太强了!深度学习的Top10模型!


自2006年深度学习概念被提出以来,20年快过去了,深度学习作为人工智能领域的一场革命,已经催生了许多具有影响力的算法或模型。那么,你所认为深度学习的最牛的模型有哪些呢?欢迎评论区留言讨论~
以下是我心目中的深度学习top10模型,它们在创新性、应用价值和影响力方面都具有重要的地位。
1、深度神经网络(DNN)
背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。
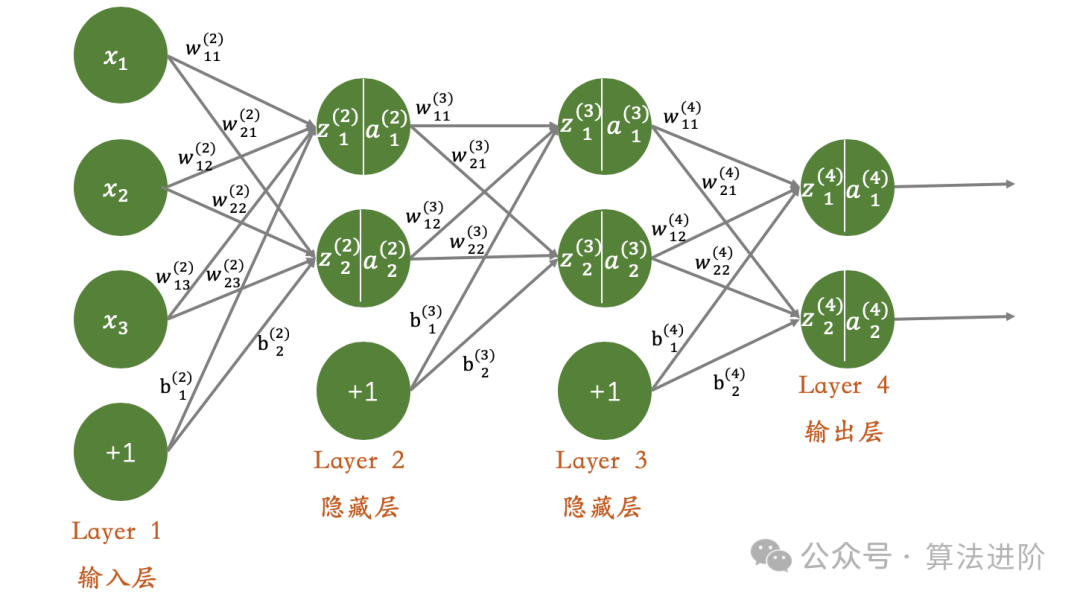
模型原理:深度神经网络(DNN)是一种构建于多层隐藏层之上的神经网络。每一层都扮演着信息的传递者和加工者的角色,通过非线性激活函数将输入数据转换为更具表现力的特征表示。正是这些连续的非线性变换,使得DNN能够捕捉到输入数据的深层次、复杂特征。
模型训练:DNN的权重更新主要依赖于反向传播算法和梯度下降优化算法。在训练过程中,通过计算损失函数关于权重的梯度,再利用梯度下降或其他优化策略,逐步调整权重值,以达到最小化损失函数的目的。
优点:DNN凭借其强大的特征学习和表示能力,能够有效学习输入数据的复杂特征,并精确捕捉非线性关系,使其在各种任务中表现出色。
缺点:然而,随着网络层数的增加,梯度消失问题逐渐凸显,这可能导致训练过程的不稳定。此外,DNN容易陷入局部最小值,从而限制了其性能,通常需要复杂的初始化策略和正则化技术来应对这些问题。
使用场景:DNN在多个领域有着广泛的应用,包括图像分类、语音识别、自然语言处理以及推荐系统等。
Python示例代码:
import tensorflow as tf
from tensorflow.keras.datasets import iris
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 加载鸢尾花数据集
(x_train, y_train), (x_test, y_test) = iris.load_data()
# 对数据进行预处理
y_train = tf.keras.utils.to_categorical(y_train) # 将标签转换为one-hot编码
y_test = tf.keras.utils.to_categorical(y_test)
# 创建神经网络模型
model = Sequential([
Dense(64, activation='relu', input_shape=(4,)), # 输入层,有4个输入节点
Dense(32, activation='relu'), # 隐藏层,有32个节点
Dense(3, activation='softmax') # 输出层,有3个节点(对应3种鸢尾花)
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32)
# 测试模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('Test accuracy:', test_acc)2、卷积神经网络(CNN)
模型原理:卷积神经网络(CNN)是一种专门为处理图像数据而设计的神经网络,由Lechun大佬设计的Lenet是CNN的开山之作。CNN通过使用卷积层来捕获局部特征,并通过池化层来降低数据的维度。卷积层对输入数据进行局部卷积操作,并使用参数共享机制来减少模型的参数数量。池化层则对卷积层的输出进行下采样,以降低数据的维度和计算复杂度。这种结构特别适合处理图像数据。
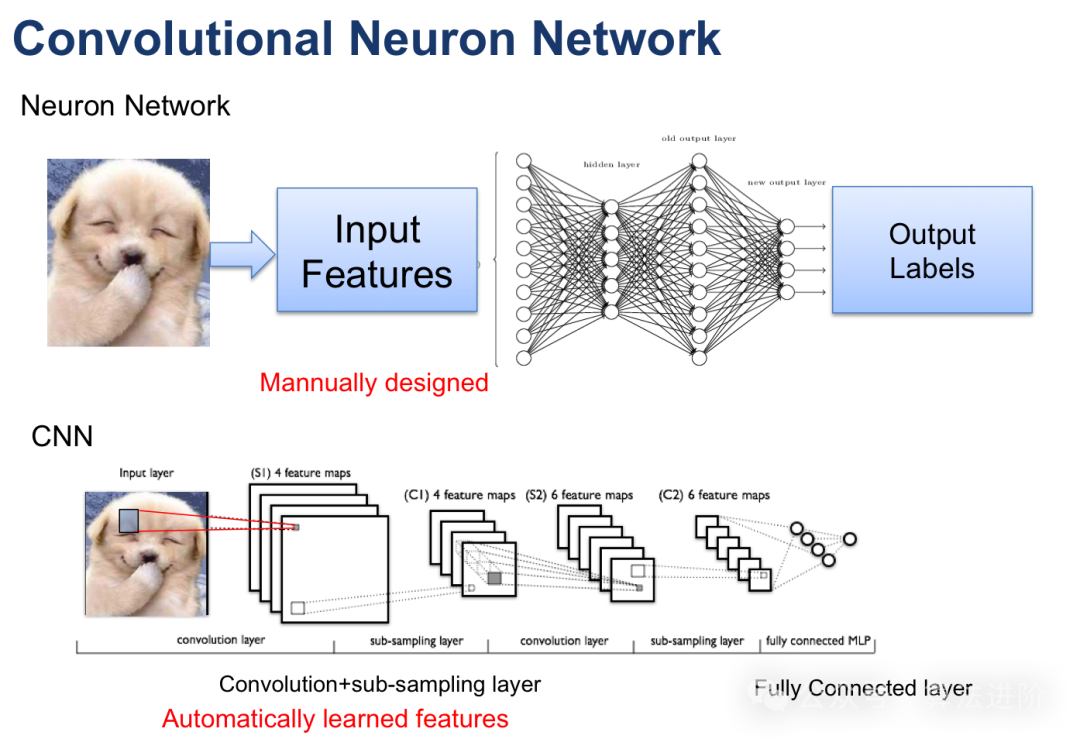
模型训练:采用反向传播算法与梯度下降优化策略,持续调整权重。在训练过程中,精准计算损失函数关于权重的梯度,借助梯度下降或其他高级优化算法,精确调整权重,旨在最小化损失函数,提升模型的准确度。
