RTC @scale 2024 | RTC 下基于机器学习的带宽估计和拥塞控制

RTC @scale 2024 | RTC 下基于机器学习的带宽估计和拥塞控制

用户1324186
发布于 2024-04-12 13:44:10
发布于 2024-04-12 13:44:10
来源:RTC @scale 2024 演讲题目:ML-based Bandwidth Estimation and Congestion Control for RTC 主讲人:Santhosh Sunderrajan, Liyan Liu 视频地址:https://atscaleconference.com/videos/machine-learning-ml-based-bandwidth-estimation-and-congestion-control-for-rtc/ 内容整理:李冰奇 本次演讲中,详细讨论如何通过针对不同的网络类型,使用基于 ML 解决方案实现质量和可靠性的提升。早在2021年,Meta 就提出了带宽估计改进方法,提高了高带宽网络的质量,但在低带宽网络中出现可靠性下降。类似地,在2021年,Meta 还提出另外一个拥塞控制机制进行带宽估计,对于低带宽网络的可靠性有所提高,但在2022年初,发现这种方法在质量上有很多下降,演讲者团队发现需要按网络类型优化不同的网络。因此,演讲者团队制定一个基于ML的解决方案。本次演讲主要包括三个方面内容,一是 RTC 场景下,基于机器学习方法的网络表征和网络预测,二是基于机器学习的解决方案面临的挑战,三是下一步计划。
研究背景
演讲者在进行介绍基于机器学习的带宽预测和拥塞控制方法之前,先介绍了当前 webRTC 中应用的基于 Google 拥塞控制机制的带宽预测方法(GCC)。
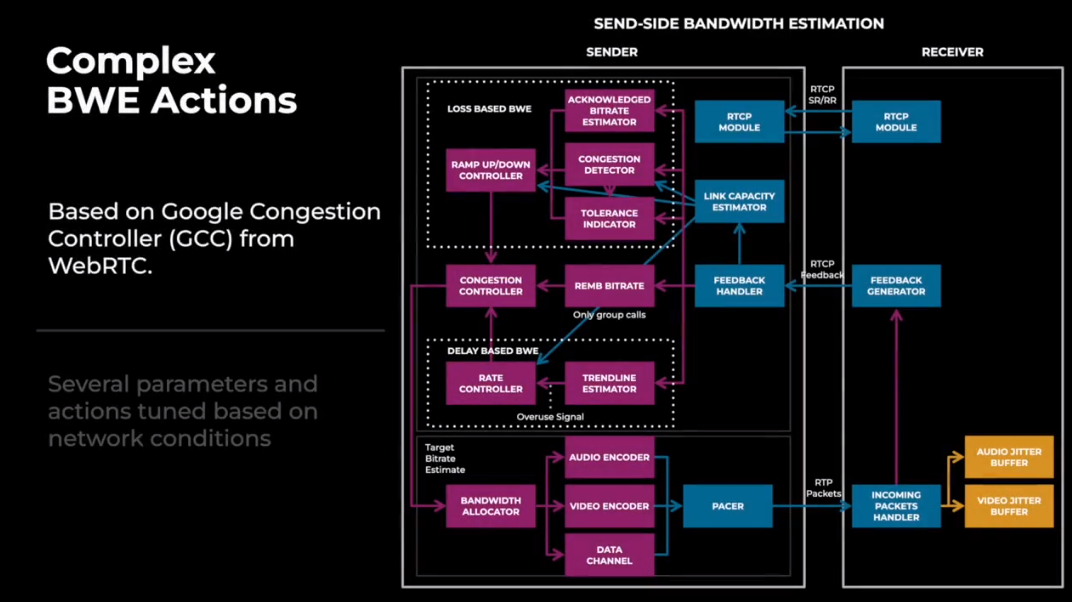
