Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(一)

Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(一)

ApacheCN_飞龙
发布于 2024-05-24 14:24:11
发布于 2024-05-24 14:24:11
原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 译者:飞龙 协议:CC BY-NC-SA 4.0
前言
机器学习海啸
2006 年,Geoffrey Hinton 等人发表了一篇论文,展示了如何训练一个能够以最先进的精度(>98%)识别手写数字的深度神经网络。他们将这种技术称为“深度学习”。深度神经网络是我们大脑皮层的(非常)简化模型,由一系列人工神经元层组成。在当时,训练深度神经网络被普遍认为是不可能的,大多数研究人员在 1990 年代末放弃了这个想法。这篇论文重新激起了科学界的兴趣,不久之后,许多新论文证明了深度学习不仅是可能的,而且能够实现令人惊叹的成就,其他任何机器学习(ML)技术都无法匹敌(在巨大的计算能力和大量数据的帮助下)。这种热情很快扩展到许多其他机器学习领域。
十年后,机器学习已经征服了行业,如今它是许多高科技产品中许多神奇功能的核心,比如排名您的网络搜索结果,为您的智能手机提供语音识别,推荐视频,甚至可能驾驶您的汽车。
在您的项目中应用机器学习
因此,您对机器学习感到兴奋,并希望加入这个派对!
也许您想让您自制的机器人拥有自己的大脑?让它识别人脸?或学会四处走动?
或者您的公司有大量数据(用户日志、财务数据、生产数据、机器传感器数据、热线统计、人力资源报告等),很可能如果您知道在哪里寻找,您可以发现一些隐藏的宝藏。通过机器学习,您可以实现以下目标以及更多:
- 分析客户并找到每个群体的最佳营销策略。
- 根据类似客户购买的产品,为每个客户推荐产品。
- 检测哪些交易可能是欺诈性的。
- 预测明年的收入。
无论出于何种原因,您已经决定学习机器学习并在您的项目中实施它。好主意!
目标和方法
本书假设您对机器学习几乎一无所知。其目标是为您提供实现能够从数据中学习的程序所需的概念、工具和直觉。
我们将涵盖大量技术,从最简单和最常用的(如线性回归)到一些经常赢得比赛的深度学习技术。为此,我们将使用生产就绪的 Python 框架:
- Scikit-Learn 非常易于使用,同时高效实现了许多机器学习算法,因此它是学习机器学习的绝佳入门点。它由 David Cournapeau 于 2007 年创建,现在由法国国家计算机与自动化研究所(Inria)的一组研究人员领导。
- TensorFlow 是一个更复杂的分布式数值计算库。它通过在数百个多 GPU(图形处理单元)服务器上分布计算,使得训练和运行非常大的神经网络变得高效。TensorFlow(TF)由 Google 创建,并支持许多其大规模机器学习应用。它于 2015 年 11 月开源,2.0 版本于 2019 年 9 月发布。
- Keras 是一个高级深度学习 API,使训练和运行神经网络变得非常简单。Keras 与 TensorFlow 捆绑在一起,并依赖于 TensorFlow 进行所有密集计算。
本书倾向于实践方法,通过具体的工作示例和一点点理论来培养对机器学习的直观理解。
提示
虽然您可以不用拿起笔记本阅读本书,但我强烈建议您尝试一下代码示例。
代码示例
本书中的所有代码示例都是开源的,可以在https://github.com/ageron/handson-ml3上在线获取,作为 Jupyter 笔记本。这些是交互式文档,包含文本、图片和可执行的代码片段(在我们的案例中是 Python)。开始的最简单最快的方法是使用 Google Colab 运行这些笔记本:这是一个免费服务,允许您直接在线运行任何 Jupyter 笔记本,无需在您的机器上安装任何东西。您只需要一个网络浏览器和一个 Google 账号。
注意
在本书中,我假设您正在使用 Google Colab,但我也在其他在线平台上测试了这些笔记本,如 Kaggle 和 Binder,所以如果您愿意,也可以使用这些平台。或者,您可以安装所需的库和工具(或本书的 Docker 镜像),并在自己的机器上直接运行这些笔记本。请参阅https://homl.info/install上的说明。
本书旨在帮助您完成工作。如果您希望使用代码示例以外的其他内容,并且该使用超出了公平使用准则的范围(例如出售或分发 O’Reilly 图书的内容,或将本书的大量材料整合到产品文档中),请通过permissions@oreilly.com联系我们以获取许可。
我们感谢,但不要求署名。署名通常包括标题、作者、出版商和 ISBN。例如:“使用 Scikit-Learn、Keras 和 TensorFlow 进行实践机器学习 by Aurélien Géron. 版权所有 2023 Aurélien Géron, 978-1-098-12597-4.”
先决条件
本书假定您具有一些 Python 编程经验。如果您还不了解 Python,https://learnpython.org是一个很好的开始。Python.org上的官方教程也非常不错。
本书还假定您熟悉 Python 的主要科学库,特别是NumPy、Pandas和Matplotlib。如果您从未使用过这些库,不用担心;它们很容易学习,我为每个库创建了一个教程。您可以在https://homl.info/tutorials上在线访问它们。
此外,如果您想完全理解机器学习算法的工作原理(不仅仅是如何使用它们),那么您应该至少对一些数学概念有基本的了解,尤其是线性代数。具体来说,您应该知道什么是向量和矩阵,以及如何执行一些简单的操作,比如添加向量,或转置和相乘矩阵。如果您需要快速了解线性代数(这真的不是什么难事!),我在https://homl.info/tutorials提供了一个教程。您还会找到一个关于微分计算的教程,这可能有助于理解神经网络是如何训练的,但并非完全必要掌握重要概念。本书偶尔还使用其他数学概念,如指数和对数,一些概率论,以及一些基本的统计概念,但没有太高级的内容。如果您需要帮助,请查看https://khanacademy.org,该网站提供许多优秀且免费的数学课程。
路线图
本书分为两部分。第一部分,“机器学习基础”,涵盖以下主题:
- 机器学习是什么,它试图解决什么问题,以及其系统的主要类别和基本概念
- 典型机器学习项目中的步骤
- 通过将模型拟合到数据来学习
- 优化成本函数
- 处理,清洗和准备数据
- 选择和工程特征
- 使用交叉验证选择模型和调整超参数
- 机器学习的挑战,特别是欠拟合和过拟合(偏差/方差权衡)
- 最常见的学习算法:线性和多项式回归,逻辑回归,k-最近邻,支持向量机,决策树,随机森林和集成方法
- 减少训练数据的维度以对抗“维度灾难”
- 其他无监督学习技术,包括聚类,密度估计和异常检测
第二部分,“神经网络和深度学习”,涵盖以下主题:
- 神经网络是什么以及它们适用于什么
- 使用 TensorFlow 和 Keras 构建和训练神经网络
- 最重要的神经网络架构:用于表格数据的前馈神经网络,用于计算机视觉的卷积网络,用于序列处理的循环网络和长短期记忆(LSTM)网络,用于自然语言处理的编码器-解码器和Transformer(以及更多!),自编码器,生成对抗网络(GANs)和扩散模型用于生成学习
- 训练深度神经网络的技术
- 如何构建一个代理(例如游戏中的机器人),通过试错学习良好策略,使用强化学习
- 高效加载和预处理大量数据
- 规模化训练和部署 TensorFlow 模型
第一部分主要基于 Scikit-Learn,而第二部分使用 TensorFlow 和 Keras。
注意
不要过于仓促地跳入深水:尽管深度学习无疑是机器学习中最令人兴奋的领域之一,但您应该先掌握基础知识。此外,大多数问题可以使用更简单的技术(如随机森林和集成方法)很好地解决(在第一部分讨论)。深度学习最适合复杂问题,如图像识别,语音识别或自然语言处理,它需要大量数据,计算能力和耐心(除非您可以利用预训练的神经网络,如您将看到的那样)。
第一版和第二版之间的变化
如果您已经阅读了第一版,以下是第一版和第二版之间的主要变化:
- 所有代码都已从 TensorFlow 1.x 迁移到 TensorFlow 2.x,并且我用更简单的 Keras 代码替换了大部分低级 TensorFlow 代码(图形,会话,特征列等)。
- 第二版引入了用于加载和预处理大型数据集的 Data API,用于规模训练和部署 TF 模型的分布策略 API,用于将模型投入生产的 TF Serving 和 Google Cloud AI Platform,以及(简要介绍)TF Transform,TFLite,TF Addons/Seq2Seq,TensorFlow.js 和 TF Agents。
- 它还引入了许多其他 ML 主题,包括一个新的无监督学习章节,用于目标检测和语义分割的计算机视觉技术,使用卷积神经网络(CNN)处理序列,使用循环神经网络(RNN)、CNN 和Transformer进行自然语言处理(NLP),GANs 等。
有关更多详细信息,请参阅https://homl.info/changes2。
第二版和第三版之间的变化
如果您阅读了第二版,以下是第二版和第三版之间的主要变化:
- 所有代码都已更新到最新的库版本。特别是,这第三版引入了许多新的 Scikit-Learn 补充(例如,特征名称跟踪,基于直方图的梯度提升,标签传播等)。它还引入了用于超参数调整的 Keras Tuner 库,用于自然语言处理的 Hugging Face 的 Transformers 库,以及 Keras 的新预处理和数据增强层。
- 添加了几个视觉模型(ResNeXt、DenseNet、MobileNet、CSPNet 和 EfficientNet),以及选择正确模型的指南。
- 第十五章现在分析芝加哥公共汽车和轨道乘客数据,而不是生成的时间序列,并介绍了 ARMA 模型及其变体。
- 第十六章关于自然语言处理现在构建了一个英语到西班牙语的翻译模型,首先使用编码器-解码器 RNN,然后使用Transformer模型。该章还涵盖了语言模型,如 Switch Transformers、DistilBERT、T5 和 PaLM(带有思维链提示)。此外,它介绍了视觉Transformer(ViTs)并概述了一些基于Transformer的视觉模型,如数据高效图像Transformer(DeiTs)、Perceiver 和 DINO,以及一些大型多模态模型的简要概述,包括 CLIP、DALL·E、Flamingo 和 GATO。
- 第十七章关于生成学习现在引入了扩散模型,并展示了如何从头开始实现去噪扩散概率模型(DDPM)。
- 第十九章从 Google Cloud AI 平台迁移到 Google Vertex AI,并使用分布式 Keras Tuner 进行大规模超参数搜索。该章现在包括您可以在线尝试的 TensorFlow.js 代码。它还介绍了其他分布式训练技术,包括 PipeDream 和 Pathways。
- 为了容纳所有新内容,一些部分被移至在线,包括安装说明、核主成分分析(PCA)、贝叶斯高斯混合的数学细节、TF Agents,以及以前的附录 A(练习解决方案)、C(支持向量机数学)和 E(额外的神经网络架构)。
更多详情请查看https://homl.info/changes3。
其他资源
有许多优秀的资源可供学习机器学习。例如,Andrew Ng 在 Coursera 上的 ML 课程令人惊叹,尽管需要投入大量时间。
还有许多关于机器学习的有趣网站,包括 Scikit-Learn 的出色用户指南。您可能还会喜欢Dataquest,它提供非常好的交互式教程,以及像Quora上列出的 ML 博客。
还有许多关于机器学习的入门书籍。特别是:
- Joel Grus 的《从零开始的数据科学》,第二版(O’Reilly),介绍了机器学习的基础知识,并使用纯 Python 实现了一些主要算法(从头开始,正如名称所示)。
- Stephen Marsland 的《机器学习:算法视角》,第二版(Chapman&Hall),是机器学习的一个很好的入门,深入涵盖了各种主题,使用 Python 中的代码示例(也是从头开始,但使用 NumPy)。
- Sebastian Raschka 的《Python 机器学习》,第三版(Packt Publishing),也是机器学习的一个很好的入门,利用了 Python 开源库(Pylearn 2 和 Theano)。
- François Chollet 的《Python 深度学习》,第二版(Manning),是一本非常实用的书,以清晰简洁的方式涵盖了广泛的主题,正如你可能从优秀的 Keras 库的作者所期望的那样。它更偏向于代码示例而不是数学理论。
- Andriy Burkov 的《百页机器学习书》(自出版)非常简短,但涵盖了令人印象深刻的一系列主题,以平易近人的术语介绍,而不回避数学方程式。
- Yaser S. Abu-Mostafa,Malik Magdon-Ismail 和 Hsuan-Tien Lin 的《从数据中学习》(AMLBook)是一个相当理论化的 ML 方法,提供了深刻的见解,特别是关于偏差/方差权衡(参见第四章)。
- Stuart Russell 和 Peter Norvig 的《人工智能:现代方法》,第 4 版(Pearson),是一本涵盖大量主题的伟大(而庞大)的书籍,包括机器学习。它有助于将 ML 置于透视中。
- Jeremy Howard 和 Sylvain Gugger 的《使用 fastai 和 PyTorch 进行编码的深度学习》(O’Reilly)提供了一个清晰实用的深度学习介绍,使用了 fastai 和 PyTorch 库。
最后,加入 ML 竞赛网站,如Kaggle.com,将使您能够在实际问题上练习技能,并获得来自一些最优秀的 ML 专业人士的帮助和见解。
本书使用的约定
本书使用以下排版约定:
斜体
指示新术语、URL、电子邮件地址、文件名和文件扩展名。
等宽
用于程序清单,以及在段落中引用程序元素,如变量或函数名、数据库、数据类型、环境变量、语句和关键字。
等宽粗体
显示用户应按照字面意义输入的命令或其他文本。
等宽斜体
显示应替换为用户提供的值或由上下文确定的值的文本。
标点
为避免混淆,本书中引号外的标点符号。对纯粹主义者表示歉意。
提示
此元素表示提示或建议。
注意
此元素表示一般说明。
警告
此元素表示警告或注意事项。
致谢
在我最疯狂的梦想中,我从未想象过这本书的第一版和第二版会获得如此庞大的读者群。我收到了许多读者的留言,许多人提出问题,一些人友善地指出勘误,大多数人给我寄来鼓励的话语。我无法表达我对所有这些读者的巨大支持的感激之情。非常感谢你们所有人!如果您在代码示例中发现错误(或者只是想提问),请毫不犹豫地在 GitHub 上提交问题,或者如果您在文本中发现错误,请提交勘误。一些读者还分享了这本书如何帮助他们找到第一份工作,或者如何帮助他们解决了他们正在处理的具体问题。我发现这样的反馈极具激励性。如果您觉得这本书有帮助,我会很高兴如果您能与我分享您的故事,无论是私下(例如通过LinkedIn)还是公开(例如在 Twitter 上@ aureliengeron 发推文或撰写亚马逊评论)。
同样非常感谢所有那些慷慨提供时间和专业知识来审阅这第三版,纠正错误并提出无数建议的出色人士。多亏了他们,这版书变得更好了:Olzhas Akpambetov、George Bonner、François Chollet、Siddha Ganju、Sam Goodman、Matt Harrison、Sasha Sobran、Lewis Tunstall、Leandro von Werra 和我亲爱的弟弟 Sylvain。你们都太棒了!
我也非常感激许多人在我前进的道路上支持我,回答我的问题,提出改进建议,并在 GitHub 上贡献代码:特别是 Yannick Assogba、Ian Beauregard、Ulf Bissbort、Rick Chao、Peretz Cohen、Kyle Gallatin、Hannes Hapke、Victor Khaustov、Soonson Kwon、Eric Lebigot、Jason Mayes、Laurence Moroney、Sara Robinson、Joaquín Ruales 和 Yuefeng Zhou。
没有 O’Reilly 出色的员工,特别是 Nicole Taché,这本书就不会存在,她给了我深刻的反馈,总是充满活力、鼓励和帮助:我无法想象有比她更好的编辑。非常感谢 Michele Cronin,她在最后几章中给予我鼓励,并帮助我完成了最后的工作。感谢整个制作团队,特别是 Elizabeth Kelly 和 Kristen Brown。同样感谢 Kim Cofer 进行了彻底的编辑工作,以及 Johnny O’Toole,他管理了与亚马逊的关系,并回答了我许多问题。感谢 Kate Dullea 大大改进了我的插图。感谢 Marie Beaugureau、Ben Lorica、Mike Loukides 和 Laurel Ruma 相信这个项目,并帮助我定义其范围。感谢 Matt Hacker 和整个 Atlas 团队回答了我关于格式、AsciiDoc、MathML 和 LaTeX 的所有技术问题,感谢 Nick Adams、Rebecca Demarest、Rachel Head、Judith McConville、Helen Monroe、Karen Montgomery、Rachel Roumeliotis 以及 O’Reilly 的所有其他贡献者。
我永远不会忘记所有在这本书的第一版和第二版中帮助过我的美好人们:朋友、同事、专家,包括 TensorFlow 团队的许多成员。名单很长:Olzhas Akpambetov,Karmel Allison,Martin Andrews,David Andrzejewski,Paige Bailey,Lukas Biewald,Eugene Brevdo,William Chargin,François Chollet,Clément Courbet,Robert Crowe,Mark Daoust,Daniel “Wolff” Dobson,Julien Dubois,Mathias Kende,Daniel Kitachewsky,Nick Felt,Bruce Fontaine,Justin Francis,Goldie Gadde,Irene Giannoumis,Ingrid von Glehn,Vincent Guilbeau,Sandeep Gupta,Priya Gupta,Kevin Haas,Eddy Hung,Konstantinos Katsiapis,Viacheslav Kovalevskyi,Jon Krohn,Allen Lavoie,Karim Matrah,Grégoire Mesnil,Clemens Mewald,Dan Moldovan,Dominic Monn,Sean Morgan,Tom O’Malley,James Pack,Alexander Pak,Haesun Park,Alexandre Passos,Ankur Patel,Josh Patterson,André Susano Pinto,Anthony Platanios,Anosh Raj,Oscar Ramirez,Anna Revinskaya,Saurabh Saxena,Salim Sémaoune,Ryan Sepassi,Vitor Sessak,Jiri Simsa,Iain Smears,Xiaodan Song,Christina Sorokin,Michel Tessier,Wiktor Tomczak,Dustin Tran,Todd Wang,Pete Warden,Rich Washington,Martin Wicke,Edd Wilder-James,Sam Witteveen,Jason Zaman,Yuefeng Zhou,以及我的兄弟 Sylvain。
最后,我要无限感谢我亲爱的妻子 Emmanuelle 和我们三个美妙的孩子 Alexandre、Rémi 和 Gabrielle,他们鼓励我努力完成这本书。他们无尽的好奇心是无价的:向妻子和孩子们解释这本书中一些最困难的概念帮助我澄清了思路,直接改进了许多部分。此外,他们还不断给我送来饼干和咖啡,还能要求什么呢?
¹ Geoffrey E. Hinton 等人,“深度信念网络的快速学习算法”,《神经计算》18 (2006): 1527–1554。
² 尽管 Yann LeCun 的深度卷积神经网络自上世纪 90 年代以来在图像识别方面表现良好,但它们并不是通用的。
第一部分:机器学习的基础知识
第一章:机器学习的概览
不久前,如果您拿起手机问路回家,它会无视您,人们会质疑您的理智。但是机器学习不再是科幻:数十亿人每天都在使用它。事实上,它实际上已经存在几十年,用于一些专业应用,比如光学字符识别(OCR)。第一个真正成为主流的机器学习应用是在上世纪 90 年代席卷全球的:垃圾邮件过滤器。它并不是一个自我意识的机器人,但从技术上讲它确实算是机器学习:它学习得如此出色,以至于您很少需要将电子邮件标记为垃圾邮件。它之后又出现了数百个机器学习应用,现在悄悄地支持着您经常使用的数百种产品和功能:语音提示、自动翻译、图像搜索、产品推荐等等。
机器学习从何开始,到何结束?机器学习某事究竟意味着什么?如果我下载了所有维基百科文章的副本,我的计算机真的学到了什么吗?它突然变聪明了吗?在本章中,我将首先澄清机器学习是什么,以及为什么您可能想要使用它。
然后,在我们开始探索机器学习大陆之前,我们将看一看地图,了解主要区域和最显著的地标:监督学习与无监督学习及其变体,在线学习与批量学习,基于实例与基于模型的学习。然后我们将看一看典型机器学习项目的工作流程,讨论您可能面临的主要挑战,并介绍如何评估和微调机器学习系统。
本章介绍了许多数据科学家应该牢记的基本概念(和行话)。这将是一个高层次的概述(这是唯一一个没有太多代码的章节),都相当简单,但我的目标是确保在继续阅读本书的其余部分之前,一切对您都是清晰的。所以泡杯咖啡,让我们开始吧!
提示
如果您已经熟悉机器学习基础知识,您可能想直接跳到第二章。如果您不确定,尝试在继续之前回答本章末尾列出的所有问题。
什么是机器学习?
机器学习是编程计算机以便它们可以从数据中学习的科学(和艺术)。
以下是一个稍微更一般的定义:
[机器学习是]一门研究领域,赋予计算机学习的能力,而无需明确编程。 亚瑟·塞缪尔,1959
还有一个更加工程导向的定义:
如果一个计算机程序在某个任务T上通过经验E,根据性能度量P的表现随着经验E的增加而改善,那么就说它从经验E中学习。 汤姆·米切尔,1997
您的垃圾邮件过滤器是一个机器学习程序,通过用户标记的垃圾邮件示例和常规邮件示例(非垃圾邮件,也称为“正常邮件”),可以学习如何标记垃圾邮件。系统用于学习的示例称为训练集。每个训练示例称为训练实例(或样本)。学习和预测的机器学习系统的部分称为模型。神经网络和随机森林是模型的示例。
在这种情况下,任务T是为新邮件标记垃圾邮件,经验E是训练数据,性能度量P需要定义;例如,您可以使用正确分类的邮件比率。这种特定的性能度量称为准确度,在分类任务中经常使用。
如果您只是下载了所有维基百科文章的副本,您的计算机拥有了更多数据,但它并不会突然在任何任务上变得更好。这不是机器学习。
为什么使用机器学习?
