RAG是什么?


什么是检索增强生成?
检索增强生成(RAG)是对大型语言模型输出进行优化的方法,使其能够在生成响应之前引用训练数据来源之外的权威知识库。大型语言模型(LLM)通过海量数据进行训练,利用数十亿个参数执行诸如回答问题、语言翻译和生成句子等任务。在已经具备强大功能的LLM基础上,RAG通过扩展其能力,使其能够访问特定领域或企业的内部知识库,而无需重新训练模型。这种方法经济高效,能够有效改进LLM输出,在不同情境下保持相关性、准确性和实用性。
为什么检索增强生成很重要?
LLM 是一项关键的人工智能(AI)技术,为智能聊天机器人和其他自然语言处理(NLP)应用程序提供支持。目标是通过交叉引用权威知识来源,创建能够在各种环境中回答用户问题的机器人。不幸的是,LLM 技术的本质在 LLM 响应中引入了不可预测性。此外,LLM 训练数据是静态的,并引入了其所掌握知识的截止日期。
LLM 面对的已知挑战包括:
- 在没有答案的情况下提供虚假信息。
- 当用户需要特定的当前响应时,提供过时或通用的信息。
- 从非权威来源创建响应。
- 由于术语混淆,不同的培训来源使用相同的术语来谈论不同的事情,因此会产生不准确的响应。
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,却总是充满自信地回答每一个问题。不幸的是,这种不负责任的态度会让用户不信任机器人!
RAG 是解决其中一些挑战的一种方法。它会重定向 LLM,从权威的、预先确定的知识来源中检索相关信息。企业可以更好地控制生成的文本输出,并且用户可以深入了解 LLM 如何生成响应。
检索增强生成有哪些好处?
RAG 技术为企业的生成式人工智能工作带来了很多好处。
经济高效的实施
聊天机器人开发通常从基础模型开始。基础模型(FM)是在广泛的广义和未标记数据上训练的 API 可访问 LLM。针对组织或领域特定信息重新训练 FM 的计算和财务成本很高。RAG 是一种将新数据引入 LLM 的更加经济高效的方法。它使生成式人工智能技术更广泛地获得和使用。
获取当前信息
即使 LLM 的原始训练数据来源适合您的需求,但保持相关性也充满挑战。RAG 允许开发人员为生成模型提供最新的研究、统计数据或新闻。他们可以使用 RAG 将 LLM 直接连接到实时社交媒体提要、新闻网站或其他经常更新的信息来源。然后,LLM 可以向用户提供最新信息。
增强用户信任度
RAG 允许 LLM 通过来源归属来呈现准确的信息。输出可以包括对来源的引文或引用。如果需要进一步说明或更详细的信息,用户也可以自己查找源文档。这可以增加对您的生成式人工智能解决方案的信任和信心。
增加开发人员控制权
借助 RAG,开发人员可以更高效地测试和改进他们的聊天应用程序。他们可以控制和更改 LLM 的信息来源,以适应不断变化的需求或跨职能使用。开发人员还可以将敏感信息的检索限制在不同的授权级别内,并确保 LLM 生成适当的响应。此外,如果 LLM 针对特定问题引用了错误的信息来源,他们还可以进行故障排除并进行修复。企业可以更有信心地实施生成式人工智能技术,将其应用于更广泛的领域。
检索增强生成的工作原理是什么?
在没有 RAG 的情况下,LLM 将接受用户输入并基于其接受的训练信息或已知信息生成响应。引入了 RAG 后,系统加入了一个信息检索组件,该组件通过用户输入首先从新数据源提取信息。用户的查询和相关信息都被提供给 LLM。LLM 利用新获取的知识和其训练数据来生成更为精准的响应。以下各部分将详细介绍该过程。
创建外部数据
LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型(sentence embedding)的 AI 技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
检索相关信息
下一步是执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。例如,一个可以回答人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。由于这些特定文件与员工输入高度相关,它们将被提取出来。相关性的计算和建立是通过数学向量计算和表示法完成的。
增强 LLM 提示
接下来,RAG 模型通过将检索到的相关数据添加到上下文中来增强用户输入(或提示)。在这一步骤中,使用提示工程技术来与LLM进行有效的交互。增强提示使得大型语言模型能够为用户的查询生成更准确的答案。
更新外部数据
下一个问题可能是——如果外部数据过时了怎么办?为了保持检索的信息是最新的,需要异步更新文档并更新文档的嵌入(embedding)表示形式。可以通过自动化的实时流程或定期的批处理来执行这一操作。这是数据分析中一个常见的挑战,可以使用各种数据科学方法来进行变更管理。
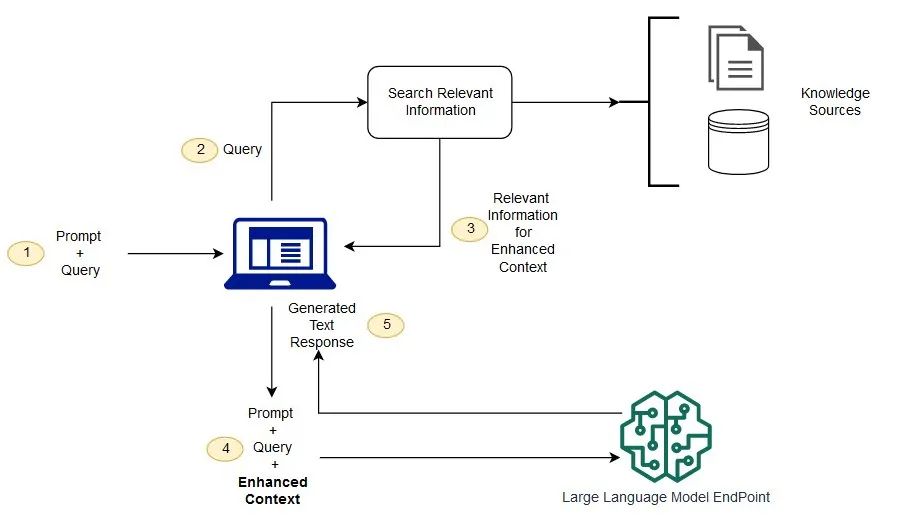
图示:RAG 与 LLM 配合使用的概念流程
检索增强生成和语义搜索有什么区别?
语义搜索可以提高 RAG 结果,适用于想要在其 LLM 应用程序中添加大量外部知识源的组织。现代企业在各种系统中存储大量信息,例如手册、常见问题、研究报告、客户服务指南和人力资源文档存储库等。上下文检索在规模上具有挑战性,因此会降低生成输出质量。
语义搜索技术可以扫描包含不同信息的大型数据库,并更准确地检索数据。例如,他们可以回答诸如 “去年在机械维修上花了多少钱?”之类的问题,方法是将问题映射到相关文档并返回特定文本而不是搜索结果。然后,开发人员可以使用该答案为 LLM 提供更多上下文。
RAG 中的传统或关键字搜索解决方案对知识密集型任务产生的结果有限。开发人员在手动准备数据时还必须处理单词嵌入(word embedding)、文档分块和其他复杂问题。相比之下,语义搜索技术可以完成知识库准备的所有工作,因此开发人员不必这样做。它们还生成语义相关的段落和按相关性排序的标记词,以最大限度地提高 RAG 有效载荷的质量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-08,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号