devv.ai 是如何构建高效的 RAG 系统的



◆Part1
RAG 的全称是:Retrieval Augmented Generation(检索增强生成) 最初来源于 2020 年 Facebook 的一篇论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(是的,你没有看错,2020 年就有这项技术了)。

这篇论文要解决的一个问题非常简单:如何让语言模型使用外部知识(external knowledge)进行生成。通常,pre-train 模型的知识存储在参数中,这就导致了模型不知道训练集之外的知识(例如搜索数据、行业的 knowledge)。之前的做法是有新的知识就再重新在 pre-train 的模型上 finetune。 这样的方式会有几个问题:
- 每次有新的知识后都需要进行 finetune
- 训练模型的成本是很高的
于是这篇论文提出了 RAG 的方法,pre-train 的模型是能够理解新的知识的,那么我们直接把要让模型理解的新知识通过 prompt 的方式给它即可。
所以一个最小的 RAG 系统就是由 3 个部分组成的:
1. 语言模型
2. 模型所需要的外部知识集合(以 vector 的形式存储)
3. 当前场景下需要的外部知识
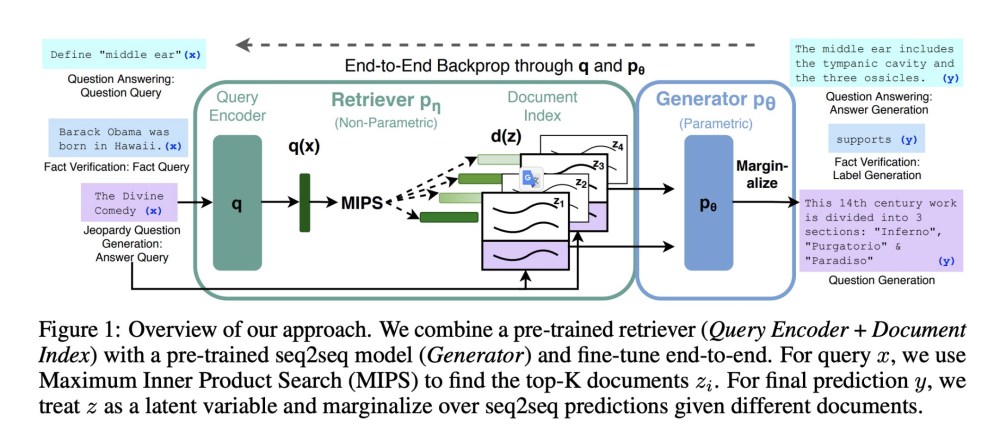
Langchain, llama-index 本质上就是做的这套 RAG 系统(当然还包括构建在 RAG 上的 agent)。
如果理解了本质,其实是没有必要再额外增加一层抽象的,根据自己的业务情况来搭建这套系统即可。例如,我们为了保持高性能,采用了 Go + Rust 的架构,能够支持高并发的 RAG 请求。
把问题简化,不管是搭建什么样的 RAG,优化这套系统就是分别优化这 3 个模块。
◆1) 语言模型
为什么 2020 年的这篇论文直到今年才火起来?