优势:本模型在处理图像数据方面表现出色,尤其擅长捕捉局部细微特征。得益于其精简的参数设计,有效降低了过拟合的风险,提升了模型的泛化能力。
局限:对于序列数据或需处理长距离依赖关系的任务,本模型可能难以胜任。此外,为了确保模型的输入质量,可能需要对原始数据进行繁琐的预处理工作。
适用场景:本模型在图像分类、目标检测、语义分割等图像处理任务中表现出色,能够为相关应用提供强有力的支持。
Python示例代码
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 设置超参数
input_shape = (28, 28, 1) # 假设输入图像是28x28像素的灰度图像
num_classes = 10 # 假设有10个类别
# 创建CNN模型
model = Sequential()
# 添加卷积层,32个3x3的卷积核,使用ReLU激活函数
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
# 添加卷积层,64个3x3的卷积核,使用ReLU激活函数
model.add(Conv2D(64, (3, 3), activation='relu'))
# 添加最大池化层,池化窗口为2x2
model.add(MaxPooling2D(pool_size=(2, 2)))
# 将多维输入展平为一维,以便输入全连接层
model.add(Flatten())
# 添加全连接层,128个神经元,使用ReLU激活函数
model.add(Dense(128, activation='relu'))
# 添加输出层,10个神经元,使用softmax激活函数进行多分类
model.add(Dense(num_classes, activation='softmax'))
# 编译模型,使用交叉熵作为损失函数,使用Adam优化器
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 打印模型结构
model.summary()3、残差网络(ResNet)
随着深度学习的快速发展,深度神经网络在多个领域取得了显著的成功。然而,深度神经网络的训练面临着梯度消失和模型退化等问题,这限制了网络的深度和性能。为了解决这些问题,残差网络(ResNet)被提出。
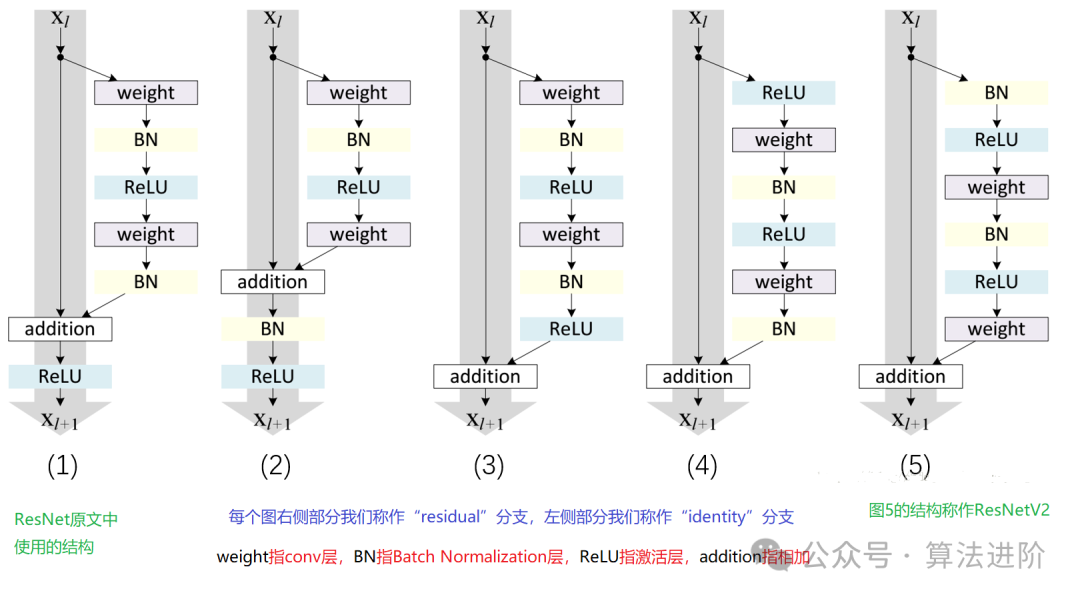
模型原理:
ResNet,通过独特设计的“残差块”,攻克了深度神经网络所面临的梯度消失与模型退化两大难题。残差块巧妙地融合了“跳跃连接”与多个非线性层,使梯度得以顺畅地从深层反向传递至浅层,显著提升了深度网络的训练效果。正是这一创新,让ResNet能够构建出极其深层的网络结构,并在众多任务中展现出卓越的性能。
模型训练:
在训练ResNet时,通常运用反向传播算法与诸如随机梯度下降的优化算法。训练过程中,计算损失函数关于权重的梯度,并借助优化算法调整权重,从而最小化损失函数。为了进一步提高训练速度和模型的泛化能力,我们还会运用正则化技术、集成学习等策略。
优点:
- 突破梯度消失与模型退化:凭借残差块与跳跃连接的引入,ResNet成功解决了深度网络的训练难题,有效避免了梯度消失与模型退化现象。
- 构建深层网络结构:由于克服了梯度消失与模型退化问题,ResNet得以构建更深层的网络结构,显著提升了模型的性能。
- 多任务卓越表现:得益于其强大的特征学习和表示能力,ResNet在图像分类、目标检测等多种任务中均展现出卓越的性能。
缺点:
- 计算资源需求高:由于ResNet通常需要构建深层的网络结构,导致计算量庞大,对计算资源和训练时间有着较高的要求。
- 参数调优难度大:ResNet的参数数量众多,需要投入大量的时间和精力进行参数调优和超参数选择。
- 对初始化权重敏感:ResNet对初始化权重的选择十分敏感,不合适的初始化可能导致训练不稳定或过拟合等问题。
应用场景:
