论文周报[0610-0616] | 推荐系统领域最新研究进展(15篇)

论文周报[0610-0616] | 推荐系统领域最新研究进展(15篇)

张小磊
发布于 2024-06-18 16:14:55
发布于 2024-06-18 16:14:55
嘿,记得给“机器学习与推荐算法”添加星标
本文精选了上周(0610-0616)最新发布的15篇推荐系统相关论文,主要研究方向包括基于语言模型推荐的偏好优化、基于蒸馏的多样性推荐、图协同过滤推荐、为序列推荐设计自定义轻量化、利用分布外词汇提高大模型推荐能力、多媒体推荐、图提示微调用于流式推荐、图社交推荐、缓解视频推荐中的时长偏差、面向推荐的俄罗斯套娃表示学习、基于基础模型的联邦推荐综述、基于弹性资源分配的推荐模型、两阶段大模型序列推荐等。
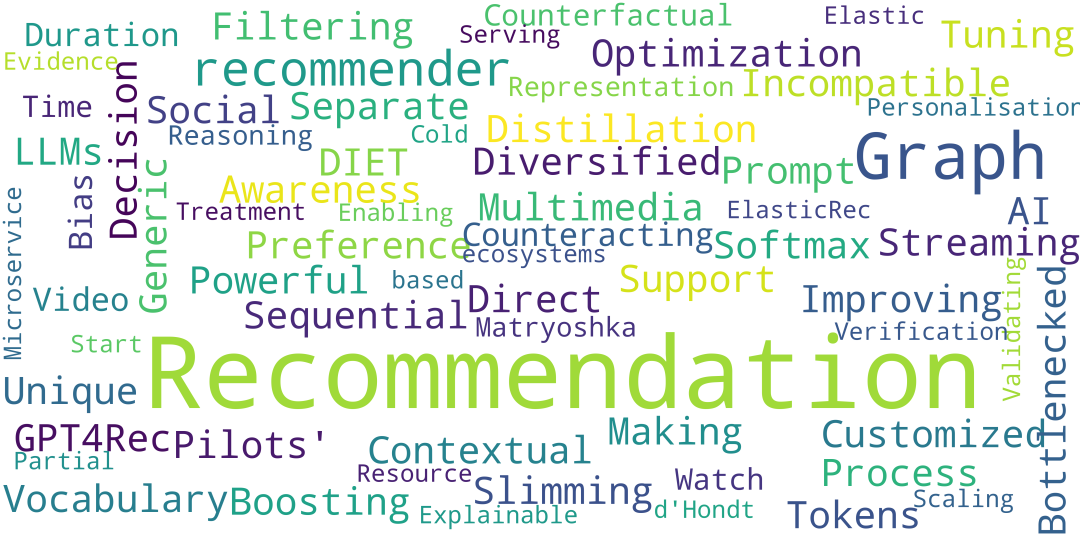
1. On Softmax Direct Preference Optimization for Recommendation
2. Contextual Distillation Model for Diversified Recommendation
3. Beyond Recommendations: From Backward to Forward AI Support of Pilots' Decision-Making Process
4. How Powerful is Graph Filtering for Recommendation
5. DIET: Customized Slimming for Incompatible Networks in Sequential Recommendation
6. Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens
7. Boosting Multimedia Recommendation via Separate Generic and Unique Awareness
8. GPT4Rec: Graph Prompt Tuning for Streaming Recommendation
9. Graph Bottlenecked Social Recommendation
10. Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time
11. Matryoshka Representation Learning for Recommendation
12. Graph Reasoning for Explainable Cold Start Recommendation
13. Navigating the Future of Federated Recommendation Systems with Foundation Models
14. ElasticRec: A Microservice-based Model Serving Architecture Enabling Elastic Resource Scaling for Recommendation Models
15. A Practice-Friendly Two-Stage LLM-Enhanced Paradigm in Sequential Recommendation
1. On Softmax Direct Preference Optimization for Recommendation
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
https://arxiv.org/abs/2406.09215
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO
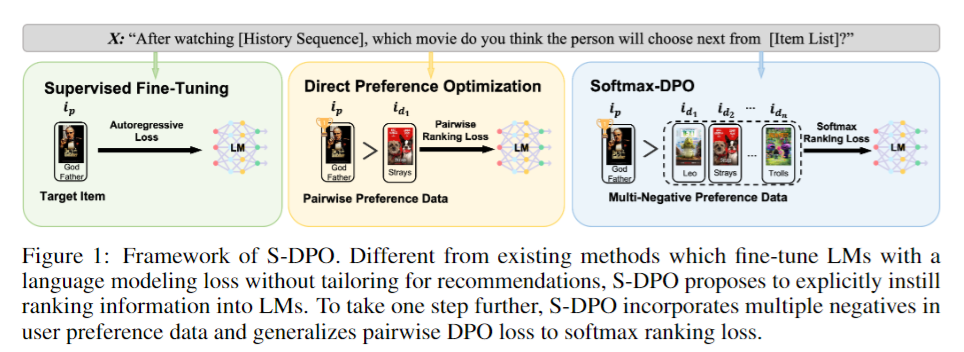
2. Contextual Distillation Model for Diversified Recommendation
Fan Li, Xu Si, Shisong Tang, Dingmin Wang, Kunyan Han, Bing Han, Guorui Zhou, Yang Song, Hechang Chen
https://arxiv.org/abs/2406.09021
The diversity of recommendation is equally crucial as accuracy in improving user experience. Existing studies, e.g., Determinantal Point Process (DPP) and Maximal Marginal Relevance (MMR), employ a greedy paradigm to iteratively select items that optimize both accuracy and diversity. However, prior methods typically exhibit quadratic complexity, limiting their applications to the re-ranking stage and are not applicable to other recommendation stages with a larger pool of candidate items, such as the pre-ranking and ranking stages. In this paper, we propose Contextual Distillation Model (CDM), an efficient recommendation model that addresses diversification, suitable for the deployment in all stages of industrial recommendation