书生·浦语2.0体系&技术报告


前言
本文是书生·浦语二期实战营课程视频笔记,如果需要详细视频教程可自行搜索。
InternLM2
- InternLM2-Base 高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
- InternLM2 在Base基础上,在多个能力方向进行了强化,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座
- InternLM2-Chat 在Base基础上,经过SFT和RLHF,面向对话交互进行了优化,具有很好的指令遵循、共情聊天和调用工具等的能力
从模型到应用典型流程
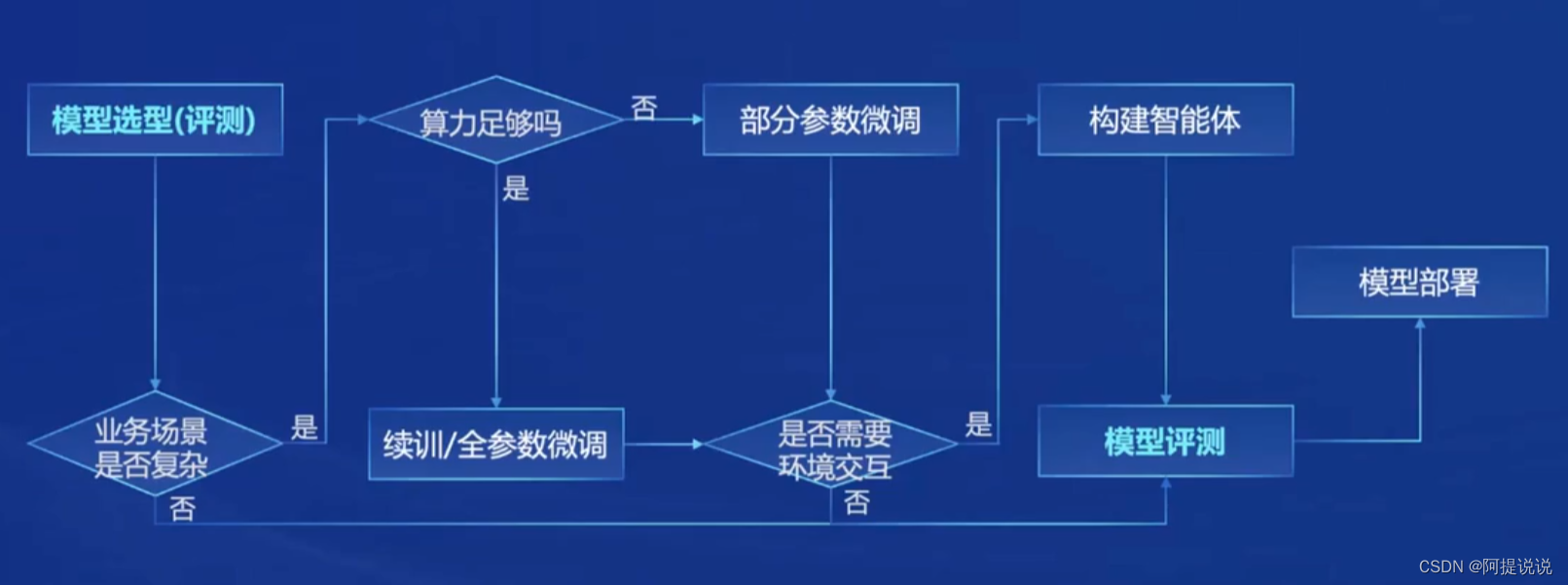
这里介绍了我们如果要做大模型应用,应该如何选择大模型,如何进行微调,以及是否需要使用工具调用,最后进行评测的整体流程
LMDeploy 性能比较
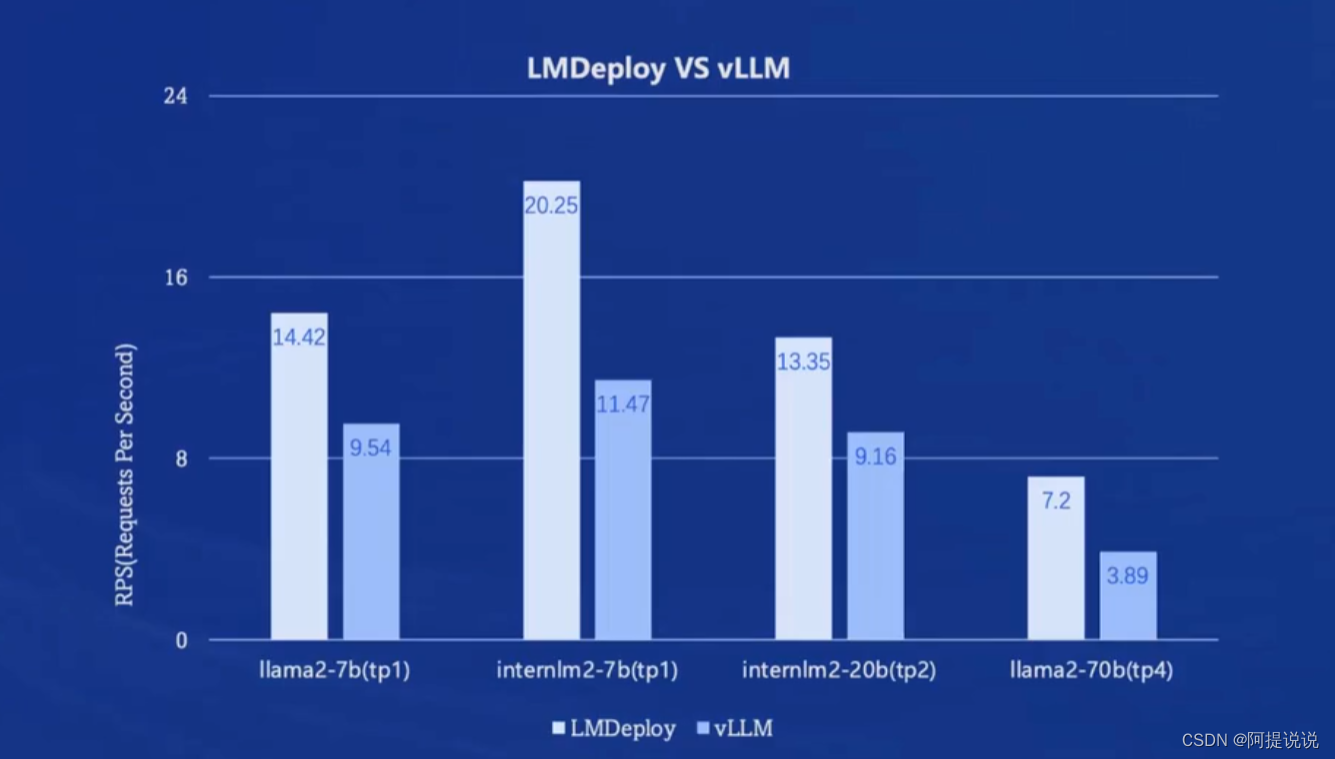
整体来说,推理性能优于vLLM。
InternLM2 技术报告
本文主要是摘录,这里我主要摘录的是我比较关注的预训练方式,完整内容请查看原报告,https://aicarrier.feishu.cn/wiki/Xarqw88ZkimmDXkdTwBcuxEfnHe
预训练
文本数据
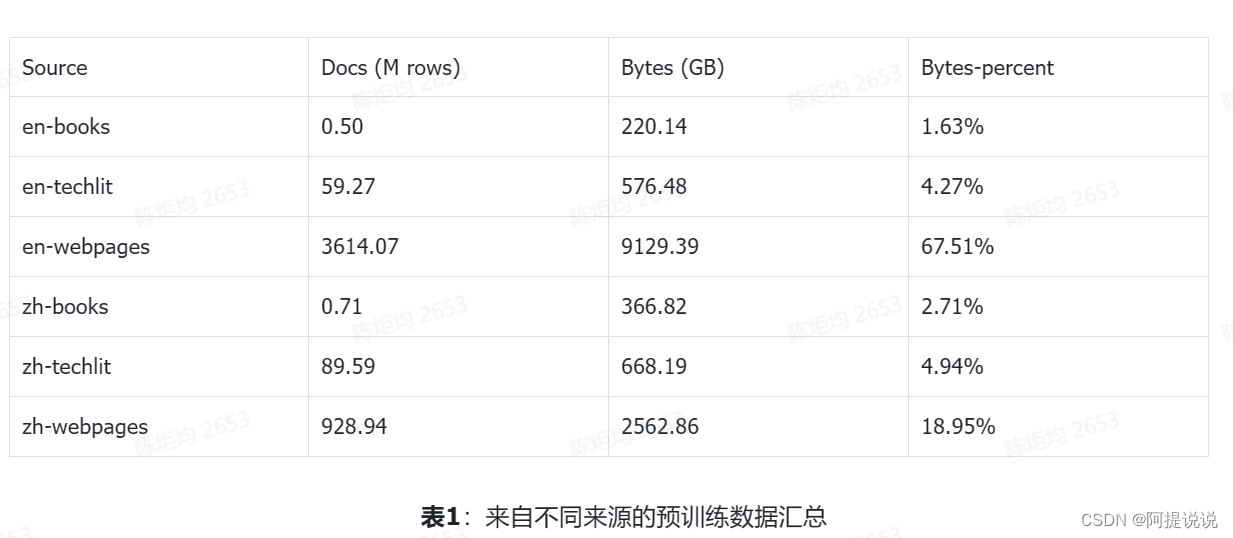
我们的预训练数据集的来源为网页、论文、专利和书籍。为了将这些原始数据转化为预训练数据集,我们首先将所有数据标准化为指定格式,然后根据内容类型和语言进行分类,并将结果存储为JSON Lines(jsonl)格式;然后,对所有数据,我们应用了包括基于规则的过滤、数据去重、安全过滤和质量过滤等多个处理步骤。这使得我们得到了一个丰富、安全且高质量的文本数据集。 