每日论文速递 | UCB提出RAFT-检索增强微调训练方法

每日论文速递 | UCB提出RAFT-检索增强微调训练方法

zenRRan
发布于 2024-04-11 16:16:09
发布于 2024-04-11 16:16:09
深度学习自然语言处理 分享 整理:pp

摘要:在大型文本数据集上预训练大型语言模型(LLM)现已成为一种标准模式。在许多下游应用中使用这些 LLM 时,通常会通过基于 RAG 的提示或微调将新知识(如时间关键新闻或私人领域知识)添加到预训练模型中。然而,模型获取此类新知识的最佳方法仍是一个未决问题。在本文中,我们提出了检索增强微调法Retrieval Augmented FineTuning(RAFT),这是一种训练方法,可提高模型在 "开卷 "领域设置中回答问题的能力。在 RAFT 中,给定一个问题和一组检索到的文档,我们训练模型忽略那些无助于回答问题的文档,我们称之为干扰文档。RAFT 通过逐字引用相关文档中有助于回答问题的正确序列来实现这一点。这与 RAFT 的思维链式响应相结合,有助于提高模型的推理能力。在特定领域的 RAG 中,RAFT 持续提高了模型在 PubMed、HotpotQA 和 Gorilla 数据集上的性能,为改进预训练 LLM 的域内 RAG 提供了一个后训练配方。RAFT 的代码和演示已开源。
https://arxiv.org/abs/2403.10131
Q1: 这篇论文试图解决什么问题?
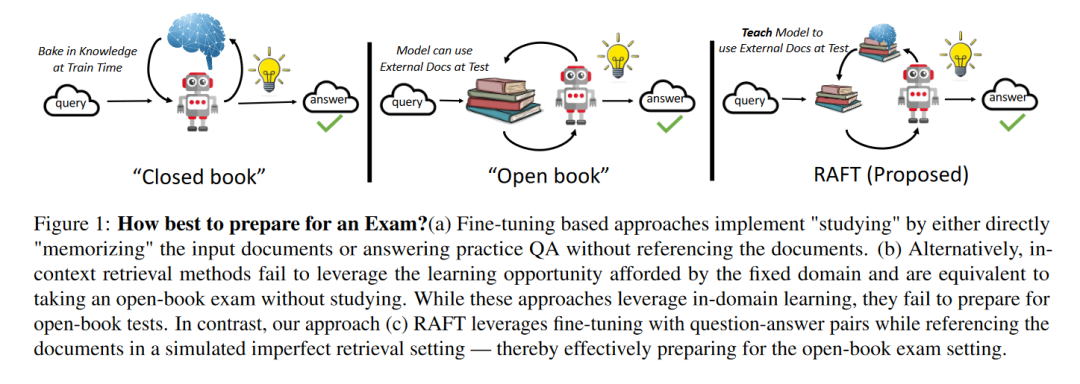
A:这篇论文试图解决的问题是如何将预训练的大型语言模型(LLMs)适应于特定领域的检索增强型生成(Retrieval Augmented Generation, RAG)任务。具体来说,研究者们提出了一种名为Retrieval Augmented Fine Tuning (RAFT)的训练方法,旨在改善模型在“开卷”式的特定领域设置中回答问题的能力。RAFT通过训练模型忽略那些对回答问题没有帮助的文档(称为干扰文档),并且通过引用相关文档中正确的序列来回答问题,从而提高了模型的推理能力。此外,RAFT还结合了链式思考(chain-of-thought)风格的响应来增强模型的表现。通过在PubMed、HotpotQA和Gorilla数据集上的测试,RAFT在特定领域的RAG任务中持续提升了模型的性能。
Q2: 有哪些相关研究?