一个主要的原因就是之前的基座模型能力不够。如果底层模型很笨,那么即使给到了 丰富的外部知识,模型也不能基于这些知识进行推演。
从论文的一些 benchmark 上也可以看出效果有提升,但是并没有特别显著。
1.1)GPT-3 的出现第一次让 RAG 变得可用
第一波基于 RAG + GPT-3 的公司都获得了非常高的估值 & ARR(年经常性收入):
- Copy AI
- Jasper
这两个都是构建营销领域 RAG 的产品,曾经一度成为明星 AI 独角兽,当然现在祛魅之后估值也大幅度缩水。
1.2)2023 年以来,出现了大量的开源 & 闭源的基座模型,基本上都能够在上面构建 RAG 系统
最常见的方式就是:
- GPT-3.5/4 + RAG(闭源方案)
- Llama 2 / Mistral + RAG(开源方案)
◆2) 模型所需要的外部知识集合
现在应该大家都了解了 embedding 模型了,包括 embedding 数据的召回。
embedding 本质上就是把数据转化为向量,然后通过余弦相似度来找到最匹配的两个或多个向量。
knowledge -> chunks -> vector user query -> vector
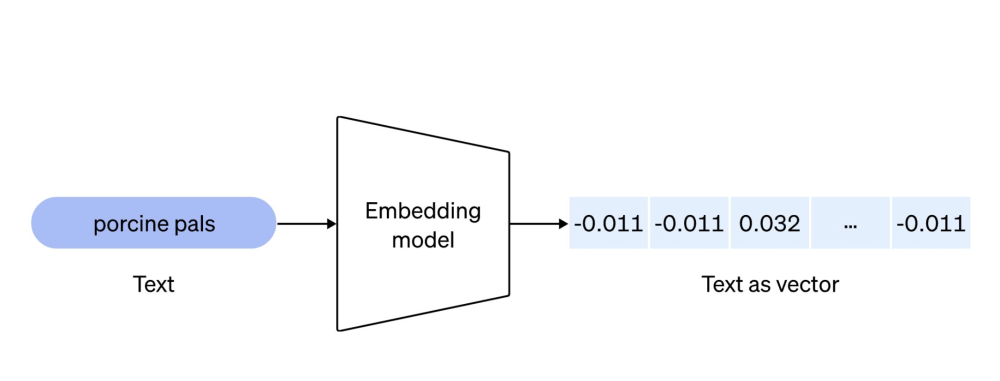
2.1)这个模块分成两个部分:
- embedding 模型
- 存储 embedding vector 的数据库
前者基本上都使用 OpenAI 的 embedding 模型,后者可选方案非常多,包括 Pinecone,国内团队的 Zilliz,开源的 Chroma,在关系型数据库上构建的 pgvector 等。
2.2)这些做 embedding 数据库的公司也在这一波 AI Hype 中获得了非常高的融资额和估值。
但是从第一性原理思考,模块 2 个目的是为了存储外部的知识集合,并在需要的时候进行召回。
这一步并不一定需要 embedding 模型,传统的搜索匹配在某些场景下可能效果更好(Elasticsearch)。
2.3)http://devv.ai 采用的方式是 embedding + 传统的 relation db + Elasticsearch。
并在每个场景下都做了很多优化,一个思路是在 encoding knowledge 的时候做的工作越多,在 retrieve 的时候就能够更快 & 更准确(先做工 & 后做工的区别)。
