「最佳实践」腾讯云 Elasticsearch 8:预训练模型与一站式向量化语义检索的完美结合
原创
「最佳实践」腾讯云 Elasticsearch 8:预训练模型与一站式向量化语义检索的完美结合
原创
岳涛
修改于 2024-02-26 10:40:11
修改于 2024-02-26 10:40:11
说明
本文描述问题及解决方法同样适用于 腾讯云 Elasticsearch Service(ES)。
另外使用到:腾讯云 云服务器(Cloud Virtual Machine,CVM)
环境配置
客户端环境
- 版本
CVM 镜像:CentOS 7.9 64位 | img-l8og963d | 20GiB
Linux环境:Centos 7.9
Python:3.9.12
- 配置
SA4.2XLARGE16(8核16G)
Elasticsearch 服务端环境
- 版本
Elasticsearch版本:8.8.1(腾讯云 Elasticsearch Service 白金版)
- 配置
规格:ES.SA2.2XLARGE16(8核16G)
节点数量:6
硬盘:200G * 3
背景
腾讯云 Elasticsearch 8.8.1 版本已经上线了一段时间的 ,这个版本带来了一项重要的功能——Elasticsearch Relevance Engine™(ESRE™)。ESRE 将 AI 的最佳实践与 Elastic 的文本搜索相结合,为开发者提供了一整套成熟的检索算法,同时还能与大型语言模型(LLM)集成。更为重要的是,ESRE 可通过简单、统一的 API 接口访问,这一接口已受到 Elastic 社区的广泛信任。
本文将采用腾讯云 ES 8.8.1,详细介绍在腾讯云ES上一站式体验向量检索的能力,达到语义搜索的功能需求。
创建 ES 集群
