跟老表学Python第二课,数据类型和变量

跟老表学Python第二课,数据类型和变量

老表
发布于 2024-06-03 13:40:44
发布于 2024-06-03 13:40:44
本文目录:
- 变量和赋值
- 变量命名规则
- 变量的创建和使用
- 基本数据类型
- 数字类型(整数、浮点数、复数)
- 字符串操作(创建、索引、切片、方法)
- 布尔类型和布尔运算
- 数据结构
- 列表(创建、操作、方法)
- 元组(不可变序列)
- 字典(键值对存储)
- 集合(集合操作)
- 附加:PEP 8命名规范
- 1. 变量名和函数名
- 2. 常量名
- 3. 类名
- 4. 模块名和包名
- 5. 私有成员
- 6. 双前导下划线
- 7. 避免与Python保留关键字冲突
哈喽,大家好,我是老表,学 Python 编程,找老表就对了。
大家好,我打算每日花1-2小时来写一篇文章,包括文章主题思考和实现,看看能不能被官方推荐。(帮我点点赞哦~)
断更好久,再次启航。点赞即是对我最大的支持。
欢迎大家留言,说说自己想看什么主题的Python文章,留言越具体,我写的越快,比如留言:我想看Python 自动操作Excel 相关文章。
如果你有具体的需求想通过使用Python实现自动化,那将更好,欢迎私聊我微信,一起交流探讨。
变量和赋值
变量命名规则
在Python中,变量名必须遵循以下规则:
- 变量名只能包含字母、数字和下划线(_),不能以数字开头。
- 变量名区分大小写。例如,
age和Age是两个不同的变量。 - 变量名应该简洁且有意义,最好遵循PEP 8命名规范,使用下划线分隔单词(如
student_name)。
变量的创建和使用
创建变量时,只需将变量名赋值给某个值即可。可以在赋值后随时更改变量的值。
# 创建变量并赋值
age = 20
student_name = "Alice"
is_passed = True
# 打印变量的值
print(age) # 输出: 20
print(student_name) # 输出: Alice
print(is_passed) # 输出: True
# 更改变量的值
age = 21
is_passed = False
print(age) # 输出: 21
print(is_passed) # 输出: False
基本数据类型
数字类型(整数、浮点数、复数)
Python支持多种数字类型:
- 整数(int):如
1,100,-50 - 浮点数(float):如
1.5,-3.14,2.0 - 复数(complex):如
3+4j,2-3j
# 整数
a = 10
b = -5
# 浮点数
pi = 3.14
gravity = 9.8
# 复数
c1 = 2 + 3j
c2 = 1 - 1j
print(a, b, pi, gravity, c1, c2)

