史上最全知识图谱建模实践(上):本体结构与语义解耦
原创
史上最全知识图谱建模实践(上):本体结构与语义解耦
原创
可信AI进展
修改于 2024-01-26 16:59:52
修改于 2024-01-26 16:59:52
在“无需复杂图谱术语,7个原则搞定Schema建模”一文中,我们总结了知识建模最佳实践的7个指导原则。本文中,我们将分基础篇、进阶篇,针对不同业务场景的建模需求,由浅及深讲解基于SPG的知识建模的方法和案例,并涉及术语的解释。
本文档所提出的建模方案,已经在OpenSPG做了对应的能力支持实现(或开发迭代中)。使用SPG,读者也可以按本文的方法论对自己的业务问题简化抽象,实施对领域知识的建模及对已有常识图谱的复用。
🌟 OpenSPG GitHub:https://github.com/OpenSPG/openspg,欢迎大家 Star 关注~下文中提到的知蛛平台是OpenSPG在蚂蚁内部的产品化平台。
- 如果你对知识图谱已有一定了解或实践,可跳过基础篇(基础篇的“属性语义标化”依然值得一读)。
- 如果你的图谱,涉及对业务类目体系、常识概念(如“行政区划”)的应用,请仔细阅读进阶篇。
基础篇·实体关系设计
解决问题
解决数据的结构化表示,包括实体各属性字段的规范定义,及设计实体间的关系,以便将数据最终构建为有别于传统数据表的图结构形式,便于基于路径的多跳关系查找。
适用场景
- 业务场景关注于静态的,体现物理世界或业务流中客观存在的“事实知识”;
- 已有结构化数据为主(实体表、关系表、用户行为数据等)的数据资产;
- 已有数据资产及业务场景,能够抽象出传统ER关系图的数据建模,可以直接套用实体-关系-属性的建模范式;
- 业务对实体的类型存在划分,如对用户的细分或对商户、门店的细分;这种细分类是有限的(一般只有两三种),每种细分有特定的属性(如线下门店才有poi)。
- 业务对实体特定属性有枚举描述,如“商户评级 = S, A,B,C”,业务应用只需要使用确定值将数据查出来,但不需要基于属性传播。
术语定义
Schema
Schema是知识的“元数据”表达方式,定义了知识的概念的属性,关系,属性及约束。主要实现了实体的结构化和实体间的关系的定义。
实体
物理世界或数字世界存在的事物是一个实体,实体对应于数据表中的一行记录。
实体类型,即实体的“schema”。它是对具有共同数据结构(特征)的一类数据实例的“元数据”模式定义。因此每一个实体类型,都有自身特定的schema。同时,实体类型存在上下位关系,通过继承,下位类拥有上位类已定义的属性和关系及其约束。在知识图谱平台中,实体类型用于对具有共同数据结构的个体进行分组管理。可以将实体类型理解为,对知识结构化表示的语法规范。如下表所示,是对自然人的schema定义。
自然人模型(Person)示意 | ||||
属性英文名 | 属性中文名 | 属性类型 | 属性值 | 是否必填 |
id | id | Text | 12345xxx | 是 |
name | 姓名 | String | 张三 | 是 |
certId | 证件号 | String | 330121xxx | 否 |
certType | 证件类型 | 枚举类型Text(枚举约束) | 身份证 | 否 |
birthday | 出生日期 | 时间类型STD.Date | 20230215 | 否 |
gender | 性别 | String | 男 | 否 |
occupation | 职业 | String | 白领 | 否 |
...... | ...... | ...... | ...... | ...... |
关系
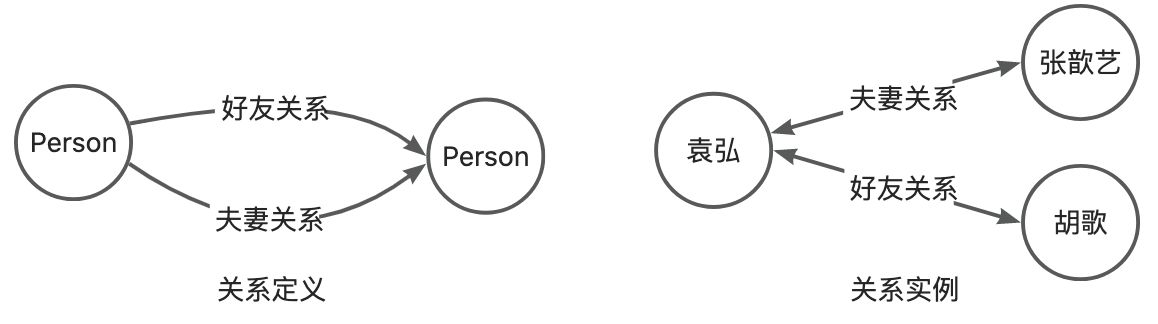
描述实体-实体间的关联。在基础的实体关系设计时,只考虑满足SPO(Subject-predicate-Object)表示的二元关系,既两个实体间确定的关系。如定义一个关系:公司-法人->自然人,“法人”是关系谓词,关系主体是“公司”这种实体类型,客体是“自然人”;注意,关系是有向的,则一个“公司”的实例拥有一个出边到确定的“自然人”,且该自然人是这个公司的法人。

自然人相关关系定义
Subject | Predicate | Object | 是否唯一 |
Company | 法人 | Person | 是 |
Person | 好友关系 | Person | 否 |
Person | 夫妻关系 | Person | 是 |
Person | 居住地 | POI | 否 |
...... | ...... | ...... | ...... |
属性语义标化
属性 vs 关系
在实体-关系建模时,对于实体的特性字段,到底应该建模为属性,还是应该将特征key构建为关系,特征值(value) 建模为实体,设计者经常陷入两难的抉择。例如:
在对商户建模的典型场景,一般商户会有关联的PID,在关系型数据表(odps)中,PID是一个id字段,pid本身也没有特别的属性,为了挖掘同pid的商户、发现用户对商户的消费行为,pid应该建模为实体,但Pid没有任何属性,这样做合适吗?
