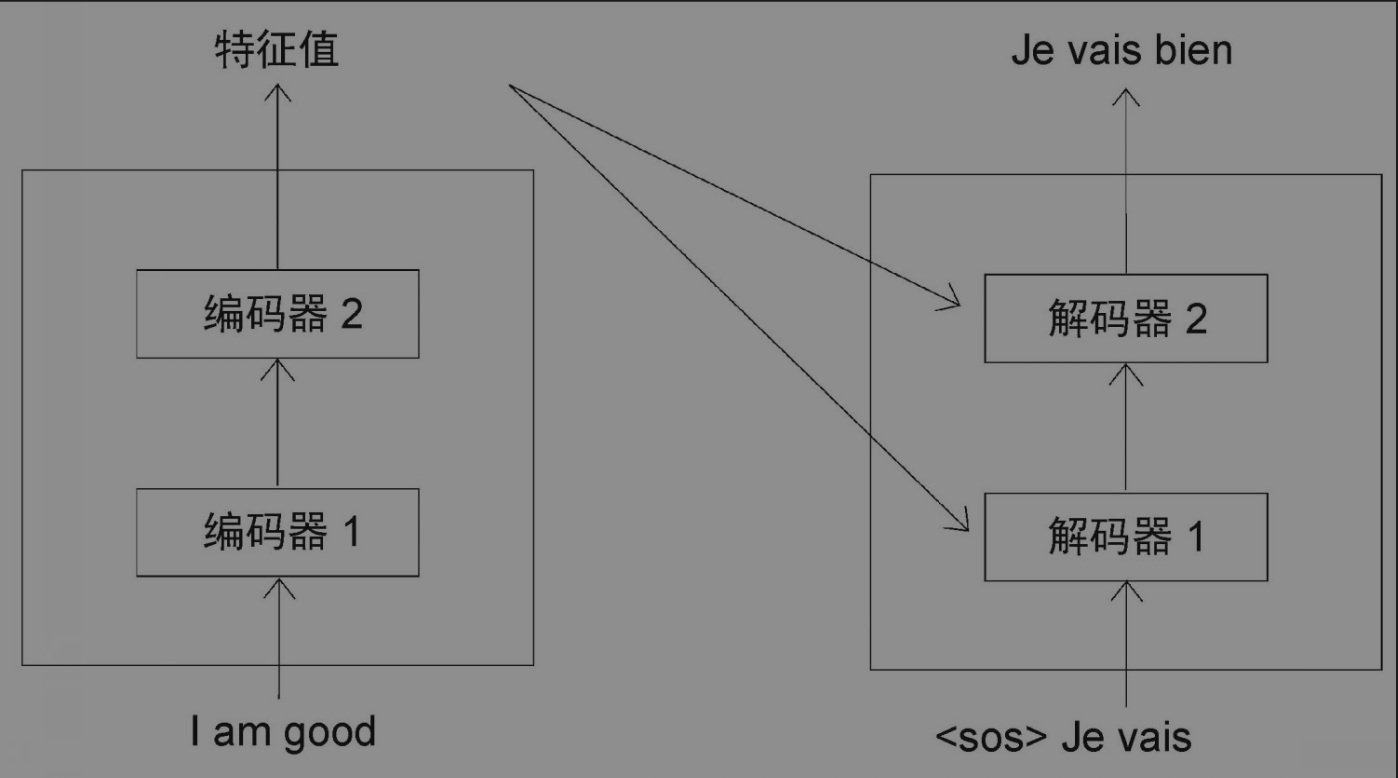
同理,你可以推断出解码器在t=3时的预测结果。此时,解码器将、Je和vais(来自上一步)作为输入,并试图生成句子中的下一个单词,如图所示。
在每一步中,解码器都将上一步新生成的单词与输入的词结合起来,并预测下一个单词。因此,在最后一步(t=4),解码器将、Je、vais和bien作为输入,并试图生成句子中的下一个单词,如图所示。
一旦生成表示句子结束的标记,就意味着解码器已经完成了对目标句的生成工作。 在编码器部分,我们将输入转换为嵌入矩阵,并将位置编码添加到其中,然后将其作为输入送入编码器。同理,我们也不是将输入直接送入解码器,而是将其转换为嵌入矩阵,为其添加位置编码,然后再送入解码器。
编码器最终输出生成的特征值,则是在解码器内部的多头注意力层引入了。这点要尤其注意。编码器的输出并不是直接作为解码器的输入。
