92. 三维重建27-立体匹配23,如何让模型适应新类型的图像

92. 三维重建27-立体匹配23,如何让模型适应新类型的图像

HawkWang
发布于 2024-06-26 12:19:27
发布于 2024-06-26 12:19:27
到目前为止,我已经给各位介绍了各种各样的端到端立体匹配算法,当这些算法在处理与其训练集的特性类似的图像时,大多能够取得非常不错的匹配结果。然而,如果待匹配的图像与训练时使用的图像在特性上存在显著差异,这些算法的效果就会大幅下降,这就是所谓的“领域转换问题(Domain Shift Issue)”。
比如,我们常在下面这些情况下观察到这种现象:
- 从室内到室外环境的变化:在不同的光照、背景和物体布局下,室内和室外的图像差异很大。
- 从合成数据到真实数据的变化:合成数据通常是通过计算机生成的,而真实数据是通过摄像头拍摄的,这两者之间在细节和质量上存在很大差异。
- 不同的室内或室外环境之间的变化:即使都是室内或者室外环境,不同的场景也可能有很大的不同。
- 相机模型或参数的变化:不同的相机型号或设置也会影响图像的质量和特点。
比如下面是典型的合成数据与真实数据之间的差异, 下图左边来自于我之前在文章76. 三维重建11-立体匹配7,解析合成数据集和工具中给大家描述过的FyingThings数据集。

这些领域转换问题会带来一些显著的负面影响。当深度学习网络在一个领域(例如合成数据)上进行训练,然后应用于另一个领域(例如真实数据)时,通常会出现一些问题。首先,网络可能会产生模糊的物体边界,无法准确区分物体的轮廓,使得图像中的物体显得模糊不清。其次,在一些难以处理的区域,例如物体遮挡、重复模式和无纹理区域,网络会产生显著的误差。这种现象也被参考文献[2]称之为generalization glitches, 即泛化失误.
有许多专家提出了各种各样的方法,来应对这种泛化失误现象,他们大体可以分为两类,一种方法采用所谓的Fine-Tuning的手段,即在新的数据集上微调模型,而另外一种方法则从数据着手,试图使两个不同域的图像的特性变为相同。
那么我的这篇文章就来为各位解析这两类方法,并给出一些实例介绍,希望能够给各位启发。
一. 在新的域上微调模型
