MMDetection全流程实战指南:手把手带你构建目标检测模型

MMDetection全流程实战指南:手把手带你构建目标检测模型

OpenMMLab 官方账号
发布于 2023-12-13 14:14:46
发布于 2023-12-13 14:14:46

本文入选技术写作营优秀文章,作者李剑锋
MMDetection 是一个由 OpenMMLab 开发的开源目标检测工具箱,基于 PyTorch 实现。该库提供了丰富的目标检测算法,包括经典的 Faster R-CNN、YOLO 和最新的一些研究成果,非常方便于研究者和工程师进行模型的训练和推理。具有高度模块化和可扩展性的设计,使得用户可以非常灵活地进行个性化配置和二次开发。这一工具箱已经成为目标检测领域的事实标准之一,被广泛应用于学术研究和产业界。
https://github.com/open-mmlab/mmdetection
(文末点击阅读原文可直达,欢迎体验)
下面,我将一步步从环境配置和数据采集开始介绍如何训练一个自己的 MMDetection 模型。
模型配置及训练
配置环境一直以来都是拦在新手面前的最大障碍,幸运的是 MMDetection 文档给出了详细的安装教程,我们跟随着文档的脚步一步步进行安装即可。
首先我们需要利用 conda 代码创建一个名为 mmdetection 的虚拟环境,并利用代码激活环境。
conda create -n mmdetection python=3.8 -y
conda activate mmdetection由于 OpenMMLab 算法是基于 PyTorch 进行开发的,因此我们需要安装 PyTorch 以实现其功能。根据官方文档,我们可以通过以下方式安装 PyTorch。一般来说,因为我们已经安装好 CUDA 和 Cudnn,因此我们选择安装 GPU 版本即可。
# GPU版本
conda install pytorch torchvision -c pytorch
# CPU版本
conda install pytorch torchvision cpuonly -c pytorch我们可以通过 conda 自带的 python 来测试是否成功安装 PyTorch 的 GPU 版本。如图所示,我在终端输入 python 后,进入了 Python 的环境并输入以下代码。假如出现了 False,则代表安装失败。假如是 True 则代表安装成功。我这里显示的是 False,就代表我安装失败了。因此我就需要卸载掉这个版本的 PyTorch 然后再在官网找到对应的版本重新安装。最后我们还需要输入 exit() 来退出 Python 环境回到终端。
import torch
torch.cuda.is_available()
exit()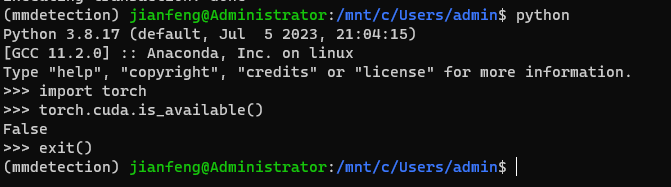
卸载 PyTorch 的指令如下:
conda uninstall pytorch torchvision -c pytorch卸载完后,我们需要前往 PyTorch的官网 找到合适的版本进行下载。可以看到,PyTorch官方提供了很多种方式让我们选择,包括 CUDA 的版本,OS 系统以及安装的方式和语言。由于目前只支持到 CUDA11.8,高于 CUDA11.8 的都下载该版本,因此我们需要选择该方式进行下载(对于之前版本的 CUDA,可以点击框选部分的链接进行查看)。
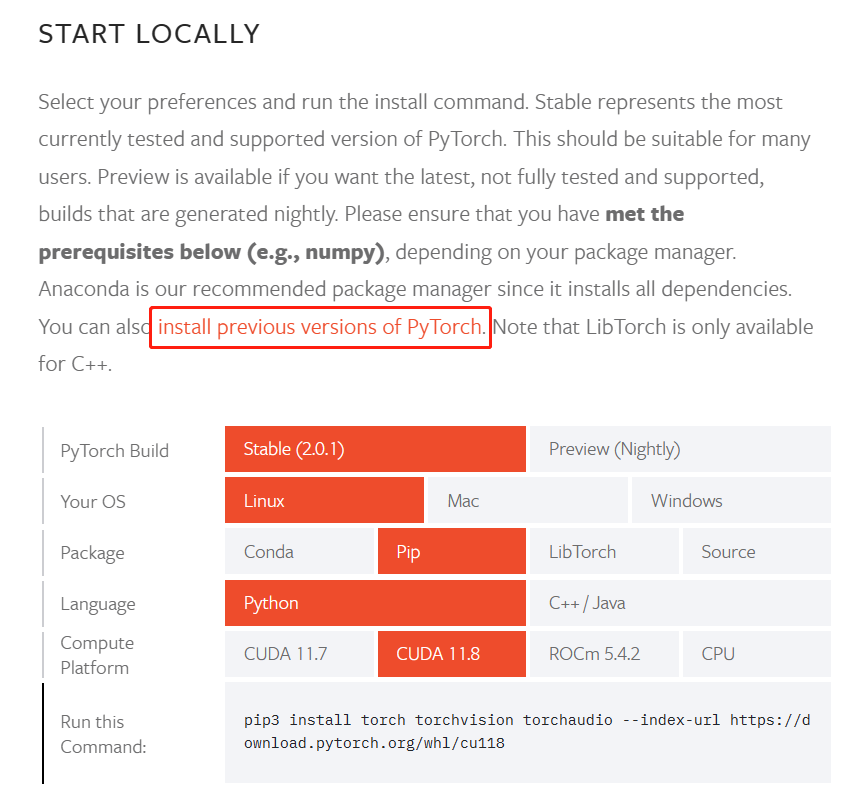
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118安装完成后,我们再来测试一下是否成功安装。
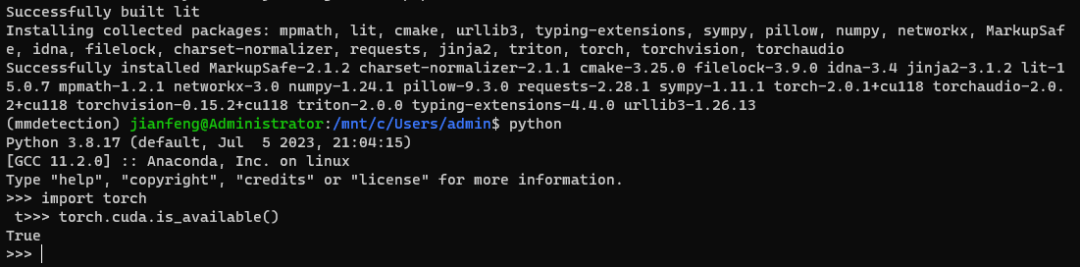
可以看到,现在显示的就是 True 了。这也就意味着 PyTorch 的 GPU 版本成功被安装了。我们就可以继续下一步的安装操作了。
下面,我们就要使用 OpenMMLab 推出的 MIM 来安装 MMEngine 和 MMCV 两个必要的库。这可能需要十分钟左右的时间才能安装完成。
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"安装完成后,我们还需要下载 GitHub 的源码到本地并安装对应的配置文件。但是在此之前,假如 C 盘的空间紧张,我建议还是更换地址后再进行下载。
# 更改地址(按自己要求)
cd /mnt/e
# 在Github上下载
git clone https://github.com/open-mmlab/mmdetection.git
# 进入对应的文件夹
cd mmdetection
# 安装配置文件
pip install -v -e .