一个解码器模块及其所有的组件如图所示。
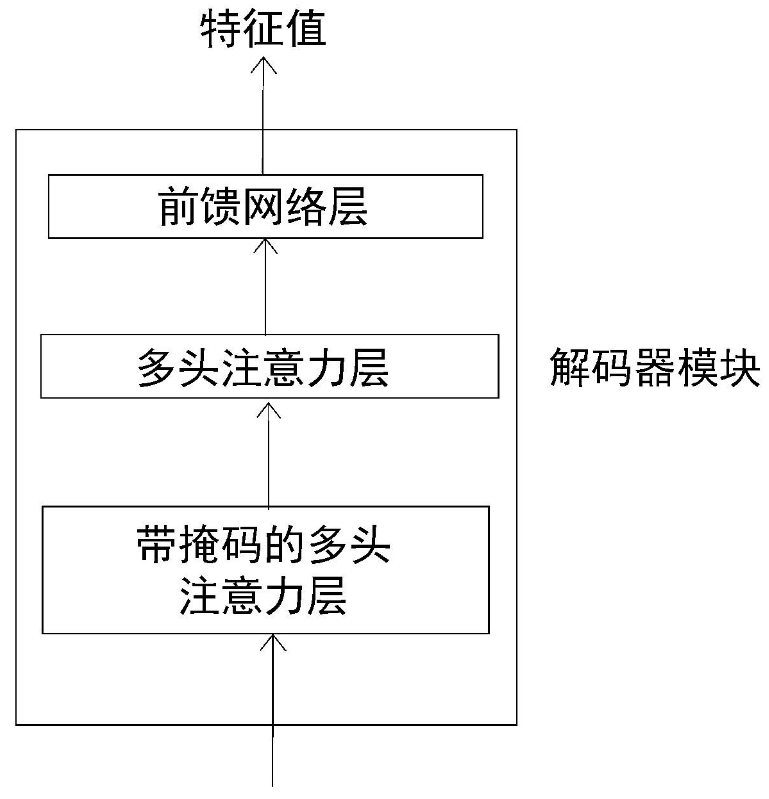
从图中可以看到,解码器内部有3个子层。
- 带掩码的多头注意力层
- 多头注意力层
- 前馈网络层
与编码器模块相似,解码器模块也有多头注意力层和前馈网络层,但多了带掩码的多头注意力层。
带掩码的多头注意力层
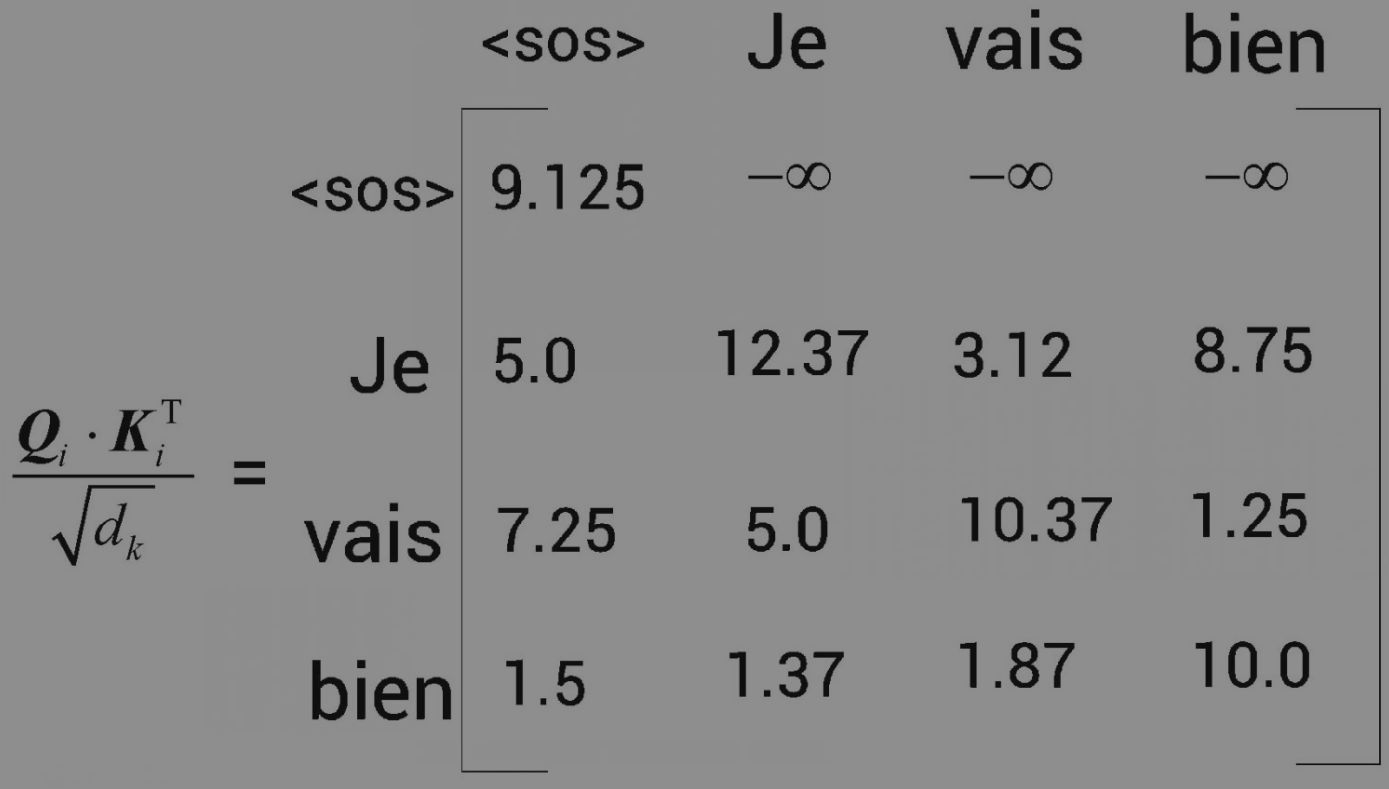
假设传给解码器的输入句是Je vais bien。我们知道,自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。但这里有一个小问题。在测试期间,解码器只将上一步生成的词作为输入。 比如,在测试期间,当t=2时,解码器的输入中只有[, Je],并没有任何其他词。因此,我们也需要以同样的方式来训练模型。