使用awk和正则表达式过滤文本或字符串 - 详细指南和示例

使用awk和正则表达式过滤文本或字符串 - 详细指南和示例

数据科学工厂
发布于 2024-03-12 09:00:40
发布于 2024-03-12 09:00:40
当我们在 Linux 中运行某些命令来读取或编辑字符串或文件中的文本时,我们经常尝试将输出过滤到感兴趣的特定部分。这就是使用正则表达式派上用场的地方。
什么是正则表达式?
正则表达式可以定义为表示多个字符序列的字符串。关于正则表达式最重要的事情之一是它允许您过滤命令或文件的输出、编辑文本或配置文件的一部分等等。
正则表达式的特点
正则表达式由以下部分组成:
- 普通字符,例如空格、下划线(_)、A-Z、a-z、0-9。
- 扩展为普通字符的元字符包括:
- (.) 它匹配除换行符之外的任何单个字符。
- (*) 它匹配零个或多个其前面的直接字符。
- [character(s)]匹配character(s)中指定的任意一个字符,也可以使用连字符(-)表示一系列字符,如[a-f]、[1-5]等。
- ^ 它匹配文件中行的开头。
- $ 匹配文件中的行尾。
- \ 它是一个转义字符。
为了过滤文本,必须使用 awk 等文本过滤工具。您可以将 awk 视为一种编程语言。但对于本指南[1]使用 awk 的范围,我们将其作为一个简单的命令行过滤工具进行介绍。
awk 的一般语法是:
awk 'script' filename
其中“script”是 awk 可以理解在文件 filename 上执行的一组命令。
它的工作原理是读取文件中的给定行,制作该行的副本,然后执行该行上的脚本。文件中的所有行都会重复此操作。
“script”的形式为“/pattern/action”,其中pattern是正则表达式,而action是 awk 在行中找到给定pattern时将执行的操作。
如何在Linux中使用awk过滤工具
在下面的示例中,我们将重点关注 awk 的元字符。
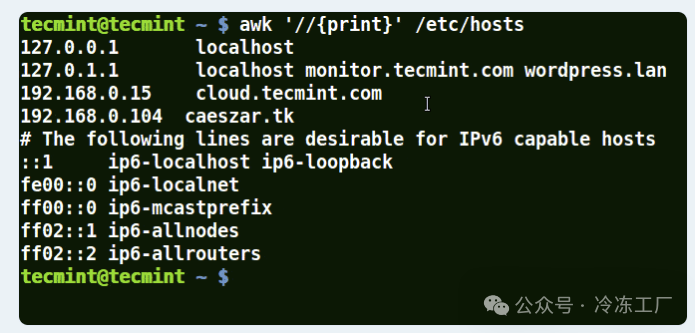
- 由于没有给出模式,下面的示例打印文件 /etc/hosts 中的所有行。
awk '//{print}'/etc/hosts
- 使用 Awk 模式:在文件中匹配带有“localhost”的行
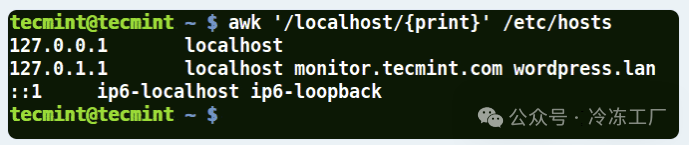
在下面的示例中,已给出模式 localhost,因此 awk 将匹配 /etc/hosts 文件中具有 localhost 的行。
awk '/localhost/{print}' /etc/hosts
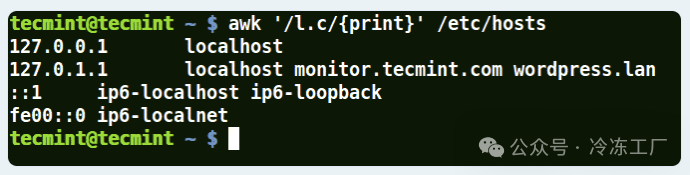
- 在模式中使用带有 (.) 通配符的 Awk
(.) 将匹配下面示例中包含 loc、localhost、localnet 的字符串。
awk '/l.c/{print}' /etc/hosts
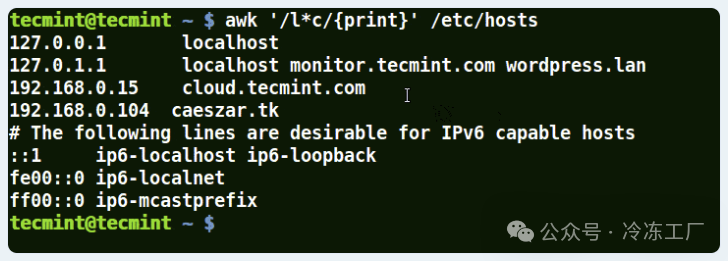
- 在模式中使用带有 (*) 字符的 Awk
它将匹配包含 localhost、localnet、lines、capable 的字符串,如下例所示:
awk '/l*c/{print}' /etc/localhost
您还将意识到 (*) 试图为您提供它可以检测到的最长匹配项。
让我们看一个案例来演示这一点,采用正则表达式 t*t,它表示匹配以下行中以字母 t 开头并以 t 结尾的字符串:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
当您使用模式 /t*t/ 时,您将得到以下可能性:
this is t
this is tecmint
this is tecmint, where you get t
this is tecmint, where you get the best good t
this is tecmint, where you get the best good tutorials, how t
this is tecmint, where you get the best good tutorials, how tos, guides, t
this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
/tt/ 通配符中的 () 允许 awk 选择最后一个选项:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
- 使用带有 set [ 字符 ] 的 awk
以集合[al1]为例,这里awk将匹配文件/etc/hosts中一行中包含字符a或l或1的所有字符串。
awk '/[al1]/{print}' /etc/hosts
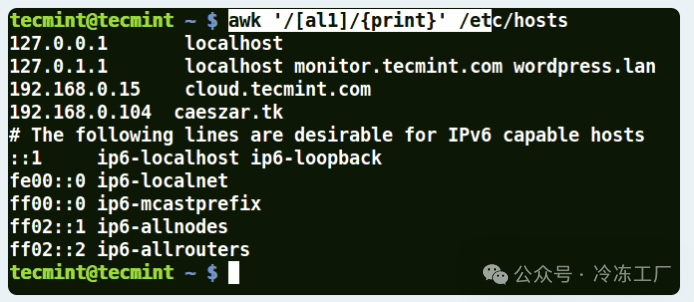
下一个示例匹配以 K 或 k 开头后跟 T 的字符串:
# awk '/[Kk]T/{print}' /etc/hosts

