Sqoop笔记


Sqoop介绍
百度:
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
我认为:
Sqoop就是将Hadoop、Hive、Habse中的数据导入到关系型数据库(MySQL)中或者MySQL到Hadoop、Hive、Habse中,避免手写MapReduce
Sqoop安装
注意
1) Sqoop的包:sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 支持 hadoop-2.x.x版本,不是只支持2.0.4
2)hadoop和hive安装成功
3)内容没有涉及HBase
4)RDBMS指的是关系型数据库,可以理解为MySQL
安装步骤
将安装包解压到制定目录下

进入解压目录下的conf目录下,将sqoop-env-template.sh复制一份重命名为sqoop-env.sh

修改sqoop-env.sh
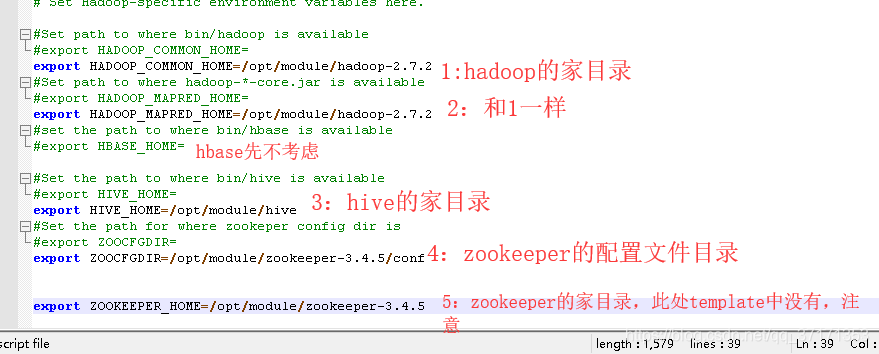
#Set path to where bin/hadoop is available
#export HADOOP_COMMON_HOME=
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2
#Set path to where hadoop-*-core.jar is available
#export HADOOP_MAPRED_HOME=
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
#export HIVE_HOME=
export HIVE_HOME=/opt/module/hive
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
export ZOOCFGDIR=/opt/module/zookeeper-3.4.5/conf
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.5拷贝JDBC驱动:因为需要操作MySQL
拷贝或者上传 jdbc 驱动(mysql-connector-java-5.1.27-bin.jar)到 sqoop 的 lib 目录下
JDBC驱动寻找地址:如果你安装配置过hive,那你就应该有将 jdbc驱动拷贝到hive/lib目录下,如果没配置过,说明你hive的配置不完整
验证 Sqoop
bin/sqoop help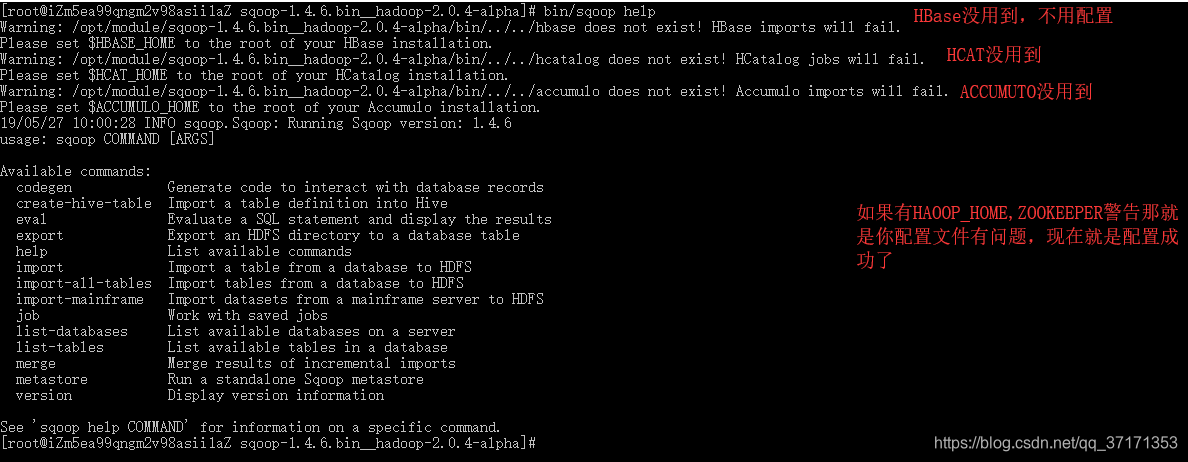
Sqoop使用
导入数据
在 Sqoop 中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE, HBASE)中传输数据,叫做:导入,即使用 import 关键字。
全部导入:RDBMS(MySQL) 到 HDFS
1)开启MySQL服务并且能正常连接
2)Hadoop开启并且HDFS能正常访问
3)创建表并且插入数据
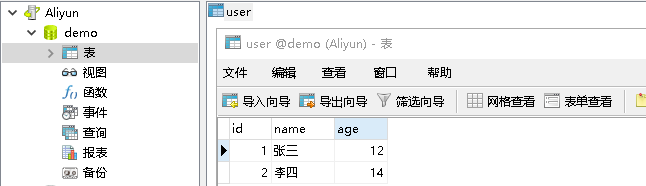
4)导入
其中 --connect jdbc: mysql的地址 --username mysql用户名 --password mysql密码 --table 操作的表 --target-dir 要存在HDFS中的哪个目录下 --delete-target-dir \ 如果 target-dir存在,就删除 --num-mappers 1 \ 设置mapper的个数为1 --fields-terminated-by "\t" 导入HFDS中,字段之间用 \t 分开
bin/sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/demo \
--username root \
--password root \
--table user \
--target-dir /demo/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"5)查看导入结果