模型的注意力机制应该只与该词之前的单词有关,而不是其后的单词。要做到这一点,我们可以掩盖后边所有还没有被模型预测的词。 如,我们想预测与相邻的单词。在这种情况下,模型应该只看到,所以我们应该掩盖后边的所有词。再比如,我们想预测Je后边的词。在这种情况下,模型应该只看到Je之前的词,所以我们应该掩盖Je后边的所有词。其他行同理,如图所示。

以矩阵的第1行为例,为了预测后边的词,模型不应该知道右边的所有词(因为在测试时不会有这些词)。因此,我们可以用-∞掩盖右边的所有词,如图所示:
接下来,让我们看矩阵的第2行。为了预测Je后边的词,模型不应该知道Je右边的所有词(因为在测试时不会有这些词)。
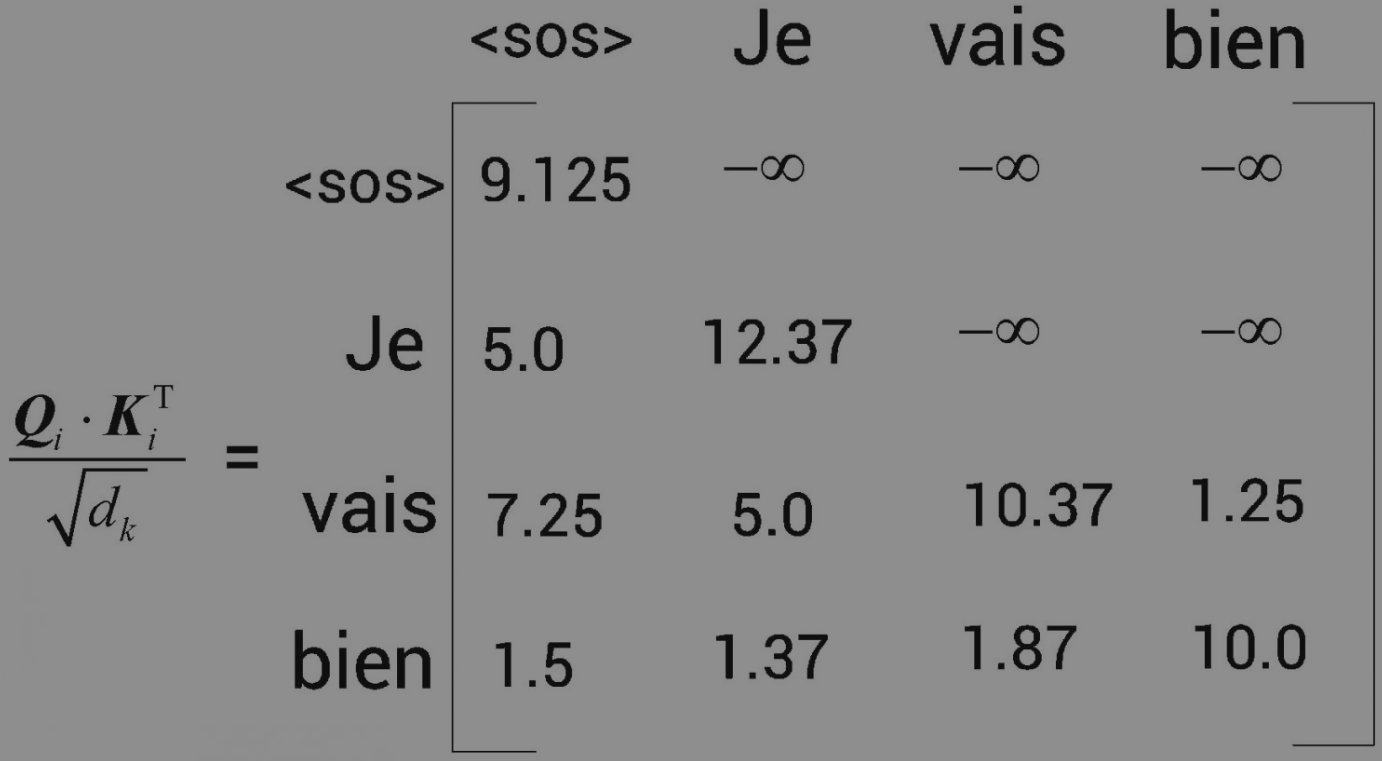
同理,我们可以掩盖vais右边的所有词
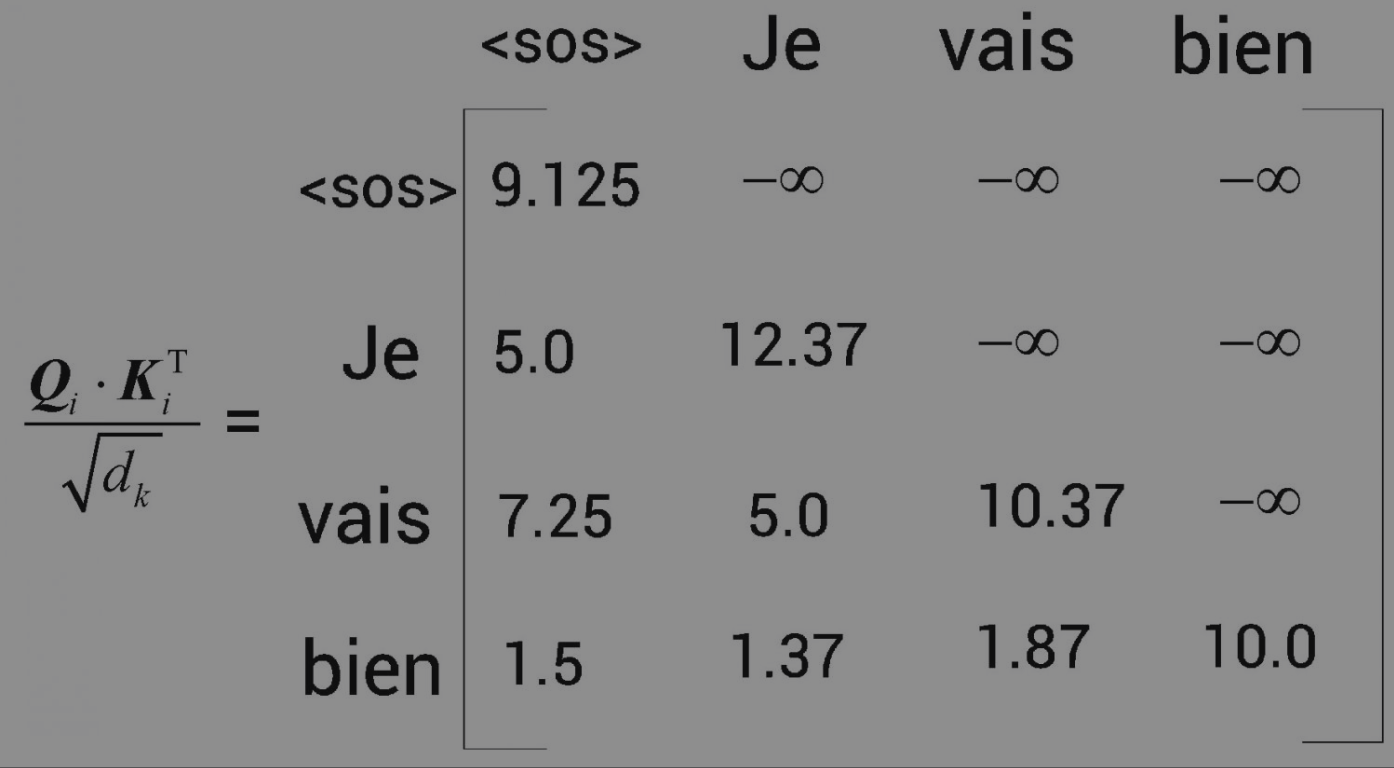
