【他山之石】Stable Diffusion 万字长文详解稳定扩散模型

【他山之石】Stable Diffusion 万字长文详解稳定扩散模型

马上科普尚尚
发布于 2024-03-02 08:47:48
发布于 2024-03-02 08:47:48
1. Stable Diffusion 稳定扩散模型简介
Stable Diffusion 是 Diffusion 扩散模型中最先进的模式( Diffusion 有一些早期版本,比如: 原始Diffusion、Latent Diffusion)。它采用了更加稳定、可控和高效的方法来生成高质量图像。在生成图像的质量、速度和成本上都有显著的进步,因此该模型可以直接在消费级显卡上实现图像生成,可达至少 512*512 像素的图像。最新的 XL 版本可以在 1024*1024 像素的级别上生成可控的图像,生成效率也比以往的 Diffusion 扩散模型提高了30倍。目前 Stable Diffusion 的应用已经不局限于图像生成领域,它还被广泛应用于自然语言处理、音频视频等生成领域。
1.1 Stable Diffusion 发展的历史
Stable Diffusion 这个模型架构是由 Stability AI 公司推于2022年8月由 CompVis、Stability AI 和 LAION 的研究人员在 Latent Diffusion Model 的基础上创建并推出的。其核心技术来源于 AI 视频剪辑技术创业公司 Runway 的首席研究科学家 Patrick Esser,以及慕尼黑大学机器视觉学习组的 Robin Rombach 这两位开发者在计算机视觉大会 CVPR22 上合作发表的潜扩散模型(Latent Diffusion Model)的研究(论文:https://arxiv.org/abs/2112.10752 )。

Patrick Esser(左)、Robin Rombach(右)
而,Latent Diffusion Model 是对早在2015年就提出的原始 Diffusion Model 的革命性升级改造。有关 Diffusion 模型的原始框架可以在这篇文章中详细了解《Diffusion 扩散模型》。
虽然,坊间最近大面积流传着 Stable diffusion 其实是抄袭 Runway 的 Latent diffusion 的代码,并且 Stability AI 的老板 Emad Mostaque 被福布斯扒皮说他学历造假等丑闻,但这一点也没有耽误 Stable diffusion 的持续火爆,并且继续获得大部头的融资。

Stability AI 的老板 Emad Mostaque
至于 Stable diffusion 是否真的抄袭 Latent diffusion 目前尚没有明确的结论,但一个不争的事实是,Stable diffusion 相对于 Latent diffusion 来说进步确实不多,可以说基本都集中在了算力基础大大提升、训练数据大大增加、数据质量大大改善等“大力出奇迹”上,而并非什么架构本质的升级换代。
但,到目前为止,我们使用的 Stable diffusion WebUI 仍然是基于 Stability AI 公司发布的 Stable diffusion 架构。所以,让我们仍然沿用这一称呼“Stable diffusion”来进行讲解。
1.2 “浅空间 Latent Space”的重要性!
Stable diffusion 相比 Latent diffusion 主要有以下几点改进:
- 训练数据:Latent Diffusion 是采用 Laion-400M 数据训练的,而 Stable Diffusion 是在 Laion-2B-en数据集上训练出来的。 “2B-en”是 20 亿个图像及英文对照文本的意思,确切的说是包含 23.2 亿个。明显后者用了更多的训练数据,而且后者还采用了数据筛选来提升样本数据质量,即采用了 Laion-Aesthetic,一个 120M 的训练子集,以专门选择美学评分较高的图像用于文生图任务。
- Text Encoder:Latent Diffusion 采用一个随机初始化的 Transformer 来编码 text(这个 Transformer 就是 GPT 用的那个 Transformer,“GPT”的最后一个字母“T”,我单独写过一篇文章来详细介绍它:《“GPT”到底是什么,三个字母应该怎样翻译!》)。而 Stable Diffusion 采用一个预训练好的 Clip text encoder 来编码 text,预训练的 text model 往往要优于从零开始训练的模型。
- 训练尺寸: Latent Diffusion 是在 256x256 分辨率数据集上训练,而 Stable Diffusion 是先在256x256分辨率上预训练,然后再在 512x512 分辨率上微调优化的,而现在 XL 版本则采用了 Laion-High-Resolution 训练集,一个规模为 170M,图像分辨率大于 1024 的高分辨率训练子集,用于超分辨率任务。
可以看出来,改进确实不是特别大。其中一个最重要的核心“Latent”并没有被改变,还一直被 Stable Diffusion 所沿用着,那么这个“Latent”到底是什么意思呢。可以说 Latent Diffusion 是 Stable Diffusion 的鼻祖,因为它首次采用了“浅空间 Latent Space”中高效处理数据的方法,解决了原始 Diffusion 模型效率低下的问题。它内部的 U-Net 网络是在“潜空间”的低维度中进行运算的,这极大地降低了内存消耗和计算的复杂度。例如,一个 512*512 像素的照片图像,数据表达为(3,512,512),即 RGB 三通道 *512*512 像素的图像数据规模,数据体积在 786432 之上。而在潜空间中则会被压缩成(4,64,64),数据体积为 16384,内存消耗将会减少到原来的 64 分之 1。这个给模型的运行带来了极大的高效性与普及性。Stable Diffusion 自然也继承了 Latent Diffusion 的这个核心优势。(有关“浅空间 Latent Space”的具体讲解,请参考此篇:《到底什么是“Latent Space 潜空间”?》)
接下来,我们将部分参考几位技术大牛对 Stable Diffusion 的文章内容,尤其是 Jay Alammar 在其博客上针对 Stable Diffusion 解构所配的十分简明扼要的拓扑图来讲解。

Jay Alammar 的博客账户
2. Stable Diffusion 稳定扩散模型详细结构
Stable Diffusion 稳定扩散模型可以被应用在许多领域,但在 AIGC 设计领域,我们仅关注它的两个主要方面:
第一个是文生图(text2img)。下图展示了一套文本和对应生成的图像。这套文本就是 Prompt 提示词: paradise cosmic beach。

提示词“paradise cosmic beach”通过Stable Diffusion 模型生成对应图像
第二个是改变图片。很明显,改变图片需要的是输入一张图片,还有用来改变图片的提示词。对应的例子是在原有图像上+提示词:Pirate ship,生成一张变化的图。

在原有图像上+提示词:“Pirate ship”,生成一张变化的图
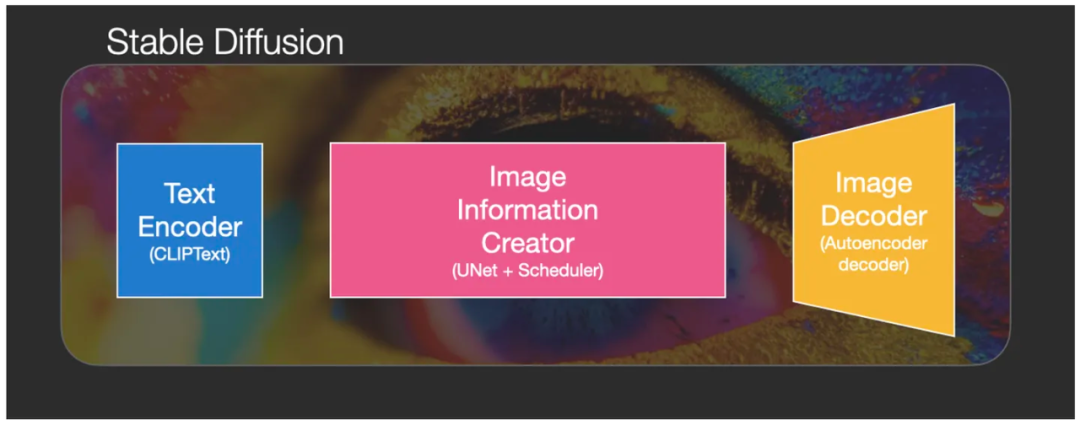
其实 Stable Diffusion 本身并不是一个模型,而是一个由多个模块和模型组成的系统架构,它由三大核心部件组成,每个组件都是一个神经网络系统,也称为三大基础模型:
1. CLIPText 用于文本编码,使文本数字化:
- Input:输入文本(提示词 Prompt);
- Output:77 token embeddings vectors,每个 token 向量有 768 个维度;
2. U-Net + Scheduler 用于逐步处理/扩散被转化到潜空间中的信息:
- Input:文本嵌入和由噪点组成的起始多维矩阵(是一种结构化的数字列表,也称为张量 Tensor);
- Output:处理后的信息矩阵;
3. AutoEncoder Decoder (主要是一个VAE:Variational AutoEncoder )使用处理后的信息矩阵解码绘制出最终图像,把潜空间的运算结果解码成实际图片维度:
- Input:处理后的信息矩阵,维度:4, 64, 64;
- Output:生成的图像,维度:3, 512, 512 即 RGB三个通道、和两维像素尺寸。
2.1 CLIPText 文本编码器
首先,让我们看一下 CLIPText,它是一个内涵编码器的文本理解组件( Text Understander 图中蓝色模块),它将文本信息转换为用数字表达的信息,以便让机器能够理解提示词文本的语义。

文本理解组件 Text Understander (蓝色模块)本质上是一个编码器 Encoder
这个文本理解组件如果按照技术结构组成来说,可以理解为一个文本编码器(Encoder),它是一个特殊的 Transformer 语言模型(技术术语: CLIP 模型的 Text Encoder 文本编码器)。它的输入是文本,输出则为数字表达的矩阵,即用 Embedding 的方式来表达提示词中的一连串文本中的每个 token,每个 token 对应一组 Embedding 向量,一连串的 token 组合到一起就形成了一个 Embedding 的矩阵,下图中蓝色网格来表示这个“矩阵”)。
(token 是词元的意思,是最小的语义单位,通常每个 token 对应一个向量,具体参考此篇来详细了解 token:《在机器学习领域“token”到底是什么意思?》。Embedding 则为对 token 的进一步编码,通常为一组向量。)