数据来源分布 我们根据数据来源对预训练数据集中的文档数量、存储容量和容量占比进行了统计分析,结果如表1所示。其中,主要来源是中文和英文网页,占总量的86.46%。尽管其他来源(如书籍和技术文献)的数据量占比相对较少,但它们的平均文档长度更长、内容质量相对较高,因此同样重要。
数据处理流程 本工作中使用的数据处理流程如图3所示。整个数据处理流程首先将来自不同来源的数据标准化以获得格式化数据。然后,使用启发式统计规则对数据进行过滤以获得干净数据。接下来,使用局部敏感哈希(LSH)方法对数据去重以获得去重数据。然后,我们应用一个复合安全策略对数据进行过滤,得到安全数据。我们对不同来源的数据采用了不同的质量过滤策略,最终获得高质量预训练数据。
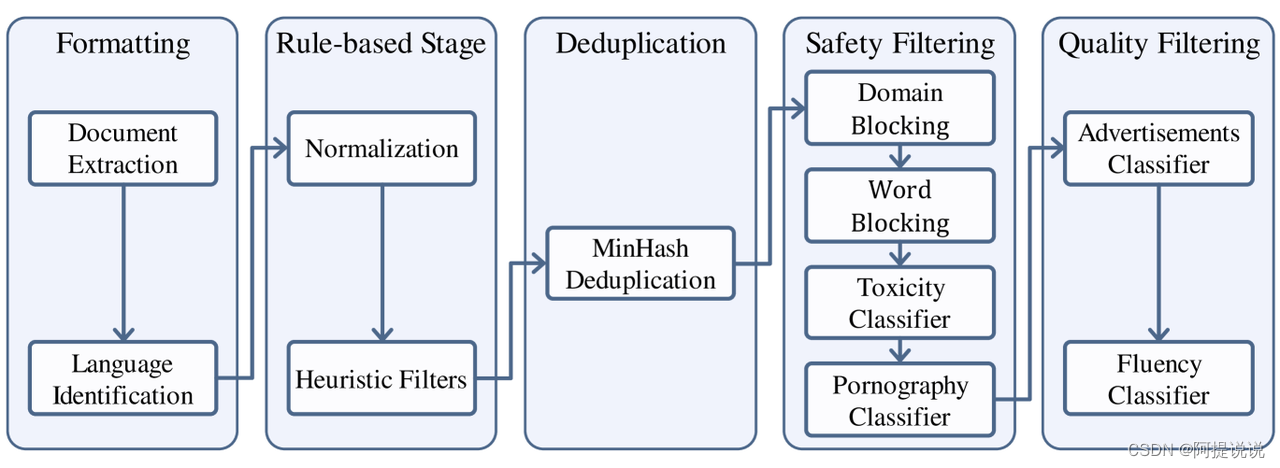
数据处理流程
数据格式化 我们将以网页数据为例详细介绍数据处理流程。我们的网页数据主要来自Common Crawl。首先,我们需要解压缩原始的Warc格式文件,并使用Trafilatura (Barbaresi, 2021)进行HTML解析和主文本提取。然后,我们使用pycld2库进行语言检测和主文本分类。最后,我们为数据分配一个唯一标识符,并以jsonl(JSON行)格式存储,从而获得格式化数据。 基于规则的处理 从互联网随机提取的网页数据通常包含大量低质量数据,如解析错误、格式错误和非自然语言文本。常见的做法是设计基于规则的正则化和过滤方法来修改和过滤数据,如 (Rae et al., 2021)、C4 (Dodge et al., 2021)和RefinedWeb (Penedo et al., 2023)。基于对数据的观察,我们设计了一系列启发式过滤规则,重点关注分隔和换行中的异常、异常字符的频率以及标点符号的分布。通过应用这些过滤器,我们得到了干净数据。 去重 互联网上存在的大量重复文本会对模型训练产生负面影响。