[MYSQL] 数据恢复, 无备份, 只剩一个 ibd 文件 怎么恢复数据?
原创
[MYSQL] 数据恢复, 无备份, 只剩一个 ibd 文件 怎么恢复数据?
原创
大大刺猬
发布于 2024-04-10 14:29:12
发布于 2024-04-10 14:29:12
背景
环境: mysql 8.0
不小心删除了mysql数据目录, 但还剩个.ibd文件在. 没得备份, 没得binlog , 要恢复这个ibd文件里面的数据.
啊. 这..... 先打一顿没有做备份的dba
分析
我们通常是使用备份+binlog来恢复数据, 但这次只有个孤零零的ibd文件.
我们知道mysql 8.0 的ibd文件也包含元数据信息(你问我怎么知道的?). 所以我们先恢复表结构, 再恢复数据.
恢复表结构
如果开发有相关的DDL更好. 没得的话. 我们就自己解析.
mysql 8.0的ibd文件存在sdi page 记录元数据信息的, 压缩的json格式. 我们可以使用官方自带的 ibd2sdi 解析出来这个json信息.
ibd2sdi /data/mysql_3314/mysqldata/ibd2sql/ddcw_alltype_table.ibd 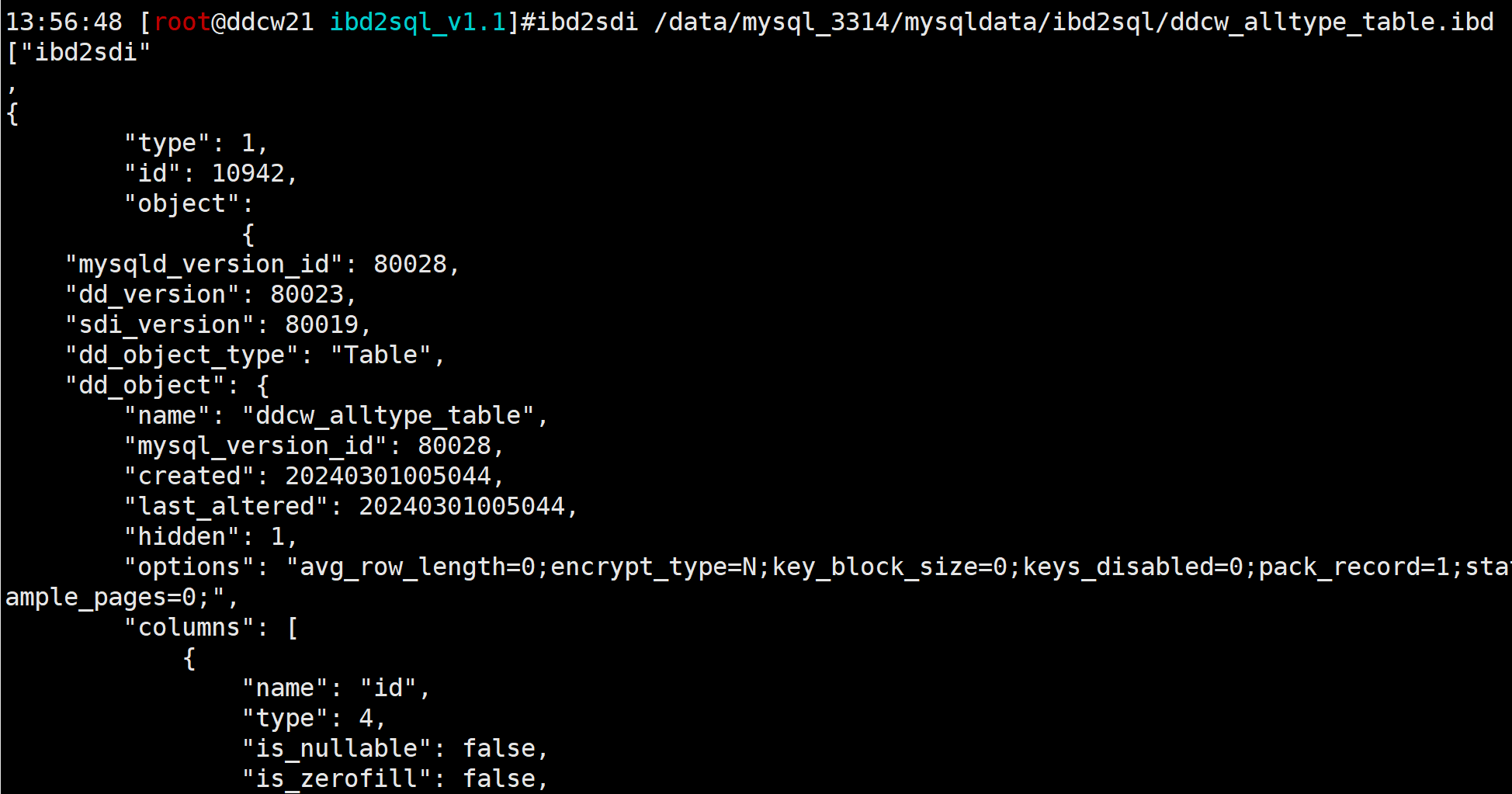
但还要自己去拼接DDL, 太麻烦了.
