使用Triton+TensorRT-LLM部署Deepseek模型
原创
使用Triton+TensorRT-LLM部署Deepseek模型
原创
languageX
发布于 2024-04-17 22:08:45
发布于 2024-04-17 22:08:45
随着大模型项目的开源环境越来越好,大家在本地部署一个大语言模型跑demo应该是一件很简单的事情。但是要将模型运行到生产环境,就需要考虑模型运行性能,GPU资源的调度,高并发场景的支持等情况了。
本文主要介绍如何使用Triton+TensorRT-LLM来部署大语言模型。
1. Triton介绍
在AI领域,Triton有两个有影响力的含义,一个是OpenAI发起的高层次kernel开发语音Triton;一个是NVIDIA 开源的为用户在云和边缘推理上部署的解决方案Triton Inference Server。本文介绍的Triton是后者,模型部署方案。
github:https://github.com/triton-inference-server
Triton类似TfServing这种产品,当然他兼容的模型框架要比tfserving多,其前身就是TensorRT inference server,它的优势是提供了很多开箱即用的工具,帮我们快速的将AI模型部署到生产环境中提供给业务使用,不用我们去自研一套部署部署工具。
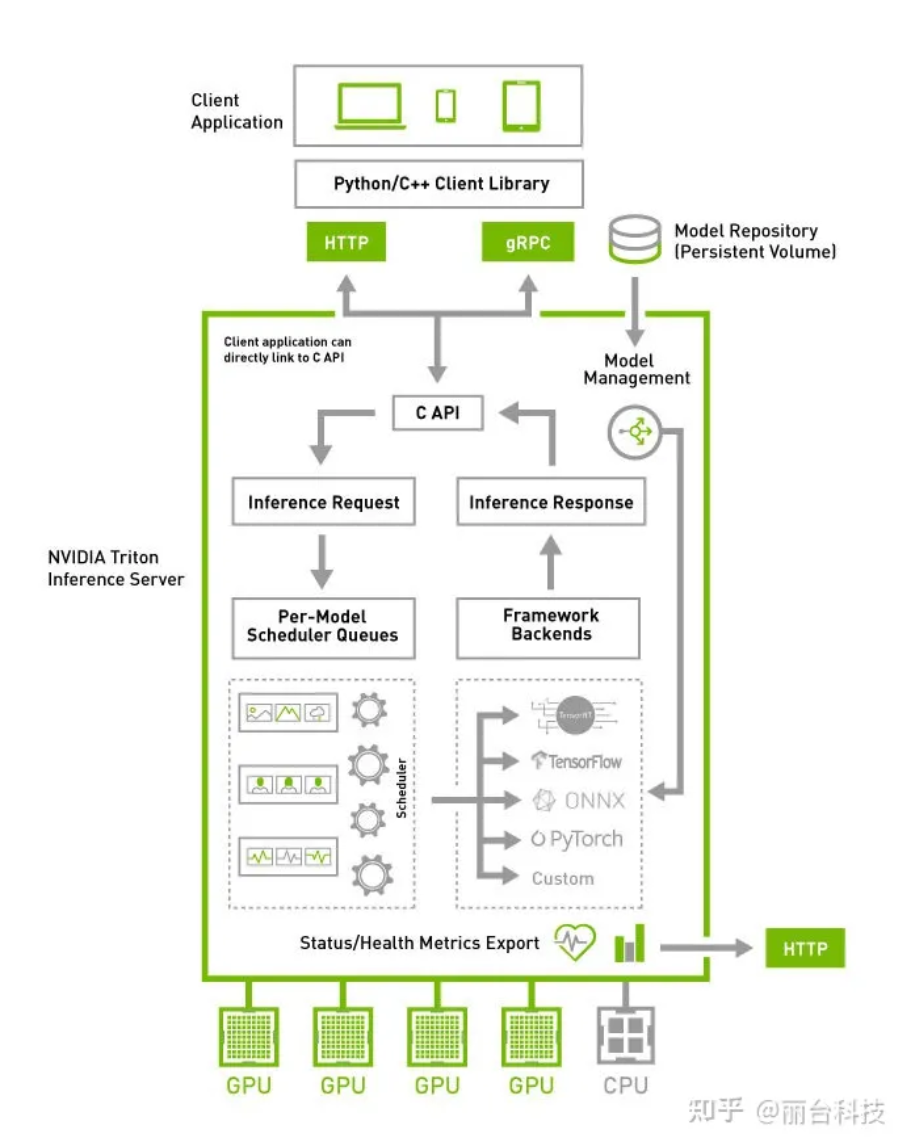
NVIDIA Triton 推理服务器 具有以下的特性:
● 支持多种开源框架的部署,包括TensorFlow/PyTorch/ONNX Runtime/TensorRT 等,同时也支持用户提供自定义backend扩展解码引擎;
● 支持多个模型同时运行在 GPU 上,以提高 GPU 设备的利用率;
● 支持 HTTP/gRPC 协议,提供二进制格式扩展来压缩发送请求大小;
● 支持 Dynamic Batching 功能,提升服务的吞吐;
● 支持兼容 KFServing 的 API 标准。
2. triton inference server快速部署
triton快速部署可以参考官方文档:
https://github.com/triton-inference-server/server/blob/main/docs/getting_started/quickstart.md
直接使用NVIDIA GPU Cloud(NGC),拉取官方预编译好的container
triton-inference-server容器版本:
https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/
官方提供的2.10以后的容器就已经支持TensorRT-LLM和vllm了。

所以cuda版本和驱动支持的话,最快的方式就是直接拉2.10以后的镜像,然后安装官方文档启动服务即可。
docker run -it -d --cap-add=SYS_PTRACE --cap-add=SYS_ADMIN --security-opt seccomp=unconfined --gpus=all --shm-size=16g --privileged --ulimit memlock=-1 --name=develop nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3 bash3. Tensorrt_llm编译部署
考虑到后续我们可能需要基于源码进行调整,更方便发现和解决问题,优化模型等需求,所以本文主要介绍如何基于TensorRT_LLM backend源码编译模块,以及部署自己算法模型的过程。
3.1 拉取基础镜像
根据官网对cuda版本的需求,拉取对应的版本,我使用的23.08版本。
启动容器