因此,我们采用基于Locality-Sensitive Hashing (LSH)的方法对数据进行模糊去重。更具体地说,我们使用MinHash方法(Broder, 1997),在文档的5-gram上使用128个哈希函数建立签名,并使用0.7作为去重阈值。我们的目标是保留最新数据,即优先考虑具有较大Common Crawl数据集版本号的数据。在LSH去重后,我们得到了去重数据。 安全过滤 互联网上充斥着有毒和色情的内容,使用这些内容进行模型训练会对模型的表现产生负面影响,增加生成不安全内容的可能性。因此,我们采用了一种综合性的安全策略,结合了“域名屏蔽”、“关键词屏蔽”、“色情内容分类器”和“有害性分类器”来过滤数据。具体来说,我们构建了一个包含大约1300万个不安全域名的屏蔽域名列表,以及一个包含36,289个不安全词汇的屏蔽词列表,用于初步的数据过滤。考虑到关键词屏蔽可能会无意中排除大量数据,我们在编制屏蔽词列表时采取了谨慎的方法。 为了进一步提高不安全内容的检测率,我们使用了来自Kaggle的“有害评论分类挑战赛(Toxic Comment Classification Challenge)”数据集对BERT模型进行了微调,从而得到了一个有害性分类器。我们从去重后的数据中抽取了一些样本,并使用Perspective API对其进行了标注来创建色情分类数据集然后,我们用这个数据集微调BERT模型,产生一个色情分类器。最后,通过使用这两个分类器对数据进行二次过滤,过滤掉分数低于阈值的数据,我们得到了安全数据。 质量过滤 与书籍、论文和专利等来源相比,从互联网获取的数据包含大量低质量内容。根据我们的观察,这种低质量内容的主要原因是两个方面:1. 互联网上充斥着营销广告,这些广告往往重复性较强,信息含量较低。2. 许多网页由文章摘要或产品描述的列表组成,导致提取的文本难以阅读且缺乏逻辑连贯性。 