这个方法的核心思想是,先在某一特定领域的图像上训练网络,然后再在目标领域的图像上进行微调,以此来让模型适应新的环境。
举个例子,假设我们先用合成图像(比如文献[22]中提到的合成数据)训练一个深度学习网络。这些合成图像虽然能提供丰富的训练数据,但它们与我们在现实中遇到的图像可能有很大的不同。这就导致了之前讲的所谓泛化失误问题:此时模型的表现往往会不尽如人意,因为它不适应这些新的数据。
要解决这个问题,我们可以在新领域的图像上对模型进行微调。然而,现实中的一个大难题是,如何获得这些目标领域图像的真实深度数据呢?依靠像LiDAR这样的主动传感器来获取这些带有深度标签的数据,虽然可行但在实际应用中并不现实,因为这些设备昂贵且操作复杂,且还存在如何准确将由主动传感器获得的深度信息映射到双目相机的问题。
因此,最近的研究提出了一种替代方案,即利用现成的立体匹配算法。这些算法虽然并不完美,但它们可以在无监督的情况下,生成目标领域图像的视差或深度标签。接着,我们会用一些最先进的置信度测量方法来评估这些视差或深度测量的可靠性。文献[3]和[4]中介绍的方法,就是通过这种方式,区分出哪些测量值是可靠的,哪些是不可靠的。然后,我们选择那些可靠的测量值,把它们当作真实标签,来微调我们预训练好的模型。
通过这种方法,我们不需要昂贵且复杂的设备,就可以实现模型的领域适应。尽管这些标签并不是完美的真实数据,但在实际应用中,它们足够好,可以显著提升模型在新领域中的表现。这样,我们就能更有效地将深度学习模型从一个领域转移到另一个领域。
1.1 文献3的基础方法
我们先来看看文献[3]的方法,这篇文章叫做Unsupervised Adaptation for Deep Stereo, 看标题就知道它是采用无监督的域适应方法。

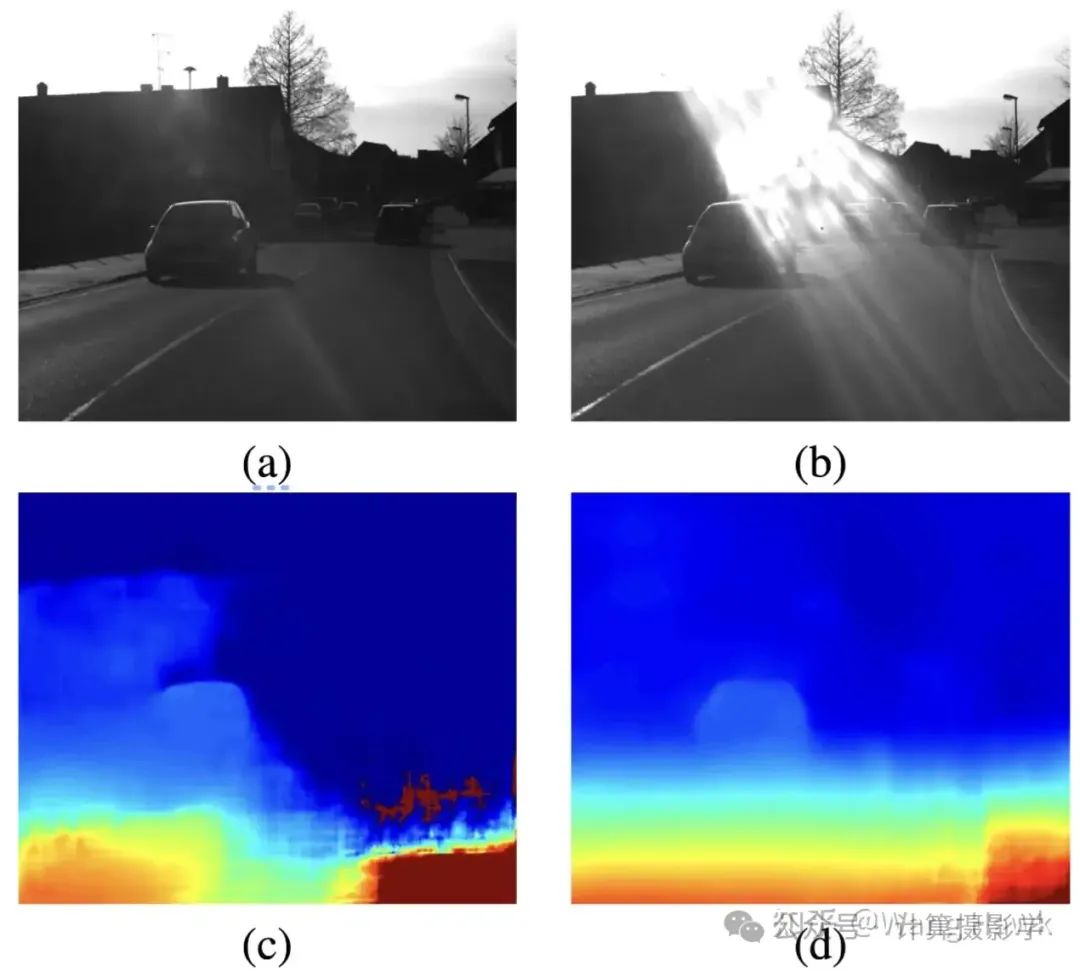
作者一开始就展示了下面这幅图,其中(a)(b)是一对双目图像,我们很明显会看到右图有明显的光晕,导致这对图像的匹配非常具有挑战性。如果模型没有在这种图像上微调过,就会得到糟糕的结果,例如c图所示,它是Dispnet-Corr1D得到的结果。而作者所提出的方案则可以得到很好的结果,即图d.