Text Encoder 将提示词转化为以 Embedding 矩阵
然后,这些信息输入给由若干模块组成的图像生成器(Image Generator 图中粉色黄色模块 ) 。
这个图像生成器进一步拆解如下:
2.2 Image information creator 图像信息创建器
这个模块就是 Stable Diffusion 稳定扩散架构的核心武器,是它比以前的 Diffusion 版本能够获得更多性能提升的地方。此组件反复迭代运行多步(Steps)来生成图像信息。Steps 数值通常默认为 50 或 100。 图像信息创建器完全在“潜在空间”中工作,这使得它比以前在像素空间中工作的效率提高了64倍。从技术上讲,这个组件由一个 U-Net 神经网络和一个调度算法组成。 在这个图像信息创建器组件中,信息的运行方式是一个逐层处理迭代处理的过程。处理完毕后,将数据传输给下一个模块——图像解码器(Image Decoder)来生成最终的图像。
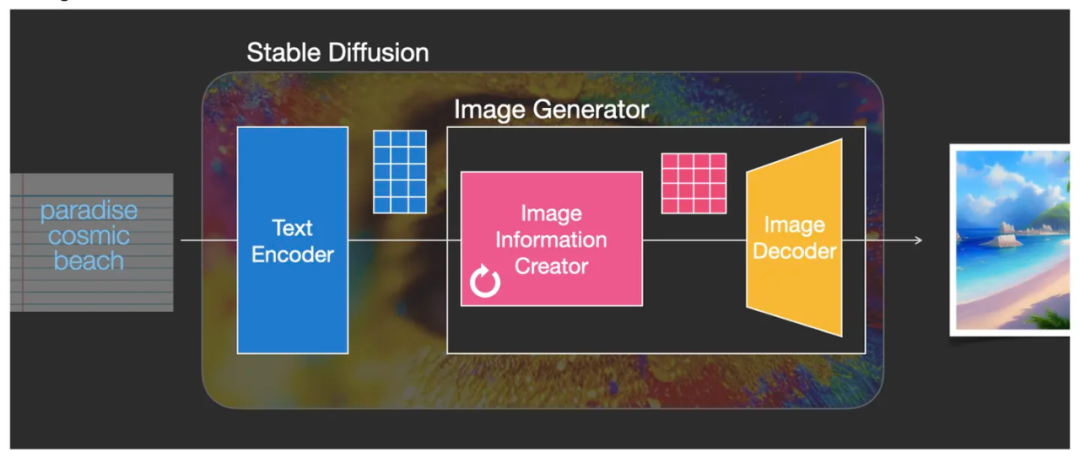
Image information creator 中 Image Generator 处理生成图像的数据,然后输出给 Image Decoder 生成最终图像
2.3 Image Decoder 图像解码器
图像解码器,实际上是一个 AutoEncoder Decoder 自动编码器(主要是一个VAE:Variational AutoEncoder ),它根据从图像信息创建器传递过来的信息绘制图像。它只在之前的 Diffusion 过程完全结束后才运行一次,即把潜空间中的图像信息解码生成最终的像素图像。(对“浅空间 Latent Space”不属性的朋友,可以请参考此篇详细了解:《到底什么是“Latent Space 潜空间”?》)
AutoEncoder Decoder (黄色模块)负责将潜空间中的图像信息解码成真实的像素图像
小结一下上面的内容,构成 Stable Diffusion 的三个主要组件 CLIPText 用于文本编码(Text Encoder)、U-Net 用于处理潜空间中的图像信息(Diffusion的实际运行过程)、AutoEncoder Decoder 自动编码器使用处理后的信息解码绘制出最终图像。

三个主要组件 CLIPText、U-Net、AutoEncoder Decoder
要继续往下进一步解构,我们首先要详细了解一下,到底“Diffusion 扩散”是怎样运行的?
3. “Diffusion 扩散”到底是怎样进行的?
实际上我们经常说的“Diffusion 扩散”过程并不是 Diffusion 模型的生图过程,而它的反向过程,即反扩散过程,才是真正的生图过程,下面会详细讲解。
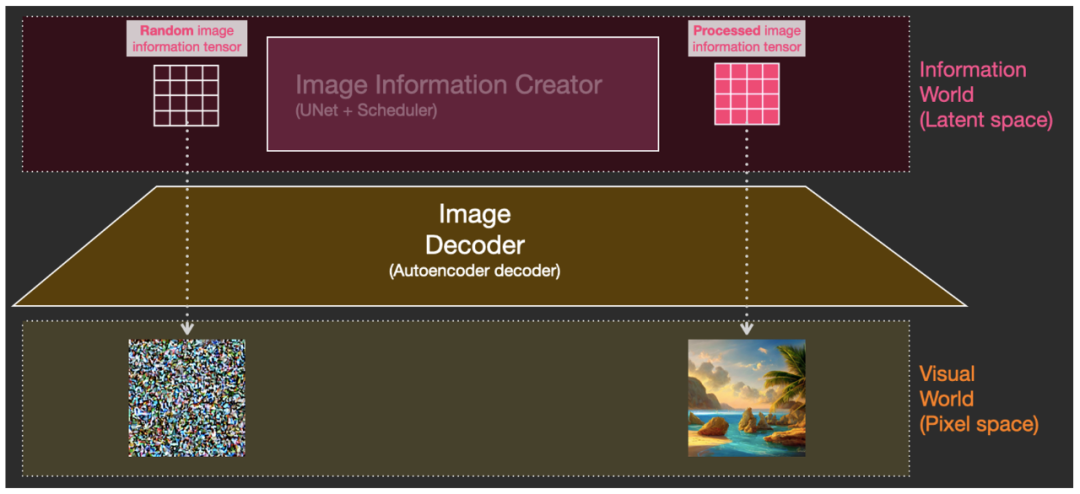
生图的过程发生在图中粉红色的部分,即图像信息创建器(Image Information Creator)组件中。这部分同时包含了两个输入,见下图:①从文本编码器( CLIPText模型)输出过来的 Token embeddings 矩阵(图中蓝色网格),和②随机的初始化图像信息矩阵,即潜空间的噪点图(图中透明网格),然后经过图像信息创建器(Image Information Creator)处理后输出③处理过的潜空间图像信息矩阵(图中粉色网格),最终交给图像解码器来绘制成图像。