pipelines. Specifically, CDM utilizes the candidate items in the same user request as context to enhance the diversification of the results. We propose a contrastive context encoder that employs attention mechanisms to model both positive and negative contexts. For the training of CDM, we compare each target item with its context embedding and utilize the knowledge distillation framework to learn the win probability of each target item under the MMR algorithm, where the teacher is derived from MMR outputs. During inference, ranking is performed through a linear combination of the recommendation and student model scores, ensuring both diversity and efficiency. We perform offline evaluations on two industrial datasets and conduct online A/B test of CDM on the short-video platform KuaiShou. The considerable enhancements observed in both recommendation quality and diversity, as shown by metrics, provide strong superiority for the effectiveness of CDM.
3. Beyond Recommendations: From Backward to Forward AI Support of Pilots' Decision-Making Process
Zelun Tony Zhang, Sebastian S. Feger, Lucas Dullenkopf, Rulu Liao, Lukas Süsslin, Yuanting Liu, Andreas Butz
https://arxiv.org/abs/2406.08959
AI is anticipated to enhance human decision-making in high-stakes domains like aviation, but adoption is often hindered by challenges such as inappropriate reliance and poor alignment with users' decision-making. Recent research suggests that a core underlying issue is the recommendation-centric design of many AI systems, i.e., they give end-to-end recommendations and ignore the rest of the decision-making process. Alternative support paradigms are rare, and it remains unclear how the few that do exist compare to recommendation-centric support. In this work, we aimed to empirically compare recommendation-centric support to an alternative paradigm, continuous support, in the context of diversions in aviation. We conducted a mixed-methods study with 32 professional pilots in a realistic setting. To ensure the quality of our study scenarios, we conducted a focus group with four additional pilots prior to the study. We found that continuous support can support pilots' decision-making in a forward direction, allowing them to think more beyond the limits of the system and make faster decisions when combined with recommendations, though the forward support can be disrupted. Participants' statements further suggest a shift in design goal away from providing recommendations, to supporting quick information gathering. Our results show ways to design more helpful and effective AI decision support that goes beyond end-to-end recommendations.