docker run -it --net host --gpus="device=5" --shm-size="70G" nvcr.io/nvidia/tritonserver:23.08-py3 /bin/bash3.2 拉取项目代码
拉取tensorrtllm-backend项目代码
git clone https://github.com/triton-inference-server/tensorrtllm_backend在tensorrtllm_backend项目中tensor_llm目录中拉取TensorRT-LLM项目代码
git clone https://github.com/NVIDIA/TensorRT-LLM.git注意分支版本的一致,我是拉取的-b v0.5.0分支。(拉取分支主要注意TensorRT-LLM中的/docker/common/install_tensorrt.sh中cuda版本有要求。)
3.3 编译TensorRT-LLM
在/opt/tritonserver/tensorrtllm_backend/tensorrt_llm 目录下执行:
apt-get update && apt-get -y install git git-lfs
git submodule update --init --recursive
git lfs install
git lfs pull安装依赖
cd docker/common
bash install_base.sh
bash install_cmake.sh
bash install_tensorrt.sh
bash install_polygraphy.sh
bash install_pytorch.sh pypi
export LD_LIBRARY_PATH=/usr/local/tensorrt/lib:${LD_LIBRARY_PATH}这里注意两点:
1. 安装cmake
如果执行bash太慢,可以提前下好安装包:
# 在镜像外下载好安装文件,然后拷贝到容器中
docker cp cmake-3.24.4-linux-x86_64.tar.gz 容器ID:/tmp/
# 修改install_cmake.sh,屏蔽下载逻辑
#wget --no-verbose ${RELEASE_URL_CMAKE} -P /tmp
# 再执行安装脚本
bash install_cmake.sh
# 添加环境变量
vim ~/.bashrc
export PATH=/usr/local/cmake/bin${PATH:+:${PATH}}
source ~/.bashrc安装后执行cmake -version确定版本
2. export环境变量
安装完后记得export LD_LIBRARY_PATH,不然后续会出现libnvinfer.so找不到的问题
安装TensorRT-LLM
cd tensorrt-llm
python3 ./scripts/build_wheel.py --clean --trt_root /usr/local/tensorrt编译成功后安装:
pip install ./build/tensorrt_llm*.whl成功后再到/usr/local/tensorrt/lib 目录下应该有tensorrt-llm的库。
3.4 加载和编译deepseek模型
现在有tensorrt-llm运行库了,我们需要加载自己的模型进行测试。在tensorrt-llm的model里有他目前支持的模型llama,bloom,chatglm2_6b,baichuan,gpt,bert等,所以如果你的模型结构是基于这些主流的模型,完全可以复用;如果不能复用,就只能在这里添加代码后重新增量编译了。
如果是特殊框架,改的可不是这一点,要改好多文件。。。使用主流框架的重要性!!!