①Token embeddings 矩阵输入,②随机的初始化图像信息矩阵输入,输出为③处理过的潜空间图像信息矩阵
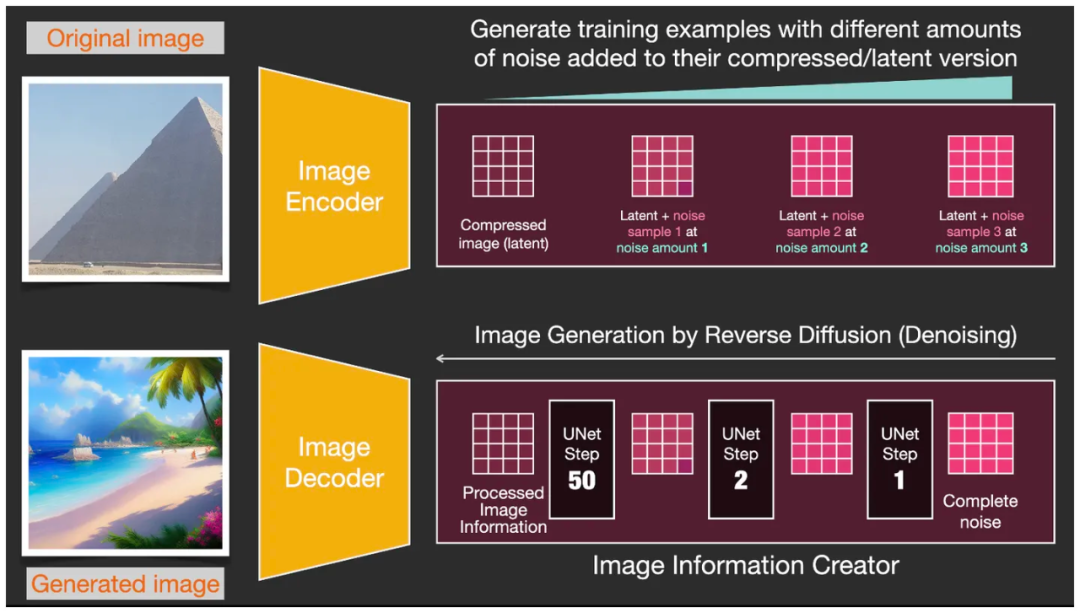
输入① ②,再输出 ③,这些步骤不是一次性完成的,而是一个反复迭代多次的进程 ,每一次迭代都会去掉部分噪点并添加更多与目标图片相关的信息。这便是“Diffusion 扩散”的反向生图过程。
这个噪点到底是什么意思,稍后会详细介绍。总之,你只要记住,“Diffusion 扩散”的反向生图过程,就是将一个全是噪点的图,一层一层地去噪点,最后生出图像的过程,即可。
在实际模型运行过程中,可以在每一次迭代步骤后添加一个检查点,以查看图像中的噪点被逐渐去除的效果。我们在使用 Stable Diffusion WebUI 软件时能够看到,每过一段时间预览窗口中就会生成出一个中间步骤的图像,这个图像从模糊逐渐变得清晰,就是源于这些检查点给出的不同阶段的图像。
在模型运行过程中,可以插入检查点以监控每一次迭代步骤后的图像状态
当“Diffusion 扩散”的反向生图过程发生时,每迭代一步就引入一个 U-Net 预测噪点矩阵,并用之前一步包含噪点的图片减去这个预测噪点矩阵,产生一个“更接近结果”的、噪点更少的图片。50或100步迭代后,便最终生成出了结果,一个不带任何噪点的图片从潜空间矩阵中被解码出来。
所谓“更接近结果”的意思就是,这个图片更接近预先训练好的大模型中抽取出的所有与输入文本语义相关的图像在潜空间中的表达。
这样讲肯定还是让人感觉一头雾水,主要是这个逐步去噪点的过程很难用一两句话就讲清楚,接下来下面我们详细地展开这部分。
下面进一步解释“Diffusion 扩散”的反向生图过程:
下图我们可以看出,CLIP 文本语义的矩阵(图中蓝色网格)和 Diffusion 扩散模型中 U-Net 各个模块的预测噪点矩阵给 Diffusion 的多次迭代过程提供了不断校准图像信息的能力。
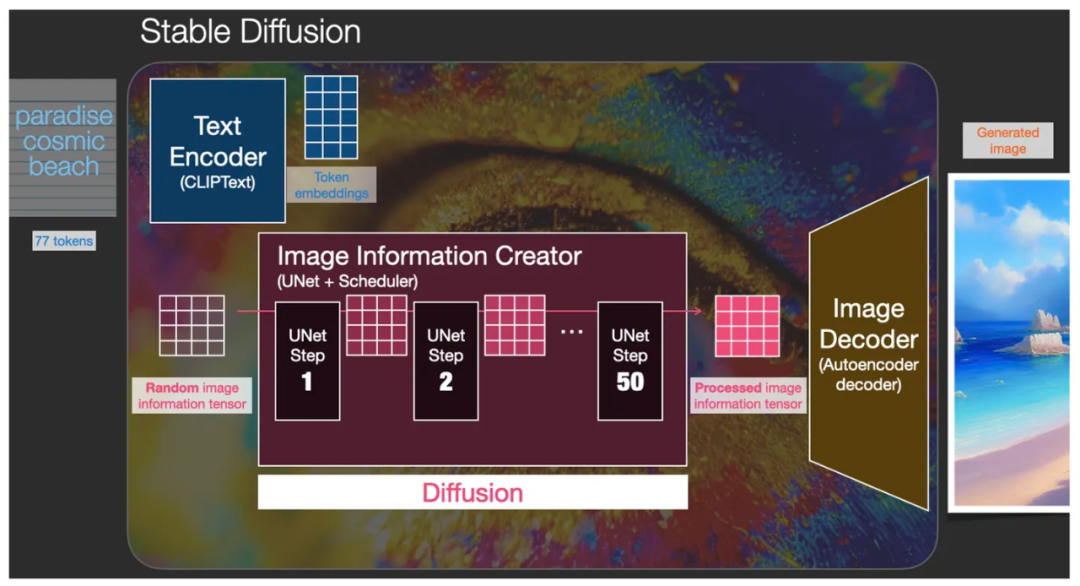
Image Information Creator 模块内部是至少是 50 个U-Net 组成的迭代串联模块组合
如刚才所说,我们可以在某一次迭代步骤之后放置一个检查点,检查一下这些矩阵的运行情况,看看降噪点的过程进展到了什么程度。比如在第 1、2、4、5、10、30、50 步后查看,就会发现,它呈现如下图中的状态。
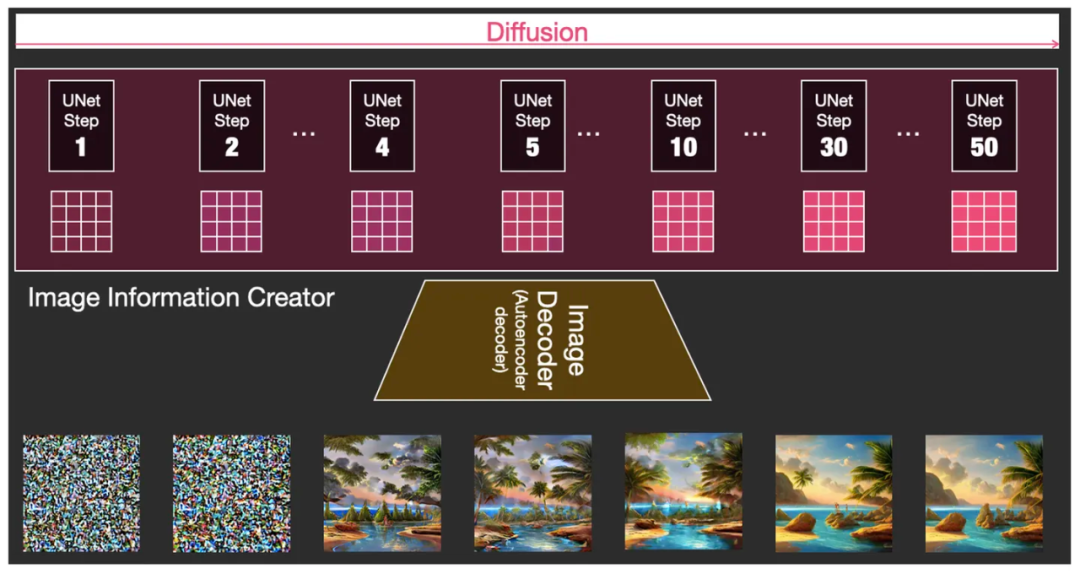
50步中取 1、2、4、5、10、30、50 步后放置检查点,查看运行中的效果
这就是 Diffusion 的反向生图过程(Reverse Diffusion Process)(这一过程的详细技术解读,可以参考:《Diffusion 扩散模型》) 。而 Diffusion 的前向过程就是模型的预训练过程,通过不断地加噪点去训练模型对每一个阶段噪点的预测能力,以便为日后反向过程中为每一次迭代去噪点阶段提供噪点校准的能力。
3.1 Diffusion 的前向过程(训练过程)
让我们看看前向(训练)阶段具体发生了什么。
如之前所述,Diffusion 扩散模型生成图像(反向过程)的过程中最关键地方是我们事先拥有了一个强大的 U-Net 模型。这个模型预训练的过程可以简述为以下几个步骤。
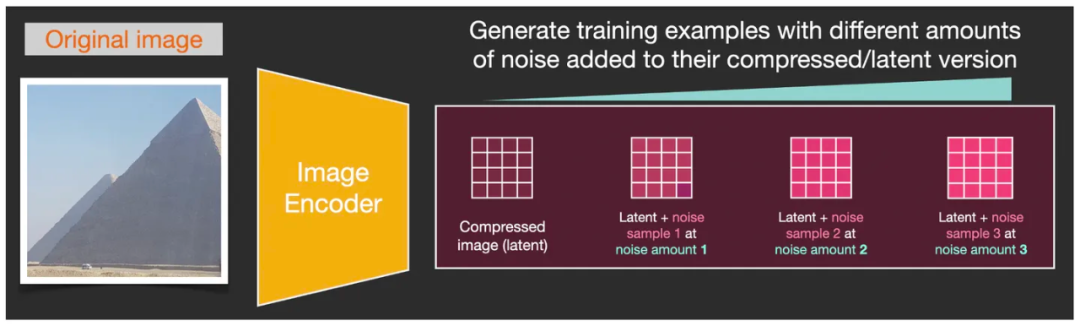
假设我们有了一张照片(下图中1),并额外生成了一些随机噪点(下图中2),然后在若干噪点强度中选择其中某一个强度级别(下图中3),然后将这个特定强度级别的噪点加到图片中(下图中4)。这样,我们就完成了一次典型的样本的训练。(注意,噪点并不是直接在像素维度加到图片上的,而是在潜空间中加到图片的潜空间数据矩阵中的。这里的噪点图只是为了方便大家理解。)

U-Net 的一次典型的样本的训练过程
然而,仅仅一幅图的一次训练是远远不够,我们需要许多许多这样的图来进行多次训练。下图演示了第二次,采用另一张样本图片训练的情况。与第一次训练图片不同的另一张照片(下图中1),另外生成了一些随机噪点(下图中2),然后在若干噪点强度中选择其中某一个强度级别(下图中3),注意第二次和第一次选择的噪点强度级别不同(意为每针对一张训练图像采用的噪点强度为随机,但这个随机的强度被记录了下来)。然后将这个特定强度级别的噪点加到图片中(下图中4)。这样,我们就完成了第二次典型的样本的训练。

U-Net 的另一次典型的样本的训练过程
当然,以上只是简化了噪点强度到4个级别(图中 0、1、2、3,四个噪点级别档位)以方便理解。在实际训练过程中,我们可以做到把噪点细分为几十个强度级别,以便我们为单一一张图片就可以进行几十次的不同噪点强度的训练,然后再对不同的图进行同样的训练。最终这些图像和不同阶段的噪点训练样本就汇聚成了一个巨大的训练数据集。
Input 数据集为大量不同噪点强度级别的图像,Output(Label 标注结果)数据集为大量不同的纯噪点图。然后输入给 Diffusion 中的 U-Net 模型进行监督学习(监督学习可以通过此篇来了解:《监督学习、无监督学习、半监督学习、强化学习、自监督学习》),以完成对 U-Net 的模型训练。
这样的图片数据集对于 Stable Diffusion 的基础大模型训练来说需要多少呢,之前讲过,有 23 亿图文对之多!