ResNet在计算机视觉领域具有广泛的应用价值,如图像分类、目标检测、人脸识别等。此外,其在自然语言处理、语音识别等领域也具有一定的应用潜力。
Python示例代码(简化版):
from keras.models import Sequential
from keras.layers import Conv2D, Add, Activation, BatchNormalization, Shortcut
def residual_block(input, filters):
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return Add()([x, input]) # Add shortcut connection
# 构建ResNet模型
model = Sequential()
# 添加输入层和其他必要的层
# ...
# 添加残差块
model.add(residual_block(previous_layer, filters=64))
# 继续添加更多的残差块和其他层
# ...
# 添加输出层
# ...
# 编译和训练模型
# model.compile(...)
# model.fit(...)4、LSTM(长短时记忆网络)
在处理序列数据时,传统的循环神经网络(RNN)面临着梯度消失和模型退化等问题,这限制了网络的深度和性能。为了解决这些问题,LSTM被提出。
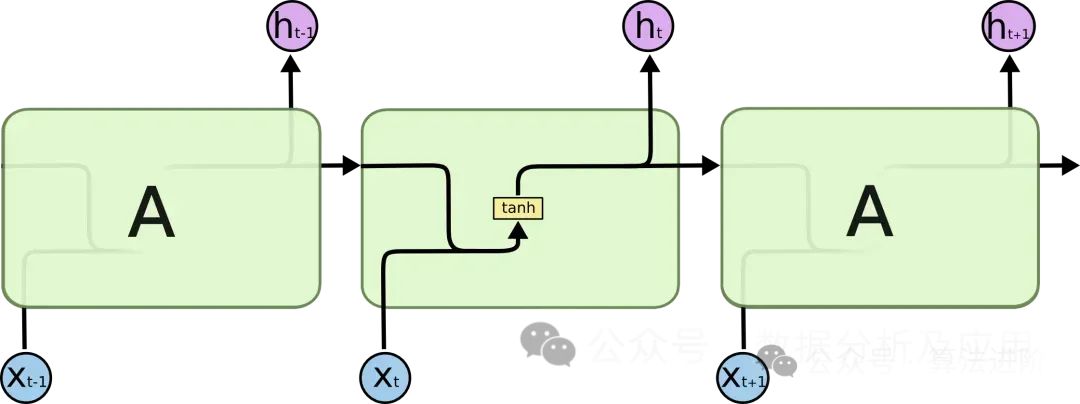
模型原理:
LSTM借助创新的“门控”机制,巧妙地调控信息的流动,从而攻克了梯度消失和模型退化这两大难题。具体而言,LSTM拥有三个核心门控机制:输入门、遗忘门和输出门。输入门负责筛选并接纳新信息,遗忘门则决定哪些旧信息应当被丢弃,而输出门则掌控着最终输出的信息流。正是这些精巧的门控机制,让LSTM在应对长期依赖问题时展现出了卓越的性能。
模型训练:
LSTM的训练过程通常采用反向传播算法和优化算法(如随机梯度下降)相结合的方式。训练过程中,算法会精确计算损失函数关于权重的梯度,并利用优化算法不断调整权重,以最小化损失函数。为了进一步提升训练效率和模型的泛化能力,还可以考虑采用正则化技术、集成学习等高级策略。
优点:
- 攻克梯度消失和模型退化:通过引入门控机制,LSTM在解决长期依赖问题上表现卓越,有效避免了梯度消失和模型退化的问题。
- 构建深邃网络结构:得益于对梯度消失和模型退化的处理,LSTM能够构建深度庞大的网络结构,从而充分发掘数据的内在规律,提升模型性能。
- 多任务表现出色:LSTM在文本生成、语音识别、机器翻译等多个任务中均展现了出色的性能,证明了其强大的特征学习和表示能力。
缺点:
- 参数调优挑战大:LSTM涉及大量参数,调优过程繁琐,需要投入大量时间和精力进行超参数选择和调整。
- 对初始化敏感:LSTM对权重的初始化极为敏感,不合适的初始化可能导致训练不稳定或出现过拟合问题。
- 计算量大:由于LSTM通常构建深度网络结构,计算量庞大,对计算资源和训练时间要求较高。
使用场景:
在自然语言处理领域,LSTM凭借其独特的优势在文本生成、机器翻译、语音识别等任务中广泛应用。此外,LSTM在时间序列分析、推荐系统等领域也展现出了巨大的潜力。
Python示例代码(简化版):
Pythonfrom keras.models import Sequential
from keras.layers import LSTM, Dense
def lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(units=128, input_shape=input_shape)) # 添加一个LSTM层
model.add(Dense(units=num_classes, activation='softmax')) # 添加一个全连接层
return model5、Word2Vec