在例如对于商户的发货地址、所在省市区等特征,在数据表中一般是个string。但为了同地址、同地区的发现,甚至特定业务场景本来就有地址实体库。那么就需要对地址属性建模为关系了。但这带来两个问题:
1.商户的发货地址、用户的收货地址可能存在变动,特别是用户收货地址,在图谱中维护时,需要在新增地址时,把历史地址边删除;
- 对于所属省、所属城市、所属区等,若都建为实体拉边,将造成“热点”(即某个点有巨量的边),为路径推理、采样带来困难。
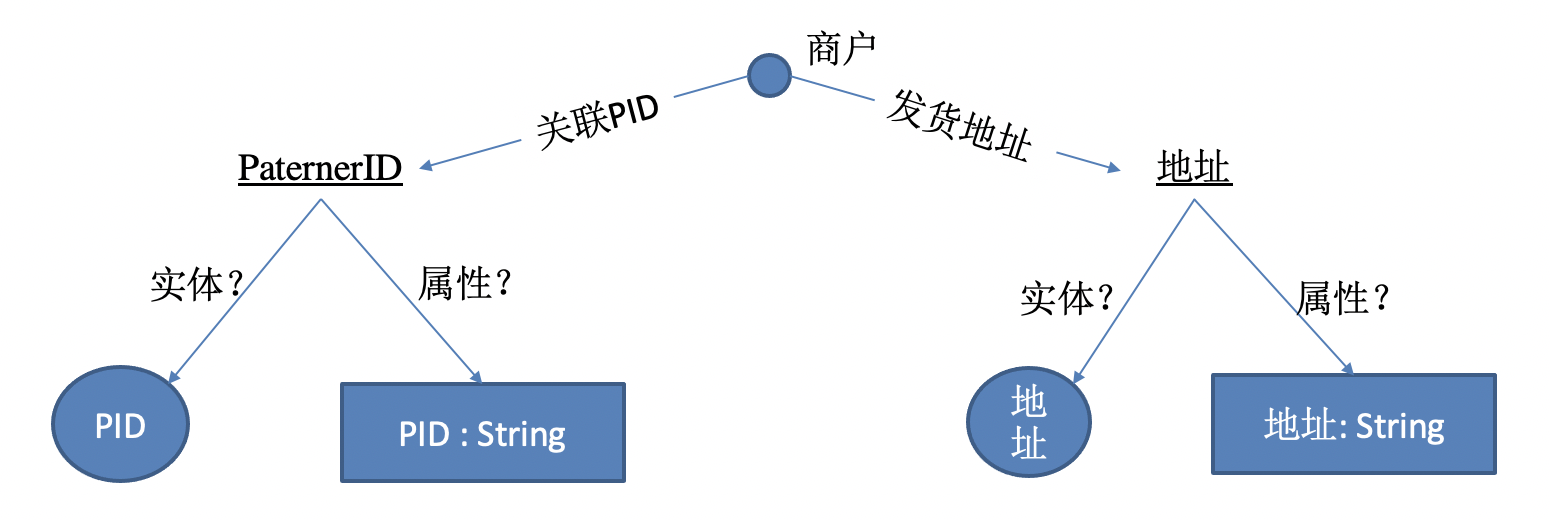
- 属性:易维护(值覆盖)、存储量小、不传播,难以发现关联(属性值相同的实体并没有显式的关联)
- 关系:有维护成本(修改需要删边再拉边)、储存量大、可传播(可加强图结构,发现节点间的共边关系)、同关系类型的边过多(例如,明星的社交关系,作为关注者只有几百条边,作为被关注者有千万级的边),对图学习的关系采样带来干扰(对图谱中的“热点”,若采样策略为不限定边类型但对邻边限定数量随机采样时,可能采到的都是数量大但重要性不大的点)
属性标化
为解决上述的属性/关系难以抉择,及提高知识管理的效率及降低存储压力,我们提出一种基于属性语义标化的建模方法,并在知蛛(OpenSPG在蚂蚁内部的产品化)产品功能上已经交付可用。
属性语义标化能力体现为:
- 用户在实体建模时,不必纠结实体特征需要定义为属性or关系,统统建模为属性;
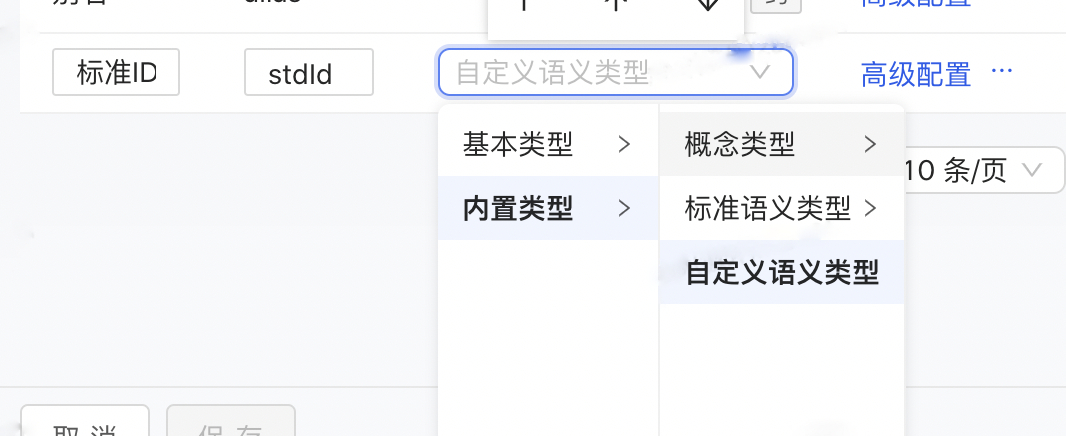
- 在属性类型选择时,除了Integer、Float、Text三种基本类型外,提供具有语义传播能力的语义类型(如内置的概念类型、内置的标准属性类型、用户自定义的实体类型或概念类型等)
- 在实例数据生产时,用户当作属性维护(如属性一样做知识导入的字段映射,属性值修改直接覆盖
- 根据所选择的属性语义标化类型,根据所填充的属性值语义(以文本匹配、id匹配的方式)系统自动构建“虚拟边”;
- 系统自动创建及维护的虚拟边,在查询效率、图算法邻边采样时,与用关系建模、关系导入生产的物理边效果一致;
- 当语义属性为多值时(如一个user拥有多个手机号码),用英文逗号分割。注意:对于实体的某特征,值是有限个(一般<10,如关联邮箱、所属业务类目、银行账户等),可以用属性语义标化建模来简化知识的管理维护。当特征值数量极大时(如:用户-消费->小程序id),依然建议使用关系建模。
属性语义化相关功能如表格所示:
属性类型 | 类型细分 | 属性定义 | 用法及示例 |
|---|---|---|---|
内置类型概念类型 | 通识概念 | 一个描述常识分类体系的树状知识库,现覆盖17个大类的2W+常识概念,详见文档 | 当实体的类型需要细粒度的分类,且该实体的细分类可以用常识知识体系描述时,定义描述实体细分类的属性(如:对于BaikeEntry定义了子类型 subType),并将属性类型选择为“内置类型-概念类型-CKG.AntTermType”。知识生产时,对实体实例的subtype赋值为常识知识树上任意的概念的文本名称,则平台自动将该属性转为一个 BaikeEntry-subtypestd->常识概念 的边。则细粒度一样的 BaikeEntry在图结构上能够拥有共同的概念节点邻居(如姚明、易建联都是“篮球运动员”) |
行业类目 | MCC类目POI类目门店类目等 | 知蛛平台上集成维护了蚂蚁域内常用的MCC2.0、高德POI类目和门店类目以往对相关商户、门店、POI/AOI实体建模时,业务往往用多个字段维护各级类目的code和名称现在对实体-特定类目的信息维护,只需定义一个属性(如定义一个“所属类目”属性),并将属性类型选择为“内置类型-概念类型-具体的某个类型体系”。知识实例生产时,将属性值填充为类目的code或名称(一般是叶子节点的类目),则平台能力可以追溯类目的上级路径,并自动拉边,关联具有同类目的实体实例。同时,平台提供存量迁移的能力,对于历史遗留的相关属性,也能够迁移为语义标化属性,如图为对蚂蚁POI库进行的迁移维护。 | |