Input 数据集为大量不同噪点强度级别的图像,Output(Label 标注结果)数据集为大量不同的纯噪点图,以对U-Net进行训练(监督学习)
这个数据集训练要想成功,它的体量必须做到十分巨大,以便可以应付我们对 Diffusion 生图的各种要求。对于Stable Diffusion 的基础大模型来说,V1.5 版本的模型时在几百个英伟达 Nvidia A100 GPU 上,用了23亿张图片来训练,这些图片基本是 512*512 像素的分辨率,耗时几十万个 GPU 小时训练出来。
而最新的 XL 版本则用了几倍于 V1.5 规模的样本图片数,以及每张 1024*1024 的分辨率。几十亿到百亿规模,如此巨大的训练数量,意味着 Stable Diffusion 阅览并记住了人类文明走到今天累计最多的图像数据,且都是每一张图都是有文本解释标注的。所以,这也是 Stable Diffusion 能够印象派地生成出任何你想要的图像的根本原因。
在如此巨大的数据集上训练出的强大的噪点预测器 U-Net ,便有“能力”在 Diffusion 的反向生图过程中,将噪点图逐步迭代去噪,转化为一张完美的图像。
我们进一步细化解构 U-Net 的训练过程:
下图中①第一步,从庞大的数据集中选择一个训练样本,通常为某一个噪点强度级别下的图像样本。②第二步,通过 U-Net 预测该噪点和噪点级别。③第三步,与实际图片中的噪点做对比。④第四步,反馈给 U-Net 第三步中的噪点对比差异。以便让 U-Net 调整参数后提高预测能力。这是一种典型的“监督学习”过程!
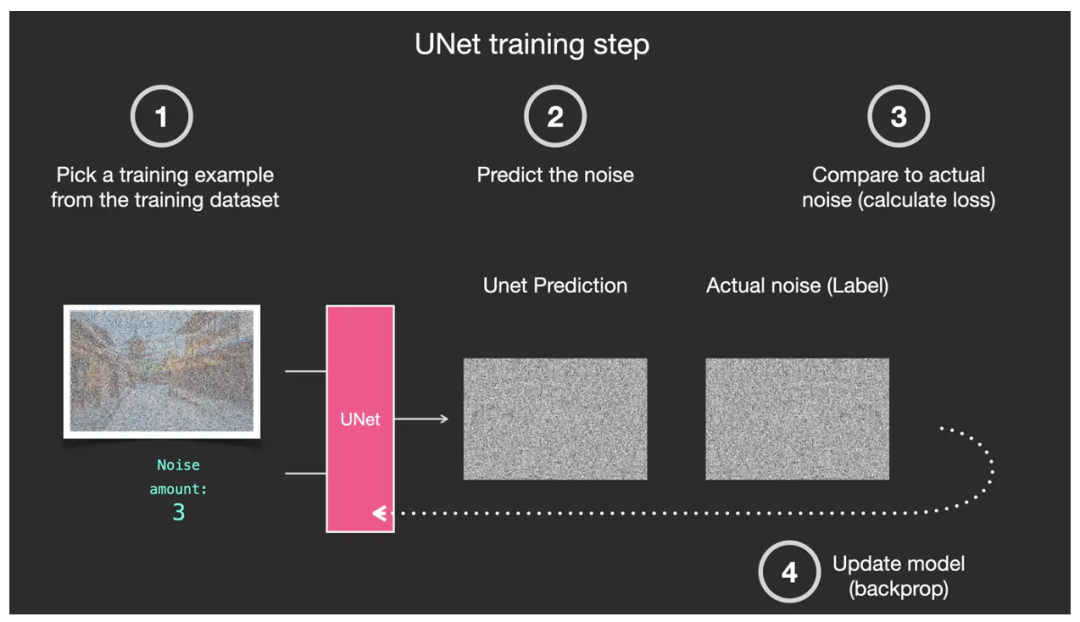
U-Net 的典型监督学习过程——预测图像中的噪点
下面再看看,Diffusion 的反向过程(图片生成过程)中,具体发生了什么。
3.2 Diffusion 的反向过程(生成过程)
反向过程就是通过一个全是噪点的潜空间图像,一步一步迭代地去除噪点来生成图像。经过训练的噪点预测器 U-Net 可以预测噪点和该噪点所处的强度级别(Noise amount),那么这个 U-Net 就有能力移除这些噪点,以生成每一步迭代的结果,即含有更少噪点的图像,直至最后生成不含噪点的完美的图像。
经过海量数据集训练的U-Net可以预测噪点和噪点强度,并去除噪点
进一步详细解释这一过程:
我们用之前给出的简化例子中的最大级别噪点(Noise amount=3)来作为最开始的第一步。那么此时输入一个全噪点图(下图中最下册是全噪点图), U-Net 就可以给出噪点和噪点级别(下图中红框圈起来的噪点),并从输入的噪点图中去除这一部分噪点,使之变为更少一点噪点的图(下图中最左侧 Slightly de-nosied Image)。
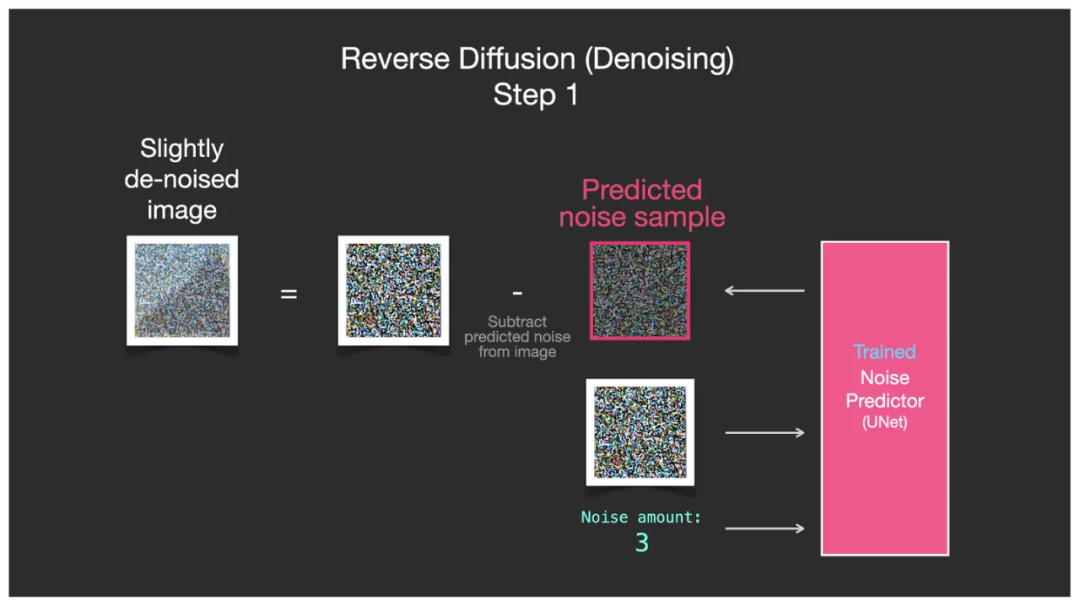
U-Net 的一次去噪点过程
然后再重复这一过程,每次都去除一个级别的噪点,一个全噪点图像就被一层一层地去噪点成为一个无噪点的、只有图像内容的图片了。(在实际的运行过程中,不可能只像这些简化流程图中仅有四步迭代,而是最起码有50步,高达100步。)
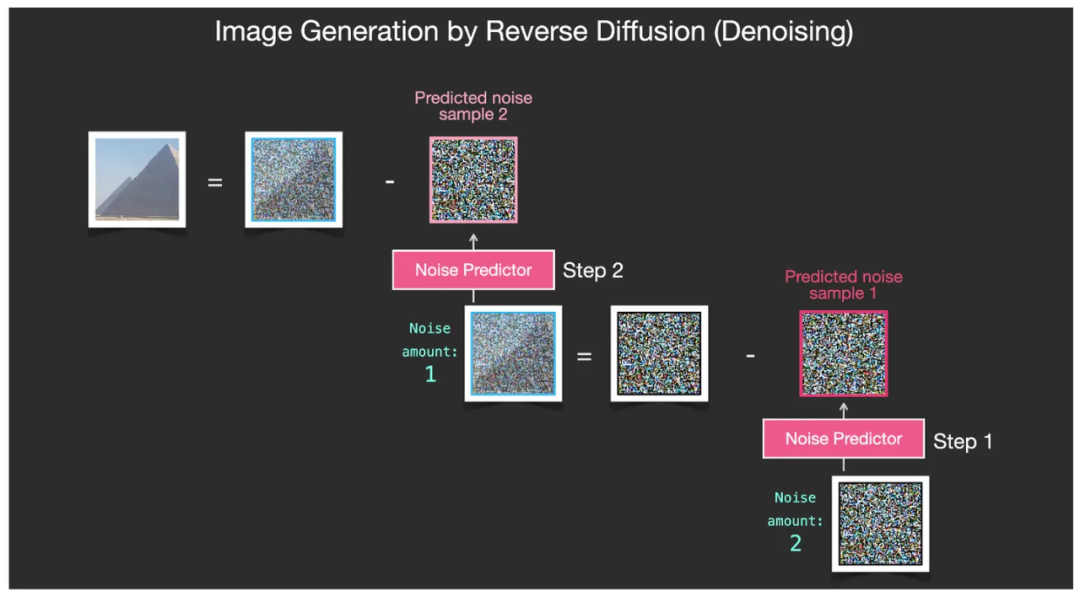
剩下的去噪点步骤,逐步走完,最终生成出一张无噪点的图像
每一步都会减去一个 U-Net 网络预测出来的某一个强度级别的噪点,所以我们便能意识到,图片最终呈现出来的内容和风格,完全是取决于 U-Net 网络当初在训练阶段固化下来的风格。每一个强度级别的噪点都和当初 U-Net 被训练时的样本图片在潜空间中有数据结构上的相似度,这便是风格迁移能够成功的关键。
请记住这个重要的概念:风格迁移!
当我们从噪点图像中去除一部分噪点后,得到的图像更接近于之前在训练阶段(前向过程)输入给大模型的训练样本图像。但是又不是 100% 等同于原样本的图像,而是与原样本图像同时符合潜空间中一定数据结构分布规律的图像,即风格极为类似的图像,这就是“风格迁移”。
3.3 AI 绘画的 “风格迁移”的进一步解释及其意义
这就好比我们人类的艺术家在画画时多多少少都会受到之前鉴赏过的其他画作影响,或收到他看到的大自然的景象的影响。这世界上,没有一个艺术家是从一出生就是瞎子情况下,在没有任何视觉积累的情况下就能画出画作的。
当艺术家看过成千上万张画作之后,他的大脑也如 Stable Diffusion 模型一样被训练过了,然后便能根据自己内心的指令,创作出一幅新的画出来。这样的风格迁移,对于人类、对于AI来说都是异曲同工的。
风格迁移,无法用公式去解释,就好比我们同样无法用公式解释艺术家大脑里的每一个神经元是怎样运作的一样。但我们却可以解释风格迁移的逻辑结构。
比如,拿真实场景的照片来说,不同的照片中都是暗含了某些规律的,这些规律是符合真实世界中天空的颜色为蓝色,人有两只眼睛,猫有尖耳朵等等这些规律的,所以生成的具体图像风格也自然取决于该模型受到的训练数据集中这些照片的潜在规律。比如对下面这幅图的标注,人类大多数会按照人类自己的语言认知标准去给该图片打出各种标签,比如:马、草地、棕色、树林...等等。但实际上这幅图像上有更多更广阔的与马相关联的有价值的信息,比如:马站在草地上面而不是在草地下面、马的头部和尾部分别在身体的前后两端,之所以是马而不是大象是因为马的耳朵眼睛鼻子嘴巴的比例是这样的、马的身体比例是这样的...等等等等,在数以千万计的马站在大自然环境中的照片进行集中机器学习时(几十万个训练集图片),甚至有很多我们人类绞尽脑汁也难以发觉得更潜在的隐藏规律都可能被 AI 挖掘出来。正因为这些种种的规律组合到了一起,才使得所有马的信息在“潜空间 Latent Space”中集中在一了起,称为了某种数据结构。