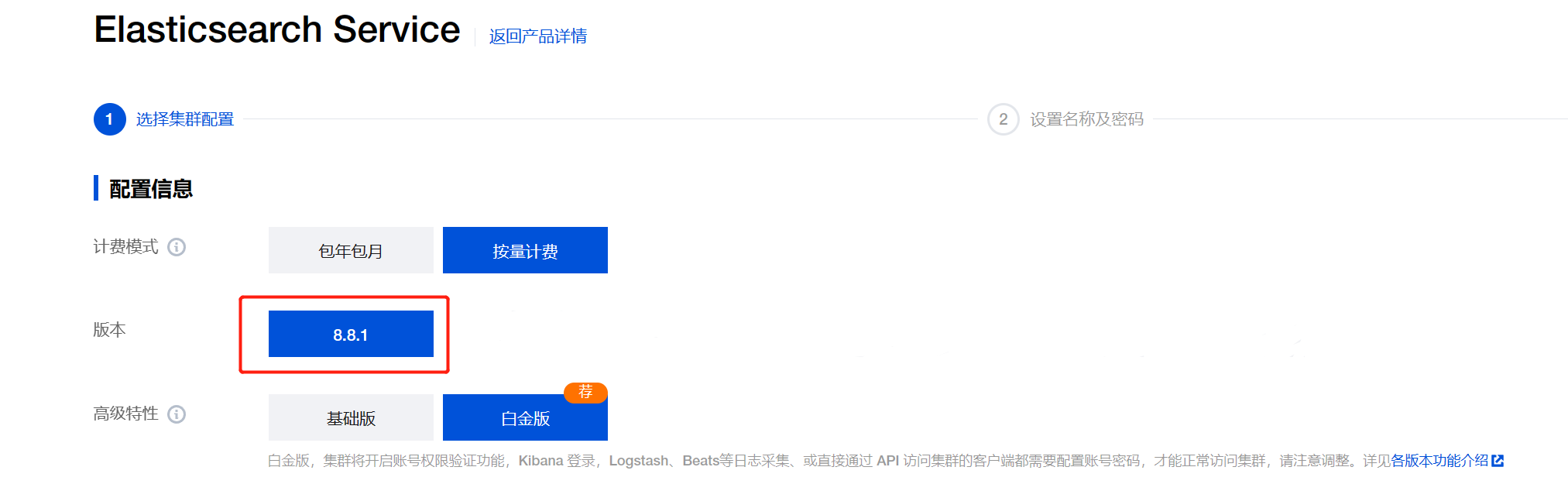
版本这里我们选择 8.8.1 白金版:
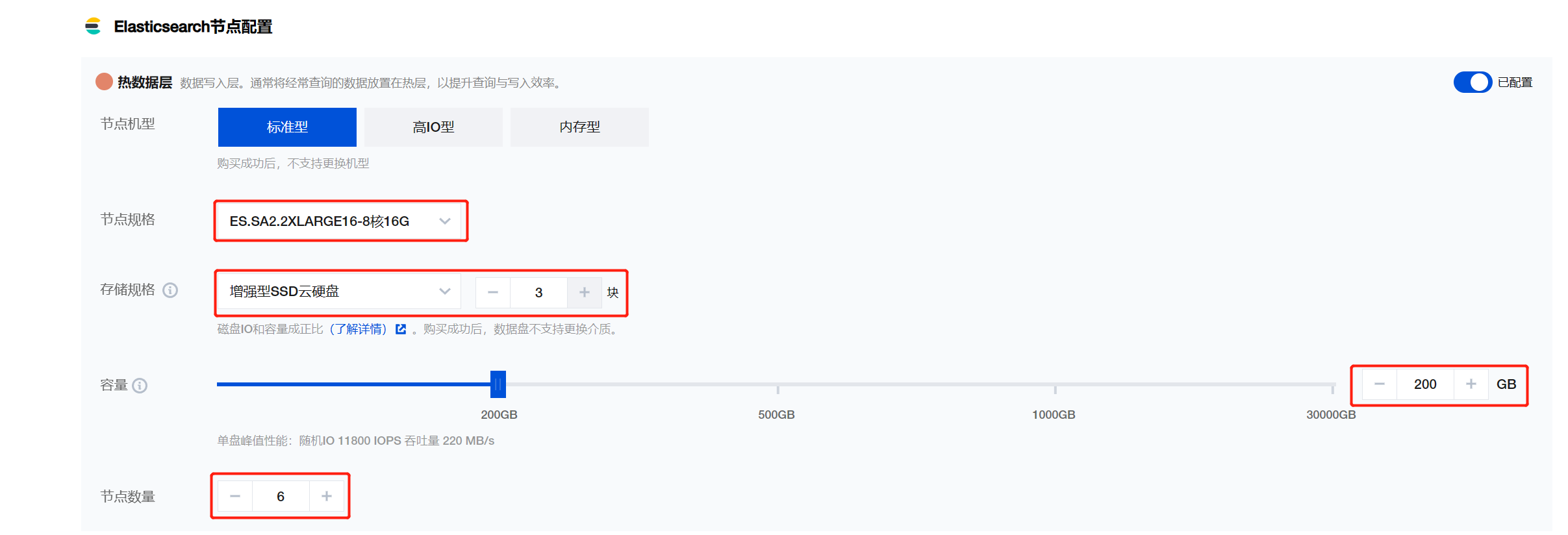
配置建议至少选择(8核16G 200G*3)6个节点,也可以根据实际需求进行调整:
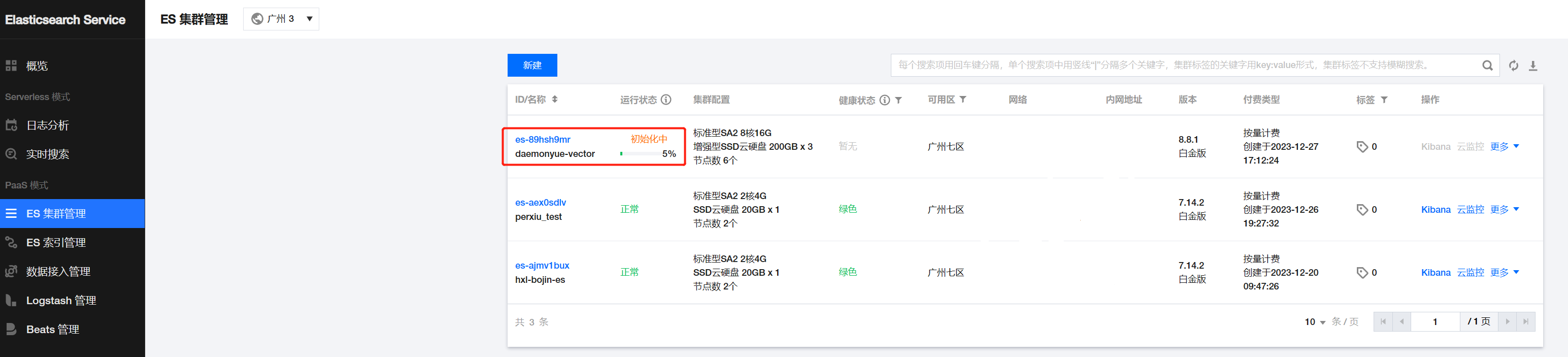
提交集群构建之后,大概需要20分钟左右可以完成:
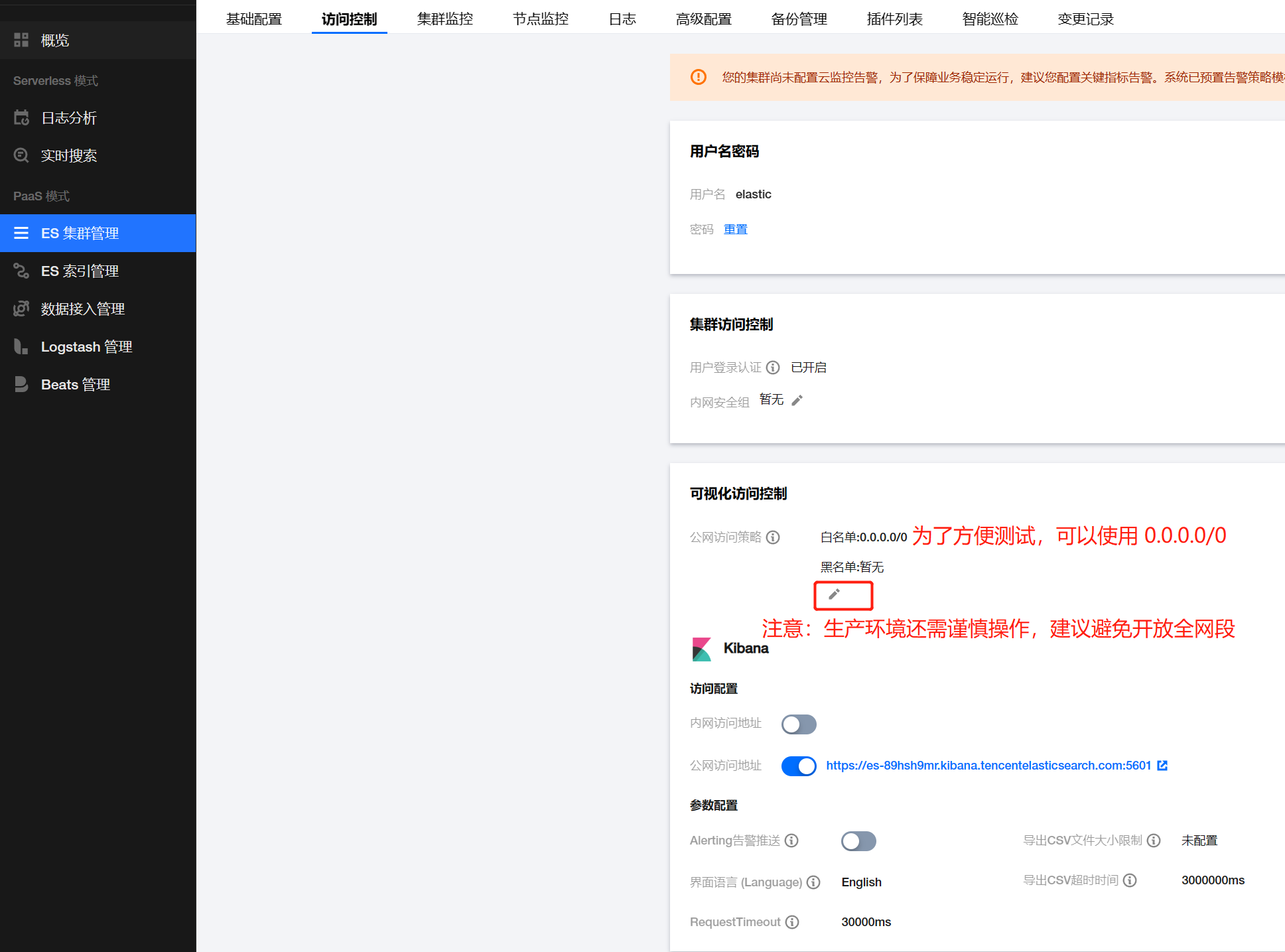
集群创建完成之后,为了方便测试,需要移步ES实例 > 访问快照 > 可视化访问控制 > 公网访问策略,将白名单修改为0.0.0.0/0
注意:此操作是为了方便测试,生产环境还需谨慎操作。
到这里,ES 产品控制台的准备工作就完成了。
客户端准备工作
环境准备
客户端服务器创建
购买Centos云服务器作为客户端:
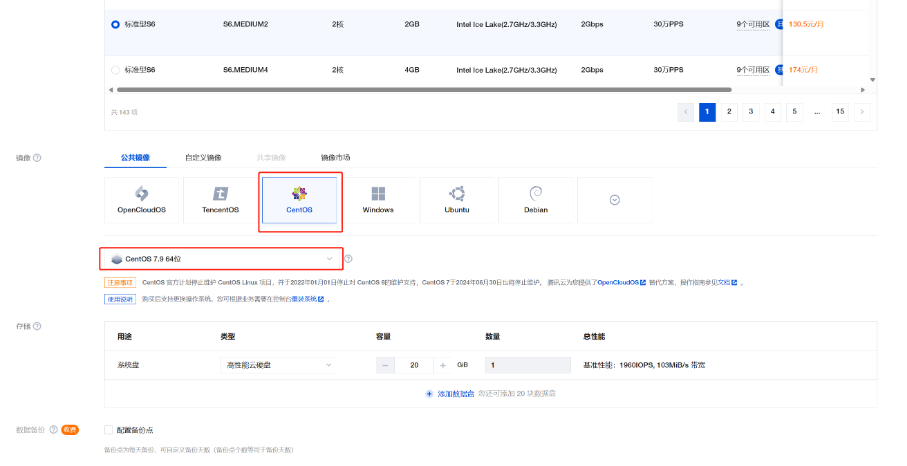
注意:客户端服务器的网络需要与 ES 互通,最好在同一个 VPC 下,子网可以不一样。
Python环境
1. 安装python环境管理工具——conda
yum install conda -y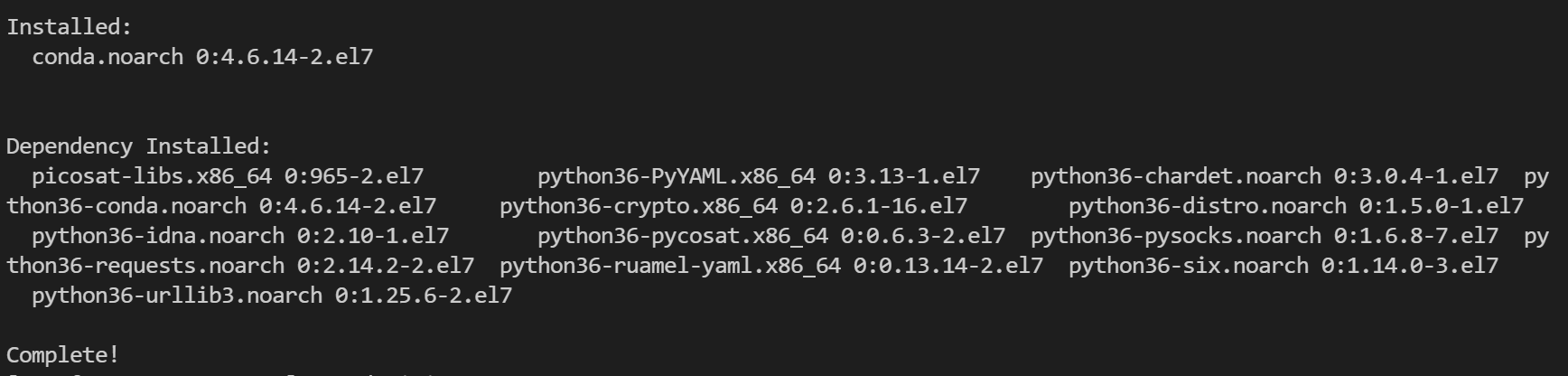
2. 初始化conda环境变量
conda init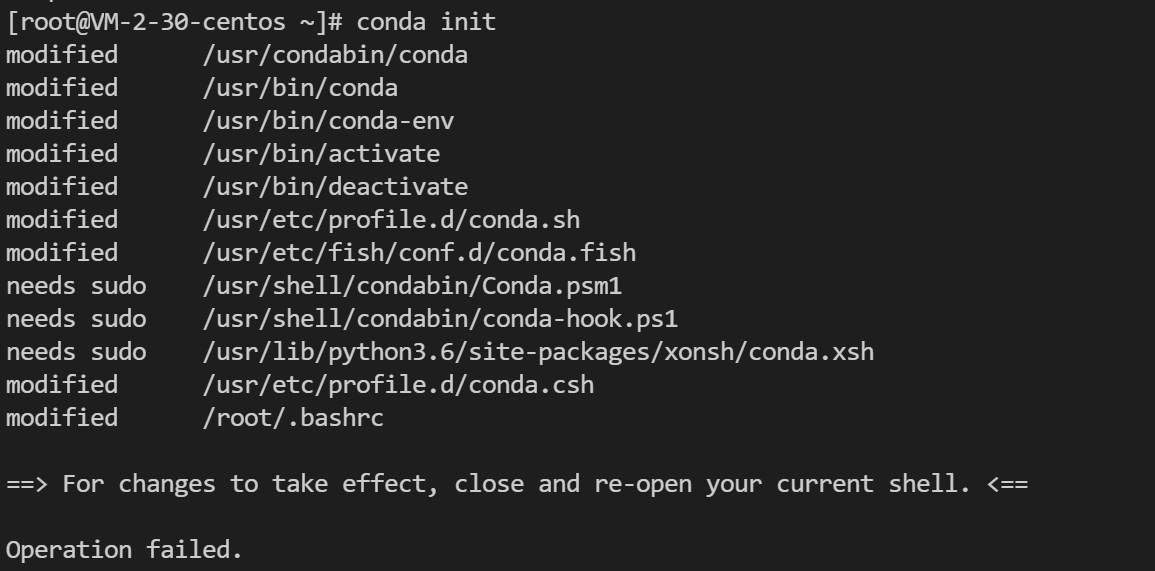
说明:结尾报错Operation failed.无需理会
3. 加载环境变量
source ~/.bashrc
4. 创建 python 虚拟环境es_vector
conda create -n es_vector python=3.9.12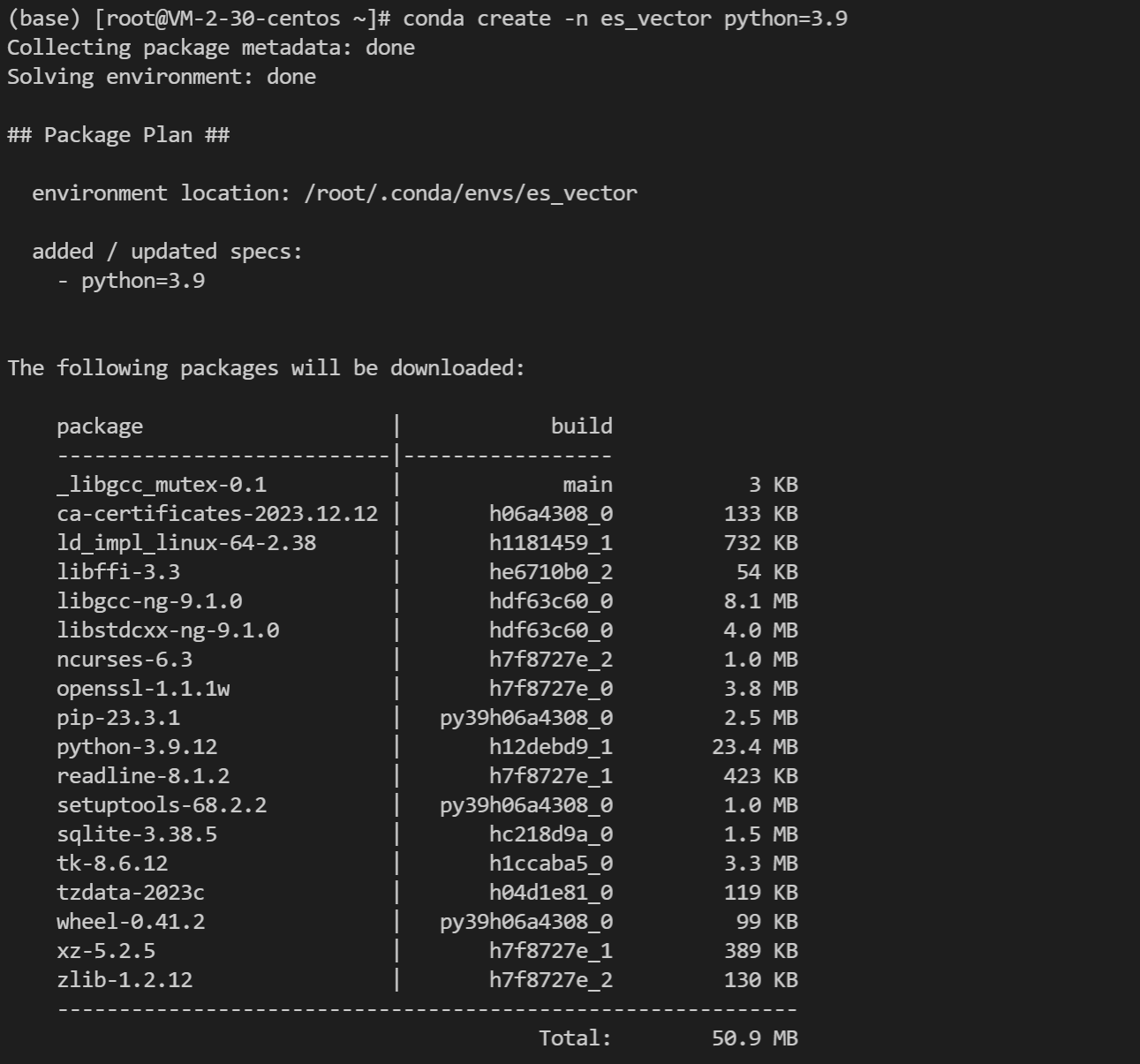
