CART决策树暴力生成风控规则

CART决策树暴力生成风控规则

Python数据科学
发布于 2024-03-18 11:14:19
发布于 2024-03-18 11:14:19
上一篇我们介绍了决策树节点信息更新的方法风控规则的决策树可视化(升级版),以辅助我们制定风控规则,可视化的方法比较直观,适合做报告展示,但分析的时候效果没那么高。
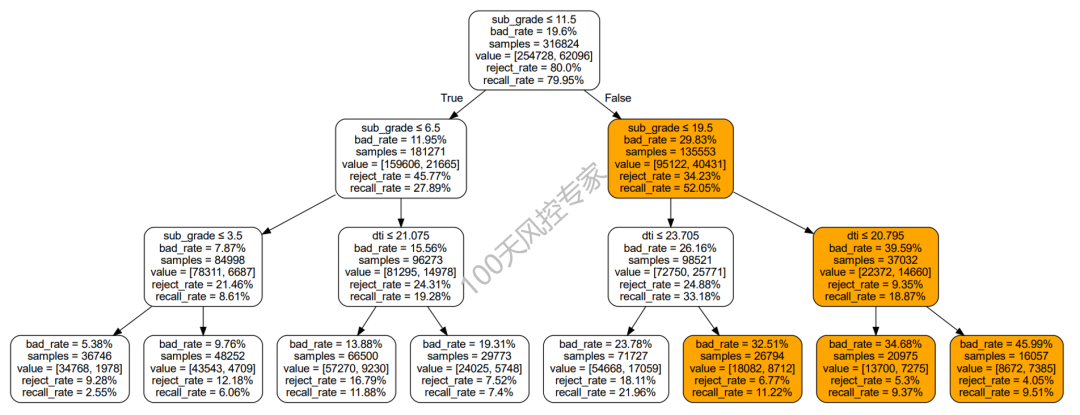
一、树结构信息
本篇我们介绍一种通过决策树自动挖掘规则的方法。
通过Sklearn中的tree_可以获取树结构的所有信息,进而将所有决策路径挖掘出来,也就是全自动化地的生成规则。总体想法就是先暴力挖掘规则,然后再从规则池中按照评估指标进行筛选。