这样带来的好处显而易见,一来这样的隐藏规律的寻找对于人类来说是无法企及的,因为太多了。一副图像中的各种元素之间排列组合出的各种逻辑过于繁杂,况且逻辑关系也过于隐蔽,并且对于不同的人来说还很因人而异得出结果。二来,这有点像道德经上所讲的“道可道非常道,名可名非常名”的道理,一旦你给一个事物命名了,那么你就相当于给他标签化了,而一旦标签化,就很容易以偏概全,无法达到事物本来的真理层面。与其用人类有限的语言的文字去打标签,不如直接用更印象派的数据结果方式去记录所有规律的总和。
哪怕是想手写数字这样的最简单的图像,通过 VAE 转化成潜空间的可视化数据结构,也可以让人看出来,拥有不少的规律在其中。
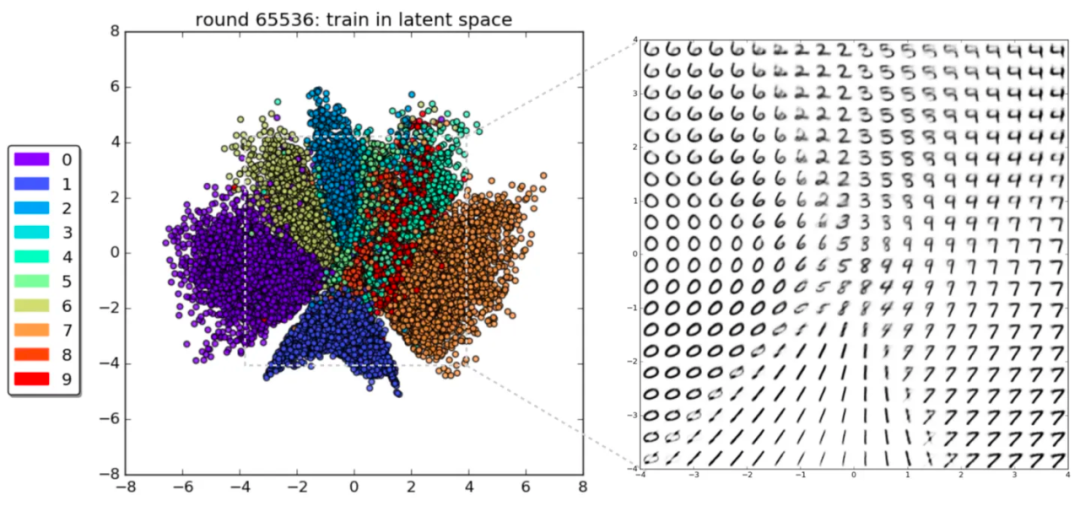
MNIST 手写数字数据集的 VAE 潜空间示意图
通过VAE模型65000多次的学习,可以看到它已经可以把0~9的手写数字在潜空间中区分开来了,并且它把这些数字通过某种规律展示在了一个 2D 空间之中,展示为某种空间中的规律排布。
简单的手写数字尚且如此,那么数万张马的照片将呈现超级复杂的潜空间结构!
那么“风格迁移”就是在如此复杂的潜空间结构中找到普遍的规律,并根据输入反向生成图像。这种反向生成图像可以用下面这两张图来做一个简单的示意。假如你训练的是三角、圆和正方形,那么“同时符合潜空间中一定数值规律分布的图像”这句话的意思就是采样后生成出来的图形是一个介乎于三角、圆和正方形之间的图像(下图左侧箭头所指),基本融合了三个形状的特征。如果采样点足够多,还会发现更多的中间状态的图形,这些图形都遵循着某些“风格迁移”的数据规律。
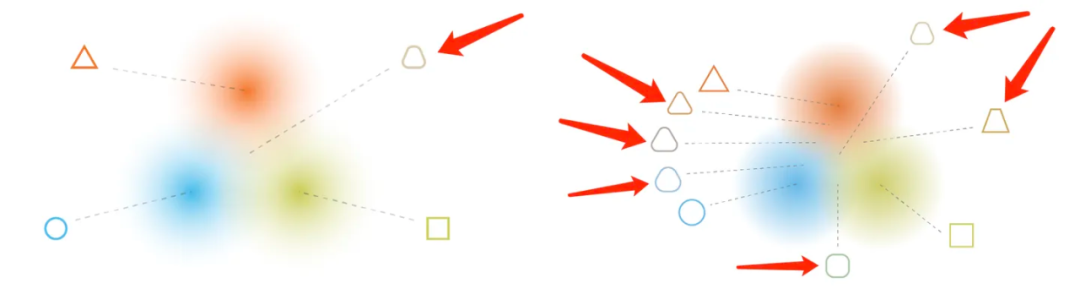
训练集为三角形、圆形、正方形,红色箭头所指为模型生成图像的采样点,根据采样点的不同取点位置,生成的图形遵循着某种变化规律
至此,我们用简化的流程图和语言讲述了 Diffusion 模型的运作机制,在 Diffusion 中主要讲述的是 U-Net 作为噪点预测机制在训练和生图过程中起到的作用。但这只是 Stable Diffusion 三大模块中的一个,另两个关键模块是 Clip text 文本编码器和AutoEncoder Decoder 自动编码器。
下面我先讲 AutoEncoder Decoder 自动编码器。
4. AutoEncoder Decoder 自动编码器(图像编码解码器)
上面的介绍中解释过“潜空间 Latent Space”的概念和思维方式(详细了解请参考:到底什么是“Latent Space 潜空间”?)。在下面,我们将结合 Stable Diffusion 的工作流程来看一下 “潜空间” Latent Space 是如何在发挥作用的。
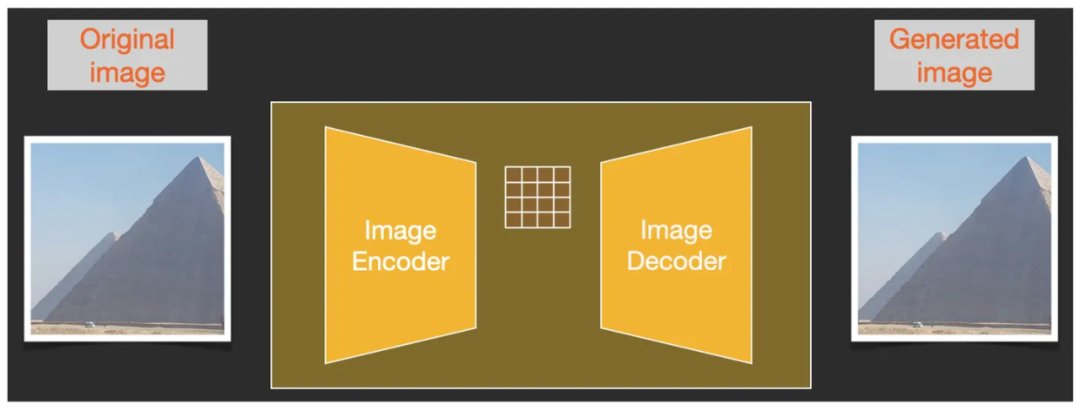
为了找到图片与图片之间潜在的联系与规律,Stable Diffusion 的运行不是在图像本身的像素维度上来进行的,而是在图像的压缩版本即“潜空间”中进行的。这种压缩和解压缩过程是通过 Autoencoder Decoder 自动编码器完成的。
自动编码器中的 Encoder 编码器将图像压缩到潜空间中,然后经过 Diffusion 模型对图像信息的处理后,再把潜空间中的信息交给 Decoder 解码器来重建图像。这个 Autoencoder Decoder 自动编码器其实就是一个VAE,Variational Autoencoder 变分自编码器(之前的课程中我们详细讲过VAE:到底什么是“ VAE 变分自编码器”?)。
黄色网格为潜空间中的噪点矩阵
由于噪点也是以潜空间中的噪点形式存在的,它在上图中用黄色网格来表示,即噪点的向量数据矩阵。因此,噪点预测器 U-Net 实际是被训练用来预测压缩后的潜空间中的噪点数据矩阵的。
U-Net 针对噪点预测,“噪点”也同样是指在潜空间中的噪点
Diffusion 的前向过程是把图片压缩到潜空间中,逐步加噪点矩阵,生成新数据,来训练噪点预测器 U-Net 。一旦它被训练成功,我们便可以利用它通过反向过程来逐步去噪点生成图像。
这两个流程在 LDM/Stable Diffusion 论文的图 3 中进行了更技术性的展示(论文 PDF 地址:https://arxiv.org/abs/2112.10752):
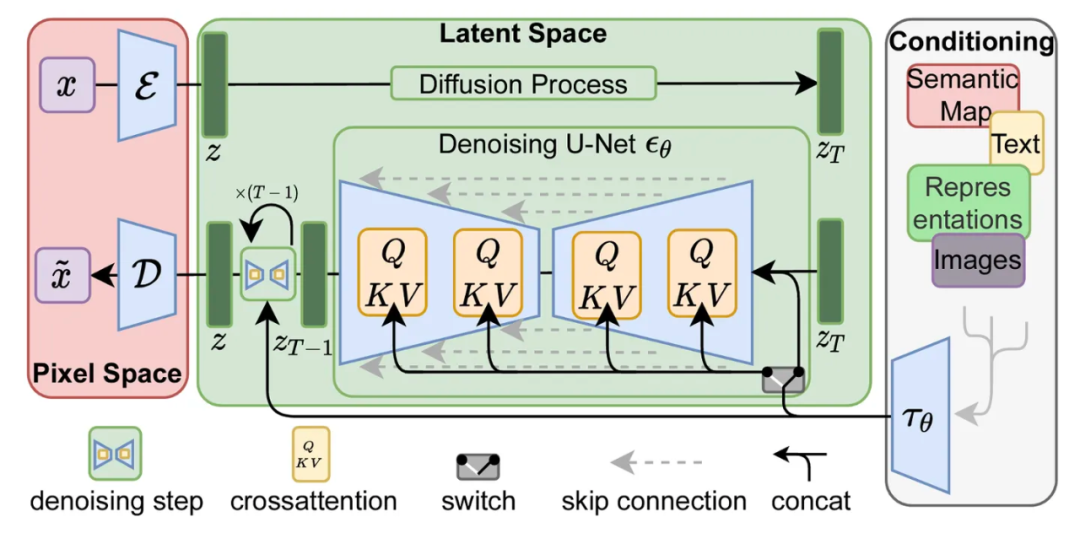
可以看到,此图最右侧还显示了输入“条件”(Conditioning)组件,这就是用来描述所生成的图像的文本提示词的转化组件 Clip text ,让我们解剖一下这个组件 。
5. CLIPText 文本编码器
如果没有 CLIPtext,你就无法用语言(即提示词)输入来控制输出图像的内容含义,Diffusion 将随机生图。所以让我们来介绍 Stable Diffusion 架构中三大模型之一的 CLIPText。
