GPT开发实战:解决GPT API限速问题

GPT开发实战:解决GPT API限速问题

MavenTalker
发布于 2023-12-04 19:14:16
发布于 2023-12-04 19:14:16
一个健壮的、安全的开放平台的架构设计,必然会针对对外开放的API接口进行速率限制,来保证整体系统的可用性,OpenAI对外的API也不例外,我们可以简单的从官方发现API使用量的限制。
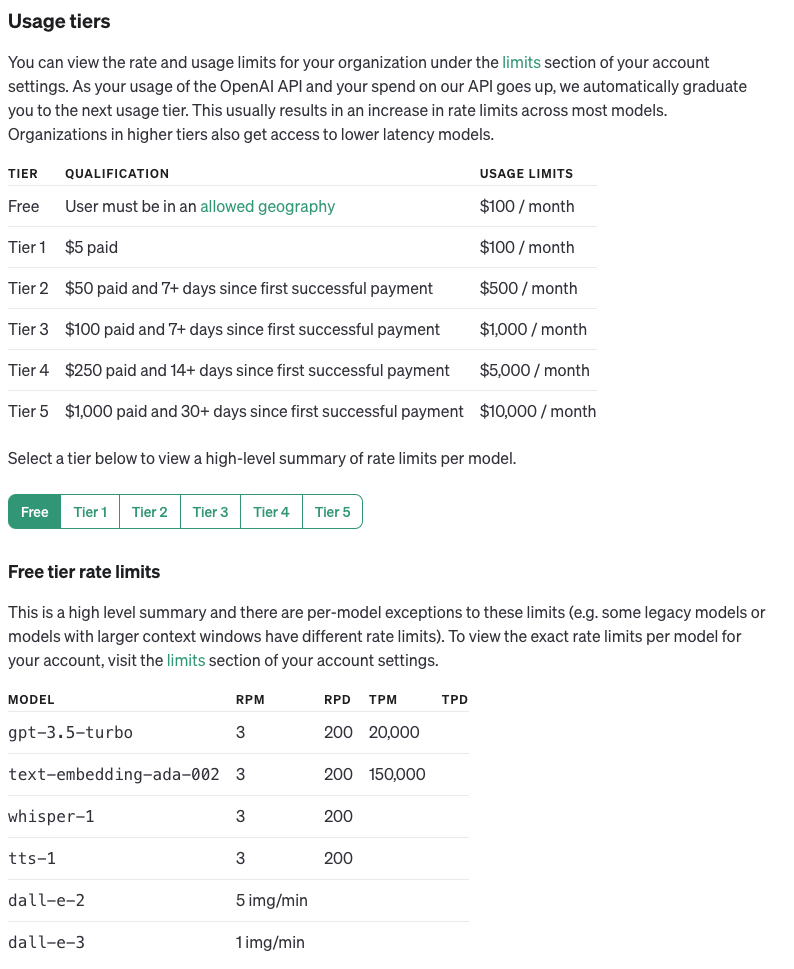
【API Doc上的限制】
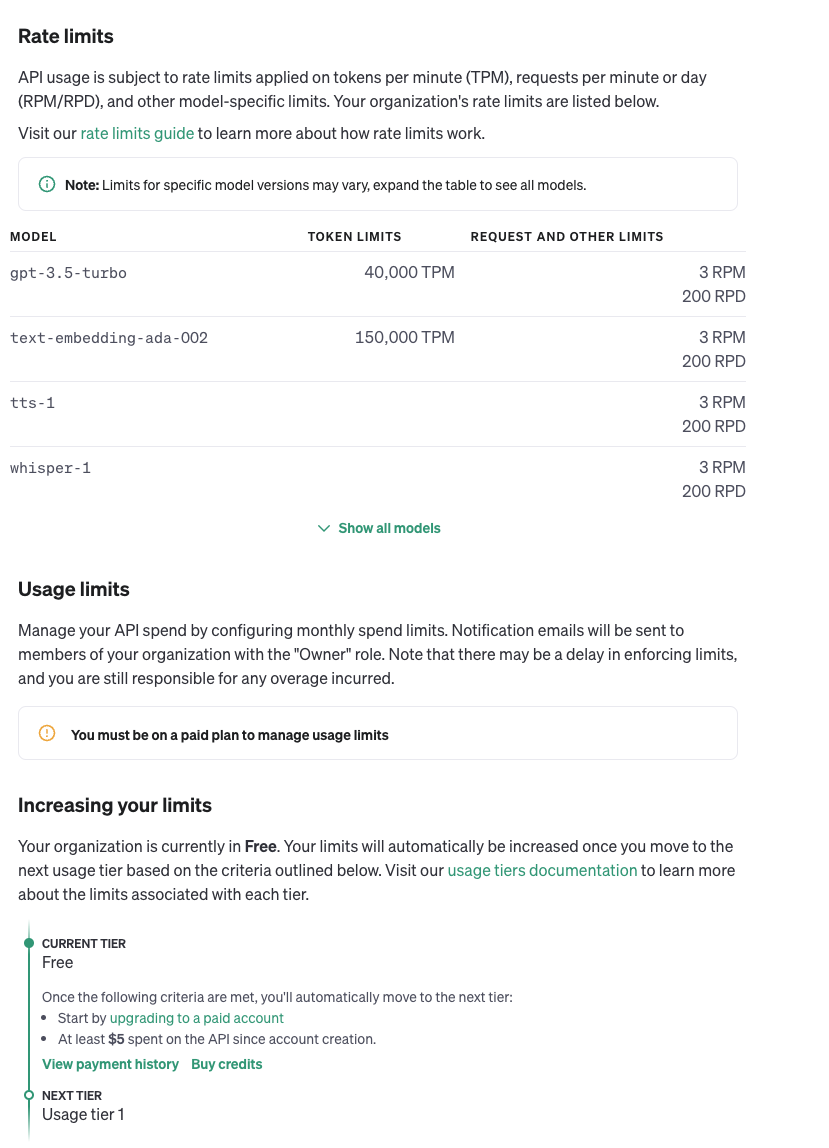
【个人账户里的速率限定以及当前所处的等级】
限定方式
速率限制有五种衡量方式:
- 每分钟请求数(RPM,requests per minute)
- 每天请求数(RPD,requests per day)
- 每分钟令牌数(TPM,tokens per minute)
- 每天令牌数(TPD,tokens per day)
- 每分钟图片数(IPM,images per minute)
速率限制可能会根据先达到的条件而被触发。例如,你可能在向 ChatCompletions 端点发送了 20 次请求,但只有 100 个令牌,这将达到你的限制(如果你的 RPM 是 20),即使在这 20 次请求中没有发送 150,000 个令牌(如果你的 TPM 限制是 150,000)。
在实际应用中,RPM常常与API或服务的限制一起使用,以确保系统不会因为过度的请求而过载。例如,如果一个API的RPM限制为100,那么在任何给定的一分钟内,该API的请求总数不得超过100次。
需要注意的是,为了更精确地计算RPM,通常会使用实际的时钟时间,而不仅仅是从第一个请求到最后一个请求的时间间隔。这是为了确保即使请求不均匀分布,也能准确计算每分钟的请求速率。
提升可用性