内置类型标准语义类型(编码id相关) | 虚拟地址 | 邮箱网址等手机号码Mac地址国内电话号码…… | 这类属性标化类型是指,用户选择特定的“内置类型-标准语义类型-特定可传播的标准id类型”,则实例数据生产时,属性字段值填写对应的id、url、电话号码等(多值用英文逗号分隔),平台提供:正则检测:平台会对邮箱、手机号码、国内号码、银行账户、2088账户等,对所填编码的逻辑格式进行正则检测ID链指:平台会对每个语义类型下,每个存在的id构建一个虚拟节点,并按照实例知识中实体-id的属性值,构建实体与该id所属虚拟节点的边关系;这项机制能够帮助用户发现及可视化同id、同电话号码、同邮箱的实体。 |
ID属性 | 身份证号码2088账号支付宝PID银行账户蚂蚁POI…… | ||
内置类型标准语义类型(时间相关) | 时间戳 | 1665476056 | 时间标准化及时间的计算比较 |
内置类型标准语义类型(空间类型) | 行政区划 | 国家-省-市-区四级(目前仅支持中国行政区) | 知蛛平台集成了四级标准行政区划类目以往业务为了表示结构化的标准多级地址,一般会构建国家编码/国家、省编码/省、市编码/市、区编码/区,共8个属性字段,存在着属性的冗余储存。且plain text的文本属性,不利于快速的发掘同地区的实体。利用语义标化,将表达实体行政区域特性的属性,类型选择为“内置类型-概念类型-行政区划”,数据生产时,将属性值填充为能够识别到的最细粒度的行政区划单位(平台提供兜底默认算子,帮助地址的结构化理解及标准化)通过语义标化链指能力,对于填充的行政区划属性值,其上级类目是可追溯的(如所在区县为“西湖区”时,西湖区-位于->杭州市-位于->浙江省-位于->中国,是已维护在“行政区划”类目树上的)平台能够自动拉边,维护实体(如poi、aoi、门店等)到特定省、市、区县的关系,并实现不同粒度下所属行政区划的查询。 |
经纬度坐标点 (Position) | (经度,纬度) | 同POI计算发现(球面距离小于epsilon) | |
经纬度范围 | (Position1,Position2)地理区块四边形(左上-右下坐标) | 判断一position是否在该范围内 | |
自定义属性类型实体/概念 | 平台内置的概念类目体系、可传播的语义属性类型,无法完全满足特定业务的建模需要;因此,用户可以将属性类型赋值为“内置类型-自定义属性类型”,则在高级配置页面,选择将属性标准化为自定义的一个实体类型(默认用id链指)或概念类型(默认用概念名称链指)。如果所示,对于“公司事件”实体,拥有两个语义标准化属性的应用——1.主体,选择为“工商机构”实体,则能够利用平台id链指能力自动拉边到确定的“工商机构”实例;2.事件的客体,属性值可能是“产品”或“金融指标”,则能够利用平台的语义化能力帮助后续的要素链指挂载。 | ||
其他待开发的属性 | 数量类型 | 数额 | 度量/指标类型+数值表示对度量/指标类型标准化同一数量类型的比较区间数值合法性检验 |
指标 | |||
区间数值属性 | 年龄年份 |
表3 属性语义标准化类型
建模步骤及案例
实体关系设计,是为具有同样结构化特性(即有同样的特征要素) 的实体定义的实体类型的schema,并建立实体类型间的关系。实体schema包含实体类型的命名、属性定义、属性类型及属性值的约束,关系schema约束关系主体和关系客体的实体类型。我们推荐在启动一个新的图谱项目时,按照以下步骤进行实体-关系建模:
CoreKG schema 复用