查询导入:RDBMS(MySQL) 到 HDFS
--quality 查询语句
注意:1) where 后面一定要加 and $CONDITIONS;
2)--quality 不能和 --table 一起使用
bin/sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/demo \
--username root \
--password root \
--target-dir /demo/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select id,name from user where id <=1 and $CONDITIONS;'导入指定列:RDBMS(MySQL) 到 HDFS
注意:columns 中如果涉及到多列,用逗号分隔,分隔时不要添加空格
bin/sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/demo \
--username root \
--password root \
--target-dir /demo/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,age \
--table userRDBMS(MySQL) 到 Hive
其中 --hive-table 为你要导入到Hive的哪张表中
bin/sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/demo \
--username root \
--password root \
--table user \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table user_hive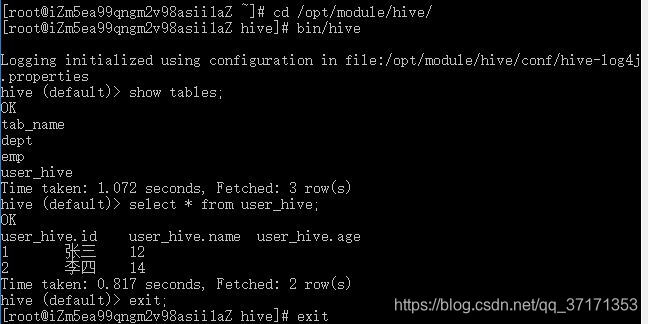
导出数据(没import用的不多)
在 Sqoop 中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群 (RDBMS)中传输数据,叫做:导出,即使用 export 关键字。
HIVE/HDFS 到 RDBMS(MySQL)
Hive的数据本身就在HDFS的某一路径下,所以将Hive中的数据迁移到MySQL本质上也是HDFS中的某文件迁移到MySQL
--table 指的是数据库中的表名称
--export -dir 指的是hive中 的数据表在HDFS上的路径
注意:如果将Hive中数据导出到MySQL上,注意主键冲突的问题,否则会卡住
bin/sqoop export \
--connect jdbc:mysql://127.0.0.1:3306/demo \
--username root \
--password root \
--table user \
--num-mappers 1 \
--export-dir /user/hive/warehouse/user_hive \
--input-fields-terminated-by "\t"脚本打包
使用 opt 格式的文件打包 sqoop 命令,然后执行
我认为:Sqoop脚本打包就是将上面学的命令放在xxx.opt文件里,然后执行文件
创建SQoop的opt脚本
注意:
1)一行一个命令或者是参数
2)不能加反斜杠
export
--connect
jdbc:mysql://127.0.0.1:3306/demo
--username
root
--password
root
--table
user
--num-mappers
1
--export-dir
/user/hive/warehouse/user_hive
--input-fields-terminated-by
"\t"运行opt文件
其实 myopt/hive2mysql.opt为自己编写的opt的路径
bin/sqoop --options-file myopt/hive2mysql.opt利用Sqoop实现Hbase的数据与MySQL数据的互导
mysql to hbase
./bin/sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/fdcp-dev \
--username root \
--password 123456 \
--table adviceMessage \
--hbase-table pzz_adviceMessage \
--column-family cf \
--hbase-row-key id \
--hbase-create-tablehbase to mysql
无
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号