- 指定范围内的字符
用 awk 理解字符:
- [0-9]表示单个数字
- [a-z] 表示匹配单个小写字母
- [A-Z] 表示匹配单个大写字母
- [a-zA-Z] 表示匹配单个字母
- [a-zA-Z 0-9] 表示匹配单个字母或数字
awk '/[0-9]/{print}' /etc/hosts
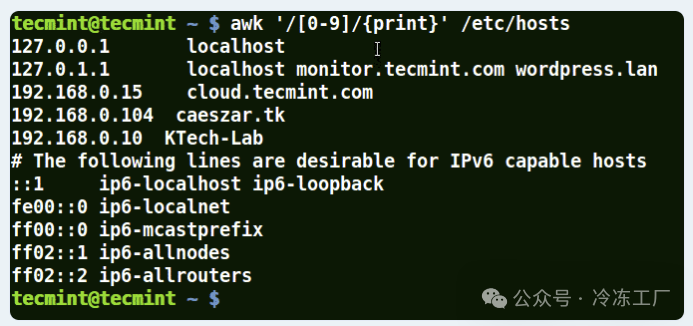
在上面的示例中,文件 /etc/hosts 中的所有行都至少包含一个数字 [0-9]。
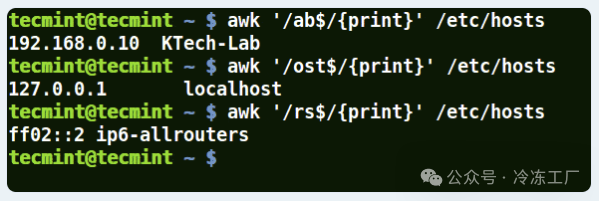
- 将 Awk 与 ($) 元字符结合使用
它匹配以提供的模式结尾的所有行:
awk '/ab$/{print}' /etc/hosts
awk '/ost$/{print}' /etc/hosts
awk '/rs$/{print}' /etc/hosts
- 将 Awk 与 () 转义字符一起使用
它允许您将其后面的字符视为文字,也就是说按原样考虑它。
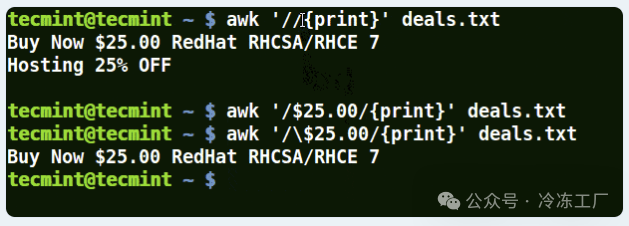
在下面的示例中,第一个命令打印出文件中的所有行,第二个命令不打印任何内容,因为我想匹配包含 $25.00 的行,但没有使用转义字符。
第三个命令是正确的,因为转义字符已用于按原样读取 $。
awk '//{print}' deals.txt
awk '/$25.00/{print}' deals.txt
awk '/\$25.00/{print}' deals.txt
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号