schema的设计具有主观性,为了消除这种主观偏差,特别是降低跨图谱知识融合的复杂性,我们从过去的业务图谱设计经验中,总结了蚂蚁场景下常见的实体类型schema,并商家到corekg核心图谱;当业务涉及到这些实体数据时,可以直接对实体schema及数据引用/复用,减少重复建设,快速启动新的图谱项目。
如果为了业务安全/数据隔离等的考虑,业务需要自定义及构建自己的实例数据,我们也推荐对于corekg已有的实体类型,用户可以对其schema设计,特别是属性的定义和命名参考借鉴。

图3 corekg核心实体定义
实体关系设计
参考corekg中已有实体的schema,针对业务问题及数据,构建业务所需实体定义。
比如前文所述对蚂蚁用户定义的自然人模型,包括"姓名(name)"、"年龄(age)"、"身份证号(certNo)"、"家庭住址(homeAddr)"等基础属性,此外,定义"Person-好友关系-Person"、"Person-夫妻关系-Person"等关系。
自然人模型(Person) 示意 | ||||
属性英文名 | 属性中文名 | 属性类型 | 属性值 | 是否必填 |
id | id | String | 101xxx | 是 |
name | 姓名 | String | 张三 | 是 |
certId | 证件号 | String | 330121xxx | 否 |
certType | 证件类型 | 枚举类型 | 身份证 | 否 |
birthday | 出生日期 | 时间类型 | 20230215 | 否 |
gender | 性别 | String | 男 | 否 |
occupation | 职业 | String | 白领 | 否 |
...... | ...... | ...... | ...... | ...... |
不同业务因领域模型不同会有自己的业务知识,比如同样一个用户,由于归属的业务不同,在蚂蚁会存在"支付宝用户(AlipayUser)"、"财富用户(FortuneUser)"、"网商用户(MyBankUser)"、"保险用户(BaoxianUser)"等用户模型,虽然这些用户模型背后指向的是同一个自然人模型,但在不同业务域有新增的属性字段,则利用schema的继承复用已定义的属性/关系约束,并在此基础上扩展新的特性。
支付宝用户模型(AlipayUser) 示意 | ||||
属性英文名 | 属性中文名 | 属性类型 | 属性值 | 是否必填 |
id | AlipayId | 编码类型 | 2088 | 是 |
name | 姓名 | String | 张三 | 否 |
memLevel | 会员等级 | 枚举类型 | 黄金会员 | 否 |
shoppingPref | 购物偏好 | 物品概念 | 小吃 | 否 |
...... | ...... | ...... | ...... | ...... |

用户统一模型示意
对于不同业务实体归属同一主体的情况,一是可以在Schema层归类到统一实体模型上(深度继承),二是可以在数据层在相同实例之间增加isA或sameAs谓词关系(实体融合),达到主体分类一致的目的。
语义标准化
参考“属性语义标化”章节的内容,优化属性/关系的定义,将可以标化的属性选择为标准属性类型,对于适用id链指/概念链指的关系,转化为语义属性。例如,由于夫妻关系是唯一的,则可以将夫妻关系建模为语义属性。而朋友关系是多对多的,一个人可能有上百个朋友,因此依然用关系建模朋友关系。
进阶篇·概念语义建模
解决问题
在知识图谱中,除了知识的元数据定义(即schema),通用常识和领域知识的语义关系、常识/业务类目的分类体系,体现了对语义的认知。为了将语义建模与知识的结构化表示解耦,我们提出的方案是用“概念语义建模”来对常识概念及常识关系建模,对特定领域知识的认知体系和经验规则建模。