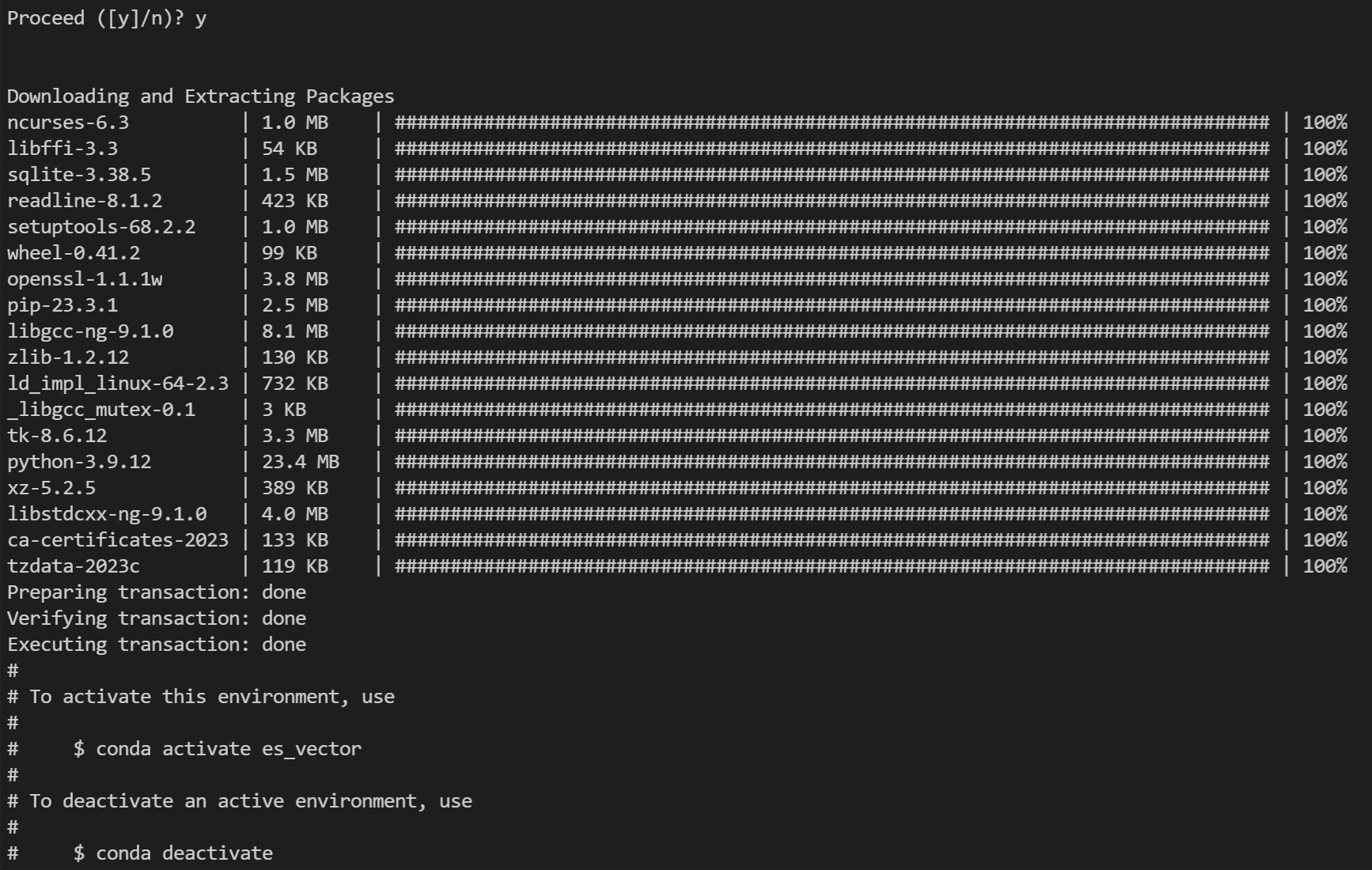
5. 激活 python 虚拟环境
conda activate es_vector
6. 安装依赖包:es、eland[pytorch]
写入es需要用到es包:
pip install elasticsearch==8.8.1上传模型需要用到eland包:
pip install eland[pytorch]==8.11.1安装 eland 需要下载很多依赖,安装时间会比较久,需要耐心等待,博主安装耗时大概 6 min。
文本准备
《斗破苍穹》文本,下载文本,上传至客户端家目录,下面的数据导入步骤会用到。
另外需要注意,本文基于测试的文本没有经过预处理,所以文本质量不高,简单用于测试是完全ok的,只是检索效果可能不是特别理想。当然,也可以使用自己的文本,文中用到的文本文件格式是每一行一段文本,没有其他字段。
上传模型
模型准备
模型下载
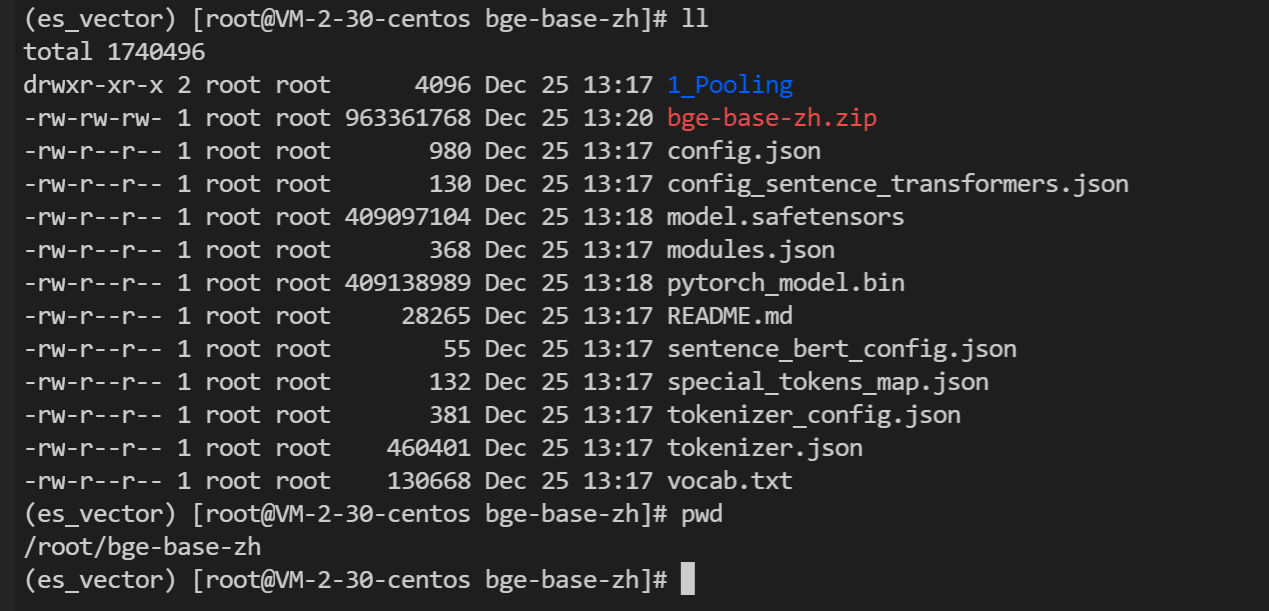
bge-base-zh,下载模型,上传至客户端家目录
解压目录
mkdir bge-base-zh
mv bge-base-zh.zip bge-base-zh
cd bge-base-zh/
unzip bge-base-zh.zip注意:不可直接原地解压,需要创建目录再将模型移动到目录后,进行解压,否则会展开到当前目录,无法使用
导入模型
博主是将所有文件都放在了家目录,可以看下家目录文件情况:

也可以在执行模型导入时,我们需要位于模型目录的外面,在导入模型时,--hub-model-id 指定的必须是相对目录,而不是绝对路径:
eland_import_hub_model --url http://10.0.0.1:9200 --hub-model-id bge-base-zh --es-username elastic --es-password changeme --task-type text_embedding说明:--url 以及 --es-password 需安装实际情况修改。

模型导入成功,最后会打印:Model successfully imported with id 'bge-base-zh'
模型导入成功之后,还需要进行模型同步:
点击synchronize your jobs and trained models
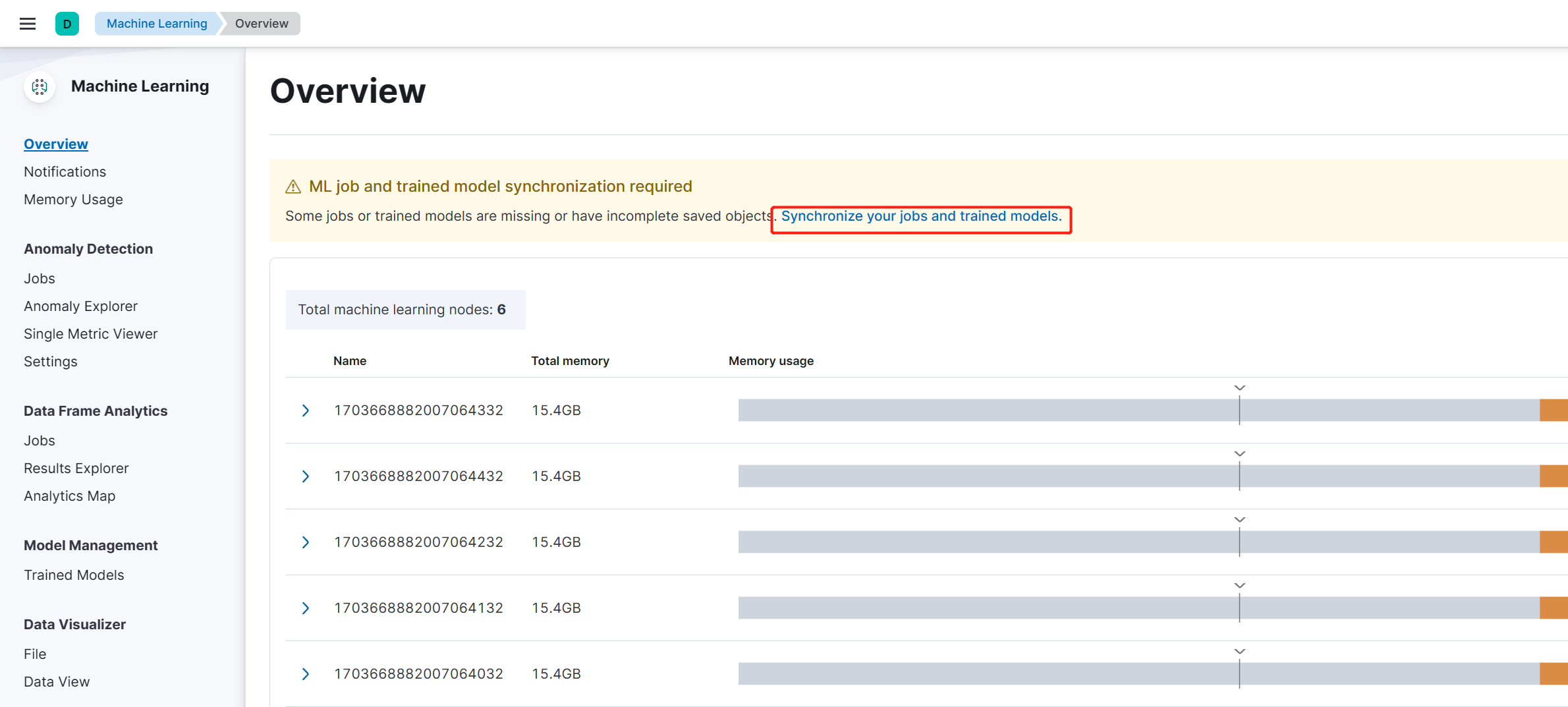
部署预训练模型
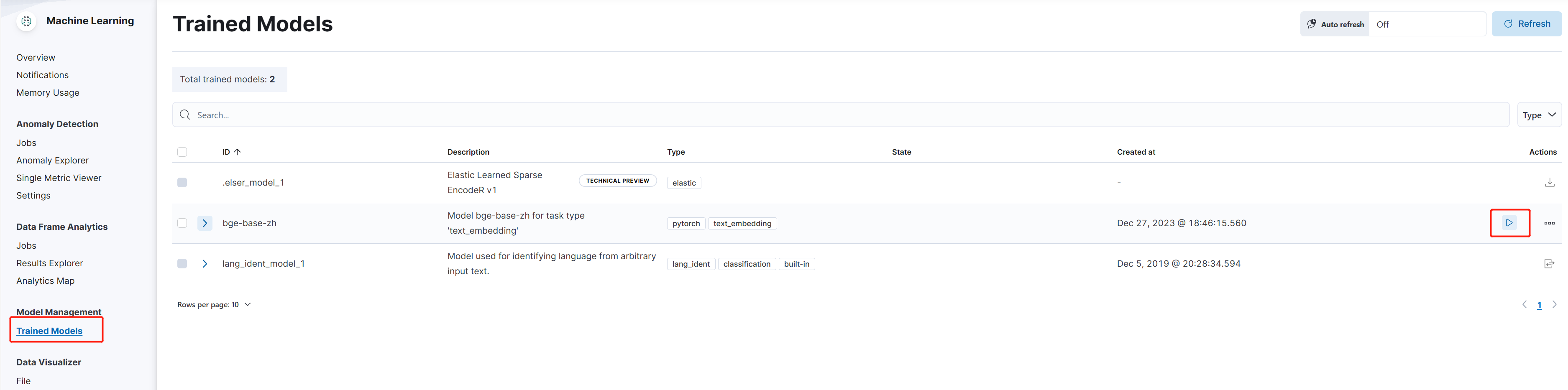
修改部署参数:
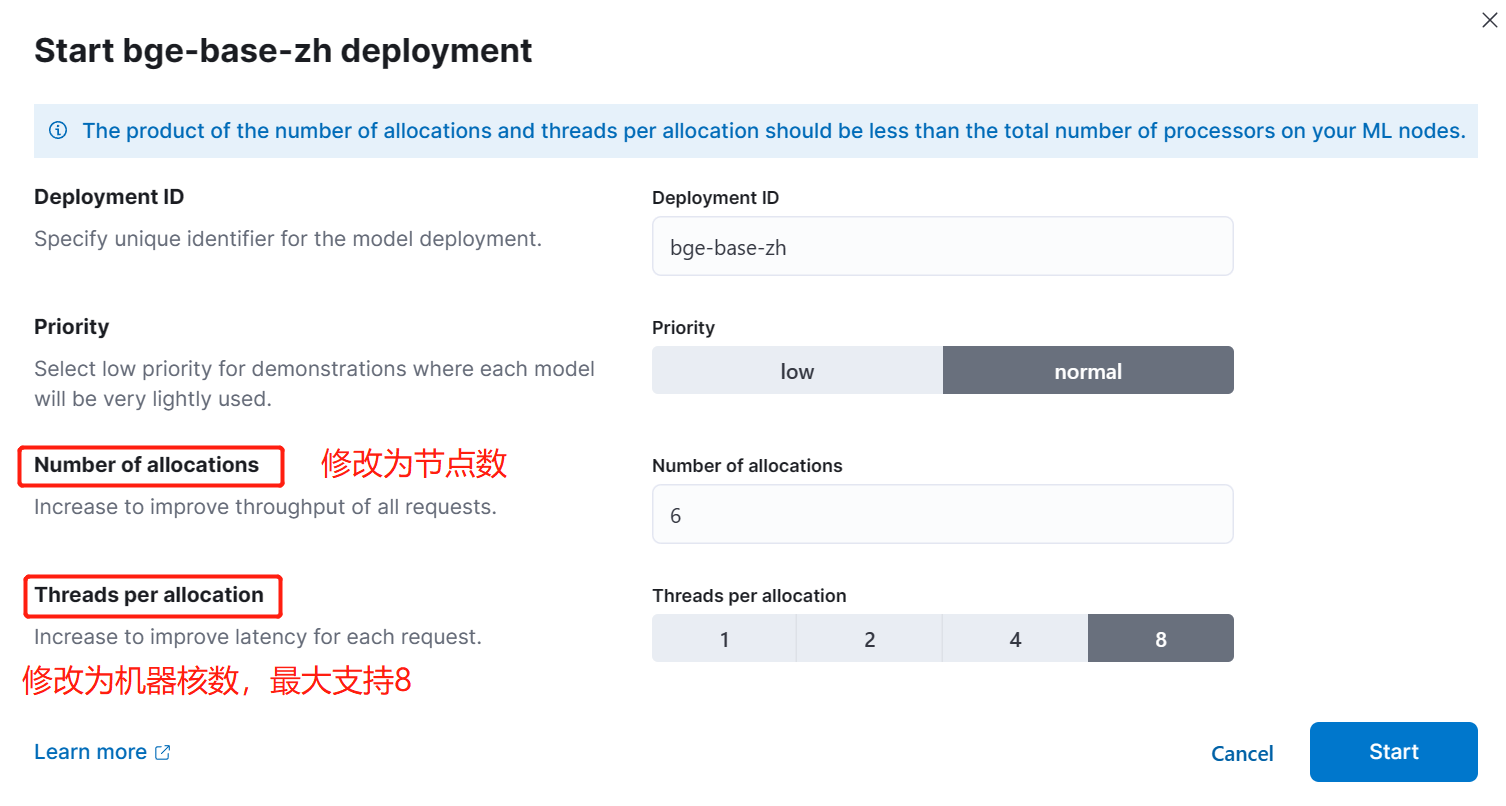
部署成功后可以在模型的 Stats 标签里看到资源分配情况:

模型到这里就部署完成了,下面我们开始准备数据。
Elasticsearch 准备工作
定义ES管道
PUT _ingest/pipeline/bge-base-zh
{
"processors": [
{
"inference": {
"model_id": "bge-base-zh",
"target_field": "vector",
"field_map": {
"sentence": "text_field"
}
}
}
]
}
管道创建成功之后,可以在模型的 Pipeline 标签看到关联情况:
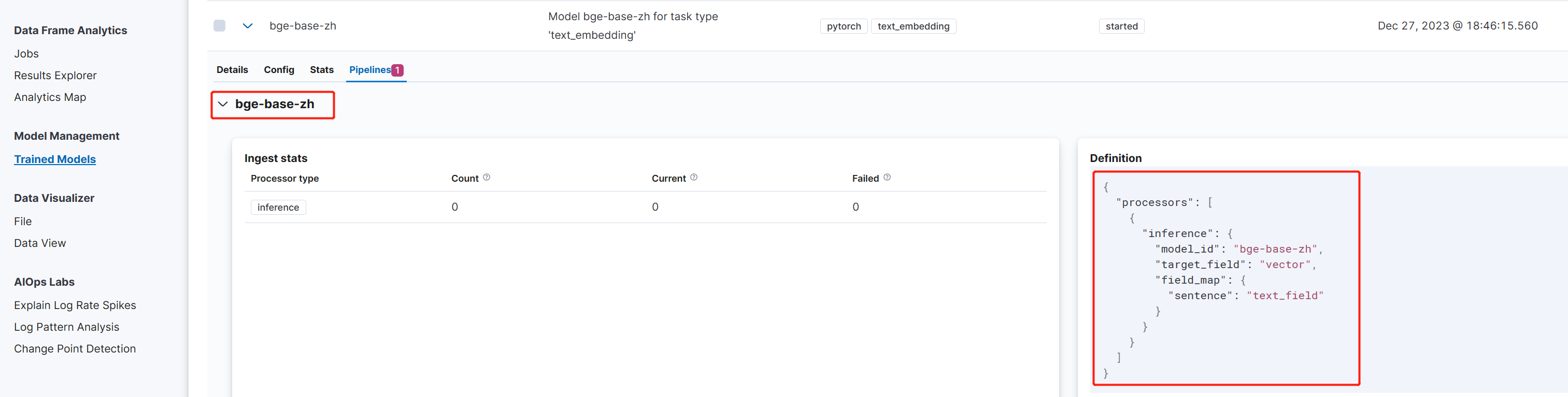
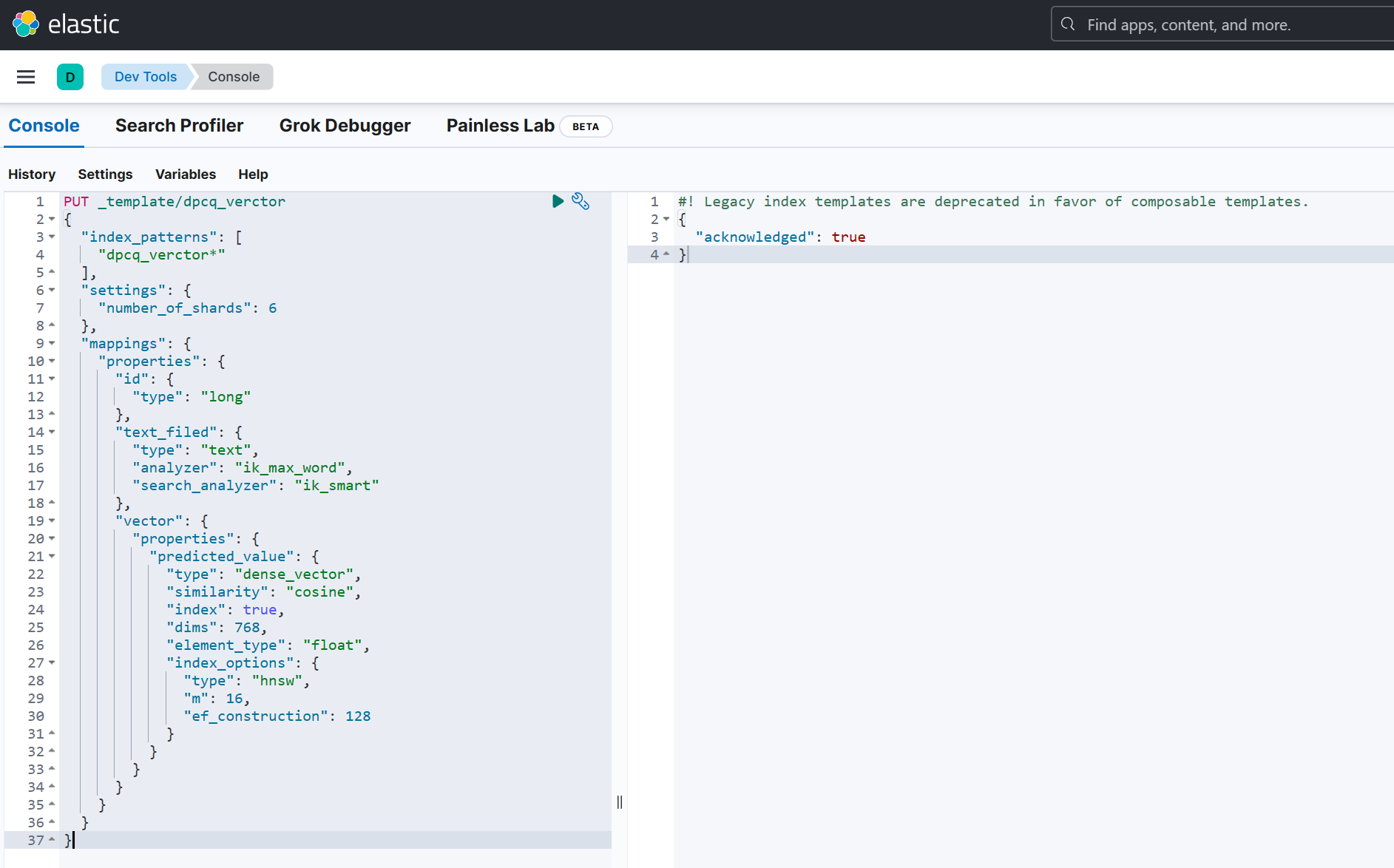
定义ES模板
说明:建议把 json 里的注释去掉执行
PUT _template/dpcq_verctor
