Pandas库的基础使用系列---DataFrame练习
原创
Pandas库的基础使用系列---DataFrame练习
原创
前言
我们前几篇文章和大家介绍了如何读取Excel,以及如何获取行数据,列数据,以及具体单元格数据。像我们目前只读取了一个Excel表中的一个sheet的数据,这个sheet的数据通常我们在pandas中称其为DataFrame,它可以包含一组有序的列(Series), 而每个Series可以有不同的数据类型,这个等我们后面再详细说,今天和一起针对DataFrame一起做几个小练习。DataFrame后面我们简称为df。
自定义默认索引
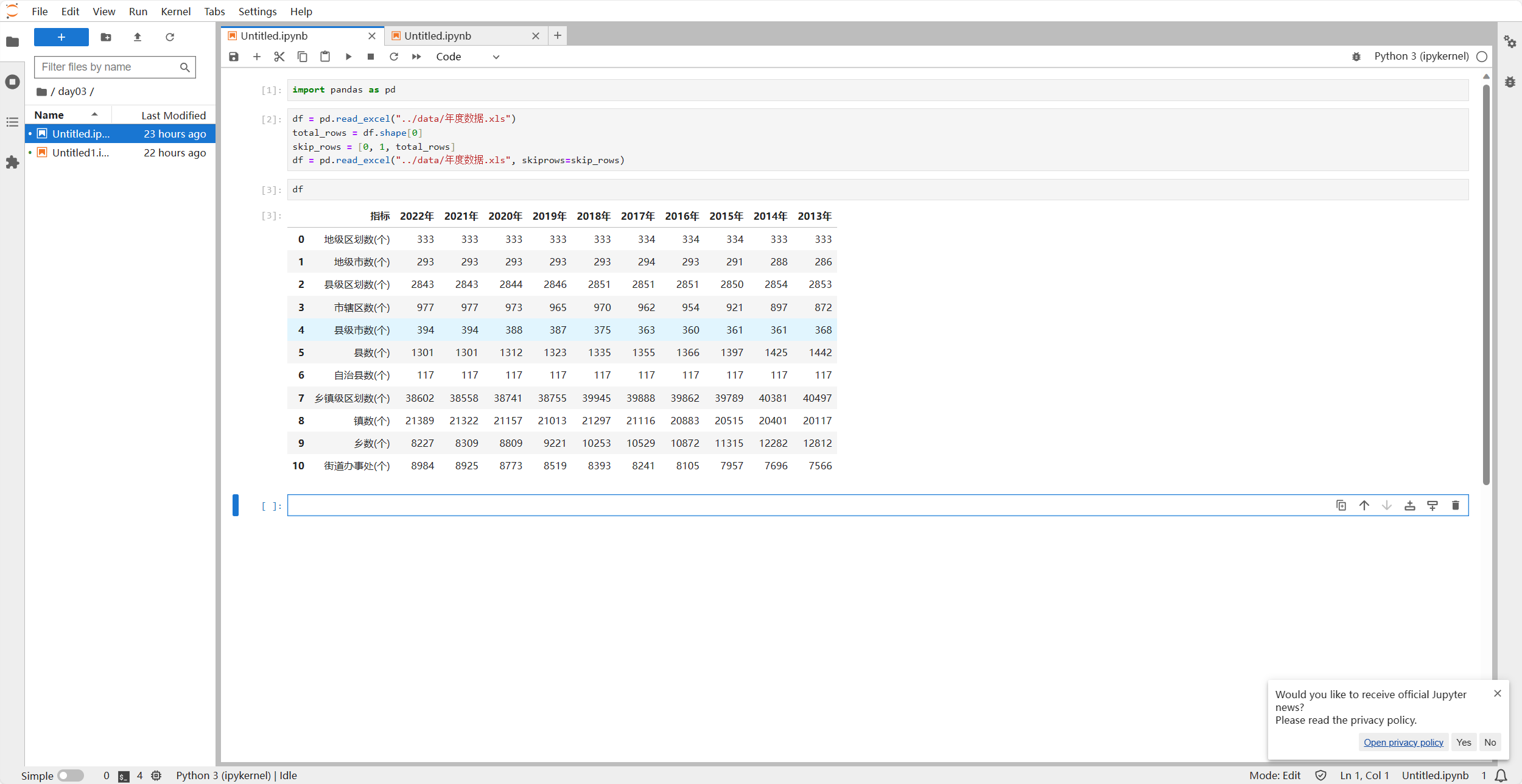
我们之前注意到读取excel数据后,pandas会自动为我们添加一列它是从0开始的一个index,我们试着将它修改为汉字的表现,即零,一,二,三,四这样的。