所以我们使用其它工具来提取DDL, 这里就使用 ibd2sql 来提取(为啥使用这个呢? 因为是我写的 -_- 用起来顺手)
python3 main.py /tmp/ddcw_alltype_table.ibd --ddl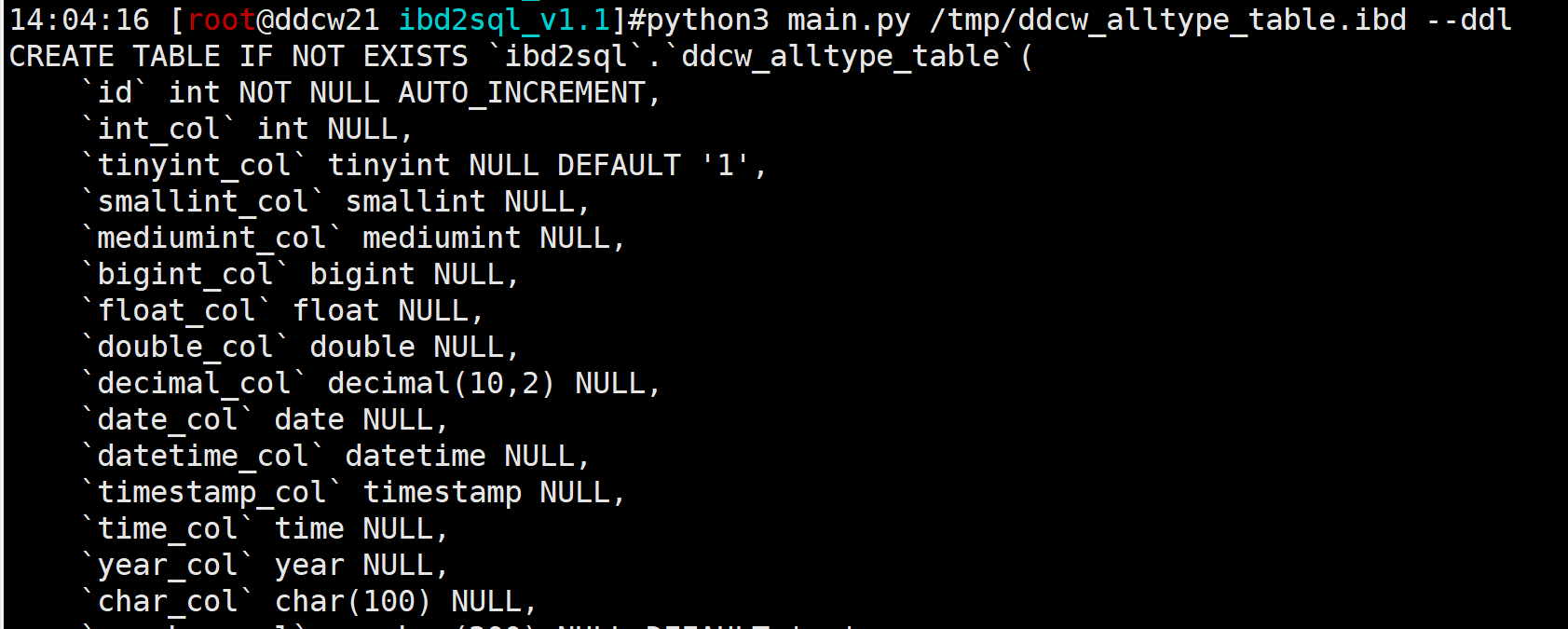
现在DDL已经提取出来了. 我们先创建个测试环境, 创建相同的库, 再使用上面的DDL去恢复相关的表结构
CREATE TABLE IF NOT EXISTS `ibd2sql`.`ddcw_alltype_table`(
`id` int NOT NULL AUTO_INCREMENT,
`int_col` int NULL,
`tinyint_col` tinyint NULL DEFAULT '1',
`smallint_col` smallint NULL,
`mediumint_col` mediumint NULL,
`bigint_col` bigint NULL,
`float_col` float NULL,
`double_col` double NULL,
`decimal_col` decimal(10,2) NULL,
`date_col` date NULL,
`datetime_col` datetime NULL,
