微前端学习笔记(5):从import-html-entry发微DOM/JS/CSS隔离
原创
微前端学习笔记(5):从import-html-entry发微DOM/JS/CSS隔离
原创
周陆军博客
发布于 2024-06-06 20:24:29
发布于 2024-06-06 20:24:29
import-html-entry 是 qiankun 中一个举足轻重的依赖,用于获取子应用的 HTML 和 JS,同时对 HTML 和 JS 进行了各自的处理,以便于子应用在父应用中加载。
import-html-entry主要是实现了以下几个能力
- 拉取 url 对应的 html 并且对 html 进行了一系列的处理
- 拉取上述 html 中所有的外联 css 并将其包裹在 style 标签中然后嵌入到上述的 html 中
- 支持执行页级 js 脚本 以及 拉取上述 html 中所有的外联 js 并支持执行
在微前端中,使用此依赖可以直接获取到子应用 (某 url ) 对应的 html 且此 html 上已经嵌好了所有的 css,同时还可以直接执行子应用的所有 js 脚本且此脚本还为 js 隔离(避免污染全局)做了预处理。
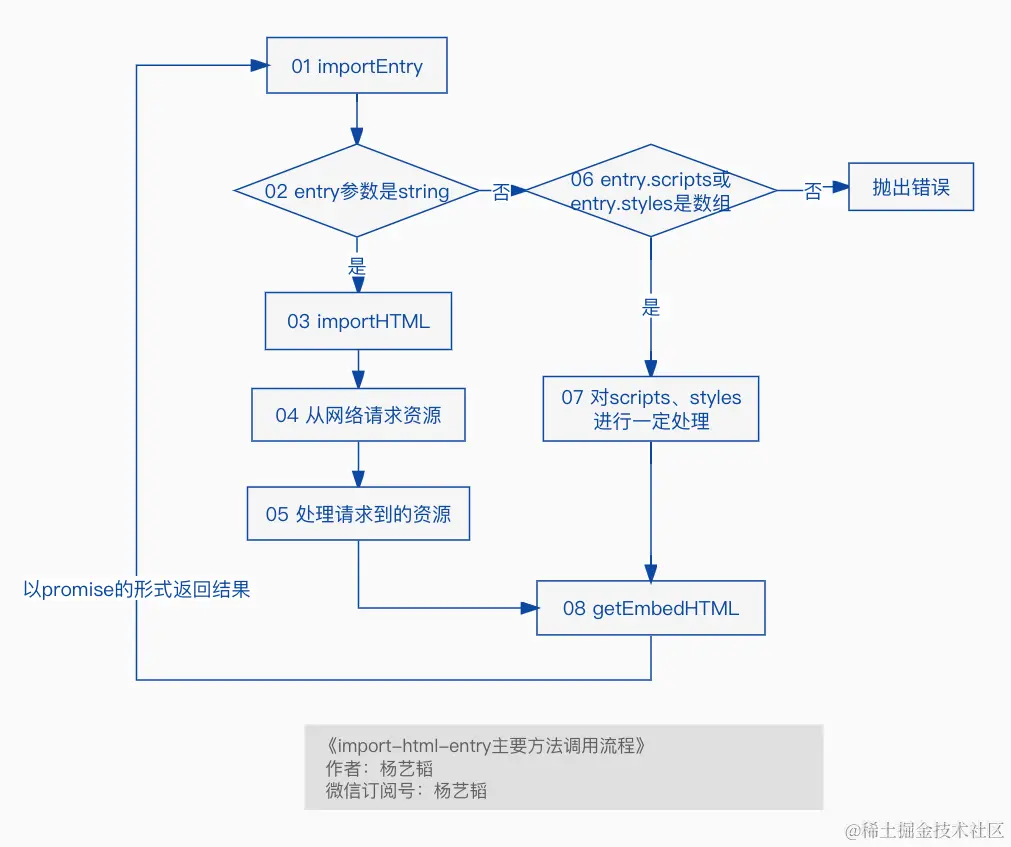
1.png
拉取 HTML 并处理
- 在 importHTML 函数中,通过 fetch 获取到 url 对应的全部内容(即示例中 index.html 全部内容的字符串)
- 调用fetch请求html资源(注意,不是js、css资源);
- 调用processTpl处理资源;
- 调用getEmbedHTML对processTpl处理后的资源中链接的远程js、css资源取到本地并嵌入到html中
- 从返回的结果中解析出以下内容:(解析过程在 processTpl 函数中,整体思路是正则匹配)
- 经过初步处理后的 html,大致为以下处理过程,整个过程
- 去掉注释
- 注释所有的外联 js 以及删除掉所有的页级 js (当然都收集起来了)
- 注释所有的外联 css,保留页级 css 得到的结果如下所示:
- <head> <!-- link https://zhoulujun.net/css/demo.css replaced by import-html-entry --> <style> h1 { font-size: 40px; } </style> </head> <body> <h1>Zhang Pao Pao</h1> <!-- script https://zhoulujun.net/js/brands.js replaced by import-html-entry --> <!-- inline scripts replaced by import-html-entry --> <!-- script http://localhost:7101/main.js replaced by import-html-entry --> </body>
- 由所有 “script” 组成的数组
- 页级的 script 直接作为数组的元素
- 外联的 script 对应的 src 作为数组的元素(以用于后续 fetch 获得对应的 js 内容)
- [ 'https://zhoulujun.net/js//brands.js', "<script>console.log('this is script in-line');</script>", ]
- 经过初步处理后的 html,大致为以下处理过程,整个过程
- 将所有的 css 嵌入到上述经过初步处理后的 html 中
- 通过 fetch 拉取到上述 “style” 数组里面对应的 css
- 将拉取到的每一个 href 对应的 css 通过 <style> </style> 包裹起来且嵌入到 html 中 准确来说不是嵌入到 html 中。整个流程是这样:首先当解析 html 中的 stylesheet link 标签时,就会将这个标签注释起来 ,然后再通过 fetch 将此 href 对应的 css 获取到,然后再使用正则将这个被注释的标签替换成由 style 包裹 css 而成的标签,如此,所有的 css 全部都嵌入到了 html 中,并且由 style 包裹,因此全部生效。
如下的代码就是将所有的 stylesheet href 对应的 css 嵌入到 html 后的结果,同样本身是字符串,在这里为了清晰做了格式化。
<head>
<style>
/* https://https://zhoulujun.net/css/brands.css */
@font-face {
font-family: 'Font Awesome 5 Brands';
...
}
.fab {
font-family: 'Font Awesome 5 Brands';
font-weight: 400;
}
</style>
<style>
h1 { font-size: 40px; }
</style>
</head>
<body>
<h1>Zhang Pao Pao</h1>
<!-- script https://zhoulujun.net//js/brands.js replaced by import-html-entry -->
