Alphafold预测后小工具


今天使用cloba版本的alpahfold预测了21个蛋白质序列。用过colab版本的alphafold的你应该知道,alphafold运行结束之后会自动下载一个压缩包。例如这个样子:
首先是预测:
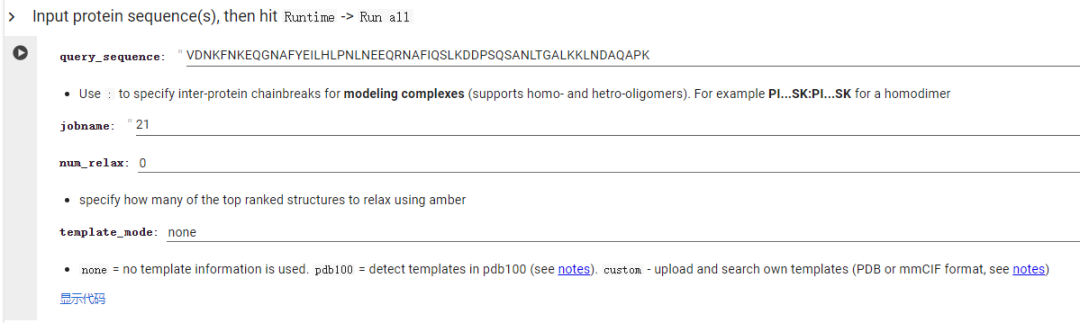
然后是下载下来的压缩包:
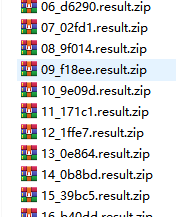
然后选择其中一个解压打开看一下:
会有这样一个子文件夹
然后就是这亚子:
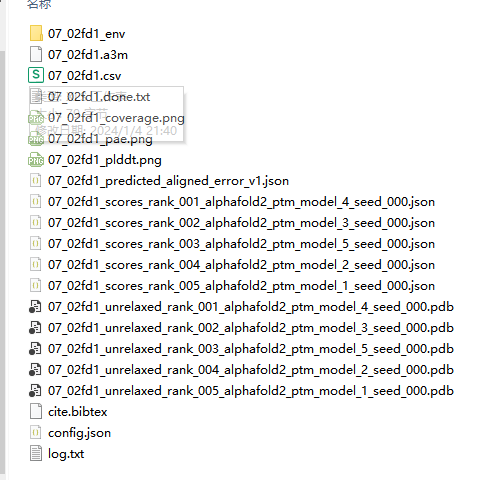
那么每次使用pymol查看蛋白质的三级结构都是需要打开那五个pdb文件中的一个,
like:
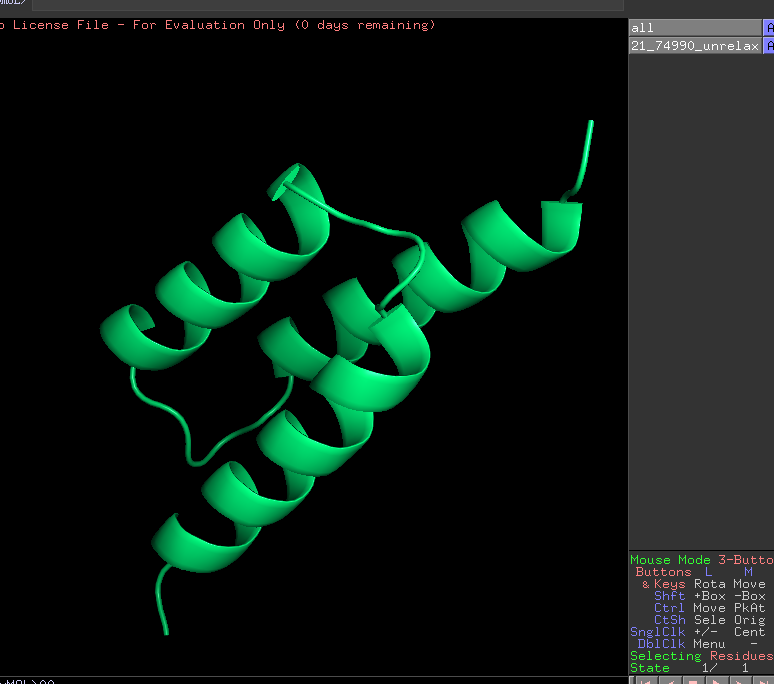
但是这次一次性要解压21个压缩文件,并且还要单独的去打开每一个蛋白质的结构文件,就会觉得很繁琐。因为之前预测的蛋白质结构其实都是一个一个的,不会觉得工作量很大。
那今天就来为colab版本的alphafold预测后的文件来写一个小脚本来批量的操作,并且展示其结构,
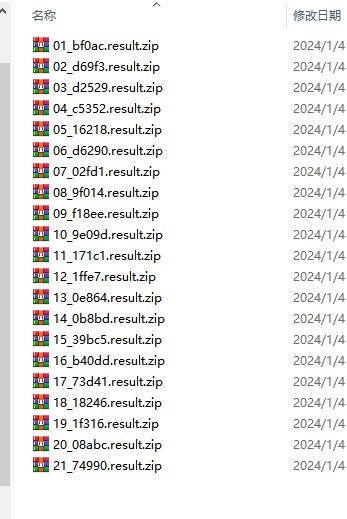
首先我们能确保的是alphafold运行后会自动下载一个压缩包,我们假定21个蛋白质的压缩包都下载到某一个指定的文件夹:
然后我们打开我们的魔法书——jupyter notebook:
启动!
先理清楚思路:
首先我们需要解压这个文件夹下所有的压缩文件,因为这些都是预测出来的蛋白质结构的压缩包。
然后我们需要提取或者把其中一个文件夹里的某个pdb结尾的文件复制出来,或者说复制到我们指定的某个系统文件下,然后使用代码来展示这个pdb的结构。
就完事了,听上去很简单,写起来也不难,来试试吧:
首先解压文件:
def extract_zip(input_zip):
""" 解压ZIP文件 """
with zipfile.ZipFile(input_zip, 'r') as zip_ref:
# 创建一个文件夹,以ZIP文件的名称命名
output_folder = input_zip.rsplit('.', 1)[0]
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 解压文件到该文件夹