Word2Vec模型是表征学习的开山之作。由Google的科学家们开发的一种用于自然语言处理的(浅层)神经网络模型。Word2Vec模型的目标是将每个词向量化为一个固定大小的向量,这样相似的词就可以被映射到相近的向量空间中。
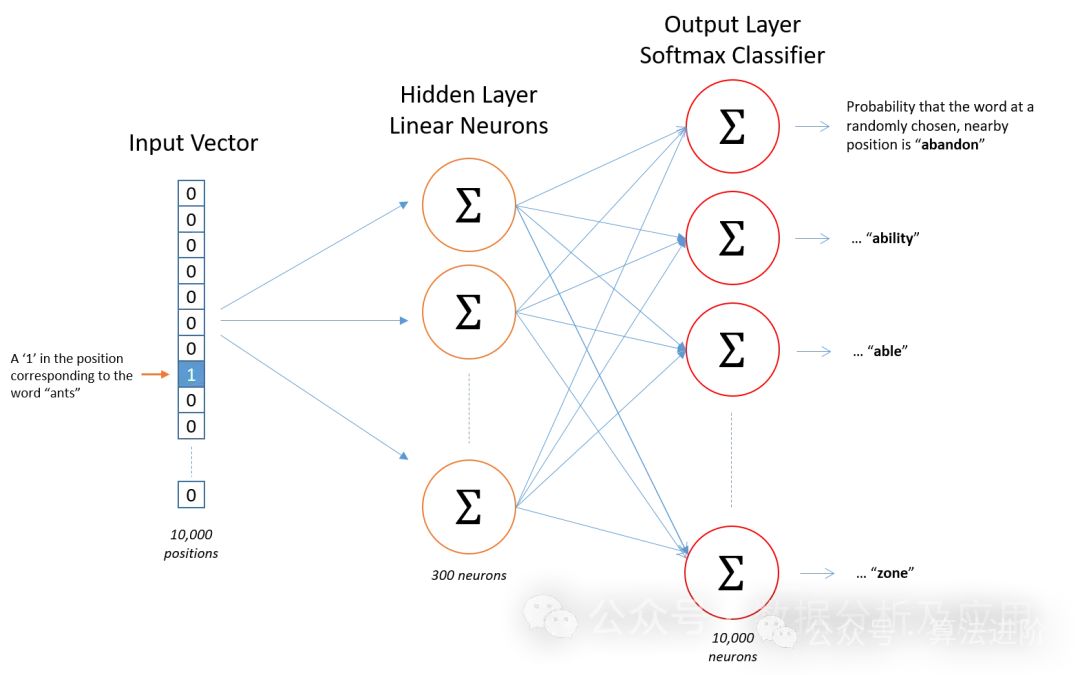
模型原理
Word2Vec模型基于神经网络,利用输入的词预测其上下文词。在训练过程中,模型尝试学习到每个词的向量表示,使得在给定上下文中出现的词与目标词的向量表示尽可能接近。这种训练方式称为“Skip-gram”或“Continuous Bag of Words”(CBOW)。
模型训练
Word2Vec模型的训练离不开丰富的文本数据资源。首先,我们会将这些数据预处理为词或n-gram的序列。接着,运用神经网络对这些词或n-gram的上下文进行深度学习。在训练过程中,模型会持续调整词的向量表示,以最小化预测误差,从而精确捕捉语义内涵。
优点概览
- 语义相似性:Word2Vec能够精准捕捉词与词之间的语义关联,使得在向量空间中,意义相近的词靠得更近。
- 训练效率:Word2Vec训练过程高效,轻松应对大规模文本数据的处理需求。
- 可解释性:Word2Vec生成的词向量具有实际应用价值,可用于诸如聚类、分类、语义相似性计算等多种任务。
潜在不足
- 数据稀疏性:对于未在训练数据中出现的词,Word2Vec可能无法生成精准的向量表示。
- 上下文窗口限制:Word2Vec的上下文窗口固定,可能会忽略远距离的词与词之间的依赖关系。
- 计算资源需求:Word2Vec的训练和推理过程对计算资源有一定要求。
- 参数调整挑战:Word2Vec的性能表现高度依赖于超参数(如向量维度、窗口大小、学习率等)的细致调整。
应用领域
Word2Vec在自然语言处理领域的应用广泛,如文本分类、情感分析、信息提取等。例如,它可以被用来识别新闻报道的情感倾向(正面或负面),或用于从大量文本中提取关键实体或概念。
Python示例代码
Pythonfrom gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
# 下载punkt分词模型
nltk.download('punkt')
# 假设我们有一些文本数据
sentences = [
"我喜欢吃苹果",
"苹果是我的最爱",
"我不喜欢吃香蕉",
"香蕉太甜了",
"我喜欢读书",
"读书让我快乐"
]
# 对文本数据进行分词处理
sentences = [word_tokenize(sentence) for sentence in sentences]
# 创建 Word2Vec 模型
# 这里的参数可以根据需要进行调整
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 训练模型
model.train(sentences, total_examples=model.corpus_count, epochs=10)
# 获取词向量
vector = model.wv['苹果']
# 找出与“苹果”最相似的词
similar_words = model.wv.most_similar('苹果')
print("苹果的词向量:", vector)
print("与苹果最相似的词:", similar_words)6、Transformer
背景:
在深度学习的早期阶段,卷积神经网络(CNN)在图像识别和自然语言处理领域取得了显著的成功。然而,随着任务复杂度的增加,序列到序列(Seq2Seq)模型和循环神经网络(RNN)成为处理序列数据的常用方法。尽管RNN及其变体在某些任务上表现良好,但它们在处理长序列时容易遇到梯度消失和模型退化问题。为了解决这些问题,Transformer模型被提出。而后的GPT、Bert等大模型都是基于Transformer实现了卓越的性能!