CLIPText 是一个 Text Encoder 文本编码器,就是之前这个图中深蓝色模块,它本身是一个特殊的 Transformer 自然语言模型,它把输入的文本提示词生成下图中 ① 的 Token embeddings 矩阵。embedding 是指将高维度的数据(可以是文字、图片、声音等)映射到低维度空间的过程,其结果也可以称为 embeddings。在 embedding 中,文本(token)以向量数据形式表现,它们可以被理解成某一个维度空间中连续数值的点。在讲解 Transformer 模型时,我们着重讲解过 embedding 这一概念,可以去详细了解一下(参考:《“GPT”到底是什么,三个字母应该怎样翻译!》)。
输入 ① 即为Text Encoder 产生的 Token embeddings 矩阵
早期的 Stable Diffusion 模型使用的是 OpenAI 公司发布的用于 GPT 的经过预先训练的 CLIPText 模型,在 Stable Diffusion V2 版本中则切换到了 2022 年发布的 CLIP 模型的改进变种,更大更好的 OpenCLIP 模型,这类模型都被统称为 CLIP 模型。
CLIP,全称是 Contrastive Language-Image Pre-Training,中文的翻译是:通过语言与图像比对方式进行预训练,可以简称为图文匹配模型,即通过对自然语言理解,和对计算机视觉分析,并最终对语言和图像之间的一一对应关系进行比对训练,然后产生一个预训练的模型,以便能为日后有文本参与的生成图像的任务所使用。比如把狗的所有相关的图像和“狗”这个词匹配起来。
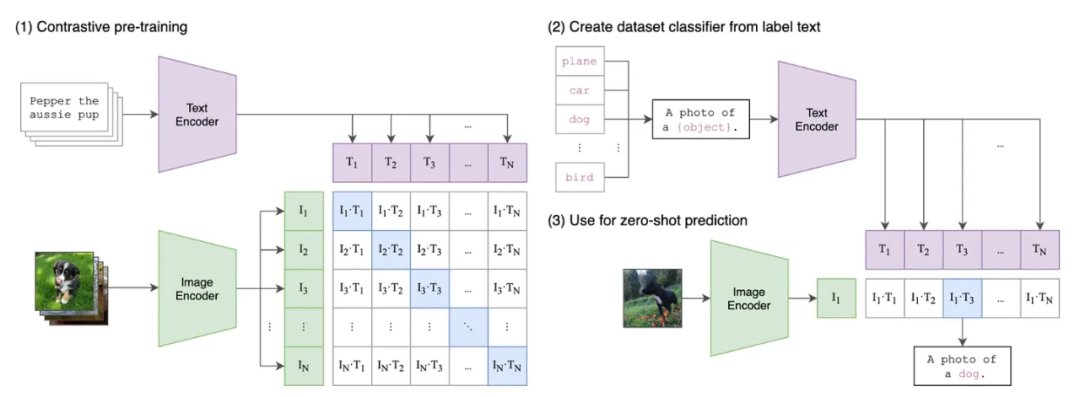
CLIP 的模型架构:左图为模型训练阶段,右图为模型输出阶段
CLIP 本身也是一个神经网络,它将 Text Encoder 从文本中提取的语义特征和 Image Encoder 从图像中提取的图像特征进行匹配训练,即不断调整两个模型内部参数, 使得模型分别输出的文字特征值和图像特征值能让对应的“文字-图像”经过简单验证确认匹配。
可以说 CLIP 的训练方式也是一种大力出奇迹的过程。起初,它搜刮了广泛分布于互联网上的 4 亿个“文本-图像”对进行训练!通过天量的数据,再砸入让人咂舌的昂贵训练硬件与时间,终于修成正果。
这样的训练方式简单直接,但效果出奇地好。研究人员发现在后续处理环节中,用来生成图像的 Diffusion 与表示的文本数据的 CLIP 可以非常好地协同工作,这也是为什么 Stable Diffusion 选择 CLIP 作为其图像生成方面的三大基础模型之一的原因。( Stable Diffusion 的三大基础模型为 CLIP、Diffusion、VAE )
既然是神经网络,CLIP 也同样有若干层,也是一种深度学习网络。我们现在已经知道神经网络的第一层(下图中layer0)是输入层,它把“dog”的Token数值通过阈值与权重的计算后的结果输出给第二层(下图中layer1),然后再由第二层做类似的运算再输入给下一层,直至最后到第十二层,即输出层进行输出。虽然大体上的运算方式类似,但是层与层之间的区别在于这些阈值和连接神经元的权重数值不同,这些不同是早先 CLIP 在预训练阶段就固化下来的特有数据,即 CLIP 模型。因此,如果数据在未跑完全部12个层时提前出来,输出给 Diffusion 扩散模型用于生图,则意味着用该数据生成的图像也会有区别。
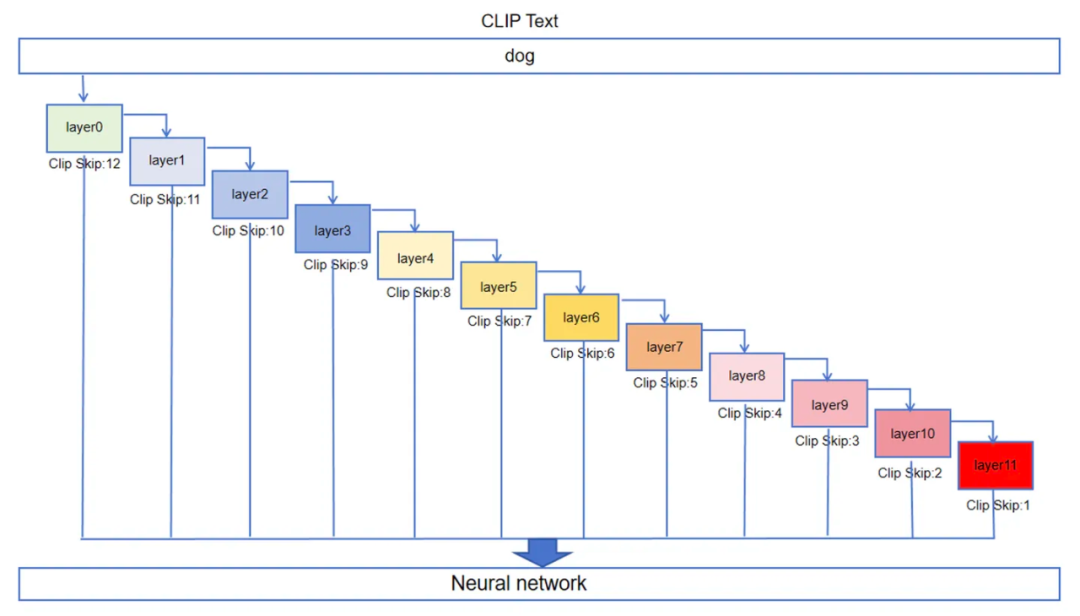
CLIP Text 模型架构图
在 Stable Diffusion WebUI 软件中有一个 CLIP Skip 参数调节滑块,可以在 1 至 12 的档位之间进行调节。12个调节档位代表了 CLIP 神经网络的 12 个层中我们期望 CLIP 运算停止在倒数第几层然后输出结果给 Diffusion 扩散模型用于图片生成运算的意思。比如滑块设置到 2,那就意味着 CLIP 运算到倒数第二层(上图中为 layer10,因为是 layer0 为起始输入层的即第一层)直接输出,从而放弃了传导至第十二层再输出的步骤。这样导致的结果是输出给 Diffusion 扩散模型的文本比对数据含有一些信息噪点,尽管图像与文本的匹配精度略微降低,但图像的信息包容会稍高一些。
反观第十二层输出由于过于苛求图文比对的精确度,于是导致了些许的过拟合情况发生,从而导致生成的图像反而缺失了某些信息。但,如果 CLIP 的进程过早地提前终止而输出,则会导致图像与文本过于不匹配,从而无法实现我们想通过 Stable Diffusion 对生图做精准控制的诉求。
Stable Diffusion 的基础大模型实际上就是在 CLIP 处于倒数第二层时训练出来的,所以很多时候,你会发现把 CLIP Skip 设置为 2 时,生成的图像会更好,更接近于我们所希望提示词所表达的含义,且画面质感很 nice。当然,这也并不绝对,很多时候图像领域的好与坏因人而异,因项目需要而异,具体的设置还需要在实际的工作中进行微调来满足不同的需求。
那么,这个 CLIP 模型是如何训练出来的呢?
5.1 CLIP 模型的训练过程
CLIP 模型是通过图像和该图的文字说明一起训练出来的。起初,这样的训练样本“图文对”足足有4亿张!当然,这些图片与文字说明部分,基本都来自于网络上抓取的图片和这些图片在网页上的 “alt” 标签的内容( “alt” 标签是网页上的代码中 Html 图像标签中的一个属性标签,它利用文字内容描述当前的图片,告知搜索引擎这张图代表什么) 。