# "-v" 指详细说明,或更多的输出# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。假如由于网络问题无法成功下载,我们可以去 MMDetection GitHub,并找到 ZIP 文件进行下载。然后把文件放到我们想要放的位置,然后再 cd到 该文件夹里,最后执行 pip install -v -e . 操作即可。
假如安装成功后将会显示以下界面:
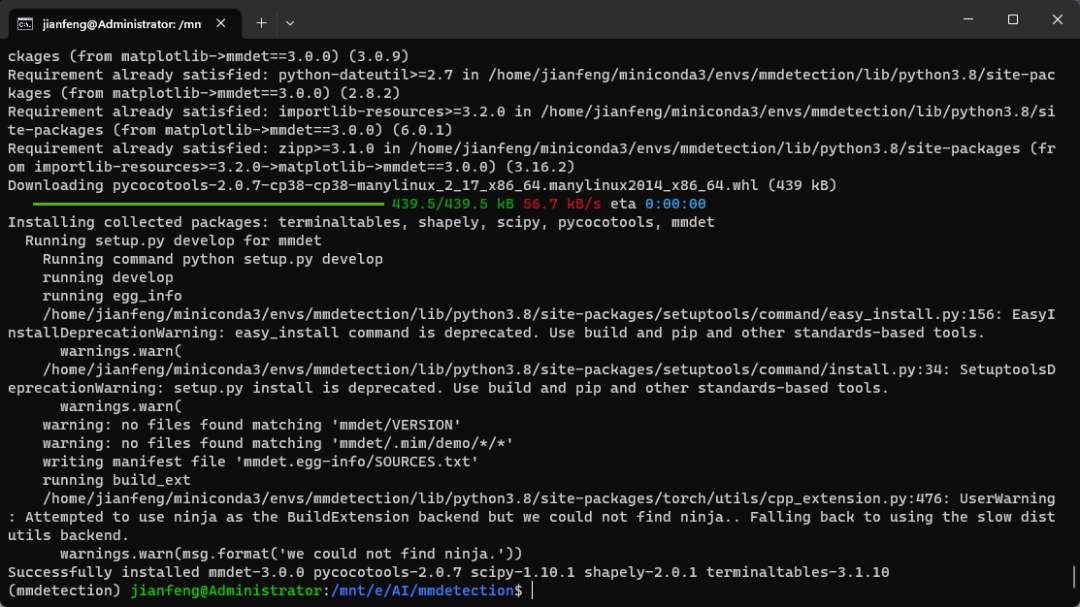
在安装完后,官网还提供一个代码来测试是否成功安装。
#步骤 1. 我们需要下载配置文件和模型权重文件。
mim download mmdet --config rtmdet_tiny_8xb32-300e_coco --dest .
#下载将需要几秒钟或更长时间,这取决于你的网络环境。完成后,你会在当前文件夹中发现两个文件 rtmdet_tiny_8xb32-300e_coco.py 和 rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth。
#步骤 2. 推理验证。
python demo/image_demo.py demo/demo.jpg rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --device cuda
#你会在当前文件夹中的 outputs/vis 文件夹中看到一个新的图像 demo.jpg,图像中包含有网络预测的检测框。假如上述的操作成功被执行而且没有报错,那么恭喜你,你成功安装了 MMDetection!接下来就可以正式进入开发的工作了。

数据准备
在本项目中,我们将使用开源的数据集来演示 MMDetection 的全流程使用。常见的开源数据集网站包括 Hugging Face、Kaggle 和 AI Studio。由于我是土木工程管理专业的,在该专业里最常见的目标检测应用就是安全帽检测,因此下面我将演示如何在 Kaggle 搜索安全帽检测数据集并在 MMDetection 训练的全流程。
进入 Kaggle 的界面后,我们可以看到左边栏里有一栏 Datasets,这就是 Kaggle 里专门存放数据集的地方。我们点击进去后搜索 Helmet Detection(安全帽检测)就可以看到大量的相关数据集。我们可以找到最多人点赞的数据集进去查阅。
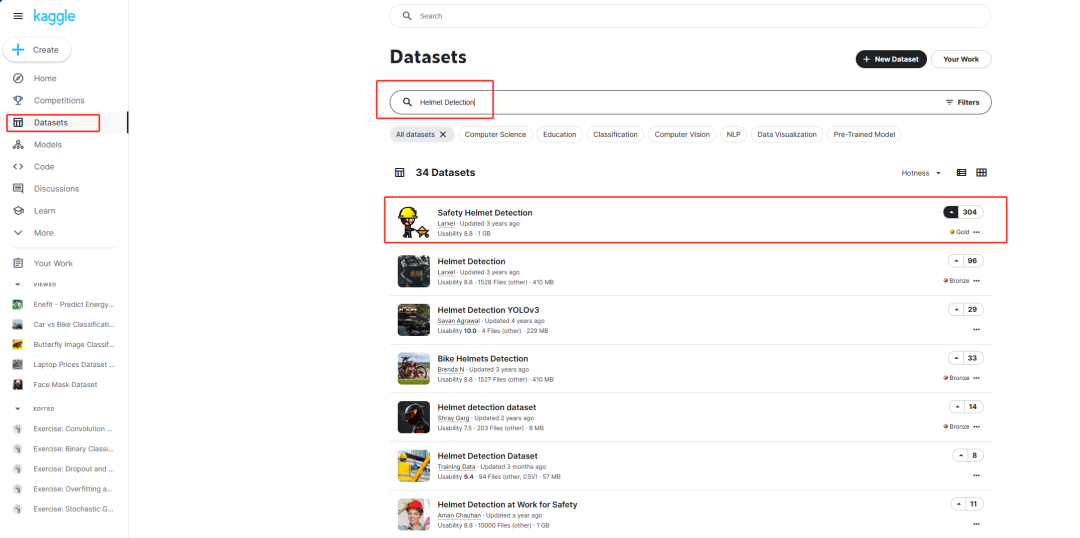
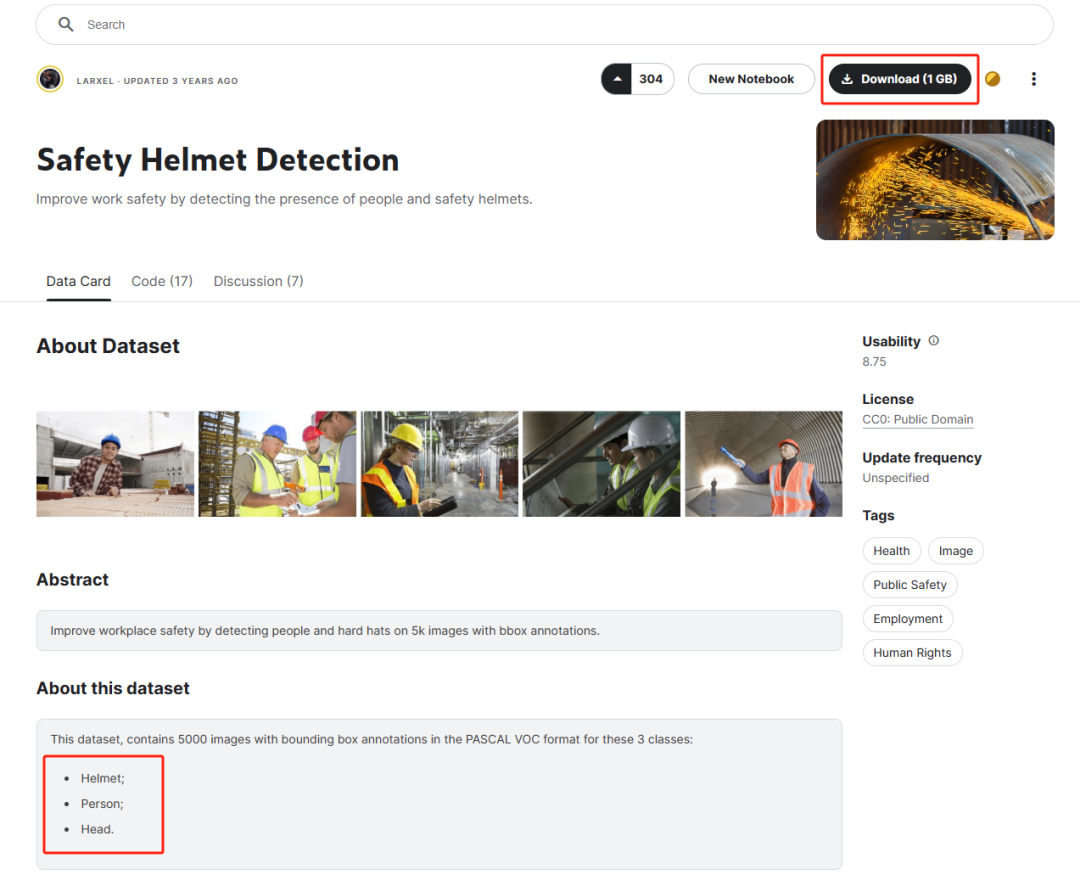
进去后可以看到一些基本的信息,包括标注的类别,文件的大小,整体文件格式和内容等等。从格式上看,这是一个 VOC 格式的标注文件(后缀名为 xml),假如我们遇到标注文件为 txt 的大概就是 YOLO 格式的标注文件,假如我们遇到 json 格式的标注文件那大概就是 COCO 和 JSON 格式的标注文件,不同的标注文件都有不同的格式,我们应用的时候都需要根据具体的要求进行转换。