`timestamp_col` timestamp NULL,
`time_col` time NULL,
`year_col` year NULL,
`char_col` char(100) NULL,
`varchar_col` varchar(200) NULL DEFAULT 'aa',
`binary_col` binary(10) NULL,
`varbinary_col` varbinary(20) NULL,
`bit_col` bit(4) NULL,
`enum_col` enum('A','B','C') NULL,
`set_col` set('X','Y','Z') NULL,
`josn_type` json NULL,
`newcol` varchar(200) NULL DEFAULT 'aa',
`newcol2` varchar(200) NULL DEFAULT 'aa',
`newcoldasdas2` varchar(300) NULL DEFAULT 'bbaa',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;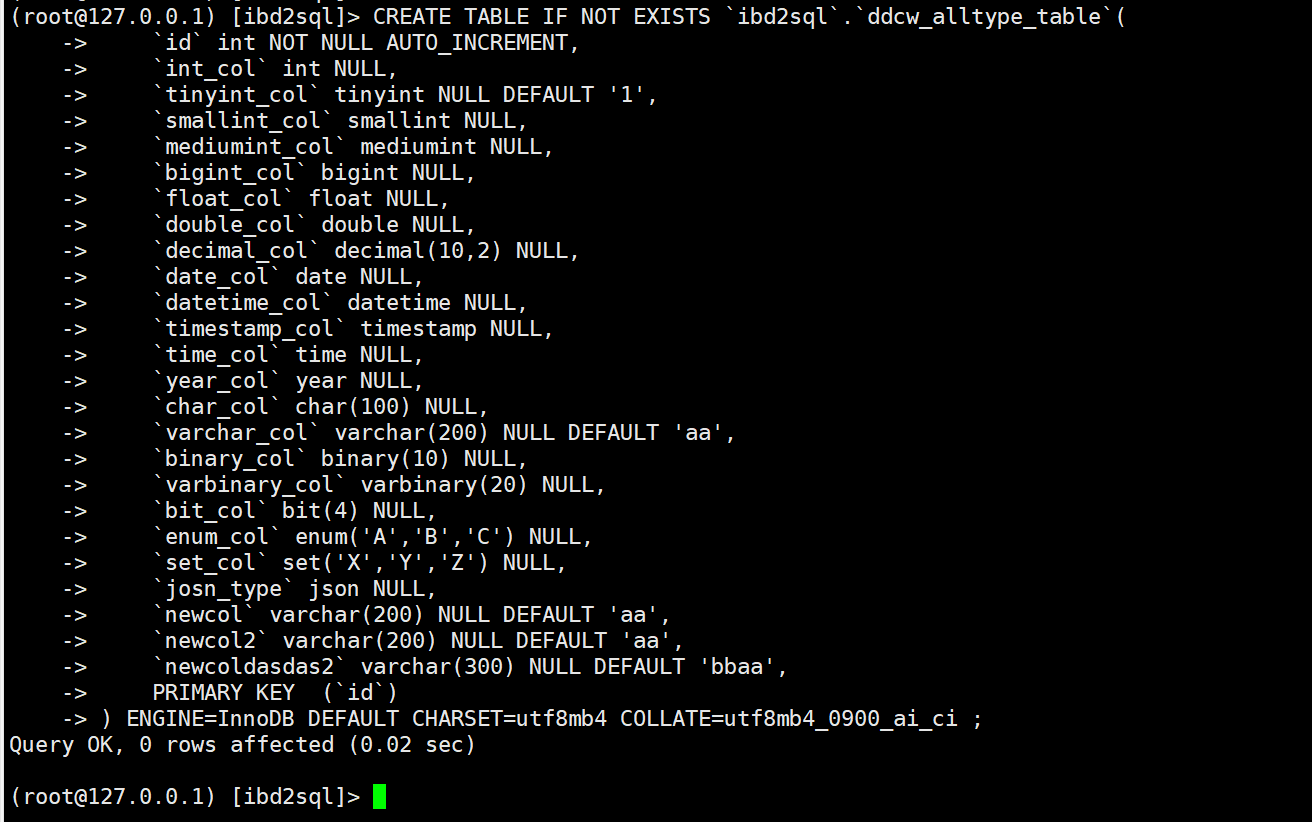
恢复数据
恢复了表结构后, 就该恢复数据了.