图文对数据集样式示意图
下面把 CLIP 拆解开看看细节,其内部是图像编码器和文本编码器的组合。首先将一张图片和它对应的文字说明分别输入到 Image Encoder 图像编码器和 Text Encoder 文本编码器中,分别输出为 Image embedding 和 Text embedding,即两组向量。
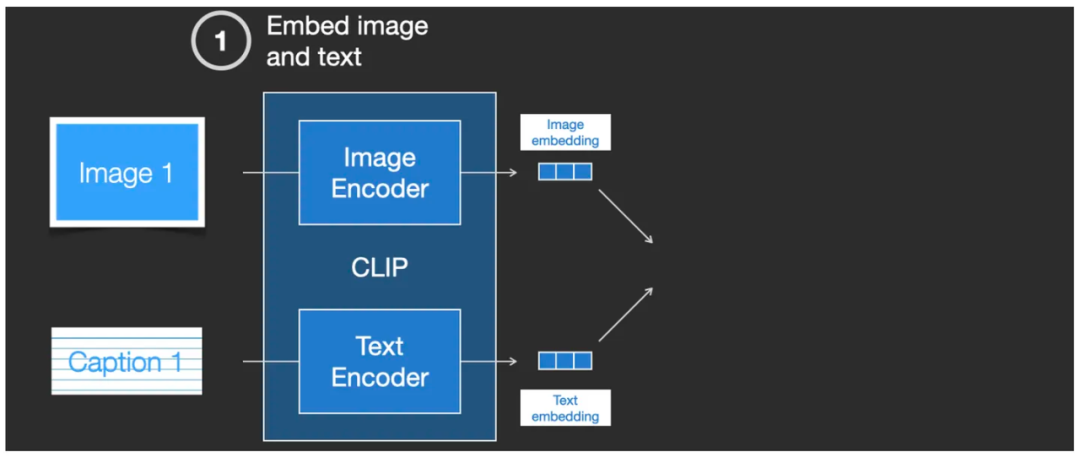
输入图片和图片描述给 CLIP 模型,输出位 Image embedding 和 Text embedding
然后,通过一种叫“余弦相似度”(cosine similarity)的向量对比方法来对比这两个生成出来的 embedding 向量。在刚开始训练时,即使在输入端来看文本准确地描述了图像,但在 CLIP 的输出来看相似度很低,即通过余弦相似度(cosine similarity)对比后的结果显示相似度很低。
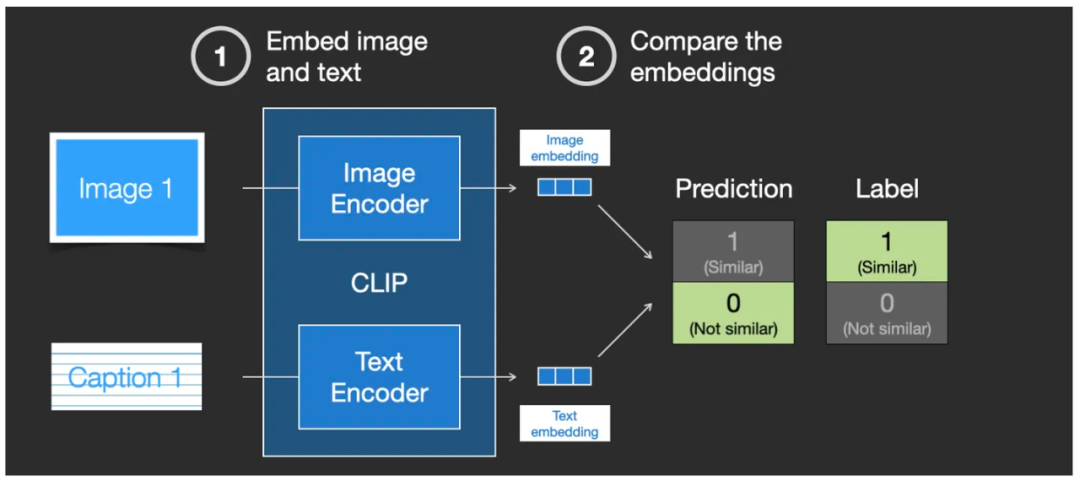
通过“余弦相似度”(cosine similarity)来对比两个生成出来的 embedding 向量的相似度
此时,模型的损失函数反馈机制发生作用,它把差值更新进入这两个编码器 Image Encoder 和 Text Encoder,以便在第二次再对同一组图和文字说明进行编码后产生的 embedding 向量之间的相似度能够有所提高,直至相似度达标为止。
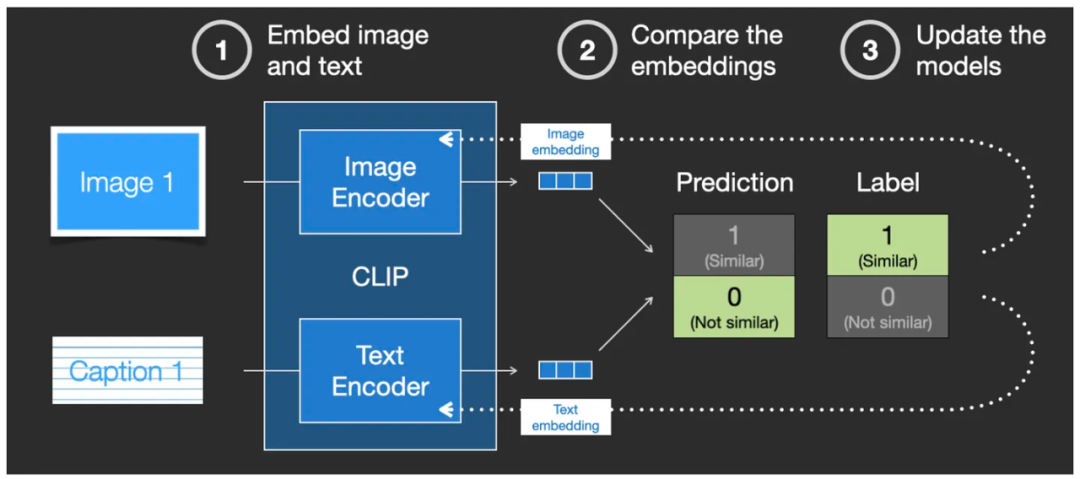
反馈机制通过损失函数来调整网络权重,从而训练 CLIP 模型
最后,通过对同一张图和文字描述进行往复不断地这个训练进程,使得两个编码器生成出来 embedding 向量十分相似时,我们就认为此时固化在 Image embedding 和 Text embedding 这两个编码器中为了调整相似度而嵌入的补充数据(即神经网络的连接权重)就为训练成功的 CLIP 模型了。然后,我们应该了解到,这样的训练操作进行了 4 亿次~!
当然,这一训练过程还需要训练那些“文不对图”的情况,即需要让编码器知道这张图和描述文字之间毫无关联,这种反向的情况也需要训练。
以上,有了 Diffusion 的生图模型,也有了文本描述的 CLIP 模型。那么,这两者又是怎么结合到一起的呢?
6. CLIPText 文本编码器 与 U-Net 噪声预测器的校正
为了使文本影响图像的生成,我们必须调整 Noise Predictor 噪声预测器 U-Net,使得提示词文本通过 CLIP 模型产生的 embedding 矩阵(图中 token embeddings)可以作为噪声预测器 U-Net 的其中一个输入。
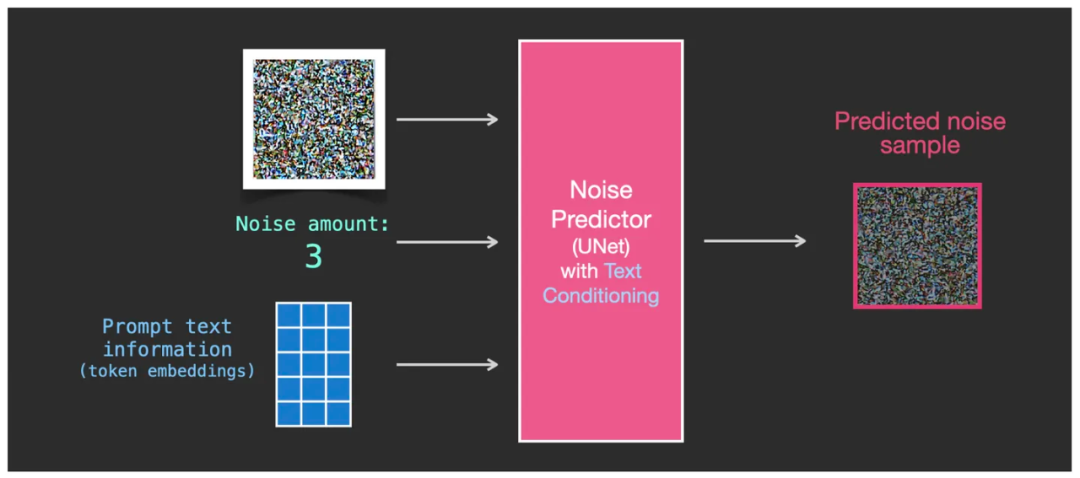
噪声预测器 U-Net 有三个输入,其中包括提示词的 token embeddings 矩阵
于是,我们现在有了三个数据作为 U-Net 的输入,分别是含噪点的图的矩阵(下图中左侧深红色网格)、噪点强度数值、文本 token embedding 矩阵(下图中蓝色网格)。而输出依旧是含有某种噪点强度级别的图像(下图中右侧深红色网格),也是以矩阵方式来表达,只不过这个噪点强度要比输入之前的降低了一些。
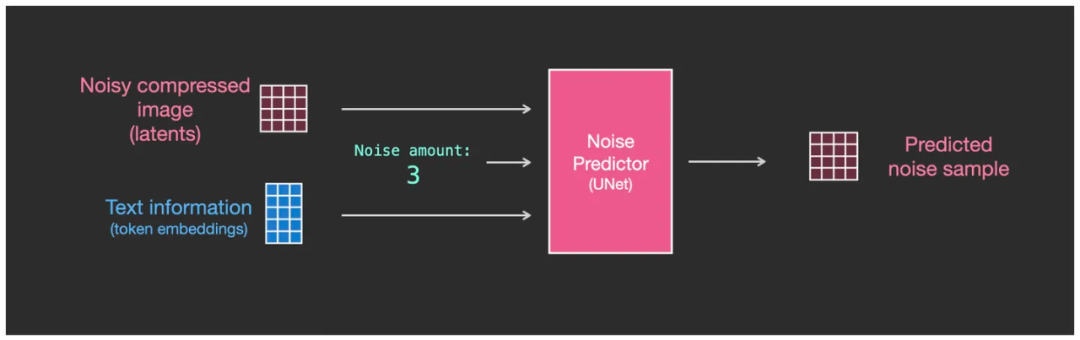
U-Net 的三个输入分别为:噪点的图的矩阵、噪点强度数值、文本 token embedding 矩阵
此时,为了更好地理解文本 token embedding 矩阵( Token embeddings )在 U-Net 模型中是如何起作用的,我们需要先来深入了解一下 U-Net。
我们先来看一个不含 token embedding 文本输入的 U-Net 的输入和输出是怎样进行的,如图:
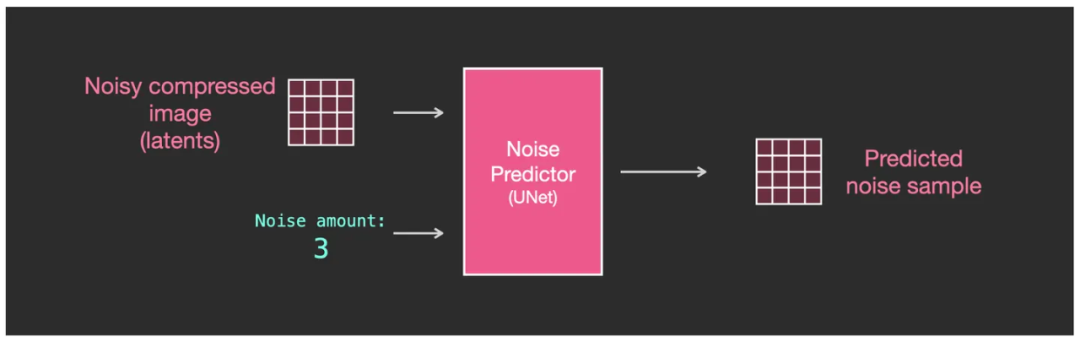
不含 token embedding 文本输入的 U-Net 的输入和输出解构
进一步解构开来可以看到(下图):
- U-Net 中有一系列转换潜空间数据的模块,它们叫残差网络(ResNet,Residual Network);
- 每一个模块与前一个模块组成输入与输出的串联,在模块中对数据进行一定的处理;
- 每个模块的输出并不是全部交由下一个模块处理,其中一部分会以残差网络(ResNet)的方式直接发送到处理进程的最后阶段;
- 噪点强度级别(Noise amount)可以通过时间步长(timestep)来表示,它也被转换成一个 embedding 向量(图中 noise amount embedding),输入到每一个残差网络模块中;
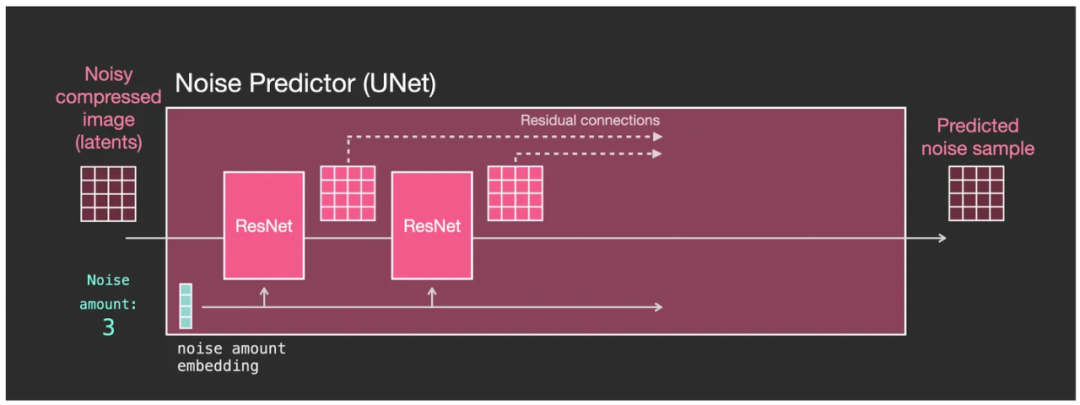
U-Net的内部结构,主要由残差网络(ResNet)组成
现在让我们加入文本 embedding 向量。此时,在 U-Net 内部可以看到(下图):
- 在每一个残差网络 ResNet 模块后面加入了一个 Attention 模块(Attention 模块可以在 Transformer 的介绍中详细了解到:这个可能是对Transformer最通俗易懂的解读了!),作为一种文本调节机制(Text Conditioning)把输入进来的 token embedding 融入到每一个处理阶段中;
- 在每一个处理阶段中,Attention 模块将这些文本特征合并到 Latent 潜空间的数据中,发往下一个 残差 ResNet 模块。然后下一个残差 ResNet 模块在处理的数据中就包括了更多的文本信息了。也就是说 Diffusion 的反向生图过程就掺入了指定语义的文本信息了。U-Net 将按照文本的语义信息来进行噪点的逐步去除工作。
于是,最终生成的图像就是我们通过提示词可以控制的图像了。
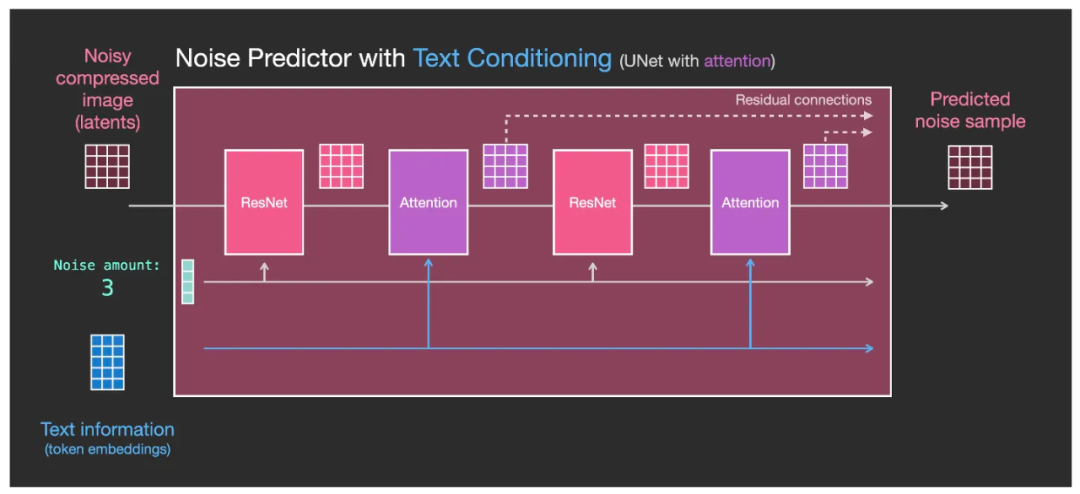
U-Net的内部结构,加入了Attention 模块后使得 token embedding 可以逐层输入进来
至此,Stable Diffusion 的基础工作原理就彻底讲完了。
7. “巨大的沙画”
最后,我们用一个特别好理解的比喻来回顾一下 Stable Diffusion,并巩固对它的理解。
Stable Diffusion 可以理解为一个巨大的沙画装置。沙子一直是那些沙子,但每次用沙子作出来的画都不一样,即使同一个主题、同一套提示词,沙子的细节都会不同,所以没有一次生成的图像是 100% 和其他一样的。毁掉画作沙子散乱后的状态每次也不一样,所以也没有任何潜空间中的噪点是一样的。
U-Net 的训练的过程就是将已经成行的沙画,轻微地持续震动画板,组成图像的沙子慢慢地逐渐散乱开来。画板每震动一次,沙子便更加地散乱,原来形成的图像逐渐模糊。这就相当于 Diffusion 的前向训练过程,每次添加一个级别的噪点,让 U-Net 此时的沙画被震动次数和散乱的状态。这个过程直至N次震动后,一副完整的沙画被变成了一片散漫的沙子。U-Net 从中识别沙子们是如何从聚集的图形状态一步一步地散乱成完全无序状态的,并将每个变化阶段的散乱状态浓缩成一个数据模型。 单一一粒沙子的变动或许没有什么规律可言,甚至成百上千的沙子的运动也未必可以总结出什么规律。但巨量的几十上百上千亿的沙粒组合像非洲草原上的角马迁徙一样,看起来虽然散漫但其中却有着某些规律。况且这样的迁徙进行了几十亿次后,U-Net 便从潜空间中看到了沙子的聚散离合隐藏的联系与规律。比如,一条线段,需要附近多远出的沙子、需要多少沙粒、通过多少步的移动、各自走到线段的什么位置,最终形成一个线段!
于是在反向的去噪点的过程中,强大的 U-Net 就有能力把散乱的沙子凝聚成最小的有意义的图像单元,比如一条线、一个三角形、一个图形轮廓、一个渐变等等,而这些基础图形之间也有相关联的逻辑,所以最终汇聚组成一幅很大的图像。
这是在2D平面上,如果在3D的空间,就是沙雕了。所以一点也不用担心SD在生成3D模型的过程中是否能够发挥类似的作用。