假如我们认为这部分数据有意义的话,我们就可以下载到 MMDetection 下的 data 文件夹里(没有的话就新建一个)进行保存。
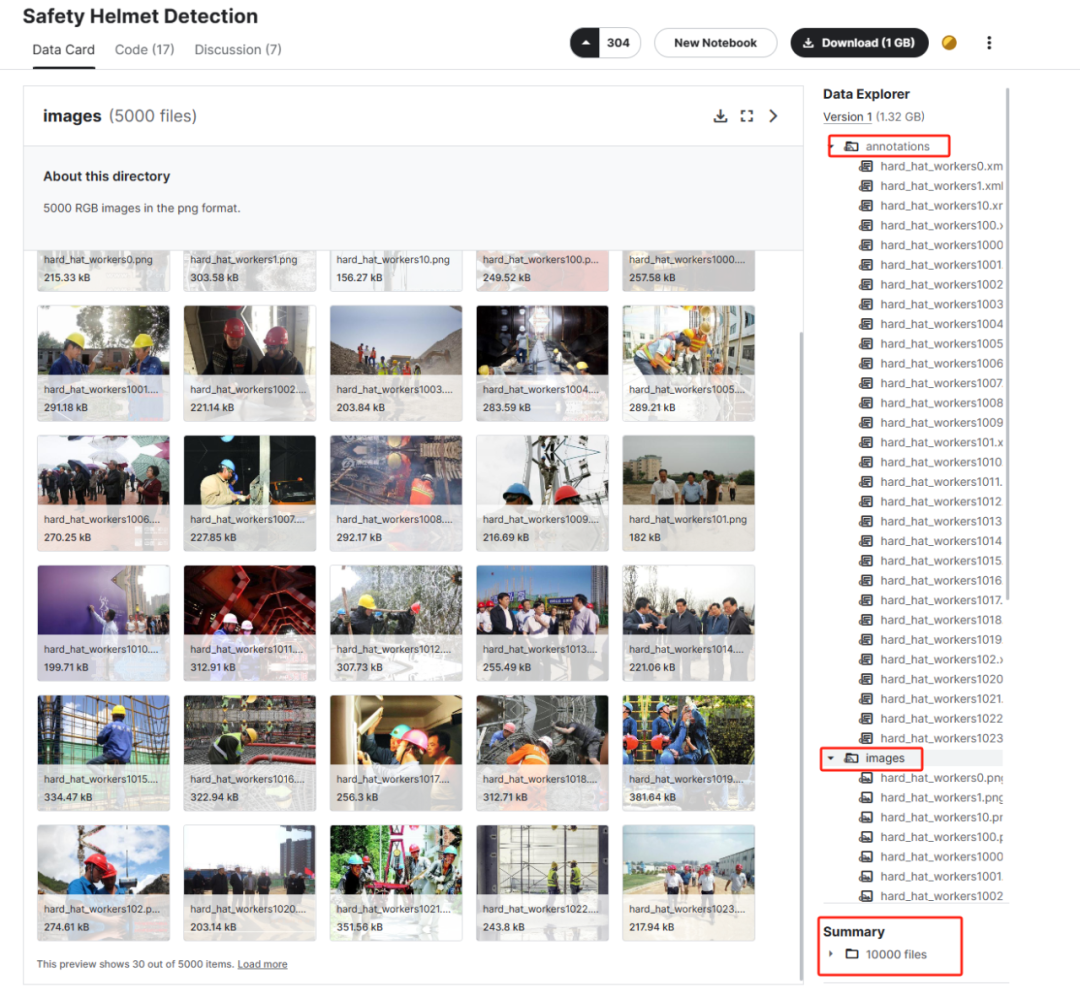
这样我们的数据准备就完成了,下面我们就需要将这部分数据转换成适合于模型训练的数据并开始模型的训练。
格式转换
在 MMDetection 和 MMYOLO 里,几乎所有的训练都是依靠 COCO JSON 标注文件,因此我们需要先将在 labelme 中转化得到的 voc 数据转化为 coco 格式的数据才能正常的进行训练。幸运的是,在 MMDetection 源码中就提供了这样的一个脚本来帮我们进行转化,我们利用这个脚本就能实现 voc 格式数据集转化成 coco 格式数据集。但是前提是要在 MMDeteciton 源码下的 mmdet/evaluation/functional/class_names.py 这个 Python 文件里找到coco_classes 和 voc_classes 的位置(按ctrl+F搜索即可)并添加我们需要的标签。不然将无法进行转化。在这里我们要添加的标签就是“helmet”、“person”、“head”。
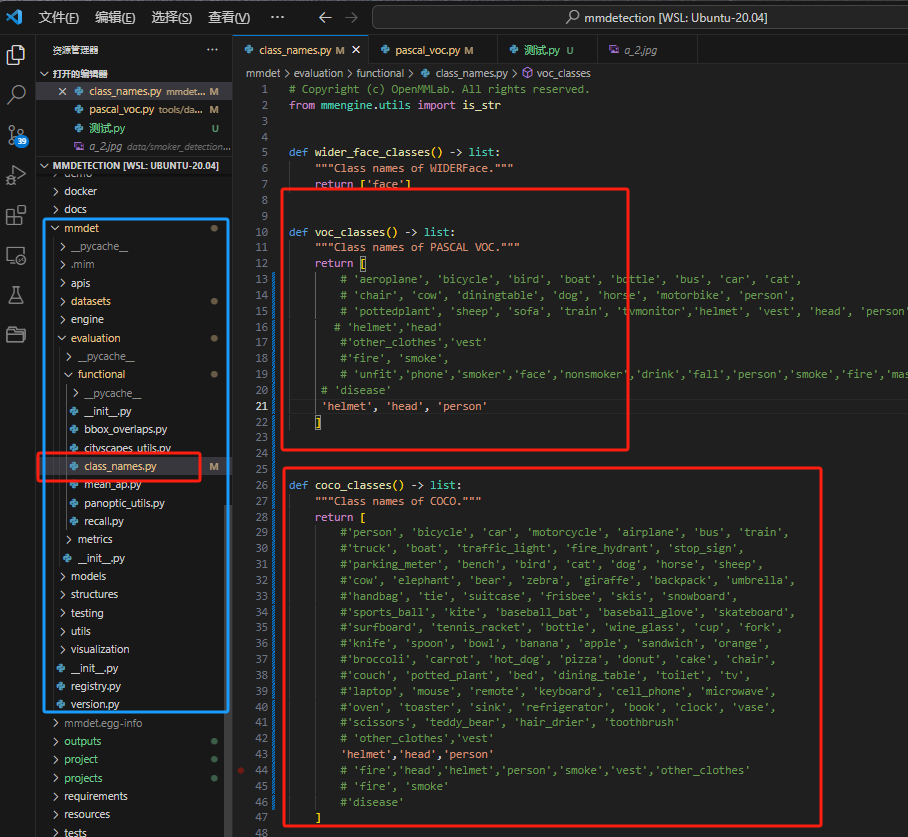
注意事项:使用其他地方搜集到的 voc2coco 可能并不能让模型正常的运行,主要原因是 voc2coco 这个脚本写得不鲁棒,如果写的比较鲁棒原则上是可以直接用的。
接下来我们就需要进入源码中找到 tools/dataset_converters/pascal_voc.py 文件,并了解其所需要的文件结构和转化后的内容。由于官方提供的代码转换出来的格式并不符合预期,我对该代码进行了修正,从而让 VOC 转出来的 COCO 格式直接可以用于实际的训练当中(修改后删除了 trainval.txt 和 test.txt 的转换,所以我们只需要考虑训练集和验证集的内容即可。另外还将根据 xml 的标注文件将图片文件按照官方 COCO 数据集的形式复制进入,那么我们就不再需要额外的脚本进行此类操作)。
我修改后的 tools/dataset_converters/pascal_voc.py 文件,请见文末。
然后假如我们要了解如何调用该模型以及我们的原数据该准备怎么样的结构输入进去的话,我们可以利用大语言模型的解析能力来为我们进行分析(下面是靠 ChatGPT 解析出来的结果)。
提示词:
#上面是代码的内容
请你作为一名 python 的代码专家,请你根据上述的代码,为我进行分析我所需要准备的数据是什么结构的,然后如何进行调用这个代码呢?