如图4所示,在概念建模中,构建对常识/特定实体类型的分类体系。Root节点,代表“常识知识树”的根结点,在这棵概念树上,我们预定义了17种实体的分类体系,如“角色”、“物体与物品”、“组织机构”、“品牌”、“事件”都是一个“概念类型”(即一个分类体系的根结点),每个概念类型作为起点的子树,定义了对该类实体的语义细分,目前蚂蚁知识树上已经有超过2W+的节点。此外,在常识概念图谱中,我们还集成了高德poi类目、意图图谱、mcc2.0行业类目、行政区划概念树、hownet义原语义网络,作为跨领域可插拔的常识语义认知系统,帮助各个业务图谱深度实体类型理解及属性语义标准化。
例如对于图中所示的描述服务内容结构化理解的领域图谱,在领域图谱中,小米10-手机类型->“智能机”,“智能机”是结构化抽取到的spo mention,通过概念链指标准化到知识树上的概念“智能手机”,则通过知识树的可追溯链路,能够知道小米10同时也属于手机、数码产品、电子电器产品。
同时,为了保障语义的内聚性,尽量为用户提供简洁的描述并加强信息间的关联,“概念”也提供对关系谓词(即属性名称、关系名称)标准化的能力。如“所属公司”这个谓词,其实约束了尾节点的实体是一个公司。
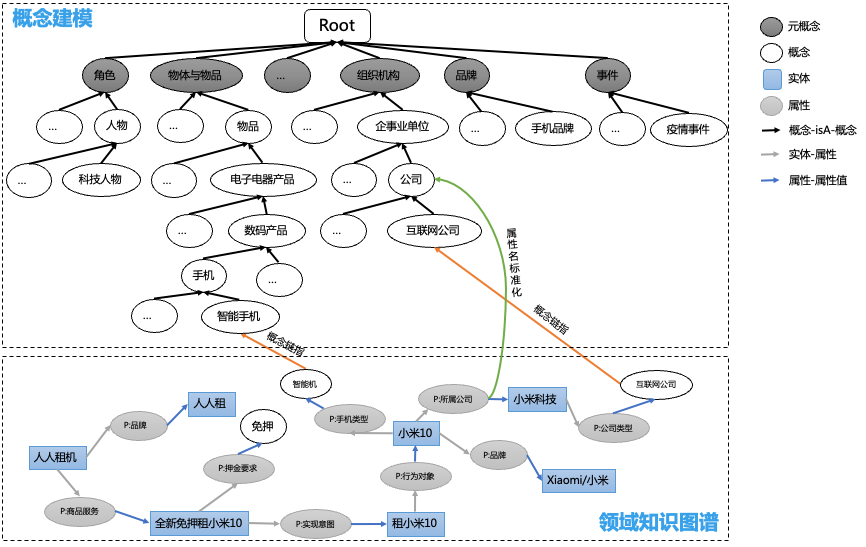
图4 概念语义建模
适用场景
- 除了将图谱当作一个能具备增删改查功能的数据库,还希望对业务逻辑、领域经验进行管理;对文本属性,不只是作为“符号”,还希望能理解文本背后的语义,挖掘知识间的隐含关联;
- 业务上对实体定义了非常详细的分类类目,一般这种类目是以树状形式组织的;
- 实体的属性字段的值是行政区划、职业、行业类型等常识术语,并希望这些属性在图上是“可传播”的(即通过这个值,可能关联扩散到其它拥有同样值的属性节点),这些常识术语本身有层级蕴含关系(如:位置在西湖区,则一定也位于杭州市)
- 业务定义的类目,不仅仅是一个用来区分实例的标签值,还存在背后的定义逻辑(如:活跃人群 = 过去30天支付宝访问超过1次的user)
- 希望表达领域常识(程序员有夜间出行偏好)并应用,而不是记录具体实例的事实(行为事实:小蚂在x年x月x日晚上21:00在A空间打车;偏好事实:小蚂的“偏好属性”字段被打上了“夜间出行偏好”)。
术语定义
概念
把所感知的事物的共同本质特点抽象出来,加以概括,是自我认知意识的一种表达,形成概念式思维惯性。概念的意思:思维的基本形式之一,反映客观事物的一般的、本质的特征。
概念建模,期望通过对实体分类体系和基于common sense的通用语义元素的定义,并以树状层级体系进行组织,自顶向下的体现实体语义的细分。其中我们将满足以下任意一个特性的短语定义为一个概念(concept)

图5 概念是什么
概念类型
meta-concept,即概念的概念,在知蛛上是指用来组织一个特定概念体系的规范。概念类型定义,就是根据对特定领域/业务的认知或常识,定义该类型概念的结构,约定概念的属性、层级结构及表达层级结构的语义谓词。
当我们需要在语义上对实体类型细分时,实体类型的schema可以对应一个概念类型,以表现对该类型实体类型的分类体系。例如图四中的“角色”、“物体与物品”、“组织机构”、“品牌”、“事件”都是“概念类型”,定义了对特定实体的语义细分体系。
概念 VS. 实体
概念 | 实体 | |
什么是概念 | 概念是对具有同样特征的实例的抽象,是语义上/认知上能够被“归类”为同一类型的实例的集合。概念是符号化的,但领域内的人对它这个符号的语义是有共识的。概念带有领域/业务/常识的主观或经验,是人为定义的,概念的内涵/语义是相对恒定的。概念的符号体现了自身的语义,概念之间构建的语义关系边 (白酒板块事件 -主体-> 白酒板块,白酒板块-产品->白酒,白酒-原料->粮食,猪瘟疫情事件-影响->猪肉价格上涨,形成了描述领域常识的语义网络。以上举例的三元组中的S和O都不是具体的、特定的实例,而是对同一类实体,及同类实体所具备共有特性的概括)。可以先简单粗暴的认为,“概念”是没有“属性”的(除了编码、别名、描述)。事件抽取出的mention,无法与实体库对齐的文本类型要素(非时间、非数值),都可以认为是概念 | 实体类型,是对拥有同样数据结构/论元要素的数据的定义。实体实例,是id化的,唯一存在的实例。实体是客观的存在,实体的特征是动态变化的。实体拥有特异的属性/关系定义。例如:某个事件的发生事件、地点、主体、客体;某部手机的型号、屏幕、尺寸、内存等参数。 |