以下是官网链接。
https://scikit-learn.org/stable/auto_examples/tree/plot_unveil_tree_structure.html#sphx-glr-auto-examples-tree-plot-unveil-tree-structure-py
二、代码实操
首先,也需要使用DecisionTreeClassifier或者DecisionTreeRegressor构建一个决策树模型对象。
X = df[df.columns.difference([yflag,'issue_d','address','emp_title','earliest_cr_line','title'])]
y = df[yflag]
# 划分数据集
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)
# 按照最优的方式分裂
model=tree.DecisionTreeClassifier(criterion="gini",
splitter='best',
random_state=42,
max_depth=3,
min_samples_leaf=0.05,
min_samples_split=0.05)
model = model.fit(x_train,y_train)
然后将模型对象喂入以下两个函数即可自动生成规则了。
# 输出每条决策树规则对应的最终预测值函数
def predict_value(tree):
"""
:param tree: 决策树对象
:return: 返回节点评估指标的列表
"""
value_list = []
tree_ = tree.tree_
def recurse(node, depth):
if tree_.feature[node] != _tree.TREE_UNDEFINED:
recurse(tree_.children_left[node], depth + 1)
recurse(tree_.children_right[node], depth + 1)
else:
# 提取value中的正负样本
good = tree_.value[node][0][0]
bad = tree_.value[node][0][1]
samples = good+bad
# 计算坏账率badrate
bad_rate = round(bad*100/(bad+good),4)
value_list.append([bad_rate,hit_rate,recall_rate,lift])
recurse(0, 1)
return value_list
# 决策树规则抽取和解析函数
def extract_tree_rules(tree, feature_names):
"""
:param tree: 决策树对象
:param feature_names: 构建决策树使用的特征名称
:return: 决策树规则抽取结果
"""
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
index_list = np.argwhere(left == -1)[:, 0]
value_list = predict_value(tree)
rule_list = []
# print(value_list)
def decision_flow_extract(left, right, child, d_flow=None):
"""
:param left: 数组格式,决策树左子节点id
:param right: 数组格式,决策树右子节点id
:param child: 子节点id
:param d_flow: 子节点决策流
:return: 子节点对应的决策流
"""
if d_flow is None:
d_flow = [child]
if child in left:
parent = np.where(left == child)[0].item()
split = 'le'
else:
parent = np.where(right == child)[0].item()
split = 'rg'
d_flow.append((parent, split, threshold[parent], features[parent]))
if parent == 0:
d_flow.reverse()
return d_flow
else:
return decision_flow_extract(left, right, parent, d_flow)
rule_list=[]
left_symbol = '<='
rgiht_symbol = '>'
for j, child in enumerate(index_list):
clause = ''
for node in decision_flow_extract(left, right, child):
if len(str(node)) < 3:
continue
i = node
if i[1] == 'le':
sign = left_symbol
else:
sign = rgiht_symbol
clause = clause + i[3] + sign + str(i[2]) + ' and '
value_list[j].append(clause[:-4])
# clause = clause[:-4] + ' Badrate:' + str(round(value_list[j],4))
rule_list.append(value_list[j])
return rule_list
这里要我们设置的决策树深度为3,并且树结构生成完整,因此生成的规则中均包含3个变量,8条决策路径总共生成8条规则,具体如下:
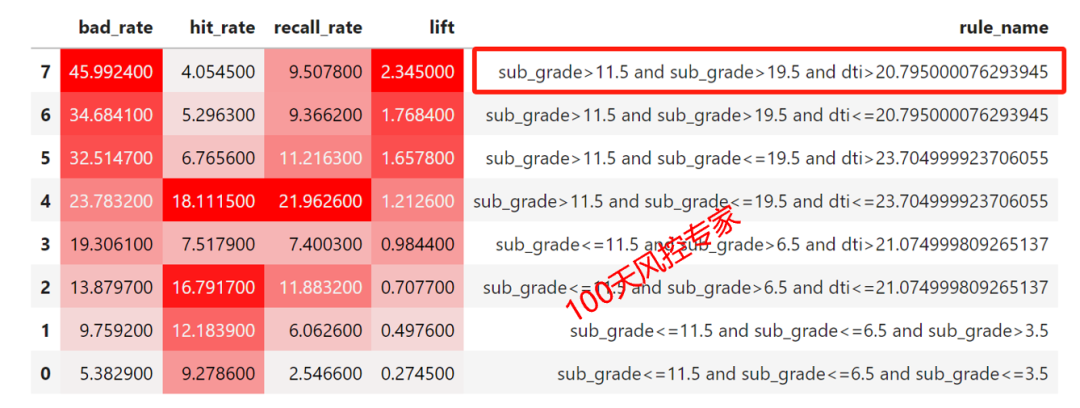
规则是用来高风险客户的,因此先对精准率进行从大到小的排序,然然后再看命中率、召回率等是否符合要求。
可以看到第一条规则的评估指标比较符合要求,但其中subgrade存在两个重复的,因为cart算法在每个决策点对特征变量是有放回的。可以考虑合并,等效于:subgrade>19.5 and dti>20.795,这样就非常快速的挖掘出一条风控规则了。
三、更多规则挖掘
如果决策树的参数和数据都固定的话,生成的树结构也就是固定的。如果想继续暴力挖掘更多的规则,可以尝试不同的参数。比如说,选择树深度为2,那么生成的规则都仅包含两个变量,选择splitter参数为random局部最优,每个节点的变量选择也会发生变量,再比如更换随机种子等等,那么不同参数的组合就可以生成不同新的树结构,这样就有成千上万条的规则了。
以下是DecisionTreeClassifier分类模型的参数。

因此,如果想挖掘更多的规则,可以按照不同参数组合的思路将以上函数进行封装来实现暴力规则挖掘的功能。
评估指标如果有固定的标准,也可以设置并完成自动的提取。当然,最后规则挖掘出来最后还要看可解释性了,因为在金融信贷风控中对业务解释性要求比较高。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号