图 1. GCC
GCC 是发送端的带宽预测算法,主要基于接收端反馈的信息。GCC 包含几个模块,例如基于丢包的带宽预测模块,基于延迟的带宽预测模块,发送码率估计模块。上图展示这几个模块,并描述了这些模块如何使用接收端反馈回来的信息。这些模块内部都有很多基于网络条件的参数。针对不同的网络条件,GCC 需要调整不同的参数来适应不同的网络场景。

图 2. GCC存在的问题
这就导致即使在多次实验迭代完成并推出后,也不清楚最佳参数是否仍然适用。另外,带宽预测系统本身非常复杂,向其中添加更多参数,难以维护和处理大量分支的复杂代码逻辑。
基于 ML 的带宽预测解决方法

图 3. 为什么用ML
ML模型为我们提供了一种跨多个子系统采取网络行动的整体方法,例如带宽估计器、网络弹性和传输,这为我们提供了一个很好的整体策略来应对不同的网络条件以及我们想要在其中进行什么样的优化。
网络表征
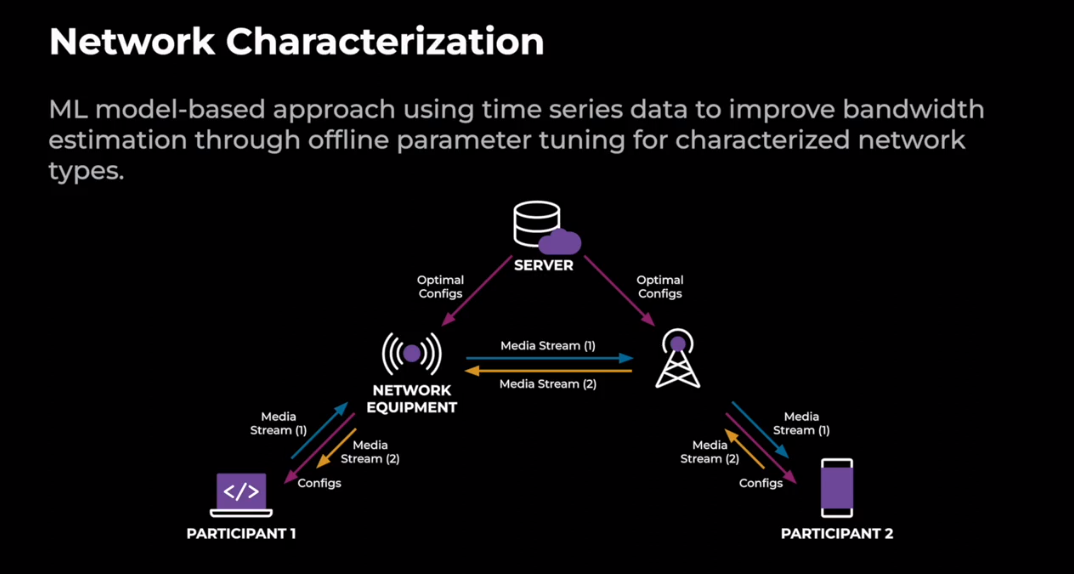
图 4. 网络表征
上面这张图定义了什么是网络特征,图中的例子有两个端点,这两个端点可以是移动设备,也可以是网络设备。在这个例子中,我们展示了一个P2P连接,离线调优的最优参数存储在服务器端,而在线推理在客户端完成,所以我们接下来讲离线模型学习和离线参数调优。
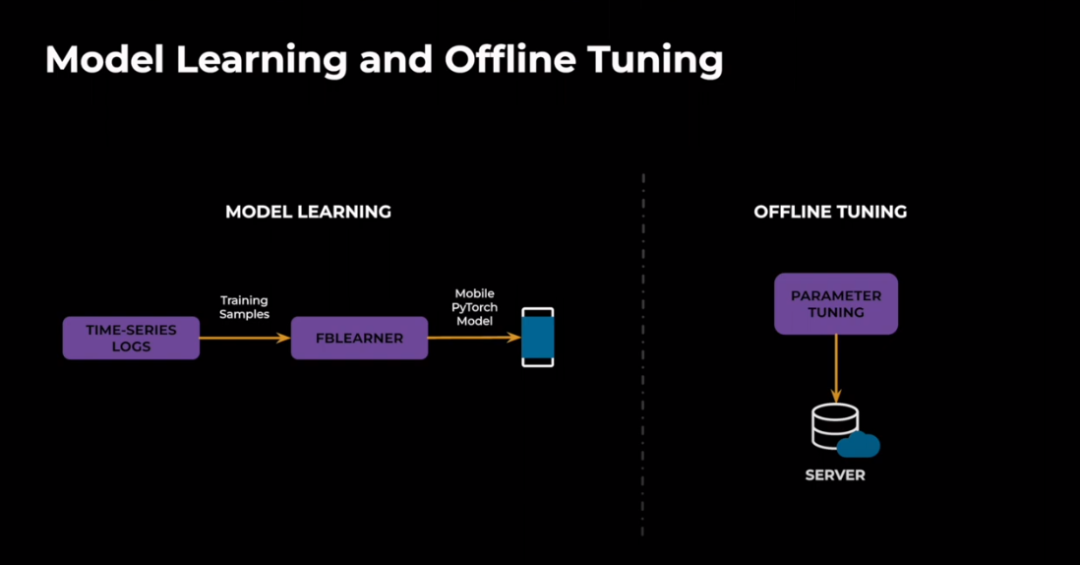
图 5.
我们利用过去网络条件的时间序列日志作为训练样本。我们使用时间序列数据,因为网络信号是时变的和时间敏感的。因此,聚合矩阵不能完全捕捉网络动态下网络的全部特征。这些时间序列锁可以是模拟的网络条件或生产锁。我们还开发了一个名为 FBLearner Workflow 的内部工具,用于使用 Pytorch 进行模型训练。我们还在客户端构建了客户端模型部署信息和推理管道。对于离线调整,我们使用模拟来运行检测类型的网络配置文件。然后我们将根据指标改进的指标为模块选择最佳参数,例如,我们可以使用视频质量。