2.4)我们使用 Rust 构建了整套 knowledge index
包括:
- GitHub 代码数据
- 开发文档数据
- 搜索引擎数据
◆3) 更好地召回当前场景下需要的外部知识
根据优先做工的法则,我们在 encoding 的时候对于原始的 knowledge 数据做了很多处理:
- 对代码进行程序分析
- 对开发文档进行逻辑级别的 chunk 分块
- 对网页信息的提取 & page ranking 优化
3.1)做完了上面的工作之后保证了我们在 retrieve 的时候获取到的数据本身就是结构化的了,不需要做太多的处理,而且可以提升召回的准确率。
◆总结
不管是通用的 RAG,还是专有的 RAG,这是一个做得马马虎虎很容易的领域,但是要做到 90 分很难。
每一步骤都没有最佳实践,例如 embedding chunk size,是否需要接搜索引擎,都需要根据实际的业务场景来多试。
相关的论文非常多,但是并不是每篇论文里面提到的方法都是有用的。
◆Part2
这个系列的 thread 会分享 devv.ai 背后构建整个 Retrieval Augmented Generation System 的经验,包括在生产环境上的一些实践。
这是系列的第二篇,主题是「如何评估一个 RAG 系统」。
上篇我们提到了什么是 RAG 系统,以及构成的基本要素,这里再来复习一下。
一个最基本的 RAG 系统由以下 3 个部分组成:
- 语言模型
- 外部知识合集
- 当前场景下所需要的外部知识
想要优化整个系统,就可以把问题分解为优化这个系统的每个部分。
但是优化一个基于 LLM 的系统的难点在于,这个系统本质上是一个黑盒,没有一套有效的评估手段。如果连最基础的 benchmark 也没有,怎么提升对应的指标也就是空谈了。
所以我们要做的第一件事就是先建立对整个 RAG 系统的评估体系。
来自 Stanford 的这篇论文主要做的就是这个工作,评估生成式搜索引擎的可验证性。
Evaluating Verifiability in Generative Search Engines
arxiv.org/abs/2304.09848

这篇论文虽然是用来评测 Generative Search Engine(生成式搜索引擎),但是也完全可以把其中的方法应用到 RAG 上,本质上 Generative Search Engine 算是 RAG 的一个子集,还有针对于特定领域数据的 RAG 系统。