当使用 OpenAI 的 GPT API 开发应用时,面对请求限制时,你可以考虑以下几个方法来提高系统的可用性和性能:
- 使用缓存: 缓存是一种有效的方式,可以减少对 GPT API 的请求次数。对于相同或相似的输入,你可以缓存相应的输出,并在下次遇到相同输入时直接返回缓存的结果,而不需要实际调用 API。
- 批量请求: 考虑将多个用户请求合并成一个批量请求。这样可以减少每个请求的开销,提高效率。然而,需要注意的是,合并请求可能会导致响应时间的增加,因此需要权衡。
- 异步请求: 将用户请求和 API 调用分离,使其异步进行。用户请求可以首先接收到一个快速的响应,而后台异步任务负责调用 GPT API 并处理结果。这可以减少用户等待时间。
- 实施本地缓存: 对于一些通用或静态的请求,你可以考虑在应用的后端实施本地缓存,避免频繁地调用 GPT API。这样可以降低对 API 的依赖,并提高应用的响应速度。
- 优化输入数据: 确保向 GPT API 发送的输入数据是最小化的、必要的。通过对输入进行合理的处理和裁剪,可以减少请求的大小和处理时间。
- 错误处理和重试策略: 实施良好的错误处理和重试策略,以处理由于网络问题或 API 限制导致的请求失败。可以使用先前提到的指数退避重试策略来有效地处理这些情况。
- 合理利用多个 API Key: 如果你的应用允许,可以使用多个 OpenAI API Key,以增加请求的并发性。确保合理轮询使用不同的密钥,以防止单个密钥的限制影响整体性能。
- 定期监测和调整: 定期监测系统的性能和 OpenAI API 的使用情况。根据监测结果,灵活调整系统策略,以应对变化的请求模式和 API 使用情况。
综合考虑这些因素,可以有效地提高系统的可用性,降低对 GPT API 的依赖,同时提供更好的用户体验。
合理利用API Key
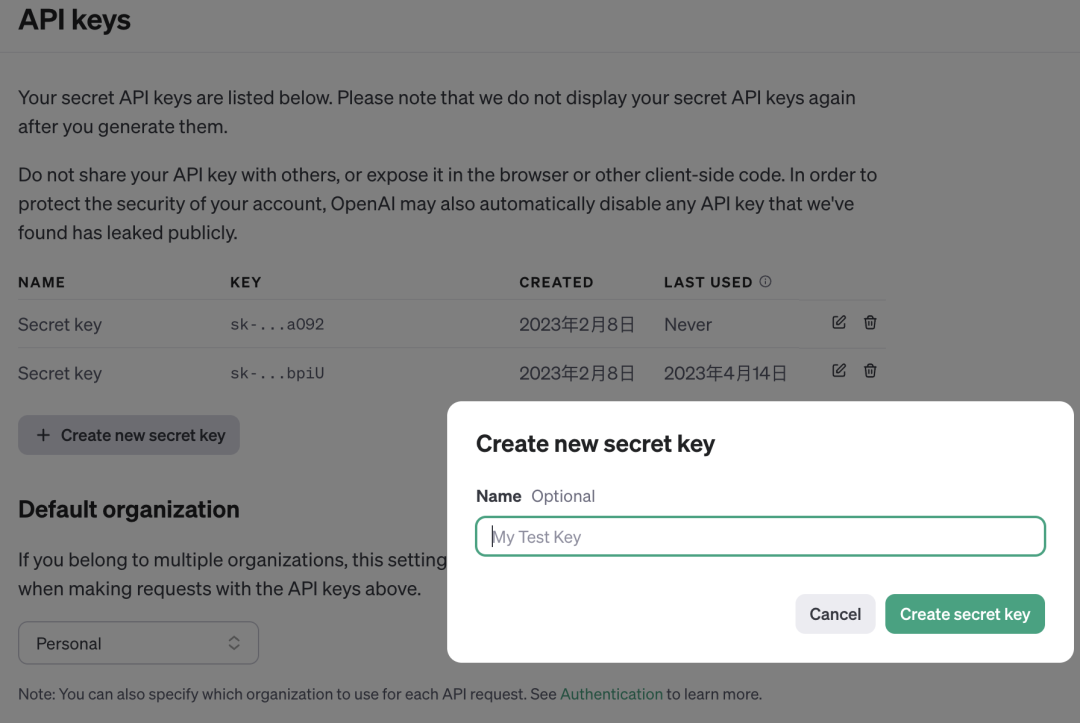