考虑如何使用传统编程技术编写垃圾邮件过滤器(图 1-1):
- 首先,您会检查垃圾邮件通常是什么样子的。您可能会注意到一些单词或短语(如“4U”、“信用卡”、“免费”和“惊人”)在主题行中经常出现。也许您还会注意到发件人姓名、电子邮件正文和其他部分中的一些其他模式。
- 你会为你注意到的每个模式编写一个检测算法,如果检测到这些模式中的一些,你的程序将会标记电子邮件为垃圾邮件。
- 您会测试您的程序,并重复步骤 1 和 2,直到它足够好以启动。
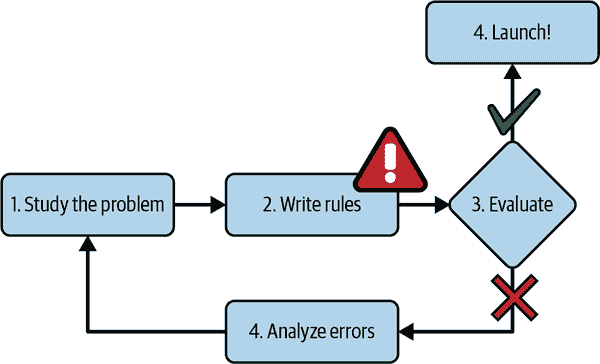
mls3 0101
图 1-1. 传统方法
由于问题很难,您的程序很可能会变成一长串复杂规则——相当难以维护。
相比之下,基于机器学习技术的垃圾邮件过滤器会自动学习哪些单词和短语是垃圾邮件的良好预测器,通过检测垃圾邮件示例中单词的异常频繁模式与正常邮件示例进行比较(图 1-2)。该程序更短,更易于维护,而且很可能更准确。
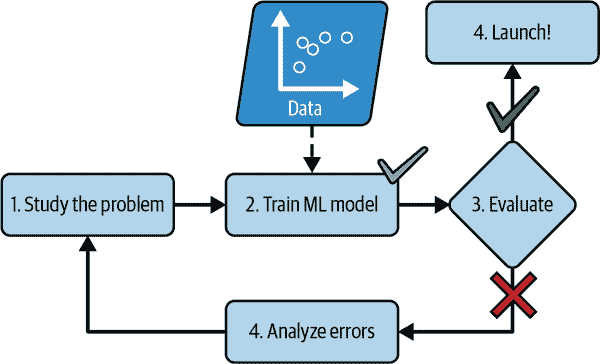
mls3 0102
图 1-2. 机器学习方法
如果垃圾邮件发送者注意到他们所有包含“4U”的电子邮件都被阻止了呢?他们可能会开始写“For U”代替。使用传统编程技术的垃圾邮件过滤器需要更新以标记“For U”电子邮件。如果垃圾邮件发送者不断绕过您的垃圾邮件过滤器,您将需要永远编写新规则。
相比之下,基于机器学习技术的垃圾邮件过滤器会自动注意到“For U”在用户标记的垃圾邮件中变得异常频繁,并开始在没有您干预的情况下标记它们(图 1-3)。
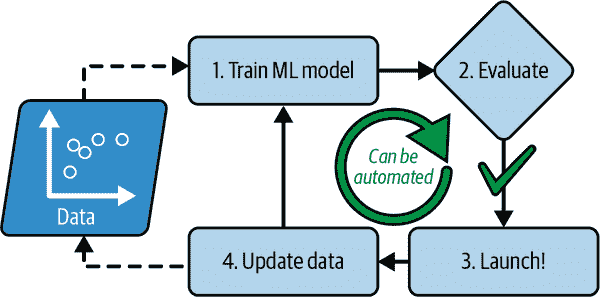
mls3 0103
图 1-3. 自动适应变化
机器学习表现出色的另一个领域是对于那些对传统方法来说要么太复杂,要么没有已知算法的问题。例如,考虑语音识别。假设你想从简单开始,编写一个能够区分“one”和“two”这两个词的程序。你可能会注意到,“two”这个词以高音(“T”)开头,因此你可以硬编码一个算法来测量高音强度,并使用它来区分“one”和“two”——但显然,这种技术无法扩展到成千上万个单词,由数百万个非常不同的人在嘈杂环境中以及数十种语言中说出。最好的解决方案(至少是今天)是编写一个算法,通过给定每个单词的许多示例录音来自学习。
最后,机器学习可以帮助人类学习(图 1-4)。机器学习模型可以被检查以查看它们学到了什么(尽管对于某些模型来说可能有些棘手)。例如,一旦一个垃圾邮件过滤器已经在足够多的垃圾邮件上训练过,就可以轻松地检查它,以显示它认为是最佳垃圾邮件预测器的单词和单词组合的列表。有时这会揭示出意想不到的相关性或新趋势,从而更好地理解问题。挖掘大量数据以发现隐藏模式被称为数据挖掘,而机器学习在这方面表现出色。
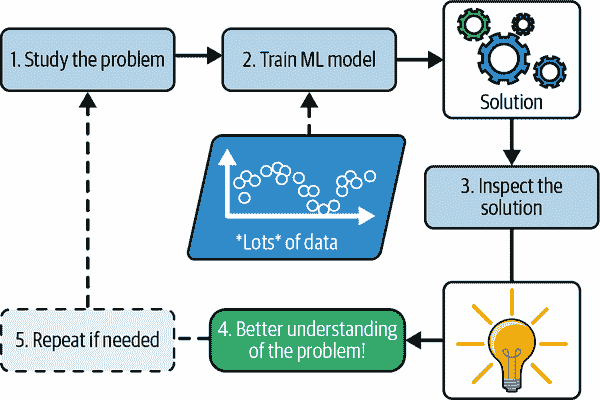
mls3 0104
图 1-4. 机器学习可以帮助人类学习
总之,机器学习非常适用于:
- 需要大量微调或长列表规则的现有解决方案的问题(机器学习模型通常可以简化代码并比传统方法表现更好)
- 对于使用传统方法得不到好解决方案的复杂问题(最好的机器学习技术或许可以找到解决方案)
- 波动的环境(机器学习系统可以轻松地在新数据上重新训练,始终保持最新状态)
- 获取关于复杂问题和大量数据的见解
应用示例
让我们看一些机器学习任务的具体示例,以及可以解决它们的技术:
分析生产线上产品的图像以自动分类它们
这是图像分类,通常使用卷积神经网络(CNN;参见第十四章)或有时使用Transformer(参见第十六章)进行处理。
检测脑部扫描中的肿瘤
这是语义图像分割,其中图像中的每个像素都被分类(因为我们想要确定肿瘤的确切位置和形状),通常使用 CNN 或Transformer。
自动分类新闻文章
这是自然语言处理(NLP),更具体地说是文本分类,可以使用循环神经网络(RNN)和 CNN 来解决,但Transformer效果更好(参见第十六章)。
自动标记讨论论坛上的攻击性评论
这也是文本分类,使用相同的 NLP 工具。
自动总结长文档
这是一种称为文本摘要的 NLP 分支,再次使用相同的工具。
创建一个聊天机器人或个人助手
这涉及许多 NLP 组件,包括自然语言理解(NLU)和问答模块。
根据许多绩效指标预测公司明年的收入
这是一个回归任务(即预测值),可以使用任何回归模型来解决,例如线性回归或多项式回归模型(参见第四章)、回归支持向量机(参见第五章)、回归随机森林(参见第七章)或人工神经网络(参见第十章)。如果您想考虑过去绩效指标的序列,可能需要使用 RNN、CNN 或Transformer(参见第十五章和第十六章)。
使您的应用程序对语音命令做出反应
这是语音识别,需要处理音频样本:由于它们是长而复杂的序列,通常使用 RNN、CNN 或Transformer进行处理(参见第十五章和第十六章)。
检测信用卡欺诈
这是异常检测,可以使用隔离森林、高斯混合模型或自编码器来解决(参见第九章)。
根据客户的购买情况对客户进行分段,以便为每个细分设计不同的营销策略
这是聚类,可以使用k-means、DBSCAN 等方法来实现(参见第九章)。
在清晰而富有洞察力的图表中表示复杂的高维数据集
这是数据可视化,通常涉及降维技术(参见第八章)。
根据过去的购买记录推荐客户可能感兴趣的产品
这是一个推荐系统。一种方法是将过去的购买记录(以及有关客户的其他信息)输入到人工神经网络中(参见第十章),并让其输出最可能的下一个购买。这种神经网络通常会在所有客户的过去购买序列上进行训练。
为游戏构建一个智能机器人
这通常是通过强化学习(RL)来解决的(请参阅第十八章),这是机器学习的一个分支,训练代理人(如机器人)选择能够随着时间最大化奖励的动作(例如,每次玩家失去一些生命值时机器人都会获得奖励),在给定环境(例如游戏)中。击败围棋世界冠军的著名 AlphaGo 程序就是使用 RL 构建的。
这个列表可以继续下去,但希望它能让您感受到机器学习可以处理的任务的广泛和复杂性,以及您将为每个任务使用的技术类型。
机器学习系统的类型
有许多不同类型的机器学习系统,将它们根据以下标准进行广泛分类是有用的:
- 它们在训练过程中如何受监督(监督、无监督、半监督、自监督等)
- 无论它们是否可以在飞行中逐步学习(在线与批量学习)
- 它们是通过简单地将新数据点与已知数据点进行比较,还是通过检测训练数据中的模式并构建预测模型,就像科学家所做的那样(基于实例与基于模型的学习)
这些标准并不是互斥的;您可以以任何您喜欢的方式组合它们。例如,一款最先进的垃圾邮件过滤器可能会使用深度神经网络模型进行在线学习,该模型是使用人类提供的垃圾邮件和正常邮件示例进行训练的;这使其成为一个在线、基于模型的监督学习系统。
让我们更仔细地看看这些标准中的每一个。
训练监督
ML 系统可以根据训练过程中获得的监督量和类型进行分类。有许多类别,但我们将讨论主要的类别:监督学习、无监督学习、自监督学习、半监督学习和强化学习。
监督学习
在监督学习中,您向算法提供的训练集包括所需的解决方案,称为标签(图 1-5)。
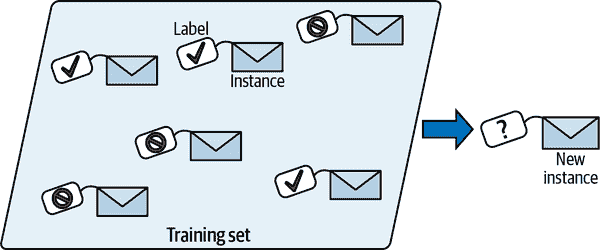
mls3 0105
图 1-5. 用于垃圾邮件分类的带标签训练集(监督学习的示例)
典型的监督学习任务是分类。垃圾邮件过滤器就是一个很好的例子:它通过许多示例电子邮件及其类别(垃圾邮件或正常邮件)进行训练,并且必须学会如何对新邮件进行分类。
另一个典型的任务是预测一个目标数值,例如一辆汽车的价格,给定一组特征(里程、年龄、品牌等)。这种类型的任务被称为回归(图 1-6)。为了训练系统,您需要提供许多汽车的示例,包括它们的特征和目标(即它们的价格)。
请注意,一些回归模型也可以用于分类,反之亦然。例如,逻辑回归通常用于分类,因为它可以输出与属于给定类别的概率相对应的值(例如,属于垃圾邮件的概率为 20%)。
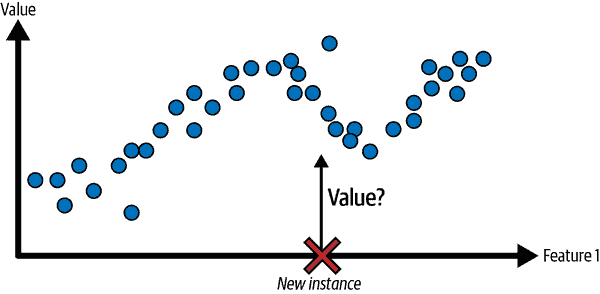
mls3 0106
图 1-6. 一个回归问题:根据输入特征预测一个值(通常有多个输入特征,有时有多个输出值)
注意
在监督学习中,目标和标签通常被视为同义词,但目标在回归任务中更常见,标签在分类任务中更常见。此外,特征有时被称为预测变量或属性。这些术语可能指个别样本(例如,“这辆车的里程特征等于 15,000”)或所有样本(例如,“里程特征与价格强相关”)。
无监督学习
在无监督学习中,正如您可能猜到的那样,训练数据是未标记的(图 1-7)。系统试图在没有老师的情况下学习。
例如,假设您有关于博客访问者的大量数据。您可能希望运行一个聚类算法来尝试检测相似访问者的群组。在任何时候,您都不告诉算法访问者属于哪个群组:它会在没有您帮助的情况下找到这些连接。例如,它可能注意到您的 40%访问者是喜欢漫画书并且通常在放学后阅读您的博客的青少年,而 20%是喜欢科幻并且在周末访问的成年人。如果使用层次聚类算法,它还可以将每个群组细分为更小的群组。这可能有助于您为每个群体定位您的帖子。

mls3 0107
图 1-7. 无监督学习的未标记训练集
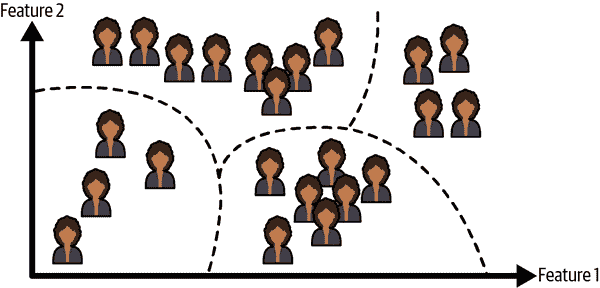
mls3 0108
图 1-8. 聚类
可视化算法也是无监督学习的很好的例子:你向它们提供大量复杂且未标记的数据,它们会输出数据的二维或三维表示,可以轻松绘制出来。这些算法试图尽可能保留数据的结构(例如,尝试在可视化中保持输入空间中的不同簇不重叠),以便您可以了解数据的组织方式,也许还可以识别出意想不到的模式。
一个相关的任务是降维,其目标是简化数据而不丢失太多信息。一种方法是将几个相关特征合并为一个。例如,一辆汽车的里程可能与其年龄强相关,因此降维算法将它们合并为一个代表汽车磨损程度的特征。这被称为特征提取。
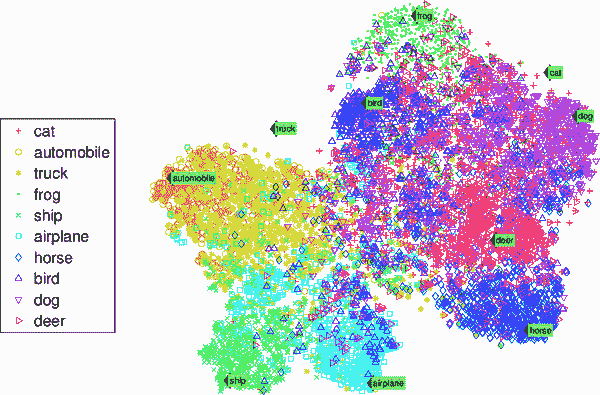
mls3 0109
图 1-9. t-SNE 可视化示例,突出显示语义簇²
提示
在将训练数据提供给另一个机器学习算法(如监督学习算法)之前,尝试使用降维算法减少训练数据的维数通常是一个好主意。这样可以使运行速度更快,数据占用的磁盘和内存空间更少,并且在某些情况下可能表现更好。
另一个重要的无监督任务是异常检测——例如,检测异常的信用卡交易以防止欺诈,捕捉制造缺陷,或在将数据提供给另一个学习算法之前自动删除异常值。系统在训练期间主要展示正常实例,因此学会了识别它们;然后,当它看到一个新实例时,它可以判断它是否看起来像一个正常实例,或者它很可能是一个异常(见图 1-10)。一个非常相似的任务是新颖性检测:它旨在检测看起来与训练集中所有实例都不同的新实例。这需要一个非常“干净”的训练集,不包含您希望算法检测的任何实例。例如,如果您有成千上万张狗的图片,其中 1%的图片代表吉娃娃,那么新颖性检测算法不应该将新的吉娃娃图片视为新颖。另一方面,异常检测算法可能认为这些狗非常罕见,与其他狗有很大不同,因此很可能将它们分类为异常(对吉娃娃没有冒犯意图)。
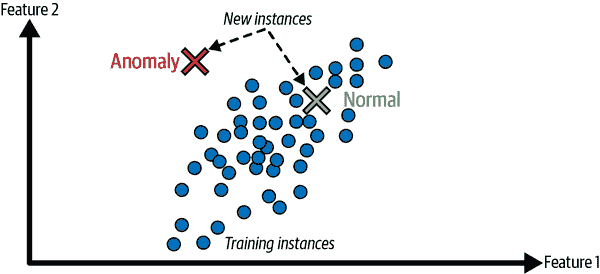
mls3 0110
图 1-10. 异常检测
最后,另一个常见的无监督任务是关联规则学习,其目标是挖掘大量数据并发现属性之间的有趣关系。例如,假设您拥有一家超市。在销售日志上运行关联规则可能会发现购买烧烤酱和薯片的人也倾向于购买牛排。因此,您可能希望将这些物品放在彼此附近。
半监督学习
由于标记数据通常耗时且昂贵,您通常会有大量未标记的实例和少量标记的实例。一些算法可以处理部分标记的数据。这被称为半监督学习(图 1-11)。
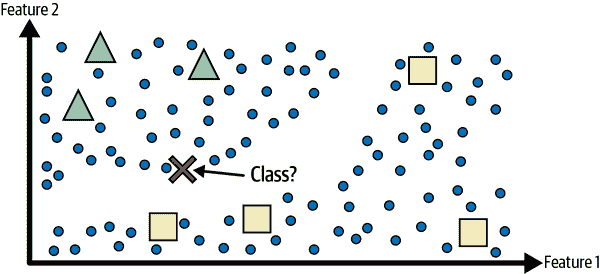
mls3 0111
图 1-11. 两类(三角形和正方形)的半监督学习:未标记的示例(圆圈)有助于将新实例(十字)分类为三角形类,而不是正方形类,即使它更接近标记的正方形
一些照片托管服务,如 Google 相册,就是很好的例子。一旦您将所有家庭照片上传到该服务,它会自动识别出同一个人 A 出现在照片 1、5 和 11 中,而另一个人 B 出现在照片 2、5 和 7 中。这是算法的无监督部分(聚类)。现在系统只需要您告诉它这些人是谁。只需为每个人添加一个标签³,它就能够为每张照片中的每个人命名,这对于搜索照片很有用。
大多数半监督学习算法是无监督和监督算法的组合。例如,可以使用聚类算法将相似的实例分组在一起,然后每个未标记的实例可以用其簇中最常见的标签进行标记。一旦整个数据集被标记,就可以使用任何监督学习算法。
自监督学习
另一种机器学习方法涉及从完全未标记的数据集中生成一个完全标记的数据集。再次,一旦整个数据集被标记,就可以使用任何监督学习算法。这种方法被称为自监督学习。
例如,如果您有一个大量未标记的图像数据集,您可以随机遮挡每个图像的一小部分,然后训练一个模型恢复原始图像(图 1-12)。在训练过程中,遮挡的图像被用作模型的输入,原始图像被用作标签。

mls3 0112
图 1-12. 自监督学习示例:输入(左)和目标(右)
得到的模型本身可能非常有用,例如用于修复损坏的图像或从图片中删除不需要的物体。但通常情况下,使用自监督学习训练的模型并不是最终目标。通常您会想要微调和调整模型以执行一个略有不同的任务,一个您真正关心的任务。
例如,假设您真正想要的是一个宠物分类模型:给定任何宠物的图片,它将告诉您它属于哪个物种。如果您有一个大量未标记的宠物照片数据集,您可以通过使用自监督学习训练一个图像修复模型来开始。一旦表现良好,它应该能够区分不同的宠物物种:当它修复一个脸部被遮盖的猫的图像时,它必须知道不要添加狗的脸。假设您的模型架构允许这样做(大多数神经网络架构都允许),那么就可以调整模型,使其预测宠物物种而不是修复图像。最后一步是在一个标记的数据集上对模型进行微调:模型已经知道猫、狗和其他宠物物种的外观,因此这一步只是为了让模型学习它已经知道的物种与我们期望从中得到的标签之间的映射。
注意
从一个任务中转移知识到另一个任务被称为迁移学习,这是当今机器学习中最重要的技术之一,特别是在使用深度神经网络(即由许多层神经元组成的神经网络)时。我们将在第二部分中详细讨论这个问题。
有些人认为自监督学习是无监督学习的一部分,因为它处理完全未标记的数据集。但是自监督学习在训练过程中使用(生成的)标签,因此在这方面更接近于监督学习。而“无监督学习”这个术语通常用于处理聚类、降维或异常检测等任务,而自监督学习侧重于与监督学习相同的任务:主要是分类和回归。简而言之,最好将自监督学习视为其自己的类别。
强化学习
强化学习是一种非常不同的学习方式。在这种情况下,学习系统被称为代理,它可以观察环境,选择和执行动作,并获得奖励(或以负奖励形式的惩罚,如图 1-13 所示)。然后,它必须自己学习什么是最佳策略,称为策略,以获得最大的奖励。策略定义了代理在特定情况下应该选择什么动作。
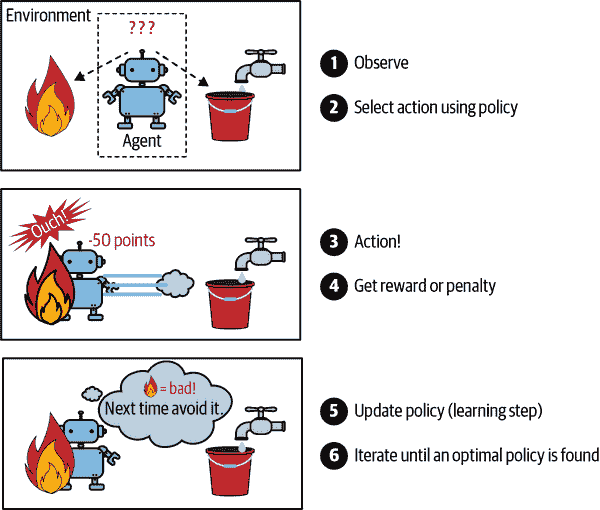
mls3 0113
图 1-13。强化学习
例如,许多机器人实现强化学习算法来学习如何行走。DeepMind 的 AlphaGo 程序也是强化学习的一个很好的例子:2017 年 5 月,它在围棋比赛中击败了当时世界排名第一的柯洁,成为头条新闻。它通过分析数百万场比赛学习了其获胜策略,然后对自己进行了许多场比赛。请注意,在与冠军对战时学习被关闭;AlphaGo 只是应用了它学到的策略。正如您将在下一节中看到的那样,这被称为离线学习。
批量学习与在线学习
用于分类机器学习系统的另一个标准是系统是否能够从不断涌入的数据流中逐步学习。
批量学习
在批量学习中,系统无法逐步学习:它必须使用所有可用数据进行训练。这通常需要大量时间和计算资源,因此通常在离线状态下进行。首先训练系统,然后将其投入生产并在不再学习的情况下运行;它只是应用它所学到的知识。这被称为离线学习。
不幸的是,模型的性能往往会随着时间的推移而缓慢下降,仅仅因为世界在不断发展,而模型保持不变。这种现象通常被称为模型腐烂或数据漂移。解决方案是定期使用最新数据对模型进行重新训练。您需要多久才能做到这一点取决于用例:如果模型对猫和狗的图片进行分类,其性能将会缓慢下降,但如果模型处理快速演变的系统,例如在金融市场上进行预测,那么它可能会迅速下降。
警告
即使是训练用于分类猫和狗图片的模型,也可能需要定期重新训练,不是因为猫和狗会在一夜之间发生变异,而是因为相机不断变化,图像格式、清晰度、亮度和大小比例也在变化。此外,人们可能会在明年喜欢不同的品种,或者决定给他们的宠物戴上小帽子——谁知道呢?