{
"index_patterns": [
"dpcq_verctor*"
],
"settings": {
"number_of_shards": 6
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"text_field": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"vector": {
"properties": {
"predicted_value": {
"type": "dense_vector",
"similarity": "cosine", // 支持 cosine, dot_product, l2_norm
"index": true,
"dims": 768, // 最高支持2048维度
"element_type": "float", // 支持 float, byte
"index_options": {
"type": "hnsw", // hnsw 高级参数配置
"m": 16,
"ef_construction": 128
}
}
}
}
}
}
}
导入文本
激活 python 虚拟环境:
conda activate es_vector将python脚本保存成 insert_sentence.py,放在客户端家目录:

from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
es_username = 'elastic'
es_password = 'changeme' # 修改ES密码
es_host = '10.0.0.1' # 修改ES HOST
es_port = 9200
index_name = 'dpcq_sentence' # 如果是想 bulk 时就产生向量字段,则把 index_name 换成下面的
# index_name = 'dpcq_verctor'
file_path = 'dpcq_sentence.txt'
es = Elasticsearch(
hosts=[{'host': es_host, 'port': es_port, 'scheme': 'http'}],
basic_auth=(es_username, es_password),
)
def read_data(file_path):
with open(file_path, 'r') as file:
counter = 1
for line in file:
yield {
'_index': index_name,
'_id': counter, # 添加自增 ID 字段
'_source': {
'id': counter,
'text_field': line.strip(),
}
}
counter += 1
# 执行批量插入
def bulk_insert(file_path, chunk_size=5000):
data = read_data(file_path)
bulk(es, data, chunk_size=chunk_size) # 如果是想 bulk 时就产生向量字段,则把 bulk 换成下面的
# bulk(es, data, chunk_size=chunk_size, pipeline='bge-base-zh')
bulk_insert(file_path)执行文本数据导入:
python insert_sentence.py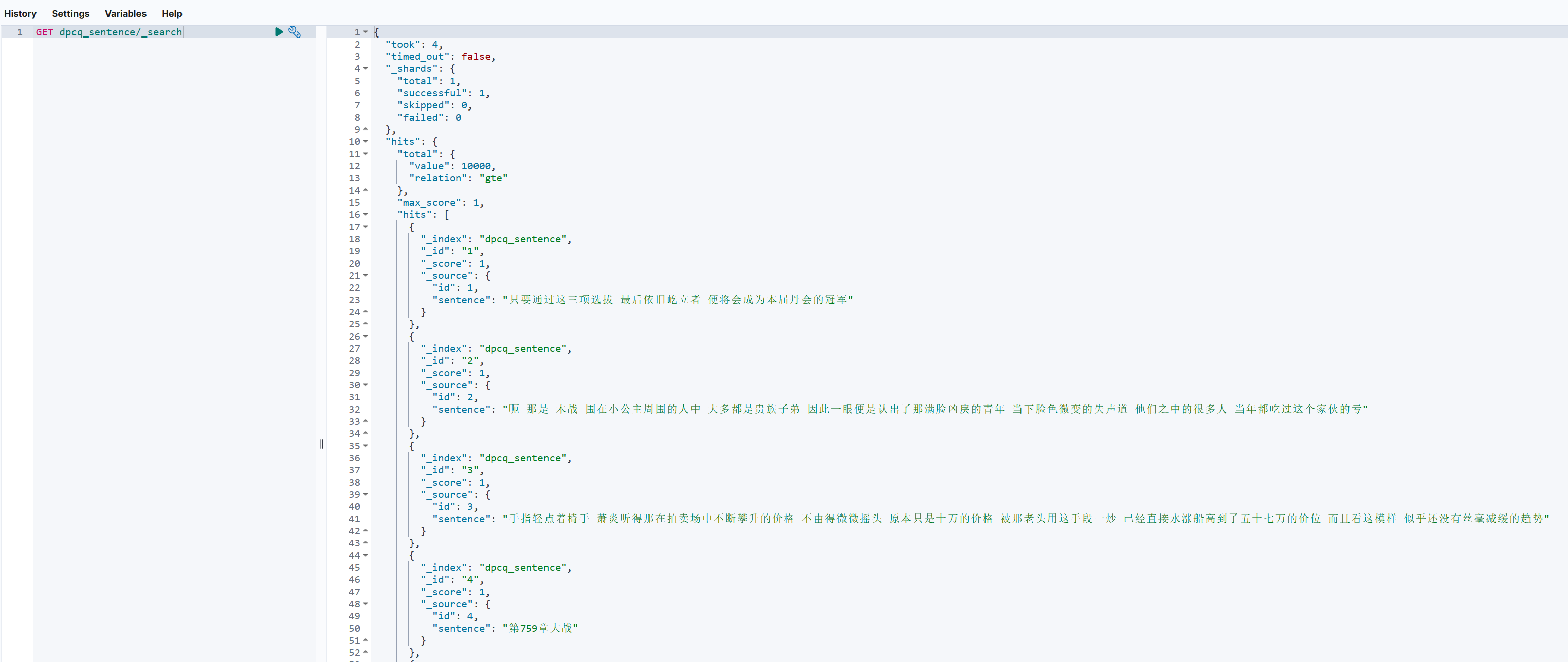
导入完成后可以在kibana中检索到数据。
生成向量字段
