Polynomial Regression in Pytorch

Polynomial Regression in Pytorch

Tom2Code
发布于 2023-12-04 10:12:30
发布于 2023-12-04 10:12:30
一个简单的多项式回归入门一下pytorch
首先导包
import torch
import numpy as np然后生成一个简单的多项式,类似于
Y=Ax2+Bx+C
那么我们不妨令
A=1
B=2
C=3
那么就有我们的方程:Y=x2+2x+1,然后使用np中的多项式函数可以写成这个样子:
polynomial=np.poly1d([1,2,3])然后打印看看

ok这是我们想要的多项式
也就是说给现在这个变量polynomial一个x 然后就能输出对应的Y
我们来试试看,假如X=1 那么Y应该等于6
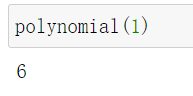
nice,这和我们的预期是一样的输出!
接下来提出我们的需求,使用pytorch中的autograd(自动求导)去算出来我们的多项式的A,B,C 在程序的一开始我们可以随机的指定一组A,B,C的值,但是一定不是我们刚才假设的A=1,B=2,C=3这样的数字
然后我们利用自动求导的方法让程序逐渐去算出来 最接近A B C的结果
具体的做法就是 我们给一组X值,把X扔到我们定义好的多项式polynomial中进行计算,这样会得到一组对应的Y我们叫做真实的Y
与此同时这一组X也要和我们随机指定的A B C做一样的运算,并且会生成一个Y,这里我们称作为预测的Y
这样真实的Y和预测的Y就会有一个差值,那么pytorch中的autograd就会利用这个差值进行计算,然后去更新我们的A,B,C 更新的标准就是使得我们的两个Y相减的差值越来越小,这样就实现了我们目的 多项式回归
好了下面直接上代码
N=20
X=np.random.randn(N,1)*5
XN的值可以自己设置,也就是生成多少个X样本使用了random来进行生成
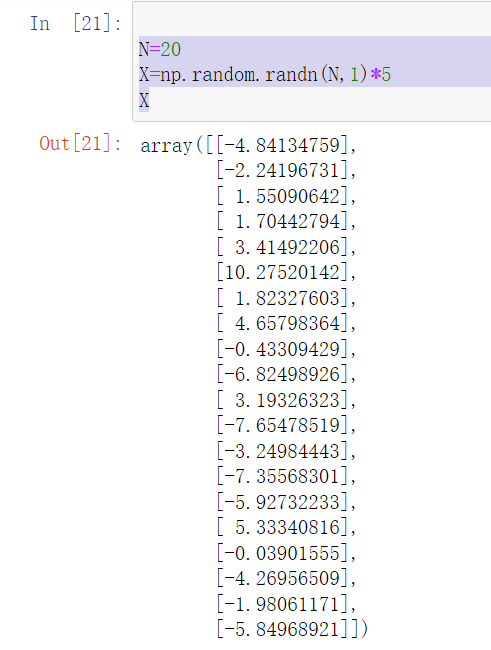
可以看到这些X是服从均值为0,方差为1的标准正态分布的随机数
然后计算我们的真实的Y 也就是把x输入到我们的多项式中

计算一下真实Y的结果:
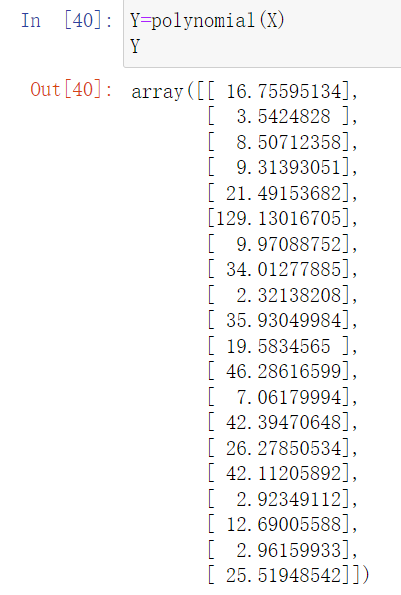
然后我们初始化三项数据,分别是x的平方,x,还有就是1,这样方便我们直接与我们生成的A,B,C相乘 方便运算
XX=np.hstack([X*X,X,np.ones_like(X)])
XX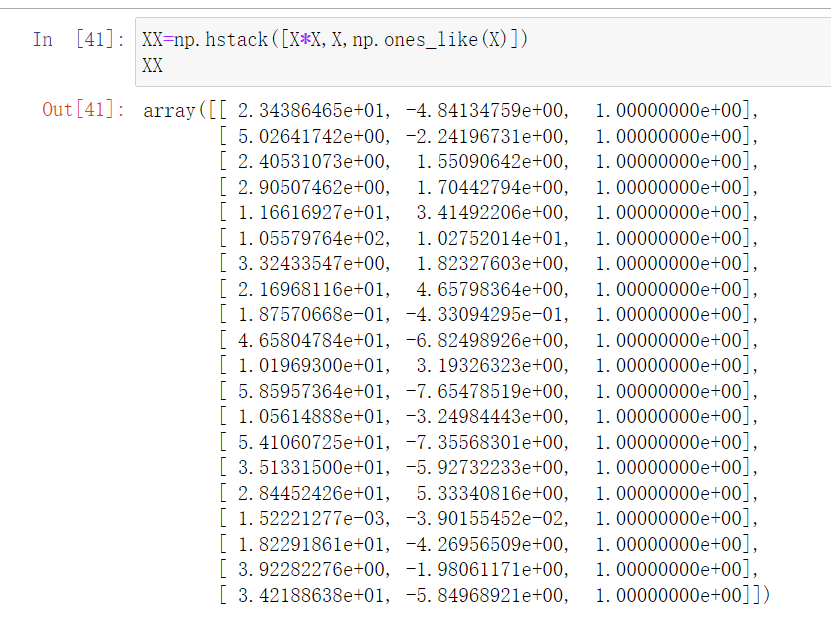
然后初始化我们随机生成的 A B C:
w=torch.randn(3,1,requires_grad=True)
w需要指定requires_grad=True因为需要保留梯度,用于optimizer更新参数