字符串操作(创建、索引、切片、方法)
字符串是字符的序列,可以通过单引号或双引号创建。字符串支持索引、切片和多种方法。
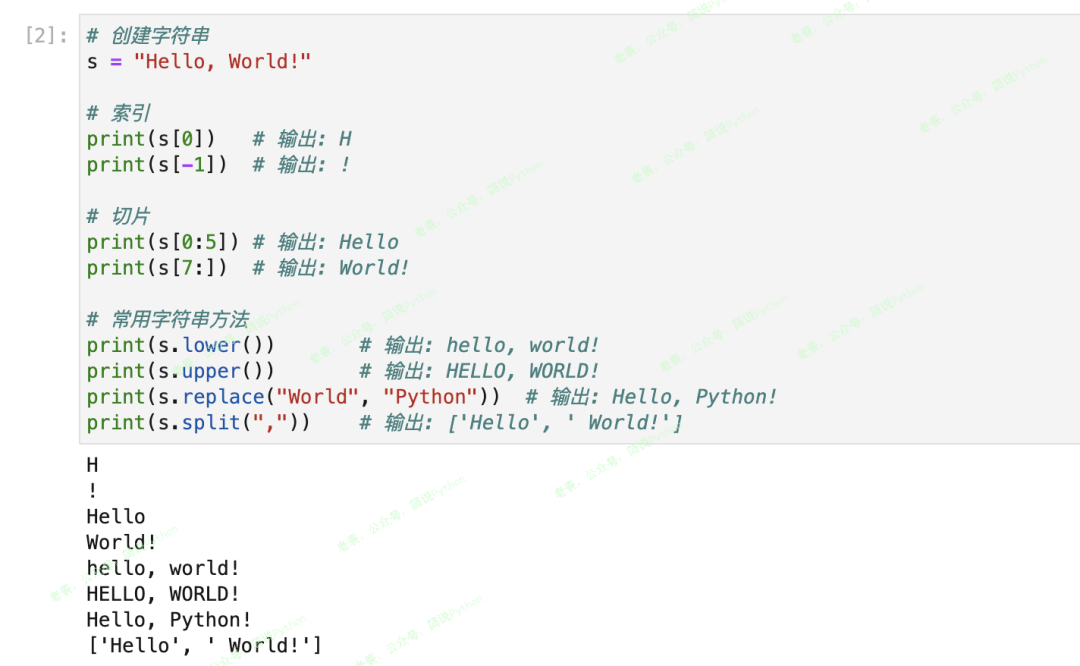
# 创建字符串
s = "Hello, World!"
# 索引
print(s[0]) # 输出: H
print(s[-1]) # 输出: !
# 切片
print(s[0:5]) # 输出: Hello
print(s[7:]) # 输出: World!
# 常用字符串方法
print(s.lower()) # 输出: hello, world!
print(s.upper()) # 输出: HELLO, WORLD!
print(s.replace("World", "Python")) # 输出: Hello, Python!
print(s.split(",")) # 输出: ['Hello', ' World!']
布尔类型和布尔运算
布尔类型只有两个值:True 和 False。布尔运算包括逻辑与(and)、逻辑或(or)、逻辑非(not)。
is_sunny = True
is_raining = False
# 布尔运算
print(is_sunny and is_raining) # 输出: False
print(is_sunny or is_raining) # 输出: True
print(not is_sunny) # 输出: False

数据结构
列表(创建、操作、方法)
列表是可变的有序序列,可以包含任意类型的元素。
# 创建列表
numbers = [1, 2, 3, 4, 5]
mixed = [1, "apple", 3.14, True]
# 访问和修改元素
print(numbers[0]) # 输出: 1
numbers[0] = 10
print(numbers) # 输出: [10, 2, 3, 4, 5]
# 列表方法
numbers.append(6)
print(numbers) # 输出: [10, 2, 3, 4, 5, 6]
numbers.remove(3)
print(numbers) # 输出: [10, 2, 4, 5, 6]

元组(不可变序列)
元组是不可变的有序序列,一旦创建就不能修改。
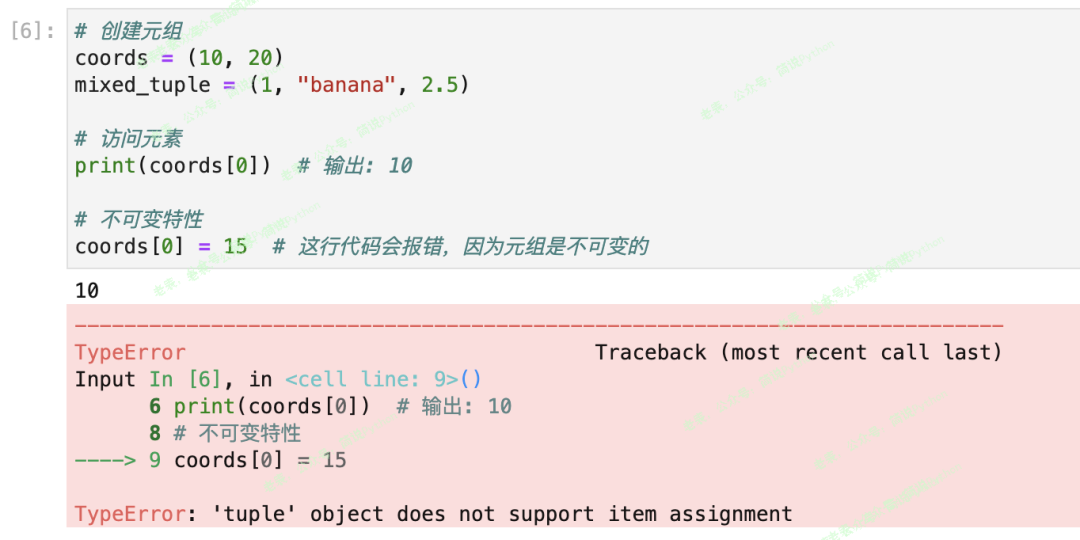
# 创建元组
coords = (10, 20)
mixed_tuple = (1, "banana", 2.5)
# 访问元素
print(coords[0]) # 输出: 10
# 不可变特性
# coords[0] = 15 # 这行代码会报错,因为元组是不可变的
字典(键值对存储)
字典是键值对的无序集合,用于高效存储和查找数据。
# 创建字典
student = {
"name": "Alice",
"age": 20,
"grade": "A"
}
# 访问和修改元素
print(student["name"]) # 输出: Alice
student["age"] = 21
print(student) # 输出: {'name': 'Alice', 'age': 21, 'grade': 'A'}
# 字典方法
student["major"] = "Computer Science"
print(student) # 输出: {'name': 'Alice', 'age': 21, 'grade': 'A', 'major': 'Computer Science'}
del student["grade"]
print(student) # 输出: {'name': 'Alice', 'age': 21, 'major': 'Computer Science'}