使用 reindex 进行数据索引,并使用 pipeline 处理文本生成向量:
POST _reindex?slices=auto&wait_for_completion=false
{
"source": {
"index": "dpcq_sentence"
},
"dest": {
"index": "dpcq_verctor_bbz768",
"pipeline": "bge-base-zh"
}
}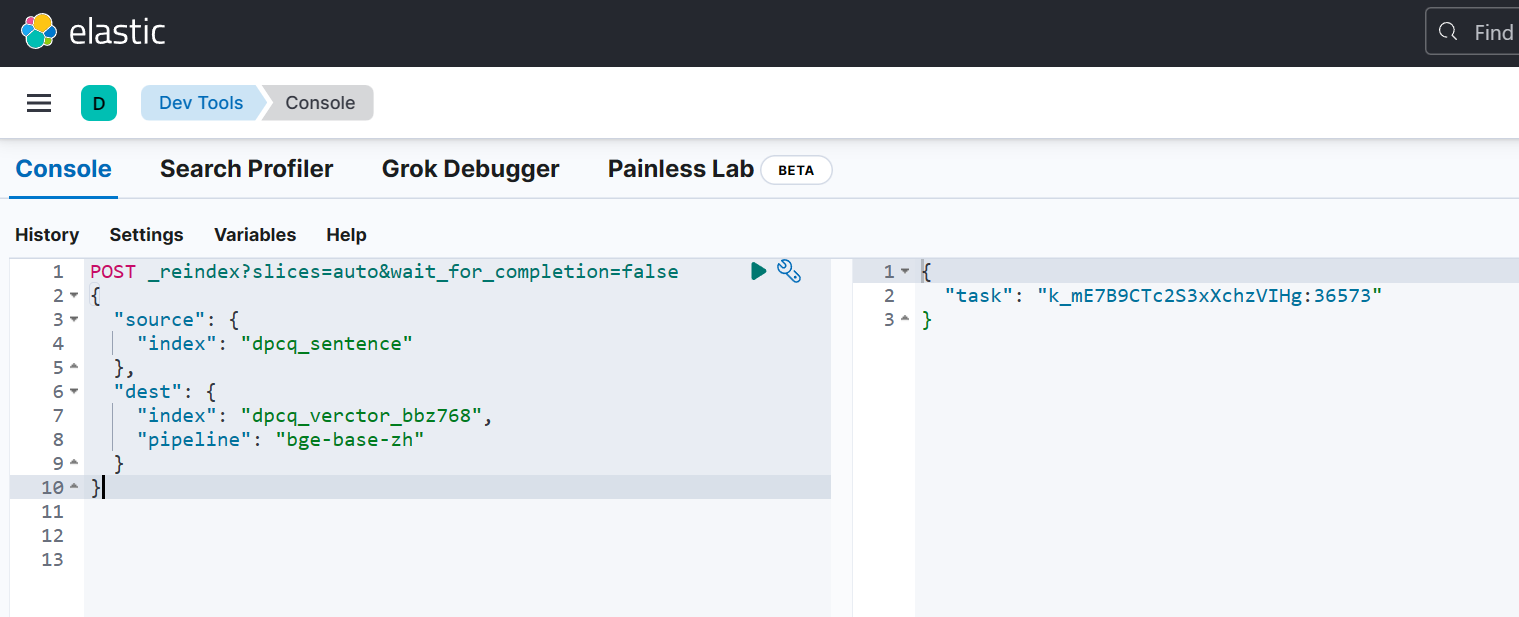
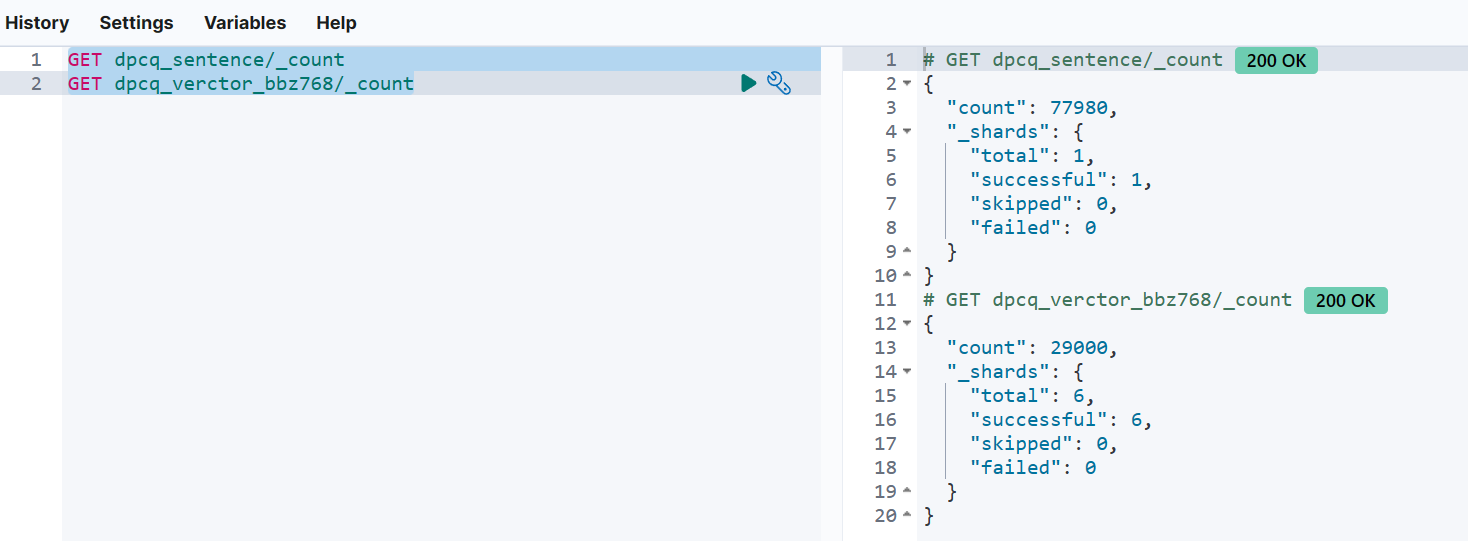
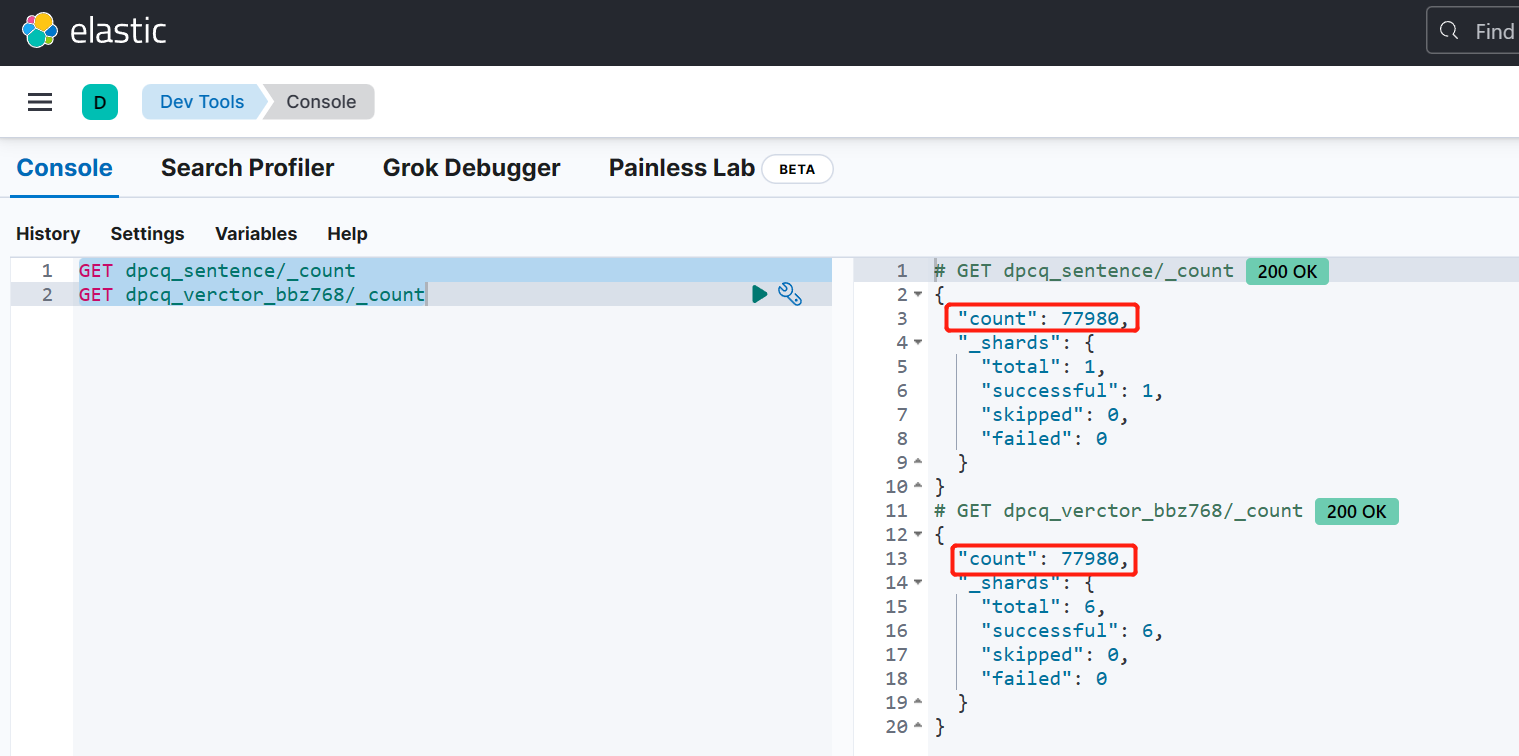
执行之后会返回一个 task id,我们可以通过 count 来观测 reindex 进度:
GET dpcq_sentence/_count
GET dpcq_verctor_bbz768/_count同时选择两条命令合并执行:
- 模型推理资源消耗较大,腾讯云ES目前使用的是CPU进行推理,可以通过横向扩展ES节点数来提升推理效率;
- 这个操作我们也可以在自建机器学习机器上进行,使用GPU进行推理运算,效率会更高,然后将数据写到腾讯云ES。感兴趣的话可以在自建机器学习机器上进行测试,本文就不予展开了。
这个过程需要耐心等待,直到 dpcq_verctor_bbz768 的条数等于 dpcq_sentence 的条数,则说明数据处理完成:
说明:
本段采用 reindex + pipeline 的方式写入向量数据,当然也可以在 bulk 写入时就指定 pipeline,直接在文本写入时就生成向量字段,只需在 bulk 写入时指定 pipeline 即可。如果只是简单测试,建议是使用 reindex + pipeline。
语义检索