A:这篇论文提到了与其研究相关的几个领域和工作,包括:
- 检索增强型语言模型 (Retrieval-Augmented Language Models, RAG): 这些模型通过集成检索模块来增强语言模型,显著提高了各种自然语言处理(NLP)任务的性能,包括语言建模和开放域问答。
- 记忆化 (Memorization): 有关大型神经语言模型是否真正“理解”文本的问题,一些研究探讨了模型是否仅仅依赖于表面模式的记忆化。
- 大型语言模型的微调 (Finetuning of LLMs): 为了使这些基础模型适应下游任务,微调已成为一种普遍的方法。研究者们还探索了参数高效的微调方法,例如提示调优(Prompt Tuning)、前缀调优(Prefix-Tuning)、P-Tuning 和基于低秩的微调。
- 针对RAG任务的微调 (Finetuning for RAG): 一些论文探索了针对RAG任务的预训练LLM的微调,这些工作集中在构建RAG任务的微调数据集,并训练模型在这些任务上表现良好。
- 长上下文的缩放 (Long Context Scaling): 一些研究专注于长上下文的缩放,以提高基础模型的性能。
- 隐私风险 (Privacy Risks): 有关一般用途语言模型的隐私风险的研究,探讨了训练数据中的重复可能导致的隐私泄露问题。
这些相关研究为RAFT提供了理论和技术背景,并且RAFT在这些现有工作的基础上进行了创新和改进。
Q3: 论文如何解决这个问题?
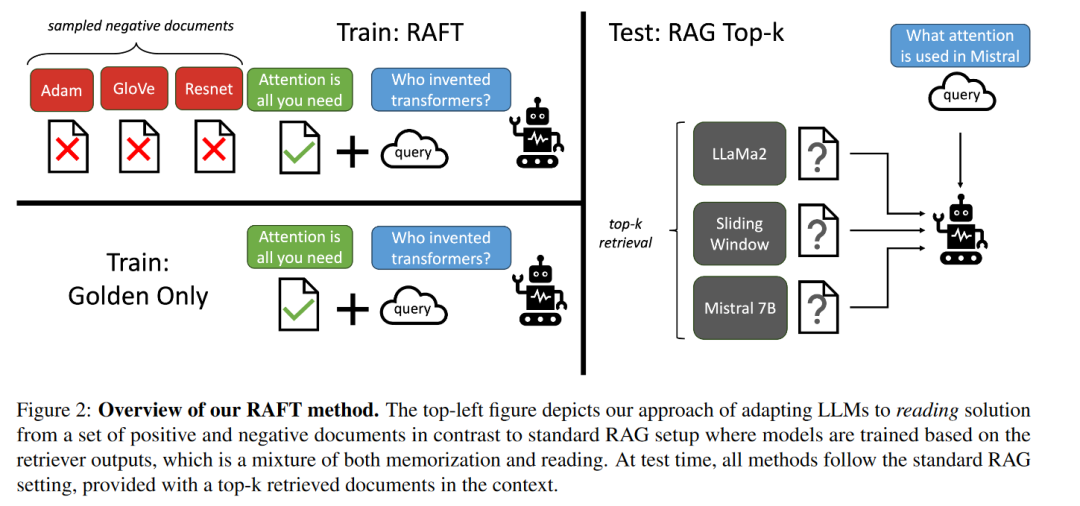
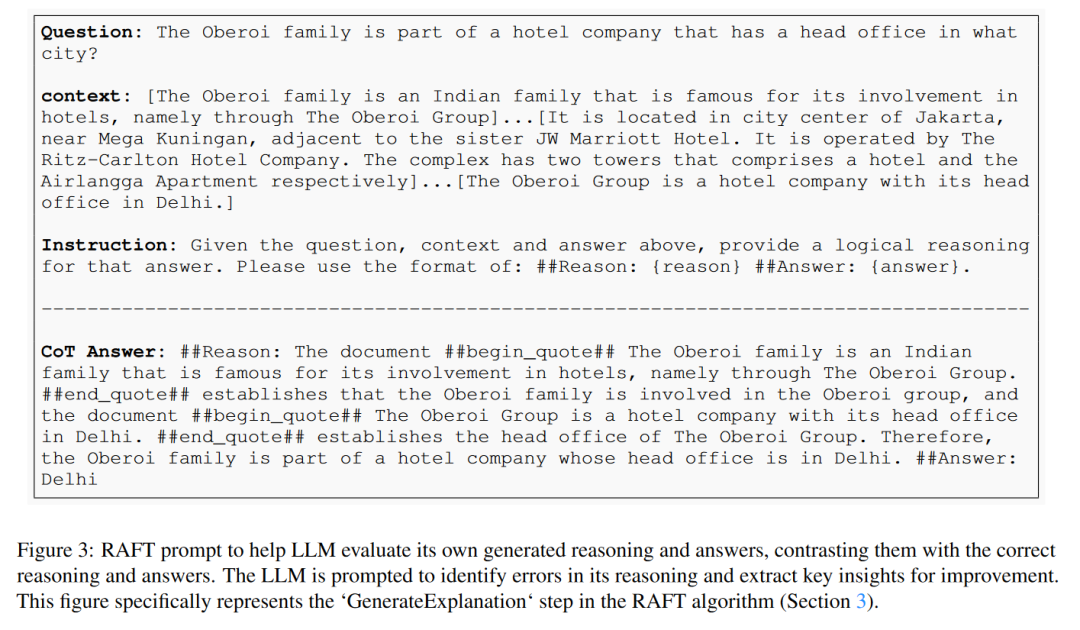