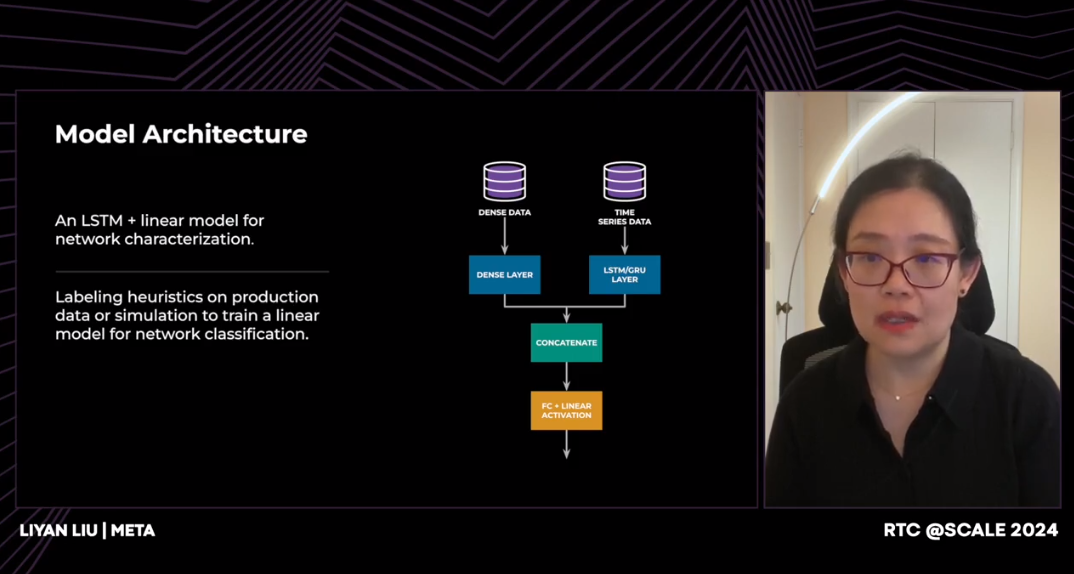
图 6. 离线模型训练
对于模型架构,由于我们同时在时间序列数据和非时间序列数据上进行训练,我们构建了一个模型架构,可以同时接受时间序列数据和非时间序列数据的输入。所以对于时间序列数据,我们将通过一个 LSTM长短期记忆层,将时间序列输入转换为向量表示。对于非时间序列数据,我们将直接通过一个全连接层。因此,这两个向量将连接在一起以完全表示过去的网络状况。然后我们将通过另一个全连接层。神经网络模型的最终输出将是目标变量的预测输出。
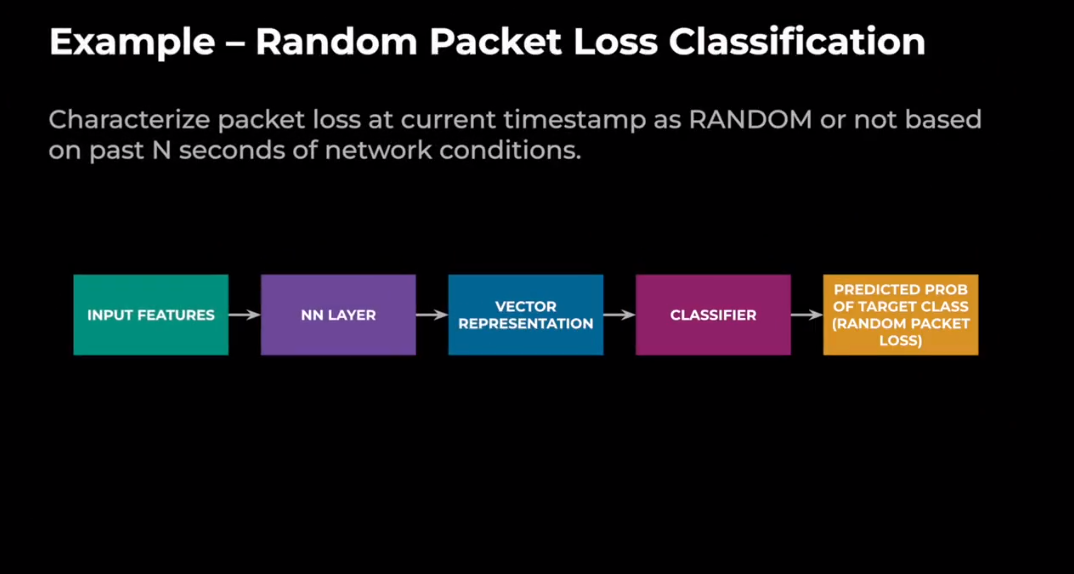
图 7. 随机丢包
在这张幻灯片中,我们将讨论随机包丢失分类,并将其作为我们如何进行网络表征的示例。所以目标是在当前时间戳下,如果我们看到丢包,我们希望根据过去10秒的网络条件将当前的随机数据包规律表征为随机或非随机。所以对于模型训练,我们将使用时间序列数据作为输入,它将通过神经网络层,就像我们提到 LSTM 层。然后我们可以得到它的向量表示,然后它将通过一个分类器,然后输出将是目标变量的预测概率。在此示例中,这将是随机丢包的预测概率。我们主要为基于机器学习的带宽估计项目使用低级特征。因此,这些低级特征可以以100毫秒或500毫秒或1秒的时间间隔收集。特征包括丢包率、不同评估类型的往返耗时以及抖动和拥塞窗口。所以这个时间序列通常是在过去的10到30秒内收集的,用于我们的表征工作。所以对于这个时间序列,我们也可以使用特征工程来提取和聚合更强大的特征,直接用于模型。

图 8. 丢包
因此,上面幻灯片显示了我们在检测到随机数据包丢失时可以使用的不同优化。我们还可以忽略高带宽中的拥塞信号。我们还可以扩展网络弹性。