作者提出了一种在没有地面真实视差标签的情况下,微调预训练的深度立体匹配模型的方法,以使其能够更好地适应新环境,它的总体思想可以总结为下图:
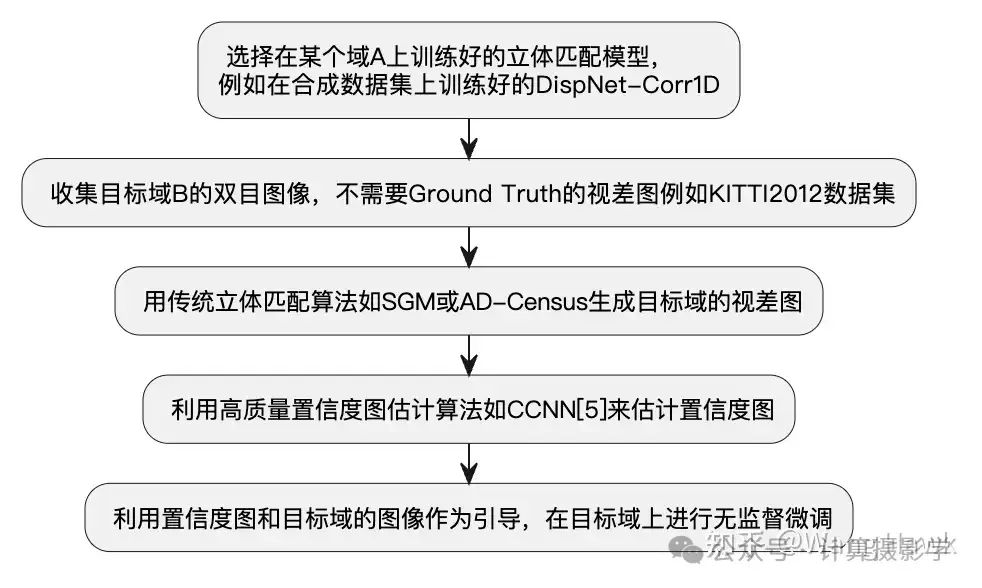
选择在某个域A上训练好的立体匹配模型,例如在合成数据集上训练好的DispNet-Corr1D收集目标域B的双目图像,不需要Ground Truth的视差图例如KITTI2012数据集用传统立体匹配算法如SGM或AD-Census生成目标域的视差图利用高质量置信度图估计算法如CCNN[5]来估计置信度图利用置信度图和目标域的图像作为引导,在目标域上进行无监督微调
首先,作者使用在合成数据上预训练的DispNet-Corr1D模型。这个模型在合成数据上训练得很好,但在面对与训练数据分布不同的新环境时,其性能会大幅下降。作者选择了KITTI2012作为模型微调时的训练集,这个数据集包含了一些真实世界的双目图像,但是没有使用其中的Ground Truth的视差图。
作者使用了传统的立体匹配算法AD-Census,来生成KITTI2012数据集上的视差图。然后,作者使用了高质量的置信度估计算法,如CCNN[5],来根据视差图生成置信度图。置信度图是一个与视差图大小相同的图像,每个像素的值表示该像素的视差值的置信度。在置信度图中,值越大表示该像素的视差值越可信。
接下来关键的一步是,作者利用置信度图和目标域的图像作为引导,在目标域上进行无监督微调。作者提出了一个新的损失函数,称之为Confidence-Weighted Loss,它可以根据置信度图来调整损失函数的权重。这样,模型在训练时会更加关注那些置信度高的像素,而对置信度低的像素则不那么敏感。这样,模型就能更好地适应新环境,提升在目标域上的性能。
作者给出的总体的损失函数是:

其中, CL 就是所谓的Confidence-Weighted Loss, 而S则是Smoothness Loss, 它是为了保持视差图的平滑性而设计的。 λ 是一个超参数,用来调整两个损失函数的权重。

公式(3)中的阈值 𝜏τ 是一个超参数,用来过滤掉那些置信度低的像素。作者通过实验发现,选择较高的置信度阈值 𝜏τ 能够有效地筛选出高质量的视差估计点,即使这些点数量较少,也能显著提升模型的性能。