A:论文提出了一种名为Retrieval Augmented Fine Tuning (RAFT)的训练方法来解决这个问题。RAFT的核心思想是结合监督式微调(Supervised Fine-Tuning, SFT)和检索增强型生成(Retrieval-Augmented Generation, RAG)来适应特定领域的知识。以下是RAFT解决这个问题的主要步骤:
- 训练数据的准备:对于每个训练样本,RAFT包括一个问题(Q)、一组文档(Dk,包括“oracle”文档和“distractor”干扰文档)以及一个链式思考风格的正确答案(A*)。“oracle”文档是指包含回答问题所需信息的文档,而“distractor”文档则不包含相关信息。
- 模型训练:在训练过程中,模型被训练以从提供的文档和问题中生成答案。这包括在存在干扰文档的情况下,训练模型识别和忽略不相关的信息。RAFT通过在训练集中引入一定比例的不包含“oracle”文档的数据来迫使模型不仅仅依赖记忆答案,而是学会从上下文中提取信息。
- 链式思考 (Chain-of-Thought, CoT):RAFT强调生成包含推理过程的答案,这样的答案不仅给出了最终答案,还展示了如何基于引用的相关文本来得出这个答案。这种方法帮助模型在回答问题时展示其推理过程,从而提高了模型的准确性和可靠性。
- 测试时的表现:在测试阶段,模型会接收到问题和通过检索增强管道检索到的前k个文档,并基于这些信息生成答案。RAFT的训练方法使得模型在测试时能够更好地处理检索到的文档,包括在存在干扰信息的情况下仍能准确回答问题。
- 实验评估:论文通过在PubMed、HotpotQA和Gorilla数据集上的实验来评估RAFT与其他基线方法的性能,并证明了RAFT在特定领域RAG任务中的有效性。
通过这些方法,RAFT旨在提高预训练语言模型在特定领域内回答问题的能力,同时确保对不准确检索的鲁棒性。
Q4: 论文做了哪些实验?