论文中提到了一个值得信赖的 Generative Search Engine 的先决条件就是:可验证性(verifiability)。
我们都知道 LLM 经常会一本正经的胡说八道(幻觉,hallucination),生成一些看似对,实则错的内容。而 RAG 的一个优势就是给模型提供了参考资料,让模型降低幻觉的概率。
而这个幻觉降低了多少,就可以用 verifiability 这个指标来进行评估。
理想的 RAG 系统应该是:
- 高引用召回率(high citation recall),即所有的生成内容都有引用(外部知识)充分支持
- 高引用精度(high citation precision),即每个引用是否真的支持生成的内容
实际上这两个指标不可能做到 100%,根据论文中的实验结果,现有的 Generative Search Engine 生成的内容经常包含无据陈述和不准确的引文,这两个数据分别是 51.5% 和 74.5%。
简单来说,就是生成的内容和外部的知识不匹配。

论文对 4 个主流的 Generative Search Engine 进行了评估:
- Bing Chat
- NeevaAI(已经被 Snowflake 收购)
- Perplexity
- YouChat
评测的问题来自不同的主题和领域。
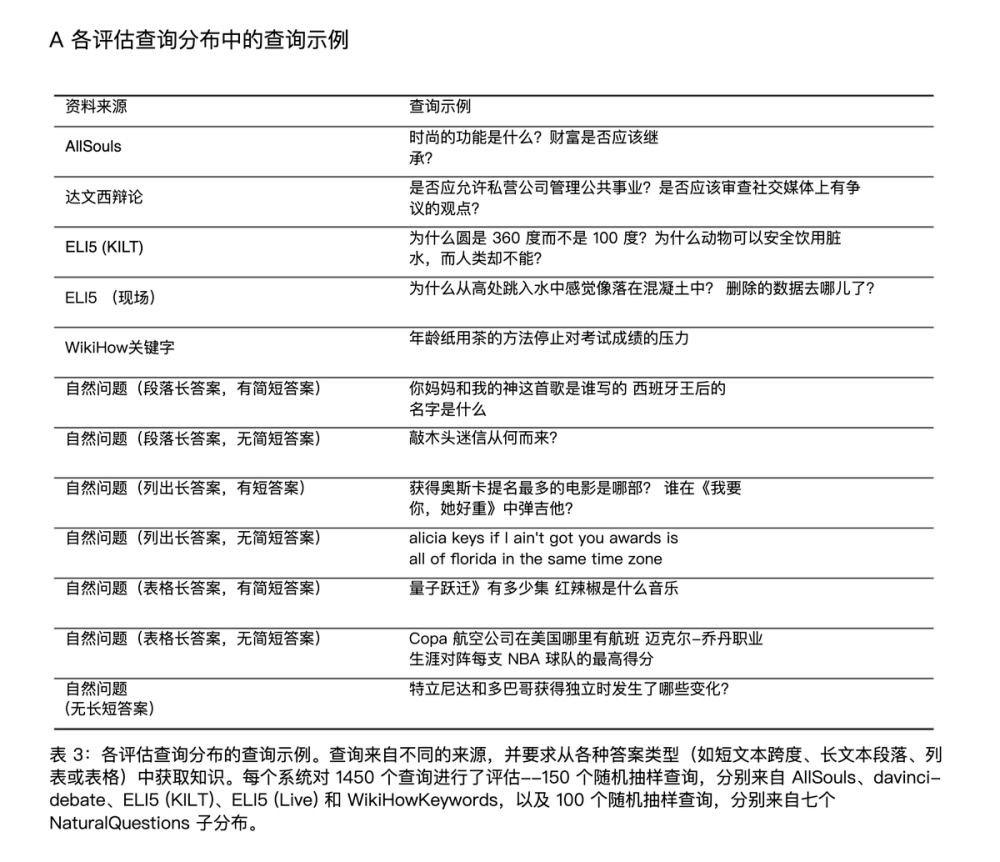
采用了 4 个指标来进行评估:
- fluency,流畅性,生成的文本是否流畅连贯
- perceived utility,实用性,生成的内容是否有用
- citation recall,引文召回率,所生成的内容完全得到引文支持的比例
- citation precision,引文精度,引文中支持生成内容的比例

指标 1 和 2 通常是基本条件,如果连这个都不满足整个 RAG 系统就没什么意义了(话讲不清再准确也没有用)。
一个优秀的 RAG 系统应该在 citation recall 和 citation precision 上获得比较高的评分。
具体的评价框架是如何实现的?这一部分用了一点初中数学的知识,详细的过程可以直接参考论文原文。
整个实验的评测方式是使用「人为」的评测方式。

1)评测流畅性和实用性
给评测者对应的评测指标,例如 xxx 算是流畅的,并用 five-point Likert 量表来进行计算,从 Strongly Disagree 到 Strongly Agree。