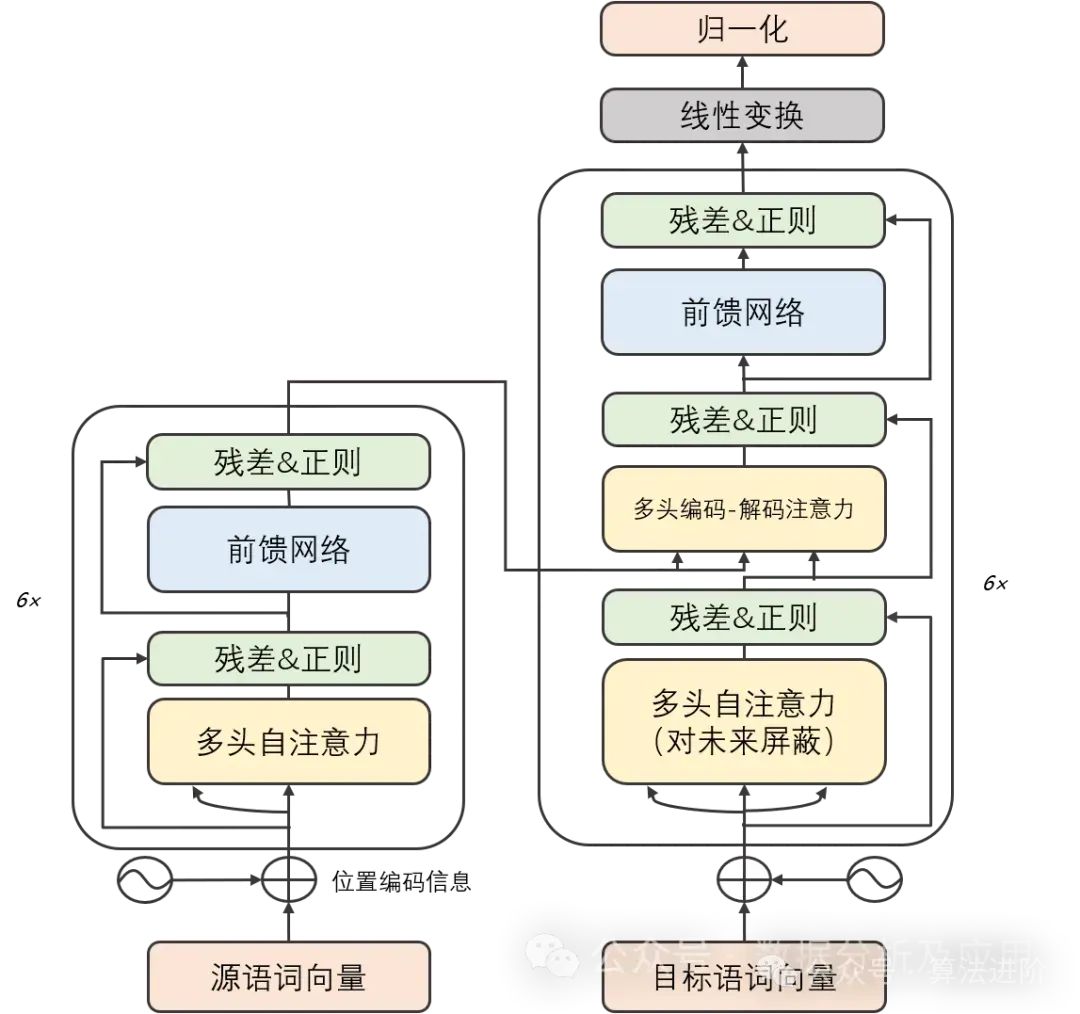
模型原理:
Transformer模型精巧地结合了编码器和解码器两大部分,每一部分均由若干相同构造的“层”堆叠而成。这些层巧妙地将自注意力子层与线性前馈神经网络子层结合在一起。自注意力子层巧妙地运用点积注意力机制,为每个位置的输入序列编织独特的表示,而线性前馈神经网络子层则汲取自注意力层的智慧,产出富含信息的输出表示。值得一提的是,编码器和解码器各自装备了一个位置编码层,专门捕捉输入序列中的位置脉络。
模型训练:
Transformer模型的修炼之道依赖于反向传播算法和优化算法,如随机梯度下降。在修炼过程中,它细致地计算损失函数对权重的梯度,并运用优化算法微调这些权重,以追求损失函数的最小化。为了加速修炼进度和提高模型的通用能力,修炼者们还常常采纳正则化技术、集成学习等策略。
优点:
- 梯度消失与模型退化之困得以解决:Transformer模型凭借其独特的自注意力机制,能够游刃有余地捕捉序列中的长期依赖关系,从而摆脱了梯度消失和模型退化的桎梏。
- 并行计算能力卓越:Transformer模型的计算架构具备天然的并行性,使得在GPU上能够风驰电掣地进行训练和推断。
- 多任务表现出色:凭借强大的特征学习和表示能力,Transformer模型在机器翻译、文本分类、语音识别等多项任务中展现了卓越的性能。
缺点:
- 计算资源需求庞大:由于Transformer模型的计算可并行性,训练和推断过程需要庞大的计算资源支持。
- 对初始化权重敏感:Transformer模型对初始化权重的选择极为挑剔,不当的初始化可能导致训练过程不稳定或出现过拟合问题。
- 长期依赖关系处理受限:尽管Transformer模型已有效解决梯度消失和模型退化问题,但在处理超长序列时仍面临挑战。
应用场景:
Transformer模型在自然语言处理领域的应用可谓广泛,涵盖机器翻译、文本分类、文本生成等诸多方面。此外,Transformer模型还在图像识别、语音识别等领域大放异彩。
Python示例代码(简化版):
import torch
import torch.nn as nn
import torch.optim as optim
#该示例仅用于说明Transformer的基本结构和原理。实际的Transformer模型(如GPT或BERT)要复杂得多,并且需要更多的预处理步骤,如分词、填充、掩码等。
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048):
super(Transformer, self).__init__()
self.model_type = 'Transformer'
# encoder layers
self.src_mask = None
self.pos_encoder = PositionalEncoding(d_model, max_len=5000)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)
# decoder layers
decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward)
self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
# decoder
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
batch_size = tgt.size(0)
tgt_len = tgt.size(1)
tgt_vocab_size = self.decoder.out_features
# forward pass through encoder
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
# prepare decoder input with teacher forcing
target_input = tgt[:, :-1].contiguous()
target_input = target_input.view(batch_size * tgt_len, -1)
target_input = torch.autograd.Variable(target_input)
# forward pass through decoder
output2 = self.transformer_decoder(target_input, output)
output2 = output2.view(batch_size, tgt_len, -1)
# generate predictions
prediction = self.decoder(output2)
prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# 超参数
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
# 实例化模型
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
# 随机生成数据
src = torch.randn(10, 32, 512)
tgt = torch.randn(10, 32, 512)
# 前向传播
prediction, predictions = model(src, tgt)
print(prediction)7、生成对抗网络(GAN)