网络预测

图 9. 网络预测
我们所说的网络预测是指给定过去的网络状况,我们能预测未来的网络状况吗?这就是剩下的关于网络预测的讨论。因此,如果我们使用基于 ML 的解决方案来预测未来的网络状况,我们觉得 ML 的力量会进一步增强。
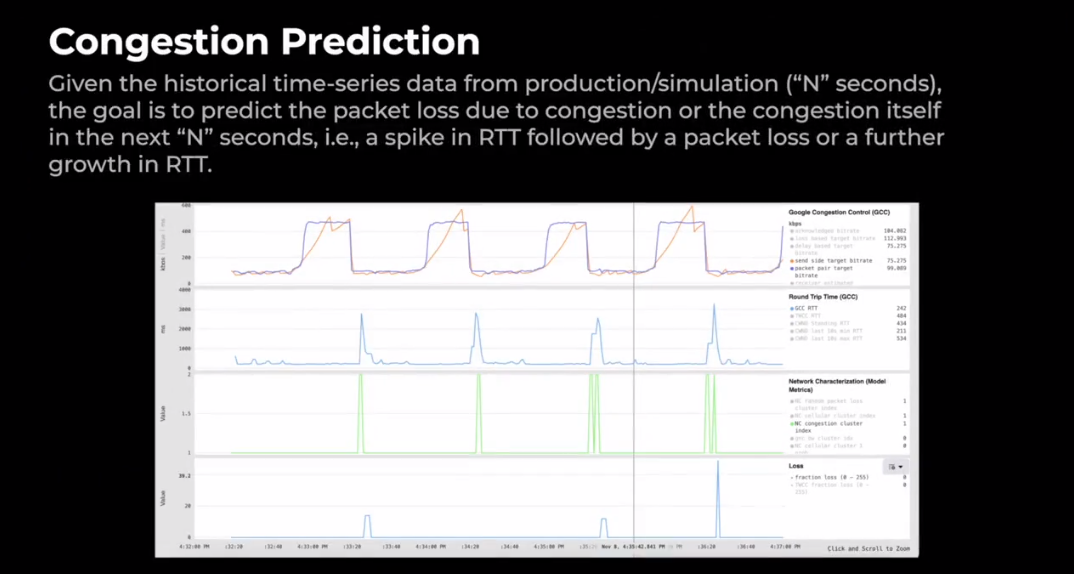
图 10. 拥塞预测
让我们深入探讨一个预测拥塞的问题。给定来自实际或模拟的10秒历史时间序列数据,目标是预测下一个结束期内由于拥塞或者包本身原因而导致的丢包,这时 RTT 增加,随后是数据包丢失,但 RTT 进一步增长。所以这涵盖了浅缓冲区和深缓冲区。即当我们发生拥塞时,浅缓冲区会导致数据包丢失,而当我们发生这种情况时,深缓冲区成本会增加。让我们举一个模拟的例子。上面这张幻灯片是一个模拟的网络条件,每30秒交替带宽。它每30秒将一些高带宽(如以kbps查找)降低到50 kbps。当带宽下降时,引起拥塞,我们看到 RTT 增加。然后根据队列大小,它有时也会导致数据包丢失。我们用绿色显示我们的网络预测输出,显示在拥塞发生之前预测拥塞。

图 11. 拥塞预测表
根据我们的模型训练,条件预测的主要挑战是我们如何进行标注。标注是基于 ML 建模的重要方面之一。所以我们可以从模拟中使用ground truth,也可以从生产中使用ground truth。使用仿真的挑战在于我们能否在仿真中获得所有不同类型的网络场景以及拥塞的不同分布。所以我们所做的是使用ground truth来标注我们的基本事实样本。所以我们在过去和未来有 10 秒的时间窗口。在我们的标签中,我们使用 4 秒的时间窗口来表示过去和未来的时间序列日志。我们根据这张大图表来标记拥塞。所以为了简化这张图表,我们想找出正负样本是什么。在这里,我们寻找过去 RTT 飙升,未来 RTT 增长。