可以看到w的三个数分别代表了
A=1.3623
B=-0.2611
C=-0.2083
然后就是数据类型的处理了, 把x都转化成张量格式
x=torch.tensor(XX,dtype=torch.float32)
x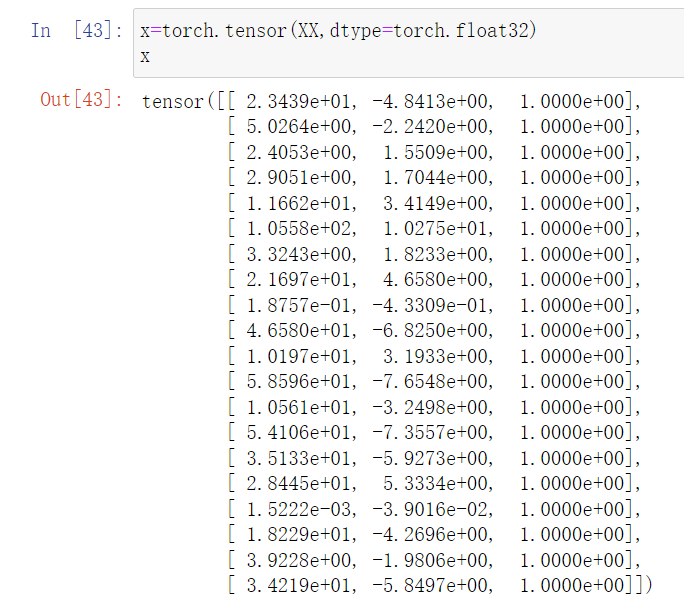
然后是真实的Y
y=torch.tensor(Y,dtype=torch.float32)
y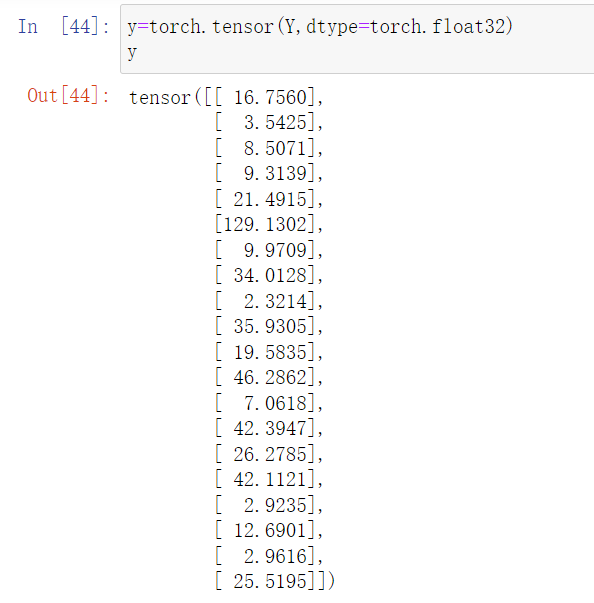
然后是优化器:
optimizer=torch.optim.NAdam([w],lr=0.001)
optimizer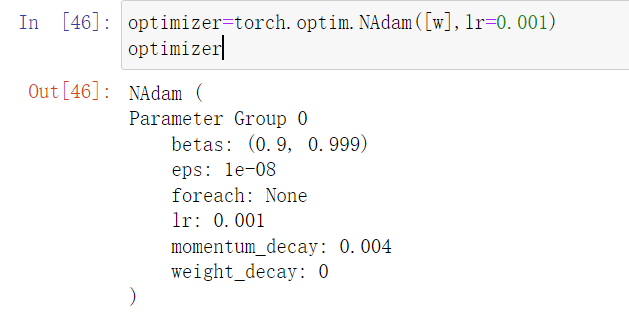
优化器先说一个点 就是利用了autograd的机制进行自动求导,第一个需要的就是指明需要优化的参数,还有学习率learning_rate
接下来要做的事情就是大致分为三件:
- 计算假的A B C和x平方 x 还有1的乘积,得出一个假的Y
- 计算真的Y和假的Y之间的差值
- 更新假的A B C
然后循环这个过程就可以使得假的A B C越来越接近真实的A B C
上代码就是:
los=[]
for _ in range(500):
y_pred=x@w
mse=torch.mean(torch.square(y-y_pred))
los.append(mse.item())
optimizer.zero_grad()
mse.backward()
optimizer.step()然后画个图看看我们的loss是不是在下降:
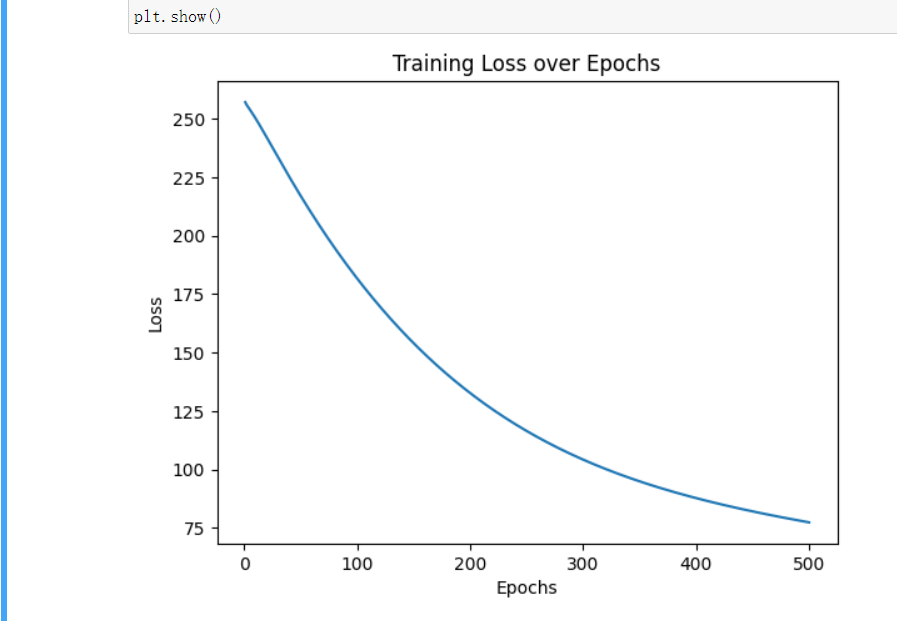
顺便也可以看一下w的值:
这是训练了500次后w的值 也就是假的A B C的值
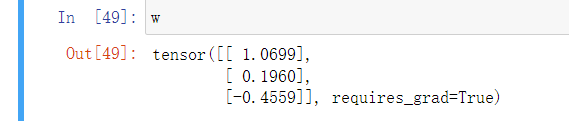
然后我们增加训练次数:

再次增加训练次数:

5000次的时候,假的 A B C就和我们刚开始指定的 A B C差不多了:

最终 我们成功的使用pytorch中的autograd实现了多项式回归
但是最后的彩蛋是,以前看过一本书上说过,敲代码就和汽修一样,你得会拆还得会组装。
所以我们看一下 改变一下learning rate会有什么样的变化:
optimizer=torch.optim.NAdam([w],lr=0.01)
optimizer之前lr是0.001
现在我们改成了0.01 这样会发生啥样子的变化呢 拭目以待:
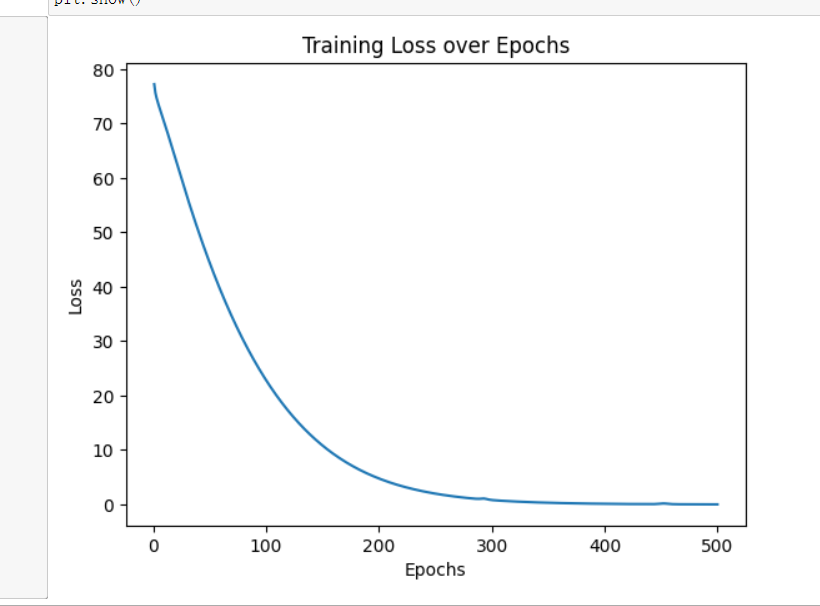
可以看出来 同样是500次迭代,但是这次loss最后会变得很小,斜率提前就变小了,我觉得在这种小型问题上,lr还是可以适度的增大的。
完,peace!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号