如下图所示,蓝色曲线表示在学习过程中使用的点的数量随 𝜏τ 的变化关系。可以看出,随着 𝜏τ 值的增加,参与学习过程的点的数量在减少,橙色曲线表示在那些由置信度度量选择出来的点中,正确点的百分比(这些点也属于可用的稀疏真值集合)。这个百分比是通过将选定点的视差估计值与真值视差进行比较得到的。图中黑色水平线表示可用的稀疏真值点的比例(不到总点数的 30%)。从图中可以看出,尽管参与学习的点的数量减少了,但在高 𝜏τ 值(即大于 0.9)时,选定点的正确率几乎达到 100%。这表明在这些高置信度点上,视差估计值非常可靠,尽管数量较少,但这些点可以有效地用于无监督学习过程中的“替代”真值数据。
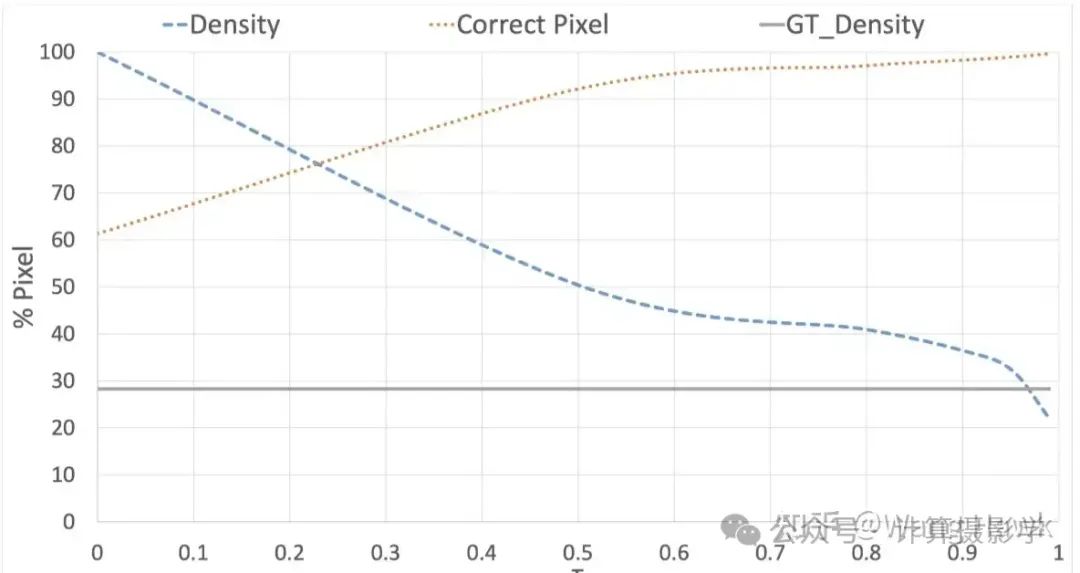
图 3 展示了 KITTI 2015 数据集中一个样本的情况。第一行包括从左到右的几幅图像:参考图像、由 AD-CENSUS 算法生成的视差图和由CCNN生成的相应置信度图。
第二行展示了通过对置信度图进行阈值处理后得到的三幅彩色图像,分别对应于阈值τ 等于 0、0.5 和 0.99 的情况。绿色部分表示超过阈值的点,蓝色部分表示这些点与可用的 ground-truth 点的交集。
通过这些图像可以看到,随着阈值 τ 的增加,参与训练的点的数量逐渐减少,但这些点在图像中的分布更加均匀。这些高置信度点能够有效地用于无监督学习过程,提高模型在新域上的泛化性能。

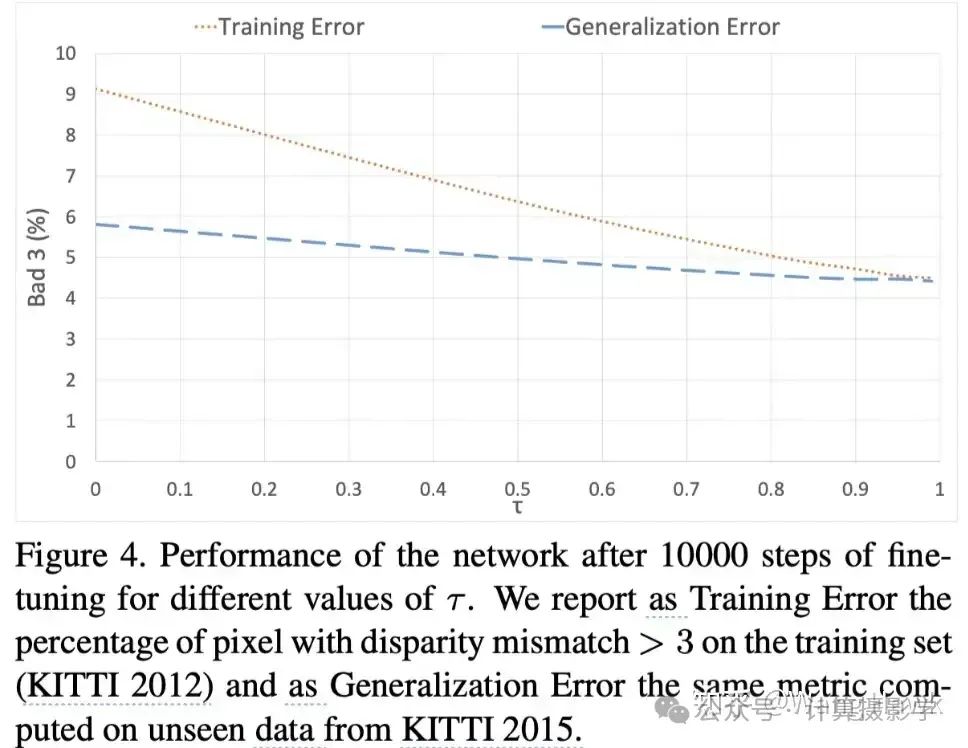
图4也证明了我们的直觉,它展示了在不同 τ 值下,经过10000次微调后的网络性能。
- 训练误差(Training Error):表示训练集(KITTI 2012)上视差误差大于3的像素百分比。
- 泛化误差(Generalization Error):表示在未见过的数据(KITTI 2015)上相同度量标准的错误率。
从图中可以看出,随着 值的增加,训练误差和泛化误差都呈现出下降趋势。即使 值非常高,错误率也能保持在较低水平,说明置信度高的视差估计更可靠,并且有助于提高模型在新环境中的泛化能力。
总之,作者通过一系列的实验,最终选择了τ =0.99,以及 λ =0.1,这样的参数组合能够在新环境中取得最好的性能。
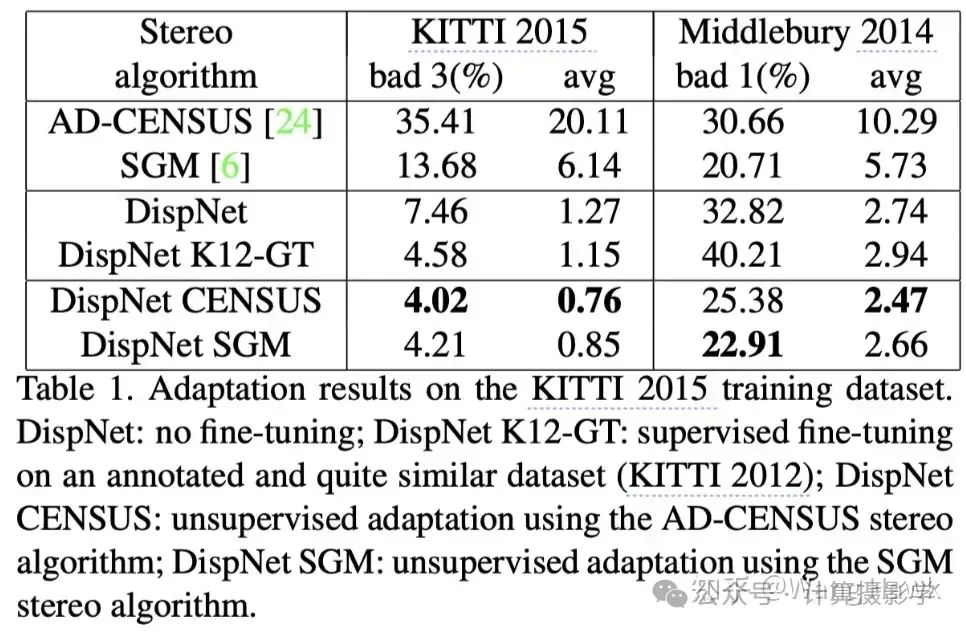