zip_ref.extractall(output_folder)然后,复制文件
def copy_specific_files(src_folder, dst_folder, file_name, file_ext):
""" 在src_folder中查找特定文件并复制到dst_folder """
for root, dirs, files in os.walk(src_folder):
for file in files:
if file_name in file and file.endswith(file_ext):
src_file = os.path.join(root, file)
shutil.copy(src_file, dst_folder)切换到我们的目录:
# 当前工作目录
current_dir = os.getcwd()指定我们要搜索的文件的名字和后缀:
# 指定文件名和后缀
specific_name = "rank_001" # 替换为你要查找的特定文件名部分
specific_ext = ".pdb" # 替换为你要查找的文件后缀可以从每个压缩包里发现规矩就是打分第一的名字里都包含rank_001,然后文件后缀是pdb
# 指定的目标文件夹路径
destination_folder = "D:\pdbCopy" # 替换为你的目标文件夹路径
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)指定一个文件夹,就是要把每个蛋白质的pdb文件复制到哪里
如果这个文件夹不存在,则创建之
好了 开始解压:
# 遍历当前目录,解压所有ZIP文件
for item in os.listdir(current_dir):
if item.endswith('.zip'):
extract_zip(item)
然后开始复制:
# 遍历解压后的文件夹,复制特定文件
for item in os.listdir(current_dir):
item_path = os.path.join(current_dir, item)
if os.path.isdir(item_path):
copy_specific_files(item_path, destination_folder, specific_name, specific_ext)
print("操作完成。")ok,我们来看一下花了多久?