方法1(推荐)
mysql可以使用discard table来删除表空间, 然后使用import tablespace 来导入表空间. 我们就使用这种方式来恢复数据.
官网介绍: https://dev.mysql.com/doc/refman/8.0/en/innodb-table-import.html
-- 移除表空间
alter table ddcw_alltype_table discard tablespace;
-- 拷贝要恢复的表空间
system cp -ra /tmp/ddcw_alltype_table.ibd /data/mysql_3314/mysqldata/ibd2sql
-- 导入要恢复的表空间
alter table ddcw_alltype_table import tablespace;
-- 验证数据
select count(*) from ddcw_alltype_table;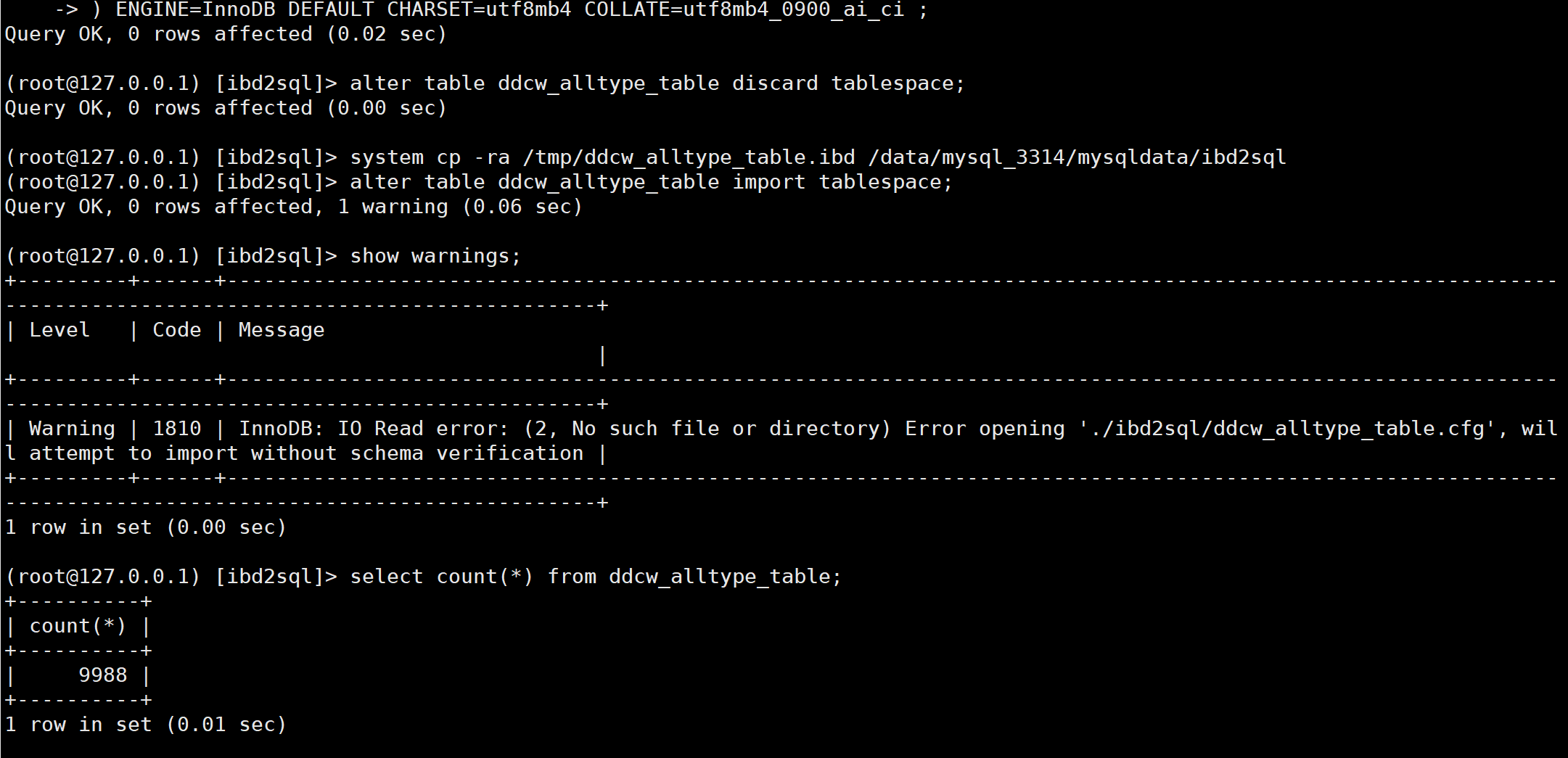
这种方法非常简单方便, 推荐使用.