4. How Powerful is Graph Filtering for Recommendation
Shaowen Peng, Xin Liu, Kazunari Sugiyama, Tsunenori Mine
https://arxiv.org/abs/2406.08827
It has been shown that the effectiveness of graph convolutional network (GCN) for recommendation is attributed to the spectral graph filtering. Most GCN-based methods consist of a graph filter or followed by a low-rank mapping optimized based on supervised training. However, we show two limitations suppressing the power of graph filtering: (1) Lack of generality. Due to the varied noise distribution, graph filters fail to denoise sparse data where noise is scattered across all frequencies, while supervised training results in worse performance on dense data where noise is concentrated in middle frequencies that can be removed by graph filters without training. (2) Lack of expressive power. We theoretically show that linear GCN (LGCN) that is effective on collaborative filtering (CF) cannot generate arbitrary embeddings, implying the possibility that optimal data representation might be unreachable.
To tackle the first limitation, we show close relation between noise distribution and the sharpness of spectrum where a sharper spectral distribution is more desirable causing data noise to be separable from important features without training. Based on this observation, we propose a generalized graph normalization G^2N to adjust the sharpness of spectral distribution in order to redistribute data noise to assure that it can be removed by graph filtering without training. As for the second limitation, we propose an individualized graph filter (IGF) adapting to the different confidence levels of the user preference that interactions can reflect, which is proved to be able to generate arbitrary embeddings. By simplifying LGCN, we further propose a simplified graph filtering (SGFCF) which only requires the top-K singular values for recommendation. Finally, experimental results on four datasets with different density settings demonstrate the effectiveness and efficiency of our proposed methods. https://github.com/tanatosuu/sgfcf
5. DIET: Customized Slimming for Incompatible Networks in Sequential Recommendation
Kairui Fu, Shengyu Zhang, Zheqi Lv, Jingyuan Chen, Jiwei Li
https://arxiv.org/abs/2406.08804
Due to the continuously improving capabilities of mobile edges, recommender systems start to deploy models on edges to alleviate network congestion caused by frequent mobile requests. Several studies have leveraged the proximity of edge-side to real-time data, fine-tuning them to create edge-specific models. Despite their significant progress, these methods require substantial on-edge computational resources and frequent network transfers to keep the model up to date. The former may disrupt other processes on the edge to acquire computational resources, while the latter consumes network bandwidth, leading to a decrease in user satisfaction. In response to these challenges, we propose a customizeD slImming framework for incompatiblE neTworks(DIET). DIET deploys the same generic backbone (potentially incompatible for a specific edge) to all devices. To minimize frequent bandwidth usage and storage consumption in personalization, DIET tailors specific subnets for each edge based on its past interactions, learning to generate slimming subnets(diets) within incompatible networks for efficient transfer. It also takes the inter-layer relationships into account, empirically reducing inference time while obtaining more suitable diets. We further explore the repeated modules within networks and propose a more storage-efficient framework, DIETING, which utilizes a single layer of parameters to represent the entire network, achieving comparably excellent performance. The experiments across four state-of-the-art datasets and two widely used models demonstrate the superior accuracy in recommendation and efficiency in transmission and storage of our framework.
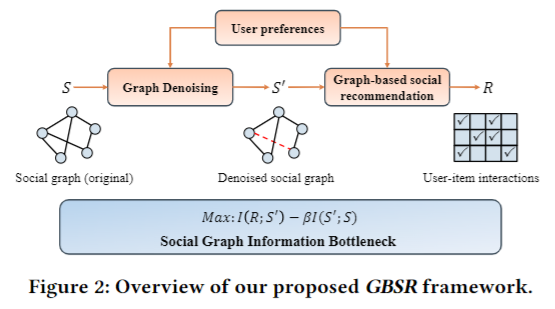
6. Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens
Ting-Ji Huang, Jia-Qi Yang, Chunxu Shen, Kai-Qi Liu, De-Chuan Zhan, Han-Jia Ye
https://arxiv.org/abs/2406.08477
Characterizing users and items through vector representations is crucial for various tasks in recommender systems. Recent approaches attempt to apply Large Language Models (LLMs) in recommendation through a question and answer format, where real users and items (e.g., Item No.2024) are represented with in-vocabulary tokens (e.g., "item", "20", "24"). However, since LLMs are typically pretrained on natural language tasks, these in-vocabulary tokens lack the expressive power for distinctive users and items, thereby weakening the recommendation ability even after fine-tuning on recommendation tasks. In this paper, we explore how to effectively tokenize users and items in LLM-based recommender systems. We emphasize the role of out-of-vocabulary (OOV) tokens in addition to the in-vocabulary ones and claim the memorization of OOV tokens that capture correlations of users/items as well as diversity of OOV tokens. By clustering the learned representations from historical user-item interactions, we make the representations of user/item combinations share the same OOV tokens if they have similar properties. Furthermore, integrating these OOV tokens into the LLM's vocabulary allows for better distinction between users and items and enhanced capture of user-item relationships during fine-tuning on downstream tasks. Our proposed framework outperforms existing state-of-the-art methods across various downstream recommendation tasks.