在使用 OpenAI GPT API 或类似的服务时,通常用户会被分配一个或多个 API Key,每个 API Key 都有自己的请求限制。通过巧妙地管理这些 API Keys,你可以提高系统的性能和可用性。
以下是一些具体的步骤和建议:
- 多个 API Key 的获取: 如果你的应用支持多个 API Key,确保你获得了多个有效的 API Key。你可以在 OpenAI 控制台上创建新的 API Key。
- 轮询使用不同的 API Key: 在应用代码中,实现一个机制来轮询使用不同的 API Key。这样可以确保每个 API Key 都有机会被使用,防止单个密钥达到请求限制而导致整体性能下降。
- 错误时切换 API Key: 当使用一个 API Key 发送请求时遇到错误(例如请求限制达到),立即切换到另一个 API Key 进行重试。这可以是一个自动的过程,以确保应用在发生错误时能够迅速切换到其他可用的密钥。
- 监控 API Key 的使用情况: 定期监控每个 API Key 的使用情况,了解每个密钥的请求频率和成功率。这可以帮助你判断是否需要更改密钥的使用顺序或者是否需要调整请求的分配策略。
- 平衡并发性和请求限制: 尽管使用多个 API Key 可以提高并发性,但也要注意不要超过 OpenAI API 的总请求数限制。确保你的系统在使用多个密钥时能够维持在允许的总请求数范围内。
- 安全性考虑: 确保 API Key 的安全性。避免将敏感信息硬编码在应用代码中,并采取必要的安全措施,例如使用环境变量或专门的安全存储来保存 API Key。
通过这些方法,你可以最大程度地利用多个 API Key,提高系统的并发性和性能,确保在高请求负载下仍能够有效地使用 OpenAI GPT API。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-11-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号