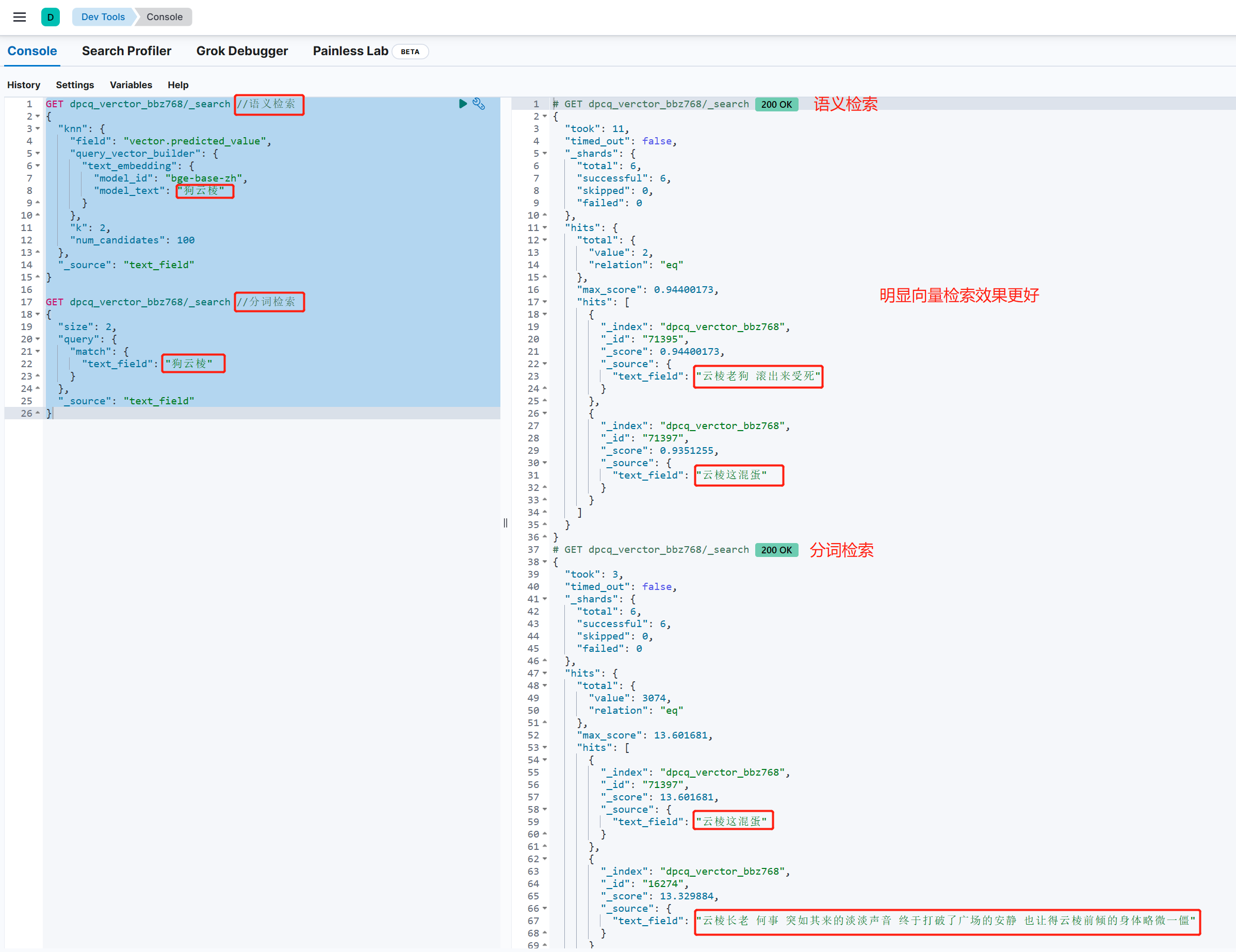
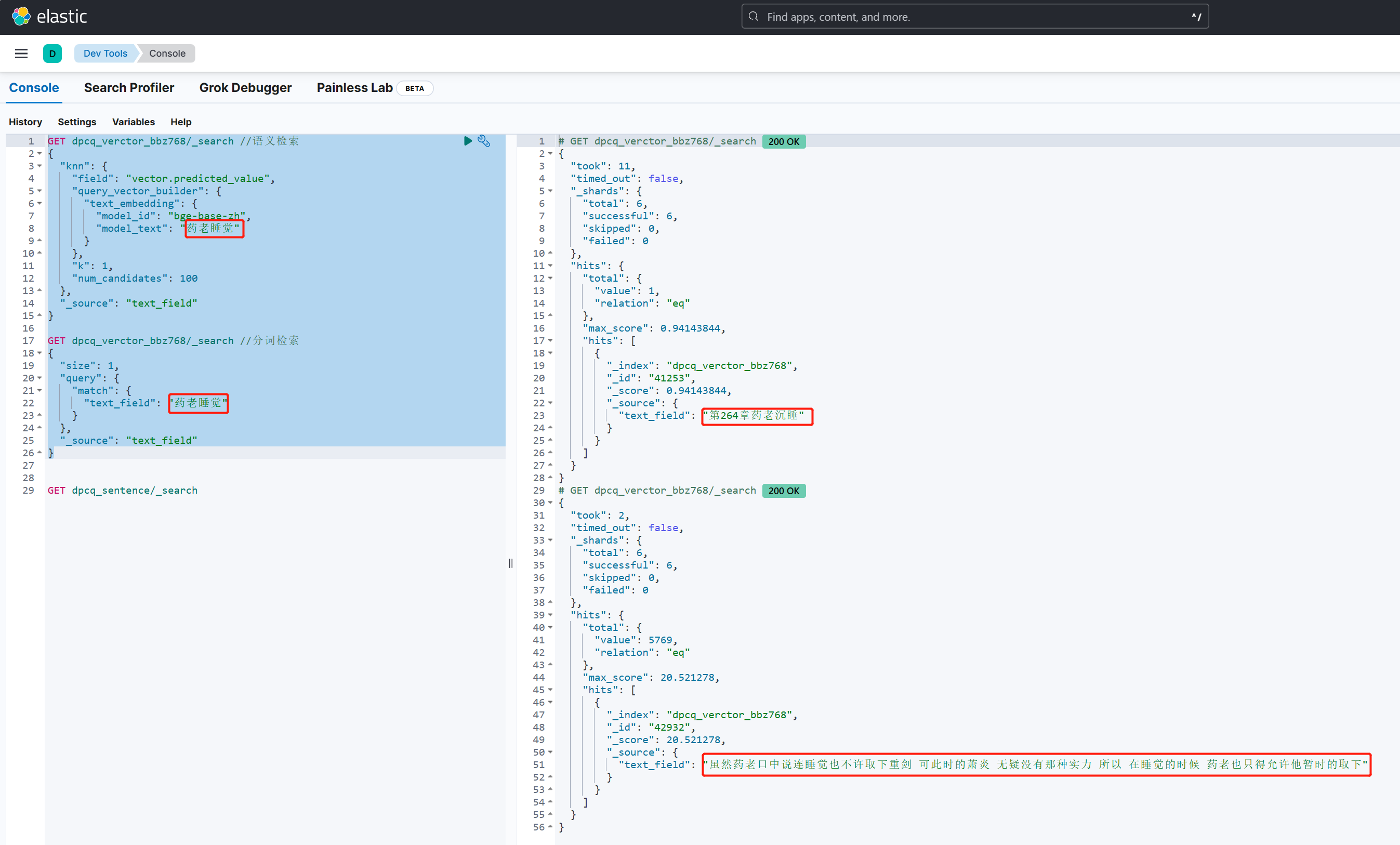
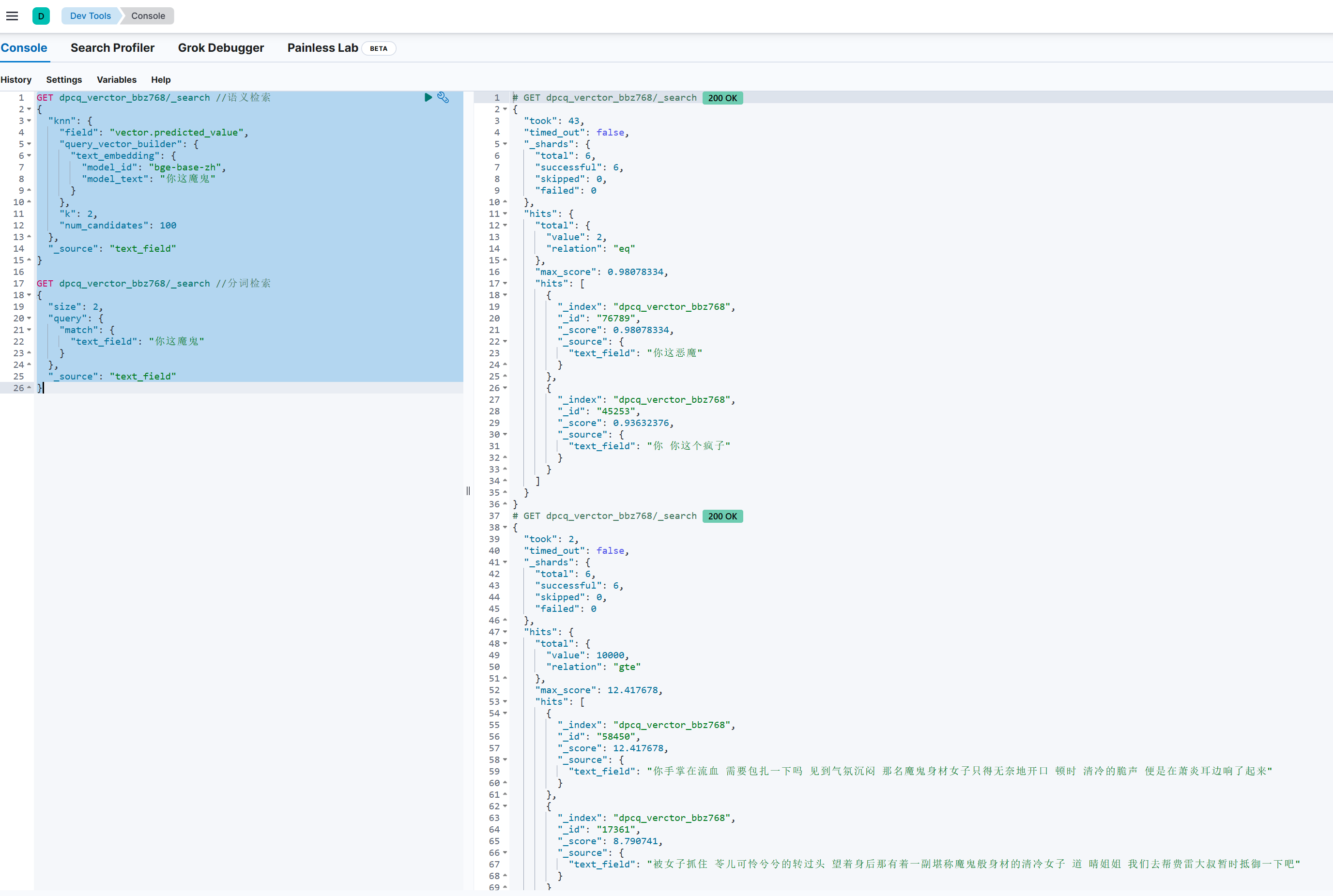
所有准备工作就绪,下面将演示向量检索,我们分别用向量检索和分词检索测试两者的检索效果:
GET dpcq_verctor_bbz768/_search //语义检索
{
"knn": {
"field": "vector.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": "bge-base-zh",
"model_text": "狗云棱"
}
},
"k": 2,
"num_candidates": 100
},
"_source": "text_field"
}
GET dpcq_verctor_bbz768/_search //分词检索
{
"size": 2,
"query": {
"match": {
"text_field": "狗云棱"
}
},
"_source": "text_field"
}
至此,基于腾讯云 Elasticsearch 8.8.1 一站式体验语义检索的教程就完成了。
总结
语义搜索之所以如此重要,是因为它能够进行更广泛的搜索范围。得益于向量搜索的支持,语义搜索能够提供更加直观的搜索体验,并根据查询的上下文和搜索意图生成相匹配的结果。
相较于关键字,语义搜索更具优势,因为它通过匹配概念而非关键字来生成更精确的搜索结果。通过维度嵌入,一个向量能够代表一个词的概念。
因此,基于向量搜索的语义搜索超越了简单匹配由词元表示的关键字概念的局限,从而实现了更高效准确的搜索体验。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号