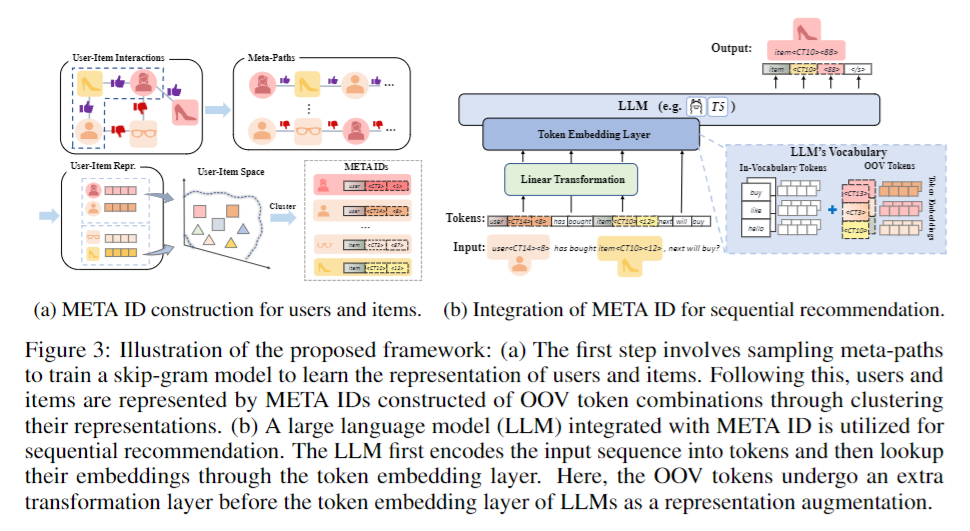
7. Boosting Multimedia Recommendation via Separate Generic and Unique Awareness
Zhuangzhuang He, Zihan Wang, Yonghui Yang, Haoyue Bai, Le Wu
https://arxiv.org/abs/2406.08270
Multimedia recommendation, which incorporates various modalities (e.g., images, texts, etc.) into user or item representation to improve recommendation quality, has received widespread attention. Recent methods mainly focus on cross-modal alignment with self-supervised learning to obtain higher quality representation. Despite remarkable performance, we argue that there is still a limitation: completely aligning representation undermines modality-unique information. We consider that cross-modal alignment is right, but it should not be the entirety, as different modalities contain generic information between them, and each modality also contains unique information. Simply aligning each modality may ignore modality-unique features, thus degrading the performance of multimedia recommendation.
To tackle the above limitation, we propose a Separate Alignment aNd Distancing framework (SAND) for multimedia recommendation, which concurrently learns both modal-unique and -generic representation to achieve more comprehensive items representation. First, we split each modal feature into generic and unique part. Then, in the alignment module, for better integration of semantic information between different modalities , we design a SoloSimLoss to align generic modalities. Furthermore, in the distancing module, we aim to distance the unique modalities from the modal-generic so that each modality retains its unique and complementary information. In the light of the flexibility of our framework, we give two technical solutions, the more capable mutual information minimization and the simple negative l2 distance. Finally, extensive experimental results on three popular datasets demonstrate the effectiveness and generalization of our proposed framework.