修改前的代码
import pandas as pd
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows)修改后的代码
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows)
df.index = ["零","一","二","三","四","五","六","七","八","九","十"]运行效果如下:
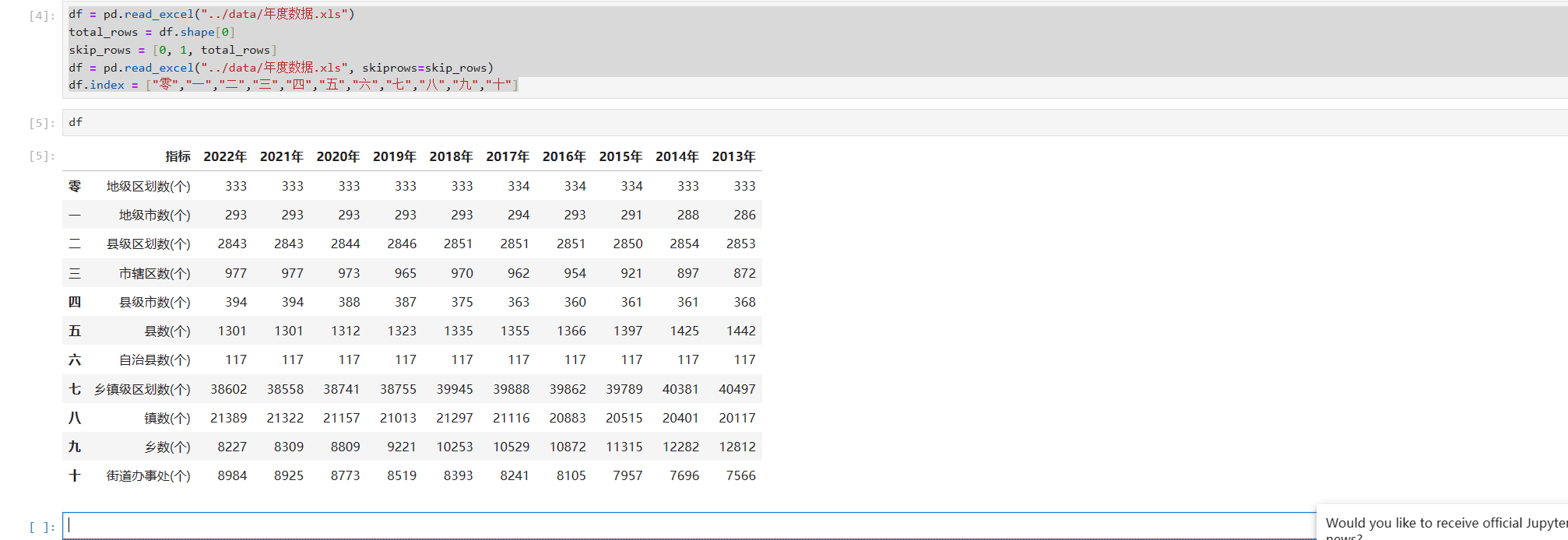
可以看到已经变化了,我们主要是通过以下代码实现的,你也可以试试其他的,比如从A开始。
df.index = ["零","一","二","三","四","五","六","七","八","九","十"]- 我们试试用一个连续的日期作为索引
