在Elasticsearch中如何选择精确和近似的kNN搜索
原创
在Elasticsearch中如何选择精确和近似的kNN搜索
原创
点火三周
发布于 2024-05-26 07:05:16
发布于 2024-05-26 07:05:16
什么是 kNN?
语义搜索 是一个用于相关度排序的强大工具。它不仅使用关键词,还考虑文档和查询的实际含义。
语义搜索基于向量搜索。在向量搜索中,我们的文档都有计算过的向量嵌入。这些嵌入是用机器学习模型计算的,并以向量的形式存储在文档数据旁边。
查询时,我们会用相同的机器学习模型计算查询文本的嵌入。语义搜索通过比较查询嵌入和文档嵌入来找到最接近查询的结果。
kNN,即k最近邻,是一种获取特定嵌入的前 k 个最接近结果的技术。
计算查询的嵌入的 kNN 有两种主要方法:精确和近似。本文将帮助您:
- 了解什么是精确和近似的 kNN 搜索
- 如何为这些方法准备您的索引
- 如何决定哪种方法最适合您的使用场景
精确的 kNN:搜索所有内容
一种计算最接近结果的方法是将所有文档嵌入与查询的嵌入进行比较。这确保了我们得到最接近的匹配,因为我们比较了所有嵌入。我们的搜索结果将非常准确,因为我们考虑了整个文档库,并将所有文档嵌入与查询嵌入进行比较。
然而,这种方法的缺点是耗时。我们需要使用相似性函数对所有文档逐一计算嵌入的相似性。这意味着搜索时间会随着文档数量的增加而线性增加。
可以在向量字段上使用script_score 和向量函数进行精确搜索,以计算向量之间的相似性。
近似的 kNN:一个好的估计
另一种方法是使用近似搜索,而不是比较所有文档。为了提供一个有效的 kNN 近似,Elasticsearch 和 Lucene 使用分层导航小世界 HNSW。
HNSW 是一种图数据结构,在不同层次上保持元素之间的链接。每一层包含连接的元素,并连接到下一层的元素。最底层包含所有元素。
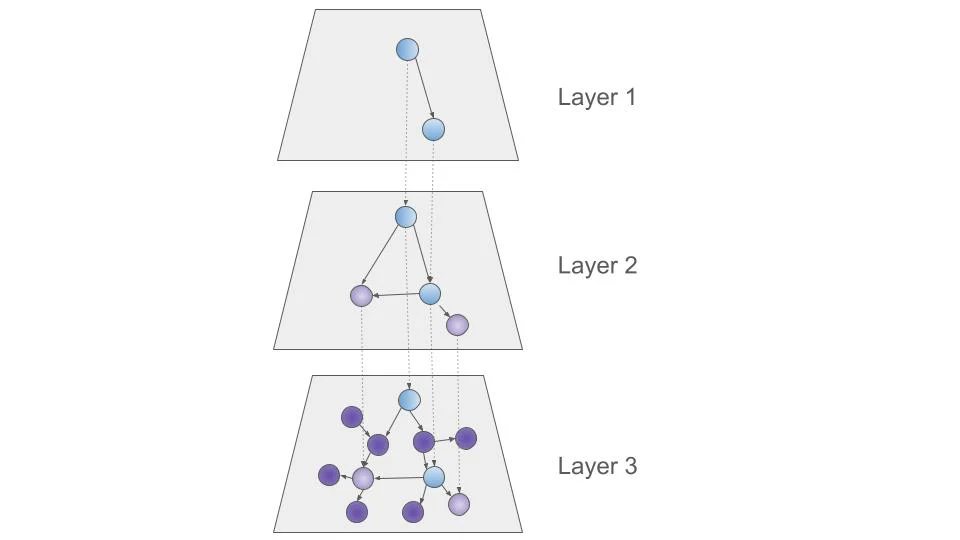
图1 - HNSW 图的一个例子。顶层包含开始搜索的初始节点。这些初始节点作为进入下层的入口点,每层都包含更多的节点。最底层包含所有节点
可以将其比作驾驶;有高速公路、道路和街道。当你在高速公路上驾驶时,你会看到一些出口标志,这些标志描述了一些高级区域(如一个城镇或社区)。然后你会到达一个有特定街道方向的地方。一旦你到达一条街道,你可以到达一个特定的地址或同一社区的其他地址。
HNSW 与此类似,因为它创建了不同级别的向量嵌入。它首先计算与初始查询更接近的高速公路,并选择看起来更有希望的出口来继续寻找更接近我们寻找的地址。这在性能方面表现很好,因为它不需要考虑所有文档,而是使用这种多级方法快速找到一个近似的更接近的地址。
然而,这是一种近似值。并非所有节点都是互联的,这意味着可能会忽略更接近特定节点的结果,因为它们可能没有连接。节点的互联性取决于 HNSW 结构的创建方式。
HNSW 的优点取决于几个因素:
- 构造方式。HNSW 的构建过程会考虑一些候选者作为特定节点的最接近的节点。增加要考虑的候选者数量将产生更精确的结构,但会在建立索引时花费更多的时间。