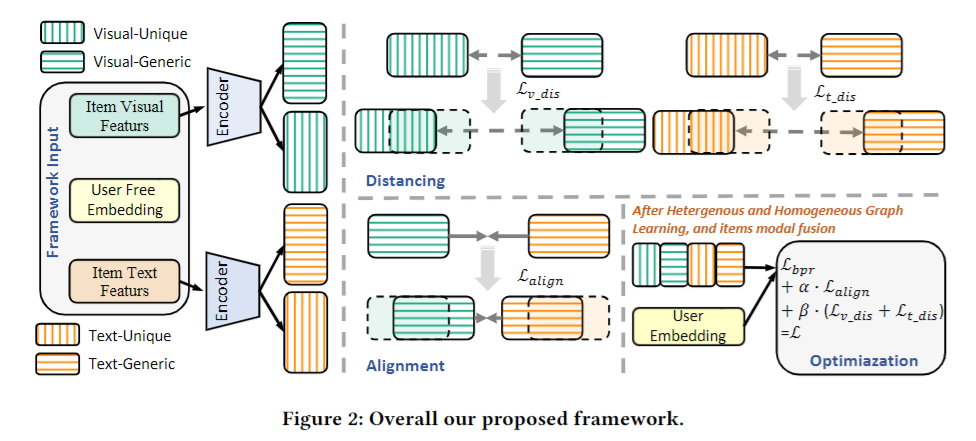
8. GPT4Rec: Graph Prompt Tuning for Streaming Recommendation
Peiyan Zhang, Yuchen Yan, Xi Zhang, Liying Kang, Chaozhuo Li, Feiran Huang, Senzhang Wang, Sunghun Kim
https://arxiv.org/abs/2406.08229
In the realm of personalized recommender systems, the challenge of adapting to evolving user preferences and the continuous influx of new users and items is paramount. Conventional models, typically reliant on a static training-test approach, struggle to keep pace with these dynamic demands. Streaming recommendation, particularly through continual graph learning, has emerged as a novel solution. However, existing methods in this area either rely on historical data replay, which is increasingly impractical due to stringent data privacy regulations; or are inability to effectively address the over-stability issue; or depend on model-isolation and expansion strategies. To tackle these difficulties, we present GPT4Rec, a Graph Prompt Tuning method for streaming Recommendation. Given the evolving user-item interaction graph, GPT4Rec first disentangles the graph patterns into multiple views. After isolating specific interaction patterns and relationships in different views, GPT4Rec utilizes lightweight graph prompts to efficiently guide the model across varying interaction patterns within the user-item graph. Firstly, node-level prompts are employed to instruct the model to adapt to changes in the attributes or properties of individual nodes within the graph. Secondly, structure-level prompts guide the model in adapting to broader patterns of connectivity and relationships within the graph. Finally, view-level prompts are innovatively designed to facilitate the aggregation of information from multiple disentangled views. These prompt designs allow GPT4Rec to synthesize a comprehensive understanding of the graph, ensuring that all vital aspects of the user-item interactions are considered and effectively integrated. Experiments on four diverse real-world datasets demonstrate the effectiveness and efficiency of our proposal.
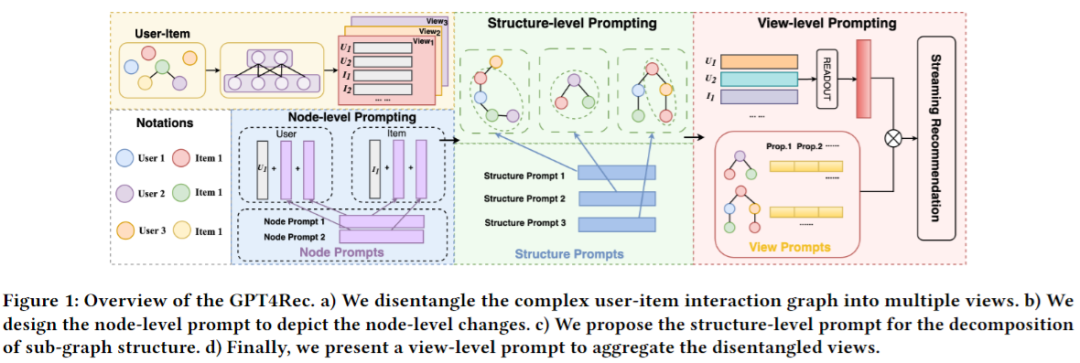
9. Graph Bottlenecked Social Recommendation
Yonghui Yang, Le Wu, Zihan Wang, Zhuangzhuang He, Richang Hong, Meng Wang
https://arxiv.org/abs/2406.08214
With the emergence of social networks, social recommendation has become an essential technique for personalized services. Recently, graph-based social recommendations have shown promising results by capturing the high-order social influence. Most empirical studies of graph-based social recommendations directly take the observed social networks into formulation, and produce user preferences based on social homogeneity. Despite the effectiveness, we argue that social networks in the real-world are inevitably noisy~(existing redundant social relations), which may obstruct precise user preference characterization. Nevertheless, identifying and