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows)
df.index = pd.date_range("20231213", periods=11)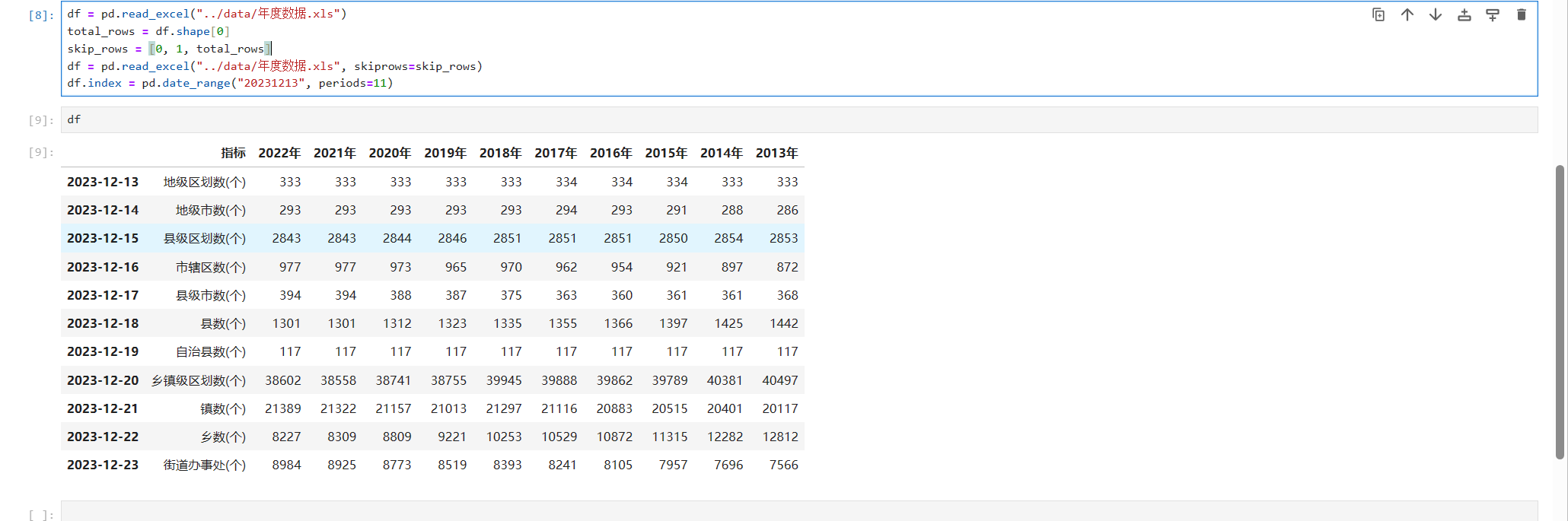
主要代码为
df.index = pd.date_range("20231213", periods=11)这里我们使用date_range这个方法创建了一个从20231213开始连续11天的列表,然后将它赋值给df.index
- 使用月份作为索引
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows)