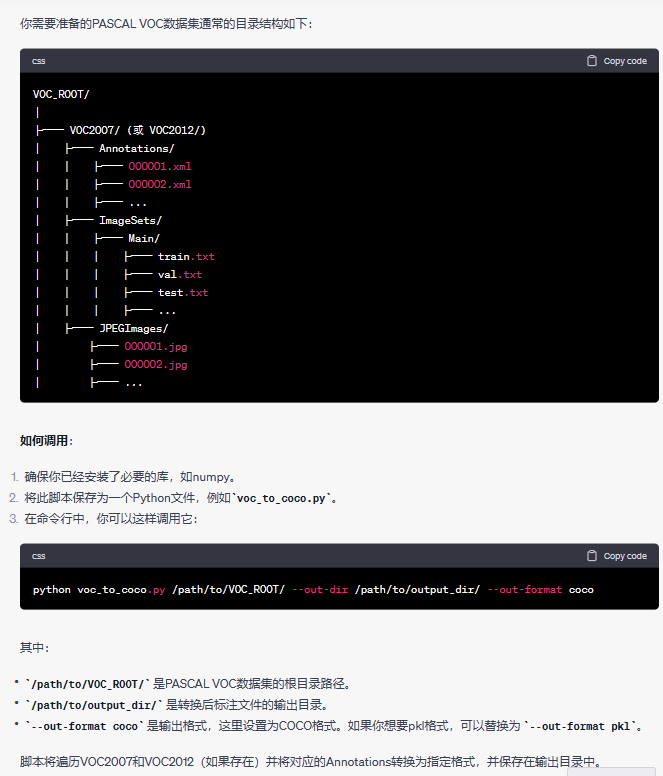
因此下面我们就需要调整一下我们原有的文件格式。下面是原有的数据结构。
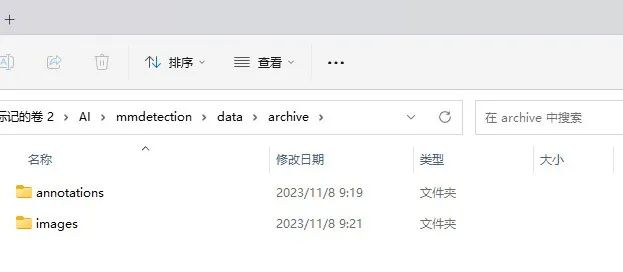
可以看到现在的文件格式和所需要的文件格式并不匹配,我们需要进一步调整该数据结构才能使用官方配备的转换代码进行转换。这部分的工作其实很重复枯燥,我们同样可以利用大语言模型来创建脚本辅助我们完成。
提示词:
请你作为一名 python 的脚本专家,辅助我完成以下任务。在 data/archive 文件夹下有两个文件夹。一个是 annotations,里面存放着所有的 xml 标注文件。另一个是 images,里面存放了所有的原始图片文件。现在我希望你能够帮我写一个脚本完成一些重复的操作。
首先你先把 archive 文件夹改名为 VOC2007,并且把里面的 annotations 文件的名称修改为 Annotations,同时把 images 的文件夹名称修改为 JPEGImages。并且检查 JPEGImages 文件夹里的文件是否为 jpg 文件,假如里面的图片文件不是 jpg 文件,请统一将里面的图片文件修改为 jpg 格式。
最后请在 data/archive 文件夹下新建一个名为 ImageSets 的文件夹,并且在里面创建一个 Main 的子文件夹,然后再在里面创建两个文件 train.txt 和 val.txt。在 train.tx t里我希望你能够放入 data/archive/JPEGImages 里随机 80% 的图片名称(不含后缀),剩余的 20% 放到 val.txt 文件中。完成代码后请给显示已完成。请一步步思考后,给我完整的脚本代码,谢谢。
下面是利用大语言模型 ChatGPT 所获得的的回复。
好的,我们可以分几个步骤来完成这个任务:
- 重命名文件夹:将 archive 重命名为 VOC2007,并在内部将 annotations 重命名为 Annotations,images 重命名为 JPEGImages。
- 转换图片格式:检查 JPEGImages 文件夹里的所有文件,如果发现非 .jpg 文件,转换为 .jpg 格式。
- 创建文件夹结构:在 data/VOC2007 下创建 ImageSets/Main 文件夹结构。
- 分配图片到文本文件:将 JPEGImages 文件夹内 80 %的图片名称(不含扩展名)写入 train.txt,剩余 20% 的图片名称写入 val.txt。
以下是完成上述步骤的 Python 脚本代码:
import os
import random
from PIL import Image
# 设置基础目录路径
base_dir = "data"
archive_dir = os.path.join(base_dir, "archive")
# 步骤1:重命名文件夹
os.rename(archive_dir, os.path.join(base_dir, "VOC2007"))
# 更新文件夹变量以匹配新路径
voc_dir = os.path.join(base_dir, "VOC2007")
annotations_dir = os.path.join(voc_dir, "annotations")
images_dir = os.path.join(voc_dir, "images")
# 重命名子文件夹
os.rename(annotations_dir, os.path.join(voc_dir, "Annotations"))
os.rename(images_dir, os.path.join(voc_dir, "JPEGImages"))
# 步骤2:转换图片格式
jpegimages_dir = os.path.join(voc_dir, "JPEGImages")
for filename in os.listdir(jpegimages_dir):
if not filename.lower().endswith(".jpg"):
original_image_path = os.path.join(jpegimages_dir, filename)
image = Image.open(original_image_path)
converted_filename = os.path.splitext(filename)[0] + '.jpg'
converted_image_path = os.path.join(jpegimages_dir, converted_filename)
image.convert('RGB').save(converted_image_path, 'JPEG') # 将图片转换为RGB格式的JPG文件
os.remove(original_image_path) # 删除原始文件
# 步骤3:创建文件夹结构
imagesets_dir = os.path.join(voc_dir, "ImageSets")
main_dir = os.path.join(imagesets_dir, "Main")
os.makedirs(main_dir, exist_ok=True)
# 步骤4:分配图片到train.txt和val.txt
image_filenames = [os.path.splitext(f)[0] for f in os.listdir(jpegimages_dir) if f.lower().endswith('.jpg')]
random.shuffle(image_filenames)
split_index = int(0.8 * len(image_filenames))
train_filenames = image_filenames[:split_index]
val_filenames = image_filenames[split_index:]
with open(os.path.join(main_dir, 'train.txt'), 'w') as file:
file.write("\n".join(train_filenames))
with open(os.path.join(main_dir, 'val.txt'), 'w') as file:
file.write("\n".join(val_filenames))
print("已完成")在运行脚本之前,请确保目标目录下有 data/archive 文件夹存在,且该文件夹下有 annotations 和 images 两个子文件夹。另外,请确保已经安装了 Pillow 库,如果没有安装,请使用 pip install Pillow 进行安装。
您可以将上述代码保存为 .py 文件,并在包含 data/archive 的目录中运行它。完成上述操作后,应会在控制台中看到"已完成"的消息。
我们运行脚本后就能得到以下格式的文件:
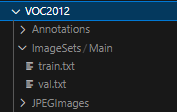
接下来我们就可以调用脚本来进行格式的转换了,调用脚本的格式如下(之所以输出格式是这样主要是满足数据集制定的要求):
python tools/dataset_converters/pascal_voc.py data --out-dir data/coco/annotations --out-format coco- python:这是启动 Python 解释器的命令。
- tools/dataset_converters/pascal_voc.py:这是脚本文件的路径,其中包含了转换工作的代码。
- data: 这是命令行参数 devkit_path,表示 VOC 数据集开发工具包的路径。它应该包含 VOC2007 和/或 VOC2012 数据集的文件夹。
- --out-dir data/coco/annotations:这是一个可选参数,用于指定输出目录。在这里,转换后的COCO格式的JSON文件将被保存在 data/coco/annotations 目录下。
- --out-format coco:这个可选参数定义了输出格式,这里指定为 COCO 格式。
经过一段时间的标注文件创建以及图片复制后,我们可以得到以下内容:
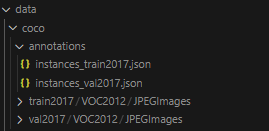
在 annotations 里创建了 train 和 val 两个 COCO 格式的标注文件,在 train2017 和 val2017 下按照具体数据集需要的格式创建了以下文件夹,并且 JPEGImages 里保存了所有训练集的图片和验证集的图片。这样我们的数据就已经符合 MMDetection 的训练条件了,下面我们可以创建自己的数据集类以及修改配置文件来真正的开始模型的训练了!