为了过滤出这些低质量内容,我们首先组织了人工数据标注。在广告分类任务中,标注人员被要求识别数据中是否包含广告内容(无论是整体还是部分广告都被标记为低质量)。在流畅性分类任务中,标注人员被要求在一致性、噪声、信息含量和语法四个维度上对数据进行评分,从而得到一个全面的流畅性得分。然后我们使用这些标注的数据微调BERT模型,得到一个广告分类器和一个流畅性分类器。最后,通过使用这两个分类器对数据进行二次过滤,过滤掉得分低于阈值的数据,我们得到了高质量预训练数据。
代码数据
编程是LLM的一项关键技能,它为多种下游应用提供支持,例如编码辅助、软件开发以及构建可使用工具的代理。此外,(Groeneveld et al. (2024)) 指出,通过在代码数据上进行训练可以增强LLM的推理能力,因为代码通常比自然语言结构更清晰、更严谨、更可预测。
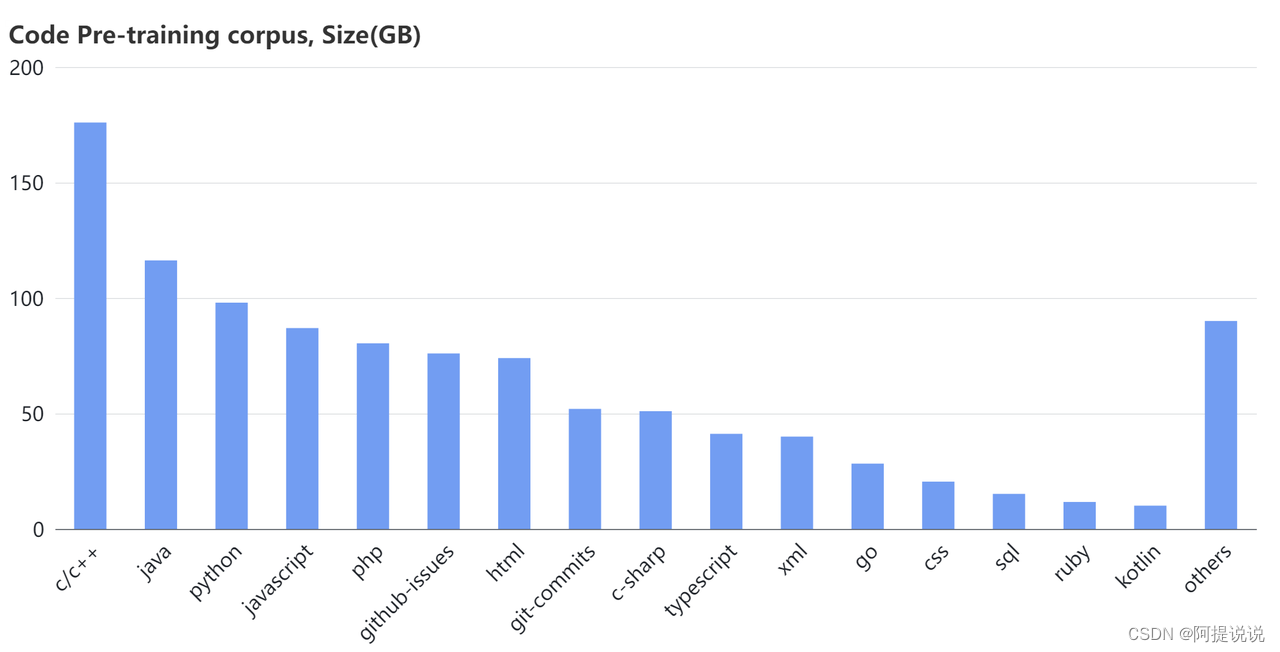
图4:预训练语料库中的代码数据统计
代码数据的来源有GitHub、公共数据集以及一些与编程相关的在线资源:如问答论坛、教程网站和API文档等。统计数据如图4所示。 表2反映了基于我们训练的评分模型的数据质量评估。高质量数据将具有更高的采样权重,并可以在预训练阶段进行多次训练。中等质量数据具有正常的采样权重,通常训练一次。低质量数据被排除在外,因为我们的实证发现,尽管它们的比例相对较小,但去除它们对于优化模型性能和确保训练稳定性至关重要。
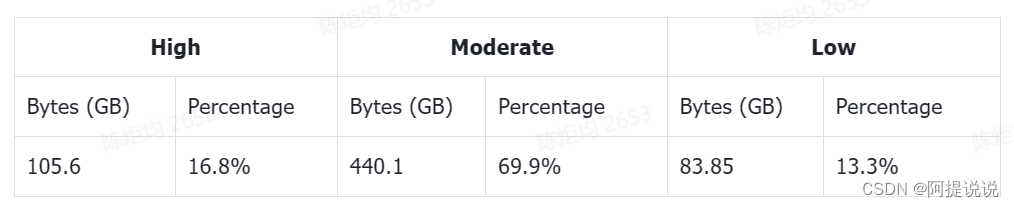
表2:基于可学习分类器的代码数据质量统计,其中高质量数据将被多次训练,中等质量数据将被训练一次,低质量数据将被丢弃。那些数据量比较少的编程语言的数据将被保留,不会在统计中考虑