df.index = pd.period_range(start='2023-01', end='2023-11', freq='M')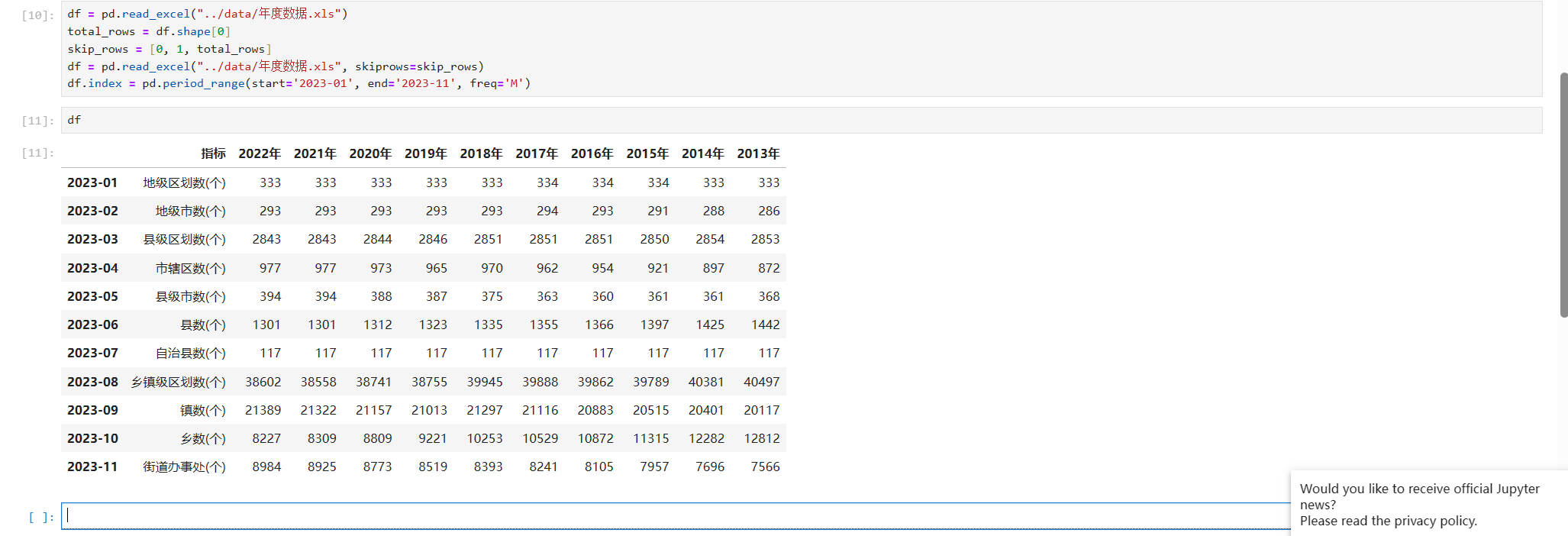
主要代码为
df.index = pd.period_range(start='2023-01', end='2023-11', freq='M')这里使用period_range这个方法,并指定了开始和结束的月份,同时指定了使用月份。
- 修改df的列名
我们看到目前df的列名里面都一个年,比如2022年,我们可以将年去掉,或者将20去掉
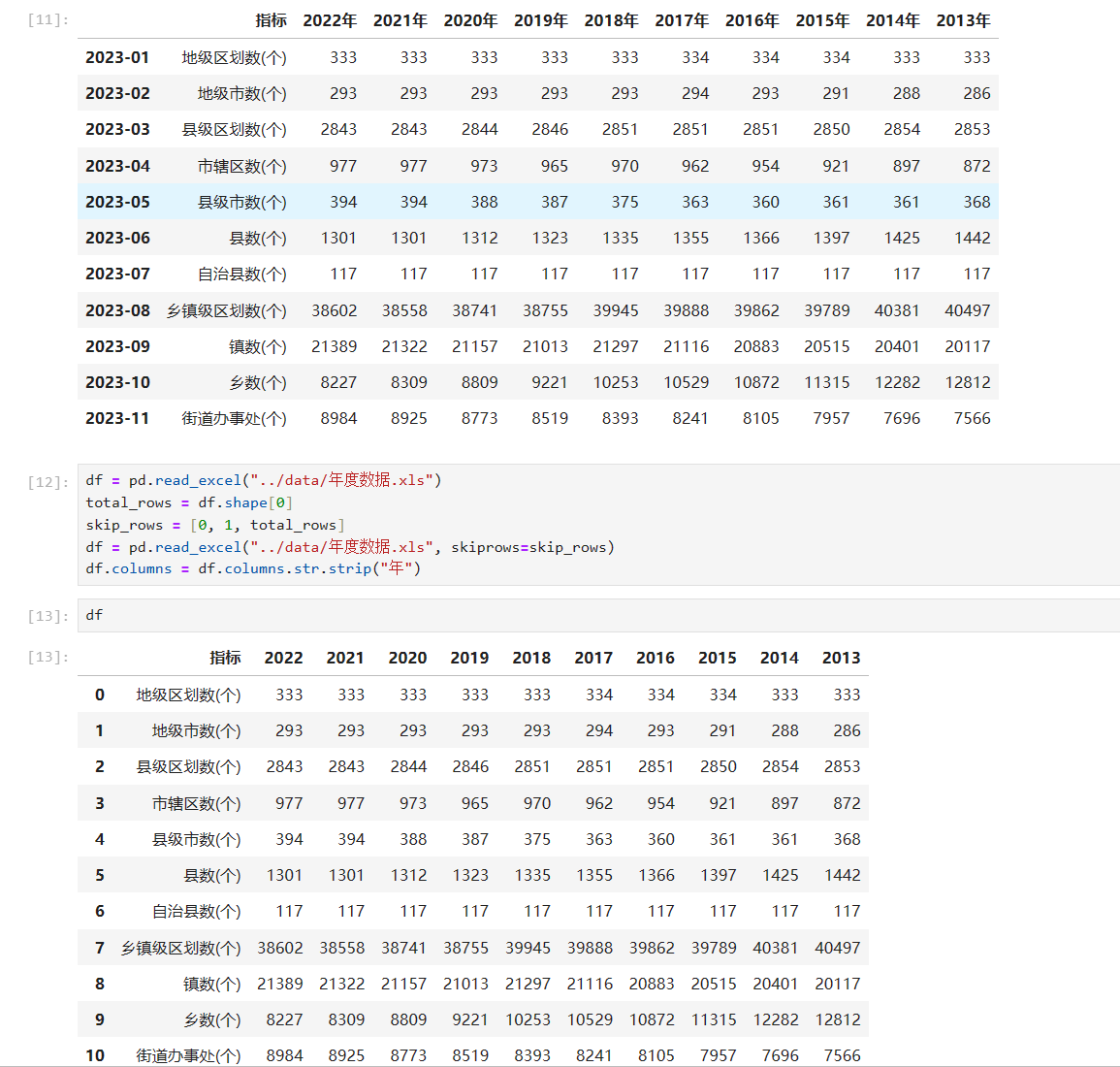
主要代码
df.columns = df.columns.str.strip("年")如果想将20去掉该怎么办呢,如果只是单纯的把年换成20,你得到的结果会很奇怪