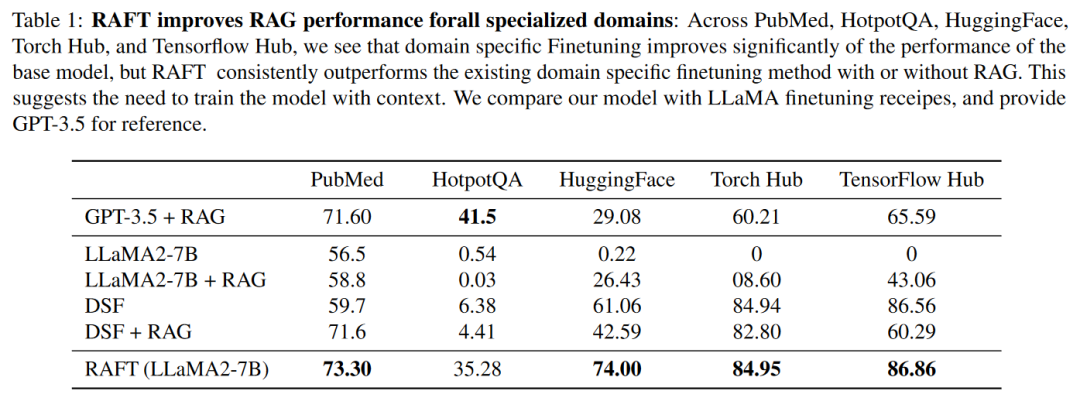
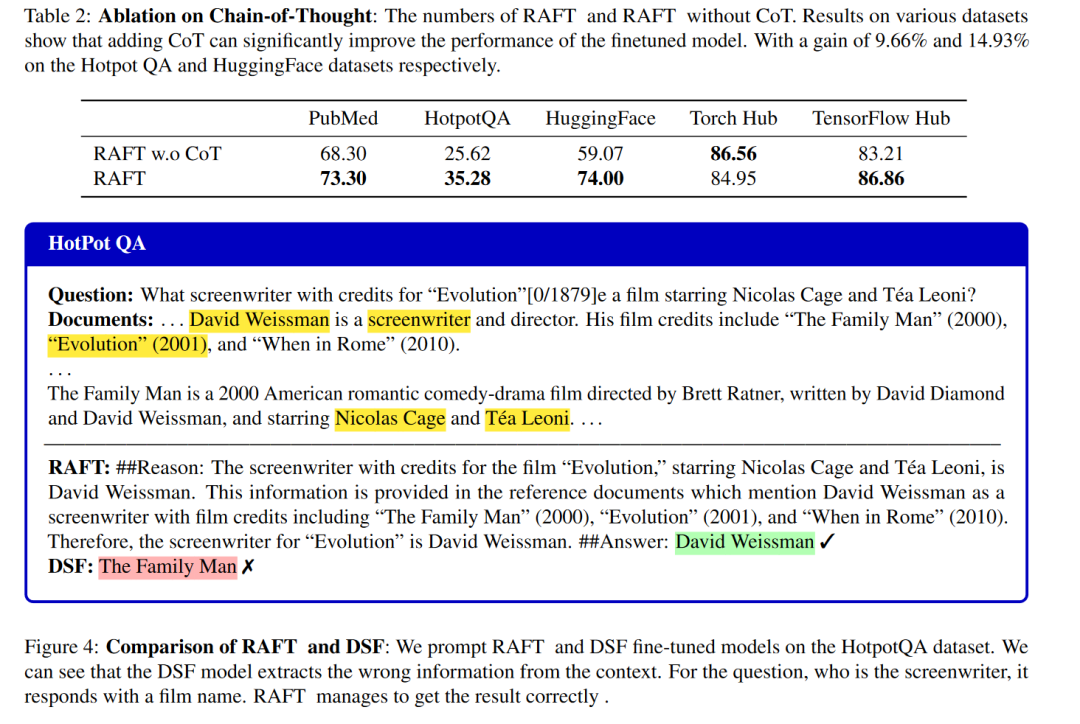
A:论文中进行了一系列实验来评估RAFT方法的有效性,并与其他基线方法进行比较。具体的实验包括:
- 数据集选择:使用了多个数据集进行实验,包括PubMed QA、HotpotQA、HuggingFace Hub、Torch Hub和TensorFlow Hub的Gorilla数据集。这些数据集涵盖了从开放域到特定领域的多样化场景。
- 基线方法:对比了RAFT与多种基线方法,包括:
- 无提示的LlaMA2-7B聊天模型(0-shot prompting)。
- 带有RAG的LlaMA2-7B聊天模型。
- 特定领域微调的模型(DSF)。
- 带有RAG的特定领域微调模型(DSF + RAG)。
- 性能评估:对RAFT模型在各个数据集上的性能进行了评估,并与基线模型进行了比较。评估指标可能包括准确率、F1分数、BLEU分数等。
- 链式思考 (Chain-of-Thought, CoT) 的影响:进行了消融实验来分析链式思考方法对模型性能的影响。比较了包含CoT的RAFT模型与不包含CoT的RAFT模型的性能。
- 定性分析:通过具体的示例比较了RAFT和DSF模型在处理特定问题时的差异,展示了RAFT在理解上下文和提取相关信息方面的优势。
- 训练数据中包含“oracle”文档的比例:研究了训练数据中包含“oracle”文档的比例(P%)对模型性能的影响。探讨了不同数据集上最佳P%的值。
- 测试时文档数量的变化:评估了训练时不同数量的干扰文档对模型在测试时面对不同数量检索结果的鲁棒性的影响。
- 与更大模型的比较:将RAFT模型与更大的GPT-3.5模型进行了比较,以展示RAFT在特定领域RAG任务中的相对优势。
这些实验结果表明RAFT在特定领域的RAG任务中持续提升了模型的性能,并且在处理检索到的文档时表现出更好的鲁棒性。

Q5: 有什么可以进一步探索的点?