如下表所示,作者在KITTI 2012数据集上微调模型,然后在KITTI 2015数据集以及MiddleBurry 2014数据集上进行测试,结果表明,作者的方法能够显著提升模型在新环境中的性能。另外由于KITTI 2015数据集和KITTI 2012数据集比较相似,而MiddleBurry 2014数据集则与KITTI 2012数据集有很大的不同,我们可以看出在MiddleBurry 2014数据集上的总体性能是比较差的,这也说明了领域转换问题的严重性。但即便如此,经过作者微调过的模型在MiddleBurry 2014数据集上的性能也比未微调的模型要好,这说明作者的方法是有效的。
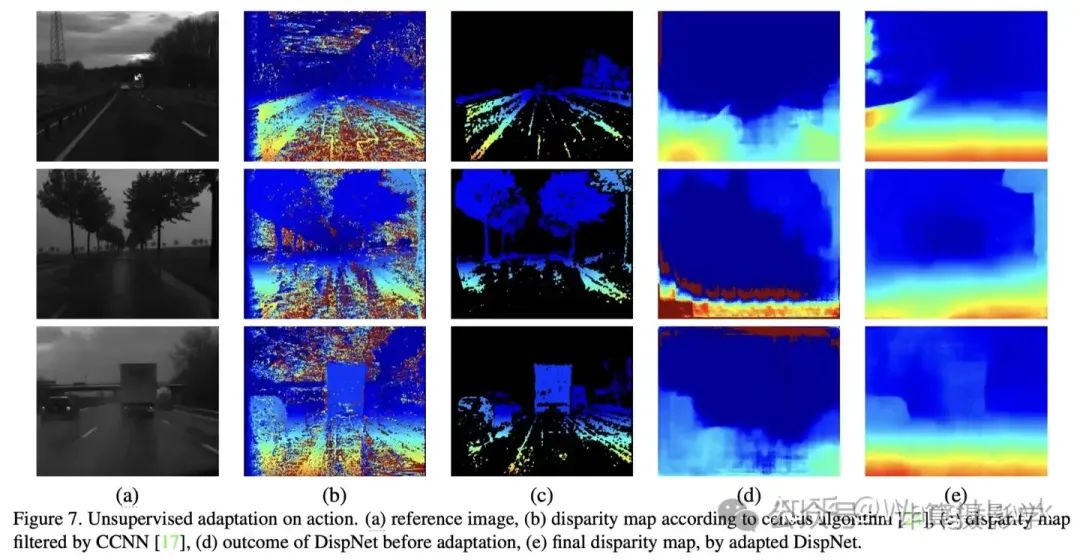
为了进一步验证所提出方法的有效性,作者在一组恶劣天气条件下获取的具有挑战性的立体序列上对DispNet进行了无监督适应。这些序列的一个特殊之处在于没有真实数据,这使其成为我们方法的一个非常合适的案例研究。
图7展示了一些显著的例子,显示了适应技术在解决与光照和天气条件相关的问题上非常有效。首先,图(a)展示了原始的立体图像对,这些图像在恶劣天气条件下拍摄,具有显著的光晕和低对比度。接下来,图(b)展示了使用传统Census算法生成的初始视差图。可以看到,由于天气和光照的影响,这些视差图中存在大量的噪声和误差。
然后,图(c)展示了经过CCNN置信度评估过滤后的视差图,虽然有所改善,但仍然存在显著的错误区域。图(d)展示了未进行任何适应之前的DispNet结果,可以看到许多细节丢失和误差。最后,图(e)展示了经过我们的方法适应后的DispNet生成的最终视差图,显著改善了视差估计的准确性,尤其是在光照和天气变化剧烈的区域。
通过这些结果可以看出,所提出的无监督适应方法在处理恶劣天气和光照条件下的立体匹配任务中表现出了优异的效果。模型能够在没有真实数据的情况下,自主调整并适应新环境,从而生成更加准确和可靠的视差图。这种能力使得我们的方法在实际应用中具有很大的潜力和实用性。
总之,作者展示了,在没有使用真实视差标签的情况下,可以将深度学习立体匹配网络适应到全新的环境中, 从而提高模型的泛化能力。作者的方法不仅能够显著提升模型在新环境中的性能,而且还能够有效地处理恶劣天气和光照条件下的立体匹配任务。这些结果表明,作者的方法在解决领域转换问题上具有很大的潜力和实用性。
1.2 文献4的进一步改进
