SIGIR'24 | 打破长度障碍:LLM增强的长文本用户行为CTR预测

SIGIR'24 | 打破长度障碍:LLM增强的长文本用户行为CTR预测

秋枫学习笔记
发布于 2024-04-11 20:10:59
发布于 2024-04-11 20:10:59
1. 导读
LLM4CTR在训练推理中主要存在以下问题:LLM在处理长文本用户行为时的效率很低,随着用户序列的增长,LLM的效率无法对数十亿用户和商品进行训练。
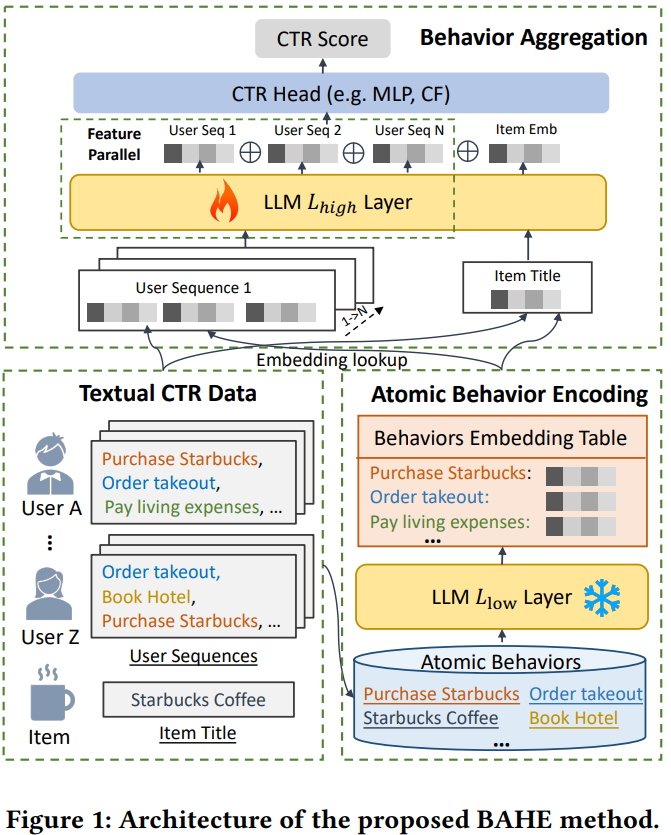
本文提出了行为聚合分层编码(BAHE)来提高基于LLM的CTR建模的效率。BAHE提出了一种新的分层架构,将用户行为的编码与行为间交互解耦。
- 首先,为了防止相同用户行为的重复编码产生计算冗余,BAHE使用LLM的预训练浅层从用户序列中提取最细粒度的原子用户行为emb,并将其存储在离线数据库中。
- 然后,LLM的更深、可训练的层学习复杂的行为间交互,生成用户emb。这种分离允许高级用户表征的学习独立于低级行为编码,从而显著降低计算复杂性。
- 最后,将这些细化的用户emb与对应的商品emb结合到CTR模型中,计算CTR得分。
省流:
- 用户之间可能存在相同行为,比如都"购买星巴克",用LLM的浅层对这些行为做离线编码存储在数据库,这样不同用户的重复行为就不需要重复编码了;通过编码和聚合后,行为编码为d维这样可以使得我们可以用更长的序列,因为本来一个行为是K个d维的token,现在变成了一个,存储的编码相当于是一个emb table,对于不同的行为直接去查找,然后再LLM深层进行行为之间的交互
- 行为有多种,比如点击,购买等,不同行为组成不同的行为序列,对于不同的行为序列可以并行执行上面的步骤得到对应的emb,然后拼接得到用户emb
2.方法
alt text
行为聚合分层编码
对于用户i和j, 原子行为序列分别是