什么应该被定义为概念 | 类目概念: 对具有同样特征的一类实体的语义抽象,可以来自业务类目、领域的taxonomy,比如POI类目、MCC类目等。常识概念: 在特定领域(概念类型)下,人们有共识的无歧义短语,比如杭州市、手机、中秋节。原子概念: 一般存在于L0-L2级的概念,概念名是不可拆分的表达完整语义的核心词,一般直接来源于领域常识术语。如:产业链事件、芯片、有色金属。业务类目、领域的分类体系(职业分类、企业分类、品类、产业分类、NER_Label、实体类型、属性名称、边关系类型、人群标签、星座、血型、人种、民族、学历、奖项、各种title,都是概念。———————————————————————— 复合概念: 在一个核心词概念上增加语义修饰限定(该限定可以是概念, 也可能代表特定实例),例如:“白酒”+“产品价格上涨” = 白酒产品价格上涨 “杭州” + “互联网”+“上市公司” = 杭州互联网上市公司 "腰封偏好" +"高日活"+ "支付宝账户" = 高日活的腰封偏好支付宝账户 “阿里巴巴”+“公司” = 阿里系公司 “华为”+“手机” = “华为手机” 复合概念 可以拆解为等价的谓词逻辑表达式 | 品牌不是“概念”,它是特定厂商定义的一个IP,本身不具备认知的层级体系。如果品牌有类目体系,则品牌类型是概念。物理世界真实存在的一个个体,蚂蚁内部特定的一个账户、一个商家、一个供给内容,是实例。 |
概念能够表达那些语义 | 1.对实体进行细分类,完成schema无法体现的更详细的语义。通过逻辑表达式定义的规则,自动完成“复合概念”的生成及帮助推理属于该集合的实例2.提供属性的标准化及语义化,则属性值不再只是一个plain text,而是依靠概念语义网络,可关联可追溯的子图。对多跳上下游产业链关系、上下位产品品类的召回进行处理 | 实体类型的schema是在知识管理的角度,来选则粗粒度的“类型”。 |
表4 概念和实体的区别
建模步骤及案例
我们以事理图谱的概念语义建模为例,介绍用户自定义概念体系并使用概念为实体做细分类的方法。
事件体系语义建模
在事理图谱场景下,需要金融事件相关的各种事件类型建模,包括宏观的行业时间、国家政策事件,也有微观的局部地区的牲畜疫情事件、个股涨跌事件、公司事件;宏观事件可能影响微观事件,微观事件的发生可能引发另一个微观事件。
金融场景下包含的事件类型十分庞大,每种事件在业务上所关注的事件要素是不同的。同时,业务会对同一大类的事件继续语义细分以便套用业务逻辑去做风险预警、评级,例如图6所示,公司事件下,会细分出工商信息变更事件、高管变动事件等,高管变动事件下又有实控人变更、股东跑路、实控人涉诉等。当事件类型语义细化到很细节的粒度时,不再涉及事件要素的新增(即元数据结构上没有变化)。
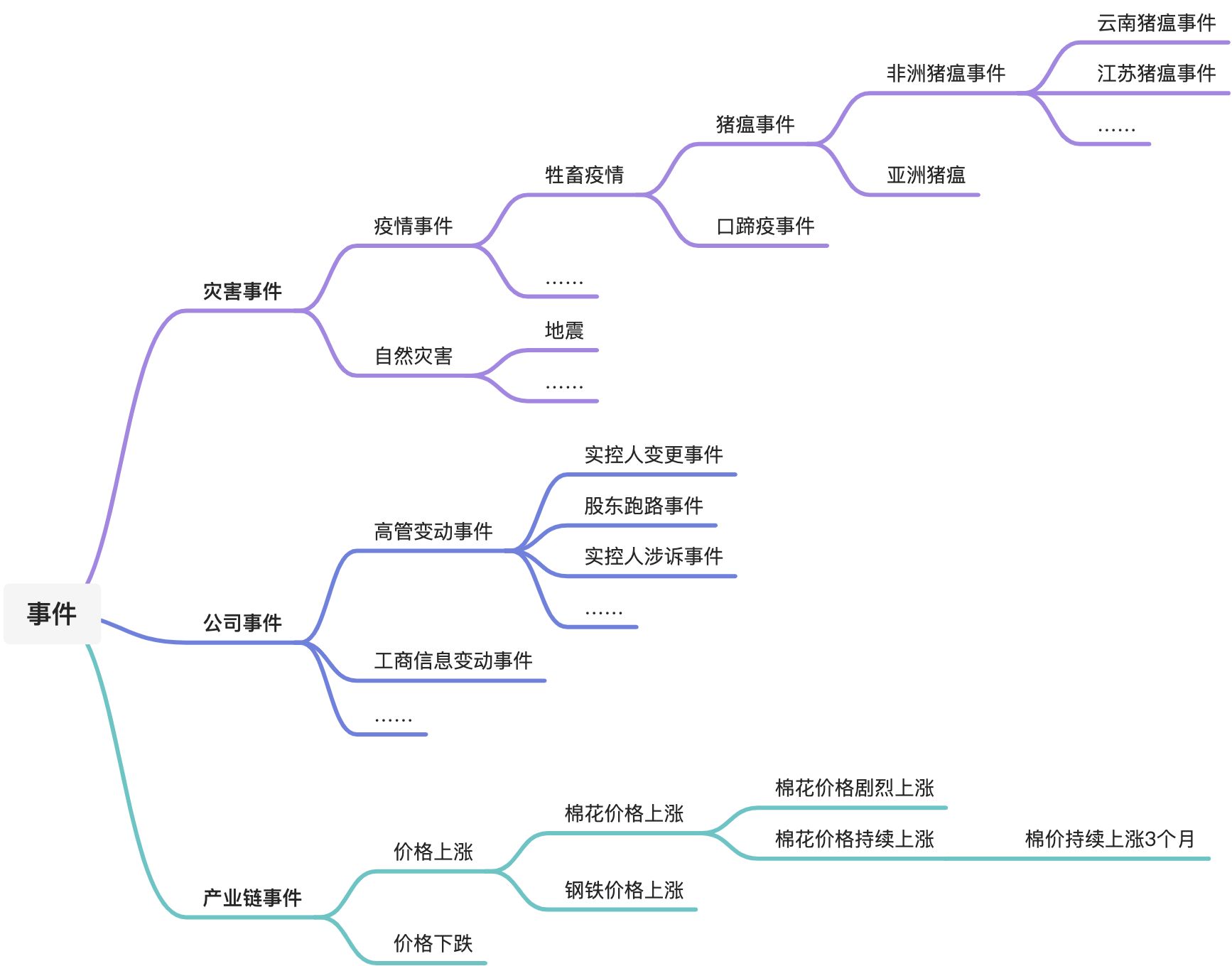
图6 事件概念体系示意(局部)
因此,如图7所示,在知识建模时,将事件的结构化表示所需要的schema定义,和业务上的事件认知分类体系解耦为两个独立的树状体系,再使用标准谓词、逻辑规则等构建结构与语义的对应关系。具体步骤如下:
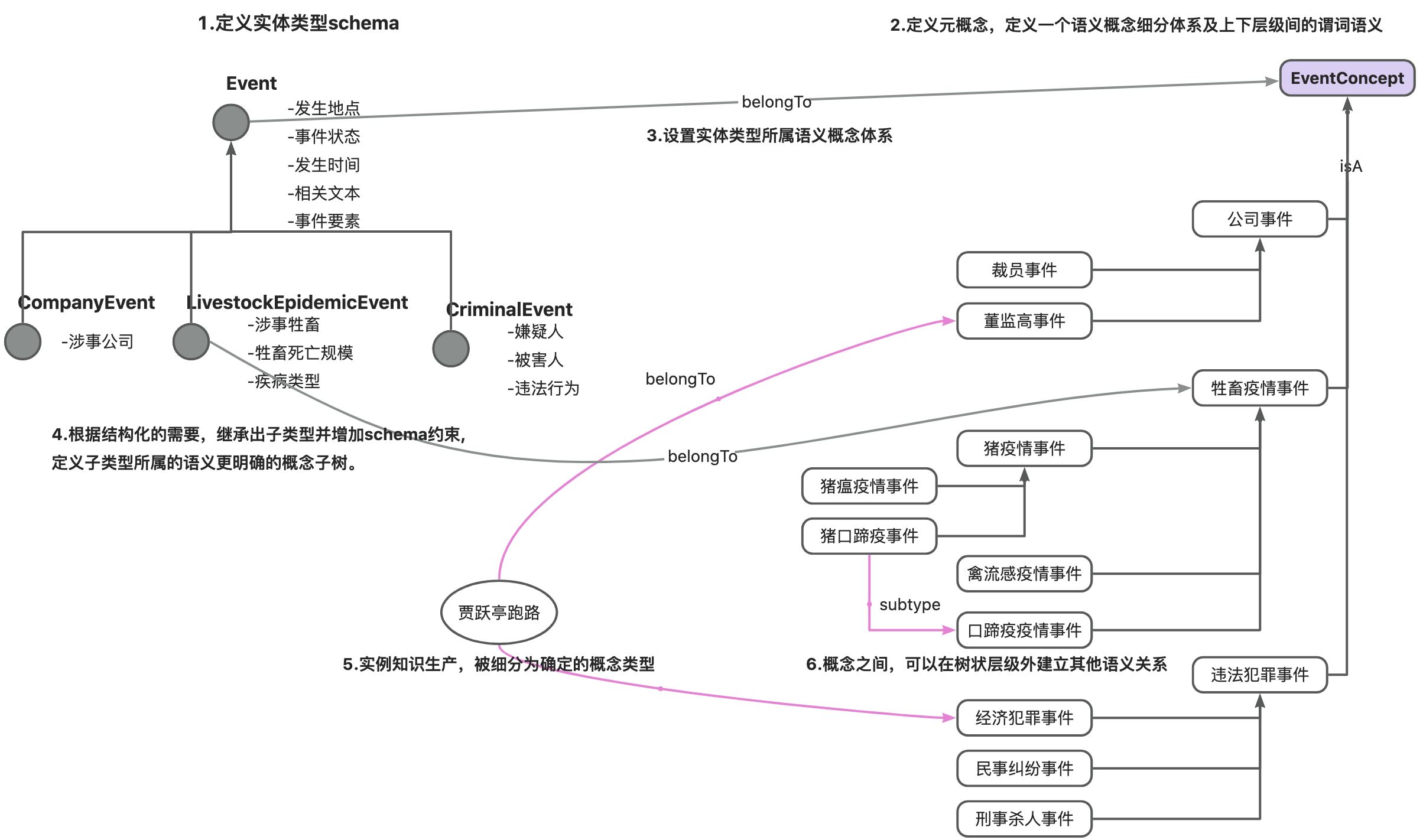
图7 事件概念体系构建及管理
1.定义实体类型schema。
对于事件的结构化表示,先构建一个定义所有事件共有事件要素的schema:Event。