GAN的思想源于博弈论中的零和游戏,其中一个玩家试图生成最逼真的假数据,而另一个玩家则尝试区分真实数据与假数据。GAN由蒙提霍尔问题(一种生成模型与判别模型组合的问题)演变而来,但与蒙提霍尔问题不同,GAN不强调逼近某些概率分布或生成某种样本,而是直接使用生成模型与判别模型进行对抗。
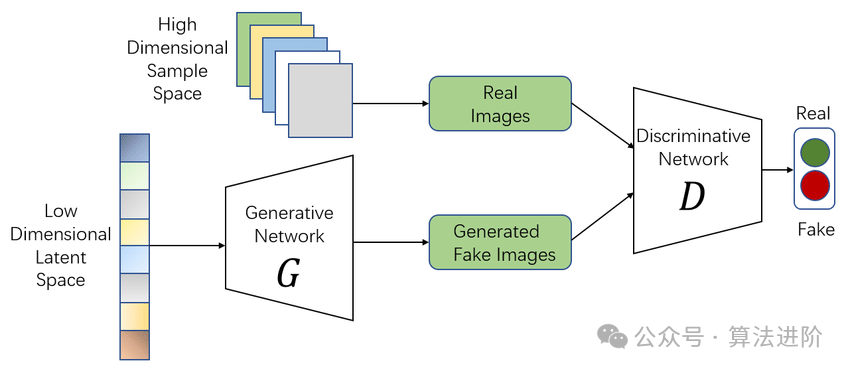
模型原理:
GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器致力于创作逼真的假数据,而判别器则致力于分辨输入数据的真伪。在持续的博弈中,两者不断调整参数,直至达到一种动态平衡。这时,生成器生成的假数据如此逼真,判别器已难以分辨其真伪。
模型训练:
GAN的训练过程是一个微妙的优化过程。在每个训练步骤中,生成器首先利用当前参数生成假数据,判别器随后对这些数据的真实性进行判断。根据判别结果,判别器的参数得到更新。同时,为了防止判别器过于精准,我们也会对生成器进行训练,使其能够创作出能欺骗判别器的假数据。这个过程反复进行,直至双方达到一种微妙的平衡。
优点:
- 强大的生成能力:GAN能够深入挖掘数据的内在结构和分布规律,创作出极其逼真的假数据。
- 无需显式监督:在GAN的训练过程中,我们无需提供显式的标签信息,只需提供真实数据即可。
- 灵活性高:GAN可以与其他模型无缝结合,如与自编码器结合形成AutoGAN,或与卷积神经网络结合形成DCGAN等,从而拓展其应用范围。
缺点:
- 训练不稳定:GAN的训练过程可能充满挑战,有时会出现模式崩溃(mode collapse)的问题,即生成器只专注于生成某一种样本,导致判别器难以准确判断。
- 调试困难:生成器和判别器之间的相互作用错综复杂,这使得GAN的调试变得颇具挑战性。
- 评估难度大:鉴于GAN出色的生成能力,准确评估其生成的假数据的真实性和多样性并非易事。
使用场景:
- 图像生成:GAN在图像生成领域大放异彩,能够创作出各种风格的图像,如根据文字描述生成图像,或将一幅图像转换为另一种风格等。
- 数据增强:GAN可以生成与真实数据极为相似的假数据,用于扩充数据集或提升模型的泛化能力。
- 图像修复:借助GAN,我们能够修复图像中的缺陷或消除图像中的噪声,使图像质量得到显著提升。
- 视频生成:基于GAN的视频生成已成为当前研究的热点之一,能够创作出各种风格独特的视频内容。
简单的Python示例代码:
以下是一个简单的GAN示例代码,使用PyTorch实现:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义生成器和判别器网络结构
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# 实例化生成器和判别器对象
input_dim = 100 # 输入维度可根据实际需求调整
output_dim = 784 # 对于MNIST数据集,输出维度为28*28=784
gen = Generator(input_dim, output_dim)
disc = Discriminator(output_dim)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失函数适用于GAN的判别器部分和生成器的logistic损失部分。但是,通常更常见的选择是采用二元交叉熵损失函数(binary cross
8、Diffusion扩散模型
火爆全网的Sora大模型的底层就是Diffusion模型,它是一种基于深度学习的生成模型,它主要用于生成连续数据,如图像、音频等。Diffusion模型的核心思想是通过逐步添加噪声来将复杂数据分布转化为简单的高斯分布,然后再通过逐步去除噪声来从简单分布中生成数据。
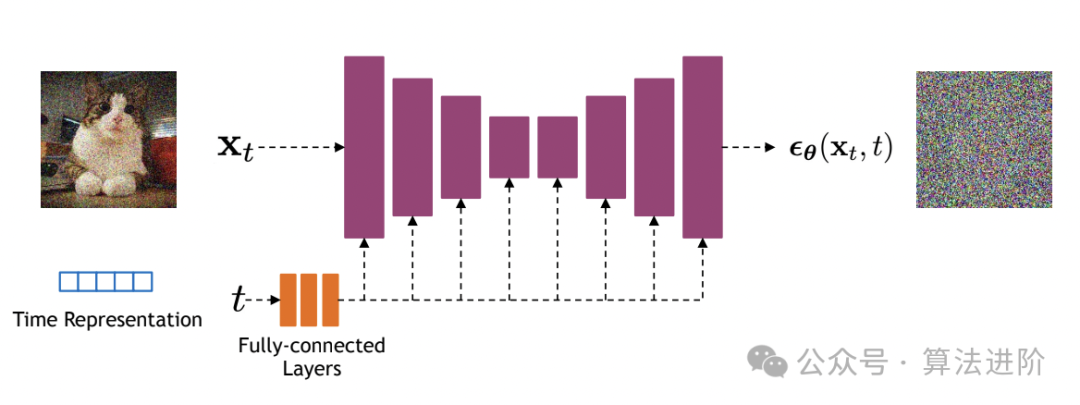
算法原理:
Diffusion Model的基本思想是将数据生成过程看作一个马尔可夫链。从目标数据开始,每一步都向随机噪声靠近,直到达到纯噪声状态。然后,通过反向过程,从纯噪声逐渐恢复到目标数据。这个过程通常由一系列的条件概率分布来描述。
训练过程:
- 前向过程(Forward Process):从真实数据开始,逐步添加噪声,直到达到纯噪声状态。这个过程中,需要计算每一步的噪声水平,并保存下来。
- 反向过程(Reverse Process):从纯噪声开始,逐步去除噪声,直到恢复到目标数据。在这个过程中,使用神经网络(通常是U-Net结构)来预测每一步的噪声水平,并据此生成数据。
- 优化:通过最小化真实数据与生成数据之间的差异来训练模型。常用的损失函数包括MSE(均方误差)和BCE(二元交叉熵)。
优点:
- 生成质量高:由于Diffusion Model采用了逐步扩散和恢复的过程,因此可以生成高质量的数据。
- 可解释性强:Diffusion Model的生成过程具有明显的物理意义,便于理解和解释。
- 灵活性好:Diffusion Model可以处理各种类型的数据,包括图像、文本和音频等。
缺点:
- 训练时间长:由于Diffusion Model需要进行多步的扩散和恢复过程,因此训练时间较长。
- 计算资源需求大:为了保证生成质量,Diffusion Model通常需要较大的计算资源,包括内存和计算力。
适用场景:
Diffusion Model适用于需要生成高质量数据的场景,如图像生成、文本生成和音频生成等。同时,由于其可解释性强和灵活性好的特点,Diffusion Model也可以应用于其他需要深度生成模型的领域。
Python示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义U-Net模型
class UNet(nn.Module):
# ...省略模型定义...
# 定义Diffusion Model
class DiffusionModel(nn.Module):