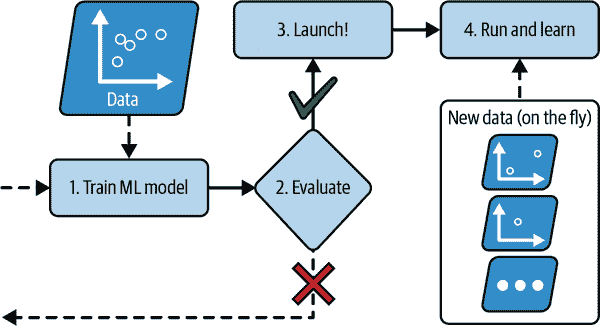
如果您希望批量学习系统了解新数据(例如新类型的垃圾邮件),您需要从头开始对完整数据集进行新版本系统的训练(不仅仅是新数据,还包括旧数据),然后用新模型替换旧模型。幸运的是,整个机器学习系统的训练、评估和启动过程可以相当容易地自动化(正如我们在图 1-3 中看到的那样),因此即使是批量学习系统也可以适应变化。只需根据需要更新数据并从头开始训练新版本的系统。
这个解决方案简单且通常效果良好,但使用完整数据集进行训练可能需要很多小时,因此您通常只会每 24 小时或甚至每周训练一个新系统。如果您的系统需要适应快速变化的数据(例如,预测股票价格),那么您需要一个更具反应性的解决方案。
此外,对完整数据集进行训练需要大量的计算资源(CPU、内存空间、磁盘空间、磁盘 I/O、网络 I/O 等)。如果您有大量数据并且自动化系统每天从头开始训练,那么最终会花费很多钱。如果数据量很大,甚至可能无法使用批量学习算法。
最后,如果您的系统需要能够自主学习并且资源有限(例如,智能手机应用程序或火星车),那么携带大量训练数据并每天花费大量资源进行训练是一个障碍。
在所有这些情况下,更好的选择是使用能够增量学习的算法。
在线学习
在在线学习中,您通过顺序地逐个或以小组(称为小批量)的方式向系统提供数据实例来逐步训练系统。每个学习步骤都很快且便宜,因此系统可以在数据到达时即时学习新数据(参见图 1-14)。
mls3 0114
图 1-14。在在线学习中,模型经过训练并投入生产,然后随着新数据的到来而不断学习
在线学习对需要极快适应变化的系统非常有用(例如,检测股市中的新模式)。如果您的计算资源有限,例如在移动设备上训练模型,这也是一个不错的选择。
此外,可以使用在线学习算法在无法适应一台机器的主内存的大型数据集上训练模型(这称为离线学习)。该算法加载部分数据,在该数据上运行训练步骤,并重复该过程,直到在所有数据上运行完毕(参见图 1-15)。
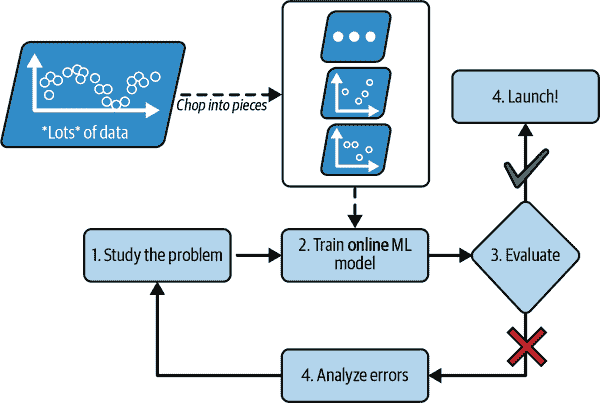
mls3 0115
图 1-15。使用在线学习处理大型数据集
在线学习系统的一个重要参数是它们应该如何快速适应变化的数据:这被称为“学习率”。如果设置较高的学习率,那么您的系统将迅速适应新数据,但也会很快忘记旧数据(您不希望垃圾邮件过滤器只标记它所展示的最新类型的垃圾邮件)。相反,如果设置较低的学习率,系统将具有更多的惯性;也就是说,它将学习得更慢,但也会对新数据中的噪声或非代表性数据点序列(异常值)不太敏感。
警告
离线学习通常是在离线系统上完成的(即不在实时系统上),因此“在线学习”可能是一个令人困惑的名称。将其视为“增量学习”。
在线学习的一个重大挑战是,如果向系统提供了错误数据,系统的性能将下降,可能会很快下降(取决于数据质量和学习率)。如果这是一个实时系统,您的客户会注意到。例如,错误的数据可能来自错误(例如,机器人上的传感器故障),也可能来自试图操纵系统的人(例如,通过垃圾信息搜索引擎以在搜索结果中排名靠前)。为了降低这种风险,您需要密切监控系统,并在检测到性能下降时及时关闭学习(并可能恢复到先前工作状态)。您还可能希望监控输入数据并对异常数据做出反应;例如,使用异常检测算法(参见第九章)。
基于实例与基于模型的学习
将机器学习系统分类的另一种方法是通过它们的泛化方式。大多数机器学习任务都是关于进行预测。这意味着给定一些训练示例,系统需要能够对它以前从未见过的示例进行良好的预测(泛化)。在训练数据上有一个良好的性能度量是好的,但不足够;真正的目标是在新实例上表现良好。
泛化有两种主要方法:基于实例的学习和基于模型的学习。
基于实例的学习
可能最琐碎的学习形式就是纯粹靠记忆学习。如果您按照这种方式创建垃圾邮件过滤器,它将只标记所有与用户已标记的电子邮件相同的电子邮件,这并不是最糟糕的解决方案,但肯定不是最好的解决方案。
而不仅仅是标记与已知垃圾邮件相同的电子邮件,您的垃圾邮件过滤器还可以被编程为标记与已知垃圾邮件非常相似的电子邮件。这需要两封电子邮件之间的相似度度量。两封电子邮件之间的(非常基本的)相似度度量可以是计算它们共同拥有的单词数量。如果一封电子邮件与已知的垃圾邮件有许多共同单词,系统将标记该电子邮件为垃圾邮件。
这称为基于实例的学习:系统通过记忆示例,然后使用相似度度量将新案例泛化到学习示例(或其中的一个子集)。例如,在图 1-16 中,新实例将被分类为三角形,因为大多数最相似的实例属于该类。
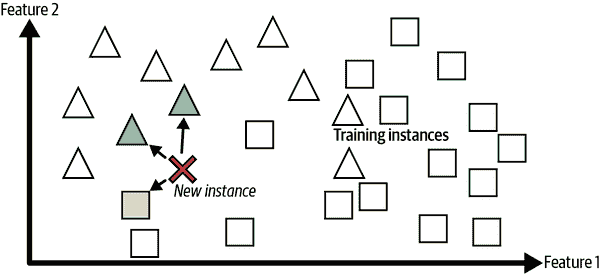
mls3 0116
图 1-16. 基于实例的学习
基于模型的学习和典型的机器学习工作流程
从一组示例中泛化的另一种方法是构建这些示例的模型,然后使用该模型进行预测。这称为基于模型的学习(图 1-17)。
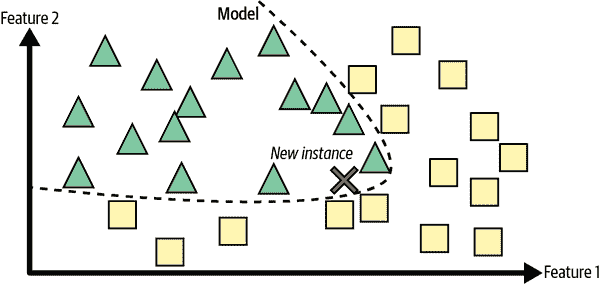
mls3 0117
图 1-17. 基于模型的学习
例如,假设您想知道金钱是否让人们快乐,因此您从OECD 网站下载更美好生活指数数据和世界银行统计数据关于人均国内生产总值(GDP)。然后您连接这些表格并按人均 GDP 排序。表 1-1 显示了您获得的摘录。
表 1-1. 金钱让人更快乐吗?
国家 | 人均 GDP(美元) | 生活满意度 |
|---|---|---|
土耳其 | 28,384 | 5.5 |
匈牙利 | 31,008 | 5.6 |
法国 | 42,026 | 6.5 |
美国 | 60,236 | 6.9 |
新西兰 | 42,404 | 7.3 |
澳大利亚 | 48,698 | 7.3 |
丹麦 | 55,938 | 7.6 |
让我们为这些国家的数据绘制图表(图 1-18)。
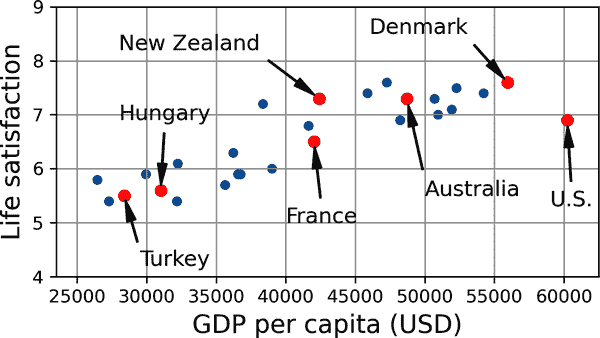
mls3 0118
图 1-18. 你看到这里有一个趋势吗?
这里似乎有一个趋势!尽管数据是嘈杂的(即部分随机),但看起来生活满意度随着国家人均 GDP 的增加而更多或更少地呈线性增长。因此,您决定将生活满意度建模为国家人均 GDP 的线性函数。这一步称为模型选择:您选择了一个只有一个属性,即国家人均 GDP 的生活满意度的线性模型(方程 1-1)。
方程 1-1. 一个简单的线性模型
life_satisfaction = θ 0 + θ 1 × GDP_per_capita
该模型有两个模型参数,θ[0]和θ[1]。⁴ 通过调整这些参数,您可以使您的模型表示任何线性函数,如图 1-19 所示。
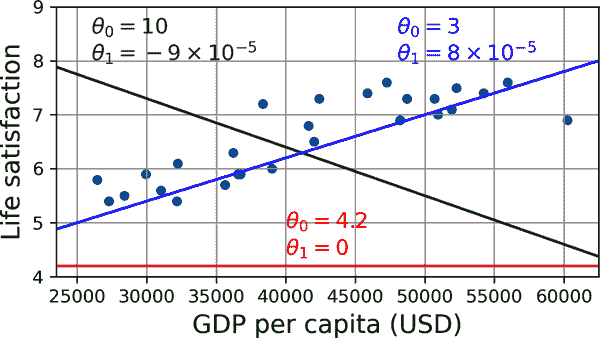
mls3 0119
图 1-19. 几种可能的线性模型
在使用模型之前,您需要定义参数值θ[0]和θ[1]。您如何知道哪些值会使您的模型表现最佳?要回答这个问题,您需要指定一个性能度量。您可以定义一个度量模型好坏的效用函数(或适应函数),也可以定义一个度量模型坏的成本函数。对于线性回归问题,人们通常使用一个测量线性模型预测与训练示例之间距离的成本函数;目标是最小化这个距离。
这就是线性回归算法的作用:您将训练示例提供给它,它会找到使线性模型最适合您的数据的参数。这称为训练模型。在我们的情况下,算法发现最佳参数值为θ[0] = 3.75 和θ[1] = 6.78 × 10^(–5)。
警告
令人困惑的是,“模型”这个词可以指一个模型类型(例如线性回归),也可以指一个完全指定的模型架构(例如具有一个输入和一个输出的线性回归),或者指准备用于预测的最终训练好的模型(例如具有一个输入和一个输出的线性回归,使用θ[0] = 3.75 和θ[1] = 6.78 × 10^(–5))。模型选择包括选择模型类型和完全指定其架构。训练模型意味着运行算法以找到使其最佳拟合训练数据的模型参数,并希望在新数据上做出良好的预测。
现在模型尽可能地拟合训练数据(对于线性模型),如您在图 1-20 中所见。
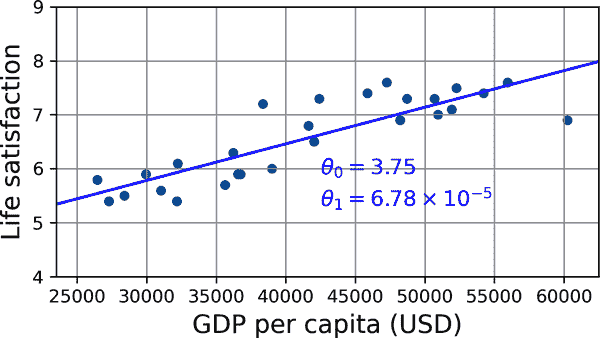
mls3 0120
图 1-20。最佳拟合训练数据的线性模型
您现在准备运行模型进行预测。例如,假设您想知道塞浦路斯人有多幸福,而 OECD 数据没有答案。幸运的是,您可以使用您的模型进行良好的预测:查找塞浦路斯的人均 GDP,找到 37655 美元,然后应用您的模型,发现生活满意度可能在 3.75 + 37655 × 6.78 × 10^(–5) = 6.30 左右。
为了激起您的兴趣,示例 1-1 展示了加载数据、将输入X与标签y分开、创建散点图进行可视化、然后训练线性模型并进行预测的 Python 代码。⁵
示例 1-1。使用 Scikit-Learn 训练和运行线性模型
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# Download and prepare the data
data_root = "https://github.com/ageron/data/raw/main/"
lifesat = pd.read_csv(data_root + "lifesat/lifesat.csv")
X = lifesat[["GDP per capita (USD)"]].values
y = lifesat[["Life satisfaction"]].values
# Visualize the data
lifesat.plot(kind='scatter', grid=True,
x="GDP per capita (USD)", y="Life satisfaction")
plt.axis([23_500, 62_500, 4, 9])
plt.show()
# Select a linear model
model = LinearRegression()
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[37_655.2]] # Cyprus' GDP per capita in 2020
print(model.predict(X_new)) # output: [[6.30165767]]注意
如果您使用了基于实例的学习算法,您会发现以色列的人均 GDP 最接近塞浦路斯的人均 GDP(38341 美元),由于 OECD 数据告诉我们以色列人的生活满意度为 7.2,您可能会预测塞浦路斯的生活满意度为 7.2。如果您稍微放大一点并查看两个最接近的国家,您会发现立陶宛和斯洛文尼亚,两者的生活满意度都为 5.9。将这三个值平均,您会得到 6.33,这与基于模型的预测非常接近。这个简单的算法称为k-最近邻回归(在这个例子中,k = 3)。
在前面的代码中用k-最近邻回归替换线性回归模型就像替换这些行一样容易:
from sklearn.linear_model import LinearRegression
model = LinearRegression()这两个:
from sklearn.neighbors import KNeighborsRegressor
model = KNeighborsRegressor(n_neighbors=3)如果一切顺利,您的模型将做出良好的预测。如果不是,您可能需要使用更多属性(就业率、健康、空气污染等)、获取更多或更高质量的训练数据,或者选择一个更强大的模型(例如多项式回归模型)。
总结:
- 您研究了数据。
- 您选择了一个模型。
- 您在训练数据上对其进行了训练(即,学习算法搜索使模型参数值最小化成本函数)。
- 最后,您应用模型对新案例进行预测(这称为推断),希望这个模型能很好地泛化。
这是一个典型的机器学习项目的样子。在第二章中,您将通过从头到尾完成一个项目来亲身体验这一过程。
到目前为止,我们已经涵盖了很多内容:您现在知道机器学习真正关注的是什么,为什么它有用,一些最常见的 ML 系统类别是什么,以及典型项目工作流程是什么样的。现在让我们看看在学习过程中可能出现的问题,阻止您做出准确的预测。
机器学习的主要挑战
简而言之,由于您的主要任务是选择一个模型并在一些数据上进行训练,可能出错的两个因素是“坏模型”和“坏数据”。让我们从坏数据的例子开始。
训练数据数量不足
对于一个幼儿来学习什么是苹果,只需要您指向一个苹果并说“苹果”(可能需要重复几次这个过程)。现在孩子能够识别各种颜色和形状的苹果了。天才。
机器学习还没有完全成熟;大多数机器学习算法需要大量数据才能正常工作。即使对于非常简单的问题,您通常也需要成千上万的示例,而对于像图像或语音识别这样的复杂问题,您可能需要数百万的示例(除非您可以重用现有模型的部分)。
非代表性训练数据
为了很好地泛化,您的训练数据必须代表您想要泛化到的新案例。无论您使用基于实例的学习还是基于模型的学习,这一点都是真实的。
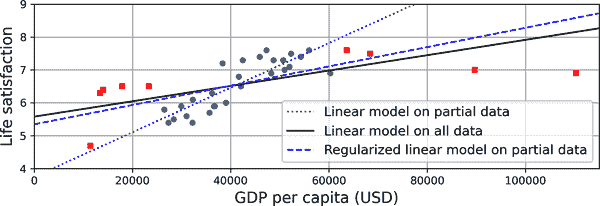
例如,您之前用于训练线性模型的国家集合并不完全代表性;它不包含人均 GDP 低于 23,500 美元或高于 62,500 美元的任何国家。图 1-22 展示了当您添加这样的国家时数据的样子。
如果您在这些数据上训练线性模型,您将得到实线,而旧模型由虚线表示。正如您所看到的,不仅添加一些缺失的国家会显著改变模型,而且清楚地表明这样一个简单的线性模型可能永远不会很好地工作。似乎非常富裕的国家并不比中等富裕的国家更幸福(事实上,它们似乎稍微不那么幸福!),反之,一些贫穷的国家似乎比许多富裕国家更幸福。
通过使用非代表性的训练集,您训练了一个不太可能做出准确预测的模型,特别是对于非常贫穷和非常富裕的国家。
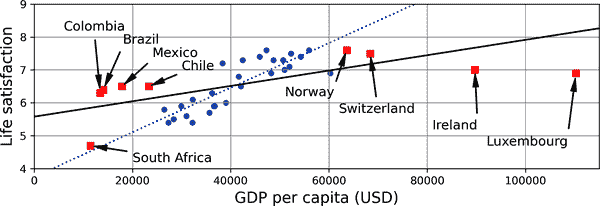
mls3 0122
图 1-22。更具代表性的训练样本
使用代表您想要泛化到的案例的训练集至关重要。这通常比听起来更难:如果样本太小,您将会有抽样误差(即由于偶然性导致的非代表性数据),但即使是非常大的样本也可能是非代表性的,如果抽样方法有缺陷的话。这被称为抽样偏差。
低质量数据
显然,如果您的训练数据中充满错误、异常值和噪音(例如,由于质量不佳的测量),这将使系统更难检测到潜在的模式,因此您的系统更不可能表现良好。花时间清理训练数据通常是非常值得的。事实上,大多数数据科学家花费大部分时间就是在做这件事。以下是您需要清理训练数据的几个例子:
- 如果一些实例明显是异常值,简单地丢弃它们或尝试手动修复错误可能有所帮助。
- 如果一些实例缺少一些特征(例如,5%的客户没有指定年龄),您必须决定是否要完全忽略这个属性,忽略这些实例,填补缺失值(例如,用中位数年龄),或者训练一个带有该特征的模型和一个不带该特征的模型。
无关特征
俗话说:垃圾进,垃圾出。只有当训练数据包含足够相关的特征而不包含太多无关的特征时,您的系统才能学习。机器学习项目成功的关键部分之一是提出一组良好的特征进行训练。这个过程被称为特征工程,包括以下步骤:
- 特征选择(在现有特征中选择最有用的特征进行训练)
- 特征提取(将现有特征组合以生成更有用的特征——正如我们之前看到的,降维算法可以帮助)
- 通过收集新数据创建新特征
现在我们已经看了很多坏数据的例子,让我们看一看一些坏算法的例子。
过拟合训练数据
假设您正在访问一个外国国家,出租车司机宰客。您可能会说那个国家的所有出租车司机都是小偷。过度概括是我们人类经常做的事情,不幸的是,如果我们不小心,机器也会陷入同样的陷阱。在机器学习中,这被称为过拟合:这意味着模型在训练数据上表现良好,但在泛化上表现不佳。
图 1-23 显示了一个高次多项式生活满意度模型的例子,它在训练数据上过拟合。尽管它在训练数据上的表现比简单线性模型要好得多,但您真的会相信它的预测吗?
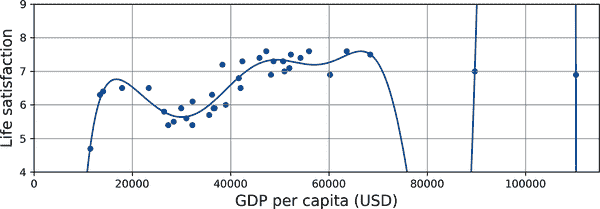
mls3 0123
图 1-23. 过拟合训练数据
像深度神经网络这样的复杂模型可以检测数据中的微妙模式,但如果训练集存在噪声,或者太小,引入了抽样误差,那么模型很可能会检测到噪声本身中的模式(就像出租车司机的例子)。显然,这些模式不会推广到新实例。例如,假设您向生活满意度模型提供了更多属性,包括无信息的属性,如国家名称。在这种情况下,复杂模型可能会检测到模式,比如训练数据中所有带有W的国家名称的生活满意度大于 7:新西兰(7.3)、挪威(7.6)、瑞典(7.3)和瑞士(7.5)。您有多大信心认为W-满意度规则适用于卢旺达或津巴布韦?显然,这种模式纯粹是偶然出现在训练数据中,但模型无法判断一个模式是真实的还是仅仅是数据中的噪声所致。
警告
过拟合发生在模型相对于训练数据的数量和噪声过多时。以下是可能的解决方案:
- 通过选择具有较少参数的模型(例如,线性模型而不是高次多项式模型)、减少训练数据中的属性数量或约束模型来简化模型。
- 收集更多的训练数据。
- 减少训练数据中的噪声(例如,修复数据错误和删除异常值)。
通过对模型进行约束使其变得更简单并减少过拟合风险称为正则化。例如,我们之前定义的线性模型有两个参数,θ[0]和θ[1]。这给学习算法两个自由度来调整模型以适应训练数据:它可以调整线的高度(θ[0])和斜率(θ[1])。如果我们强制θ[1] = 0,算法将只有一个自由度,并且更难正确拟合数据:它只能上下移动线以尽可能接近训练实例,因此最终会在均值附近。一个非常简单的模型!如果允许算法修改θ[1]但强制保持较小,则学习算法实际上将在一个自由度和两个自由度之间。它将产生一个比具有两个自由度的模型更简单,但比只有一个自由度的模型更复杂的模型。您希望找到完全拟合训练数据并保持模型足够简单以确保其良好泛化的正确平衡。
图 1-24 展示了三个模型。虚线代表原始模型,该模型是在以圆圈表示的国家上进行训练的(不包括以方块表示的国家),实线是我们的第二个模型,训练了所有国家(圆圈和方块),虚线是一个使用与第一个模型相同数据进行训练但带有正则化约束的模型。您可以看到正则化强制模型具有较小的斜率:这个模型不像第一个模型那样很好地拟合训练数据(圆圈),但实际上更好地泛化到在训练过程中没有见过的新示例(方块)。
mls3 0124
图 1-24. 正则化减少过拟合风险
在学习过程中应用的正则化量可以通过超参数来控制。超参数是学习算法的参数(而不是模型的参数)。因此,它不受学习算法本身的影响;它必须在训练之前设置,并在训练过程中保持不变。如果将正则化超参数设置为非常大的值,您将得到一个几乎平坦的模型(斜率接近零);学习算法几乎肯定不会过度拟合训练数据,但更不太可能找到一个好的解决方案。调整超参数是构建机器学习系统的重要部分(您将在下一章中看到一个详细的示例)。
训练数据欠拟合
正如您可能猜到的,欠拟合是过拟合的相反:当您的模型过于简单而无法学习数据的基本结构时,就会发生欠拟合。例如,对生活满意度的线性模型容易发生欠拟合;现实比模型更复杂,因此其预测很可能不准确,即使在训练示例上也是如此。
以下是解决此问题的主要选项:
- 选择一个更强大的模型,具有更多参数。
- 向学习算法提供更好的特征(特征工程)。
- 减少模型的约束(例如通过减少正则化超参数)。
退一步
到目前为止,您已经了解了很多关于机器学习的知识。然而,我们讨论了许多概念,您可能感到有点迷茫,所以让我们退一步,看看整体情况:
- 机器学习是通过从数据中学习来使机器在某些任务上变得更好,而不是必须明确编写规则。
- 有许多不同类型的 ML 系统:监督或非监督,批处理或在线,基于实例或基于模型。
- 在一个机器学习项目中,你在训练集中收集数据,并将训练集提供给学习算法。如果算法是基于模型的,它会调整一些参数以使模型适应训练集(即,在训练集上做出良好的预测),然后希望它也能在新案例上做出良好的预测。如果算法是基于实例的,它只是通过记忆例子并使用相似度度量来将它们与学习的实例进行比较,从而推广到新实例。
- 如果你的训练集太小,或者数据不具代表性,噪音太大,或者包含无关特征(垃圾进,垃圾出),系统将无法表现良好。最后,你的模型既不能太简单(这样它会欠拟合),也不能太复杂(这样它会过拟合)。
最后一个重要的主题要讨论:一旦你训练了一个模型,你不希望只是“希望”它能推广到新案例。你希望对其进行评估,并在必要时进行微调。让我们看看如何做到这一点。
测试和验证
了解一个模型将如何推广到新案例的唯一方法是实际在新案例上尝试。一种方法是将你的模型投入生产并监控其表现。这种方法效果很好,但如果你的模型非常糟糕,用户会抱怨——这不是最好的主意。
更好的选择是将数据分为两组:训练集和测试集。正如这些名称所暗示的,你使用训练集训练你的模型,并使用测试集测试它。新案例的错误率称为泛化误差(或样本外误差),通过在测试集上评估你的模型,你可以得到这个误差的估计。这个值告诉你你的模型在它从未见过的实例上的表现如何。
如果训练误差很低(即,你的模型在训练集上犯了很少的错误),但泛化误差很高,这意味着你的模型正在过拟合训练数据。
提示
通常使用 80%的数据进行训练,保留20%用于测试。但是,这取决于数据集的大小:如果包含 1000 万个实例,那么保留 1%意味着你的测试集将包含 100,000 个实例,可能足够得到泛化误差的良好估计。
超参数调整和模型选择
评估一个模型很简单:只需使用一个测试集。但是假设你在两种类型的模型之间犹豫不决(比如,线性模型和多项式模型):你如何决定呢?一种选择是训练两种模型,并比较它们在测试集上的泛化效果。
现在假设线性模型泛化效果更好,但你想应用一些正则化来避免过拟合。问题是,你如何选择正则化超参数的值?一种选择是使用 100 个不同的值训练 100 个不同的模型。假设你找到了一个最佳的超参数值,可以产生泛化误差最低的模型——比如,只有 5%的误差。你将这个模型投入生产,但不幸的是它的表现并不如预期,产生了 15%的错误。发生了什么?