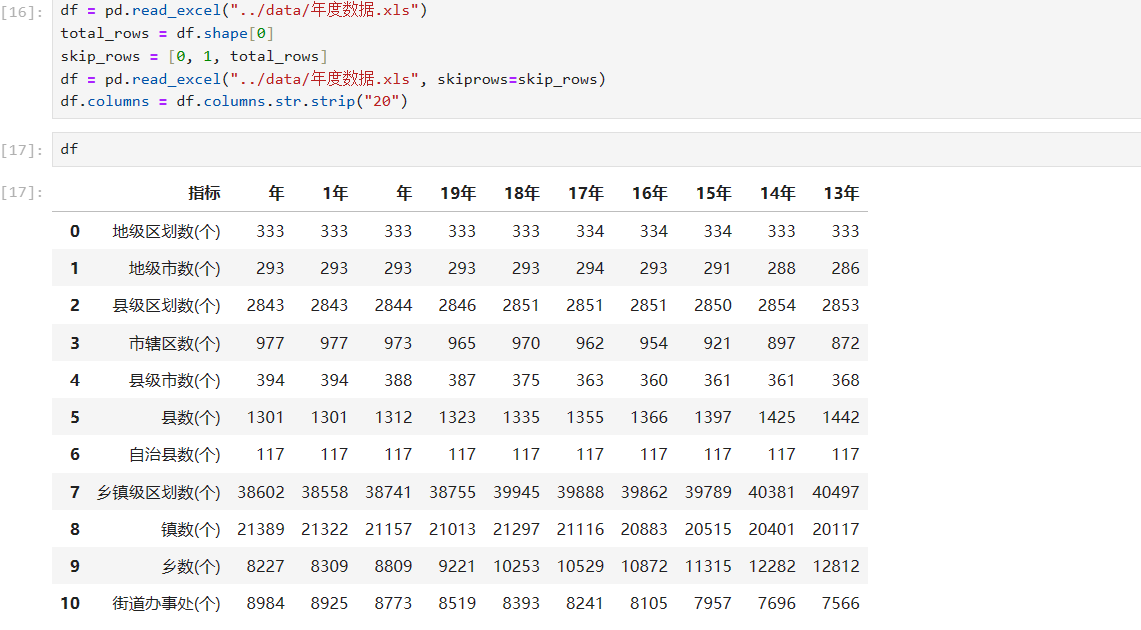
正确的做法是,通过rename和lambda结合进行修改,代码如下
df = pd.read_excel("../data/年度数据.xls")
total_rows = df.shape[0]
skip_rows = [0, 1, total_rows]
df = pd.read_excel("../data/年度数据.xls", skiprows=skip_rows, index_col=0)
df.rename(columns=lambda x: x[2:])效果如下
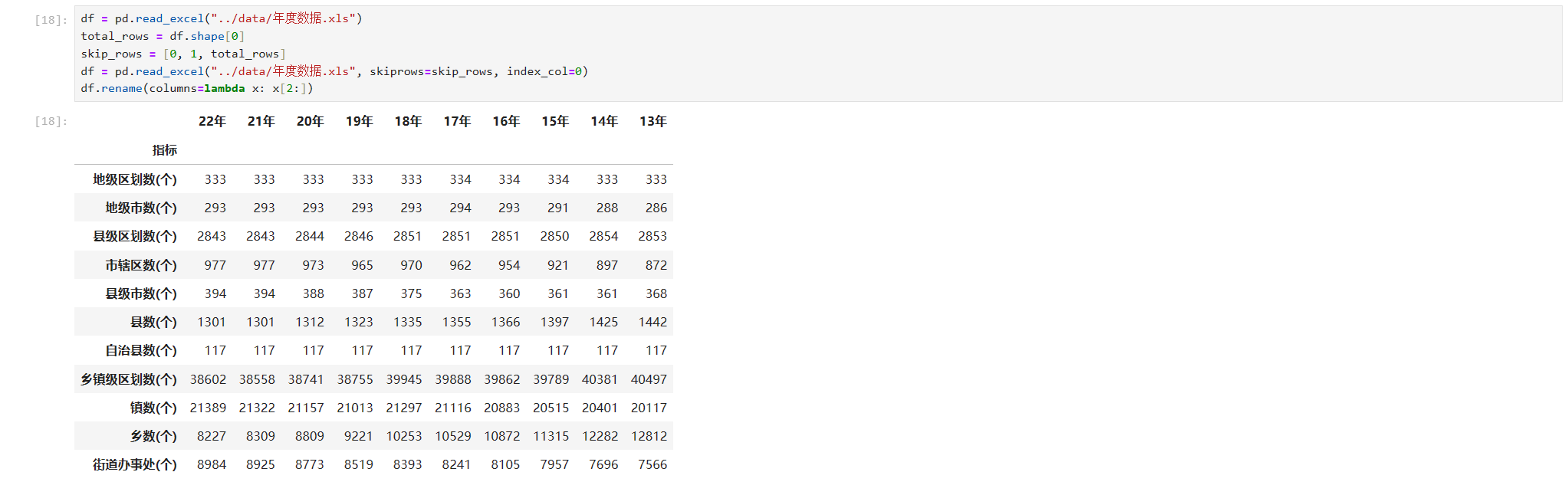
关键代码如下