但有可能会失败(人生不总是一帆风顺)
方法2
如果无法导入表空间的话, 我们还可以解析这个ibd文件得到相关的数据. 这种工具市面上较少 我这里还是使用 ibd2sql (夹带私货-_-)
目前不支持溢出页(默认置为NULL). 也不建议在mysql里面存储大数据.
数据类型基本上都支持, 不支持空间坐标字段(为啥? 因为要太复杂了, 一时半会解析不了...)
python3 main.py /tmp/ddcw_alltype_table.ibd --sql > /tmp/ddcw_alltype_table.sql
然后我们就可以把解析出来的sql导入数据库了. 当然也可以解析的时候直接通过管道写入数据库
mysql -h127.0.0.1 -P3314 -p123456 < /tmp/ddcw_alltype_table.sql
总结
虽然只剩一个ibd文件也能恢复数据, 但还是要备份. 毕竟这些工具不一定能用. (多数都有备份, 这些工具使用例子就少, 支持范围就小)
如果ibd2sql工具使用有啥问题, 请到github提相关issue, 附上ibd2sql版本和mysql版本, 最好能附上debug日志.
这里就不附下载地址了, 最新版未打包哈, 需下载源码使用(python3写的, 无依赖包, 直接使用就行.)
附上ibd2sql的用法:
14:20:37 [root@ddcw21 ibd2sql_v1.1]#python3 main.py --help
usage: main.py [-h] [--version] [--ddl] [--sql] [--delete] [--complete-insert] [--force] [--set] [--multi-value] [--replace]
[--table TABLE_NAME] [--schema SCHEMA_NAME] [--sdi-table SDI_TABLE] [--where-trx WHERE_TRX]
[--where-rollptr WHERE_ROLLPTR] [--where WHERE] [--limit LIMIT] [--debug] [--debug-file DEBUG_FILE]
[--page-min PAGE_MIN] [--page-max PAGE_MAX] [--page-start PAGE_START] [--page-count PAGE_COUNT]
[--page-skip PAGE_SKIP] [--parallel PARALLEL]
[FILENAME]
解析mysql8.0的ibd文件 https://github.com/ddcw/ibd2sql
positional arguments:
FILENAME ibd filename
options:
-h, --help show this help message and exit
--version, -v, -V show version
--ddl, -d print ddl
--sql print data by sql
--delete print data only for flag of deleted
--complete-insert use complete insert statements for sql
--force, -f force pasrser file when Error Page
--set set/enum to fill in actual data instead of strings
--multi-value single sql if data belong to one page
--replace "REPLACE INTO" replace to "INSERT INTO" (default)
--table TABLE_NAME replace table name except ddl
--schema SCHEMA_NAME replace table name except ddl
--sdi-table SDI_TABLE
read SDI PAGE from this file(ibd)(partition table)
--where-trx WHERE_TRX
default (0,281474976710656)
--where-rollptr WHERE_ROLLPTR
default (0,72057594037927936)
--where WHERE filter data(TODO)
--limit LIMIT limit rows
--debug, -D will DEBUG (it's too big)
--debug-file DEBUG_FILE
default sys.stdout if DEBUG
--page-min PAGE_MIN if PAGE NO less than it, will break
--page-max PAGE_MAX if PAGE NO great than it, will break
--page-start PAGE_START
INDEX PAGE START NO
--page-count PAGE_COUNT
page count NO
--page-skip PAGE_SKIP
skip some pages when start parse index page
--parallel PARALLEL, -p PARALLEL
parse to data/sql with N threads.(default 4) TODO原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号