<!-- inline scripts replaced by import-html-entry -->
<!-- script http://localhost:7101/main.js replaced by import-html-entry -->
</body>下面是拉取 HTML 并处理的主要代码,整体的内容可到 import-html-entry 中查看。
importHTML源码解读
// 代码片段2,所属文件:src/index.js
export default function importHTML(url, opts = {}) {
// 1. 通过 fetch 获取到 url 对应的 html
return embedHTMLCache[url] || (embedHTMLCache[url] = fetch(url)
.then(html => {
// 2. 从返回的结果中解析出以下内容a.经过初步处理后的 html, b.由所有 "script" 组成的数组, c.由所有 "style" 组成的数组
const { template, scripts, entry, styles } = processTpl(getTemplate(html), assetPublicPath, postProcessTemplate);
// 3. 将所有的 css 嵌入到上述经过初步处理后的 html 中
return getEmbedHTML(template, styles, { fetch }).then(embedHTML => ({
template: embedHTML,
assetPublicPath,
getExternalScripts: () => getExternalScripts(scripts, fetch),
getExternalStyleSheets: () => getExternalStyleSheets(styles, fetch),
execScripts: (proxy, strictGlobal, execScriptsHooks = {}) => {
if (!scripts.length) {
return Promise.resolve();
}
return execScripts(entry, scripts, proxy, {
fetch,
strictGlobal,
beforeExec: execScriptsHooks.beforeExec,
afterExec: execScriptsHooks.afterExec,
});
},
}));
}));
}
}embedHTMLCache[url] || (embedHTMLCache[url] = fetch(url)这种使用缓存和给缓存赋值的方式,在日常开发中可以借鉴。
getEmbedHTML
getEmbedHTML实际上主要做了两件事:
- 一是获取processTpl中提到style资源链接对应的资源内容;
- 二是将这些内容拼装成style标签,然后将processTpl中的占位符替换掉。
function getEmbedHTML(template, styles, opts = {}) {
// 1. fetch "style" 数组里面对应的 css
return getExternalStyleSheets(styles, fetch)
.then(styleSheets => {
embedHTML = styles.reduce((html, styleSrc, i) => {
// 2. 将拉取到的每一个 href 对应的 css 通过 `<style> </style>` 包裹起来且嵌入到 html 中
html = html.replace(genLinkReplaceSymbol(styleSrc), `<style>/* ${styleSrc} */${styleSheets[i]}</style>`);
return html;
}, embedHTML);
});
}getExternalStyleSheets
export function getExternalStyleSheets(styles, fetch = defaultFetch) {
return Promise.all(styles.map(styleLink => {
if (isInlineCode(styleLink)) {
// if it is inline style
return getInlineCode(styleLink);
} else {
// external styles
return styleCache[styleLink] ||
(styleCache[styleLink] = fetch(styleLink).then(response => response.text()));
}
},
));
}execScripts
export function execScripts(entry, scripts, proxy = window, opts = {}) {
// 此处省略许多代码...