问题在于你在测试集上多次测量了泛化误差,并且调整了模型和超参数以产生最佳模型针对那个特定集合。这意味着该模型不太可能在新数据上表现得很好。
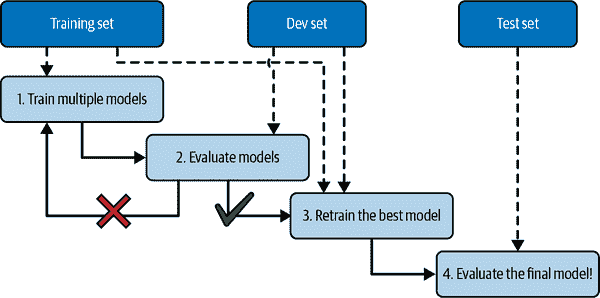
解决这个问题的常见方法称为留出验证(图 1-25):您只需留出部分训练集来评估几个候选模型并选择最佳模型。新的留出集称为验证集(或开发集,或开发集)。更具体地说,您在减少的训练集上(即完整训练集减去验证集)上训练多个具有不同超参数的模型,并选择在验证集上表现最佳的模型。在进行留出验证过程之后,您在完整训练集上(包括验证集)训练最佳模型,这将为您提供最终模型。最后,您评估这个最终模型在测试集上,以获得泛化误差的估计。
mls3 0125
图 1-25. 使用留出验证进行模型选择
这种解决方案通常效果很好。然而,如果验证集太小,则模型评估将不够精确:您可能会错误地选择次优模型。相反,如果验证集太大,则剩余的训练集将比完整训练集小得多。为什么这样不好呢?因为最终模型将在完整训练集上训练,所以将候选模型训练在一个小得多的训练集上进行比较并不理想。这就好比选择最快的短跑选手参加马拉松比赛。解决这个问题的一种方法是执行重复的交叉验证,使用许多小的验证集。每个模型在其余数据上训练后,每个验证集对其进行一次评估。通过对模型的所有评估进行平均,您将获得更准确的性能度量。然而,这种方法的一个缺点是:训练时间将乘以验证集的数量。
数据不匹配
在某些情况下,很容易获得大量用于训练的数据,但这些数据可能不会完全代表将在生产中使用的数据。例如,假设您想创建一个移动应用程序来拍摄花朵并自动确定它们的种类。您可以轻松地在网上下载数百万张花朵图片,但它们不会完全代表实际使用移动设备上应用程序拍摄的图片。也许您只有 1,000 张代表性图片(即实际使用应用程序拍摄的图片)。
在这种情况下,最重要的规则是记住验证集和测试集必须尽可能代表您预期在生产中使用的数据,因此它们应该完全由代表性图片组成:您可以对它们进行洗牌,并将一半放入验证集,一半放入测试集(确保没有重复或近似重复的图片同时出现在两个集合中)。在对网络图片训练模型后,如果您观察到模型在验证集上的表现令人失望,您将不知道这是因为您的模型已经过度拟合训练集,还是仅仅是由于网络图片和移动应用程序图片之间的不匹配。
一种解决方案是在另一个由 Andrew Ng 命名为训练-开发集的集合中保留一些训练图片(来自网络)(图 1-26)。在模型训练完成后(在训练集上,不是在训练-开发集上),您可以在训练-开发集上评估它。如果模型表现不佳,则必须过度拟合训练集,因此应尝试简化或正则化模型,获取更多训练数据,并清理训练数据。但如果模型在训练-开发集上表现良好,则可以在开发集上评估模型。如果模型在开发集上表现不佳,则问题可能来自数据不匹配。您可以尝试通过预处理网络图像使其看起来更像移动应用程序将拍摄的图片,然后重新训练模型来解决此问题。一旦您有一个在训练-开发集和开发集上表现良好的模型,您可以最后一次在测试集上评估它,以了解它在生产中的表现如何。

mls3 0126
图 1-26。当真实数据稀缺时(右侧),您可以使用类似丰富的数据(左侧)进行训练,并在训练-开发集中保留一些数据以评估过拟合;然后使用真实数据来评估数据不匹配(开发集)并评估最终模型的性能(测试集)
练习
在本章中,我们已经介绍了机器学习中一些最重要的概念。在接下来的章节中,我们将深入探讨并编写更多代码,但在此之前,请确保您能回答以下问题:
- 您如何定义机器学习?
- 您能否列出四种应用程序的类型,它们在哪些方面表现出色?
- 什么是标记训练集?
- 最常见的两种监督任务是什么?
- 您能否列出四种常见的无监督任务?
- 您会使用什么类型的算法来允许机器人在各种未知地形中行走?
- 您会使用什么类型的算法将客户分成多个群组?
- 您会将垃圾邮件检测问题框定为监督学习问题还是无监督学习问题?
- 什么是在线学习系统?
- 什么是离线学习?
- 依赖相似度度量进行预测的算法类型是什么?
- 模型参数和模型超参数之间有什么区别?
- 基于模型的算法搜索什么?它们成功的最常见策略是什么?它们如何进行预测?
- 您能否列出机器学习中的四个主要挑战?
- 如果您的模型在训练数据上表现良好,但对新实例的泛化能力差,那么发生了什么?您能否列出三种可能的解决方案?
- 什么是测试集,为什么要使用它?
- 验证集的目的是什么?
- 什么是训练-开发集,何时需要它,以及如何使用它?
- 如果使用测试集调整超参数会出现什么问题?
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 有趣的事实:这个听起来奇怪的名字是由弗朗西斯·高尔顿引入的统计术语,当时他正在研究高个子父母的孩子往往比父母矮的事实。由于孩子们较矮,他将此称为回归到平均值。然后,这个名字被应用于他用来分析变量之间相关性的方法。
² 请注意,动物与车辆相当分离,马与鹿接近但与鸟类相距甚远。图由 Richard Socher 等人允许复制,来源于“通过跨模态转移实现零样本学习”,第 26 届国际神经信息处理系统会议论文集 1(2013):935-943。
³ 这就是系统完美运行的时候。在实践中,它经常为每个人创建几个簇,并有时会混淆看起来相似的两个人,因此您可能需要为每个人提供一些标签,并手动清理一些簇。
⁴ 按照惯例,希腊字母θ(theta)经常用于表示模型参数。
⁵ 如果您还不理解所有的代码,没关系;我将在接下来的章节中介绍 Scikit-Learn。
⁶ 例如,根据上下文知道是写“to”、“two”还是“too”。
⁷ Peter Norvig 等,“数据的不合理有效性”,《IEEE 智能系统》24 卷 2 期(2009 年):8–12。
⁸ 图片经 Michele Banko 和 Eric Brill 许可重印,“用于自然语言消歧的非常大的语料库的扩展”,《计算语言学协会第 39 届年会论文集》(2001 年):26–33。
⁹ David Wolpert,“学习算法之间缺乏先验区别”,《神经计算》8 卷 7 期(1996 年):1341–1390。
第二章:端到端的机器学习项目
在本章中,您将通过一个示例项目端到端地工作,假装自己是一家房地产公司最近雇用的数据科学家。这个例子是虚构的;目标是说明机器学习项目的主要步骤,而不是了解房地产业务。以下是我们将要走过的主要步骤:
- 看大局。
- 获取数据。
- 探索和可视化数据以获得洞见。
- 为机器学习算法准备数据。
- 选择模型并训练它。
- 微调您的模型。
- 呈现解决方案。
- 启动、监控和维护您的系统。
使用真实数据
当您学习机器学习时,最好尝试使用真实世界的数据,而不是人工数据集。幸运的是,有成千上万的开放数据集可供选择,涵盖各种领域。以下是您可以查找数据的一些地方:
- 流行的开放数据存储库:
- 元门户网站(它们列出开放数据存储库):
- 其他页面列出了许多流行的开放数据存储库:
在本章中,我们将使用 StatLib 存储库中的加利福尼亚房价数据集(见图 2-1)。该数据集基于 1990 年加利福尼亚人口普查数据。虽然不是最新的(在那个时候,旧金山湾区的漂亮房子仍然是负担得起的),但它具有许多学习的优点,因此我们将假装它是最新的数据。出于教学目的,我添加了一个分类属性并删除了一些特征。
mls3 0201
图 2-1。加利福尼亚房屋价格
看大局
欢迎来到机器学习房地产公司!您的第一个任务是使用加利福尼亚人口普查数据来建立该州房价模型。这些数据包括加利福尼亚每个街区组的人口、中位收入和中位房价等指标。街区组是美国人口普查局发布样本数据的最小地理单位(一个街区组通常有 600 到 3000 人口)。我会简称它们为“区”。
您的模型应该从这些数据中学习,并能够预测任何地区的房屋中位数价格,考虑到所有其他指标。
提示
由于您是一个组织良好的数据科学家,您应该做的第一件事是拿出您的机器学习项目清单。您可以从附录 A 开始;对于大多数机器学习项目来说,这应该运行得相当顺利,但请确保根据您的需求进行调整。在本章中,我们将逐个检查许多项目,但也会跳过一些,要么是因为它们是不言自明的,要么是因为它们将在后续章节中讨论。
构建问题框架
向老板提出问题的第一个问题是业务目标究竟是什么。构建模型可能不是最终目标。公司希望如何使用和从这个模型中受益?知道目标很重要,因为它将决定您如何构建问题,选择哪些算法,使用哪种性能度量来评估您的模型,以及您将花费多少精力来调整它。
你的老板回答说,你模型的输出(一个区域的中位房价的预测)将被馈送到另一个机器学习系统(见图 2-2),以及许多其他信号。这个下游系统将确定是否值得在一个给定区域进行投资。做对这一点至关重要,因为它直接影响收入。
下一个问题要问你的老板是,当前的解决方案是什么样子的(如果有的话)。当前情况通常会给你一个性能的参考,以及解决问题的见解。你的老板回答说,目前专家们手动估计区域房价:一个团队收集关于一个区域的最新信息,当他们无法获得中位房价时,他们使用复杂的规则来估计。
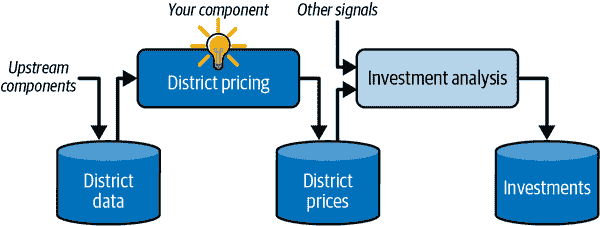
mls3 0202
图 2-2。房地产投资的机器学习流程
这是昂贵且耗时的,他们的估计并不好;在他们设法找出实际的中位房价的情况下,他们经常意识到他们的估计偏差超过 30%。这就是为什么公司认为训练一个模型来预测一个区域的中位房价,给出该区域的其他数据,将是有用的。人口普查数据看起来是一个很好的数据集,可以用来实现这个目的,因为它包括数千个区域的中位房价,以及其他数据。
有了所有这些信息,你现在可以开始设计你的系统了。首先,确定模型将需要什么样的训练监督:是监督、无监督、半监督、自监督还是强化学习任务?这是一个分类任务、回归任务还是其他任务?应该使用批量学习还是在线学习技术?在继续阅读之前,暂停一下,尝试自己回答这些问题。
你找到答案了吗?让我们看看。这显然是一个典型的监督学习任务,因为模型可以通过标记的示例进行训练(每个实例都带有预期的输出,即区域的中位房价)。这是一个典型的回归任务,因为模型将被要求预测一个值。更具体地说,这是一个多元回归问题,因为系统将使用多个特征来进行预测(区域的人口,中位收入等)。这也是一个单变量回归问题,因为我们只是尝试预测每个区域的一个单一值。如果我们试图预测每个区域的多个值,那么它将是一个多元回归问题。最后,系统中没有连续的数据流进入,没有特别需要快速调整到变化的数据,数据足够小以适应内存,因此普通的批量学习应该做得很好。
提示
如果数据很大,你可以将批量学习工作分配到多台服务器上(使用 MapReduce 技术),或者使用在线学习技术。
选择一个性能度量
你的下一步是选择一个性能度量。回归问题的一个典型性能度量是均方根误差(RMSE)。它给出了系统在预测中通常产生多少误差的概念,对大误差给予更高的权重。方程 2-1 显示了计算 RMSE 的数学公式。
方程 2-1。均方根误差(RMSE)
RMSE ( X , h ) = 1 m ∑ i=1 m h(x (i) )-y (i) 2
尽管均方根误差通常是回归任务的首选性能度量,但在某些情况下,您可能更喜欢使用另一个函数。例如,如果有许多异常值区域。在这种情况下,您可能考虑使用平均绝对误差(MAE,也称为平均绝对偏差),如方程 2-2 所示:
方程 2-2. 平均绝对误差(MAE)
MAE ( X , h ) = 1 m ∑ i=1 m h ( x (i) ) - y (i)
均方根误差(RMSE)和平均绝对误差(MAE)都是衡量两个向量之间距离的方法:预测向量和目标值向量。各种距离度量,或范数,都是可能的:
- 计算平方和的根(RMSE)对应于欧几里德范数:这是我们都熟悉的距离概念。它也被称为ℓ[2] 范数,表示为∥ · ∥[2](或只是∥ · ∥)。
- 计算绝对值之和(MAE)对应于ℓ[1] 范数,表示为∥ · ∥[1]。这有时被称为曼哈顿范数,因为它测量了在城市中两点之间的距离,如果您只能沿着正交的城市街区行驶。
- 更一般地,包含n个元素的向量v的ℓ[k] 范数被定义为∥v∥[k] = (|v[1]|^(k) + |v[2]|^(k) + … + |v[n]|(*k*))(1/k)。ℓ[0]给出向量中非零元素的数量,ℓ[∞]给出向量中的最大绝对值。
范数指数越高,就越关注大值并忽略小值。这就是为什么均方根误差(RMSE)比平均绝对误差(MAE)更容易受到异常值的影响。但是当异常值呈指数稀有性(如钟形曲线)时,均方根误差表现非常好,通常更受青睐。
检查假设
最后,列出并验证迄今为止已经做出的假设(由您或他人)是一个很好的做法;这可以帮助您及早发现严重问题。例如,您的系统输出的区域价格将被馈送到下游机器学习系统中,您假设这些价格将被如此使用。但是,如果下游系统将价格转换为类别(例如,“便宜”,“中等”或“昂贵”),然后使用这些类别而不是价格本身呢?在这种情况下,完全准确地获取价格并不重要;您的系统只需要获取正确的类别。如果是这样,那么问题应该被定义为一个分类任务,而不是一个回归任务。您不希望在为回归系统工作数月后才发现这一点。
幸运的是,在与负责下游系统的团队交谈后,您确信他们确实需要实际价格,而不仅仅是类别。太好了!您已经准备就绪,灯光是绿色的,现在可以开始编码了!
获取数据
现在是动手的时候了。毫不犹豫地拿起你的笔记本电脑,浏览代码示例。正如我在前言中提到的,本书中的所有代码示例都是开源的,可在在线作为 Jupyter 笔记本使用,这些笔记本是交互式文档,包含文本、图像和可执行代码片段(在我们的情况下是 Python)。在本书中,我假设您正在 Google Colab 上运行这些笔记本,这是一个免费服务,让您可以直接在线运行任何 Jupyter 笔记本,而无需在您的计算机上安装任何东西。如果您想使用另一个在线平台(例如 Kaggle),或者如果您想在自己的计算机上本地安装所有内容,请参阅本书 GitHub 页面上的说明。
使用 Google Colab 运行代码示例
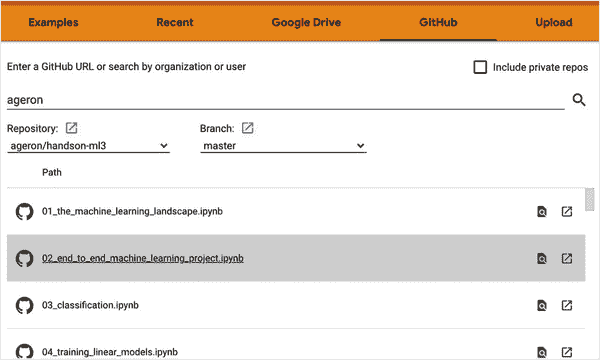
首先,打开一个网络浏览器,访问https://homl.info/colab3:这将带您到 Google Colab,并显示本书的 Jupyter 笔记本列表(参见图 2-3)。您将在每章找到一个笔记本,以及一些额外的笔记本和 NumPy、Matplotlib、Pandas、线性代数和微积分的教程。例如,如果您点击02_end_to_end_machine_learning_project.ipynb,将会在 Google Colab 中打开第二章的笔记本(参见图 2-4)。
Jupyter 笔记本由一系列单元格组成。每个单元格包含可执行代码或文本。尝试双击第一个文本单元格(其中包含句子“欢迎来到机器学习房地产公司!”)。这将打开单元格进行编辑。请注意,Jupyter 笔记本使用 Markdown 语法进行格式化(例如,**粗体**,*斜体*,# 标题,url等)。尝试修改这段文本,然后按 Shift-Enter 查看结果。
mls3 0203
图 2-3. Google Colab 中的笔记本列表
mls3 0204
图 2-4. 在 Google Colab 中的笔记本
接下来,通过选择插入→“代码单元格”菜单来创建一个新的代码单元格。或者,您可以在工具栏中点击+代码按钮,或者将鼠标悬停在单元格底部直到看到+代码和+文本出现,然后点击+代码。在新的代码单元格中,输入一些 Python 代码,例如print("Hello World"),然后按 Shift-Enter 运行此代码(或者点击单元格左侧的▷按钮)。
如果您尚未登录 Google 账户,现在将被要求登录(如果您尚未拥有 Google 账户,您需要创建一个)。一旦您登录,当您尝试运行代码时,您将看到一个安全警告,告诉您这个笔记本不是由 Google 编写的。一个恶意的人可能会创建一个试图欺骗您输入 Google 凭据的笔记本,以便访问您的个人数据,因此在运行笔记本之前,请务必确保信任其作者(或在运行之前仔细检查每个代码单元格将执行的操作)。假设您信任我(或者您计划检查每个代码单元格),现在可以点击“仍然运行”。
Colab 将为您分配一个新的运行时:这是位于 Google 服务器上的免费虚拟机,包含一堆工具和 Python 库,包括大多数章节所需的一切(在某些章节中,您需要运行一个命令来安装额外的库)。这将需要几秒钟。接下来,Colab 将自动连接到此运行时,并使用它来执行您的新代码单元格。重要的是,代码在运行时上运行,而不是在您的计算机上。代码的输出将显示在单元格下方。恭喜,您已在 Colab 上运行了一些 Python 代码!
