AI办公自动化:用通义千问Qwen-Long批量总结PDF长文档内容

AI办公自动化:用通义千问Qwen-Long批量总结PDF长文档内容

AIGC部落
发布于 2024-06-24 19:28:00
发布于 2024-06-24 19:28:00
Qwen-Long是在通义千问针对超长上下文处理场景的大语言模型,支持中文、英文等不同语言输入,支持最长1000万tokens(约1500万字或1.5万页文档)的超长上下文对话。配合同步上线的文档服务,可支持word、pdf、markdown、epub、mobi等多种文档格式的解析和对话。借助Qwen-Long可以批量总结长文档。
而且费用也很便宜:
模型调用-输入0.0005元/text_token(千个)
模型调用-输出0.002元/text_token(千个)
现在申请API还有免费额度:3600万tokens,到期时间1个月;
在deepseek中输入提示词:
你是一个开发AI大模型应用的Python编程专家,要完成批量总结PDF文档内容的Python脚本:
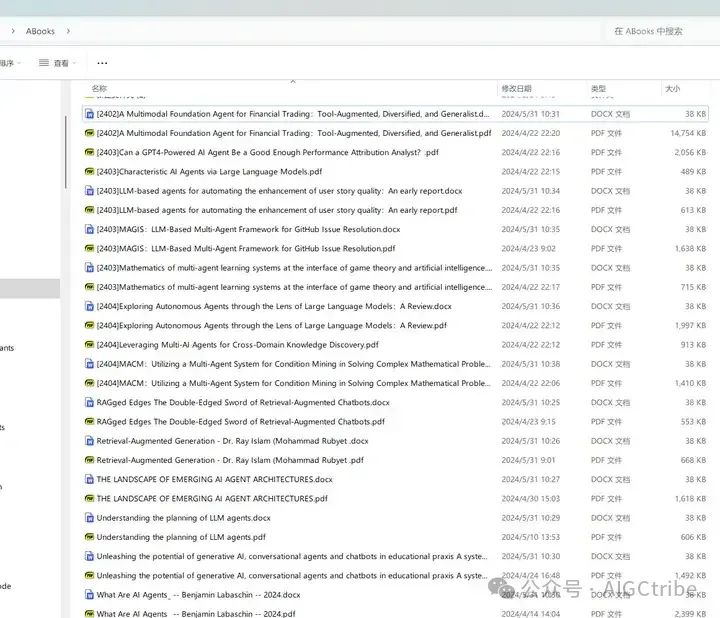
打开文件夹:"D:\ABooks"
逐一读取文件夹里面的PDF文件的文件名;
调用通义千问Qwen-Long的API上传PDF文件;
发送提示词:“总结这本书每个章节的内容,用中文输出”,获取返回结果,保存在docx格式的word文档中,文件名使用PDF文件的文件名,文档保存到文件夹"D:\ABooks"下;
文档保存完后,在通义千问Qwen-Long中删除这个PDF文件;
然后读取下一个PDF文件,上传,总结,删除,直到文件夹中全部PDF文件都总结完成。
注意:
每一步都要输出相关信息到屏幕上
如果PDF文本长度或者总结返回的文本长度超过限制,那就进行拆分,然后组合在一起;
如果某个PDF文件读取或者内容抽取等发生错误,就跳过,继续下一个;
通义千问Qwen-Long有限流,调用频次 ≤ 100 QPM,每分钟不超过100次API调用;
过程中可能会发生错误:Error code: 400 - {'error': {'code': 'ResponseTimeout', 'param': None, 'message': 'Response timeout!', 'type': 'ResponseTimeout'}},可以实现一个重试机制,设置最大重试次数,并在重试请求之前等待一定的时间。
#通义千问Qwen-Long的API使用方法和示例
##模型为:qwen-long,最大输入+输出总长度是1000万个tokens
API Key为:XXX
base_url为:https://dashscope.aliyuncs.com/compatible-mode/v1
## 调用限制。
如果超出调用限制,用户的API请求将会因为限流控制而失败,用户需要等待一段时间待满足限流条件后方能再次调用。调用频次 ≤ 100 QPM,每分钟不超过100次API调用;
##上传文件
文件格式支持常见的文本文件(txt docx pdf epub mobi md),单文件大小限制为150M,总量限制为1万个文件,总文件大小限制为100G。以下示例展示了通过OpenAI接口访问DashScope的文件上传。
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key="$your-dashscope-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# data.pdf 是一个示例文件
file_object = client.files.create(file=Path("data.pdf"), purpose="file-extract")
返回值类型为File,详细参考File object,示例如下
{
"id": "file-fe-9TIRfHksHmf5gLKZwi06o7Np",
"object": "file",
"bytes": 5,
"created_at": 1715256442973,
"filename": "test.txt",
"purpose": "file-extract"
}
##删除文件
from openai import OpenAI
client = OpenAI(
api_key="$your-dashscope-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
client.files.delete("file-fe-9TIRfHksHmf5gLKZwi06o7Np")
##通义千问Qwen-Long的调用示例:
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key="$your-dashscope-api-key", # 替换成真实DashScope的API_KEY
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 填写DashScope服务base_url
)
# data.pdf 是一个示例文件
file = client.files.create(file=Path("data.pdf"), purpose="file-extract")
# 新文件上传后需要等待模型解析,首轮rt可能较长
completion = client.chat.completions.create(
model="qwen-long",
messages=[
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'system',
'content': f'fileid://{file.id}'
},
{
'role': 'user',
'content': '这篇文章讲了什么?'
}
],
stream=False
)
print(completion.choices[0].message.dict())
deepseek生成的Python源代码:
import os
import requests
from pathlib import Path
from docx import Document
from openai import OpenAI
# 设置API Key和base_url
api_key = "XXX"
base_url = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 初始化OpenAI客户端
client = OpenAI(api_key=api_key, base_url=base_url)
# 设置文件夹路径
folder_path = "D:\\ABooks"
# 遍历文件夹中的所有PDF文件
for filename in os.listdir(folder_path):
if filename.endswith(".pdf"):
print(f"Processing file: {filename}")
file_path = os.path.join(folder_path, filename)
try:
# 上传PDF文件
file_object = client.files.create(file=Path(file_path), purpose="file-extract")
print(f"Uploaded file: {file_object.id}")
# 创建消息列表
messages = [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "system",
"content": f"fileid://{file_object.id}"
},
{"role": "user", "content": "总结这本书每个章节的内容,用中文输出。"},
]
# 发送请求
completion = client.chat.completions.create(
model="qwen-long",
messages=messages,
stream=False
)
# 创建Word文档
doc = Document()
doc.add_paragraph(completion.choices[0].message.content)
# 保存Word文档
doc_path = os.path.join(folder_path, f"{os.path.splitext(filename)[0]}.docx")
doc.save(doc_path)
print(f"Saved document: {doc_path}")
# 删除PDF文件
client.files.delete(file_id=file_object.id)
print(f"Deleted file: {file_object.id}")
except Exception as e:
print(f"Error processing file {filename}: {e}")
continue
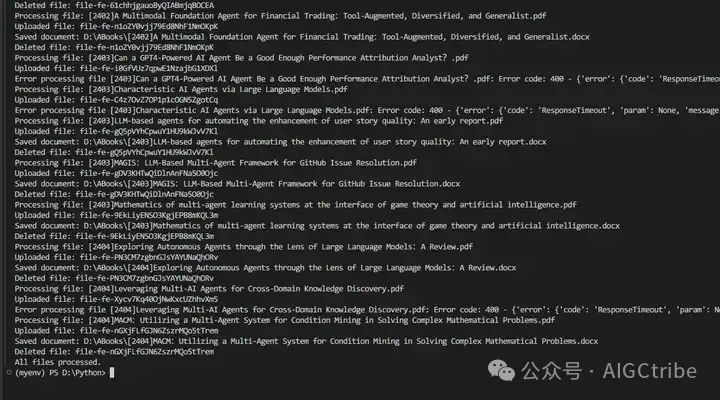
print("All files processed.")
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Dance with GenAI 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号