2.建立实体类型对应的概念类型。
实体类型的schema定义,只是对结构化表示的约束。为了体现对实体的语义的认知,用概念建模来定义实体的细分类体系。对于事件的分类体系,定义EventConcept作为概念类型。并在这个概念类型下,类似决策树一样,根据特定场景/业务最重要、最有区分度的特征为度,按照树状层级,细分出细粒度层级的概念。
在概念类型上,可以定义概念的属性,如概念别名等。概念类型上还需要定义该概念体系的谓词,用于解释这颗概念树上下层级概念间的语义关系。一般默认为“isA”,体现上下位关系。但对于行政区划等类目,需要重写为locatedAt等特定谓词,以更明确、恰当的表面概念树的组织形式。
3.为实体类型schema设置专属分类体系。
belongTo是知蛛平台的保留谓词,用于为一个实体类型schema设置专属的概念分类体系。例如,建立Event-belongTo->EventConcept的关系,则定义了Event(及其子类型)的实例,由EventConcept为_Root的概念体系做细分类。
4.schema的结构细化
由于不同事件可能需要抽取和结构化的特有的事件要素,则通过schema的继承,来定义一个子类的事件schema及增加要素定义。如companyEvent增加了“涉事公司”,LivestockEpidemicEvent增加了涉事牲畜、牲畜死亡规模、疾病类型等要素。对于schema上定义的属性,能够进行标准化或概念化的事件要素,属性类型选择为语义类型(需要提前定义概念体系)。
本方案所体现的建模方式是强schema约束(为了便于知识的规范管理)及语义标准化的。当细粒度的分类不涉及事件要素的新增时,则在对应概念体系上增加概念事件来完成对语义的细化。如在图7的概念树上,对牲畜疫情事件,继续细化为猪疫情事件、禽流感疫情事件等。
5.实例生产
实例生产有两种模式:1.非结构化数据:基于schema约束的信息抽取,并将抽取到的信息标准化(依赖实体链指、概念链指)后,对schema定义的实体要素(属性、关系)进行填充,完成实例知识的结构化;2.结构化数据:这类数据一般已经是在odps表中,自身是有schema的,则对odps表和实体类型schema的知识结构映射,完成数据实例化及入图谱。
如图8所示,描述了受schema结构约束和最终语义标准化的事件实例的生产过程推演。
对于图7中“贾跃亭跑路”事件,其schema是CompanyEvent,则在数据结构上,能够建立“贾跃亭跑路-涉事公司->乐视”等事实描述。而对该事件的细分类型,基于算法模型或规则推理,挂载到概念树的1个或多个节点。对于该例,既是一个“经济犯罪事件”又是一个“董监高事件”。
6.语义网络构建
每个概念体系本身是树状结构,但概念之间还可能存在丰富的常识语义关联,概念建模也包含着对常识/领域语义网络的构建。如图7中,在事件概念树上,选择将“猪口蹄疫事件”的上级概念设置为“猪疫情事情”;同时“猪口蹄疫事件”也是一种“口蹄疫事件”,则定义事件概念间的subtype语义关系(与实体关系建模类似的方式),来构建细粒度语义概念与其关联的其他概念间的关系。
图8中,白酒-原料->小麦,白酒-上游产业->粮食,也体现了概念间的常识语义关系建模。
事件生产链路
1.使用一个统一的模型/框架进行所有类型事件的抽取
2.抽取完成,相关事件要素及所属的粗粒度事件类型(schema类型)变成已知
3.拿到schema后,完成抽取的槽位跟schema定义的论元的映射,则该槽位值是实体(及其EntityType)还是概念(及其概念类型)是已知的
4.根据schema映射,进行相关要素的实体链指、挂念挂载
5.完成要素的标化及链指后,用规则谓词推理其belongto的概念事件类型
6.最终完成子图构建(图中围绕实例事件e1、e2及其关联实体、概念组成的子图)