提示
要插入新的代码单元格,您也可以键入 Ctrl-M(或 macOS 上的 Cmd-M),然后按 A(在活动单元格上方插入)或 B(在下方插入)。还有许多其他可用的键盘快捷键:您可以通过键入 Ctrl-M(或 Cmd-M)然后 H 来查看和编辑它们。如果您选择在 Kaggle 上或使用 JupyterLab 或带有 Jupyter 扩展的 IDE(如 Visual Studio Code)在自己的机器上运行笔记本,您将看到一些细微差异——运行时称为内核,用户界面和键盘快捷键略有不同等等——但从一个 Jupyter 环境切换到另一个并不太困难。
保存您的代码更改和数据
您可以对 Colab 笔记本进行更改,并且只要保持浏览器标签打开,这些更改将持续存在。但一旦关闭它,更改将丢失。为了避免这种情况,请确保通过选择文件→“在驱动器中保存副本”将笔记本保存到您的谷歌驱动器。或者,您可以通过选择文件→下载→“下载.ipynb”将笔记本下载到计算机。然后,您可以稍后访问https://colab.research.google.com并再次打开笔记本(从谷歌驱动器或通过从计算机上传)。
警告
Google Colab 仅用于交互使用:您可以在笔记本中玩耍并调整代码,但不能让笔记本在长时间内无人看管运行,否则运行时将关闭并丢失所有数据。
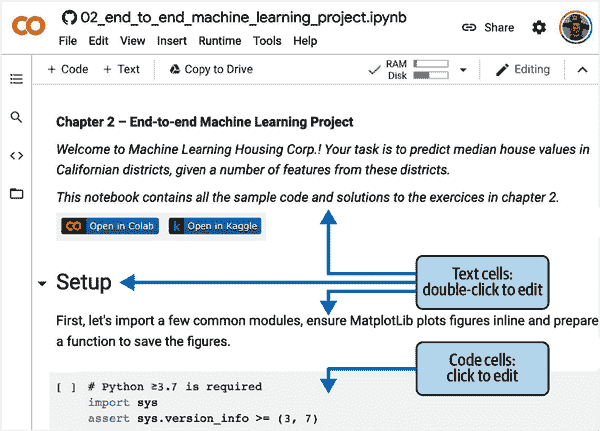
如果笔记本生成了您关心的数据,请确保在运行时关闭之前下载这些数据。要做到这一点,请点击文件图标(参见图 2-5 中的步骤 1),找到要下载的文件,点击其旁边的垂直点(步骤 2),然后点击下载(步骤 3)。或者,您可以在运行时挂载您的谷歌驱动器,使笔记本能够直接读写文件到谷歌驱动器,就像它是一个本地目录一样。为此,请点击文件图标(步骤 1),然后点击谷歌驱动器图标(在图 2-5 中用圈圈圈出)并按照屏幕上的说明操作。
mls3 0205
图 2-5。从 Google Colab 运行时下载文件(步骤 1 至 3),或挂载您的谷歌驱动器(圈圈图标)
默认情况下,您的谷歌驱动器将挂载在*/content/drive/MyDrive*。如果要备份数据文件,只需通过运行!cp /content/my_great_model /content/drive/MyDrive将其复制到此目录。任何以感叹号(!)开头的命令都被视为 shell 命令,而不是 Python 代码:cp是 Linux shell 命令,用于将文件从一个路径复制到另一个路径。请注意,Colab 运行时在 Linux 上运行(具体来说是 Ubuntu)。
交互性的力量和危险
Jupyter 笔记本是交互式的,这是一件好事:您可以逐个运行每个单元格,在任何时候停止,插入单元格,玩弄代码,返回并再次运行相同的单元格等等,我强烈鼓励您这样做。如果您只是逐个运行单元格而从不玩弄它们,您学习速度不会那么快。然而,这种灵活性是有代价的:很容易按错误的顺序运行单元格,或者忘记运行一个单元格。如果发生这种情况,后续的代码单元格很可能会失败。例如,每个笔记本中的第一个代码单元格包含设置代码(如导入),因此请确保首先运行它,否则什么都不会起作用。
提示
如果您遇到奇怪的错误,请尝试重新启动运行时(通过选择运行时→“重新启动运行时”菜单)然后再次从笔记本开头运行所有单元格。这通常可以解决问题。如果不行,很可能是您所做的更改之一破坏了笔记本:只需恢复到原始笔记本并重试。如果仍然失败,请在 GitHub 上提交问题。
书中代码与笔记本代码
您有时可能会注意到本书中的代码与笔记本中的代码之间存在一些小差异。这可能是由于以下几个原因:
- 图书馆可能在您阅读这些文字时略有变化,或者尽管我尽力了,但书中可能存在错误。遗憾的是,我不能在您的这本书中神奇地修复代码(除非您正在阅读电子副本并且可以下载最新版本),但我可以修复笔记本。因此,如果您在从本书中复制代码后遇到错误,请查找笔记本中的修复代码:我将努力保持它们没有错误,并与最新的库版本保持同步。
- 笔记本包含一些额外的代码来美化图形(添加标签,设置字体大小等)并将它们保存为高分辨率以供本书使用。如果您愿意,可以安全地忽略这些额外的代码。
我优化了代码以提高可读性和简单性:我尽可能将其线性化和扁平化,定义了很少的函数或类。目标是确保您运行的代码通常就在您眼前,而不是嵌套在几层抽象中,需要搜索。这也使您更容易玩弄代码。为简单起见,我没有进行太多的错误处理,并且将一些不常见的导入放在需要它们的地方(而不是像 PEP 8 Python 风格指南建议的那样将它们放在文件顶部)。也就是说,您的生产代码不会有太大的不同:只是更模块化,还有额外的测试和错误处理。
好了!一旦您熟悉了 Colab,您就可以下载数据了。
下载数据
在典型环境中,您的数据可能存储在关系数据库或其他常见数据存储中,并分布在多个表/文档/文件中。要访问它,您首先需要获取您的凭据和访问授权,并熟悉数据模式。然而,在这个项目中,情况要简单得多:您只需下载一个压缩文件housing.tgz,其中包含一个名为housing.csv的逗号分隔值(CSV)文件,其中包含所有数据。
与手动下载和解压数据相比,通常最好编写一个函数来执行此操作。特别是如果数据经常更改,这将非常有用:您可以编写一个小脚本,使用该函数获取最新数据(或者您可以设置定期自动执行此操作的计划任务)。自动获取数据的过程也很有用,如果您需要在多台机器上安装数据集。
这是用于获取和加载数据的函数:
from pathlib import Path
import pandas as pd
import tarfile
import urllib.request
def load_housing_data():
tarball_path = Path("datasets/housing.tgz")
if not tarball_path.is_file():
Path("datasets").mkdir(parents=True, exist_ok=True)
url = "https://github.com/ageron/data/raw/main/housing.tgz"
urllib.request.urlretrieve(url, tarball_path)
with tarfile.open(tarball_path) as housing_tarball:
housing_tarball.extractall(path="datasets")
return pd.read_csv(Path("datasets/housing/housing.csv"))
housing = load_housing_data()当调用load_housing_data()时,它会查找datasets/housing.tgz文件。如果找不到该文件,它会在当前目录内创建datasets目录(默认为*/content*,在 Colab 中),从ageron/data GitHub 存储库下载housing.tgz文件,并将其内容提取到datasets目录中;这将创建datasets/housing目录,并在其中包含housing.csv文件。最后,该函数将此 CSV 文件加载到一个包含所有数据的 Pandas DataFrame 对象中,并返回它。
快速查看数据结构
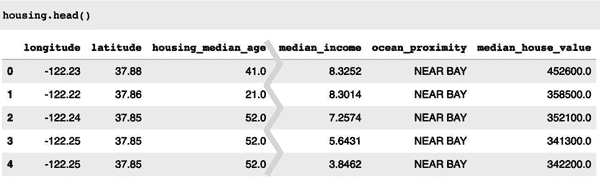
您可以通过使用 DataFrame 的head()方法来查看数据的前五行(请参见图 2-6)。
mls3 0206
图 2-6。数据集中的前五行
每一行代表一个地区。有 10 个属性(并非所有属性都显示在屏幕截图中):longitude、latitude、housing_median_age、total_rooms、total_bedrooms、population、households、median_income、median_house_value和ocean_proximity。
info()方法对于快速获取数据的简要描述非常有用,特别是总行数、每个属性的类型和非空值的数量:
>>> housing.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB注意
在本书中,当代码示例包含代码和输出混合时,就像这里一样,它的格式类似于 Python 解释器,以便更好地阅读:代码行以>>>(或缩进块的情况下为...)为前缀,输出没有前缀。
数据集中有 20,640 个实例,这意味着按照机器学习的标准来说,它相当小,但是非常适合入门。您会注意到total_bedrooms属性只有 20,433 个非空值,这意味着有 207 个地区缺少这个特征。您需要稍后处理这个问题。
所有属性都是数字的,除了ocean_proximity。它的类型是object,因此它可以保存任何类型的 Python 对象。但是由于您从 CSV 文件中加载了这些数据,您知道它必须是一个文本属性。当您查看前五行时,您可能会注意到ocean_proximity列中的值是重复的,这意味着它可能是一个分类属性。您可以使用value_counts()方法找出存在哪些类别以及每个类别包含多少个地区:
>>> housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64让我们看看其他字段。describe()方法显示了数字属性的摘要(图 2-7)。
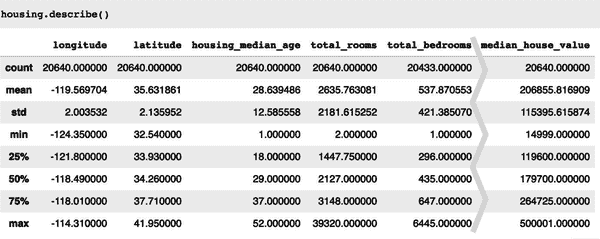
mls3 0207
图 2-7。每个数字属性的总结
count、mean、min和max行是不言自明的。请注意,空值被忽略了(因此,例如,total_bedrooms的count是 20,433,而不是 20,640)。std行显示了标准差,它衡量了值的分散程度。⁵ 25%、50%和75%行显示了相应的百分位数:百分位数表示给定百分比的观察值中有多少落在一组观察值之下。例如,25%的地区的housing_median_age低于 18,而 50%低于 29,75%低于 37。这些通常被称为第 25 百分位数(或第一个四分位数)、中位数和第 75 百分位数(或第三四分位数)。
另一种快速了解您正在处理的数据类型的方法是为每个数字属性绘制直方图。直方图显示了具有给定值范围的实例数量(在水平轴上)(在垂直轴上)。您可以一次绘制一个属性,也可以在整个数据集上调用hist()方法(如下面的代码示例所示),它将为每个数字属性绘制一个直方图(参见图 2-8):
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(12, 8))
plt.show()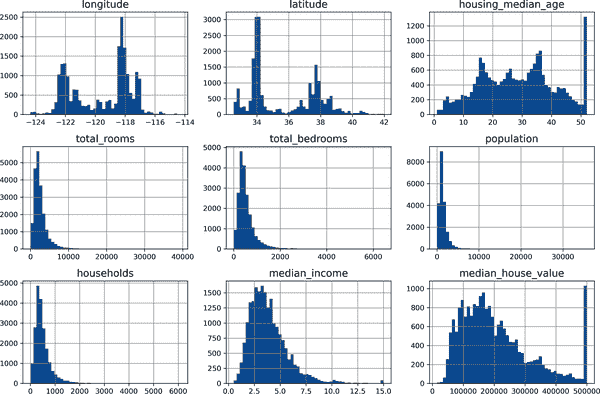
mls3 0208
图 2-8。每个数字属性的直方图
查看这些直方图,您会注意到一些事情:
- 首先,中位收入属性看起来不像是以美元(USD)表示的。在与收集数据的团队核实后,他们告诉您数据已经被缩放,并且对于更高的中位收入,已经被限制在 15(实际上是 15.0001),对于更低的中位收入,已经被限制在 0.5(实际上是 0.4999)。这些数字大致表示数万美元(例如,3 实际上表示约 30,000 美元)。在机器学习中使用预处理的属性是很常见的,这并不一定是问题,但您应该尝试了解数据是如何计算的。
- 房屋中位年龄和房屋中位价值也被限制了。后者可能是一个严重的问题,因为它是您的目标属性(您的标签)。您的机器学习算法可能会学习到价格永远不会超过那个限制。您需要与客户团队(将使用您系统输出的团队)核实,看看这是否是一个问题。如果他们告诉您他们需要精确的预测,甚至超过 50 万美元,那么您有两个选择:
- 收集那些标签被限制的地区的正确标签。
- 从训练集中删除这些地区(也从测试集中删除,因为如果您的系统预测超过 50 万美元的值,它不应该被评估不良)。
- 这些属性具有非常不同的比例。当我们探索特征缩放时,我们将在本章后面讨论这一点。
- 最后,许多直方图是右偏的:它们在中位数的右侧延伸得更远,而不是左侧。这可能会使一些机器学习算法更难检测到模式。稍后,您将尝试转换这些属性,使其具有更对称和钟形分布。
现在您应该对您正在处理的数据有更好的了解。
警告
等等!在进一步查看数据之前,您需要创建一个测试集,将其放在一边,永远不要查看它。
创建一个测试集
在这个阶段自愿设置一部分数据似乎有点奇怪。毕竟,您只是快速浏览了数据,而在决定使用什么算法之前,您肯定应该更多地了解它,对吧?这是真的,但您的大脑是一个惊人的模式检测系统,这也意味着它很容易过拟合:如果您查看测试集,您可能会在测试数据中发现一些看似有趣的模式,导致您选择特定类型的机器学习模型。当您使用测试集估计泛化误差时,您的估计将过于乐观,您将启动一个性能不如预期的系统。这被称为数据窥探偏差。
创建测试集在理论上很简单;随机选择一些实例,通常是数据集的 20%(如果您的数据集非常大,则可以更少),并将它们放在一边:
import numpy as np
def shuffle_and_split_data(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]然后,您可以像这样使用这个函数:
>>> train_set, test_set = shuffle_and_split_data(housing, 0.2)
>>> len(train_set)
16512
>>> len(test_set)
4128好吧,这样做是有效的,但并不完美:如果再次运行程序,它将生成不同的测试集!随着时间的推移,您(或您的机器学习算法)将看到整个数据集,这是您要避免的。
一种解决方案是在第一次运行时保存测试集,然后在后续运行中加载它。另一个选项是在调用np.random.permutation()之前设置随机数生成器的种子(例如,使用np.random.seed(42))^([6](ch02.html#idm45720239285936)),以便它始终生成相同的洗牌索引。
然而,这两种解决方案在获取更新的数据集后会失效。为了在更新数据集后仍然保持稳定的训练/测试分割,一个常见的解决方案是使用每个实例的标识符来决定是否应该放入测试集中(假设实例具有唯一且不可变的标识符)。例如,您可以计算每个实例标识符的哈希值,并且如果哈希值低于或等于最大哈希值的 20%,则将该实例放入测试集中。这确保了测试集将在多次运行中保持一致,即使您刷新数据集。新的测试集将包含新实例的 20%,但不会包含以前在训练集中的任何实例。
这是一个可能的实现:
from zlib import crc32
def is_id_in_test_set(identifier, test_ratio):
return crc32(np.int64(identifier)) < test_ratio * 2**32
def split_data_with_id_hash(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: is_id_in_test_set(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]不幸的是,住房数据集没有标识符列。最简单的解决方案是使用行索引作为 ID:
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_data_with_id_hash(housing_with_id, 0.2, "index")如果使用行索引作为唯一标识符,您需要确保新数据附加到数据集的末尾,并且永远不会删除任何行。如果这不可能,那么您可以尝试使用最稳定的特征来构建唯一标识符。例如,一个地区的纬度和经度保证在几百万年内保持稳定,因此您可以将它们组合成一个 ID,如下所示:^([7](ch02.html#idm45720242437568))
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_data_with_id_hash(housing_with_id, 0.2, "id")Scikit-Learn 提供了一些函数,以各种方式将数据集拆分为多个子集。最简单的函数是train_test_split(),它基本上与我们之前定义的shuffle_and_split_data()函数做的事情差不多,但有一些额外的功能。首先,有一个random_state参数,允许您设置随机生成器种子。其次,您可以传递多个具有相同行数的数据集,并且它将在相同的索引上拆分它们(例如,如果您有一个单独的标签 DataFrame,这是非常有用的):
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)到目前为止,我们已经考虑了纯随机抽样方法。如果您的数据集足够大(尤其是相对于属性数量),这通常是可以接受的,但如果不是,您就有可能引入显著的抽样偏差。当调查公司的员工决定打电话给 1,000 人询问一些问题时,他们不会仅仅在电话簿中随机挑选 1,000 人。他们会努力确保这 1,000 人在问题上代表整个人口。例如,美国人口中 51.1%是女性,48.9%是男性,因此在美国进行良好的调查将尝试保持这个比例在样本中:511 名女性和 489 名男性(至少如果可能的话,答案可能会因性别而有所不同)。这被称为分层抽样:人口被划分为称为层的同质子群,从每个层中抽取正确数量的实例以确保测试集代表整体人口。如果进行调查的人员使用纯随机抽样,那么抽取一个偏斜的测试集,女性参与者少于 48.5%或多于 53.5%的概率约为 10.7%。无论哪种方式,调查结果可能会相当偏倚。
假设您与一些专家交谈过,他们告诉您,中位收入是预测中位房价的一个非常重要的属性。您可能希望确保测试集代表整个数据集中各种收入类别。由于中位收入是一个连续的数值属性,您首先需要创建一个收入类别属性。让我们更仔细地看一下中位收入直方图(回到图 2-8):大多数中位收入值聚集在 1.5 到 6 之间(即 15,000 美元至 60,000 美元),但有些中位收入远远超过 6。对于每个层,您的数据集中应该有足够数量的实例,否则对层重要性的估计可能会有偏差。这意味着您不应该有太多层,并且每个层应该足够大。以下代码使用pd.cut()函数创建一个具有五个类别(从 1 到 5 标记)的收入类别属性;类别 1 范围从 0 到 1.5(即 15,000 美元以下),类别 2 从 1.5 到 3,依此类推:
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])这些收入类别在图 2-9 中表示:
housing["income_cat"].value_counts().sort_index().plot.bar(rot=0, grid=True)
plt.xlabel("Income category")
plt.ylabel("Number of districts")
plt.show()现在您可以根据收入类别进行分层抽样。Scikit-Learn 在sklearn.model_selection包中提供了许多拆分器类,实现了各种策略来将数据集拆分为训练集和测试集。每个拆分器都有一个split()方法,返回相同数据的不同训练/测试拆分的迭代器。
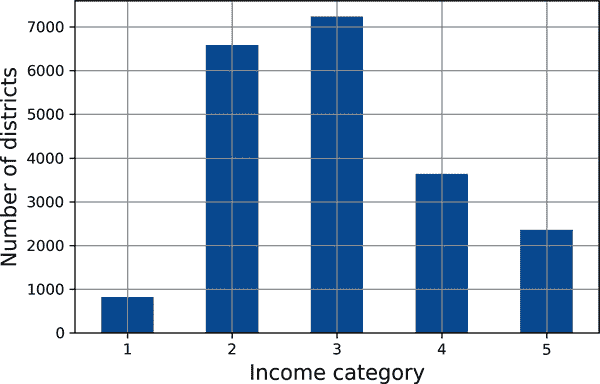
mls3 0209
图 2-9。收入类别直方图
要准确,split()方法产生训练和测试索引,而不是数据本身。如果您想更好地估计模型的性能,拥有多个拆分可能是有用的,这将在本章后面讨论交叉验证时看到。例如,以下代码生成了同一数据集的 10 个不同的分层拆分:
from sklearn.model_selection import StratifiedShuffleSplit
splitter = StratifiedShuffleSplit(n_splits=10, test_size=0.2, random_state=42)
strat_splits = []
for train_index, test_index in splitter.split(housing, housing["income_cat"]):
strat_train_set_n = housing.iloc[train_index]
strat_test_set_n = housing.iloc[test_index]
strat_splits.append([strat_train_set_n, strat_test_set_n])现在,您可以使用第一个拆分:
strat_train_set, strat_test_set = strat_splits[0]或者,由于分层抽样相当常见,可以使用train_test_split()函数的stratify参数来更快地获得单个拆分:
strat_train_set, strat_test_set = train_test_split(
housing, test_size=0.2, stratify=housing["income_cat"], random_state=42)让我们看看这是否按预期工作。您可以从测试集中查看收入类别的比例:
>>> strat_test_set["income_cat"].value_counts() / len(strat_test_set)
3 0.350533
2 0.318798
4 0.176357
5 0.114341
1 0.039971
Name: income_cat, dtype: float64使用类似的代码,您可以测量完整数据集中的收入类别比例。图 2-10 比较了整体数据集中的收入类别比例,使用分层抽样生成的测试集以及使用纯随机抽样生成的测试集。如您所见,使用分层抽样生成的测试集的收入类别比例几乎与完整数据集中的相同,而使用纯随机抽样生成的测试集则有所偏差。
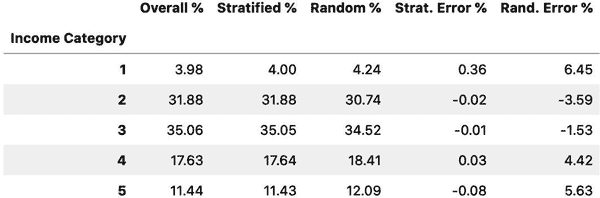
mls3 0210
图 2-10。分层与纯随机抽样的抽样偏差比较
您不会再使用income_cat列,因此可以将其删除,将数据恢复到原始状态:
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)我们花了相当多的时间在测试集生成上,这是一个经常被忽视但至关重要的机器学习项目的关键部分。此外,当我们讨论交叉验证时,许多这些想法将在以后派上用场。现在是时候进入下一个阶段了:探索数据。
探索和可视化数据以获得洞见
到目前为止,您只是快速浏览了数据,以对您正在处理的数据类型有一个大致了解。现在的目标是深入一点。
首先,请确保您已经将测试集放在一边,只探索训练集。此外,如果训练集非常庞大,您可能希望对探索集进行抽样,以便在探索阶段进行操作更加轻松和快速。在这种情况下,训练集相当小,因此您可以直接在完整集上工作。由于您将尝试对完整训练集进行各种转换,因此应该先复制原始数据,以便之后可以恢复到原始状态:
housing = strat_train_set.copy()可视化地理数据
由于数据集包含地理信息(纬度和经度),因此创建一个散点图来可视化所有地区是一个好主意(图 2-11):
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True)
plt.show()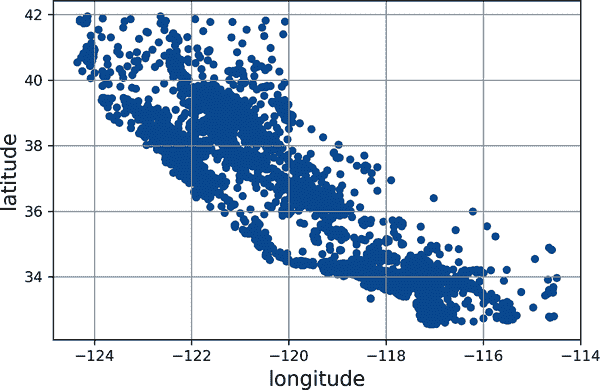
mls3 0211
图 2-11。数据的地理散点图
这看起来确实像加利福尼亚,但除此之外很难看出任何特定的模式。将alpha选项设置为0.2可以更容易地可视化数据点密度较高的地方(图 2-12):
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True, alpha=0.2)
plt.show()现在好多了:您可以清楚地看到高密度区域,即旧金山湾区、洛杉矶周围和圣迭戈周围,以及中央谷地(特别是萨克拉门托和弗雷斯诺周围)的一长串相当高密度区域。
我们的大脑非常擅长发现图片中的模式,但您可能需要调整可视化参数来突出这些模式。
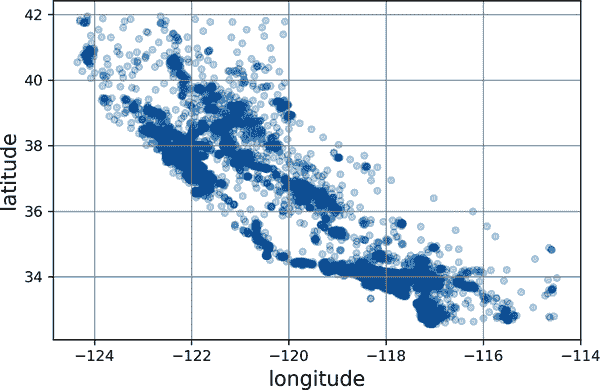
mls3 0212
图 2-12。一个更好的可视化,突出显示高密度区域
接下来,您将查看房屋价格(图 2-13)。每个圆的半径代表地区的人口(选项s),颜色代表价格(选项c)。在这里,您使用了一个预定义的颜色映射(选项cmap)称为jet,从蓝色(低值)到红色(高价格):⁸
housing.plot(kind="scatter", x="longitude", y="latitude", grid=True,
s=housing["population"] / 100, label="population",
c="median_house_value", cmap="jet", colorbar=True,
legend=True, sharex=False, figsize=(10, 7))
plt.show()这幅图告诉你,房价与位置(例如靠近海洋)和人口密度密切相关,这可能是你已经知道的。聚类算法应该对检测主要集群和添加衡量到集群中心距离的新特征很有用。海洋接近度属性也可能有用,尽管在加利福尼亚北部,沿海地区的房价并不太高,所以这并不是一个简单的规则。
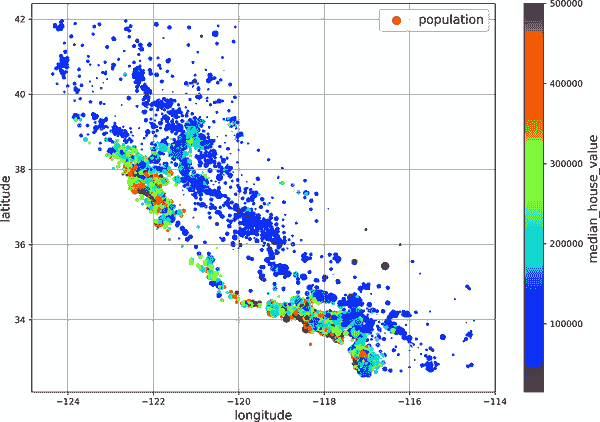
mls3 0213
图 2-13. 加利福尼亚房价:红色是昂贵的,蓝色是便宜的,较大的圆圈表示人口较多的地区
寻找相关性
由于数据集不太大,你可以使用corr()方法轻松计算每对属性之间的标准相关系数(也称为皮尔逊相关系数):
corr_matrix = housing.corr()现在你可以看看每个属性与房屋中位价值的相关程度:
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.688380
total_rooms 0.137455
housing_median_age 0.102175
households 0.071426
total_bedrooms 0.054635
population -0.020153
longitude -0.050859
latitude -0.139584
Name: median_house_value, dtype: float64相关系数的范围是-1 到 1。当它接近 1 时,意味着有很强的正相关性;例如,当中位收入上升时,中位房价往往会上涨。当系数接近-1 时,意味着有很强的负相关性;你可以看到纬度和中位房价之间存在微弱的负相关性(即,当你向北走时,价格略有下降的趋势)。最后,接近 0 的系数意味着没有线性相关性。
检查属性之间的相关性的另一种方法是使用 Pandas 的scatter_matrix()函数,它将每个数值属性与其他每个数值属性绘制在一起。由于现在有 11 个数值属性,你将得到 11² = 121 个图,这些图无法放在一页上,所以你决定专注于一些看起来与房屋中位价值最相关的有希望的属性(图 2-14):
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))
plt.show()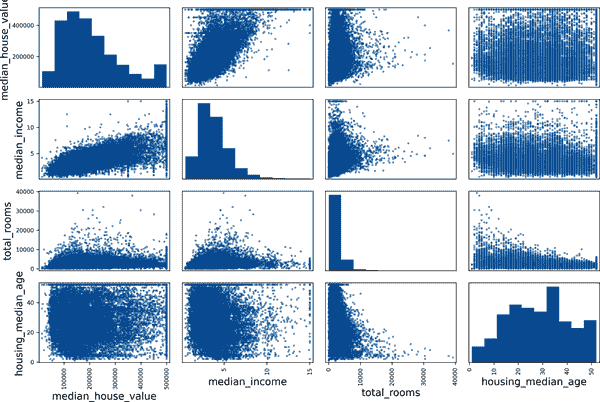
mls3 0214
图 2-14. 这个散点矩阵将每个数值属性与其他每个数值属性绘制在一起,主对角线上是每个数值属性值的直方图(从左上到右下)
如果 Pandas 将每个变量与自身绘制在一起,主对角线将充满直线,这将没有太大用处。因此,Pandas 显示了每个属性的直方图(还有其他选项可用;请参阅 Pandas 文档以获取更多详细信息)。
看着相关性散点图,似乎最有希望预测房屋中位价值的属性是中位收入,所以你放大了它们的散点图(图 2-15):
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1, grid=True)
plt.show()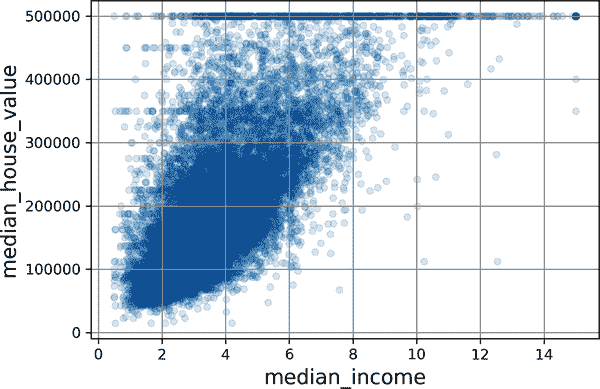
mls3 0215
图 2-15. 中位收入与中位房价
这个图揭示了一些事情。首先,相关性确实非常强;你可以清楚地看到上升趋势,点的分散程度也不大。其次,你之前注意到的价格上限在500,000 处清晰可见。但这个图还显示了其他不太明显的直线:一个在450,000 左右的水平线,另一个在350,000 左右,也许还有一个在280,000 左右,以及一些更低的线。你可能想尝试删除相应的地区,以防止你的算法学习复制这些数据怪癖。
警告
