数据结构原理:Hash表的时间复杂度为什么是O(1)?
原创

Hash 表的时间复杂度为什么是 O(1)?
想要回答这个问题,就必须要了解 Hash 表的数据结构原理,以及先从数组说起。
数组
数组是最常用的数据结构,创建数组必须要内存中一块连续的空间,并且数组中必须存放相同的数据类型。比如创建一个长度为 10,数据类型为整型的数组,在内存中的地址是从 1000 开始,那么它在内存中的存储格式如下。
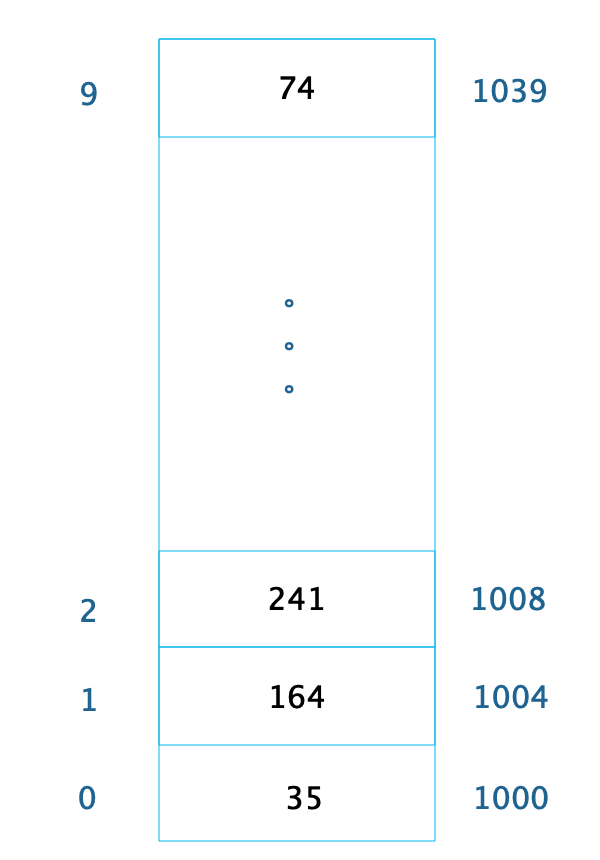
由于每个整型数据占据 4 个字节的内存空间,因此整个数组的内存空间地址是 1000~1039,由此可以推算出数组中每个数据的内存下标地址。只要知道了数组下标,也就是数据在数组中的位置,就能快速读取数据。比如要查询下标为 2的元素,可以计算出这个数据在内存中的位置是 1008,从而对这个位置的数据 241 进行快速读写访问,时间复杂度为 O(1)。
随机快速读写是数组的一个重要特性,但是要随机访问数据,必须知道数据在数组中的下标。如果只是知道数据的值,想要在数组中找到这个值,那么就只能遍历整个数组,时间复杂度为 O(N)。
链表
不同于数组必须要连续的内存空间,而链表可以使用零散的内存空间存储数据。
不过,因为链表在内存中的数据不是连续的,所以链表中的每个数据元素都必须包含一个指向下一个数据元素的内存地址指针。如图所示,链表的每个元素包含两部分,一部分是数据,一部分是指向下一个元素的地址指针。最后一个元素指向 null,表示链表到此为止。

因为链表是不连续存储的,要想在链表中查找一个数据,只能遍历链表,所以链表的查找复杂度总是 O(N)。但是正因为链表是不连续存储的,所以在链表中插入或者删除一个数据是非常容易的,只要找到要插入(删除)的位置,修改链表指针就可以了。如图所示,在 b 和 c 之间插入一个元素 x,只需要将 b 指向 c 的指针修改为指向 x,然后将 x 的指针指向 c 就可以了。
