Nginx中常见问题与错误处理


一、场景错误日志总结
1、502伴随出现错误no live upstreams while connecting to upstream的原因:
具体场景:接入层的负载均衡的nginx集群转发给业务nginx,业务nginx再转发给后端的应用服务器。业务nginx配置文件如下:
upstream ads {
server ap1:8888 max_fails=1 fail_timeout=60s;
server ap2:8888 max_fails=1 fail_timeout=60s;
}如果业务nginx出现日志: no live upstreams while connecting to upstream 的日志,
此外还有大量的“upstream prematurely closed connection while reading response header from upstream”的日志。
看“no live upstreams”的问题。
看字面意思是nginx发现没有存活的backend后端了,但是奇怪的是,只有部分接口访问异常出现502。
可以从nginx源码的角度来看了。
因为是upstream有关的报错,所以在ngx_http_upstream.c中查找“no live upstreams”的关键字,可以找到如下代码(其实,你会发现,如果在nginx全局代码中找的话,也只有这个文件里面有这个关键字):
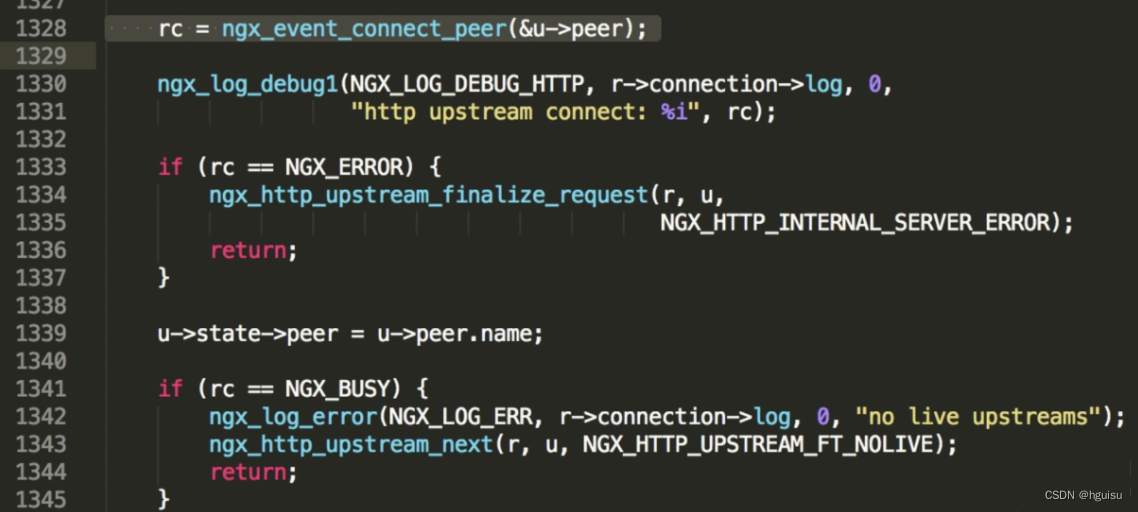
在这里可以看出,当rc等于NGX_BUSY的时候,就会记录“no live upstreams”的错误。
往上看1328行,可以发现rc的值又是ngx_event_connect_peer这个函数返回的。
ngx_event_connect_peer是在event/ngx_event_connect.c中实现的。这个函数中,只有这个地方会返回NGX_BUSY,其他地方都是NGX_OK或者NGX_ERROR或者NGX_AGAIN之类的。
rc = pc->get(pc, pc->data);
if (rc != NGX_OK) {
return rc;
}这里的pc是指向ngx_peer_connection_t结构体的指针, get是个ngx_event_get_peer_pt的函数指针,具体指向哪里,一时无从得知。接着翻看ngx_http_upstream.c
在ngx_http_upstream_init_main_conf中看到了,如下代码:
uscfp = umcf->upstreams.elts;
for (i = 0; i < umcf->upstreams.nelts; i++) {
init = uscfp[i]->peer.init_upstream ? uscfp[i]->peer.init_upstream:
ngx_http_upstream_init_round_robin;
if (init(cf, uscfp[i]) != NGX_OK) {
return NGX_CONF_ERROR;
}
}这里可以看到,默认的配置为轮询(事实上负载均衡的各个模块组成了一个链表,每次从链表到头开始往后处理,从上面到配置文件可以看出,nginx不会在轮询前调用其他的模块),并且用ngx_http_upstream_init_round_robin初始化每个upstream。
再看ngx_http_upstream_init_round_robin函数,里面有如下行:
r->upstream->peer.get = ngx_http_upstream_get_round_robin_peer;
这里把get指针指向了ngx_http_upstream_get_round_robin_peer
在ngx_http_upstream_get_round_robin_peer中,可以看到:
if (peers->single) {
peer = &peers->peer[0];
if (peer->down) {
goto failed;
}
} else {
/* there are several peers */