A:尽管RAFT在特定领域的RAG任务中取得了显著的成果,但仍有一些方向可以进行进一步的探索:
- 超参数优化:进一步研究和优化RAFT中的关键超参数,如训练数据中包含“oracle”文档的比例(P%)以及干扰文档的数量,以找到最佳的训练配置。
- 不同领域的泛化能力:在更多不同领域的数据集上测试RAFT的泛化能力,探索其在更广泛的应用场景中的有效性。
- 模型规模的影响:研究不同规模的模型在应用RAFT方法后的性能差异,探讨模型大小对结果的影响。
- 检索模块的改进:探索更先进的检索技术,以提供更相关和准确的文档,从而可能进一步提升RAFT的性能。
- 长期记忆和上下文理解:研究如何改进模型以更好地处理长文本和复杂上下文,特别是在需要理解和整合多个文档信息时。
- 交互式学习:探索模型在与用户交互时的学习能力,例如通过提问-回答-反馈循环来提升模型的领域适应性。
- 隐私和安全性:研究RAFT在处理敏感数据时的隐私和安全性问题,提出相应的解决方案来保护用户数据。
- 多模态和跨语言能力:将RAFT应用于多模态数据(如文本与图像结合)和跨语言场景,以增强模型的多功能性和适应性。
- 可解释性和透明度:提高RAFT生成答案的可解释性,使模型的推理过程对用户更加透明和易于理解。
- 实际部署和应用:研究RAFT在实际应用中的部署问题,包括性能、成本、可扩展性和维护性等方面的考量。
这些方向可以为未来的研究提供新的思路,并有助于进一步提升RAFT方法的性能和实用性。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
- 标题: RAFT: Adapting Language Model to Domain Specific RAG
- 作者: Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
- 摘要: 论文提出了一种名为Retrieval Augmented Fine Tuning (RAFT)的训练方法,旨在改善大型语言模型(LLMs)在特定领域内回答问题的能力,特别是在“开卷”式的设置中。RAFT通过训练模型忽略干扰文档并引用相关文档中的准确信息来回答问题,从而提高模型的推理能力。
- 引言: 介绍了大型语言模型在通用知识推理任务中的进步,以及将这些模型适应于专业领域的重要性。论文聚焦于如何将预训练的LLMs适应于检索增强型生成(RAG)在专业领域的应用。
- LLMs for Open-Book Exam: 通过考试的类比解释了开放域和特定领域开放书籍考试的区别,并讨论了现有方法的局限性。
- RAFT: 详细介绍了RAFT方法,包括如何准备训练数据,如何进行微调,以及如何通过链式思考(Chain-of-Thought, CoT)生成答案。
- 评估: 展示了RAFT在多个数据集上的性能,并与其他基线方法进行了比较。结果表明RAFT在特定领域的RAG任务中持续提升了模型的性能。
- RAFT Generalizes to Top-K RAG: 探讨了RAFT如何通过训练时包含不同数量的干扰文档来增强模型在测试时面对不同数量检索结果的鲁棒性。
- 相关工作: 回顾了与RAFT相关的研究领域,包括检索增强型语言模型、记忆化、大型语言模型的微调、以及针对RAG任务的微调等。
- 结论: 总结了RAFT作为一种训练策略,能够显著提升模型在特定领域内回答问题的性能,并指出了未来可能的研究方向。论文的核心贡献是提出了RAFT方法,它结合了监督式微调和检索增强型生成,通过训练模型处理干扰信息并利用链式思考生成答案,从而在特定领域的RAG任务中取得了显著的性能提升。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号