同样,我们寻找快速丢包和未来的丢包。举个简单的例子,我们标记正例,我们寻找过去的 RTT 峰值,如果它导致未来的数据包丢失,我们强烈将其标记为正例。我们还寻找过去的 RTT 峰值,如果这导致未来 RTT 的进一步增长,我们将它们标记为积极的例子。

图 12. 模型性能
这就是我们如何使用 ML 方法标记用于预测拥塞的监督模型。模型训练完成后,我们使用 F1 数、AUC、准确率和召回率等性能指标在测试集上评估模型。我们使用拥塞模型在离线测试中预测了 5.5% 的案例拥塞。我们还在客户端记录模型推断的ground truth。我们所做的是基于过去的预测,在未来的窗口中,我们有了拥塞是否发生的 ground truth。我们从客户端的 ML 推断中锁定ground truth,并将其与离线进行比较。因此,正如我们可以从这张图表或这里的表格中看到的那样,离线和在线评估的预测拥塞百分比是相似的。这告诉您该模型能够预测拥塞,并且与离线训练非常相似。
一旦预测到拥塞,我们就会应用类似于上面网络表征中提到的随机丢包的某些操作。例如,在预测拥塞时,我们会触发更多的过度使用(过度使用会导致带宽下降),所以我们能够在网络上更不拥挤。类似地,我们将拥塞信号增强到基于损失的带宽预测模块中的现有拥塞导向器。正如之前在演讲中提到的,我们如何为带宽估计和传输网络弹性制定现实的方法。

图 13. 结果
所以我们的 ML 模型实际上是在 Messenger 和 Whatsapp 中推出的 BW 优化。拥塞预测模型需要可靠性,我们看到视频冻结百分比降低了2个百分点。同样,对于随机丢包,该模型产生了 3.44% 的质量增益,用户参与(意味着通话时间)增加了0.15%。因此,最初,我们希望通过针对不同网络类型优化基于 ML 的解决方案来提高可靠性和质量,这就是我们所取得的成就。
总结和展望

图 14. 总结和展望