peer = ngx_http_upstream_get_peer(rrp);
if (peer == NULL) {
goto failed;
}再看看failed的部分:
failed:
if (peers->next) {
/* ngx_unlock_mutex(peers->mutex); */
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, pc->log, 0, "backup servers");
rrp->peers = peers->next;
n = (rrp->peers->number + (8 * sizeof(uintptr_t) - 1))
/ (8 * sizeof(uintptr_t));
for (i = 0; i < n; i++) {
rrp->tried[i] = 0;
}
rc = ngx_http_upstream_get_round_robin_peer(pc, rrp);
if (rc != NGX_BUSY) {
return rc;
}
/* ngx_lock_mutex(peers->mutex); */
}
/* all peers failed, mark them as live for quick recovery */
for (i = 0; i < peers->number; i++) {
peers->peer[i].fails = 0;
}
/* ngx_unlock_mutex(peers->mutex); */
pc->name = peers->name;
return NGX_BUSY;这里就真相大白了,如果连接失败了,就去尝试连下一个,如果所有的都失败了,就会进行quick recovery 把每个peer的失败次数都重置为0,然后再返回一个NGX_BUSY,然后nginx就会打印一条no live upstreams ,最后又回到原始状态,接着进行转发了。
这就解释了no live upstreams之后还能正常访问。
重新看配置文件,如果其中一台有一次失败,nginx就会认为它已经死掉,然后就会把以后的流量全都打到另一台上面,当另外一台也有一次失败的时候,就认为两个都死掉了,然后quick recovery,然后打印一条日志。
2、nginx日志中request_time过大的原因
场景: 查看nginx日志发现请求响应body为1500k左右和request_time为6s左右,导致请求超时无法获取正常数据。
原因: 用户端网络问题:
tcp传输如果分包时,每个tcp包大约1400字节,之前那个请求响应body有1500K左右,要分成100多个tcp包。tcp有个慢启动过程,起初每次发送10个包,之后再根据网络情况调整每次发包数量,假设网络不好,就得分10次发送。然后由于tcp是可靠传输,需要确保每个包对方都收到了(通过给每个包编序号,以及接收对方发送的ack实现),如果在约定时间内没收到对方发的ack会重传该包。此外,tcp有发送窗口的概念,假设发送窗口为10,那么一次性可以发送10个包,之后每收到一个ack才能把这个包对应的发送窗口位置空余出来,发送下一个包。因此,用户端网络不好是会影响响应body全部发完的时间,进而影响nginx日志中request_time的时间。
请求响应body体过大:
因为请求接口输出的数据中有些过大的无用数据导致请求响应body过大导致分包发送影响了request_time。
3、400 bad request错误的原因和解决办法
配置nginx.conf相关设置如下.
client_header_buffer_size 16k; large_client_header_buffers 4 64k;
根据具体情况调整,一般适当调整值就可以。
4、Nginx出现的413 Request Entity Too Large错误
这个错误一般在上传文件的时候会出现:服务器拒绝处理当前请求,因为该请求提交的实体数据大小超过了服务器愿意或者能够处理的范围。此种情况下,服务器可以关闭连接以免客户端继续发送此请求。
配置文件Nginx.conf的http{}段,添加
client_max_body_size 10m; //设置多大根据自己的需求作调整.