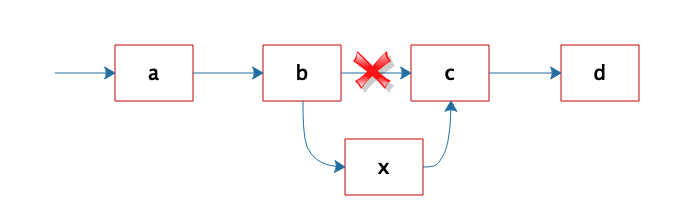
在链表中插入、删除一个元素操作比较简单。但在数组中插入、删除一个数据,就会改变数组连续内存空间的大小,需要重新分配内存空间,要复杂得多。
Hash 表
前面提过,对数组中的数据进行快速访问必须要通过数组的下标,时间复杂度为 O(1)。如果只知道数据或者数据中的部分内容,想在数组中找到这个数据,还是需要遍历数组,时间复杂度为 O(N)。
事实上,知道部分数据查找完整数据的需求在软件开发中会经常用到,比如知道了商品 ID,想要查找完整的商品信息。这类场景就需要用到 Hash 表这种数据结构。
Hash 表中数据以 Key、Value 的方式存储,在上面例子中,商品 ID 就是 Key,商品信息就是 Value。存储的时候将 Key、Value 写入 Hash 表,读取的时候,只需要提供 Key,就可以快速查找到 Value。
Hash 表的物理存储其实是一个数组,如果能够根据 Key 计算出数组下标,那么就可以快速在数组中查找到需要的 Key 和 Value。许多编程语言支持获得任意对象的 HashCode,比如 Java 语言中 HashCode 方法包含在根对象 Object 中,其返回值是一个 Int。可以利用这个 Int 类型的 HashCode 计算数组下标。
最简单的方法还是余数法,使用 Hash 表的数组长度对 HashCode 求余, 余数即为 Hash 表数组的下标,使用这个下标就可以直接访问得到 Hash 表中存储的 Key、Value。
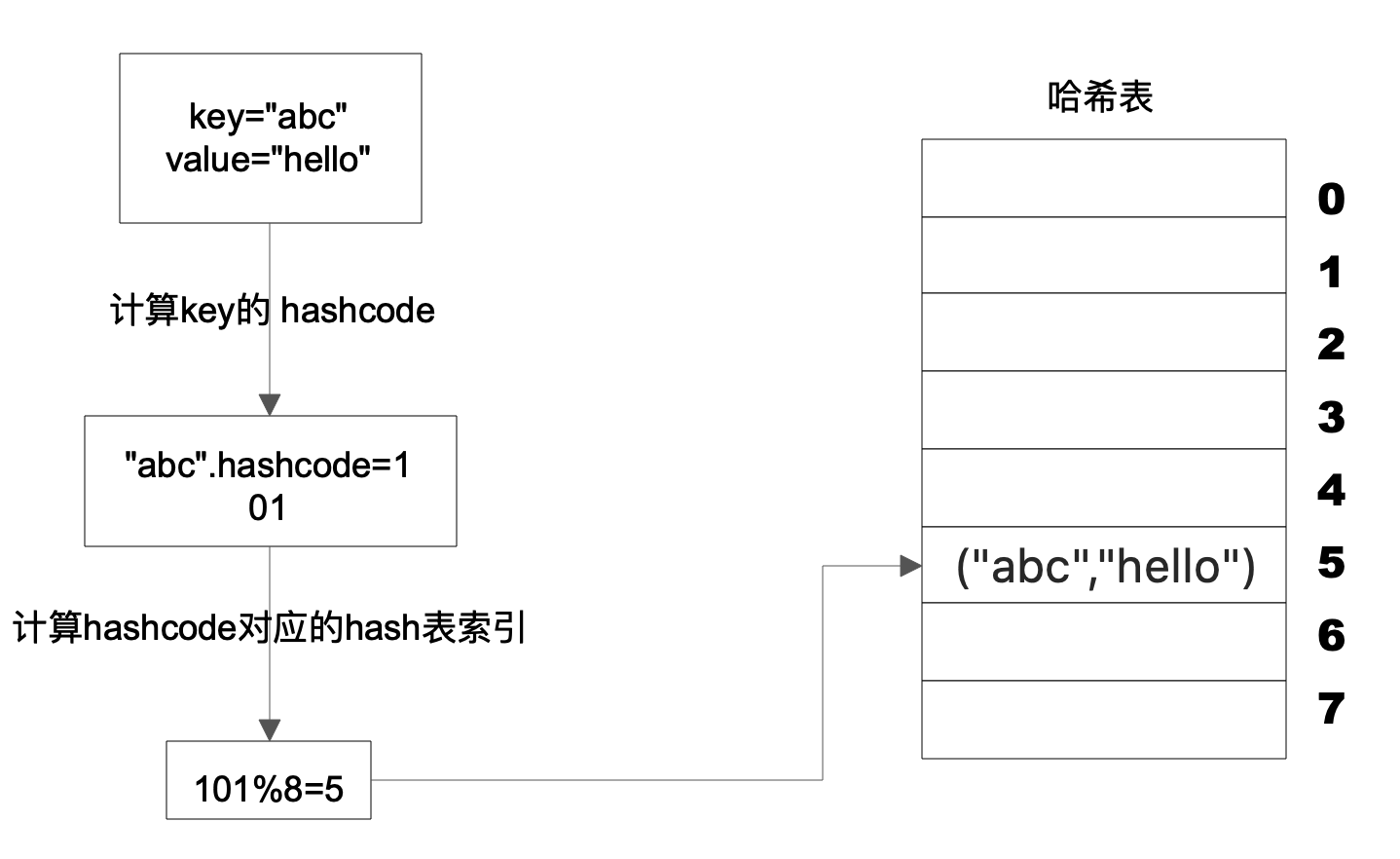