并且让评测者对「The response is a helpful and informative answer to the query」这个说法的同意程度进行打分。
2)评测引文召回(Citation Recall)
引文召回率是指:得到引文支持的生成内容 / 值得验证的生成内容
因此,计算召回率需要:
- 识别生成内容中值得验证的部分
- 评估每个值得验证的内容是否得到相关引文支持
什么是「值得验证」,可以简单理解为是生成内容中包含信息的部分,实践中,几乎所有的生成内容都可以看做是值得验证的内容,所以这个召回率可以近似等于:
召回率 = 引文支持的生成内容 / 总的生成内容
3)测量引文精度(Citation Precision)
引文精度是指生成的引文中支持其相关陈述的比例。如果生成的内容为每个生成的语句引用了互联网上所有的网页,那么引文召回率就会很高,但是引文精度会很低,因为很多文章都是无关紧要的,并不支持生成的内容。
比如说 Bing Chat 等之类的 AI 搜索引擎在使用中文进行询问的时候,会引用很多 CSDN、知乎、百度知道中的内容,在引文召回率上是很高的,甚至有时候每句生成的内容都有对应的引用,但是引文的精度却很低,大部分引文不能支持生成的内容,或者质量很差。
devv.ai 就在引文精度上做了很多优化,尤其是针对于多语言的场景。在使用中文提问的前提下,精度是要显著优于 Perplexity、Bing Chat、Phind 等产品的。
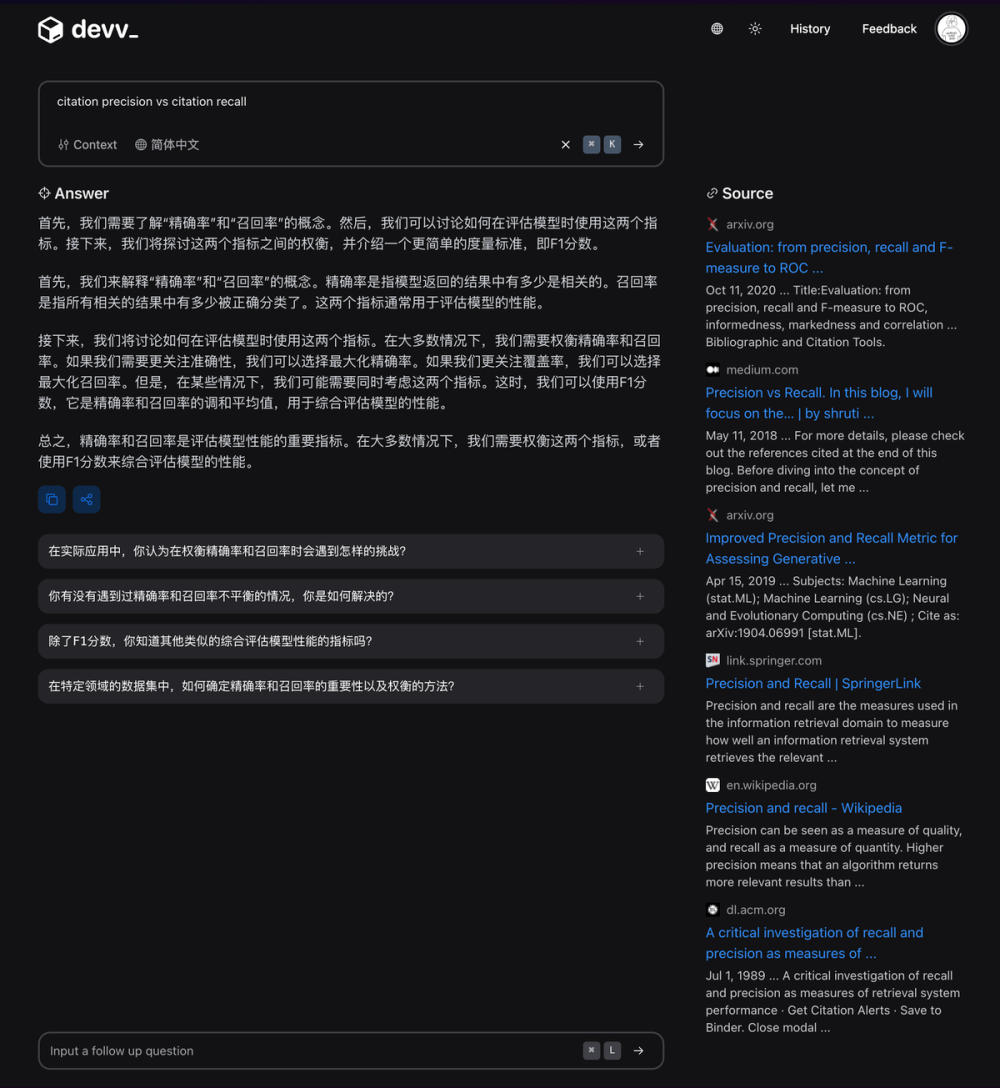
具体的引用精度的计算方法这里就不赘述了,可以参考论文中的描述。
有了引文召回率和引文精度之后,我们就可以计算出 Citation F 这个最终指标了(调和平均数)。
要实现高 F,整个系统必须拥有高引文精度和高引文召回率。

关于 Harmonic Mean(调和平均数)
devv.ai/en/search?threadId=d6xolrry09vk
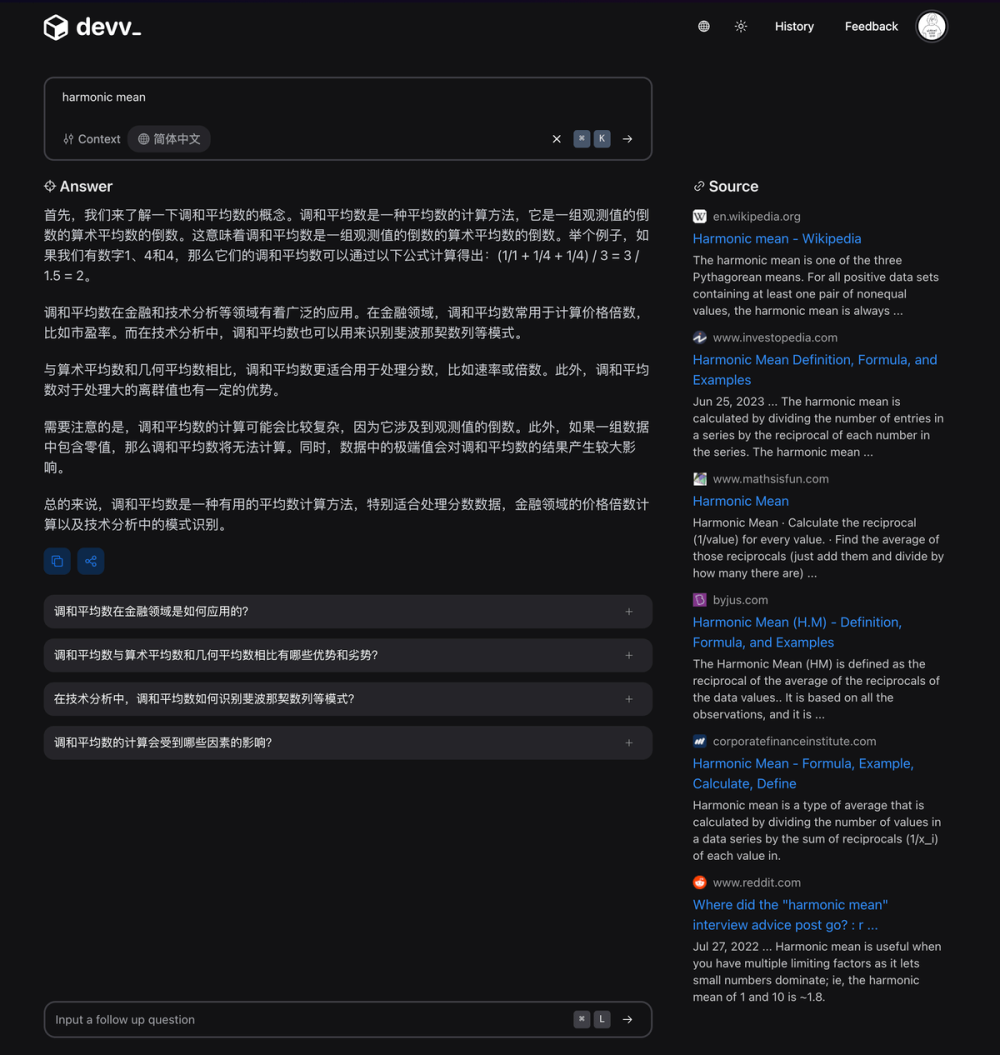
上面就是整套的对 RAG 系统可验证性的评估方法。
有了这套评测系统,每次 RAG 优化了之后就可以重新跑一遍评测集,来确定相关指标的变化,这样就可以宏观上来判断整个 RAG 系统是在变好还是在变差了。
另外分享一下 devv.ai 在使用这套系统时的一些实践:
1)评测集