相关系数只能测量线性相关性(“随着x的增加,y通常上升/下降”)。它可能完全忽略非线性关系(例如,“随着x接近 0,y通常上升”)。图 2-16 展示了各种数据集以及它们的相关系数。请注意,尽管底部行的所有图都具有相关系数为 0,但它们的坐标轴显然不是独立的:这些是非线性关系的示例。此外,第二行显示了相关系数等于 1 或-1 的示例;请注意,这与斜率无关。例如,您的身高以英寸为单位与以英尺或纳米为单位的身高的相关系数为 1。
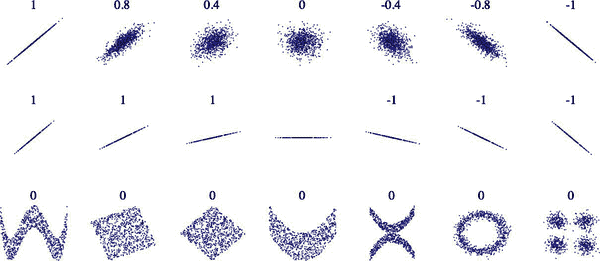
mls3 0216
图 2-16. 各种数据集的标准相关系数(来源:维基百科;公共领域图像)
尝试属性组合
希望前面的部分给您提供了一些探索数据和获得见解的方法。您发现了一些可能需要在将数据馈送到机器学习算法之前清理的数据怪癖,并且找到了属性之间的有趣相关性,特别是与目标属性相关的。您还注意到一些属性具有右偏分布,因此您可能希望对其进行转换(例如,通过计算其对数或平方根)。当然,每个项目的情况会有很大不同,但总体思路是相似的。
在准备数据用于机器学习算法之前,您可能希望尝试各种属性组合。例如,一个地区的总房间数如果不知道有多少户,就不是很有用。您真正想要的是每户的房间数。同样,单独的卧室总数并不是很有用:您可能想要将其与房间数进行比较。每户人口也似乎是一个有趣的属性组合。您可以按照以下方式创建这些新属性:
housing["rooms_per_house"] = housing["total_rooms"] / housing["households"]
housing["bedrooms_ratio"] = housing["total_bedrooms"] / housing["total_rooms"]
housing["people_per_house"] = housing["population"] / housing["households"]然后再次查看相关矩阵:
>>> corr_matrix = housing.corr()
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.688380
rooms_per_house 0.143663
total_rooms 0.137455
housing_median_age 0.102175
households 0.071426
total_bedrooms 0.054635
population -0.020153
people_per_house -0.038224
longitude -0.050859
latitude -0.139584
bedrooms_ratio -0.256397
Name: median_house_value, dtype: float64嘿,不错!新的bedrooms_ratio属性与房屋中位数的相关性要比总房间数或卧室总数高得多。显然,卧室/房间比例较低的房屋往往更昂贵。每户房间数也比一个地区的总房间数更具信息量——显然,房屋越大,价格越高。
这一轮探索不必绝对彻底;重点是要以正确的方式开始,并迅速获得有助于获得第一个相当不错原型的见解。但这是一个迭代过程:一旦您建立起一个原型并使其运行起来,您可以分析其输出以获得更多见解,并回到这一探索步骤。
为机器学习算法准备数据
现在是为您的机器学习算法准备数据的时候了。您应该为此目的编写函数,而不是手动操作,有几个很好的理由:
- 这将使您能够轻松在任何数据集上重现这些转换(例如,下次获取新数据集时)。
- 您将逐渐构建一个转换函数库,可以在将来的项目中重复使用。
- 您可以在实时系统中使用这些函数,在将新数据馈送到算法之前对其进行转换。
- 这将使您能够轻松尝试各种转换,并查看哪种转换组合效果最好。
但首先,恢复到一个干净的训练集(再次复制strat_train_set)。您还应该分开预测变量和标签,因为您不一定希望对预测变量和目标值应用相同的转换(请注意,drop()会创建数据的副本,不会影响strat_train_set):
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()清理数据
大多数机器学习算法无法处理缺失特征,因此您需要处理这些问题。例如,您之前注意到total_bedrooms属性有一些缺失值。您有三种选项来解决这个问题:
- 摆脱相应的地区。
- 摆脱整个属性。
- 将缺失值设置为某个值(零、均值、中位数等)。这称为填充。
使用 Pandas DataFrame 的dropna()、drop()和fillna()方法可以轻松实现这些功能:
housing.dropna(subset=["total_bedrooms"], inplace=True) # option 1
housing.drop("total_bedrooms", axis=1) # option 2
median = housing["total_bedrooms"].median() # option 3
housing["total_bedrooms"].fillna(median, inplace=True)您决定选择第 3 个选项,因为它是最不破坏性的,但是不使用前面的代码,而是使用一个方便的 Scikit-Learn 类:SimpleImputer。好处是它将存储每个特征的中位数值:这将使得不仅可以在训练集上填补缺失值,还可以在验证集、测试集和任何输入到模型的新数据上填补缺失值。要使用它,首先需要创建一个SimpleImputer实例,指定您要用该属性的中位数替换每个属性的缺失值:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")由于中位数只能计算在数值属性上,因此您需要创建一个仅包含数值属性的数据副本(这将排除文本属性ocean_proximity):
housing_num = housing.select_dtypes(include=[np.number])现在,您可以使用fit()方法将imputer实例拟合到训练数据中:
imputer.fit(housing_num)imputer只是计算了每个属性的中位数,并将结果存储在其statistics_实例变量中。只有total_bedrooms属性有缺失值,但是您不能确定系统上线后新数据中是否会有缺失值,因此最好将imputer应用于所有数值属性:
>>> imputer.statistics_
array([-118.51 , 34.26 , 29\. , 2125\. , 434\. , 1167\. , 408\. , 3.5385])
>>> housing_num.median().values
array([-118.51 , 34.26 , 29\. , 2125\. , 434\. , 1167\. , 408\. , 3.5385])现在,您可以使用这个“训练好的”imputer来转换训练集,用学习到的中位数替换缺失值:
X = imputer.transform(housing_num)缺失值也可以用均值(strategy="mean")、最频繁值(strategy="most_frequent")或常数值(strategy="constant", fill_value=…)替换。最后两种策略支持非数值数据。
提示
sklearn.impute包中还有更强大的填充器(仅适用于数值特征):
-
KNNImputer用该特征的k个最近邻值的均值替换每个缺失值。距离基于所有可用的特征。 -
IterativeImputer为每个特征训练一个回归模型,以预测基于所有其他可用特征的缺失值。然后,它再次在更新后的数据上训练模型,并在每次迭代中重复这个过程,改进模型和替换值。
Scikit-Learn 转换器输出 NumPy 数组(有时候也输出 SciPy 稀疏矩阵),即使它们以 Pandas DataFrame 作为输入。因此,imputer.transform(housing_num)的输出是一个 NumPy 数组:X既没有列名也没有索引。幸运的是,将X包装在 DataFrame 中并从housing_num中恢复列名和索引并不太困难:
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing_num.index)处理文本和分类属性
到目前为止,我们只处理了数值属性,但是您的数据可能还包含文本属性。在这个数据集中,只有一个:ocean_proximity属性。让我们看一下前几个实例的值:
>>> housing_cat = housing[["ocean_proximity"]]
>>> housing_cat.head(8)
ocean_proximity
13096 NEAR BAY
14973 <1H OCEAN
3785 INLAND
14689 INLAND
20507 NEAR OCEAN
1286 INLAND
18078 <1H OCEAN
4396 NEAR BAY这不是任意的文本:可能的值有限,每个值代表一个类别。因此,这个属性是一个分类属性。大多数机器学习算法更喜欢使用数字,所以让我们将这些类别从文本转换为数字。为此,我们可以使用 Scikit-Learn 的OrdinalEncoder类:
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)这是housing_cat_encoded中前几个编码值的样子:
>>> housing_cat_encoded[:8]
array([[3.],
[0.],
[1.],
[1.],
[4.],
[1.],
[0.],
[3.]])您可以使用categories_实例变量获取类别列表。它是一个包含每个分类属性的类别的 1D 数组的列表(在这种情况下,由于只有一个分类属性,因此包含一个单一数组的列表):
>>> ordinal_encoder.categories_
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]这种表示的一个问题是,机器学习算法会假设两个相邻的值比两个远离的值更相似。在某些情况下这可能没问题(例如,对于有序类别如“bad”、“average”、“good”和“excellent”),但显然不适用于ocean_proximity列(例如,类别 0 和 4 明显比类别 0 和 1 更相似)。为了解决这个问题,一个常见的解决方案是为每个类别创建一个二进制属性:当类别是"<1H OCEAN"时一个属性等于 1(否则为 0),当类别是"INLAND"时另一个属性等于 1(否则为 0),依此类推。这被称为独热编码,因为只有一个属性将等于 1(热),而其他属性将等于 0(冷)。新属性有时被称为虚拟属性。Scikit-Learn 提供了一个OneHotEncoder类来将分类值转换为独热向量:
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)默认情况下,OneHotEncoder的输出是 SciPy 的稀疏矩阵,而不是 NumPy 数组:
>>> housing_cat_1hot
<16512x5 sparse matrix of type '<class 'numpy.float64'>'
with 16512 stored elements in Compressed Sparse Row format>稀疏矩阵是包含大部分零的矩阵的非常高效的表示。实际上,它内部只存储非零值及其位置。当一个分类属性有数百或数千个类别时,对其进行独热编码会导致一个非常大的矩阵,除了每行一个单独的 1 之外,其他都是 0。在这种情况下,稀疏矩阵正是你需要的:它将节省大量内存并加快计算速度。你可以像使用普通的 2D 数组一样使用稀疏矩阵,但如果你想将其转换为(密集的)NumPy 数组,只需调用toarray()方法:
>>> housing_cat_1hot.toarray()
array([[0., 0., 0., 1., 0.],
[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
...,
[0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.]])或者,当创建OneHotEncoder时设置sparse=False,在这种情况下,transform()方法将直接返回一个常规(密集的)NumPy 数组。
与OrdinalEncoder一样,你可以使用编码器的categories_实例变量获取类别列表:
>>> cat_encoder.categories_
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]Pandas 有一个名为get_dummies()的函数,它也将每个分类特征转换为一种独热表示,每个类别一个二进制特征:
>>> df_test = pd.DataFrame({"ocean_proximity": ["INLAND", "NEAR BAY"]})
>>> pd.get_dummies(df_test)
ocean_proximity_INLAND ocean_proximity_NEAR BAY
0 1 0
1 0 1看起来很简单漂亮,那为什么不使用它而不是OneHotEncoder呢?嗯,OneHotEncoder的优势在于它记住了它训练过的类别。这非常重要,因为一旦你的模型投入生产,它应该被喂入与训练期间完全相同的特征:不多,也不少。看看我们训练过的cat_encoder在我们让它转换相同的df_test时输出了什么(使用transform(),而不是fit_transform()):
>>> cat_encoder.transform(df_test)
array([[0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0.]])看到区别了吗?get_dummies()只看到了两个类别,所以输出了两列,而OneHotEncoder按正确顺序输出了每个学习类别的一列。此外,如果你给get_dummies()一个包含未知类别(例如"<2H OCEAN")的 DataFrame,它会高兴地为其生成一列:
>>> df_test_unknown = pd.DataFrame({"ocean_proximity": ["<2H OCEAN", "ISLAND"]})
>>> pd.get_dummies(df_test_unknown)
ocean_proximity_<2H OCEAN ocean_proximity_ISLAND
0 1 0
1 0 1但是OneHotEncoder更聪明:它会检测到未知类别并引发异常。如果你愿意,你可以将handle_unknown超参数设置为"ignore",在这种情况下,它将只用零表示未知类别:
>>> cat_encoder.handle_unknown = "ignore"
>>> cat_encoder.transform(df_test_unknown)
array([[0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.]])提示
如果一个分类属性有大量可能的类别(例如,国家代码,职业,物种),那么独热编码将导致大量的输入特征。这可能会减慢训练速度并降低性能。如果发生这种情况,您可能希望用与类别相关的有用的数值特征替换分类输入:例如,您可以用到海洋的距离替换ocean_proximity特征(类似地,国家代码可以用国家的人口和人均 GDP 替换)。或者,您可以使用category_encoders包在GitHub上提供的编码器之一。或者,在处理神经网络时,您可以用一个可学习的低维向量替换每个类别,称为嵌入。这是表示学习的一个例子(有关更多详细信息,请参见第十三章和第十七章)。
当您使用 DataFrame 拟合任何 Scikit-Learn 估计器时,估计器会将列名存储在feature_names_in_属性中。然后,Scikit-Learn 确保在此之后将任何 DataFrame 提供给该估计器(例如,用于transform()或predict())具有相同的列名。转换器还提供了一个get_feature_names_out()方法,您可以使用它来构建围绕转换器输出的 DataFrame:
>>> cat_encoder.feature_names_in_
array(['ocean_proximity'], dtype=object)
>>> cat_encoder.get_feature_names_out()
array(['ocean_proximity_<1H OCEAN', 'ocean_proximity_INLAND',
'ocean_proximity_ISLAND', 'ocean_proximity_NEAR BAY',
'ocean_proximity_NEAR OCEAN'], dtype=object)
>>> df_output = pd.DataFrame(cat_encoder.transform(df_test_unknown),
... columns=cat_encoder.get_feature_names_out(),
... index=df_test_unknown.index)
...特征缩放和转换
您需要对数据应用的最重要的转换之一是特征缩放。除了少数例外,当输入的数值属性具有非常不同的比例时,机器学习算法的表现不佳。这适用于房屋数据:房间总数的范围大约从 6 到 39,320,而中位收入的范围仅从 0 到 15。如果没有进行任何缩放,大多数模型将倾向于忽略中位收入,更多地关注房间数量。
有两种常见的方法可以使所有属性具有相同的比例:最小-最大缩放和标准化。
警告
与所有估计器一样,将缩放器仅适配于训练数据非常重要:永远不要对除训练集以外的任何内容使用fit()或fit_transform()。一旦您有了一个经过训练的缩放器,您就可以使用它来transform()任何其他集合,包括验证集,测试集和新数据。请注意,虽然训练集的值将始终缩放到指定的范围内,但如果新数据包含异常值,则这些值可能会缩放到范围之外。如果要避免这种情况,只需将clip超参数设置为True。
最小-最大缩放(许多人称之为归一化)是最简单的:对于每个属性,值被移动和重新缩放,以便最终范围为 0 到 1。这是通过减去最小值并除以最小值和最大值之间的差异来执行的。Scikit-Learn 提供了一个名为MinMaxScaler的转换器。它有一个feature_range超参数,让您更改范围,如果出于某种原因,您不想要 0-1(例如,神经网络最适合具有零均值输入,因此-1 到 1 的范围更可取)。使用起来非常简单:
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)标准化是不同的:首先它减去均值(因此标准化值具有零均值),然后将结果除以标准差(因此标准化值的标准差等于 1)。与最小-最大缩放不同,标准化不限制值到特定范围。然而,标准化受异常值的影响要小得多。例如,假设一个地区的中位收入等于 100(错误),而不是通常的 0-15。将最小-最大缩放到 0-1 范围会将这个异常值映射到 1,并将所有其他值压缩到 0-0.15,而标准化不会受到太大影响。Scikit-Learn 提供了一个名为StandardScaler的标准化器:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)提示
如果要对稀疏矩阵进行缩放而不先将其转换为密集矩阵,可以使用StandardScaler,并将其with_mean超参数设置为False:它只会通过标准差除以数据,而不会减去均值(因为这样会破坏稀疏性)。
当一个特征的分布具有重尾(即远离均值的值并不呈指数稀有)时,最小-最大缩放和标准化会将大多数值压缩到一个小范围内。机器学习模型通常不喜欢这种情况,正如您将在第四章中看到的那样。因此,在对特征进行缩放之前,您应该首先对其进行转换以缩小重尾,并尽可能使分布大致对称。例如,对于具有右侧重尾的正特征,常见的做法是用其平方根替换特征(或将特征提升到 0 到 1 之间的幂)。如果特征具有非常长且重尾的分布,例如幂律分布,那么用其对数替换特征可能有所帮助。例如,population特征大致遵循幂律:拥有 1 万居民的地区只比拥有 1,000 居民的地区少 10 倍,而不是指数级别少。图 2-17 显示了当计算其对数时,这个特征看起来更好多少:它非常接近高斯分布(即钟形)。
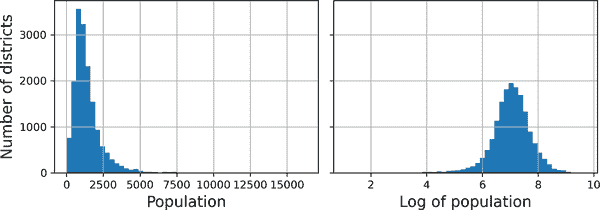
mls3 0217
图 2-17。将特征转换为更接近高斯分布
处理重尾特征的另一种方法是将特征分桶。这意味着将其分布分成大致相等大小的桶,并用桶的索引替换每个特征值,就像我们创建income_cat特征时所做的那样(尽管我们只用它进行分层抽样)。例如,您可以用百分位数替换每个值。使用等大小的桶进行分桶会产生一个几乎均匀分布的特征,因此不需要进一步缩放,或者您可以只除以桶的数量以将值强制为 0-1 范围。
当一个特征具有多峰分布(即有两个或更多明显峰值,称为模式)时,例如housing_median_age特征,将其分桶也可能有所帮助,但这次将桶 ID 视为类别而不是数值值。这意味着桶索引必须进行编码,例如使用OneHotEncoder(因此通常不希望使用太多桶)。这种方法将使回归模型更容易学习不同范围的特征值的不同规则。例如,也许大约 35 年前建造的房屋有一种不合时宜的风格,因此它们比其年龄单独表明的要便宜。
将多模态分布转换的另一种方法是为每个模式(至少是主要的模式)添加一个特征,表示房屋年龄中位数与该特定模式之间的相似性。相似性度量通常使用径向基函数(RBF)计算 - 任何仅取决于输入值与固定点之间距离的函数。最常用的 RBF 是高斯 RBF,其输出值随着输入值远离固定点而指数衰减。例如,房龄x与 35 之间的高斯 RBF 相似性由方程 exp(–γ(x – 35)²)给出。超参数γ(gamma)确定随着x远离 35,相似性度量衰减的速度。使用 Scikit-Learn 的rbf_kernel()函数,您可以创建一个新的高斯 RBF 特征,衡量房屋年龄中位数与 35 之间的相似性:
from sklearn.metrics.pairwise import rbf_kernel
age_simil_35 = rbf_kernel(housing[["housing_median_age"]], [[35]], gamma=0.1)图 2-18 显示了这个新特征作为房屋年龄中位数的函数(实线)。它还显示了如果使用较小的gamma值,该特征会是什么样子。正如图表所示,新的年龄相似性特征在 35 岁时达到峰值,正好在房屋年龄中位数分布的峰值附近:如果这个特定年龄组与较低价格有很好的相关性,那么这个新特征很可能会有所帮助。
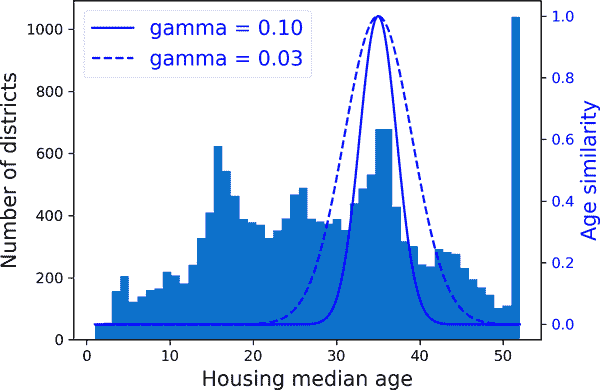
mls3 0218
图 2-18. 高斯 RBF 特征,衡量房屋年龄中位数与 35 之间的相似性
到目前为止,我们只看了输入特征,但目标值可能也需要转换。例如,如果目标分布具有重尾,您可能选择用其对数替换目标。但是,如果这样做,回归模型现在将预测中位数房价的对数,而不是中位数房价本身。如果您希望预测的中位数房价,您需要计算模型预测的指数。
幸运的是,大多数 Scikit-Learn 的转换器都有一个inverse_transform()方法,使得计算其转换的逆变换变得容易。例如,以下代码示例显示如何使用StandardScaler缩放标签(就像我们为输入做的那样),然后在生成的缩放标签上训练一个简单的线性回归模型,并使用它对一些新数据进行预测,然后使用训练好的缩放器的inverse_transform()方法将其转换回原始比例。请注意,我们将标签从 Pandas Series 转换为 DataFrame,因为StandardScaler需要 2D 输入。此外,在此示例中,我们只对单个原始输入特征(中位收入)进行了模型训练,以简化问题:
from sklearn.linear_model import LinearRegression
target_scaler = StandardScaler()
scaled_labels = target_scaler.fit_transform(housing_labels.to_frame())
model = LinearRegression()
model.fit(housing[["median_income"]], scaled_labels)
some_new_data = housing[["median_income"]].iloc[:5] # pretend this is new data
scaled_predictions = model.predict(some_new_data)
predictions = target_scaler.inverse_transform(scaled_predictions)这样做效果很好,但更简单的选择是使用TransformedTargetRegressor。我们只需要构建它,给定回归模型和标签转换器,然后在训练集上拟合它,使用原始未缩放的标签。它将自动使用转换器来缩放标签,并在生成的缩放标签上训练回归模型,就像我们之前做的那样。然后,当我们想要进行预测时,它将调用回归模型的predict()方法,并使用缩放器的inverse_transform()方法来生成预测:
from sklearn.compose import TransformedTargetRegressor
model = TransformedTargetRegressor(LinearRegression(),
transformer=StandardScaler())
model.fit(housing[["median_income"]], housing_labels)
predictions = model.predict(some_new_data)自定义转换器
尽管 Scikit-Learn 提供了许多有用的转换器,但对于自定义转换、清理操作或组合特定属性等任务,您可能需要编写自己的转换器。
对于不需要任何训练的转换,您可以编写一个函数,该函数以 NumPy 数组作为输入,并输出转换后的数组。例如,如前一节所讨论的,通常最好通过用其对数替换具有重尾分布的特征(假设特征为正且尾部在右侧)来转换特征。让我们创建一个对数转换器,并将其应用于population特征:
from sklearn.preprocessing import FunctionTransformer
log_transformer = FunctionTransformer(np.log, inverse_func=np.exp)
log_pop = log_transformer.transform(housing[["population"]])inverse_func参数是可选的。它允许您指定一个逆转换函数,例如,如果您计划在TransformedTargetRegressor中使用您的转换器。
您的转换函数可以将超参数作为额外参数。例如,以下是如何创建一个与之前相同的高斯 RBF 相似性度量的转换器:
rbf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[[35.]], gamma=0.1))
age_simil_35 = rbf_transformer.transform(housing[["housing_median_age"]])请注意,RBF 核函数没有逆函数,因为在固定点的给定距离处始终存在两个值(除了距离为 0 的情况)。还要注意,rbf_kernel()不会单独处理特征。如果您传递一个具有两个特征的数组,它将测量 2D 距离(欧几里得距离)以衡量相似性。例如,以下是如何添加一个特征,用于衡量每个地区与旧金山之间的地理相似性:
sf_coords = 37.7749, -122.41
sf_transformer = FunctionTransformer(rbf_kernel,
kw_args=dict(Y=[sf_coords], gamma=0.1))
sf_simil = sf_transformer.transform(housing[["latitude", "longitude"]])自定义转换器也可用于组合特征。例如,这里有一个FunctionTransformer,计算输入特征 0 和 1 之间的比率:
>>> ratio_transformer = FunctionTransformer(lambda X: X[:, [0]] / X[:, [1]])
>>> ratio_transformer.transform(np.array([[1., 2.], [3., 4.]]))
