Meta最新推荐算法:统一的生成式推荐第一次打败了分层架构的深度推荐系统?

Meta最新推荐算法:统一的生成式推荐第一次打败了分层架构的深度推荐系统?

NewBeeNLP
发布于 2024-03-18 14:36:04
发布于 2024-03-18 14:36:04
大家好,这里是 NewBeeNLP。今天看看Meta的最新推荐算法论文,“统一的生成式推荐”(GR) 第一次在核心产品线替换掉了近十年推荐工业界长期使用的分层海量特征的模型范式。

地址:https://arxiv.org/pdf/2402.17152.pdf
作者:萧瑟
链接:https://www.zhihu.com/question/646766849/answer/3428951063
论文工作还挺有意思的。之前有AutoInt等用transformer做特征自动交叉的工作,也有Transformers4Rec等把transformer用到序列建模的工作,这个工作把用户画像和用户行为甚至target信息都放到超长序列中,结合多层(应该是精排3层,召回6层,最多24层)transformer进行建模,很简洁。
看文章有可能是meta的短视频推荐业务,由于不知道线上baseline的具体情况,因此推测效果来源可能有下面几点:
- 更强的特征交叉能力 :直接在原始用户行为上引入用户画像和target信息进行交叉,没有信息损失,交叉更为充分。而很多特征交叉工作是在用户建模处理后已经压缩的用户表征上进行,信息损失比较大。当然也有笛卡尔积和CAN等工作是在原始用户行为上进行,不过建模能力有可能弱于多层transformer结构。另外看论文工作embedding维度可能是512这个维度,因此模型容量应该也是足够的。另外不知道baseline有没有类似senet、ppnet这种gateing网络,如果没有的话,新架构应该也会有更多效果增强。
- 信息利用更充分 :对稀疏参数来说,自回归预测next item的loss,相比原来样本维度的交叉熵loss,参数的梯度更新可能会更充分,样本利用效率也会更高。这个感觉非常像DIEN中的辅助loss。
- 更丰富的用户行为引入以及更强的序列建模能力 :目前不太确定baseline是否有用户行为建模,以及baseline的用户行为量级和新架构相比如何,新架构是有可能使用了更长的用户行为。或者用户行为时间相同,但是新架构有可能引入更丰富的用户行为信号(例如baseline只使用点击,新架构引入了曝光等)。另外即使是在用户行为完全相同的情况下,新架构对用户行为的建模能力显然会更强,这个应该也是有效果增益的。
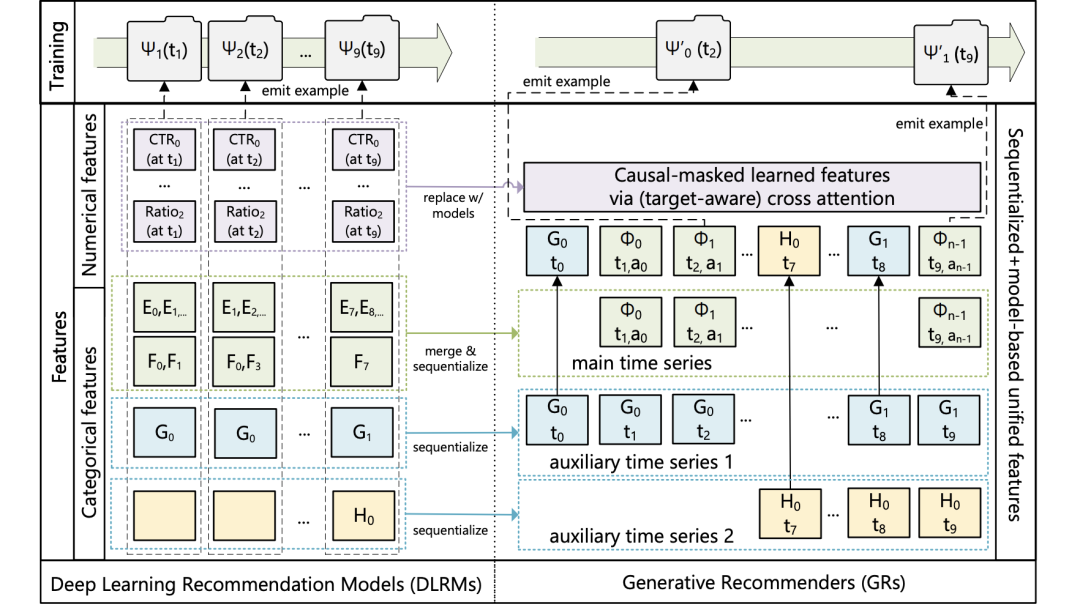
论文中cross attention的实现,感觉挺有意思的。如果在CTR推荐场景落地论文的架构,有可能是把曝光和点击行为,都放到一条序列中,把item的time diff、类目等属性信息以类似position embedding的方式相加引入进来,把行为类型也放到了序列中,序列形式类似于:item1,曝光未点击,item2,点击,item3,点击。。。 后面就是一个next item prediction的loss,不过只预测是否点击,其他部分mask掉。
论文中出现的scaling law现象令人振奋 ,不过LLM的scaling law论文中提到,参数量和数据集大小要同步增加,只提升一个的话会有效果提升幅度的惩罚,不知道论文中进行实验的时候,数据集大小是怎么变化的,是否有足够的数据来支撑。
另外LLM的scaling law论文中在讨论计算量参数量的时候,是把embedding层排除掉了,这个论文中应该没有排除,不知道是不是推荐和NLP大模型scaling law上的一个差异点。