def __init__(self, unet):
super(DiffusionModel, self).__init__()
self.unet = unet
def forward(self, x_t, t):
# x_t为当前时刻的数据,t为噪声水平
# 使用U-Net预测噪声水平
noise_pred = self.unet(x_t, t)
# 根据噪声水平生成数据
x_t_minus_1 = x_t - noise_pred * torch.sqrt(1 - torch.exp(-2 * t))
return x_t_minus_1
# 初始化模型和优化器
unet = UNet()
model = DiffusionModel(unet)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练过程
for epoch in range(num_epochs):
for x_real in dataloader: # 从数据加载器中获取真实数据
# 前向过程
x_t = x_real # 从真实数据开始
for t in torch.linspace(0, 1, num_steps):
# 添加噪声
noise = torch.randn_like(x_t) * torch.sqrt(1 - torch.exp(-2 * t))
x_t = x_t + noise * torch.sqrt(torch.exp(-2 * t))
# 计算预测噪声
noise_pred = model(x_t, t)
# 计算损失
loss = nn.MSELoss()(noise_pred, noise)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
9、图神经网络(GNN)
图神经网络(Graph Neural Networks,简称GNN)是一种专为图结构数据量身打造的深度学习模型。在现实世界中,图结构被广泛用于描述各种复杂系统,如社交网络、分子结构和交通网络等。然而,传统的机器学习模型在处理这些图数据时经常遇到瓶颈,而图神经网络则为这些问题提供了全新的解决方案。
图神经网络的核心思想在于,通过神经网络学习图中节点的特征表示,并同时考虑节点之间的关联性。它利用迭代传递邻居信息的方式来更新节点表示,使得相似的社区或邻近的节点具有相似的表示。在每一层中,节点都会基于其邻居节点的信息来更新自身的表示,从而能够捕捉到图中的复杂模式。
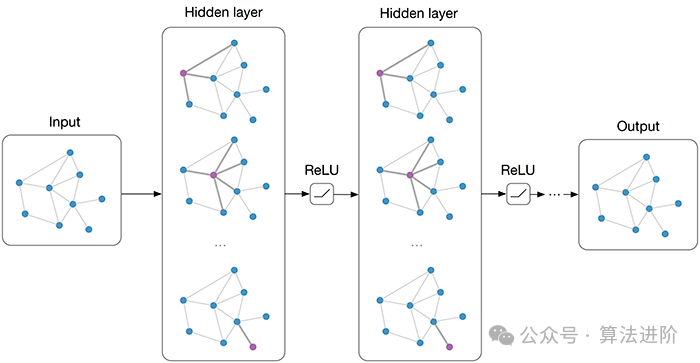
在训练图神经网络时,通常采用基于梯度的优化算法,如随机梯度下降(SGD)。通过反向传播算法计算损失函数的梯度,并根据这些梯度来更新神经网络的权重。常用的损失函数包括用于节点分类的交叉熵损失和用于链接预测的二元交叉熵损失等。
图神经网络具有以下显著优点:首先,它具有强大的表示能力,能够有效地捕捉图结构中的复杂模式,从而在节点分类、链接预测等任务上展现出卓越的性能。其次,它能够自然处理图结构数据,无需将图转换为矩阵形式,从而避免了大规模稀疏矩阵带来的计算和存储开销。最后,图神经网络具有很强的可扩展性,通过堆叠更多的层可以捕获更复杂的模式。
然而,图神经网络也存在一些局限性。首先,随着图中节点和边的增加,其计算复杂度会迅速上升,可能导致训练时间较长。其次,图神经网络的超参数较多,如邻域大小、层数和学习率等,调整这些参数需要深入理解任务需求。此外,图神经网络最初是为无向图设计的,对于有向图的适应性可能较弱。
在实际应用中,图神经网络在多个领域都展现出了广阔的应用前景。例如,在社交网络分析中,它可以用于分析用户之间的相似性、社区发现以及影响力传播等问题。在化学领域,图神经网络可用于预测分子的性质和化学反应。此外,在推荐系统和知识图谱等场景中,图神经网络也发挥着重要作用,能够帮助我们深入理解数据的内在结构和关联性。
GNN示例代码:
Pythonimport torch
from torch_geometric.nn import GCNConv
from torch_geometric.data import Data
# 定义一个简单的图结构
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
# 定义一个简单的两层图卷积网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = torch.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return torch.log_softmax(x, dim=1)
# 实例化模型、损失函数和优化器
model = Net()
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# 训练模型
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
# 在测试集上评估模型
model.eval()
_, pred = model(data).max(dim=1)
correct = int((pred == data.y).sum().item())
acc = correct / int(data.y.sum().item())
print('Accuracy: {:.4f}'.format(acc))10、深度强化学习(DQN):
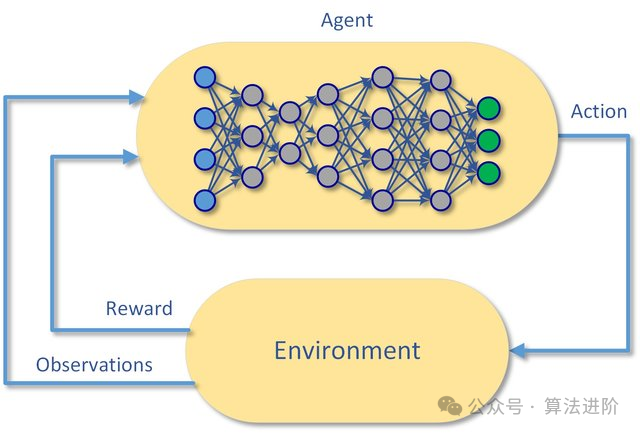
模型原理:
Deep Q-Networks (DQN) 是一种集成了深度学习和Q-learning的强化学习算法。其核心理念在于利用神经网络去逼近Q函数,也就是状态-动作值函数,从而为智能体在特定状态下决策最优动作提供有力的支撑。
模型训练:
DQN的训练过程分为两个关键阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的互动收集数据,进而训练神经网络。进入在线阶段,智能体开始依赖神经网络进行动作的选择和更新。为了防范过度估计的风险,DQN创新性地引入了目标网络的概念,使得目标网络在一段时间内保持稳定,从而大幅提升了算法的稳定性。
优点:
DQN以其出色的性能,成功攻克了高维度状态和动作空间的难题,尤其在处理连续动作空间的问题上表现卓越。它不仅稳定性高,而且泛化能力强,显示出强大的实用价值。
缺点:
DQN也存在一些局限性。例如,它有时可能陷入局部最优解,难以自拔。此外,它需要庞大的数据和计算资源作为支撑,并且对参数的选择十分敏感,这些都增加了其实际应用的难度。
使用场景:
DQN依然在游戏、机器人控制等多个领域大放异彩,充分展现了其独特的价值和广泛的应用前景。
示例代码:
import tensorflow as tf
import numpy as np
import random
import gym
from collections import deque
# 设置超参数
BUFFER_SIZE = int(1e5) # 经验回放存储的大小
BATCH_SIZE = 64 # 每次从经验回放中抽取的样本数量
GAMMA = 0.99 # 折扣因子
TAU = 1e-3 # 目标网络更新的步长
LR = 1e-3 # 学习率
UPDATE_RATE = 10 # 每多少步更新一次目标网络
# 定义经验回放存储
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
# 定义DQN模型
class DQN:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.model = self._build_model()
def _build_model(self):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(24, input_dim=self.state_size, activation='relu'))
model.add(tf.keras.layers.Dense(24, activation='relu'))
model.add(tf.keras.layers.Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=LR))
return model
def remember(self, state, action, reward, next_state, done):
self.replay_buffer.push((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= 0.01:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = self.replay_buffer.sample(batch_size)
for state, action, reward, next_state, done in minibatch:
target = self.model.predict(state)
if done:
target[0][action] = reward
else:
Q_future = max(self.target_model.predict(next_state)[0])
target[0][action] = reward + GAMMA * Q_future
self.model.fit(state, target, epochs=1, verbose=0)
if self.step % UPDATE_RATE == 0:
self.target_model.set_weights(self.model.get_weights())
def load(self, name):
self.model.load_weights(name)
def save(self, name):
self.model.save_weights(name)
# 创建环境
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# 初始化DQN和回放存储
dqn = DQN(state_size, action_size)
replay_buffer = ReplayBuffer(BUFFER_SIZE)
# 训练过程
total_steps = 10000
for step in range(total_steps):
state = env.reset()
state = np.reshape(state, [1, state_size])
for episode in range(100):
action = dqn.act(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
replay_buffer.remember(state, action, reward, next_state, done)
state = next_state
if done:
break
if replay_buffer.buffer.__哪个模型、算法是你心目中的TOP呢?↓
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号