return getExternalScripts(scripts, fetch, error)// 和获取js资源链接对应的内容
.then(scriptsText => {
const geval = (scriptSrc, inlineScript) => {
// 此处省略许多代码...
// 这里主要是把js代码进行一定处理,然后拼装成一个自执行函数,然后用eval执行
// 这里最关键的是调用了getExecutableScript,绑定了window.proxy改变js代码中的this引用
};
function exec(scriptSrc, inlineScript, resolve) {
// 这里省略许多代码...
// 根据不同的条件,在不同的时机调用geval函数执行js代码,并将入口函数执行完暴露的含有微应用生命周期函数的对象返回
// 这里省略许多代码...
}
function schedule(i, resolvePromise) {
// 这里省略许多代码...
// 依次调用exec函数执行js资源对应的代码
}
return new Promise(resolve => schedule(0, success || resolve));
});
}processTpl
关于processTpl的代码,我不打算逐行进行分析,相反我会讲其中一个原本不应该是重要的点,那就是其中涉及到的正则表达式,这部分虽然看起来很基础,但实际上是理解函数processTpl的关键所在。我将在下面代码片段中注释上各个正则表达式可能匹配的内容,再整体描述一下主要逻辑,有了这些介绍,相信朋友们可以自己读懂该函数剩下的代码。
// 代码片段3,所属文件:src/process-tpl.js
/*
匹配整个script标签及其包含的内容,比如 <script>xxxxx</script>或<script xxx>xxxxx</script>
[\s\S] 匹配所有字符。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行
* 匹配前面的子表达式零次或多次
+ 匹配前面的子表达式一次或多次
正则表达式后面的全局标记 g 指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配。
表达式的结尾处的不区分大小写 i 标记指定不区分大小写。
*/
const ALL_SCRIPT_REGEX = /(<script[\s\S]*?>)[\s\S]*?<\/script>/gi;
/*
. 匹配除换行符 \n 之外的任何单字符
? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
圆括号会有一个副作用,使相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用。
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?!, ?=为正向预查,在任何开始匹配圆括
号内的正则表达式模式的位置来匹配搜索字符串,?!为负向预查,在任何开始不匹配该正则表达式模
式的位置来匹配搜索字符串。
举例:exp1(?!exp2):查找后面不是 exp2 的 exp1。
所以这里的真实含义是匹配script标签,但type不能是text/ng-template
*/
const SCRIPT_TAG_REGEX = /<(script)\s+((?!type=('|")text\/ng-template\3).)*?>.*?<\/\1>/is;
/*
* 匹配包含src属性的script标签
^ 匹配输入字符串的开始位置,但在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。
*/
const SCRIPT_SRC_REGEX = /.*\ssrc=('|")?([^>'"\s]+)/;
// 匹配含 type 属性的标签
const SCRIPT_TYPE_REGEX = /.*\stype=('|")?([^>'"\s]+)/;
// 匹配含entry属性的标签//
const SCRIPT_ENTRY_REGEX = /.*\sentry\s*.*/;
// 匹配含 async属性的标签
const SCRIPT_ASYNC_REGEX = /.*\sasync\s*.*/;
// 匹配向后兼容的nomodule标记
const SCRIPT_NO_MODULE_REGEX = /.*\snomodule\s*.*/;
// 匹配含type=module的标签
const SCRIPT_MODULE_REGEX = /.*\stype=('|")?module('|")?\s*.*/;
// 匹配link标签
const LINK_TAG_REGEX = /<(link)\s+.*?>/isg;
// 匹配含 rel=preload或rel=prefetch 的标签, 小提示:rel用于规定当前文档与被了链接文档之间的关系,比如rel=“icon”等
const LINK_PRELOAD_OR_PREFETCH_REGEX = /\srel=('|")?(preload|prefetch)\1/;
// 匹配含href属性的标签
const LINK_HREF_REGEX = /.*\shref=('|")?([^>'"\s]+)/;
// 匹配含as=font的标签