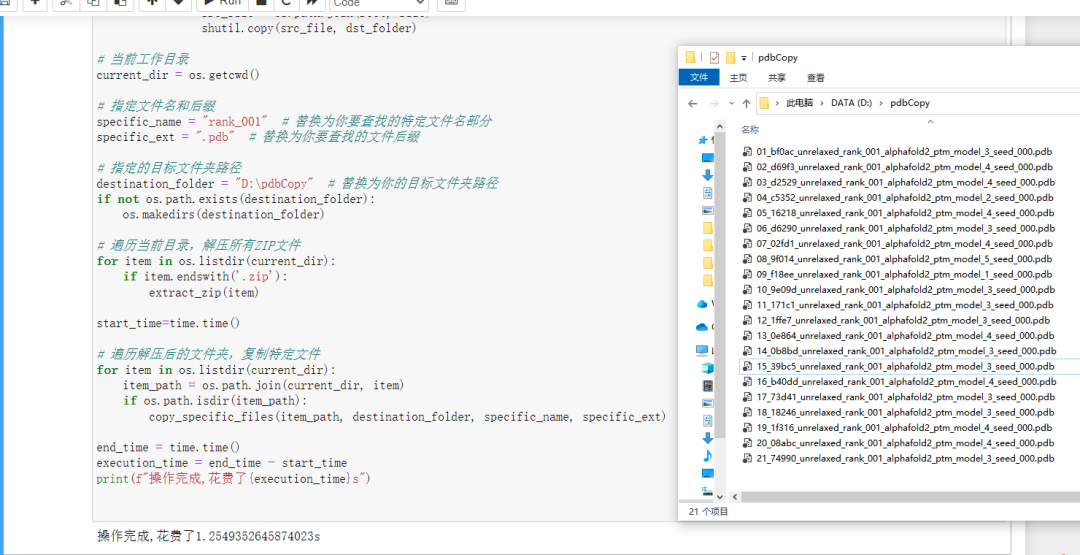
没错,只花了一秒时间,帮我们省了很多时间。
然后就是对应的展示了,直接使用py3dmol就可以了:
首先还是遍历pdb文件,因为我们已经把21个pdb文件复制到了某一个目录下:
os.chdir('D:\pdbCopy')
# 获取当前文件夹中的所有文件和文件夹名
files = os.listdir('.')
pdb_list=[]
for file in files:
print(file)
pdb_list.append(file)然后开始展示其三级结构:
import py3Dmol
pdb_dir='D:\pdbCopy/'
for i in range(len(pdb_list)):
with open(pdb_dir+pdb_list[i], 'r') as file:
pdb_content = file.read()
viewer = py3Dmol.view(width=800, height=400)
viewer.addModel(pdb_content, 'pdb')
viewer.setStyle({'cartoon': {'color': 'spectrum'}}) # 可以根据需要调整显示风格
viewer.zoomTo()
viewer.show()然后看一下效果:
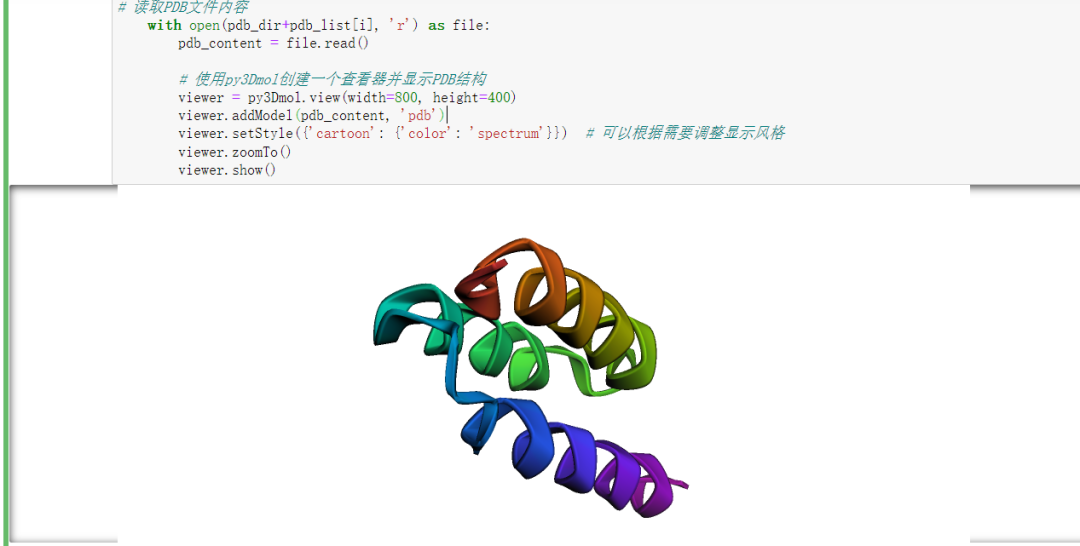
。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号