Data Fabric 2024:现代数据集成组件指南

Data Fabric 2024:现代数据集成组件指南

大数据杂货铺
发布于 2024-04-15 12:54:48
发布于 2024-04-15 12:54:48
数据管理和数据集成是任何组织数字化转型战略的关键组成部分。在当今的全渠道业务环境中,组织必须实时访问和分析来自各种来源的大规模数据。然而,传统的数据管理方法对于这些要求来说常常太慢。数据编织架构可以帮助克服这些问题。
对于寻求数字加速的组织来说,数据编织非常有益。由于这是一个相对较新的概念,许多企业领导者可能并不了解。在本文中,我们将探讨数据编织、其用例及其优势。
1.什么是数据编织?
数据编织是一个单一且一致的数据管理框架,可帮助组织管理其数据。数据编织的目的是减少数据管理的复杂性。它通过消除低效的手动数据集成流程来帮助组织解决复杂的数据问题,并提供用于分析的业务就绪数据。它使用户能够无缝访问和共享数据,无论数据存储在何处。
Data Fabric 软件架构汇集并连接来自不同来源的企业数据,例如:
- 云平台
- 本地数据库
- 数据孤岛
- 数据仓库
- 数据湖
- 边缘设备
数据编织还可以让组织自动执行以下任务:
- 数据复制。
- 数据治理。
- 数据管理和集成相关的数据安全。
1.1什么是数据编织架构?
数据编织架构是指整体数据编织设计和结构。它包括数据编织组件、技术和原理,以及它们的集成和配置,以支持:
- 统一
- 灵活
- 可扩展的数据管理平台。
1.2数据编织架构和数据编织如何结合在一起?
数据编织为组织提供了一个统一、灵活且可扩展的平台,用于管理结构化和非结构化数据,他们可以使用这些数据来实时访问和分析。组织可以通过实施数据编织架构来创建数据编织。该架构使组织能够使用该平台有效地访问和分析数据。
2.为什么数据编织现在很重要?
缺乏数据访问(即需要数据的用户可以访问数据)和数据集成的复杂性等挑战阻碍了组织最大限度地发挥数据的价值并充分利用其数据。传统的数据集成已不足以满足通用转换、实时连接等业务需求。将组织数据与多个来源的数据集成、处理和转换是许多组织面临的挑战。
Data Fabric 为用户提供全面的实时数据访问;无论用户位于何处,它都可以可视化。用户可以使用数据编织来简化多云数据环境中的数据治理和管理。
3.公司如何从数据编织中受益?
- 自动化数据治理:它自动将公司策略应用于数据并提供可信数据。
- 促进数据集成:它通过自动化这些流程来简化对所有数据的访问并加速组织内的数据交付。
- 消除数据孤岛:数据孤岛是由一组持有且其他人无法完全访问的数据。Data Fabric 是用于收集和访问数据的统一数据管理框架。它使同一组织中的其他组可以访问数据。
- 提高数据管理合规性:它为所有数据提供单一环境,并集中数据管理和治理。
- 加速数字化转型过程:数据编织无需使用多种工具,从而减少了数据集成问题,提高了数据质量,并简化了数据治理、共享和管理。它为您提供公司数据的单一、全面的视图。它可以通过最大化数据价值来加速您的数字化转型过程。
4.数据编织由哪些组件组成?