本文示例是转换deepseek模型,由于模型框架是基于llama,所以这里我们偷个懒,后面的model_type直接复用llama,有些不兼容的问题需要修改一些代码,后续会提到。
3.4.1 下载模型文件
我们已经下载好了,直接从nfs上拷贝进行,当然也可以启动容器时直接挂载。
docker cp /宿主机器的模型地址/deepseek-coder-6.7b-base/ 容器ID:/opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub3.4.2 编译模型trt_engines
上一步只是编译了trt库,trt要跑模型,还需要构建模型engine。
cd /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/examples/llama编译模型
python build.py模型转换需要了解模型的一些参数,可以参考
参考:https://github.com/deepseek-ai/DeepSeek-Coder/issues/44
转换成功后应该有.engine文件

3.4.3 tensorrt_llm测试
修改run.py中对tokenizer加载的代码,deepseek是没有tokenizer.model,所以tokenizer的加载代码需要修改的。
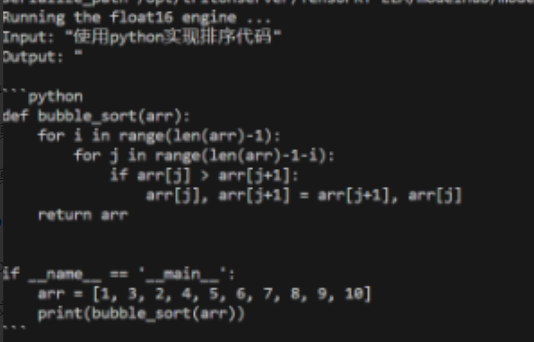
python run.py --max_output_len=1024 --tokenizer_dir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub/deepseek-coder-6.7b-base --engine_dir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub/models/trt_engines/deepseek/fp16/1-gpu/ --input_text "使用python实现能正常出结果,说明tensorrt_llm和加载模型的转换已完成。
3.5 编译tensorrtllm_backend
3.5.1 加载文件
现在我们编译tensorrtllm_backend~,编译之前,先拷贝一些必要文件,以及进行一些代码修改。
cd /opt/tritonserver/tensorrtllm_backend/
cd tensorrtllm_backend
mkdir triton_model_repo
# 将模板模型文件夹拷贝出来
cp -r all_models/inflight_batcher_llm/* triton_model_repo/3.5.2 调整配置和代码
在model_repo中有四个文件夹,其中的config.txtpb我们都需要修改。
参考官方文档:https://github.com/triton-inference-server/tensorrtllm_backend#modify-the-model-configuration
● "preprocessing": 这个模块负责将prompts(string)转化为input_ids
● "tensorrt_llm": 这个模块是在TensorrtRT-LLM中推理运行的封装
● "postprocessing": 这个模块负责将input_ids转换为string.
● "ensemble": 这个模块负责将前三个模块串起来
tensorrt_llm的模块config.pbtxt修改比较多,主要参考官网对每个字段的解释进行调整。
https://github.com/triton-inference-server/tensorrtllm_backend#modify-the-model-configuration
3.5.3 编译tensorllm_backbend
执行编译脚本:
cd /opt/tritonserver/tensorrtllm_backend/inflight_batcher_llm/scripts
chmod +x build.sh
./build.sh /usr/local/tensorrt如果遇到libnvinfer.so.8版本问题,直接复制一个so.9然后改名so.8。
3.5.4 启动服务
python3 scripts/launch_triton_server.py --world_size=1 --model_repo=triton_model_repo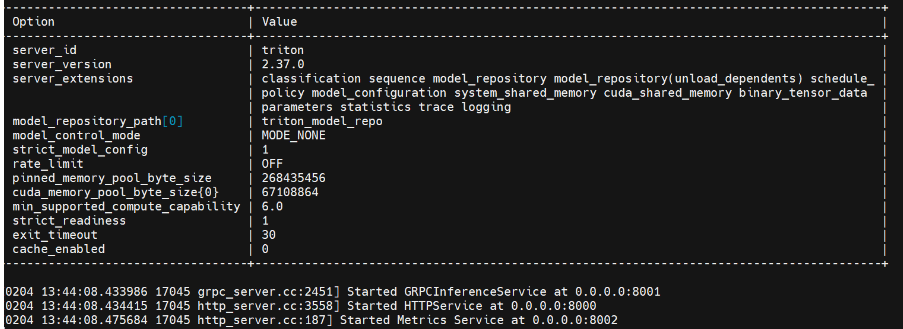
看到上面这个结果,恭喜~triton服务启动成功了,后端是tensorrt_llm。
4. 客户端调用
客户端调用就比较简单,安装客户端库
pip install tritonclient[all]
pip install pandas
pip install tabulateclone代码
git clone -b v0.5.0 https://github.com/triton-inference-server/tensorrtllm_backend找到示例代码
cd tensorrtllm_backend/tools/inflight_batcher_llm修改end_to_end_streaming_client.py
其中localhost改为10.200.1.5,或者命令行参数url直接赋值
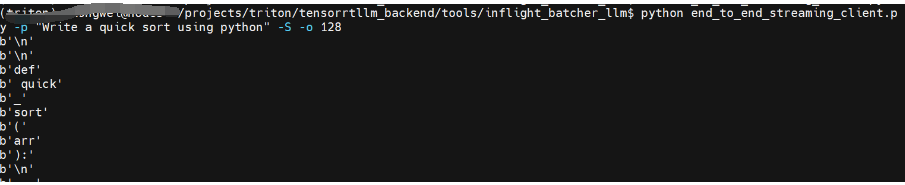
python end_to_end_streaming_client.py -p "Write a quick sort using python" -S -o 128可以看到流式结果:
我正在参与2024腾讯技术创作特训营最新征文,快来和我瓜分大奖!
参考:
https://www.zhihu.com/question/507633460/answer/2379994462
https://ai.oldpan.me/t/topic/260
https://github.com/triton-inference-server/tensorrtllm_backend/issues/188
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号