removing redundant social relations is challenging due to a lack of labels. In this paper, we focus on learning the denoised social structure to facilitate recommendation tasks from an information bottleneck perspective. Specifically, we propose a novel Graph Bottlenecked Social Recommendation (GBSR) framework to tackle the social noise issue.GBSR is a model-agnostic social denoising framework, that aims to maximize the mutual information between the denoised social graph and recommendation labels, meanwhile minimizing it between the denoised social graph and the original one. This enables GBSR to learn the minimal yet sufficient social structure, effectively reducing redundant social relations and enhancing social recommendations. Technically, GBSR consists of two elaborate components, preference-guided social graph refinement, and HSIC-based bottleneck learning. Extensive experimental results demonstrate the superiority of the proposed GBSR, including high performances and good generality combined with various backbones. Our code is available at: https://github.com/yimutianyang/KDD24-GBSR
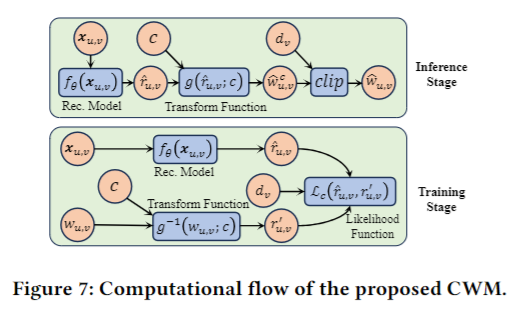
10. Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time
Haiyuan Zhao, Guohao Cai, Jieming Zhu, Zhenhua Dong, Jun Xu, Ji-Rong Wen
https://arxiv.org/abs/2406.07932
In video recommendation, an ongoing effort is to satisfy users' personalized information needs by leveraging their logged watch time. However, watch time prediction suffers from duration bias, hindering its ability to reflect users' interests accurately. Existing label-correction approaches attempt to uncover user interests through grouping and normalizing observed watch time according to video duration. Although effective to some extent, we found that these approaches regard completely played records (i.e., a user watches the entire video) as equally high interest, which deviates from what we observed on real datasets: users have varied explicit feedback proportion when completely playing videos. In this paper, we introduce the counterfactual watch time(CWT), the potential watch time a user would spend on the video if its duration is sufficiently long. Analysis shows that the duration bias is caused by the truncation of CWT due to the video duration limitation, which usually occurs on those completely played records. Besides, a Counterfactual Watch Model (CWM) is proposed, revealing that CWT equals the time users get the maximum benefit from video recommender systems. Moreover, a cost-based transform function is defined to transform the CWT into the estimation of user interest, and the model can be learned by optimizing a counterfactual likelihood function defined over observed user watch times. Extensive experiments on three real video recommendation datasets and online A/B testing demonstrated that CWM effectively enhanced video recommendation accuracy and counteracted the duration bias.