array([[0.5 ],
[0.75]])FunctionTransformer非常方便,但如果您希望您的转换器是可训练的,在fit()方法中学习一些参数,并在transform()方法中稍后使用它们,该怎么办?为此,您需要编写一个自定义类。Scikit-Learn 依赖于鸭子类型,因此这个类不必继承自任何特定的基类。它只需要三个方法:fit()(必须返回self)、transform()和fit_transform()。
只需将TransformerMixin作为基类添加进去,就可以免费获得fit_transform():默认实现只会调用fit(),然后调用transform()。如果将BaseEstimator作为基类(并且避免在构造函数中使用*args和**kwargs),还会获得两个额外的方法:get_params()和set_params()。这些对于自动超参数调整会很有用。
例如,这里有一个自定义的转换器,它的功能类似于StandardScaler:
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.utils.validation import check_array, check_is_fitted
class StandardScalerClone(BaseEstimator, TransformerMixin):
def __init__(self, with_mean=True): # no *args or **kwargs!
self.with_mean = with_mean
def fit(self, X, y=None): # y is required even though we don't use it
X = check_array(X) # checks that X is an array with finite float values
self.mean_ = X.mean(axis=0)
self.scale_ = X.std(axis=0)
self.n_features_in_ = X.shape[1] # every estimator stores this in fit()
return self # always return self!
def transform(self, X):
check_is_fitted(self) # looks for learned attributes (with trailing _)
X = check_array(X)
assert self.n_features_in_ == X.shape[1]
if self.with_mean:
X = X - self.mean_
return X / self.scale_以下是一些需要注意的事项:
-
sklearn.utils.validation包含了几个我们可以用来验证输入的函数。为简单起见,我们将在本书的其余部分跳过这些测试,但生产代码应该包含它们。 - Scikit-Learn 管道要求
fit()方法有两个参数X和y,这就是为什么我们需要y=None参数,即使我们不使用y。 - 所有 Scikit-Learn 估计器在
fit()方法中设置n_features_in_,并确保传递给transform()或predict()的数据具有这个特征数量。 -
fit()方法必须返回self。 - 这个实现并不完全:所有的估计器在传入 DataFrame 时应该在
fit()方法中设置feature_names_in_。此外,所有的转换器应该提供一个get_feature_names_out()方法,以及一个inverse_transform()方法,当它们的转换可以被逆转时。更多细节请参考本章末尾的最后一个练习。
一个自定义转换器可以(并经常)在其实现中使用其他估计器。例如,以下代码演示了一个自定义转换器,在fit()方法中使用KMeans聚类器来识别训练数据中的主要聚类,然后在transform()方法中使用rbf_kernel()来衡量每个样本与每个聚类中心的相似程度:
from sklearn.cluster import KMeans
class ClusterSimilarity(BaseEstimator, TransformerMixin):
def __init__(self, n_clusters=10, gamma=1.0, random_state=None):
self.n_clusters = n_clusters
self.gamma = gamma
self.random_state = random_state
def fit(self, X, y=None, sample_weight=None):
self.kmeans_ = KMeans(self.n_clusters, random_state=self.random_state)
self.kmeans_.fit(X, sample_weight=sample_weight)
return self # always return self!
def transform(self, X):
return rbf_kernel(X, self.kmeans_.cluster_centers_, gamma=self.gamma)
def get_feature_names_out(self, names=None):
return [f"Cluster {i} similarity" for i in range(self.n_clusters)]提示
您可以通过将一个实例传递给sklearn.utils.estimator_checks包中的check_estimator()来检查您的自定义估计器是否符合 Scikit-Learn 的 API。有关完整的 API,请查看https://scikit-learn.org/stable/developers。
正如您将在第九章中看到的,k-means 是一种在数据中定位聚类的算法。它搜索的聚类数量由n_clusters超参数控制。训练后,聚类中心可以通过cluster_centers_属性获得。KMeans的fit()方法支持一个可选参数sample_weight,让用户指定样本的相对权重。k-means 是一种随机算法,意味着它依赖于随机性来定位聚类,因此如果您想要可重现的结果,必须设置random_state参数。正如您所看到的,尽管任务复杂,代码还是相当简单的。现在让我们使用这个自定义转换器:
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
similarities = cluster_simil.fit_transform(housing[["latitude", "longitude"]],
sample_weight=housing_labels)这段代码创建了一个ClusterSimilarity转换器,将聚类数设置为 10。然后它使用训练集中每个区域的纬度和经度调用fit_transform(),通过每个区域的中位房价加权。转换器使用k-means 来定位聚类,然后测量每个区域与所有 10 个聚类中心之间的高斯 RBF 相似性。结果是一个矩阵,每个区域一行,每个聚类一列。让我们看一下前三行,四舍五入到两位小数:
>>> similarities[:3].round(2)
array([[0\. , 0.14, 0\. , 0\. , 0\. , 0.08, 0\. , 0.99, 0\. , 0.6 ],
[0.63, 0\. , 0.99, 0\. , 0\. , 0\. , 0.04, 0\. , 0.11, 0\. ],
[0\. , 0.29, 0\. , 0\. , 0.01, 0.44, 0\. , 0.7 , 0\. , 0.3 ]])图 2-19 显示了k-means 找到的 10 个聚类中心。根据它们与最近聚类中心的地理相似性,地区被着色。如您所见,大多数聚类位于人口稠密和昂贵的地区。
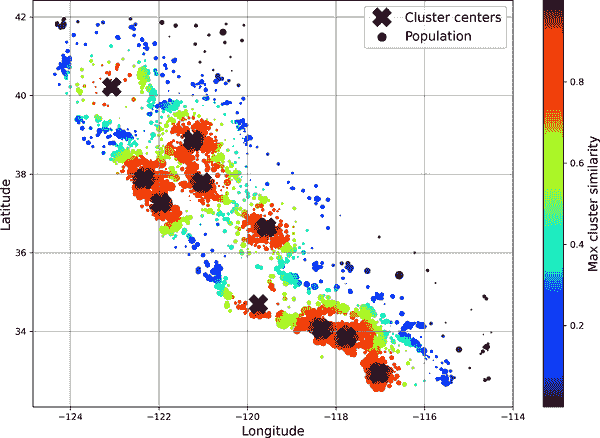
mls3 0219
图 2-19. 高斯 RBF 相似度到最近的聚类中心
转换管道
如您所见,有许多数据转换步骤需要按正确顺序执行。幸运的是,Scikit-Learn 提供了Pipeline类来帮助处理这样的转换序列。这是一个用于数值属性的小管道,它将首先填充然后缩放输入特征:
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
("impute", SimpleImputer(strategy="median")),
("standardize", StandardScaler()),
])Pipeline构造函数接受一系列步骤定义的名称/估计器对(2 元组)列表。名称可以是任何您喜欢的内容,只要它们是唯一的且不包含双下划线(__)。稍后在我们讨论超参数调整时,它们将很有用。所有估计器必须是转换器(即,它们必须具有fit_transform()方法),除了最后一个,它可以是任何东西:一个转换器,一个预测器或任何其他类型的估计器。
提示
在 Jupyter 笔记本中,如果import sklearn并运行sklearn.set_config(display="diagram"),则所有 Scikit-Learn 估计器都将呈现为交互式图表。这对于可视化管道特别有用。要可视化num_pipeline,请在最后一行中运行一个包含num_pipeline的单元格。单击估计器将显示更多详细信息。
如果您不想为转换器命名,可以使用make_pipeline()函数;它将转换器作为位置参数,并使用转换器类的名称创建一个Pipeline,名称为小写且没有下划线(例如,"simpleimputer"):
from sklearn.pipeline import make_pipeline
num_pipeline = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())如果多个转换器具有相同的名称,将在它们的名称后附加索引(例如,"foo-1","foo-2"等)。
当您调用管道的fit()方法时,它会按顺序在所有转换器上调用fit_transform(),将每次调用的输出作为下一次调用的参数,直到达到最终的估计器,对于最终的估计器,它只调用fit()方法。
管道公开与最终估计器相同的方法。在这个例子中,最后一个估计器是StandardScaler,它是一个转换器,因此管道也像一个转换器。如果调用管道的transform()方法,它将顺序应用所有转换到数据。如果最后一个估计器是预测器而不是转换器,则管道将具有predict()方法而不是transform()方法。调用它将顺序应用所有转换到数据,并将结果传递给预测器的predict()方法。
让我们调用管道的fit_transform()方法,并查看输出的前两行,保留两位小数:
>>> housing_num_prepared = num_pipeline.fit_transform(housing_num)
>>> housing_num_prepared[:2].round(2)
array([[-1.42, 1.01, 1.86, 0.31, 1.37, 0.14, 1.39, -0.94],
[ 0.6 , -0.7 , 0.91, -0.31, -0.44, -0.69, -0.37, 1.17]])如您之前所见,如果要恢复一个漂亮的 DataFrame,可以使用管道的get_feature_names_out()方法:
df_housing_num_prepared = pd.DataFrame(
housing_num_prepared, columns=num_pipeline.get_feature_names_out(),
index=housing_num.index)管道支持索引;例如,pipeline[1]返回管道中的第二个估计器,pipeline[:-1]返回一个包含除最后一个估计器之外的所有估计器的Pipeline对象。您还可以通过steps属性访问估计器,该属性是名称/估计器对的列表,或者通过named_steps字典属性访问估计器,该属性将名称映射到估计器。例如,num_pipeline["simpleimputer"]返回名为"simpleimputer"的估计器。
到目前为止,我们已经分别处理了分类列和数值列。有一个单一的转换器可以处理所有列,对每一列应用适当的转换会更方便。为此,您可以使用ColumnTransformer。例如,以下ColumnTransformer将num_pipeline(我们刚刚定义的)应用于数值属性,将cat_pipeline应用于分类属性:
from sklearn.compose import ColumnTransformer
num_attribs = ["longitude", "latitude", "housing_median_age", "total_rooms",
"total_bedrooms", "population", "households", "median_income"]
cat_attribs = ["ocean_proximity"]
cat_pipeline = make_pipeline(
SimpleImputer(strategy="most_frequent"),
OneHotEncoder(handle_unknown="ignore"))
preprocessing = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs),
])首先我们导入 ColumnTransformer 类,然后定义数值和分类列名的列表,并为分类属性构建一个简单的管道。最后,我们构建一个 ColumnTransformer。它的构造函数需要一个三元组(3 元组)的列表,每个三元组包含一个名称(必须是唯一的,不包含双下划线)、一个转换器和一个应用转换器的列名(或索引)列表。
提示
如果你想要删除列,可以指定字符串 "drop",如果你想要保留列不变,可以指定 "passthrough"。默认情况下,剩余的列(即未列出的列)将被删除,但是如果你想要这些列被处理方式不同,可以将 remainder 超参数设置为任何转换器(或 "passthrough")。
由于列名的列举并不是很方便,Scikit-Learn 提供了一个 make_column_selector() 函数,返回一个选择器函数,你可以用它自动选择给定类型的所有特征,比如数值或分类。你可以将这个选择器函数传递给 ColumnTransformer,而不是列名或索引。此外,如果你不关心命名转换器,你可以使用 make_column_transformer(),它会为你选择名称,就像 make_pipeline() 一样。例如,以下代码创建了与之前相同的 ColumnTransformer,只是转换器自动命名为 "pipeline-1" 和 "pipeline-2",而不是 "num" 和 "cat":
from sklearn.compose import make_column_selector, make_column_transformer
preprocessing = make_column_transformer(
(num_pipeline, make_column_selector(dtype_include=np.number)),
(cat_pipeline, make_column_selector(dtype_include=object)),
)现在我们准备将这个 ColumnTransformer 应用到房屋数据中:
housing_prepared = preprocessing.fit_transform(housing)太棒了!我们有一个预处理管道,它接受整个训练数据集,并将每个转换器应用于适当的列,然后水平连接转换后的列(转换器绝不能改变行数)。再次返回一个 NumPy 数组,但你可以使用 preprocessing.get_feature_names_out() 获取列名,并像之前一样将数据包装在一个漂亮的 DataFrame 中。
注意
OneHotEncoder 返回一个稀疏矩阵,而 num_pipeline 返回一个密集矩阵。当存在稀疏和密集矩阵混合时,ColumnTransformer 会估计最终矩阵的密度(即非零单元格的比例),如果密度低于给定阈值(默认为 sparse_threshold=0.3),则返回稀疏矩阵。在这个例子中,返回一个密集矩阵。
你的项目进展得很顺利,你几乎可以开始训练一些模型了!现在你想创建一个单一的管道,执行到目前为止你已经尝试过的所有转换。让我们回顾一下管道将做什么以及为什么:
- 数值特征中的缺失值将被中位数替换,因为大多数 ML 算法不希望有缺失值。在分类特征中,缺失值将被最频繁的类别替换。
- 分类特征将被独热编码,因为大多数 ML 算法只接受数值输入。
- 将计算并添加一些比率特征:
bedrooms_ratio、rooms_per_house和people_per_house。希望这些特征与房屋价值中位数更好地相关,并帮助 ML 模型。 - 还将添加一些集群相似性特征。这些特征可能对模型比纬度和经度更有用。
- 具有长尾的特征将被其对数替换,因为大多数模型更喜欢具有大致均匀或高斯分布的特征。
- 所有数值特征将被标准化,因为大多数 ML 算法更喜欢所有特征具有大致相同的尺度。
构建执行所有这些操作的管道的代码现在应该对你来说很熟悉:
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ["ratio"] # feature names out
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler())
log_pipeline = make_pipeline(
SimpleImputer(strategy="median"),
FunctionTransformer(np.log, feature_names_out="one-to-one"),
StandardScaler())
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1., random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy="median"),
StandardScaler())
preprocessing = ColumnTransformer([
("bedrooms", ratio_pipeline(), ["total_bedrooms", "total_rooms"]),
("rooms_per_house", ratio_pipeline(), ["total_rooms", "households"]),
("people_per_house", ratio_pipeline(), ["population", "households"]),
("log", log_pipeline, ["total_bedrooms", "total_rooms", "population",
"households", "median_income"]),
("geo", cluster_simil, ["latitude", "longitude"]),
("cat", cat_pipeline, make_column_selector(dtype_include=object)),
],
remainder=default_num_pipeline) # one column remaining: housing_median_age如果你运行这个 ColumnTransformer,它将执行所有转换并输出一个具有 24 个特征的 NumPy 数组:
>>> housing_prepared = preprocessing.fit_transform(housing)
>>> housing_prepared.shape
(16512, 24)
>>> preprocessing.get_feature_names_out()
array(['bedrooms__ratio', 'rooms_per_house__ratio',
'people_per_house__ratio', 'log__total_bedrooms',
'log__total_rooms', 'log__population', 'log__households',
'log__median_income', 'geo__Cluster 0 similarity', [...],
'geo__Cluster 9 similarity', 'cat__ocean_proximity_<1H OCEAN',
'cat__ocean_proximity_INLAND', 'cat__ocean_proximity_ISLAND',
'cat__ocean_proximity_NEAR BAY', 'cat__ocean_proximity_NEAR OCEAN',
'remainder__housing_median_age'], dtype=object)选择并训练模型
终于!你确定了问题,获取了数据并对其进行了探索,对训练集和测试集进行了抽样,并编写了一个预处理管道来自动清理和准备数据以供机器学习算法使用。现在你准备好选择和训练一个机器学习模型了。
在训练集上训练和评估
好消息是,由于之前的所有步骤,现在事情将变得容易!你决定训练一个非常基本的线性回归模型来开始:
from sklearn.linear_model import LinearRegression
lin_reg = make_pipeline(preprocessing, LinearRegression())
lin_reg.fit(housing, housing_labels)完成了!你现在有一个可用的线性回归模型。你可以在训练集上尝试一下,查看前五个预测值,并将其与标签进行比较:
>>> housing_predictions = lin_reg.predict(housing)
>>> housing_predictions[:5].round(-2) # -2 = rounded to the nearest hundred
array([243700., 372400., 128800., 94400., 328300.])
>>> housing_labels.iloc[:5].values
array([458300., 483800., 101700., 96100., 361800.])好吧,它起作用了,但并不总是:第一个预测结果相差太远(超过 20 万美元!),而其他预测结果更好:两个相差约 25%,两个相差不到 10%。记住你选择使用 RMSE 作为性能指标,所以你想使用 Scikit-Learn 的mean_squared_error()函数在整个训练集上测量这个回归模型的 RMSE,将squared参数设置为False:
>>> from sklearn.metrics import mean_squared_error
>>> lin_rmse = mean_squared_error(housing_labels, housing_predictions,
... squared=False)
...
>>> lin_rmse
68687.89176589991这比没有好,但显然不是一个很好的分数:大多数地区的median_housing_values在 12 万美元到 26.5 万美元之间,因此典型的预测误差 68,628 美元确实令人不满意。这是一个模型欠拟合训练数据的例子。当这种情况发生时,可能意味着特征提供的信息不足以做出良好的预测,或者模型不够强大。正如我们在前一章中看到的,修复欠拟合的主要方法是选择更强大的模型,用更好的特征来训练算法,或者减少模型的约束。这个模型没有正则化,这排除了最后一个选项。你可以尝试添加更多特征,但首先你想尝试一个更复杂的模型看看它的表现如何。
你决定尝试一个DecisionTreeRegressor,因为这是一个相当强大的模型,能够在数据中找到复杂的非线性关系(决策树在第六章中有更详细的介绍):
from sklearn.tree import DecisionTreeRegressor
tree_reg = make_pipeline(preprocessing, DecisionTreeRegressor(random_state=42))
tree_reg.fit(housing, housing_labels)现在模型已经训练好了,你可以在训练集上评估它:
>>> housing_predictions = tree_reg.predict(housing)
>>> tree_rmse = mean_squared_error(housing_labels, housing_predictions,
... squared=False)
...