通过这种方式的处理,最终就可以通过之前的计算公式,算出来注意力矩阵Z
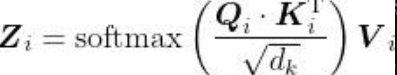
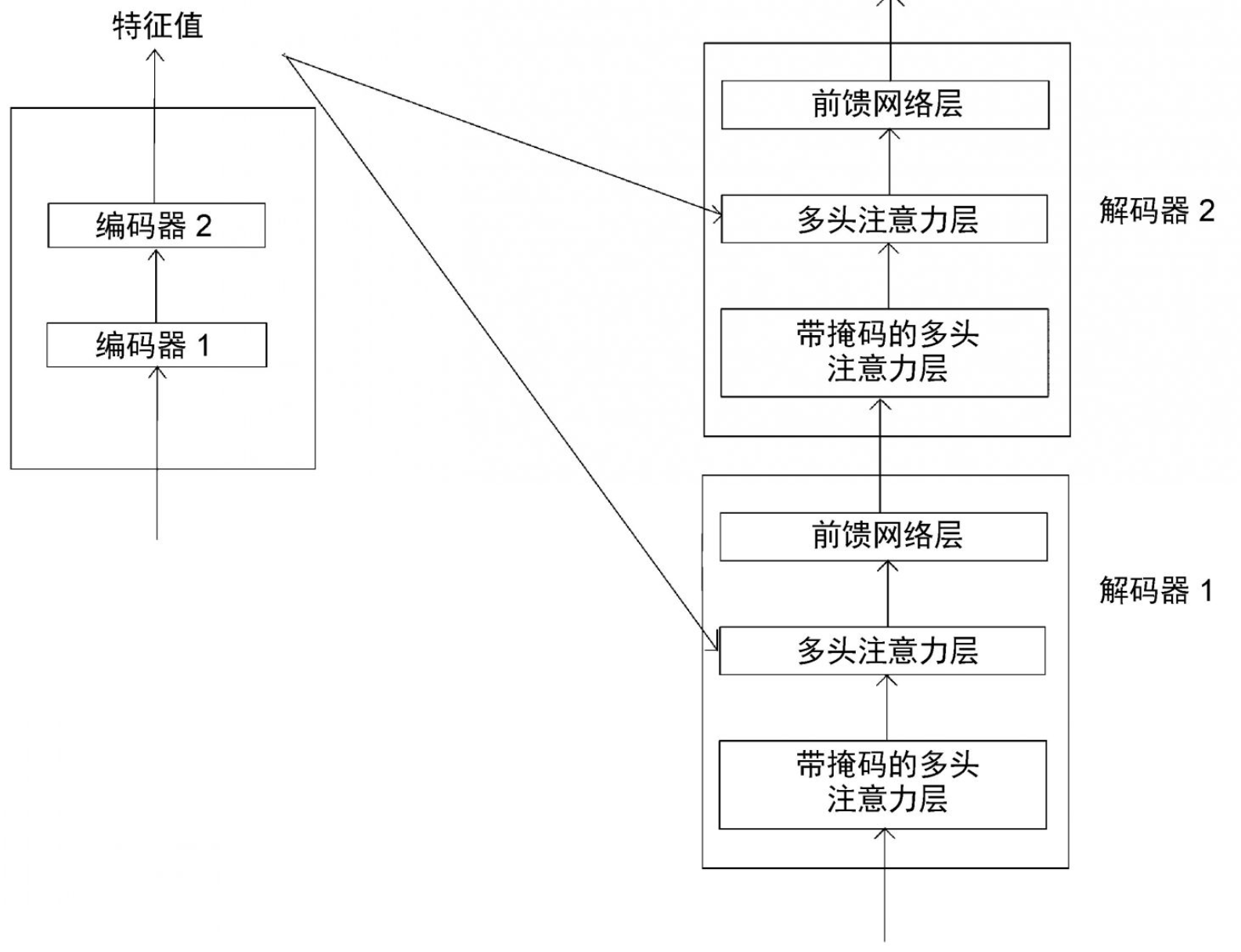
多头注意力层
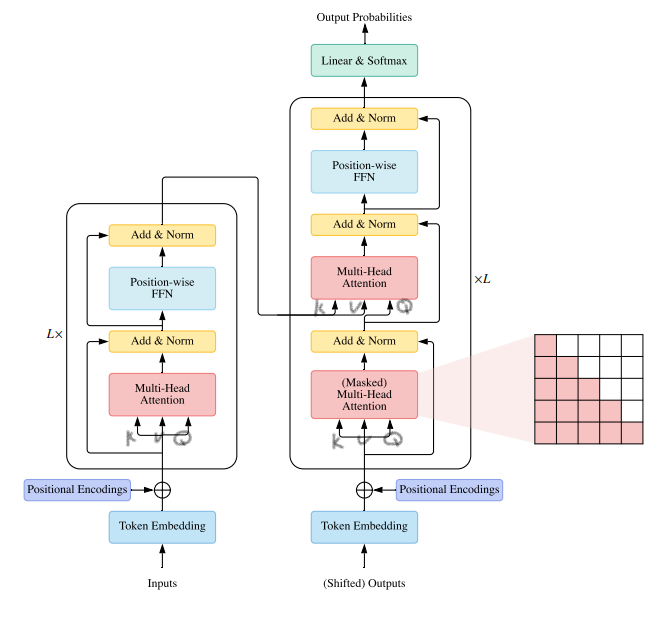
下图展示了Transformer模型中的编码器和解码器。我们可以看到,每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值。
用 R 来表示编码器输出的特征值,用 M 来表示由带掩码的多头注意力层输出的注意力矩阵。 多头注意力机制的第1步是创建查询矩阵、键矩阵和值矩阵。而已知可以通过将输入矩阵乘以权重矩阵来创建查询矩阵、键矩阵和值矩阵。 