const LINK_AS_FONT = /.*\sas=('|")?font\1.*/;
// 匹配style标签
const STYLE_TAG_REGEX = /<style[^>]*>[\s\S]*?<\/style>/gi;
// 匹配rel=stylesheet的标签
const STYLE_TYPE_REGEX = /\s+rel=('|")?stylesheet\1.*/;
// 匹配含href属性的标签
const STYLE_HREF_REGEX = /.*\shref=('|")?([^>'"\s]+)/;
// 匹配注释
const HTML_COMMENT_REGEX = /<!--([\s\S]*?)-->/g;
// 匹配含ignore属性的 link标签
const LINK_IGNORE_REGEX = /<link(\s+|\s+.+\s+)ignore(\s*|\s+.*|=.*)>/is;
// 匹配含ignore属性的style标签
const STYLE_IGNORE_REGEX = /<style(\s+|\s+.+\s+)ignore(\s*|\s+.*|=.*)>/is;
// 匹配含ignore属性的script标签
const SCRIPT_IGNORE_REGEX = /<script(\s+|\s+.+\s+)ignore(\s*|\s+.*|=.*)>/is;了解了这些正则匹配规则,为我们接下来的分析做好了准备,由于源码中processTpl内容比较丰富,为了方便理解,接下来我会将源码中实际的代码替换成我的注释。
// 代码片段4,所属文件:src/process-tpl.js
export default function processTpl(tpl, baseURI, postProcessTemplate) {
// 这里省略许多代码...
let styles = [];
const template = tpl
.replace(HTML_COMMENT_REGEX, '') // 删掉注释
.replace(LINK_TAG_REGEX, match => {
// 这里省略许多代码...
// 如果link标签中有ignore属性,则替换成占位符`<!-- ignore asset ${ href || 'file'} replaced by import-html-entry -->`
// 如果link标签中没有ignore属性,将标签替换成占位符`<!-- ${preloadOrPrefetch ? 'prefetch/preload' : ''} link ${linkHref} replaced by import-html-entry -->`
})
.replace(STYLE_TAG_REGEX, match => {
// 这里省略许多代码...
// 如果style标签有ignore属性,则将标签替换成占位符`<!-- ignore asset style file replaced by import-html-entry -->`
})
.replace(ALL_SCRIPT_REGEX, (match, scriptTag) => {
// 这里省略许多代码...
// 这里虽然有很多代码,但可以概括为匹配正则表达式,替换成相应的占位符
});
// 这里省略一些代码...
let tplResult = {
template,
scripts,
styles,
entry: entry || scripts[scripts.length - 1],
};
// 这里省略一些代码...
return tplResult;
}从上面代码中可以看出,在将相应的标签被替换成占位符后,最终返回了一个tplResult对象。该对象中的scripts、styles都是是数组,保存的是一个个链接,也就是被占位符替换的标签原有的href对应的值。
拉取 JS 并支持执行
通过 1.2.b 可以获取到 url 文件下对应的由所有 “script” 组成的数组 ,其中包含两部分内容:
- 页级的 script
- 外联的 script 对应的 src
获取到所有的 script code
- 如果是页级 script,直接返回即可
- 如果不是,那么通过 fetch 获取
export function getExternalScripts(scripts, fetch) {
// 根据 script src 的 url fetch js
const fetchScript = scriptUrl => fetch(scriptUrl).then(response => (...)));
return Promise.all(scripts.map(script => {
// 如果是页级 script ,直接返回
if (isInlineCode(script)) {
return getInlineCode(script);
} else {
// 如果不是,那么通过 fetch 获取
return fetchScript(script);
}
},
));
}将获取到的 js code 处理成 IIFE 字符串,并且为后续实现应用与应用之间隔离做处理
其实这里描述成 “处理成 IIFE 字符串” 不是非常正确,因为 IIFE 指的是立即执行函数,是一个函数,而这里只是把 js code 包裹在 (function(xxx){ code })(xxx) 中,但的确没有想到更好的描述方式,所以暂时这样描述吧!!