>>> tree_rmse
0.0等等,什么!?一点错误都没有?这个模型真的完全完美吗?当然,更有可能的是模型严重过拟合了数据。你怎么确定?正如你之前看到的,你不想在准备启动一个你有信心的模型之前触摸测试集,所以你需要使用部分训练集进行训练和部分进行模型验证。
使用交叉验证进行更好的评估
评估决策树模型的一种方法是使用train_test_split()函数将训练集分成一个较小的训练集和一个验证集,然后针对较小的训练集训练模型,并针对验证集评估模型。这需要一些努力,但并不太困难,而且效果还不错。
一个很好的选择是使用 Scikit-Learn 的k_-fold 交叉验证功能。以下代码将训练集随机分成 10 个不重叠的子集,称为folds,然后对决策树模型进行 10 次训练和评估,每次选择一个不同的 fold 进行评估,并使用其他 9 个 folds 进行训练。结果是一个包含 10 个评估分数的数组:
from sklearn.model_selection import cross_val_score
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)警告
Scikit-Learn 的交叉验证功能期望一个效用函数(值越大越好)而不是成本函数(值越小越好),因此评分函数实际上与 RMSE 相反。它是一个负值,因此您需要改变输出的符号以获得 RMSE 分数。
让我们看看结果:
>>> pd.Series(tree_rmses).describe()
count 10.000000
mean 66868.027288
std 2060.966425
min 63649.536493
25% 65338.078316
50% 66801.953094
75% 68229.934454
max 70094.778246
dtype: float64现在决策树看起来不像之前那么好。事实上,它似乎表现几乎和线性回归模型一样糟糕!请注意,交叉验证允许您不仅获得模型性能的估计,还可以获得这个估计的精确度(即其标准偏差)。决策树的 RMSE 约为 66,868,标准偏差约为 2,061。如果您只使用一个验证集,您将无法获得这些信息。但是交叉验证的代价是多次训练模型,因此并非总是可行。
如果您对线性回归模型计算相同的度量,您会发现均值 RMSE 为 69,858,标准偏差为 4,182。因此,决策树模型似乎比线性模型表现稍微好一些,但由于严重过拟合,差异很小。我们知道存在过拟合问题,因为训练误差很低(实际上为零),而验证误差很高。
现在让我们尝试最后一个模型:RandomForestRegressor。正如你将在第七章中看到的,随机森林通过在特征的随机子集上训练许多决策树,然后平均它们的预测来工作。这种由许多其他模型组成的模型被称为集成:它们能够提升底层模型的性能(在本例中是决策树)。代码与之前基本相同:
from sklearn.ensemble import RandomForestRegressor
forest_reg = make_pipeline(preprocessing,
RandomForestRegressor(random_state=42))
forest_rmses = -cross_val_score(forest_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)让我们看一下分数:
>>> pd.Series(forest_rmses).describe()
count 10.000000
mean 47019.561281
std 1033.957120
min 45458.112527
25% 46464.031184
50% 46967.596354
75% 47325.694987
max 49243.765795
dtype: float64哇,这好多了:随机森林看起来对这个任务非常有前途!然而,如果你训练一个RandomForest并在训练集上测量 RMSE,你会发现大约为 17,474:这个值要低得多,这意味着仍然存在相当多的过拟合。可能的解决方案是简化模型,约束它(即对其进行正则化),或者获得更多的训练数据。然而,在深入研究随机森林之前,你应该尝试许多其他来自各种机器学习算法类别的模型(例如,几个具有不同核的支持向量机,可能还有一个神经网络),而不要花费太多时间调整超参数。目标是列出几个(两到五个)有前途的模型。
调整模型
假设您现在有了几个有前途的模型的候选名单。现在您需要对它们进行微调。让我们看看您可以这样做的几种方法。
网格搜索
一种选择是手动调整超参数,直到找到一组很好的超参数值的组合。这将是非常繁琐的工作,你可能没有时间去探索很多组合。
相反,您可以使用 Scikit-Learn 的GridSearchCV类来为您搜索。您只需要告诉它您想要尝试哪些超参数以及要尝试的值,它将使用交叉验证来评估所有可能的超参数值组合。例如,以下代码搜索RandomForestRegressor的最佳超参数值组合:
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([
("preprocessing", preprocessing),
("random_forest", RandomForestRegressor(random_state=42)),
])
param_grid = [
{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]},
]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3,
scoring='neg_root_mean_squared_error')
grid_search.fit(housing, housing_labels)请注意,您可以引用管道中任何估计器的任何超参数,即使这个估计器深度嵌套在多个管道和列转换器中。例如,当 Scikit-Learn 看到"preprocessing__geo__n_clusters"时,它会在双下划线处拆分这个字符串,然后在管道中查找名为"preprocessing"的估计器,并找到预处理ColumnTransformer。接下来,它在这个ColumnTransformer中查找名为"geo"的转换器,并找到我们在纬度和经度属性上使用的ClusterSimilarity转换器。然后找到这个转换器的n_clusters超参数。类似地,random_forest__max_features指的是名为"random_forest"的估计器的max_features超参数,这当然是RandomForest模型(max_features超参数将在第七章中解释)。
提示
将预处理步骤包装在 Scikit-Learn 管道中允许您调整预处理超参数以及模型超参数。这是一个好事,因为它们经常互动。例如,也许增加n_clusters需要增加max_features。如果适合管道转换器计算成本很高,您可以将管道的memory超参数设置为缓存目录的路径:当您首次适合管道时,Scikit-Learn 将保存适合的转换器到此目录。然后,如果您再次使用相同的超参数适合管道,Scikit-Learn 将只加载缓存的转换器。
在这个param_grid中有两个字典,所以GridSearchCV将首先评估第一个dict中指定的n_clusters和max_features超参数值的所有 3×3=9 个组合,然后它将尝试第二个dict中超参数值的所有 2×3=6 个组合。因此,总共网格搜索将探索 9+6=15 个超参数值的组合,并且它将对每个组合进行 3 次管道训练,因为我们使用 3 折交叉验证。这意味着将有总共 15×3=45 轮训练!可能需要一段时间,但完成后,您可以像这样获得最佳参数组合:
>>> grid_search.best_params_
{'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 6}在这个示例中,通过将n_clusters设置为 15 并将max_features设置为 8 获得了最佳模型。
提示
由于 15 是为n_clusters评估的最大值,您可能应该尝试使用更高的值进行搜索;分数可能会继续提高。
您可以使用grid_search.best_estimator_访问最佳估计器。如果GridSearchCV初始化为refit=True(这是默认值),那么一旦它使用交叉验证找到最佳估计器,它将在整个训练集上重新训练。这通常是一个好主意,因为提供更多数据可能会提高其性能。
评估分数可使用grid_search.cv_results_获得。这是一个字典,但如果将其包装在 DataFrame 中,您将获得所有测试分数的一个很好的列表,每个超参数组合和每个交叉验证拆分的平均测试分数:
>>> cv_res = pd.DataFrame(grid_search.cv_results_)
>>> cv_res.sort_values(by="mean_test_score", ascending=False, inplace=True)
>>> [...] # change column names to fit on this page, and show rmse = -score
>>> cv_res.head() # note: the 1st column is the row ID
n_clusters max_features split0 split1 split2 mean_test_rmse
12 15 6 43460 43919 44748 44042
13 15 8 44132 44075 45010 44406
14 15 10 44374 44286 45316 44659
7 10 6 44683 44655 45657 44999
9 10 6 44683 44655 45657 44999最佳模型的平均测试 RMSE 分数为 44,042,比使用默认超参数值(47,019)获得的分数更好。恭喜,您已成功微调了最佳模型!
随机搜索
当您探索相对较少的组合时,像在先前的示例中一样,网格搜索方法是可以接受的,但是RandomizedSearchCV通常更可取,特别是当超参数搜索空间很大时。这个类可以像GridSearchCV类一样使用,但是它不是尝试所有可能的组合,而是评估固定数量的组合,在每次迭代中为每个超参数选择一个随机值。这可能听起来令人惊讶,但这种方法有几个好处:
- 如果您的一些超参数是连续的(或离散的但具有许多可能的值),并且让随机搜索运行,比如说,1,000 次迭代,那么它将探索每个超参数的 1,000 个不同值,而网格搜索只会探索您为每个超参数列出的少量值。
- 假设一个超参数实际上并没有太大的差异,但您还不知道。如果它有 10 个可能的值,并且您将其添加到网格搜索中,那么训练将需要更长时间。但如果将其添加到随机搜索中,将不会有任何区别。
- 如果有 6 个要探索的超参数,每个超参数有 10 个可能的值,那么网格搜索除了训练模型一百万次之外别无选择,而随机搜索可以根据您选择的任意迭代次数运行。
对于每个超参数,您必须提供可能值的列表或概率分布:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters': randint(low=3, high=50),
'random_forest__max_features': randint(low=2, high=20)}
rnd_search = RandomizedSearchCV(
full_pipeline, param_distributions=param_distribs, n_iter=10, cv=3,
scoring='neg_root_mean_squared_error', random_state=42)
rnd_search.fit(housing, housing_labels)Scikit-Learn 还有HalvingRandomSearchCV和HalvingGridSearchCV超参数搜索类。它们的目标是更有效地利用计算资源,要么训练更快,要么探索更大的超参数空间。它们的工作原理如下:在第一轮中,使用网格方法或随机方法生成许多超参数组合(称为“候选”)。然后使用这些候选来训练模型,并像往常一样使用交叉验证进行评估。然而,训练使用有限资源,这显著加快了第一轮的速度。默认情况下,“有限资源”意味着模型在训练集的一小部分上进行训练。然而,也可能存在其他限制,比如如果模型有一个超参数来设置它,则减少训练迭代次数。一旦每个候选都被评估过,只有最好的候选才能进入第二轮,他们被允许使用更多资源进行竞争。经过几轮后,最终的候选将使用全部资源进行评估。这可能会节省一些调整超参数的时间。
集成方法
微调系统的另一种方法是尝试组合表现最佳的模型。该组(或“集成”)通常比最佳单个模型表现更好——就像随机森林比它们依赖的单个决策树表现更好一样——特别是如果单个模型产生非常不同类型的错误。例如,您可以训练和微调一个k最近邻模型,然后创建一个集成模型,该模型只预测随机森林预测和该模型的预测的平均值。我们将在第七章中更详细地介绍这个主题。
分析最佳模型及其错误
通过检查最佳模型,您通常会对问题有很好的洞察。例如,RandomForestRegressor可以指示每个属性对于进行准确预测的相对重要性:
>>> final_model = rnd_search.best_estimator_ # includes preprocessing
>>> feature_importances = final_model["random_forest"].feature_importances_
>>> feature_importances.round(2)
array([0.07, 0.05, 0.05, 0.01, 0.01, 0.01, 0.01, 0.19, [...], 0.01])让我们按降序对这些重要性分数进行排序,并将它们显示在其对应的属性名称旁边:
>>> sorted(zip(feature_importances,
... final_model["preprocessing"].get_feature_names_out()),
... reverse=True)
...
[(0.18694559869103852, 'log__median_income'),
(0.0748194905715524, 'cat__ocean_proximity_INLAND'),
(0.06926417748515576, 'bedrooms__ratio'),
(0.05446998753775219, 'rooms_per_house__ratio'),
(0.05262301809680712, 'people_per_house__ratio'),
(0.03819415873915732, 'geo__Cluster 0 similarity'),
[...]
(0.00015061247730531558, 'cat__ocean_proximity_NEAR BAY'),
(7.301686597099842e-05, 'cat__ocean_proximity_ISLAND')]有了这些信息,您可能想尝试删除一些不太有用的特征(例如,显然只有一个ocean_proximity类别是真正有用的,因此您可以尝试删除其他类别)。
提示
sklearn.feature_selection.SelectFromModel转换器可以自动为您删除最不重要的特征:当您拟合它时,它会训练一个模型(通常是随机森林),查看其feature_importances_属性,并选择最有用的特征。然后当您调用transform()时,它会删除其他特征。
您还应该查看系统产生的具体错误,然后尝试理解为什么会出错以及如何解决问题:添加额外特征或去除无信息的特征,清理异常值等。
现在也是一个好时机确保您的模型不仅在平均情况下表现良好,而且在所有类型的地区(无论是农村还是城市,富裕还是贫穷,北方还是南方,少数民族还是非少数民族等)中都表现良好。为每个类别创建验证集的子集需要一些工作,但这很重要:如果您的模型在某个地区类别上表现不佳,那么在解决问题之前可能不应部署该模型,或者至少不应用于为该类别做出预测,因为这可能会带来更多伤害而不是好处。
在测试集上评估您的系统
调整模型一段时间后,最终你有了一个表现足够好的系统。你准备在测试集上评估最终模型。这个过程没有什么特别的;只需从测试集中获取预测变量和标签,运行你的final_model来转换数据并进行预测,然后评估这些预测结果:
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
final_predictions = final_model.predict(X_test)
final_rmse = mean_squared_error(y_test, final_predictions, squared=False)
print(final_rmse) # prints 41424.40026462184在某些情况下,这种泛化误差的点估计可能不足以说服您启动:如果它比当前生产中的模型仅好 0.1%怎么办?您可能想要知道这个估计有多精确。为此,您可以使用scipy.stats.t.interval()计算泛化误差的 95%置信区间。您得到一个相当大的区间,从 39,275 到 43,467,而您之前的点估计为 41,424 大致位于其中间:
>>> from scipy import stats
>>> confidence = 0.95
>>> squared_errors = (final_predictions - y_test) ** 2
>>> np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
... loc=squared_errors.mean(),
... scale=stats.sem(squared_errors)))
...
array([39275.40861216, 43467.27680583])如果您进行了大量的超参数调整,性能通常会略低于使用交叉验证测量的性能。这是因为您的系统最终被微调以在验证数据上表现良好,可能不会在未知数据集上表现得那么好。在这个例子中并非如此,因为测试 RMSE 低于验证 RMSE,但当发生这种情况时,您必须抵制调整超参数以使测试集上的数字看起来好的诱惑;这种改进不太可能推广到新数据。
现在是项目预启动阶段:您需要展示您的解决方案(突出显示您学到了什么,什么有效,什么无效,做出了什么假设以及您的系统有什么限制),记录一切,并创建具有清晰可视化和易于记忆的陈述的漂亮演示文稿(例如,“收入中位数是房价的头号预测因子”)。在这个加利福尼亚州住房的例子中,系统的最终性能并不比专家的价格估计好多少,这些估计通常偏离 30%,但如果这样做可以为专家节省一些时间,让他们可以从事更有趣和更有成效的任务,那么启动它可能仍然是一个好主意。
启动、监控和维护您的系统
完美,您已获得启动批准!现在您需要准备好将解决方案投入生产(例如,完善代码,编写文档和测试等)。然后,您可以将模型部署到生产环境。最基本的方法就是保存您训练的最佳模型,将文件传输到生产环境,并加载它。要保存模型,您可以像这样使用joblib库:
import joblib
joblib.dump(final_model, "my_california_housing_model.pkl")提示
通常最好保存您尝试的每个模型,这样您就可以轻松地返回到您想要的任何模型。您还可以保存交叉验证分数,也许是验证集上的实际预测结果。这将使您能够轻松比较不同模型类型之间的分数,并比较它们所产生的错误类型。
一旦您的模型转移到生产环境,您就可以加载并使用它。为此,您必须首先导入模型依赖的任何自定义类和函数(这意味着将代码转移到生产环境),然后使用joblib加载模型并用它进行预测:
import joblib
[...] # import KMeans, BaseEstimator, TransformerMixin, rbf_kernel, etc.
def column_ratio(X): [...]
def ratio_name(function_transformer, feature_names_in): [...]
class ClusterSimilarity(BaseEstimator, TransformerMixin): [...]
final_model_reloaded = joblib.load("my_california_housing_model.pkl")
new_data = [...] # some new districts to make predictions for
predictions = final_model_reloaded.predict(new_data)例如,也许该模型将在网站内使用:用户将输入有关新区域的一些数据,然后点击“估算价格”按钮。这将向包含数据的查询发送到 Web 服务器,Web 服务器将其转发到您的 Web 应用程序,最后您的代码将简单地调用模型的predict()方法(您希望在服务器启动时加载模型,而不是每次使用模型时都加载)。或者,您可以将模型封装在专用的 Web 服务中,您的 Web 应用程序可以通过 REST API 查询该服务¹³(请参见图 2-20)。这样可以更容易地将模型升级到新版本,而不会中断主要应用程序。它还简化了扩展,因为您可以启动所需数量的 Web 服务,并将来自 Web 应用程序的请求负载均衡到这些 Web 服务中。此外,它允许您的 Web 应用程序使用任何编程语言,而不仅仅是 Python。

mls3 0220
图 2-20. 作为 Web 服务部署并由 Web 应用程序使用的模型
另一种流行的策略是将模型部署到云端,例如在 Google 的 Vertex AI 上(以前称为 Google Cloud AI 平台和 Google Cloud ML 引擎):只需使用joblib保存您的模型并将其上传到 Google Cloud Storage(GCS),然后转到 Vertex AI 并创建一个新的模型版本,将其指向 GCS 文件。就是这样!这为您提供了一个简单的网络服务,可以为您处理负载平衡和扩展。它接受包含输入数据(例如一个地区的数据)的 JSON 请求,并返回包含预测的 JSON 响应。然后,您可以在您的网站(或您正在使用的任何生产环境)中使用此网络服务。正如您将在第十九章中看到的那样,将 TensorFlow 模型部署到 Vertex AI 与部署 Scikit-Learn 模型并没有太大不同。
但部署并不是故事的终点。您还需要编写监控代码,定期检查系统的实时性能,并在性能下降时触发警报。它可能会非常快速地下降,例如如果您的基础设施中的某个组件出现故障,但请注意,它也可能会非常缓慢地衰减,这很容易在很长一段时间内不被注意到。这是很常见的,因为模型腐烂:如果模型是使用去年的数据训练的,那么它可能不适应今天的数据。
因此,您需要监控模型的实时性能。但如何做到这一点呢?嗯,这取决于情况。在某些情况下,可以从下游指标推断模型的性能。例如,如果您的模型是推荐系统的一部分,并且建议用户可能感兴趣的产品,那么每天销售的推荐产品数量很容易监控。如果这个数字下降(与非推荐产品相比),那么主要嫌疑人就是模型。这可能是因为数据管道出现问题,或者可能是模型需要重新训练以适应新数据(我们将很快讨论)。
但是,您可能还需要人工分析来评估模型的性能。例如,假设您训练了一个图像分类模型(我们将在第三章中讨论这些内容)来检测生产线上各种产品缺陷。在数千个有缺陷的产品运送给客户之前,如何在模型性能下降时获得警报?一个解决方案是向人工评分员发送模型分类的所有图片样本(特别是模型不太确定的图片)。根据任务的不同,评分员可能需要是专家,也可能是非专业人员,例如众包平台上的工人(例如,亚马逊 Mechanical Turk)。在某些应用中,甚至可以是用户自己,例如通过调查或重新利用的验证码进行回应。
无论如何,您都需要建立一个监控系统(无论是否有人工评分员来评估实时模型),以及定义在发生故障时应该采取的所有相关流程以及如何为其做好准备。不幸的是,这可能是一项很多工作。事实上,通常比构建和训练模型要多得多。
如果数据不断发展,您将需要定期更新数据集并重新训练模型。您应该尽可能自动化整个过程。以下是一些您可以自动化的事项:
- 定期收集新数据并对其进行标记(例如,使用人工评分员)。
- 编写一个脚本来自动训练模型并微调超参数。该脚本可以自动运行,例如每天或每周一次,具体取决于您的需求。
- 编写另一个脚本,将在更新的测试集上评估新模型和先前模型,并在性能没有下降时将模型部署到生产环境(如果性能下降了,请确保调查原因)。该脚本可能会测试模型在测试集的各种子集上的性能,例如贫困或富裕地区,农村或城市地区等。
您还应该确保评估模型的输入数据质量。有时性能会因为信号质量不佳(例如,故障传感器发送随机值,或其他团队的输出变得陈旧)而略微下降,但可能需要一段时间,直到系统性能下降到足以触发警报。如果监控模型的输入,您可能会更早地发现这一点。例如,如果越来越多的输入缺少某个特征,或者均值或标准差与训练集相差太远,或者分类特征开始包含新类别,您可以触发警报。
最后,确保您保留您创建的每个模型的备份,并具备回滚到先前模型的过程和工具,以防新模型因某种原因开始严重失败。备份还使得可以轻松地将新模型与先前模型进行比较。同样,您应该保留每个数据集版本的备份,以便在新数据集损坏时(例如,如果添加到其中的新数据被证明充满异常值),可以回滚到先前数据集。备份数据集还可以让您评估任何模型与任何先前数据集的关系。
正如您所看到的,机器学习涉及相当多的基础设施。第十九章讨论了其中的一些方面,但这是一个名为ML Operations(MLOps)的非常广泛的主题,值得有一本专门的书来讨论。因此,如果您的第一个机器学习项目需要大量的工作和时间来构建和部署到生产环境,也不要感到惊讶。幸运的是,一旦所有基础设施就绪,从构思到生产将会更快。
试一试!
希望本章让您对机器学习项目的外观有了一个很好的了解,并向您展示了一些可以用来训练出色系统的工具。正如您所看到的,大部分工作在数据准备阶段:构建监控工具,设置人工评估流水线,以及自动化常规模型训练。当然,机器学习算法很重要,但可能更好的是熟悉整个过程,并且对三四种算法很熟悉,而不是花费所有时间探索高级算法。
因此,如果您还没有这样做,现在是时候拿起笔记本电脑,选择您感兴趣的数据集,并尝试从头到尾完成整个过程。一个很好的开始地方是在竞赛网站上,比如Kaggle:您将有一个数据集可以使用,一个明确的目标,以及可以分享经验的人。玩得开心!
练习
以下练习基于本章的房屋数据集:
- 尝试使用各种超参数的支持向量机回归器(
sklearn.svm.SVR),例如kernel="linear"(对于C超参数的各种值)或kernel="rbf"(对于C和gamma超参数的各种值)。请注意,支持向量机在大型数据集上不容易扩展,因此您可能应该仅在训练集的前 5,000 个实例上训练模型,并仅使用 3 折交叉验证,否则将需要数小时。现在不用担心超参数的含义;我们将在第五章中讨论它们。最佳SVR预测器的表现如何? - 尝试用
RandomizedSearchCV替换GridSearchCV。 - 尝试在准备流水线中添加
SelectFromModel转换器,仅选择最重要的属性。 - 尝试创建一个自定义转换器,在其
fit()方法中训练一个k最近邻回归器(sklearn.neighbors.KNeighborsRegressor),并在其transform()方法中输出模型的预测。然后将此功能添加到预处理流水线中,使用纬度和经度作为该转换器的输入。这将在模型中添加一个特征,该特征对应于最近地区的房屋中位数价格。 - 使用
GridSearchCV自动探索一些准备选项。 - 尝试从头开始再次实现
StandardScalerClone类,然后添加对inverse_transform()方法的支持:执行scaler.inverse_transform(scaler.fit_transform(X))应该返回一个非常接近X的数组。然后添加特征名称的支持:如果输入是 DataFrame,则在fit()方法中设置feature_names_in_。该属性应该是一个列名的 NumPy 数组。最后,实现get_feature_names_out()方法:它应该有一个可选的input_features=None参数。如果传递了,该方法应该检查其长度是否与n_features_in_匹配,并且如果定义了feature_names_in_,则应该匹配;然后返回input_features。如果input_features是None,那么该方法应该返回feature_names_in_(如果定义了)或者长度为n_features_in_的np.array(["x0", "x1", ...])。
这些练习的解决方案可以在本章笔记本的末尾找到,网址为https://homl.info/colab3。
原始数据集出现在 R. Kelley Pace 和 Ronald Barry 的“稀疏空间自回归”中,统计与概率信件 33,第 3 期(1997 年):291-297。
馈送给机器学习系统的信息片段通常称为信号,这是指克劳德·香农在贝尔实验室开发的信息论,他的理论是:您希望有高的信噪比。
记住,转置运算符将列向量翻转为行向量(反之亦然)。
您可能还需要检查法律约束,例如不应将私有字段复制到不安全的数据存储中。
标准差通常用σ(希腊字母 sigma)表示,它是方差的平方根,即与均值的平方偏差的平均值。当一个特征具有钟形的正态分布(也称为高斯分布)时,这是非常常见的,“68-95-99.7”规则适用:大约 68%的值落在均值的 1σ范围内,95%在 2σ范围内,99.7%在 3σ范围内。
经常会看到人们将随机种子设置为 42。这个数字没有特殊的属性,除了它是生命、宇宙和一切终极问题的答案。
位置信息实际上相当粗糙,因此许多地区将具有相同的 ID,因此它们最终会进入相同的集合(测试或训练)。这引入了一些不幸的抽样偏差。
如果您是在灰度模式下阅读本文,请拿一支红笔,在从旧金山湾到圣迭戈的大部分海岸线上涂鸦(正如您所期望的那样)。您也可以在萨克拉门托周围添加一块黄色的区域。
有关设计原则的更多详细信息,请参阅 Lars Buitinck 等人的“机器学习软件的 API 设计经验:来自 Scikit-Learn 项目的经验”,arXiv 预印本 arXiv:1309.0238(2013)。
一些预测器还提供测量其预测置信度的方法。
当您阅读这些文字时,可能会有可能使所有的转换器在接收到 DataFrame 作为输入时输出 Pandas DataFrames:Pandas 输入,Pandas 输出。可能会有一个全局配置选项:sklearn.set_config(pandas_in_out=True)。
查看 SciPy 的文档以获取更多详细信息。
¹³ 简而言之,REST(或 RESTful)API 是基于 HTTP 的 API,遵循一些约定,例如使用标准的 HTTP 动词来读取、更新、创建或删除资源(GET、POST、PUT 和 DELETE),并使用 JSON 作为输入和输出。
¹⁴ 验证码是一种测试,用于确保用户不是机器人。这些测试经常被用作标记训练数据的廉价方式。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-02-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号