11. Matryoshka Representation Learning for Recommendation
Riwei Lai, Li Chen, Weixin Chen, Rui Chen
https://arxiv.org/abs/2406.07432
Representation learning is essential for deep-neural-network-based recommender systems to capture user preferences and item features within fixed-dimensional user and item vectors. Unlike existing representation learning methods that either treat each user preference and item feature uniformly or categorize them into discrete clusters, we argue that in the real world, user preferences and item features are naturally expressed and organized in a hierarchical manner, leading to a new direction for representation learning. In this paper, we introduce a novel matryoshka representation learning method for recommendation (MRL4Rec), by which we restructure user and item vectors into matryoshka representations with incrementally dimensional and overlapping vector spaces to explicitly represent user preferences and item features at different hierarchical levels. We theoretically establish that constructing training triplets specific to each level is pivotal in guaranteeing accurate matryoshka representation learning. Subsequently, we propose the matryoshka negative sampling mechanism to construct training triplets, which further ensures the effectiveness of the matryoshka representation learning in capturing hierarchical user preferences and item features. The experiments demonstrate that MRL4Rec can consistently and substantially outperform a number of state-of-the-art competitors on several real-life datasets. Our code is publicly available at https://github.com/Riwei-HEU/MRL
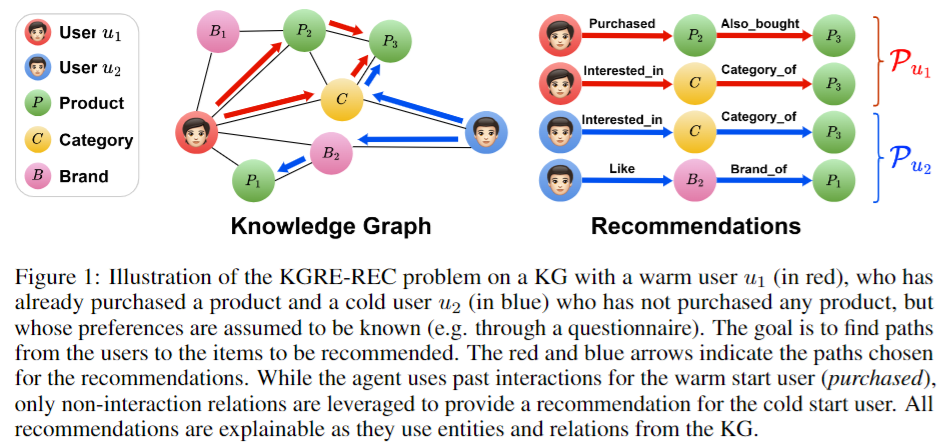
12. Graph Reasoning for Explainable Cold Start Recommendation
Jibril Frej, Marta Knezevic, Tanja Kaser
https://arxiv.org/abs/2406.07420
The cold start problem, where new users or items have no interaction history, remains a critical challenge in recommender systems (RS). A common solution involves using Knowledge Graphs (KG) to train entity embeddings or Graph Neural Networks (GNNs). Since KGs incorporate auxiliary data and not just user/item interactions, these methods can make relevant recommendations for cold users or items. Graph Reasoning (GR) methods, however, find paths from users to items to recommend using relations in the KG and, in the context of RS, have been used for interpretability. In this study, we propose GRECS: a framework for adapting GR to cold start recommendations. By utilizing explicit paths starting for users rather than relying only on entity embeddings, GRECS can find items corresponding to users' preferences by navigating the graph, even when limited information about users is available. Our experiments show that GRECS mitigates the cold start problem and outperforms competitive baselines across 5 standard datasets while being explainable. This study highlights the potential of GR for developing explainable recommender systems better suited for managing cold users and items. https://anonymous.4open.science/r/cold_rec-B765
13. Navigating the Future of Federated Recommendation Systems with Foundation Models
Zhiwei Li, Guodong Long
https://arxiv.org/abs/2406.00004
In recent years, the integration of federated learning (FL) and recommendation systems (RS), known as Federated Recommendation Systems (FRS), has attracted attention for preserving user privacy by keeping private data on client devices. However, FRS faces inherent limitations such as data heterogeneity and scarcity, due to the privacy requirements of FL and the typical data sparsity issues of RSs. Models like ChatGPT are empowered by the concept of transfer learning and self-supervised learning, so they can be easily applied to the downstream tasks after fine-tuning or prompting. These models, so-called Foundation Models (FM), fouce on understanding the human's intent and perform following their designed roles in the specific tasks, which are widely recognized for producing high-quality content in the image and language domains. Thus, the achievements of FMs inspire the design of FRS and suggest a promising research direction: integrating foundation models to address the above limitations. In this study, we conduct a comprehensive review of FRSs with FMs. Specifically, we: 1) summarise the common approaches of current FRSs and FMs; 2) review the challenges posed by FRSs and FMs; 3) discuss potential future research directions; and 4) introduce some common benchmarks and evaluation metrics in the FRS field. We hope that this position paper provides the necessary background and guidance to explore this interesting and emerging topic.