创建新的数据集类
或参考这篇文档分享修改 metainfo 即可:https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/get_started/15_minutes_object_detection.md#%E9%85%8D%E7%BD%AE%E5%87%86%E5%A4%87
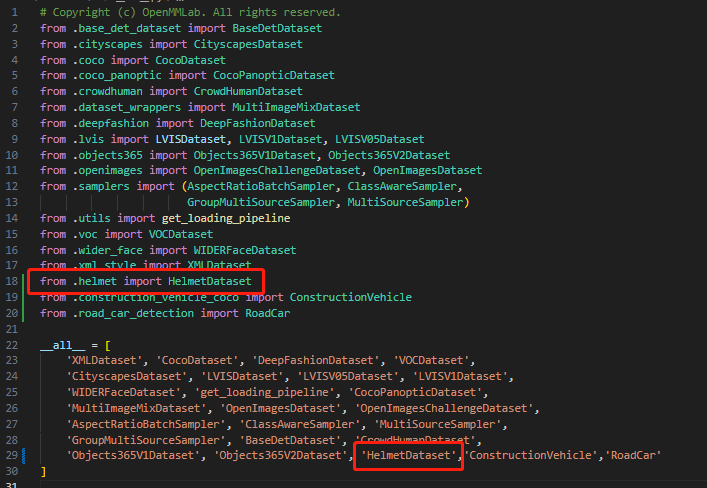
首先我们需要先进入 mmdet/datasets 这个文件夹里,并创建一个自己命名数据集的 Python 文件,比如说 helmet。
然后,由于大部分都是 coco 格式的数据集,因此我们需要复制名为 coco.py 文件的内容到 helmet.py 文件,然后修改里面对应的内容。如下图所示,我们主要要修改的内容就是 classes 和 palette,使其的类别的色彩板能够一一对应。同时我们还要修改 class 的名称,可以改为 HelmetDataset。
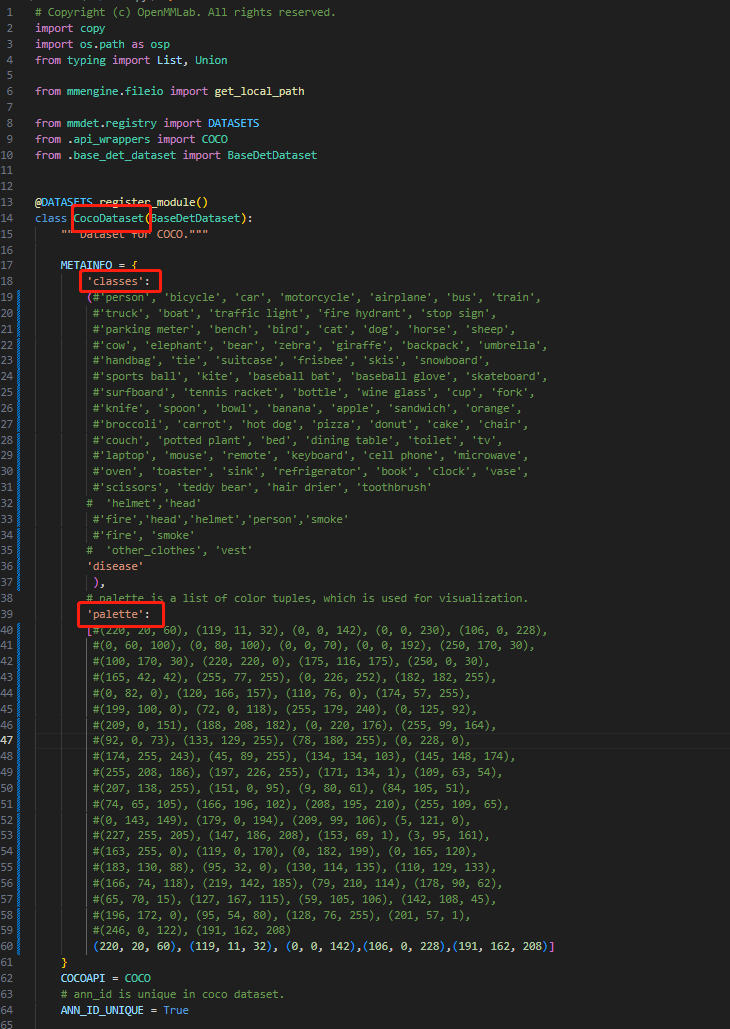
下面这张图是原本 CocoDataset 的内容:
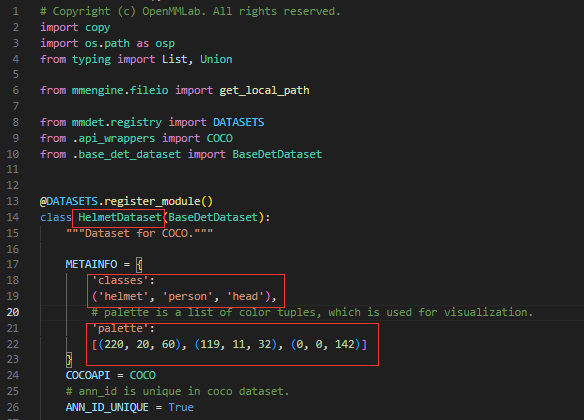
下面这张图是修改为 HelmetDataset 的内容:
在创建完后,我们还需要去 mmdet/datasets/__init__.py 文件里进行录入,.helmet 指的就是我们的 helmet.py 文件,我们也可以输入完整的路径,import 的内容就是我们自定义的 dataset 名字。最后在下面也要加上对应 Dataset 的名称。
配置文件准备及修改
由于在 MMDetection 或者 MMYOLO 里大多用的都是 COCO 格式的数据集,因此我认为在这里我们直接用终端进行调用然后修改 work_dir 文件夹里对应的配置文件会比起重新创建更加的方便。
首先我们需要找到 config 文件夹里我们想要的模型文件(我常用的就是 yolo),然后查看里面的 README 文件来看适合我们显卡内存的配置文件(我的显存有 8G,所以基本都可以使用)。越大的模型效果越好,但是假如我们训练的时候出现 CUDA out of memory 的话,那就是显存不够或者算力不够的情况,我们就需要选择更小的模型进行训练。
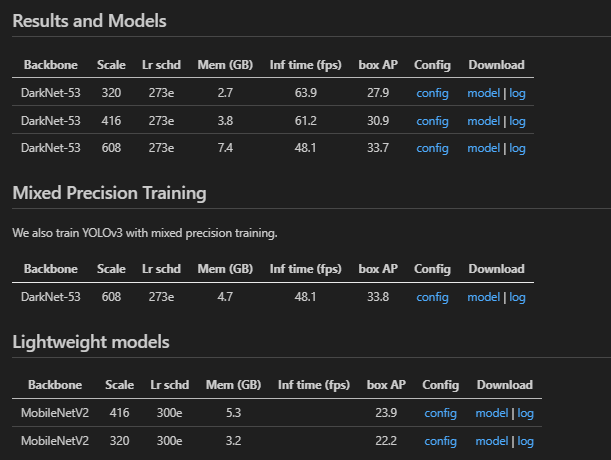
然后选择了一个 mobilenetv2 的模型直接在终端输入以下命令。
python tools/train.py configs/yolo/yolov3_mobilenetv2_8xb24-320-300e_coco.py然后我们就能够在 work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco 文件夹里找到完整的配置文件(yolov3_mobilenetv2_8xb24-320-300e_coco.py)。
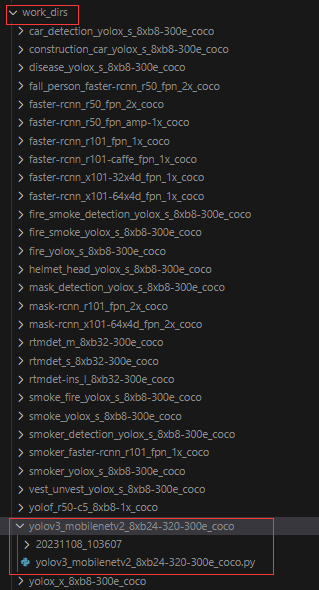
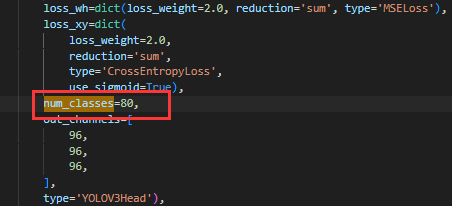
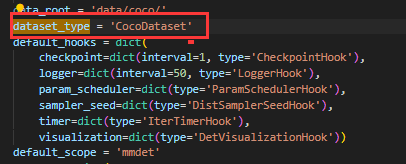
然后我们点击配置文件,为了让模型能够顺利训练,我们主要修改的就是 dataset_type 以及 num_classes(数据格式已经在前面转换中完成),我们可以点击 Ctrl+F 找到这部分的内容并进行修改。
- 把类别从 80 修改为我们的类别 3
- 将 dataset_type 修改为我们刚刚制作的 HelmetDataset
除此之外,我们其实也可以调整一些模型的超参数。比如说我们数据集很少的话,然后我希望其能够不那么快拟合,我们可以把学习率调得比较小,从而让其能够慢慢的学习到图像的特征。
- lr 学习率可以从 0.003 调整为 0.0001

我们还可以修改优化器类型,比如 SGD 修改为 Adam等 。但是一般来说我们其实只有在模型效果不好的时候才会考虑使用这部分操作。
修改完成后,我们就可以调用这个配置文件进行模型的训练了。
模型训练
在完成配置文件后,我们只需要利用终端调用就可以进行训练了。
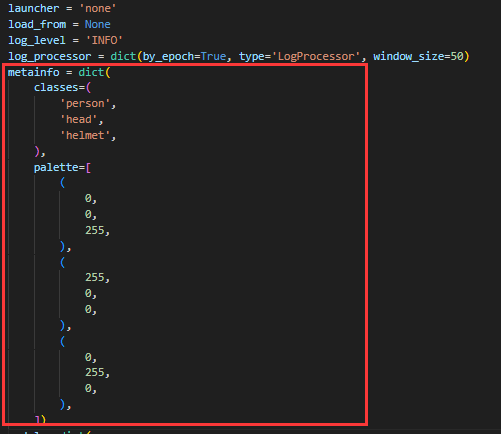
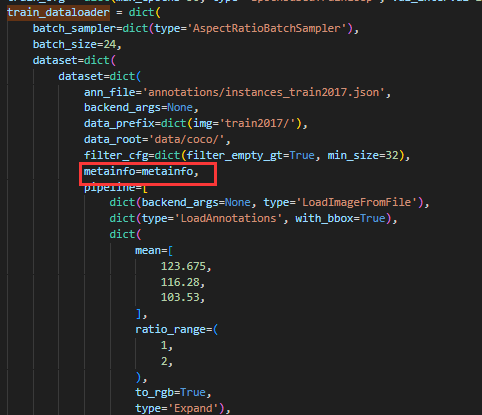
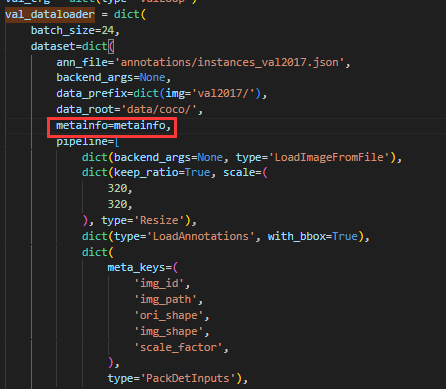
python tools/train.py work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/yolov3_mobilenetv2_8xb24-320-300e_coco.py但是我们输入了代码后,会很惊奇地发现出现了一个问题,就是出现了 need at least one array to concatenate 的报错。这个报错其实比较常见,其主要原因是数据集或者是配置文件出了问题。在检查了自己的数据集并查阅了网上的解决方案后,我定位了问题。就是我们需要以类似于创建 Datasets 的方式创建一个 metainfo,将自己的 classes(标签类别)和 palette(调色板)写入,并且在 train_dataloader、val_dataloader 和 test_dataloader 里写入即可。
- 创建 metainfo
- 写入 train_dataloader
- 写入 val_dataloader
- 写入 test_dataloader
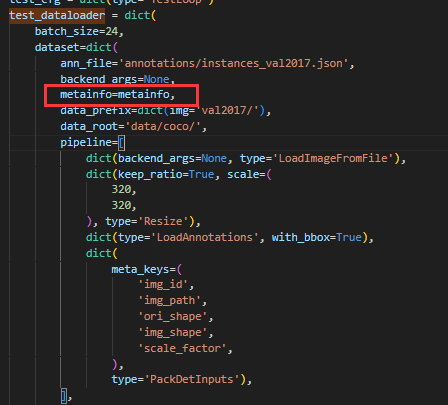
修改后我们再尝试在终端运行代码。
python tools/train.py work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/yolov3_mobilenetv2_8xb24-320-300e_coco.py当我们看到第一个批次出现后就代表训练正式进行中,我们还可以看到其他一些信息,包括 eta(预计完成时间)以及 Loss(损失值)。
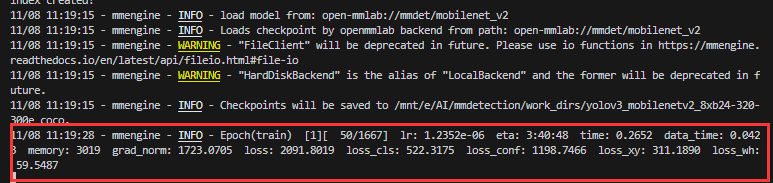
训练过程中常见的问题及方法:
- 成功训练后发现打印出来的 loss 有些为 0:比如说上面这个第一批次里基本上 loss 都很大,但是假如有几个为 0 并且损失值掉落非常迅速的话,我们可以考虑检查一下数据集是否有问题。在官方代码中有一个展示数据集的工具,可以看到训练的数据集是否被成功的标注上。我们可以在使用这个脚本文件:tools/analysis_tools/browse_dataset.py 并在终端输入 python tools/analysis_tools/browse_dataset.py xxx.py(你的 config 文件)即可检查数据集是否成功标注。假如有问题就要查看原始的数据集并进行解决。
- 假如出现了 CUDA out of memory,这个主要的原因就是在于显卡的显存不足。这个时候就需要选择更小的模型或者是替换更高算力的卡进行使用。
- 假如出现了上面这个 need at least one array to concatenate 的报错,就要按照我上面讲的方式进行处理。这个报错其实在 YOLO 模型中会经常出现,我在调用 YOLOV5 模型的时候就因为这个问题困扰了很久。
- 然后其他的问题主要的就是检查数据集的路径是否一一对应。我这个数据集的设定几乎就是所有 MMDetection 里标准的数据集对应格式(假如用 psacal_voc.py 进行转换的话)。然后还需要检查的就是数据集的类是否能够对应上,class_names 里是否在 voc_classes 和 coco_classes 里把数据集里的标签是否添加进去。这样几乎就能够解决绝大部分的问题了。