文献[4]来自同样的作者团队,他们进一步改进了文献[3]的方法,提出了一种新的无监督域适应方法,用于深度图像预测任务。这篇文章叫做Unsupervised Domain Adaptation for Depth Prediction from Images。

作者的方法的总体思想和文献[3]类似,但是作者在几个方面进行了改进。
最关键的改进是损失函数的变化,新的损失函数变为了这样:
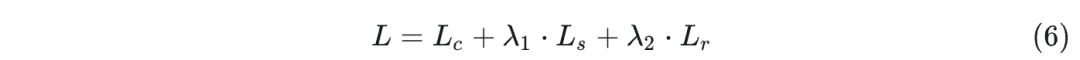
这里面我们可以看到,作者除了在文献3的损失函数基础上,加入了一个新的损失函数 Lr,这个损失函数是一个重构损失,用来保持输入图像和输出图像的一致性。这个损失函数的定义如下:
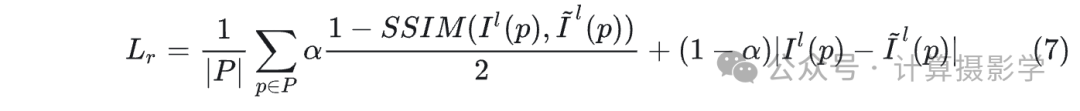

1.3 小结
采用我这里讲解的"先在某一特定领域的图像上训练网络,然后再在目标领域的图像上进行微调,以此来让模型适应新的环境"的论文还有很多,大家可以查阅文献[1],这里就不一一列举了。我认为这是一种非常有实用性的方法,因为它不需要目标数据集的真实的深度标签。这种方法在实际应用中具有很大的潜力和实用性,我希望大家可以多多关注这个方向。
文献[1]还特别提到,上述方法是一种“离线微调”的域适应方法,这种方法尽管有效,但意味着每个不同的目标域,都需要重新训练模型。这在实际应用中并不现实,因为每个新的目标域都需要大量的计算资源和时间。因此,未来的研究方向之一是设计一种“在线微调”的域适应方法,即在新的目标域上进行微调时,不需要重新训练整个模型,而是通过在线学习的方式,快速适应新的环境。例如文献[5]通过将域适应问题视为一个连续的学习过程来解决,其中立体匹配网络可以根据相机在实际部署过程中收集的图像在线演变。这个过程以无监督的方式进行,通过在当前帧上计算误差信号,通过单次反向传播迭代更新整个网络,然后转到下一对输入帧。为了保持足够高的帧率,作者提出了一种轻量级、快速且模块化的架构,称为MADNet,这使得可以独立训练整个网络的各个子部分。这使得在大约每秒25帧的情况下,可以在无监督的情况下将视差估计网络适应未见过的环境,同时实现与DispNetC相当的准确性。
二. 从数据着手,使两个不同域的图像的特性变为相同
上面我们介绍了一种方法,即在新的域上微调模型,以此来适应新的环境。这种方法虽然有效,但是需要大量的计算资源和时间,因此在实际应用中并不现实。另外一种方法则是从数据着手,试图使两个不同域的图像的特性变为相同。