ef_construction参数在 dense vector index_options 中用于此目的。 - 搜索时考虑的候选者数量。在寻找更接近的结果时,该过程会跟踪一些候选者。这个数字越大,搜索越精确,速度也越慢。
num_candidates在 kNN 参数 中控制这种行为。 - 搜索的段数量。每个段都有一个需要搜索的 HNSW 图,需要将其结果与其他段图合并。段数越少意味着搜索的图越少(速度更快),但结果集样本也会更少(不够精确)。
总体而言,HNSW 在性能和召回率之间提供了良好的权衡,并允许在索引和查询方面进行微调。
使用 HNSW 搜索可以在大多数情况下使用 kNN 搜索部分。对于更高级的用例,例如:
- 将 kNN 与其他查询结合(作为布尔查询或固定查询的一部分)
- 使用
function_score微调评分 - 提高聚合和字段折叠的多样性
你可以在这篇文章中了解 kNN 查询和 kNN 搜索部分的区别。我们将在下面深入讨论你何时想使用这种方法而不是其他方法。
为精确和近似搜索建立索引
dense_vector 字段类型
对于存储你的嵌入,你可以选择两种主要的 dense_vector 字段索引类型:
- flat 类型(包括 flat 和 int8_flat)存储原始向量,不添加 HNSW 数据结构。使用 flat 索引类型的 dense_vectors 将始终使用精确的 kNN - kNN 查询实际上将执行一个精确的查询而不是一个近似的查询。
- HNSW 类型(包括 hnsw 和 int8_hnsw)创建 HNSW 数据结构,允许使用近似的 kNN 搜索。
这是否意味着你不能用 HNSW 字段类型使用精确的 kNN?并非如此!你可以通过 script_score query 使用精确的 kNN,或者通过 kNN section 和 kNN query 使用近似的 kNN。这根据你的搜索用例提供了更多的灵活性。
使用 HNSW 字段类型意味着需要构建 HNSW 图结构,这需要时间,内存 和磁盘空间。如果你只是使用精确搜索,你可以使用 flat 向量字段类型。这确保了你的嵌入被最优地索引并使用更少的空间。
请记住,无论如何都要避免在 _source 中存储你的嵌入,以减少存储需求。
量化
使用量化,无论是 flat(int8_flat)还是 HNSW(int8_hnsw)类型的索引都将帮助你减小嵌入大小,从而使用更少的内存和磁盘存储来保存嵌入信息。
由于搜索性能依赖于嵌入尽可能多地适应内存,你应该始终寻找可能的数据减少方法。使用量化是内存和召回之间的权衡。
我应该如何在精确和近似搜索之间选择?
这里没有一刀切的答案。你需要考虑一些因素,并进行实验,以找到性能和精度之间的最佳平衡:
数据大小
搜索所有内容并不是你应该不惜一切代价避免的事情。根据你的数据大小(文档数量和嵌入维度),进行精确的 kNN 搜索可能是有意义的。
作为经验法则,如果你有少于 1 万个文档需要搜索,精确搜索可能是一个好的选择。请记住,可以提前过滤要搜索的文档数量,通过应用过滤器来限制要搜索的有效文档数量。
近似搜索在文档数量方面更好地扩展,所以如果你有大量文档需要搜索,或者预期文档数量会显著增加,那么近似搜索是更好的选择。
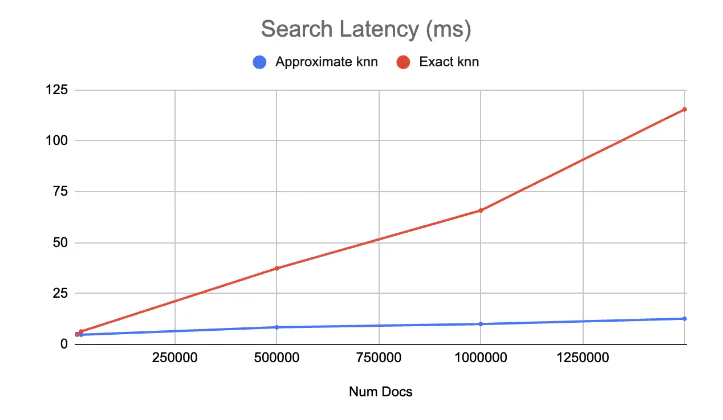