,
。以往的基于LLM的CTR建模效率比较低:
- 冗余行为编码:相同的行为在不同用户的序列中冗余编码。如上述两个行为序列中都包含
,会重复对这些行为进行编码和计算,导致计算冗余。
- 紧密耦合:行为
,具有固定的含义,而它们的顺序因用户而异。现有的方法将表征提取和序列理解耦合在一起,当行为发生变化时,就需要更新,而这种更新的消耗是比较大的。
原子行为编码(ABE)
BAHE首先使用LLM的预训练低层(
)对所有行为进行编码, 然后将它们离线存储,作为行为嵌入表E。然后,LLM的更深的层将利用E作为token对应的表,学习用户行为之间的交互。原子行为的编码如下所示:
其中
是原子行为, 由K个文本token组成,所以
有得到d维的emb,其中𝑑 是维度。
是池化函数将
的tensor聚合为d维。BAHE将编码从token级别转换为行为级别,从而将编码长度从token数量减少到原子行为的数量。
行为聚合(BA)
获得原子行为嵌入表E后, 对于每一个原子行为
,可以从E中检索对应的表征,对于用户u的第n个序列
,可以表示为下式,序列长度为M。
然后利用LLM的深层进行行为交互的学习,表示如下,
表示用户u的第n个序列的表征。
特征并行
为了避免LLM的注意力计算随着用户序列的数量的增加而呈指数级增长,在用
处理用户行为的时候,对于n条序列可以并行处理提高效率,然后再将他们拼接起来
得到用户表征
和商品表征
后,拼接送入ctr模型,得到ctr打分
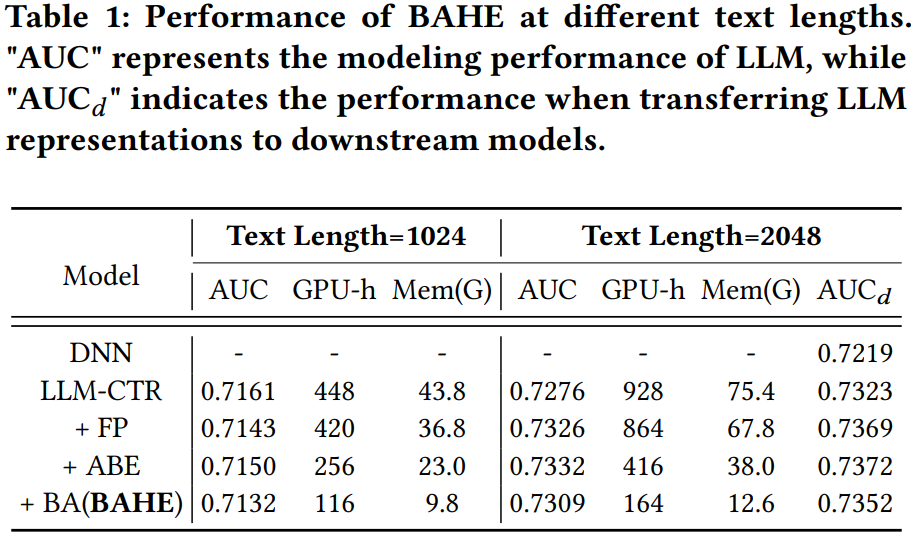
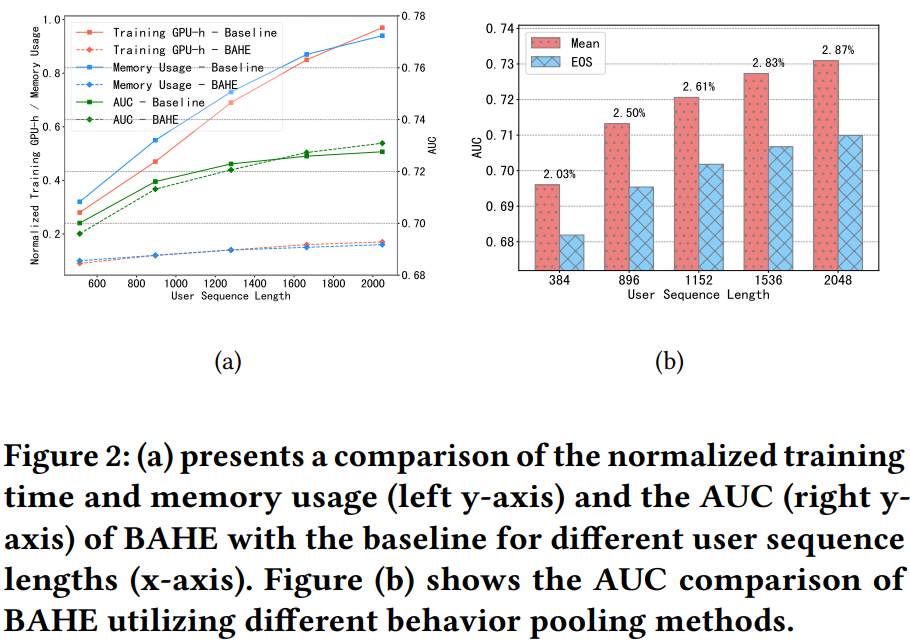
3. 结果
从结果可以发现,在维持模型性能的同时可以显著降低训练时间和显存。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号