Deep Dive into Elasticsearch's Distributed Architecture

Deep Dive into Elasticsearch's Distributed Architecture

ppxai
发布于 2023-11-18 08:34:19
发布于 2023-11-18 08:34:19
Deep Dive into Elasticsearch's Distributed Architecture
I. Introduction
In the digital age, data stands as a crucial asset for enterprises. The effective storage, retrieval, and analysis of this data are among the primary challenges faced by businesses today. Elasticsearch, commonly referred to as "ES", is a robust, scalable, and real-time search and analytics engine, proving to be an indispensable component in the contemporary data pipeline. With a wide range of applications, from full-text search and logging to more complex use cases such as machine learning and graph analysis, Elasticsearch stands out. This blog post provides a comprehensive insight into Elasticsearch's distributed architecture, touching upon its main components, read-write operations, indexing principles, and application scenarios.
II. Understanding Elasticsearch's Components
Elasticsearch boasts a set of distinct components.
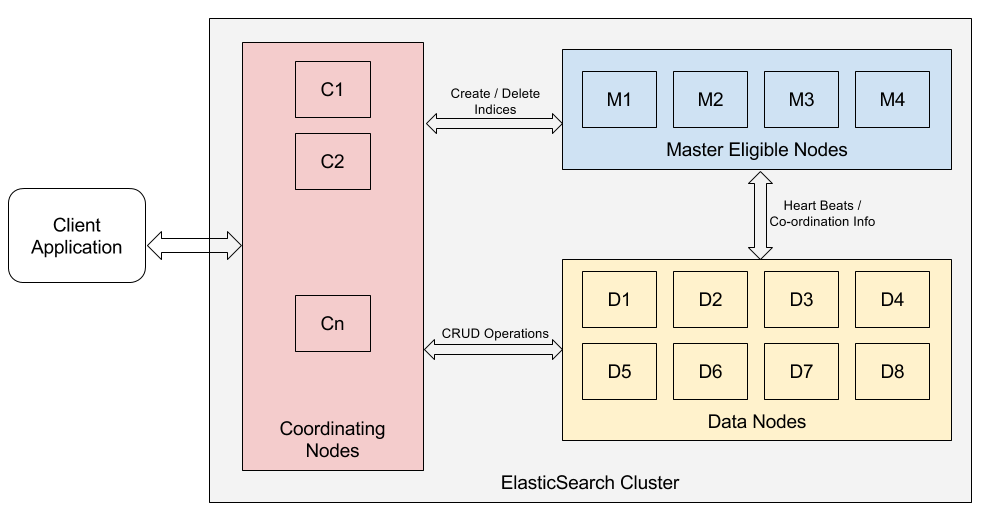
- Node: Each server that is part of a cluster in Elasticsearch is a node. It not only stores data but also participates in the cluster's indexing and search capabilities.
- Cluster: A collection of one or more nodes is called a cluster. A cluster is capable of housing an infinite number of nodes, collectively delivering indexing and search capabilities across all nodes.
- Index: An index in Elasticsearch is a collection of documents sharing similar characteristics. For instance, you might have one index for customer data, another for a product catalog, and yet another for order data.
- Document: A basic unit of information that can be indexed is a document. Elasticsearch documents are expressed in JSON (JavaScript Object Notation), a popular internet data interchange format.
- Shard: Elasticsearch offers the feature to divide your index into multiple sub-parts called shards. Each shard operates as a fully-functional and independent "index" that can be hosted on any node within a cluster.
III. Indexing Principles
The process of writing data in Elasticsearch involves indexing. When data is indexed, it gets distributed across various shards in the cluster. The arrangement and allocation of these shards are automatically managed by Elasticsearch. When data is written, it goes to a primary shard and then gets replicated to replica shards. Elasticsearch can fetch data from either a primary shard or one of its replicas during a read operation. This ensures effective load-balancing across multiple nodes, offering high availability and fault tolerance.
Indexing in Elasticsearch context refers to storing data optimally to support quick search. This process involves several crucial steps and mechanisms.
Document Analysis
The first step in indexing is document analysis. Elasticsearch uses an analyzer to break down the text in a document into smaller pieces or tokens, a process known as tokenization. Tokens, which are typically individual words or numbers, form the basic units of search. The analyzer also performs additional processing like lowercasing and removal of common words (known as stop words), a process known as normalization.
Inverted Index
Post document analysis, Elasticsearch uses tokens to build an inverted index. This is a data structure mapping each unique token to a list of documents containing it. This structure enables Elasticsearch to quickly locate all documents containing a specific token, forming the backbone of quick full-text search.
Sharding and Replication
Elasticsearch spreads data in an index across multiple shards, which can be distributed across multiple nodes. This process, known as sharding, enables data to be distributed and parallelized across a cluster, leading to enhanced capacity and throughput. You can specify the number of primary shards while creating an index. Each document in an index belongs to one primary shard. Elasticsearch also supports replicas of each shard for high availability and data durability. Each replica is a copy of a primary shard and can serve read requests or recover data if a primary shard fails.
Mapping
Elasticsearch also supports a feature called mapping, which is akin to schema definition in a relational database. Mappings define how documents and their fields are stored and indexed. Elasticsearch detects the data structure automatically and maps the data types accordingly during document indexing. Custom mappings can also be defined.
Understanding the principles of Elasticsearch indexing allows us to optimize the way we store and search data in Elasticsearch. It's a process central to Elasticsearch's performance and flexibility.
IV. Exploring Application Scenarios
The powerful features of Elasticsearch make it apt for a wide array of applications. Here are some common ones:
- Full-text Search: Elasticsearch can handle complex full-text search operations, making it a preferred choice for implementing search features in applications.
- Log and Event Data Analysis: Given its ability to manage large volumes of data nearly in real-time, Elasticsearch is commonly employed in log and event data analysis pipelines.
- Real-time Application Monitoring: When combined with Logstash and Kibana, forming the "ELK Stack", Elasticsearch provides robust real-time monitoring capabilities for applications.
- Advanced Analytics: Elasticsearch supports intricate aggregations that can be used for advanced analytics, making it suitable for business intelligence applications.
Elasticsearch's distributed architecture and robust functionality render it a powerful tool for various data-intensive applications. Grasping the principles behind its design and operation can help you better utilize its capabilities in your applications.
V. Conclusion
Elasticsearch, or ES, is a potent distributed search and analytics engine, adept at handling large-scale data sets and offering near real-time data indexing and search capabilities. By comprehending the principles of ES's distributed architecture, we gain insight into how it handles large data and ensures high availability and data consistency through replication and election mechanisms. As data scales continue to expand, understanding and leveraging these features of ES will become increasingly important.
References
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号