模型结果
当训练完成后,训练好的结果就能够在 work_dir 里查看到,里面有模型的配置文件,权重文件以及训练过程中的记录。
MMDetection 提供了对这些 log 文件进行图像绘制的工具,我们可以打印看看这里面 Loss 的变化情况如何。脚本的位置为tools/analysis_tools/analyze_logs.py,具体调用的地址如下:
python tools/analysis_tools/analyze_logs.py plot_curve work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/20231108_113125/vis_data/20231108_113125.json --keys loss --out results.png --legend loss- python tools/analysis_tools/analyze_logs.py plot_curve:运行 analyze_logs.py 脚本,并告诉它执行 plot_curve 任务,这是一个子命令。
- work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/20231108_113125/vis_data/20231108_113125.json:这是输入的 JSON 格式的日志文件路径,其中记录了训练过程中的数据。
- --keys loss:指定了要绘制的关键指标,这里是损失(loss)。
- --out results.png:指定输出图像的文件名。
- --legend loss:为绘制的曲线指定图例。
打印出来的 loss 图如下所示:
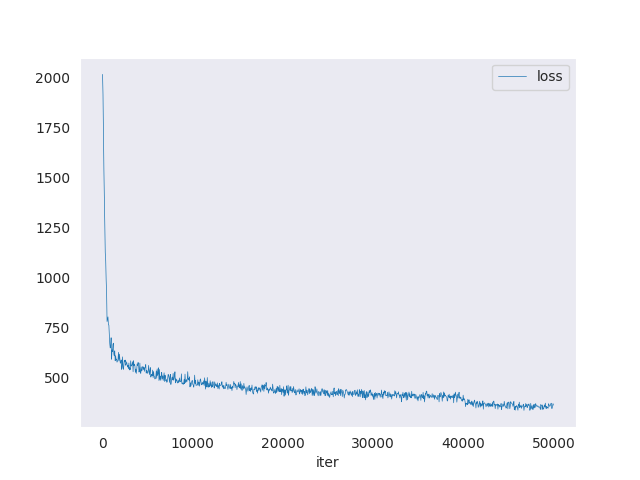
可以看到 loss 随着训练逐步降低,从原本的 2000 降到接近于 300。但是这个还是一个相对较高的 loss,因此模型的准确度也仅在 30 %左右。我们可以在网上实际找几张图片来测试一下模型在实际图片上的效果如何。
模型测试
MMDetection 源码里提供了调用模型的配置和权重文件来直接对图像进行测试的 demo 工具,我们可以直接在终端调用 demo/image_demo.py 这个文件来实现模型的效果测试。具体的调用方式如下:
python demo/image_demo.py demo/1.jfif work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/20231108_113125/vis_data/config.py --weights work_dirs/yolov3_mobilenetv2_8xb24-320-300e_coco/epoch_30.pth --show我在网上随意找了几张图片放进去测试。切记不能够在原本数据集找图片进行测试,除非是预留了 test。因为被训练的图像都已经过拟合了,因此其就算判断正确不也能够确保是模型的效果很好还是过拟合的程度很高。



得到的结果为:
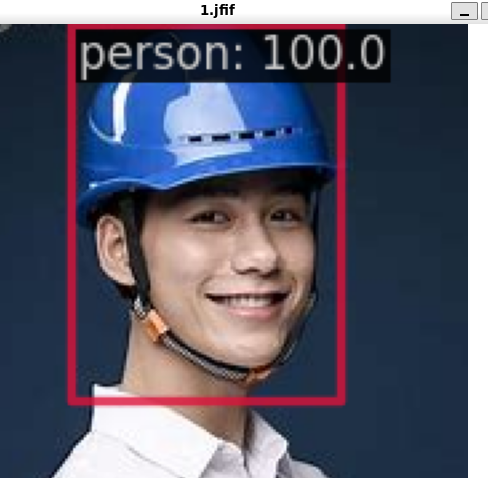
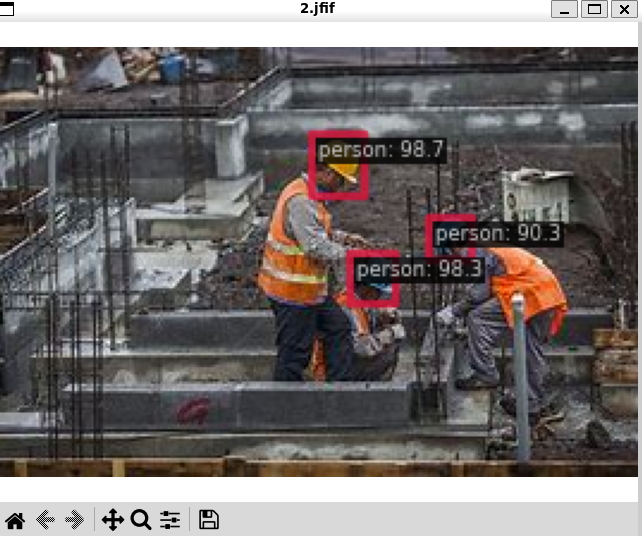

这里虽然预测结果显示为 person,但是这并不代表模型检测真的认为是 person,可能只是因为输出的类是 person 而已。这里的 person 应该就是代表的是 helmet,我们后期只需要对其更改一下即可。但是总体来看,模型的效果还是可以的,即便是有多个人站在一起或者说是在一些复杂的施工场地下也能够识别出来带了安全帽的人,因此该模型还是有可取之处的。
总结
MMDetection 不仅提供了丰富的模型选择和配置,还提供了完善的安装、配置和训练流程。用户可以根据自己的需求,从中选择合适的模型进行训练和推理,无论是追求速度还是效果,MMDetection 都能提供相应的解决方案。
此外,MMDetection 还为用户提供了强大的可视化工具和日志分析工具,使得用户可以直观地观察模型的训练过程和结果,及时调整策略。通过充分利用 MMDetection 的这些工具和特性,即使是深度学习领域的新手也能有效地进行模型训练和优化,推进自己的研究或项目。
相信经过以上的详细介绍,大家已经对 MMDetection 工具箱有了深入的认识,那么是时候开始一步步训练一个自己的 MMDetection 模型啦。
但是假如我们认为这个模型还不够好,我们希望能够进一步地优化模型呢?别急,我将在之后的文章继续为大家介绍模型优化的方式,敬请期待哦 ~
附录
(以下是我修改后的 tools/dataset_converters/pascal_voc.py 文件)
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os.path as osp
import xml.etree.ElementTree as ET
import shutil
import numpy as np
from mmengine.fileio import dump, list_from_file
from mmengine.utils import mkdir_or_exist, track_progress
from mmdet.evaluation import voc_classes
label_ids = {name: i for i, name in enumerate(voc_classes())}
def parse_xml(args):
xml_path, img_path = args
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
bboxes = []
labels = []
bboxes_ignore = []
labels_ignore = []
for obj in root.findall('object'):
name = obj.find('name').text
label = label_ids[name]
difficult = obj.find('difficult')
difficult = 0 if difficult is None else int(difficult.text) # 设置默认值为0
bnd_box = obj.find('bndbox')
bbox = [
round(float(bnd_box.find('xmin').text)), # 使用四舍五入取整
round(float(bnd_box.find('ymin').text)), # 使用四舍五入取整
round(float(bnd_box.find('xmax').text)), # 使用四舍五入取整
round(float(bnd_box.find('ymax').text)) # 使用四舍五入取整
]
if difficult:
bboxes_ignore.append(bbox)
labels_ignore.append(label)
else:
bboxes.append(bbox)
labels.append(label)
if not bboxes:
bboxes = np.zeros((0, 4))
labels = np.zeros((0, ))
else:
bboxes = np.array(bboxes, ndmin=2) - 1
labels = np.array(labels)
if not bboxes_ignore:
bboxes_ignore = np.zeros((0, 4))
labels_ignore = np.zeros((0, ))
else:
bboxes_ignore = np.array(bboxes_ignore, ndmin=2) - 1
labels_ignore = np.array(labels_ignore)
annotation = {
'filename': img_path,
'width': w,
'height': h,
'ann': {
'bboxes': bboxes.astype(np.float32),
'labels': labels.astype(np.int64),
'bboxes_ignore': bboxes_ignore.astype(np.float32),
'labels_ignore': labels_ignore.astype(np.int64)
}
}
return annotation
def cvt_annotations(devkit_path, years, split, out_file):
if not isinstance(years, list):
years = [years]
annotations = []
for year in years:
filelist = osp.join(devkit_path,
f'VOC{year}/ImageSets/Main/{split}.txt')
if not osp.isfile(filelist):
print(f'filelist does not exist: {filelist}, '
f'skip voc{year} {split}')
return
img_names = list_from_file(filelist)
xml_paths = [
osp.join(devkit_path, f'VOC{year}/Annotations/{img_name}.xml')
for img_name in img_names
]
img_paths = [
f'VOC{year}/JPEGImages/{img_name}.jpg' for img_name in img_names
]
part_annotations = track_progress(parse_xml,
list(zip(xml_paths, img_paths)))
annotations.extend(part_annotations)
if out_file.endswith('json'):
annotations = cvt_to_coco_json(annotations)
dump(annotations, out_file)
return annotations
def cvt_to_coco_json(annotations):
image_id = 0
annotation_id = 0
coco = dict()
coco['images'] = []
coco['type'] = 'instance'
coco['categories'] = []
coco['annotations'] = []
image_set = set()
def addAnnItem(annotation_id, image_id, category_id, bbox, difficult_flag):
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x1,y1,x2,y2
# left_top
seg.append(int(bbox[0]))
seg.append(int(bbox[1]))
# left_bottom
seg.append(int(bbox[0]))
seg.append(int(bbox[3]))
# right_bottom
seg.append(int(bbox[2]))
seg.append(int(bbox[3]))
# right_top
seg.append(int(bbox[2]))
seg.append(int(bbox[1]))
annotation_item['segmentation'].append(seg)
xywh = np.array(
[bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]])
annotation_item['area'] = int(xywh[2] * xywh[3])
if difficult_flag == 1:
annotation_item['ignore'] = 0
annotation_item['iscrowd'] = 1
else:
annotation_item['ignore'] = 0
annotation_item['iscrowd'] = 0
annotation_item['image_id'] = int(image_id)
annotation_item['bbox'] = xywh.astype(int).tolist()
annotation_item['category_id'] = int(category_id)
annotation_item['id'] = int(annotation_id)
coco['annotations'].append(annotation_item)
return annotation_id + 1
for category_id, name in enumerate(voc_classes()):
category_item = dict()
category_item['supercategory'] = str('none')
category_item['id'] = int(category_id)
category_item['name'] = str(name)
coco['categories'].append(category_item)
for ann_dict in annotations:
file_name = ann_dict['filename']
ann = ann_dict['ann']
assert file_name not in image_set
image_item = dict()
image_item['id'] = int(image_id)
image_item['file_name'] = str(file_name)
image_item['height'] = int(ann_dict['height'])
image_item['width'] = int(ann_dict['width'])
coco['images'].append(image_item)
image_set.add(file_name)
bboxes = ann['bboxes'][:, :4]
labels = ann['labels']
for bbox_id in range(len(bboxes)):
bbox = bboxes[bbox_id]
label = labels[bbox_id]
annotation_id = addAnnItem(
annotation_id, image_id, label, bbox, difficult_flag=0)
bboxes_ignore = ann['bboxes_ignore'][:, :4]
labels_ignore = ann['labels_ignore']
for bbox_id in range(len(bboxes_ignore)):
bbox = bboxes_ignore[bbox_id]