在这里由于有两个输入矩阵,区别于之前只有一个输入矩阵的情况,要特殊的处理。 使用上一个子层获得的注意力矩阵M创建查询矩阵Q;使用编码器层输出的特征值R创建键矩阵与值矩阵。 计算图如下所示:

为什么要用 M 计算查询矩阵,而用 R 计算键矩阵和值矩阵呢?因为查询矩阵是从 M 求得的,所以本质上包含了目标句的特征。键矩阵和值矩阵则含有原句的特征,因为它们是用 R 计算的。
按照公式
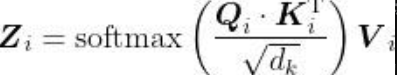
逐步计算 第1步是计算查询矩阵与键矩阵的点积。

通过计算
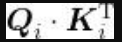
,可以得出查询矩阵(目标句特征)与键矩阵(原句特征)的相似度。 计算多头注意力矩阵的下一步是将
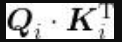
除以
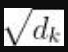
,然后应用softmax函数,得到分数矩阵
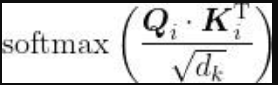
。 接下来,我们将分数矩阵乘以值矩阵V,得到
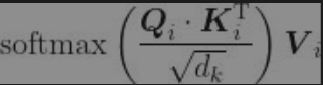
,即注意力矩阵Z

为了进一步理解,让我们看看Je这个词的自注意力值Z2是如何计算的,如图所示。

其实就是向量的点积运算。这个结果可以帮助模型理解目标词Je指代的是原词I。因为其计算分数中包含了98%的I。 同样,我们可以计算出h个注意力矩阵,将它们串联起来。然后,将结果乘以一个新的权重矩阵W,得出最终的注意力矩阵,如下所示。

前馈网络层
同编码器层的前馈网络层。
叠加与归一组件
同编码器层的叠加归一层。
概览