2.1 文献7的方法
我们来看看文献[7],这篇文章叫做Real-Time Monocular Depth Estimation Using Synthetic Data With Domain Adaptation via Image Style Transfer。

作者提出了一种通过样式迁移和域适应来解决从一个域到另一个域的图像转换的方法。这个方法的目标是将合成数据上训练的深度估计模型应用到真实世界的数据上,并通过样式迁移减少这两个数据分布之间的差异。

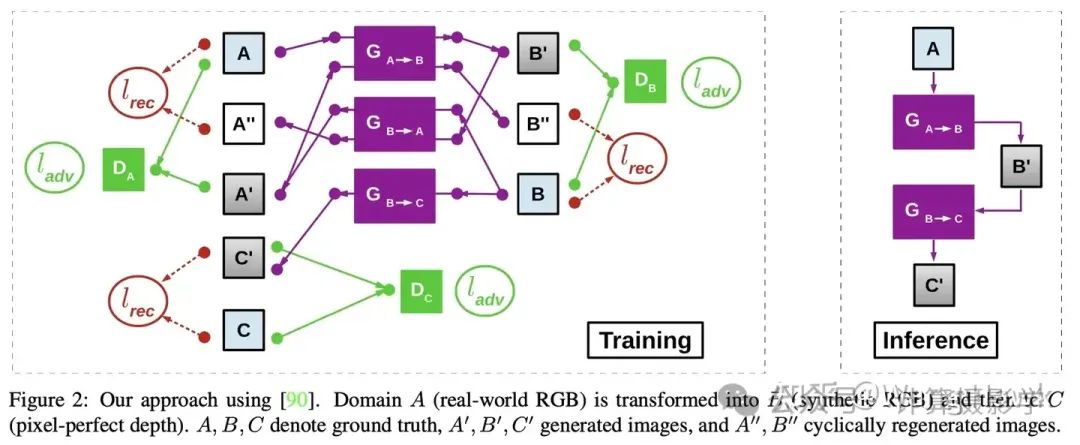
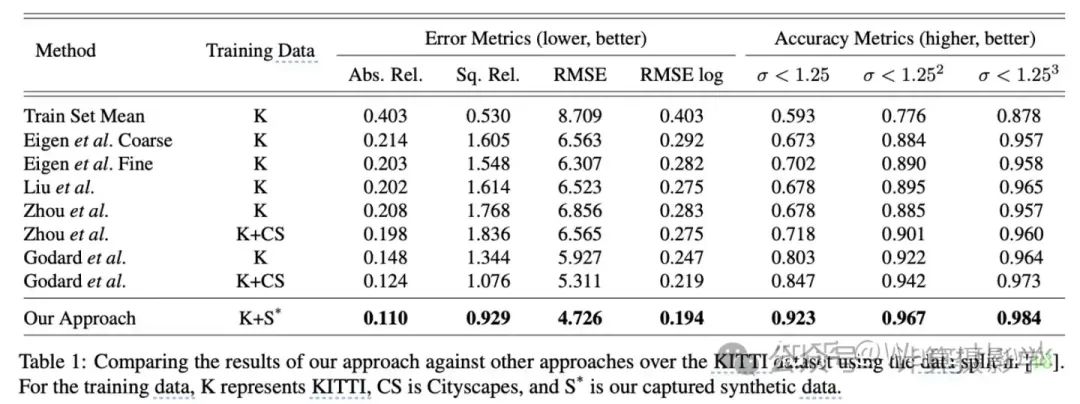
为了更好地与现有方法进行数值比较,作者使用了697张图像进行测试。从表1中可以看出,作者的方法在误差更低和准确度更高方面优于当前的最先进方法。这些度量标准基于现有的评价指标。一些对比方法使用了不同数据集的组合进行训练和微调,以提高性能,而作者仅使用了合成数据和KITTI数据集。此外,按照文献中的惯例,所有的误差测量都是在深度空间中进行的,而作者的方法生成的是视差图,这可能会带来一些小的精度问题。
作者还使用了KITTI数据集中200张图像的拆分数据,以提供更好的定性评估,因为这个拆分中的真实视差图的质量明显高于Velodyne激光数据,并且提供了用于移动汽车的CAD模型替代品。
如图3所示,与在类似数据域上训练的最先进方法相比,作者的方法生成了更清晰和更锐利的输出,其中物体边界和细结构得到了很好的保留。通过这些实验,作者展示了他们的方法在不同数据域上的泛化能力,即使在未见过的数据上也能表现良好。总的来说,作者的方法在多个方面表现出色,并在许多评估指标上超过了现有的最先进方法。

总之,我们通过上述信息可以看出,作者的方法通过样式迁移和域适应,将合成数据上训练的深度估计模型应用到真实世界的数据上,从而提高模型在新环境中的性能。这种方法不仅能够显著提升模型在新环境中的性能,而且还能够有效地处理不同数据域之间的差异。这些结果表明,作者的方法在解决领域转换问题上具有很大的潜力和实用性。
2.2 其他同类方法
在参考文献[1]中还提到了其他一些类似的方法。