格式清理 所有数据都转换为统一的Markdown格式。尽管我们并没有在格式清理上投入太多的精力,但是仍然有一小部分数据中出现了损坏的HTML或XML格式,我们还是应用了一套启发式规则来确保数据的格式正确。我们选择Markdown格式是因为它能最大化的减少的格式化后的 tokens 开销,并且它对代码和自然语言交织的数据具有更好的兼容性。因涉及根据代码之间的依赖关系连接多个代码文件,预训练实际使用的数据格式更为复杂。主要思想是利用交织了代码和自然语言的数据,这对于教会模型编程至关重要。这一点在最近的研究中也有提及(Guo et al., 2024)。 数据去重 代码数据的去重操作与自然语言的去重操作类似,但除了分词,因为这会影响超参数的选择。例如,Python示例使用两个空格、四个空格或制表符来表示缩进。传统的空格分词器,或者为自然语言定制的分词器,可能会错误地将这些示例评估为不同的数据。我们认为,一个有效的分词器对于提高去重策略的整体效果至关重要。尽管最近的研究已经探讨了在段落或行级别进行细粒度去重,但我们仍然在文件级别进行去重,以保持上下文的完整性。 质量过滤 数据质量是LLM研究中一个关键而模糊的方面,主要是难以量化其对模型性能影响。我们设计的质量过滤流程是混合的和多阶段的,包含了基于规则的和基于模型的质量评分器。其中基于规则的评分器是启发式的且因不同的编程语言而各不相同,因为我们发现代码风格不是一个可靠的优质指标,并且会错误地将许多代码分类为低质量。对于基于模型的评分器,我们评估了几种骨干模型,用大约50,000个标记样本训练它们。然而,我们观察到评分器的评估与人类的评估之间的相关性在不同语言之间存在差异,而且扩大训练集并没有显著提高评分器的准确性。因此,我们只在那些模型评估与人类标注的验证集上的评估相一致的编程语言中,使用基于模型的评分器。
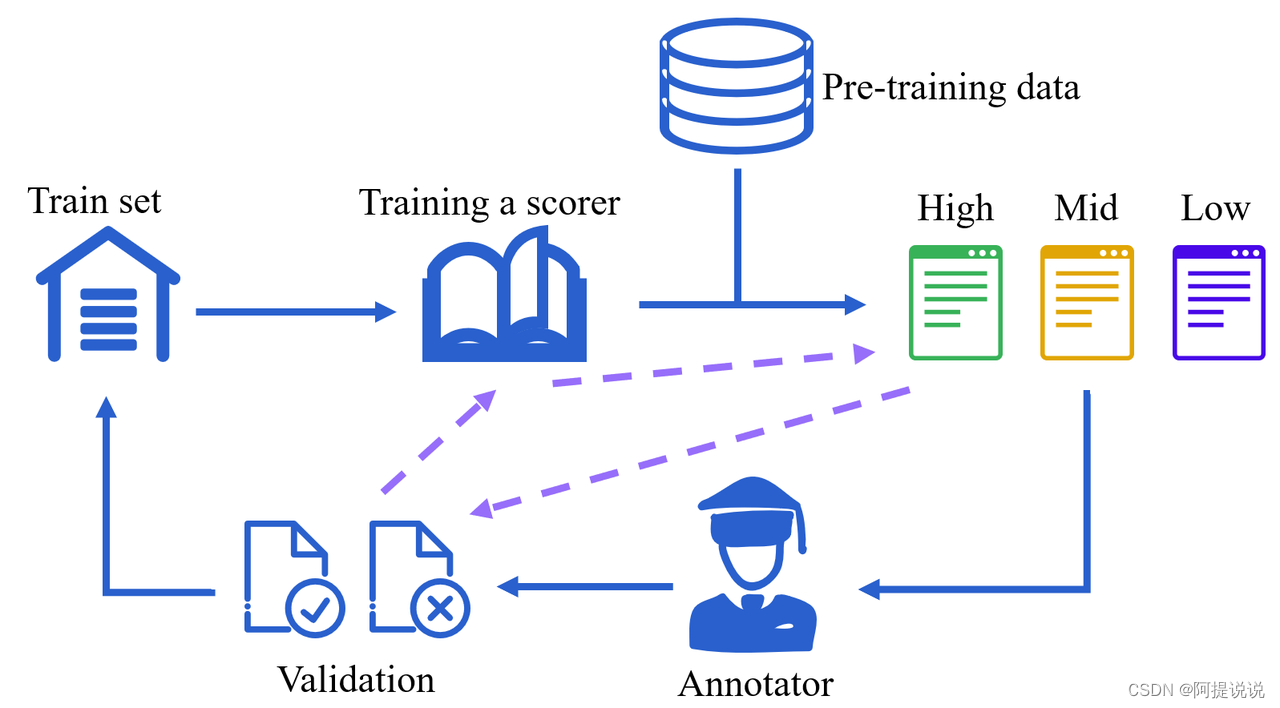