如果运行php的话这个大小client_max_body_size要和php.ini中的如下值的最大值一致或者稍大,这样就不会因为提交数据大 小不一致出现的错误。
post_max_size = 10M upload_max_filesize = 2M
5、 “upstream sent invalid header while reading response header from upstream”
出现该问题的原因未知,
解决方法,增加下面的配置:
proxy_http_version 1.1;
配置项proxy_http_version的默认值为1.0,所以怀疑与1.1中的keepalive特性有关。
二、nginx日志总结
1、访问日志Access.log配置
log_format main ‘remote_addr remote_user [time_local] “request” http_host ‘ ‘status upstream_status body_bytes_sent “http_referer” ‘ ‘”http_user_agent” ssl_protocol ssl_cipher upstream_addr ‘ ‘request_time
变量名称 | 变量描述 | 举例说明 |
|---|---|---|
$remote_addr | 客户端地址 | 113.140.15.90 |
$remote_user | 客户端用户名称 | - |
$time_local | 访问时间和时区 | 18/Jul/2012:17:00:01 +0800 |
$request | 请求的URI和HTTP协议 | “GET /pa/img/home/logo-alipay-t.png HTTP/1.1″ |
$http_host | 请求地址,即浏览器中你输入的地址(IP或域名) | img.alipay.com 10.253.70.103 |
$status | HTTP请求状态 | 200 |
$upstream_status | upstream状态 | 200 |
$body_bytes_sent | 发送给客户端文件内容大小 | 547 |
$http_referer | 跳转来源 | “https://cashier.alipay.com…/” |
$http_user_agent | 用户终端代理 | “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; SV1; GTB7.0; .NET4.0C; |
$ssl_protocol | SSL协议版本 | TLSv1 |
$ssl_cipher | 交换数据中的算法 | RC4-SHA |
$upstream_addr | 后台upstream的地址,即真正提供服务的主机地址 | 10.228.35.247:80 |
$request_time | 整个请求的总时间 | 0.205 |
$upstream_response_time | 请求过程中,upstream响应时间 | 0.002 |
示例: 116.9.137.90 – [02/Aug/2012:14:47:12 +0800] “GET /images/XX/20100324752729.png HTTP/1.1″img.alipay.com 200 200 2038 https://cashier.alipay.com/XX/PaymentResult.htm?payNo=XX&outBizNo=2012XX “Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0; 360SE)” TLSv1 AES128-SHA 10.228.21.237:80 0.198 0.001
2、错误日志[Error.log]
错误信息 | 错误说明 |
|---|---|
“upstream prematurely(过早的) closed connection” | 请求uri的时候出现的异常,是由于upstream还未返回应答给用户时用户断掉连接造成的,对系统没有影响,可以忽略 |
“recv() failed (104: Connection reset by peer)” | (1)服务器的并发连接数超过了其承载量,服务器会将其中一些连接Down掉; (2)客户关掉了浏览器,而服务器还在给客户端发送数据; (3)浏览器端按了Stop |
“(111: Connection refused) while connecting to upstream” | 用户在连接时,若遇到后端upstream挂掉或者不通,会收到该错误 |
“(111: Connection refused) while reading response header from upstream” | 用户在连接成功后读取数据时,若遇到后端upstream挂掉或者不通,会收到该错误 |
“(111: Connection refused) while sending request to upstream” | Nginx和upstream连接成功后发送数据时,若遇到后端upstream挂掉或者不通,会收到该错误 |
“(110: Connection timed out) while connecting to upstream” | nginx连接后面的upstream时超时 |
“(110: Connection timed out) while reading upstream” | nginx读取来自upstream的响应时超时 |
“(110: Connection timed out) while reading response header from upstream” | nginx读取来自upstream的响应头时超时 |
“(110: Connection timed out) while reading upstream” | nginx读取来自upstream的响应时超时 |
“(104: Connection reset by peer) while connecting to upstream” | upstream发送了RST,将连接重置 |
“upstream sent invalid header while reading response header from upstream” | upstream发送的响应头无效 |
“upstream sent no valid HTTP/1.0 header while reading response header from upstream” | upstream发送的响应头无效 |
“client intended to send too large body” | 用于设置允许接受的客户端请求内容的最大值,默认值是1M,client发送的body超过了设置值 |
“reopening logs” | 用户发送kill -USR1命令 |
“gracefully shutting down”, | 用户发送kill -WINCH命令 |
“no servers are inside upstream” | upstream下未配置server |
“no live upstreams while connecting to upstream” | upstream下的server全都挂了 |
“SSL_do_handshake() failed” | SSL握手失败 |
“SSL_write() failed (SSL:) while sending to client” | |
“(13: Permission denied) while reading upstream” | |
“(98: Address already in use) while connecting to upstream” | |
“(99: Cannot assign requested address) while connecting to upstream” | |
“ngx_slab_alloc() failed: no memory in SSL session shared cache” | ssl_session_cache大小不够等原因造成 |
“could not add new SSL session to the session cache while SSL handshaking” | ssl_session_cache大小不够等原因造成 |
“send() failed (111: Connection refused)” |
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号