14. ElasticRec: A Microservice-based Model Serving Architecture Enabling Elastic Resource Scaling for Recommendation Models
Yujeong Choi, Jiin Kim, Minsoo Rhu
https://arxiv.org/abs/2406.06955
With the increasing popularity of recommendation systems (RecSys), the demand for compute resources in datacenters has surged. However, the model-wise resource allocation employed in current RecSys model serving architectures falls short in effectively utilizing resources, leading to sub-optimal total cost of ownership. We propose ElasticRec, a model serving architecture for RecSys providing resource elasticity and high memory efficiency. ElasticRec is based on a microservice-based software architecture for fine-grained resource allocation, tailored to the heterogeneous resource demands of RecSys. Additionally, ElasticRec achieves high memory efficiency via our utility-based resource allocation. Overall, ElasticRec achieves an average 3.3x reduction in memory allocation size and 8.1x increase in memory utility, resulting in an average 1.6x reduction in deployment cost compared to state-of-the-art RecSys inference serving system.
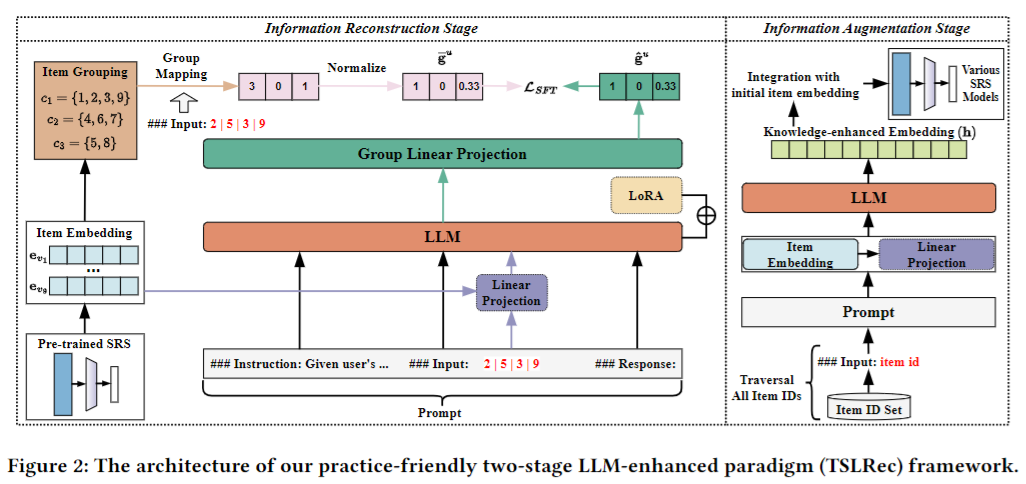
15. A Practice-Friendly Two-Stage LLM-Enhanced Paradigm in Sequential Recommendation
Dugang Liu, Shenxian Xian, Xiaolin Lin, Xiaolian Zhang, Hong Zhu, Yuan Fang, Zhen Chen, Zhong Ming
https://arxiv.org/abs/2406.00333
The training paradigm integrating large language models (LLM) is gradually reshaping sequential recommender systems (SRS) and has shown promising results. However, most existing LLM-enhanced methods rely on rich textual information on the item side and instance-level supervised fine-tuning (SFT) to inject collaborative information into LLM, which is inefficient and limited in many applications. To alleviate these problems, this paper proposes a novel practice-friendly two-stage LLM-enhanced paradigm (TSLRec) for SRS. Specifically, in the information reconstruction stage, we design a new user-level SFT task for collaborative information injection with the assistance of a pre-trained SRS model, which is more efficient and compatible with limited text information. We aim to let LLM try to infer the latent category of each item and reconstruct the corresponding user's preference distribution for all categories from the user's interaction sequence. In the information augmentation stage, we feed each item into LLM to obtain a set of enhanced embeddings that combine collaborative information and LLM inference capabilities. These embeddings can then be used to help train various future SRS models. Finally, we verify the effectiveness and efficiency of our TSLRec on three SRS benchmark datasets.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号