图5:代码质量评分器的迭代提炼标注流程 为了获得代码质量评分器的可靠标注,我们引入了一个迭代标注流程(如图5所示),以解决代码质量定义模糊的挑战。对于人类专家来说,确定对教授大语言模型(LLM)有帮助的代码同样不是一件小事,例如,一个广为人知的代码库可能对初学者来说过于复杂。我们提出的迭代标注工作流程允许标注人员验证模型预测结果,并相应地完善标注指南。为了提高标注效率,我们只要求标注人员检查评分器以高置信度标记为高质量和低质量的样本。此外,在每次迭代中都有一个自动验证过程,以确保之前标注的样本被评分器正确分类,这在图中以虚线表示。在实际操作中,我们进行了三次迭代才最终确定了我们的评分模型。 依赖排序 InternLM2的训练上下文窗口已扩展到32,000个tokens,这个长度可以允许利用代码仓库的整个上下文。但是因为在之前的数据处理步骤中,比如对代码文件的扩展名过滤和去重等操作,可能已经破坏了代码仓库的结构。所以我们首先重新组合来自同一个仓库的代码文件,然后通过依赖排序以建立一个拼接这些文件的序列。这样一个代码仓库将被视为一个由多个代码块组成的大Markdown文件,这使得模型能够学习跨文件之间的依赖关系。 我们采用正则表达式来检测各种编程语言之间的“import”关系,并使用拓扑排序来确定文件的拼接顺序。在实践中,文件的排列可能会打破文件夹边界,导致来自多个子文件夹的文件以交错的方式排列。对于非代码文件,如Markdown和其他文档,我们把它们放在同一子文件夹中的第一个代码文件之前。 对于一些特殊情况,如代码文件之间存在的多重依赖路径,我们选择最短的路径来处理,对于“import”关系图中的循环引用,我们使用字母顺序来决定引用的起始点。寻找“import”关系的一个技巧是解决好批量导入问题,例如“init.py”或“#include xx.h”。这些文件可能导入了一大批未使用的依赖项,因此我们应用启发式规则来细化我们对“import”关系的检测,确保我们能够准确识别并在更精细的层面上处理这些关系。
长上下文