function getExecutableScript(scriptSrc, scriptText, proxy, strictGlobal) {
const sourceUrl = isInlineCode(scriptSrc) ? '' : `//# sourceURL=${scriptSrc}\n`;
// 通过这种方式获取全局 window,具体原因可参考源码在这里的注释
const globalWindow = (0, eval)('window');
// 如果这里的 proxy 为 window 沙箱,那么就可以实现应用隔离
globalWindow.proxy = proxy;
// 利用 IIFE 将 code 里会使用到的 window, self, globalThis 传递进去,为后续的应用与应用之间隔离做处理
return strictGlobal
? `;(function(window, self, globalThis){with(window){;${scriptText}\n${sourceUrl}}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`
: `;(function(window, self, globalThis){;${scriptText}\n${sourceUrl}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`;
}这里的代码非常的有意思(但实际开发千万不要用,感觉用了要挨锤)
- (0, eval)('window') 获取全局 window
- (function(window, self, globalThis){...}.bind(window.proxy))(window.proxy,window.proxy,window.proxy,), 这里首先实现了 window, self, globalThis 的传递,同时还 bind 的 code 的 this
- strictGlobal 为真时的 with 语法,可实现拦截作用域
示例中页级 script 得到的 IIFE 字符串(同样本身是字符串,在这里为了清晰做了格式化)
;(
function(window, self, globalThis){
;console.log('this is script in-line');
}
).bind(window.proxy)
(window.proxy, window.proxy, window.proxy);当然,外联的 script 得到的也是同样 IIFE 字符串,只是其中内容不同。
执行上述的 IIFE 字符串,实际上就是执行所有的 js code
export function evalCode(scriptSrc, code) {
const key = scriptSrc;
if (!evalCache[key]) {
// 将 IIFE 字符串包裹在 function 中
const functionWrappedCode = `window.__TEMP_EVAL_FUNC__ = function(){${code}}`;
// window.__TEMP_EVAL_FUNC__ = function(){...} eval 将上面的字符串转换成代码
(0, eval)(functionWrappedCode);
evalCache[key] = window.__TEMP_EVAL_FUNC__;
delete window.__TEMP_EVAL_FUNC__;
}
const evalFunc = evalCache[key];
// 执行上面得到的匿名函数,其中内容为第二点的 IIFE ,因此也就是执行了 js code
// 这里是真正的执行
evalFunc.call(window);
}CSS 沙箱分析
对于 CSS 沙箱,常见的实现有三种模式,我们称之为 Dynamic Style 模式 , ShadowDOM 模式与Scoped 模式。以下,对每种模式做一个简单的分析。
- Dynamic Style 模式: 该模式的主要原理是通过 Fetch 加载 entry 后,动态把 entry 中访问到的 Link,style 打上标签并加载到主应用中,在卸载时移除所有的标签。 显而易见,该模式无法支持单页多应用,甚至无法隔离主子应用的样式。
- ShadowDOM 模式:该模式的主要原理是通过对于所有被挂载的应用 DOM,该模式会把根 DOM 放入到一个 ShadowDOM 中,通过 ShadowDOM 自身的能力来做到样式隔离。 该模式下,所有基于 window 的点击代理将会失效。比如 react16 的所有点击事件都需要特殊处理。
- Scoped 模式:该模式会对所有内联样式表在运行时添加一个前缀。 但对于 Link 引入的样式,这里的模式无法直接处理,需要进行内联转化。
由此可见,与 JS 沙箱相似,CSS 沙箱的常见做法中每个模式都会有一部分问题无法很好的解决,那是否我们就无法得到一个安全隔离的运行环境了呢? 我们是否能够限制不可控的范围呢?
参考文章:
揭开 import-html-entry 面纱 https://blog.csdn.net/qq_41800366/article/details/122093720
转载本站文章《微前端学习笔记(5):从import-html-entry发微DOM/JS/CSS隔离》, 请注明出处:https://www.zhoulujun.cn/html/webfront/engineer/Architecture/9066.html
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号