集合(集合操作)
集合是无序的不重复元素集合,常用于去重和集合运算。
# 创建集合
fruits = {"apple", "banana", "cherry"}
more_fruits = {"banana", "orange", "grape"}
# 添加和删除元素
fruits.add("watermelon")
print(fruits) # 无序,每次输出可能不一样
fruits.remove("banana")
print(fruits) # 无序,每次输出可能不一样
# 集合运算
print(fruits.union(more_fruits)) # 无序,每次输出可能不一样
print(fruits.intersection(more_fruits)) # 输出: set()
print(fruits.difference(more_fruits)) # 无序,每次输出可能不一样

通过这一模块的学习,学生将掌握Python中常用的数据类型和数据结构的基本操作,为后续的编程实践打下坚实基础。
如有问题或者补充,欢迎评论交流。
万水千山总是情,点个 👍 行不行。
今天文章内容就到这里啦,快来监督我:
附加:PEP 8命名规范
PEP 8(Python Enhancement Proposal 8)是Python代码风格的指导文档,旨在提高代码的可读性和一致性。以下是PEP 8命名规范中最主要的几点:
1. 变量名和函数名
小写字母和下划线分隔:变量名和函数名应使用小写字母,单词之间用下划线分隔。这种命名风格称为“snake_case”。
student_name = "Alice"
def calculate_average(score_list):
pass
2. 常量名
全大写字母和下划线分隔:常量名应使用全大写字母,单词之间用下划线分隔。
MAX_CONNECTIONS = 100
PI = 3.14159
3. 类名
大写字母开头的单词组合:类名应使用每个单词首字母大写的方式,称为“CamelCase”或“PascalCase”。
class StudentRecord:
pass
class BankAccount:
pass
4. 模块名和包名
小写字母:模块名应尽量简短,使用小写字母,可以使用下划线分隔单词(但不推荐)。
import my_module
import mypackage
5. 私有成员
前导下划线:单下划线前缀表示模块内或类内的私有成员。
_private_variable = 42
class MyClass:
def _private_method(self):
pass
6. 双前导下划线
双前导下划线:双前导下划线会触发名称重整(name mangling),使其更难在子类中意外覆盖,通常用于类的私有成员。
class MyClass:
def __init__(self):
self.__private_attr = 42
def __private_method(self):
pass
7. 避免与Python保留关键字冲突
下划线后缀:如果变量名可能与Python的保留关键字冲突,可以在变量名后加一个下划线以示区别。
class_ = "Physics"
def function_(parameter):
pass
通过遵循这些PEP 8命名规范,可以确保代码的清晰和一致性,使团队协作更顺畅,代码维护更容易。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号