处理非常长的上下文(超过32K个 tokens )是在LLM研究中一个日益受到关注的话题,它拓宽并促进了LLM在应用领域的发展,例如书籍摘要、支持长期对话以及处理涉及复杂推理步骤的任务等。预训练数据是扩大模型上下文窗口的一个关键因素。我们遵循 Lv et al. (2024) 中提到的准备长文本预训练数据的工作,其中包括附加的实验和讨论。我们在下文中仅概述InternLM2中使用的数据准备工作。 数据过滤流水线 我们的数据过滤流水线旨在过滤掉低质量的长文本数据。它包括三个阶段:a)长度选择,这是一个基于规则的过滤器,选取超过32K字节的样本;b)统计过滤器,利用统计特征来识别和移除异常数据;c)困惑度过滤器,利用困惑度的差异来评估文本片段之间的连贯性,过滤掉上下文不连贯的样本。需要注意的是,选定用于长上下文训练的所有数据都是标准预训练语料库的一个子集,这意味着长上下文数据至少在预训练期间会被学习两次。 统计过滤器 我们使用各种词汇和语言特征来构建我们的统计过滤器。不符合既定规则的数据样本被排除在预训练语料库之外。这些过滤器的完整列表可以在 Lv et al. (2024) 中找到。一个典型的过滤器是存在连词和其他暗示话语结构的词,比如“Especially”(特别是)、“Formally”(理论上)等。设计这些过滤器的总体指导思想是过滤掉无意义的数据,而不是选择最高质量的数据。统计过滤器对长文本数据特别有效,因为统计特征比短文本数据中的统计特征更加一致。例如,20个 token 的文本可能不会产生可靠的统计数据,但32K个 token 的文本将具有更清晰的统计特征分布。 困惑度过滤器 困惑度通常被视为文本序列概率
的估计器,我们稍微改变了它的使用,以估计两个文本片段之间的条件概率
,其中
是
的前置内容。当
和
高度相关时,条件概率应该高于单独估计
的概率,这也意味着负的困惑度差异。相反,如果概率变化方向相反,意味着