比如,参考文献[8]恰恰相反,它通过将合成图像转换为更真实的图像,并使用它们来训练深度估计网络。这种方法的优点是,它不需要真实的深度标签,而只需要合成数据和真实数据之间的图像对。这样,我们就可以更有效地将深度学习模型从一个领域转移到另一个领域。
文献[9]提出了一种方法,它使用了两个转换器,一个负责将合成图像转换为真实图像,另一个负责将真实图像转换为合成图像。这两个转换器都在对抗训练的框架下进行优化,利用对抗损失来提升图像的真实感。同时,他们还使用循环一致性损失来确保图像在双向转换过程中的一致性。通过这种方式,他们可以更好地将合成数据和真实数据之间的差异减小到最小,从而提高深度估计模型在新环境中的性能。
尽管上面这些方法主要用于单目深度估计,但它们同样适用于多视图立体匹配方法。换句话说,这种转换技术不仅可以提升单目相机的深度估计性能,还可以在立体相机的匹配过程中发挥作用,通过将不同域的图像进行转换,来提升整体匹配的准确性和稳定性。
三. 总结
我之前已经给大家介绍了很多基于深度学习,甚至端到端学习的立体匹配算法。这些算法在合成数据集上训练得很好,但在面对与训练数据分布不同的新环境时,其性能会大幅下降。这就是所谓的领域转换问题。为了解决这个问题,我们需要将深度学习模型从一个领域转移到另一个领域,以此来提高模型在新环境中的性能。
在这篇文章中,我们介绍了两类用于解决领域转换问题的方法。第一类方法是通过在新的域上微调模型,以此来适应新的环境。当采用无监督的方法时,这种方法时不需要新数据集的GT深度标签的,因此在实际应用中具有很大的潜力和实用性。不过这种方法虽然有效,但是需要大量的计算资源和时间来微调,因此被称为离线微调方法。还有一些学者提出了所谓的在线微调方法,我们仅仅提了一嘴,没有深入介绍,大家可以阅读参考文献[1],了解详情。
第二类方法是从数据着手,试图使两个不同域的图像的特性变为相同。这种方法不仅能够显著提升模型在新环境中的性能,而且还能够有效地处理不同数据域之间的差异。这些结果表明,这种方法在解决领域转换问题上具有很大的潜力和实用性。
本文同步发表在我的微信公众号和知乎专栏“计算摄影学”,欢迎扫码关注,转载请注明作者和来源,如果你觉得有用的话,真诚的希望你顺手点个赞,并推荐给你的朋友们!也欢迎你加入我的计算摄影知识星球和广大的计算摄影爱好者进行讨论交流。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号