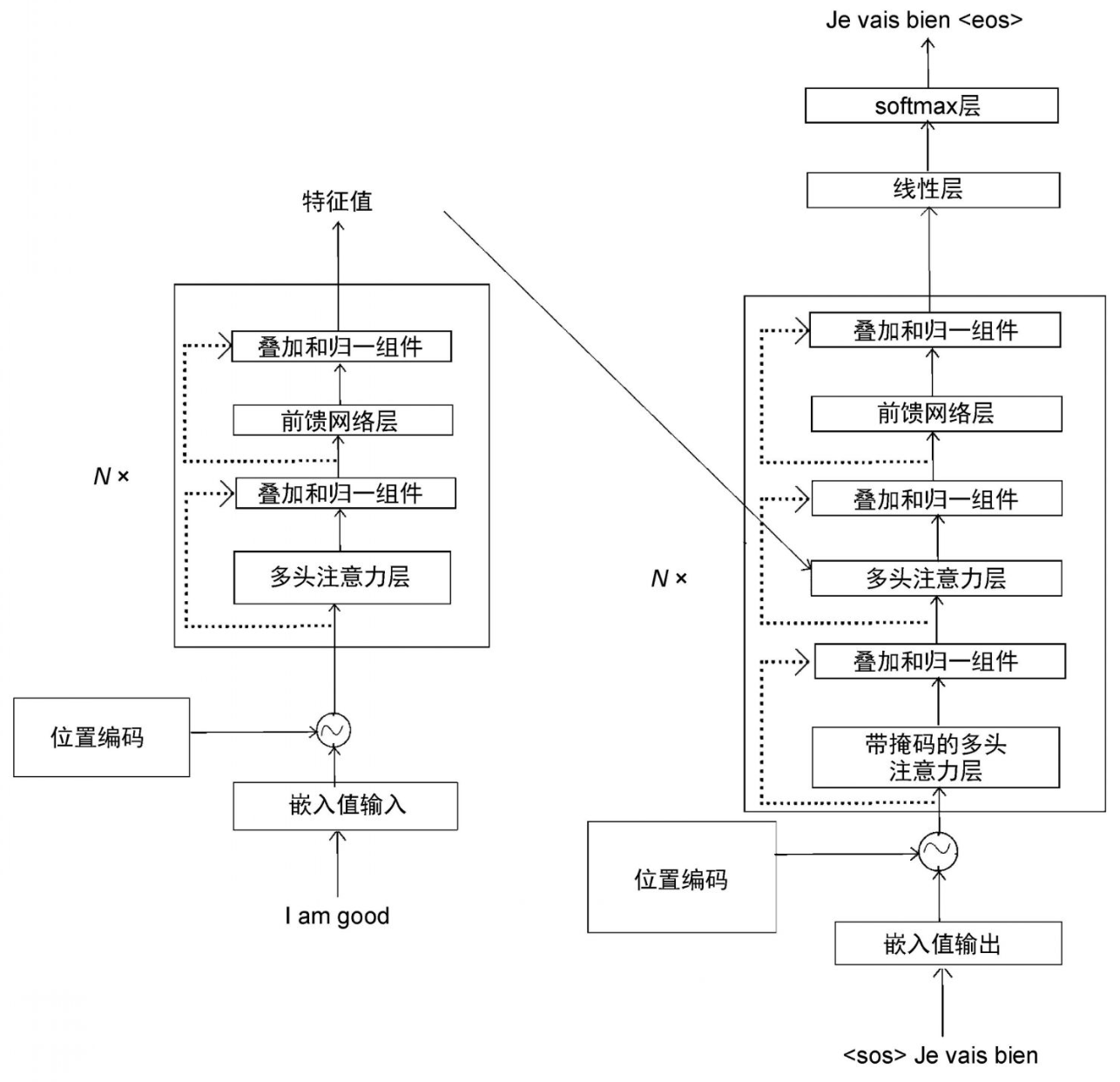
如下显示了两个解码器,将解码器1的所有组件完全展开。
(1) 首先,我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器1)。 (2) 解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵M。 (3) 然后,将注意力矩阵M和编码器输出的特征值R作为多头注意力层(编码器−解码器注意力层)的输入,并再次输出新的注意力矩阵。 (4) 把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。 (5) 最后,我们把从解码器1得到的输出作为输入,将其送入解码器2。 (6) 解码器2进行同样的处理,并输出目标句的特征。 我们可以将N个解码器层层堆叠起来。