上图这个例子中,Key 是字符串 abc,Value 是字符串 hello。先计算 Key 的哈希值,得到 101 这样一个整型值。然后用 101 对 8 取模,这个 8 是哈希表数组的长度。101 对 8 取模余 5,这个 5 就是数组的下标,这样就可以把 (“abc”,“hello”) 这样一个 Key、Value 值存储在下标为 5 的数组记录中。
当读取数据时,只要给定 Key = “abc”,还是用这样一个算法过程,先求取它的 HashCode = 101,然后再对 8 取模,因为数组的长度不变,对 8 取模以后依然是余 5,然后在数组下标中去找 5 的这个位置,就可以找到前面存储进去的 abc 对应的 Value 值。
但是如果不同的 Key 计算出来的数组下标相同怎么办?HashCode101 对 8 取模余数是 5,HashCode109 对 8 取模余数还是 5,也就是说,不同的 Key 有可能计算得到相同的数组下标,这就是所谓的 Hash 冲突,解决 Hash 冲突常用的方法是链表法。
事实上,(“abc”,“hello”) 这样的 Key、Value 数据并不会直接存储在 Hash 表的数组中,因为数组要求存储固定数据类型,主要目的是每个数组元素中要存放固定长度的数据。所以,数组中存储的是 Key、Value 数据元素的地址指针。一旦发生 Hash 冲突,只需要将相同下标,不同 Key 的数据元素添加到这个链表就可以了。查找的时候再遍历这个链表,匹配正确的 Key。如图所示:
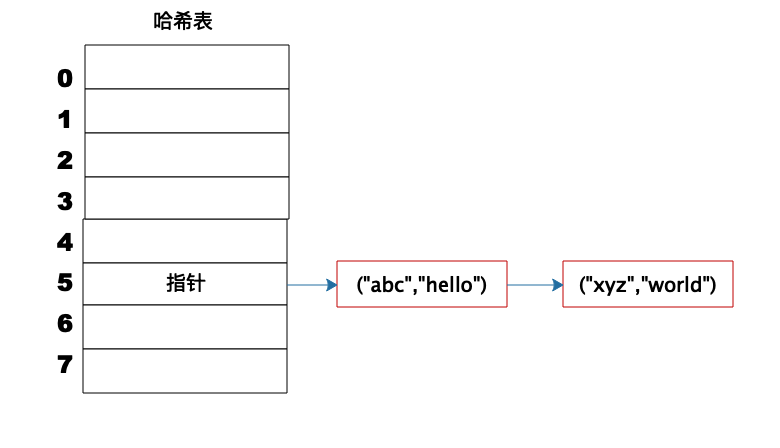
因为有 Hash 冲突的存在,所以“Hash 表的时间复杂度为什么是 O(1)?”这句话并不严谨,极端情况下,如果所有 Key 的数组下标都冲突,那么 Hash 表就退化为一条链表,查询的时间复杂度是 O(N)。但是作为一个面试题,“Hash 表的时间复杂度为什么是 O(1)”是没有问题的。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号