上: 从左至右为把噪声通过Diffusion的逆向过程转换成某种形状。中: 以点阵云的形式进行3D模型切换。下: 在前空中在两种3D点阵云种进行差值运算
如果再将不同序列的3D沙雕连贯起来,就变成了动画,如果是完全拟真的3D,最终生成的动画就变成了真人大片的电影!SD的未来可以说在AIGC领域前途无量!
请允许我在最后的最后,再感慨一番~~~
一个人类沙画家与 Stable Diffusion 沙画家的基础技能类似,但实力相差悬殊。人类沙画家的大脑本身就是一个神经网络模型,只不过这个模型训练的数据量要比 Stable Diffusion 差了太多太多。
Stable Diffusion 模型在经过了几十亿张图像文本对的训练过后,毋庸置疑是目前为止,人类文明诞生到今天阅览研究图像最多的智能体,多的不是一点半点,差距十分巨大。设想一下一个天才的人类从出生开始每天研究10张图,对图像与标注文字的关系了如指掌,对每张图的内容都记忆历久弥新永不遗忘任何细节,且对已经看过的所有图像之间的关系,图像中每个元素与其他图像中元素间存在的含义联系也要了如指掌,这样连续研究100年直至死亡,他一生中阅览的总数也不过 36.5 万个图文对。这个数字则是仅 1 个月时间内训练出来的 Stable Diffusion 模型阅览总数的不到万分之二。别说100年后,仅仅 3 年后 Stable Diffusion 的训练规模还将达到更加难以想象的地步!
100年后,一个如此刻苦研究的天才人类沙画家,带着他 36.5 万个图文对的记忆与处理能力连同他的躯体一同离开了这个世界,他脑中的神经网络无法复刻给他的后代。然而,这个实际上比365万这个规模要大上万倍的浩如烟海的图像数据依旧安详地躺在超级计算机的存储器里。并且就在当下,这个世界还在以每天数以亿计的新图像的产生速度快速地增长中!这些数据从人类文明诞生以来逐渐累加到现在这个规模,从来就未曾找到过一个单一肉身的个体有能力全部消化这些信息和继承这些信息。可是人类的每一个肉身的个体终究都要消失,人类文明的延续也并不是靠每个计算机里的硬盘,而是靠智能体。
10年后,Stable Diffusion 大模型累积的学习能力可能已经进入了万亿规模。100年后,Stable Diffusion 早已成为历史,它的替代版本可能演化出了几十上百个新生代。考虑到不仅仅限于静态图片和存储的视频,而是给这些智能体接入摄像头后,它们实时查看这个地球甚至太阳系的每一个角落。我们作为肉身的人类个体需要的图像,怎么能不如此丝滑地轻松地通过 AI 展现在眼前呢?!
最后,仅仅是 10 年后,脑机接口逐渐成熟,加之 AIGC 所产生的这个 C-Content 可以包揽人类的所有感受器眼、耳、鼻、舌、身的感受信息,我们极有可能不通过眼睛就能直接“看”到无穷无尽的神奇“世界”,不通过耳朵就能直接“听”到这万籁喧嚣的“世界”。。。。。这个“世界”是不是我们每个人心中想要的那个,尚无法确定,但可以肯定一点,这个“世界”足可以乱真,以至于让我们沉浸其中,认为一定是一个“真实的世界”,是我们的一闪念就可以毫无延迟地生成出来这个所谓的“真实的世界”。
这可能就是相由心生的真正含义吧!
- 我将始终本着让非专业人士也能看懂的讲解原则,尽量以通俗易懂的比喻和图表等方式来描述AIGC相关的技术术语。这同样是本着 AI 将人类知识壁垒大幅度降低门槛好让更多的普通人都能够涉足专业领域的宗旨,不仅仅是语言领域的巴别塔的解决,更是所有领域的巴别塔的解决,比如 Stable Diffusion 模型让一个从没有学过 PS 却有着超强艺术细胞和创造力的广场舞大妈都能绘出顶级的 CG 作品,而他们却因为年轻时的某些原因错过了走入设计专业领域的机会,或许是出身、或许是经济条件、或许是其他的命运所致。所以,用普通人、非专业人士都能看懂的方式来讲解是我的原则,也请专业人士给予一定理解。
- 查询资料、分析、组织、撰写…工作不易,请多多支持我。转载请注明出处,将万分感谢 。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号