图2 - 使用来自 so_vector rally track 的 768 维向量进行精确和近似 kNN 的一个例子运行。该例子演示了精确 kNN 的线性运行时间与 HNSW 搜索的对数运行时间
过滤
过滤很重要,因为它减少了需要考虑搜索的文档数量。在决定使用精确还是近似时需要考虑这一点。你可以使用查询过滤器来减少需要考虑的文档数量,无论是精确还是近似搜索。
然而,近似搜索对过滤采取了不同的方法。当使用 HNSW 进行近似搜索时,查询过滤器将在检索到前 k 个结果后应用。这就是为什么在 kNN 查询中使用查询过滤器被称为 kNN 的后过滤器。
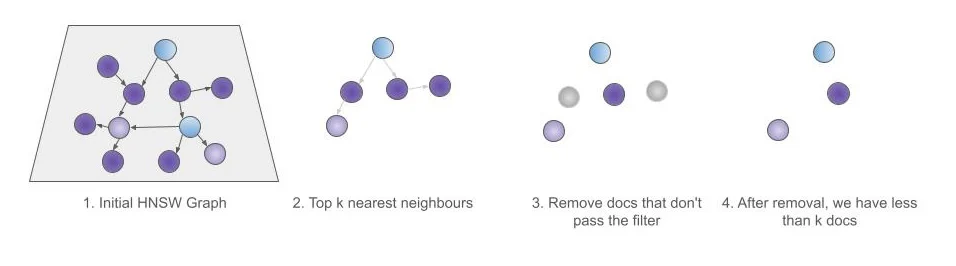
图3 - kNN 搜索中的后过滤
在 kNN 中使用后过滤的问题是,过滤器是在我们收集到前 k 个结果之后应用的。这意味着我们可能会得到少于 k 个结果,因为我们需要从我们已经从 HNSW 图中检索到的前 k 个结果中移除那些不通过过滤器的元素。
幸运的是,kNN 有另一种方法,那就是在 kNN 查询本身中指定一个过滤器。这个过滤器在遍历 HNSW 图时应用到图元素上,而不是在之后应用。这确保了返回前 k 个元素,因为图将被遍历 - 跳过不通过过滤器的元素 - 直到我们得到前 k 个元素。
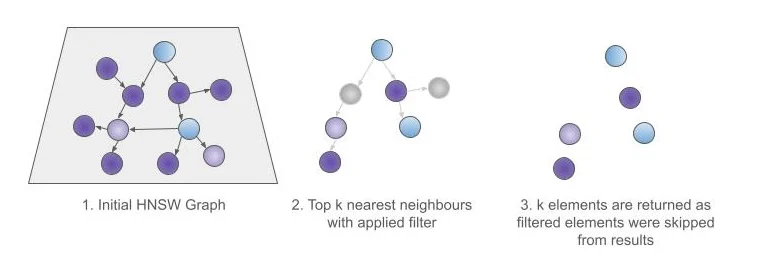
图4 - kNN 搜索中的预过滤
这个特定的 kNN 查询过滤器被称为kNN 预过滤器,因为它是在检索结果之前应用的,而不是之后应用。这就是为什么,在使用 kNN 查询的情况下,常规查询过滤器被称为后过滤器。
使用 kNN 预过滤器会影响近似搜索的性能,因为我们需要在 HNSW 图中考虑更多的元素 - 丢弃不通过过滤器的元素,因此我们需要在每次搜索中寻找更多的元素以获得相同数量的结果。
即将到来…
有一些改进即将到来,将有助于精确和近似 kNN。
Elasticsearch 将增加从 flat 升级到 HNSW 的 dense_vector 类型的可能性。这意味着你可以开始使用 flat 向量类型进行精确的 kNN,最终在需要规模时开始使用 HNSW。当使用近似 kNN 时,你的段将被透明地搜索,并在它们合并在一起时自动转换为 HNSW。
将添加一个新的精确 kNN 查询,使得可以用一个简单的查询对 flat 和 HNSW 字段进行精确的 kNN 搜索,而不是依赖于脚本得分查询。这将使精确 kNN 更加直观。
结论
那么,你应该在文档上使用近似还是精确的 kNN 呢?检查以下内容:
- 有多少文档?少于 1 万个(在应用过滤器后)可能是使用精确搜索的好例子。
- 你的搜索是否使用过滤器?这影响了需要搜索的文档数量。如果你需要使用近似 kNN,请记住使用 kNN 预过滤器,虽然这会牺牲性能,但会得到更多的结果。
你可以通过使用 HNSW dense_vector 索引,然后将 kNN 搜索与 script_score 进行比较来进行精确的 kNN。这允许使用相同的字段类型比较两种方法(只要记住,如果你决定使用精确搜索,就要将你的 dense_vector 字段类型改为 flat!)
祝你搜索愉快!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号