df.rename(columns=lambda x: x[2:])这段lambda表达式的作用是获取每个列名然后去掉前两个字符即“20”。还有一个需要注意的是,我们在加载数据时,指定了索引列,如果不指定你会看到下面这个效果
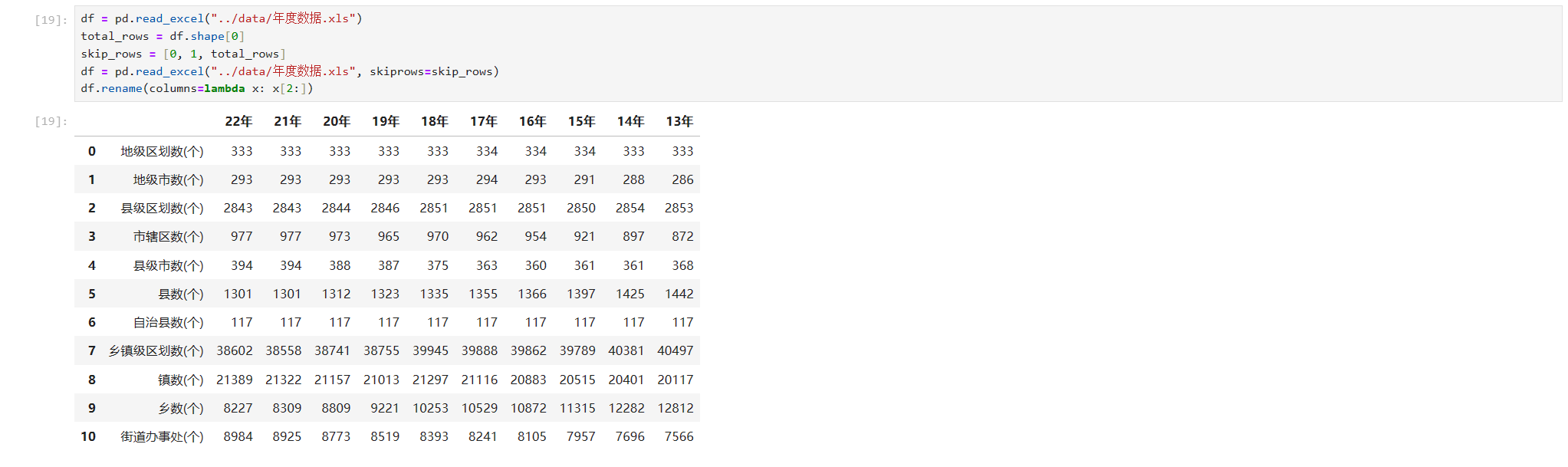
你会发现,指标这两个字也不见了,因为默认情况下它也算是一个列名。
结尾
好了,常用的一些方法今天就和大家分享到这里,除了这些还有很多实用的方法,例如工作日,前缀后缀什么的,大家可以自行查看一下文档练习一下,有问题留言给我。
我是Tango,一个热爱分享技术的程序猿我们下期见。
我正在参与2023腾讯技术创作特训营第四期有奖征文,快来和我瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