是一个分散性的上下文,它应该从预训练语料库中移除。理想情况下,添加更多上下文不应该影响后续文本的可预测性。然而,我们观察到在不正确拼接的文本的情况下会出现例外,比如失败的HTML解析、随机社交媒体片段以及源自复杂布局的源中的识别错误等其他情况。请注意,我们仅基于困惑度差异而不是困惑度本身来过滤数据,这可以在很大程度上减少估计器本身引入的偏差(使用哪个模型来计算困惑度)。困惑度估计器的偏差已在 Wettig et al. (2024);Sachdeva et al. (2024)中讨论。
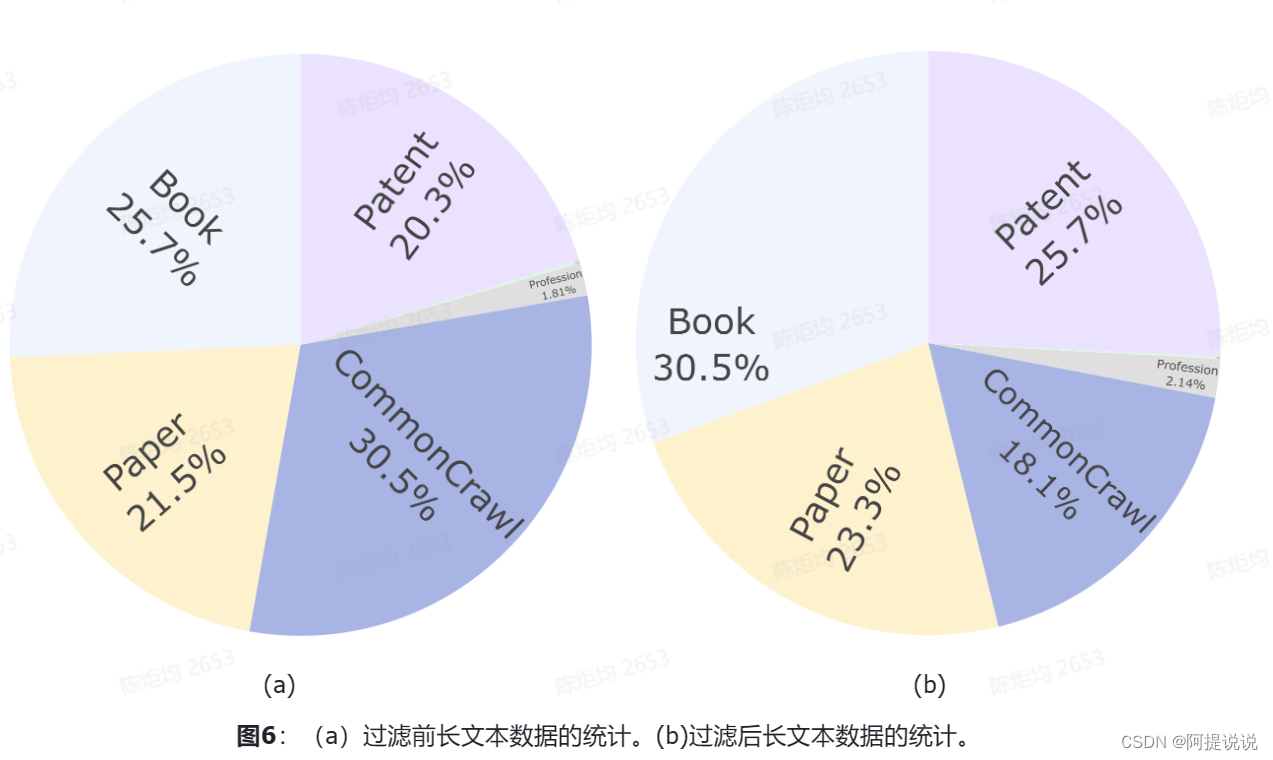
阈值选择 选择适当的阈值是数据过滤过程的关键且具有挑战性的部分,这一挑战因我们构建了许多过滤器而变得更加严峻。我们在设定阈值方面有两个经验教训: 为每个领域定制阈值,而不是寻求一个普遍的解决方案。例如,针对连词的统计过滤器不适用于通常没有任何连词的代码数据。同样,教科书、研究论文、小说和专利各自具有独特的特征。一个普遍的阈值可能会错误地分类大量数据。同样的逻辑也适用于在不同语言之间设定阈值;因此,我们针对每个领域单独调整阈值。 使用验证集来简化过程,只关注边缘案例。与基于学习的特征提取器或评分器不同,我们的统计和困惑度过滤器在同一领域内产生平滑的结果。这使我们能够专注于靠近阈值的样本,简化阈值的调整过程,因为我们只需要决定是降低还是提高它们。Lv et al. (2024) 展示了特定过滤器在数据集上的得分,证明了我们提出的过滤器的可解释性。 图6 展示了经过所有提出的过滤器处理,数据的前后分布的情况。整个过滤过程移除了大量网页(Common Crawl)和专利数据,而大多数书籍和论文数据都被保留了下来。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-03-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号