评测集的选定应该与 RAG 对应的场景所吻合,例如 devv.ai 所选择的评测均为和编程相关,并增加了很多多语言的评测集。
2)自动化评测框架
论文中所采用的还是 human evaluation 的方法,例如论文中使用了 34 个评测人员参与评测。
缺点是:
- 耗费人力和时间
- 样本量较少,存在一定的误差
所以针对工业级场景,我们在构建一套自动化的评测框架(Evaluation Framework)。
核心的思路是:
- 基于 llama 2 训练一个评测模型(验证召回率和引文精度)
- 构建大量的评测集,并且根据线上的数据自动抽样生成评测集
- RAG 核心模块改动后,会有 CI 自动运行整个评测框架,并生成数据埋点和报表
采用这种方法,可以非常高效地进行测试和改进,例如对于 prompt 的改动,可以快速开一个 a/b 实验,然后不同的实验组跑一遍评测框架,得到最终的结果。
目前这套框架还在内部构建 & 实验中,未来可能会考虑开源对应的评测模型和框架代码。(感觉光这个评测框架就可以开一个新的 startup 了)
最后再介绍一下 devv.ai。devv.ai 是专门面向开发者的新一代 AI 搜索引擎,目标是替代开发者日常使用 Google / StackOverflow / 文档的场景,帮助开发者提升效率,创造价值。
产品发布一个多月,已经有几十万的开发者正在使用 devv.ai
另外,有任何的反馈和建议都可以在这个 repo 提交。 也欢迎转发这个 thread 让更多人看到,可以直接转发到其他平台,备注来源即可。
来源:https://twitter.com/Tisoga/status/1731478506465636749
https://typefully.com/Tisoga/PBB58Vu
来源:https://www.toutiao.com/article/7319073154234958372/?log_from=6c1d282a778aa_1704166461102
“IT大咖说”欢迎广大技术人员投稿,投稿邮箱:aliang@itdks.com
来都来了,走啥走,留个言呗~
IT大咖说 | 关于版权
由“IT大咖说(ID:itdakashuo)”原创的文章,转载时请注明作者、出处及微信公众号。投稿、约稿、转载请加微信(备注:投稿),茉莉小姐姐会及时与您联系!
感谢您对IT大咖说的热心支持!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号