论文虽然抛弃了人工构造的统计特征,但仍然是基于ID体系进行学习的,并没有多模态信息的引入。目前一些研究表明,多模态信息在一些情况下是可以打平ID体系的,不知道后面结合模型复杂度和数据量的提升,是否会有一些质的飞跃,这个还是比较期待的。
论文的架构,看起来可以在线上推理的时候,把上百个候选集做成一条序列,一次进行推理,这个应该能节省一定的算力。另外因为少了很多特征加工,特征抽取加工部分的计算会比较简单,应该也能节省挺多机器。文章可以做到推理的算力成本和基线差不多,Meta的工程优化能力确实很强。后面如果大家进行落地尝试的话,效果空间可能取决于当前基线的特征交叉和用户建模技术水位,另外工程优化的挑战也会比较大。
作者:Lunarmony
链接:https://www.zhihu.com/question/646766849/answer/3417573481
作为本文共同作者其中一位尝试回答一下。
首先本文亮点还是比较多的,包括且不限于
- “统一的生成式推荐”(GR) 第一次在核心产品线替换掉了近十年推荐工业界长期使用的分层海量特征的模型范式;
- 新的encoder (HSTU) 通过新架构 + 算法稀疏性加速达到了模型质量超过Transformer + 实际训练侧效率比FlashAttention2 (目前最快的Transformer实现)快15.2倍;
- 我们通过新的推理算法M-FALCON达成了推理侧700倍加速(285倍复杂模型,2.48x推理QPS);
- 通过新架构HSTU+训练算法GR,我们模型总计算量达到了1000x级的提升,第一次达到GPT-3 175b/LLaMa-2 70b等LLM训练算力,且第一次我们在推荐模态观测到了语言模态的scaling law;
- 传统测试集MovieLens Amazon Reviews等相对经典SASRec提升20.3%-65.8% NDCG@10;
- 实际中多产品界面上线单特定ranking界面提升12.4%;
- etc.
然后回答一下题主问题:
- 12%是在线E-Task (Table 6)。"we report the main engagement event (“E-Task”) and the main consumption event (“C-Task”)." E-Task是我们最主要的在线参与度指标,可以想象成点赞转发。C-Task可以想象成完播,时长这样的任务。再另外12.4% 只是单纯ranking stage的结果,如果我们把召回+排序两个阶段加起来就12.4% (table 6) + 6.2% (table 5) = 18.6%了。。
- 自回归训练时因为核心推荐场景词表在billion级以上,采样是必须的。我们这里也有一些算法改进,限于篇幅这篇文章没有写。后续tech report或者follow up paper可能会更新。
- ranking的setup可以看2.2最后一段。“We address this problem by interleaving items and actions in the main time series. The resulting new time series (before categorical features) is then x0, a0, x1, a1, . . . , xn−1, an−1, where mask m_i's are 0s for the action positions”。我们是通过交错放置item content和item action序列来达到target aware cross attention in autoregressive setting的。后续appendix会补一下图。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号