数据编织不仅仅是一个网络。通常,数据编织由以下主要组件组成:
- 数据管理层
- 数据安全层
- 数据访问层
- 数据消费层
4.1数据管理层
数据管理层负责跨众多存储资源的数据组织和管理。它可以具有数据管理功能,例如:
- 分层。
- 重复数据删除。
- 压缩有助于优化存储资源并削减开支。
- 复制。
- 迁移可以有效地跨不同存储资源移动数据。
4.2数据保护层
数据保护层的工作是确保数据始终安全且可访问。它可以包括数据管理功能,例如:
- 备份
- 灾难恢复
- 归档
此外;它可以包括数据加密等安全功能,以保护您的数据免遭未经授权的访问或破坏。
4.3数据访问层
数据访问层允许应用程序访问和检索来自云环境和数据湖等不同来源的数据。该层可以统一数据访问,而不管数据源如何。它可以提供应用程序编程接口(API)和接口:
- 查询。
- 插入。
- 更新。
- 删除数据。
4.4数据消费层
消费层负责控制应用程序和系统如何使用数据。它通常由接口和API组成,允许程序和系统根据需要访问和使用数据。
消费层可以整合多个数据源的数据消费。该层提供以下功能:
- 数据的统一视图:统一所有来源的数据,无论格式或位置如何。
- 查询和分析:通过确保数据正确索引和优化,实现高效的数据查询和分析。
- 数据安全:提供安全和访问控制,确保只有授权的业务用户和应用程序才能访问数据。
- 性能优化:通过以下方式提高性能并消除数据重复:
- 数据缓存:数据可以本地存储在缓存中,最大限度地减少重复查询相同数据的需要。
- 数据虚拟化:无需物理迁移或复制即可访问和集成数据。
- 数据联邦:允许组织通过中间件或连接器访问来自不同来源的数据,就像它们位于单个位置一样。
5.用于运营工作负载的数据编织、数据湖与数据库
由于“数据编织”、“数据湖”和“数据库”都存储和管理数据,因此可能会混淆。但是,它们的用例和功能可能有所不同:
- 数据编织是一种连接和管理来自各种来源和技术的企业数据的方法。它通常用于具有多种不同类型的数据和系统的大型复杂环境。
- 数据湖或冷数据是业务用户和数据工程师可以存储任意大小数据的中心位置。它用于处理大量数据,通常用于存储稍后分析的原始数据。
- 数据库是一种以结构化方式存储和管理信息的方法,通常使用软件。它专为快速数据查询和检索而设计,通常用于运行网站或应用程序等操作任务。
5.1数据编织、数据湖与数据数据库比较表
在表 1 中,您可以找到数据编织、数据湖和数据库之间的一些相似点和差异的摘要。
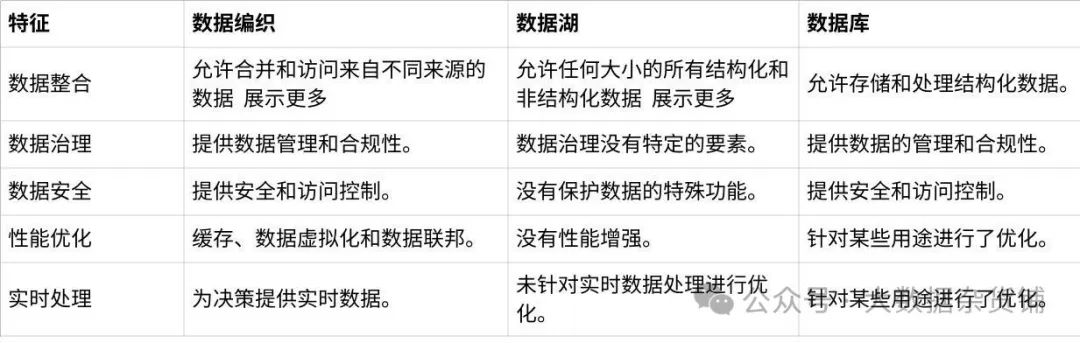
点击图片可查看完整电子表格
表 1:数据编织、数据湖、数据库。
6.为什么使用数据编织?Data Fabric 架构的关键数据管理优势
数据编织可以使组织能够管理数据,无论数据存储在何处。数据编织可以提供以下数据管理优势:
6.1数据可访问性
数据编织允许组织以统一一致的方式访问和管理来自不同来源的数据,包括:
- 数据库
- 数据湖
- 云储存。这可以让您更轻松地获取和使用数据进行业务分析和其他用途。
6.2数据治理
数据编织使组织能够在其数据管道中实施治理策略。有关政策:
- 数据质量
- 数据沿袭
- 数据安全可以帮助确保数据正确、遵循规则且安全。
6.3数据整合
数据编织可以自动将来自不同来源的结构化和非结构化数据组合成一个统一的视图。
6.4数据敏捷性
数据编织解决方案可以让组织轻松地根据需求的变化快速更改其数据架构。这可以帮助企业适应商业世界的变化并保持竞争力。
例如,假设组织需要添加新的数据源,例如物联网设备或社交媒体。在这种情况下,数据编织可以将其数据集成到现有架构中。
6.5数据可扩展性
数据编织解决方案可以让组织扩展其数据基础设施以满足以下需求:
- 不断增长的数据量
- 多样化的数据类型和格式。
例如,组织可以将客户数据存储在多个数据库和文件系统中。数据编织可以将所有这些数据汇集在一起并用于分析。
6.6云集成
数据编织技术可以让组织跨以下位置移动和管理数据:
- 多云
- 混合云
- 和本地环境
这可以提供灵活性并减少供应商锁定。
7.数据编织不需要收集和分析所有形式的元数据
数据编织帮助公司管理和整合多个来源的数据。然而,它不需要收集和分析每一条信息。数据编织对于收集和分析元数据的有用程度取决于组织的用例和需求。例如,元数据在数据编织中很有用:
7.1数据治理
组织可以通过收集和分析元数据来改善非结构化和结构化数据源的治理和合规性。元数据可以追踪数据沿袭、所有权和适当的使用。
7.2安全性
元数据在存储(静态)和传输(动态)时都可以在安全方面发挥重要作用。元数据可以加密数据、实施访问限制并监控数据活动。例如,元数据可用于跟踪谁查看了特定文件以及何时查看,以及检测敏感数据和应用数据屏蔽。
7.3数据分析
元数据可用于分析不同的数据源并从中学习。元数据可以帮助理解数据模式、组合来自不同来源的数据并实时分析流数据。
8.数据编织、数据虚拟化、数据联邦
数据编织、数据虚拟化和数据联邦有时会被混淆。在本节中,我们将解释这些术语。
8.1数据编织和数据虚拟化有什么区别?
数据编织是一个与数据虚拟化相混淆的概念。两者都是用于管理组织数据的数据架构。数据虚拟化是集成用于转换数据源以获得实时洞察的解决方案的最快方法。另一方面,数据编织是一种管理架构,可为物联网分析、数据科学和客户 360 等更广泛的用例提供全面的管理。数据虚拟化有助于数据编织架构更好地工作。
8.2数据虚拟化
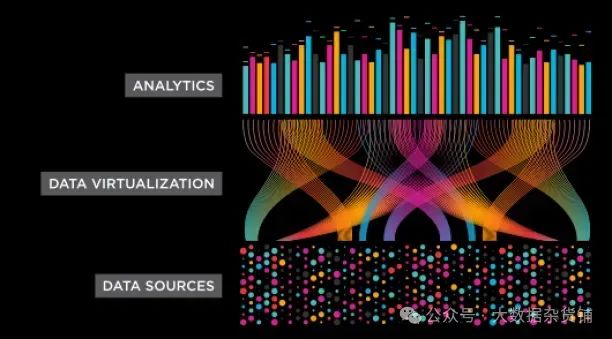
图 2:虚拟化将数据源连接到分析。(1)
数据虚拟化是一种允许企业访问和使用数据的方法,就像数据存储在单个位置一样,即使数据分布在多个数据源中。这是通过在底层数据源之上构建虚拟层来实现的,该虚拟层提供了一致且统一的数据表示。
8.3数据联邦
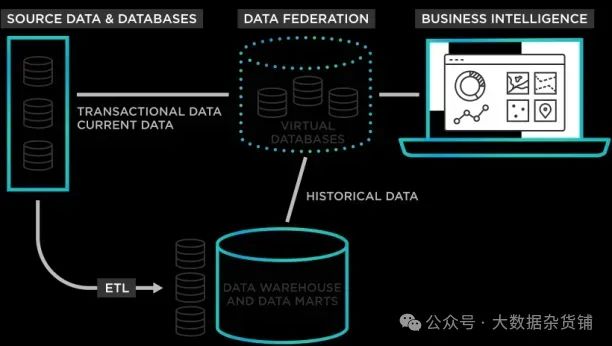