从最后的解码器得到的输出(解码后的特征)将是目标句的特征。接下来,我们将目标句的特征送入线性层和softmax层,通过概率得到预测的词。
整合编码器与解码器
带有编码器和解码器的Transformer架构如下所示。
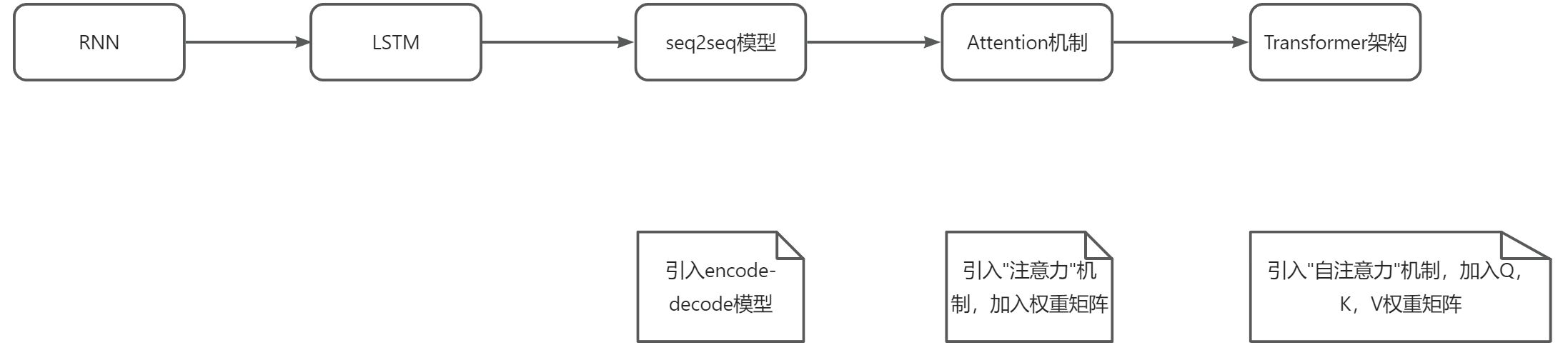
从之前的RNN系列到现在的Transformer模型,是一个演进的过程,技术的实现与迭代并不是一蹴而就,而是一个持续演进的历程。如果一开始就从Tranformer的模型机制来学习,知识的不全面以及欠缺就会导致懵逼甚至看不懂又不理解。以下是我个人对Tranformer演进的理解:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-11-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号