flink之算子链
原创

前言:
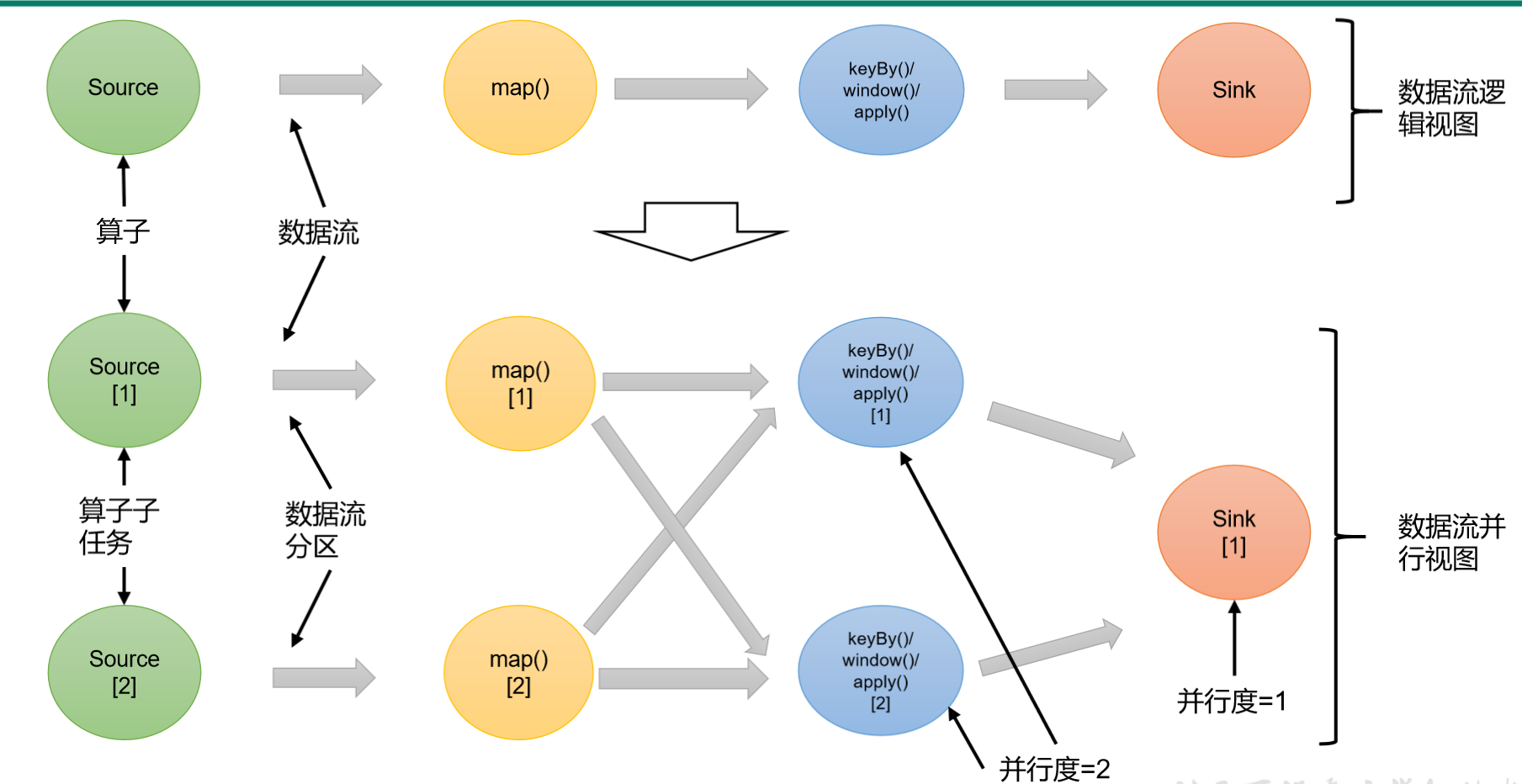
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
一、算子链形式
(1)一对一(One-to-one,forwarding)
相当于一条队列,上游传输的数据在队列里进行先进先出,后进后出,不存在数据乱序延迟问题。
这种模式下,数据流维护着分区以及元素的顺序。比如source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间传输不需要重新分区,也不需要调整数据的顺序。这就意味着map 算子的子任务,看到的元素个数和顺序跟source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于Spark中的窄依赖。
(2)重分区(Redistributing)
相当于挤公交车,人从不同方向往前门上车点靠近,这个时候是乱序。
在这种模式下,数据流的分区会发生改变。比如的map和keyBy/window算子之间,以及keyBy/window算子和Sink算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