图 3:数据联邦将数据库中的数据连接到商业智能。(2)
数据联邦与数据虚拟化类似,因为它提供了单一、一致的数据视图,但其实现方式有所不同。
8.3.1数据联邦连接器
在数据联邦中,数据保留在其原始位置,并通过一组中间件或连接器进行访问。这些连接器使应用程序和系统可以访问和使用来自不同数据源的数据,但数据仍保留在其来源处。连接器负责将来自不同来源的数据转换为通用格式,并每次都以相同的方式显示。
8.3.2数据虚拟化与数据联邦
相比之下,虚拟化创建了一个位于底层数据源之上的虚拟层,并提供统一且一致的数据视图。数据通常被移动或复制到虚拟层并从那里访问和使用。
8.4数据编织、数据虚拟化与数据联邦比较表。
表 2 总结了数据编织、虚拟化和数据联邦之间的差异。
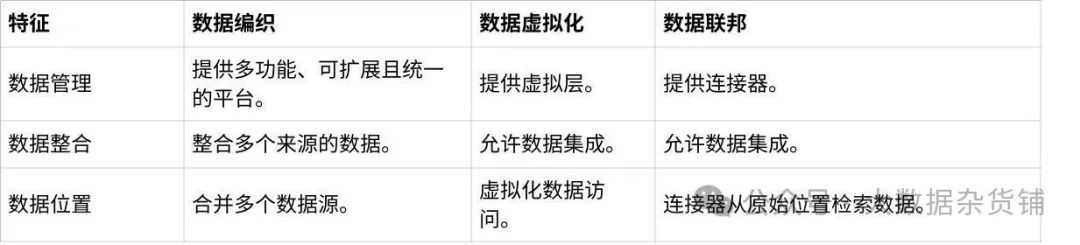
点击图片可查看完整电子表格
表 2:数据编织、虚拟化和数据联邦。
9.Data Fabric 如何与 AI/ML 配合使用?
人工智能 (AI) 和机器学习 (ML) 可以通过多种方式处理数据。这里有一些例子:
- 数据准备:Data Fabric 可以收集并组合来自多个来源的数据,为 AI 和 ML 模型提供用于数据分析的单一视图。Data Fabric还可用于数据预处理和清理,以提高 AI 和 ML 模型的数据质量。
- 实时数据分析:数据编织为人工智能和机器学习模型提供实时数据。这可以提供基于模型的实时决策和行动。
- 数据治理:Data Fabric 可以处理数据治理和合规性,以确保人工智能和机器学习应用程序中数据的使用符合道德和合法性。
- 数据安全:数据编织可保护所有来源的静态和动态数据。人工智能和机器学习应用程序必须保护敏感数据。
- 混合和多云:Data Fabric 可以结合来自本地、云和边缘设置的数据,创建灵活且可扩展的 AI 和 ML 架构。
10.现实世界的数据编织可以执行即时复杂的查询
数据编织可以通过分区、索引、缓存和物化视图来加速查询处理。此外,数据编织可以使用分布式处理和并行性来处理大数据。这里有些例子:
- 实时分析:在金融服务和电子商务中,数据编织可以组合来自多个来源的数据,执行复杂的计算并产生近乎实时的结果。
- 物联网 (IoT):数据编织可以在物联网用例中实时分析和响应传感器数据。在智慧城市中,数据编织可以协助分析来自交通摄像头和灯光的传感器数据,以优化交通流量并消除拥堵。
- Ad-hoc 报告:数据编织可以通过组合来自不同来源的数据并运行复杂的计算来帮助您快速制作临时报告。例如,零售公司可以使用它来快速报告特定时间段内按类别和地区的销售情况。
原文链接:https://research.aimultiple.com/data-fabric/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号