因此,从网络校准和网络预测的解释中,我们可以看到基于 ML 方法比传统的手动调整规则更有效地进行网络定位、监控和更新。我们还可以看到,基于 ML 解决方案的效率在很大程度上依赖于数据质量和ground truth标签。因此,如果我们能有更好的数据质量,无论是来自模拟数据还是生产数据,如果我们能有更好的ground truth标记策略,我们就能有更好的基于 ML 的模型。因此,将 ML 用于模型预测问题,放大了它的力量。它还可以自动学习网络动作。
图 15. 展望
因此,目前我们仍在探索基于 ML 网络优化方法的新领域。所以我们有一些未来的计划,目前我们正在探索这些计划。首先,我们计划为各种应用开发和部署更多的 ML 模型。有必要为多任务架构设计一个广义的 ML 模型。我们正在尝试构建一个骨干模型,它以过去的网络状况为输入,生成网络状况的表示。此网络表示将用于特定 BWE 优化和应用的下游任务。并且每个下游任务都会有自己的目标。所以这些广义的模型架构将大大增加模型的可扩展性,降低离线和在线的模型复杂度。其次,目前我们专注于在 10 秒到 30 秒的短期窗口内捕获网络模式。但捕捉网络中的长期网络模式也非常重要。因此,我们未来的计划还包括探索如何在模型预测中对长期网络模式进行建模。第三,我们还计划改进我们的模拟场景,以构建更逼真的生产,如网络场景。我们甚至可以利用 GNI 来训练生成模型,以生成更多类似网络场景的生产,以缩小生产和模拟之间的差距。
最后,我们的长期目标是使用强化学习在线动态建模 BW 。所以我们将首先研究如何提出一个好的模型理论公式和一个好的奖励函数。然后,我们将把强化学习应用到基于模拟的网络场景中。我们的最终长期目标是使用强化学习取代当前基于网络的算法。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号