label = labels_ignore[bbox_id]
annotation_id = addAnnItem(
annotation_id, image_id, label, bbox, difficult_flag=1)
image_id += 1
return coco
def parse_args():
parser = argparse.ArgumentParser(
description='Convert PASCAL VOC annotations to mmdetection format')
parser.add_argument('devkit_path', help='pascal voc devkit path')
parser.add_argument('-o', '--out-dir', help='output path')
parser.add_argument(
'--out-format',
default='coco',
choices=('pkl', 'coco'),
help='output format, "coco" indicates coco annotation format')
args = parser.parse_args()
return args
def copy_images_to_folders(devkit_path, out_dir):
jpeg_images_dir = osp.join(devkit_path, 'JPEGImages')
image_sets_main_dir = osp.join(devkit_path, 'ImageSets', 'Main')
splits_and_dirs = {
'train': 'train2017',
'test': 'test2017',
'val': 'val2017'
}
for split, new_dir_name in splits_and_dirs.items():
txt_file = osp.join(image_sets_main_dir, f'{split}.txt')
new_folder = osp.join(out_dir, new_dir_name)
mkdir_or_exist(new_folder) # Ensure the directory exists
with open(txt_file, 'r') as f:
img_names = [line.strip() for line in f.readlines()]
for img_name in img_names:
src_img_path = osp.join(jpeg_images_dir, f'{img_name}.jpg')
dest_img_path = osp.join(new_folder, f'{img_name}.jpg')
shutil.copy(src_img_path, dest_img_path)
import os.path as osp
import shutil
def copy_images_to_dest(src_dir, dest_dir, img_list_file):
"""复制图片到目标文件夹"""
with open(img_list_file, 'r') as f:
lines = f.readlines()
img_names = [line.strip() + '.jpg' for line in lines]
print(f"Copying {len(img_names)} images from {src_dir} to {dest_dir} ...")
for img_name in img_names:
src_path = osp.join(src_dir, img_name)
dest_path = osp.join(dest_dir, img_name)
if not osp.exists(src_path):
print(f"Image {src_path} does not exist!")
continue
shutil.copy(src_path, dest_path)
print(f"Copied {img_name} to {dest_dir}")
def main():
args = parse_args()
devkit_path = args.devkit_path
out_dir = args.out_dir if args.out_dir else devkit_path
mkdir_or_exist(out_dir)
years = []
if osp.isdir(osp.join(devkit_path, 'VOC2007')):
years.append('2007')
if osp.isdir(osp.join(devkit_path, 'VOC2012')):
years.append('2012')
if '2007' in years and '2012' in years:
years.append(['2007', '2012'])
if not years:
raise IOError(f'The devkit path {devkit_path} contains neither '
'"VOC2007" nor "VOC2012" subfolder')
out_fmt = f'.{args.out_format}'
if args.out_format == 'coco':
out_fmt = '.json'
for year in years:
if isinstance(year, list):
multi_year = year
else:
multi_year = [year]
for y in multi_year:
for split in ['train', 'val']:
if split == 'train':
dataset_name = 'instances_train2017'
sub_folder = 'train2017'
elif split == 'val':
dataset_name = 'instances_val2017'
sub_folder = 'val2017'
else:
continue
print(f'processing {dataset_name} for VOC{y} ...')
cvt_annotations(devkit_path, y, split,
osp.join(out_dir, dataset_name + out_fmt))
# 创建并复制图片到对应的文件夹
img_out_dir = osp.join(out_dir, "..", sub_folder, f'VOC{y}', 'JPEGImages')
mkdir_or_exist(img_out_dir)
img_list_file = osp.join(devkit_path, f'VOC{y}', 'ImageSets', 'Main', f'{split}.txt')
src_img_dir = osp.join(devkit_path, f'VOC{y}', 'JPEGImages')
copy_images_to_dest(src_img_dir, img_out_dir, img_list_file)
print('Done!')
if __name__ == '__main__':
main()
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-08,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号