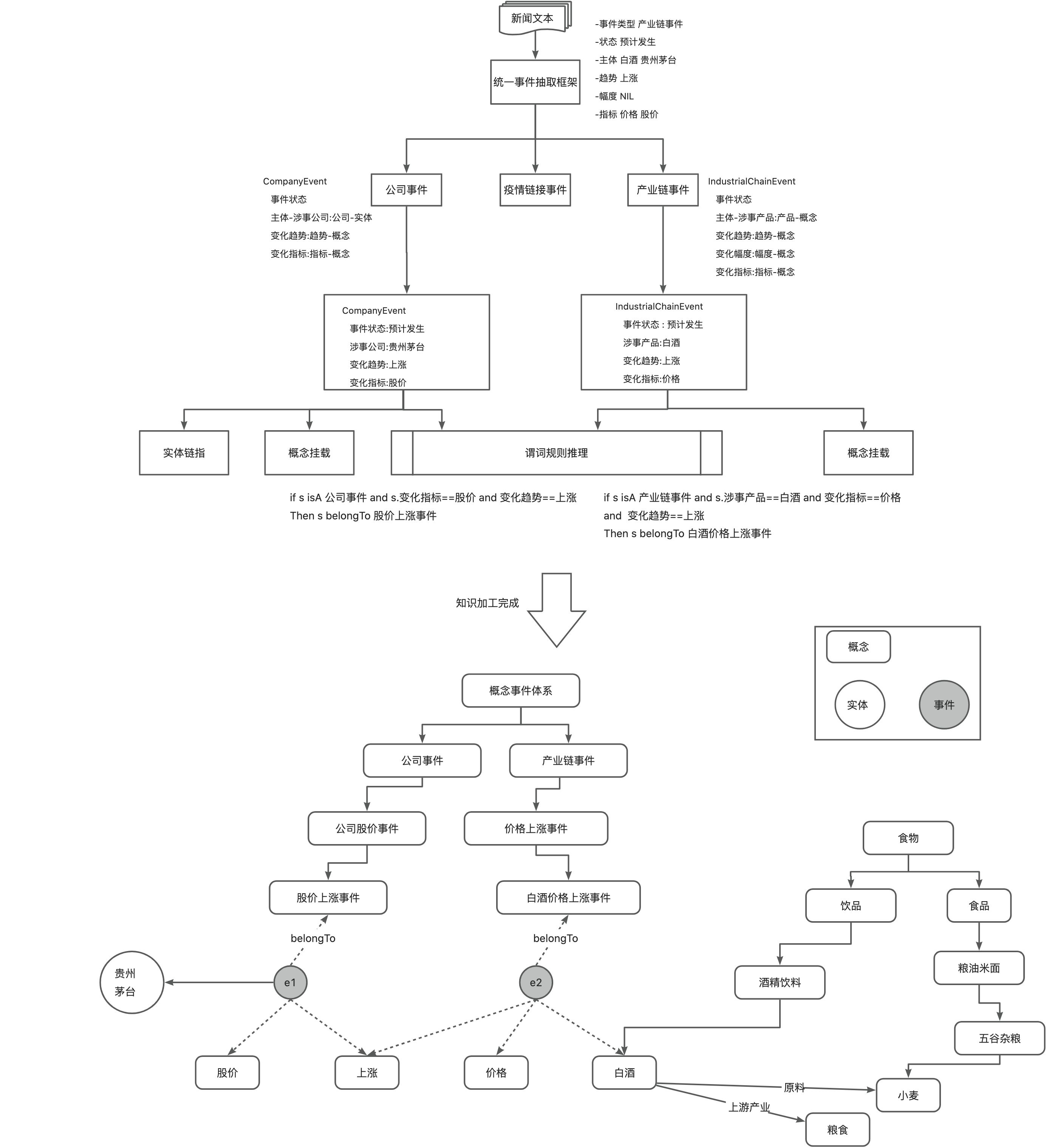
图8 强schema、强语义约束的事件实例生产
通用常识语义建模
基于对蚂蚁内部常见主体及其相关类目、属性字段的分析,并参考百科词条分类体系、Hownet、termtree体系,我们定义了覆盖17个“概念类型”类型的常识知识树的主干框架。
L0-概念类型
对应为实体类型。例子:品牌、术语、事件、组织机构。即一个特定的schema实体类型,对应拥有一个概念类目体系,则L0为该体系的root节点。
L1-概念分型的模式
决定了概念类目细分的方式。这里就像是决策树一样,先选择最有区分度、子概念类型不重合的方向细分。在L1定义的概念,是概念类型在不同纬度、行业、领域、应用场景的类目树的根节点。
L2-类目细分
L2-Ln,为概念类型在确定子领域/场景下的细分。
在蚂蚁常识知识图谱,我们集成了常识知识树、行政区划类目树、MCC2.0、高德POI、意图知识树等蚂蚁域内通用的常识认知体系和领域分类体系,来帮助跨业务的概念类目集成和内容理解。

图9 常识概念建模及应用
保险语义网络建模
保险产品图谱,是为了将保险业务中对保险产品的业务分类类目、领域标准分类、保险产品的各个重要特性建模,并将对每个业务自定义的产品标签概念(如“心血管保障好”)背后关联的产品特性、产品分类的逻辑固化到图谱中,进而使用图谱的路径推理能力帮助具体保险产品实例所属类型的判断。
如图10中,显示了对保险产品的schema定义,业务对“产品渠道”、“保障风险项”、“人群特征”、“产品分类”、“特色保障”等属性都做了语义标准化,即这些属性的取值都受到某个概念类型体系的约束,而这些概念类型体系是业务根据自身领域的各个类目树预先定义的。
图11中,在模式层定义了保险产品schema专属的分类体系——“产品类型”概念类型;在概念层,构建了各个业务概念类目体系及这些概念间的语义关联。最终在实例层,演绎了如何准对一个具体保险产品的语义字段,套用概念语义网络及逻辑规则,实现对实例产品类型的推理。
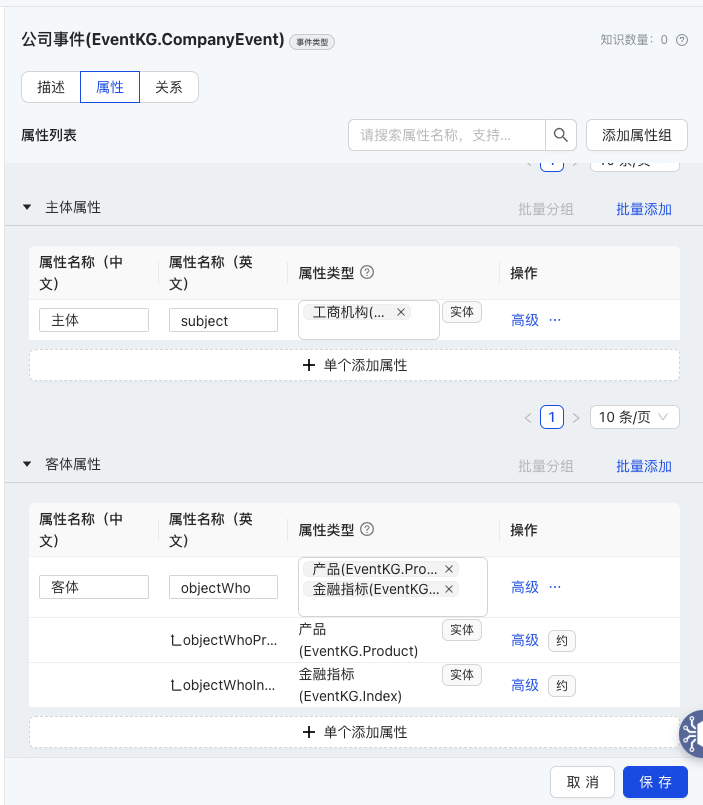

图10 保险产品语义网络构建及应用

图11 保险产品语义网络构建及应用
意图语义网络建模
意图图谱的核心本体主要共包含四类节点(意图,功能词,产品词,义原) 和三类关系(isA,Consist,Has) ,如图所示。具体来说,“意图”描述了用户需求背后的动机,主要由一个功能动词(动词)和一个产品实体(名词)组成动宾结构,例如“打网约车”、“买咖啡”和“维修家电” 等。此外,“功能动词”和“产品实体”可以用更细粒度的Hownet义原表示,拆分为最基本的语义单位,如“movie ticket|电影票 = {coupon|票证, look|看, shows|表演物}”。
构建意图图谱,主要有两个作用:
1.功能词、产品词、义原实体可以丰富意图的语义信息;
2.拥有相同功能词/产品词/义原的意图之间建立起新的关联关系。

图12 意图概念图谱构建及应用
本文主要介绍了在相对静态的事实关联场景下的知识图谱建模实践,分别介绍了实体语义设计和概念语义建模2种建模方式,未来我们还将发布一篇高阶的实践内容。如果你的图谱,涉及对带有时空信息的行为事件的表达,或建模场景下的业务规则、专家经验,需要对所定义“概念”的内涵和外延有计算机可处理可计算的逻辑语义解释,高阶篇中有你所需知道的一切。
 | 作者:袁琳博士****蚂蚁集团高级算法工程师袁琳,蚂蚁集团高级算法工程师,浙江大学计算机应用技术博士。主要研究方向是知识工程,图谱构建。最近一年的工作聚焦于大语言模型与图谱构建的交叉方向,包括基于schema结构和语义的prompt engineering和统一信息抽取大模型的研发。 |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号