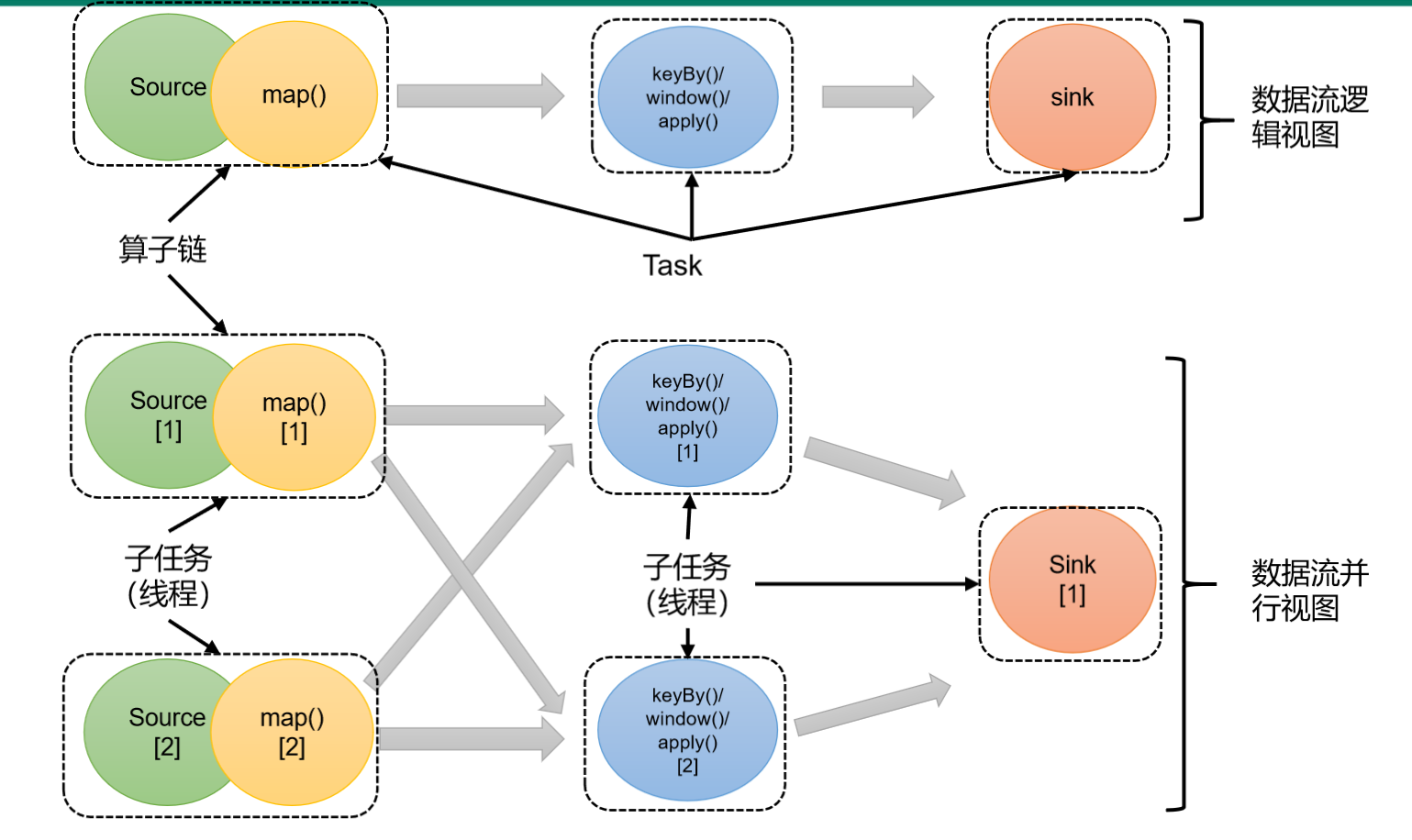
二、算子链的合并
算子合并的概念:
在Flink中,并行度相同(条件一)的 一对一(条件二)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
算子链的合并的优点:
将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
简单点说就是提升了数据的处理效率。
如图的source和map算子之间的数据传输的形式就是一对一形式并且是并行度相同,此时source和map的算子之间算子操作就可以合并成为一个算子链,形成一个整体的Task,被同一个Taskslot执行,从七个线程缩减到五个线程(taskSlot)。
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置(了解,不推荐使用):
// 从map算子后禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号