Transformers 4.37 中文文档(九十三)

Transformers 4.37 中文文档(九十三)

ApacheCN_飞龙
发布于 2024-06-26 18:50:29
发布于 2024-06-26 18:50:29
Pix2Struct
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/pix2struct
概述
Pix2Struct 模型是由 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova 在《Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding》中提出的。
论文摘要如下:
视觉定位语言是无处不在的 — 源头包括带有图表的教科书、带有图像和表格的网页,以及带有按钮和表单的移动应用程序。也许正是由于这种多样性,先前的工作通常依赖于具有限制性的领域特定配方,对底层数据、模型架构和目标的共享有限。我们提出了 Pix2Struct,这是一个预训练的图像到文本模型,用于纯粹的视觉语言理解,可以在包含视觉定位语言的任务上进行微调。Pix2Struct 通过学习将屏幕截图的掩码解析为简化的 HTML 来进行预训练。网络,其丰富的视觉元素清晰地反映在 HTML 结构中,为下游任务的多样性提供了大量的预训练数据。直观地说,这个目标包含了常见的预训练信号,如 OCR、语言建模、图像字幕。除了新颖的预训练策略,我们还引入了可变分辨率的输入表示和更灵活的语言和视觉输入集成,其中语言提示(如问题)直接呈现在输入图像的顶部。我们首次展示,单个预训练模型可以在四个领域的九项任务中的六项中取得最先进的结果: 文档、插图、用户界面和自然图像。
提示:
Pix2Struct 已经在各种任务和数据集上进行了微调,包括图像字幕、视觉问答(VQA)以及不同输入(书籍、图表、科学图表)、字幕 UI 组件等。完整列表可以在论文的表 1 中找到。因此,我们建议您将这些模型用于它们已经进行微调的任务。例如,如果您想要将 Pix2Struct 用于 UI 字幕,您应该使用在 UI 数据集上进行微调的模型。如果您想要将 Pix2Struct 用于图像字幕,您应该使用在自然图像字幕数据集上进行微调的模型,依此类推。
如果您想要使用模型执行有条件的文本字幕,确保使用add_special_tokens=False的处理器。
资源
Pix2StructConfig
class transformers.Pix2StructConfig
( text_config = None vision_config = None initializer_factor = 1.0 initializer_range = 0.02 is_vqa = False tie_word_embeddings = False is_encoder_decoder = True **kwargs )参数
-
text_config(dict, 可选) — 用于初始化 Pix2StructTextConfig 的配置选项字典。 -
vision_config(dict, 可选) — 用于初始化 Pix2StructVisionConfig 的配置选项字典。 -
initializer_factor(float, 可选, 默认为 1.0) — 用于乘以初始化范围的因子。 -
initializer_range(float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 -
is_vqa(bool, 可选, 默认为False) — 模型是否已经为 VQA 进行了微调。 -
kwargs(optional) — 关键字参数的字典。
Pix2StructConfig 是用于存储 Pix2StructForConditionalGeneration 配置的配置类。根据指定的参数实例化 Pix2Struct 模型,定义文本模型和视觉模型配置。使用默认值实例化配置将产生类似于 Pix2Struct-base google/pix2struct-base 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Pix2StructConfig, Pix2StructForConditionalGeneration
>>> # Initializing a Pix2StructConfig with google/pix2struct-base style configuration
>>> configuration = Pix2StructConfig()
>>> # Initializing a Pix2StructForConditionalGeneration (with random weights) from the google/pix2struct-base style configuration
>>> model = Pix2StructForConditionalGeneration(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a Pix2StructConfig from a Pix2StructTextConfig and a Pix2StructVisionConfig
>>> # Initializing a Pix2Struct text and Pix2Struct vision configuration
>>> config_text = Pix2StructTextConfig()
>>> config_vision = Pix2StructVisionConfig()
>>> config = Pix2StructConfig.from_text_vision_configs(config_text, config_vision)from_text_vision_configs
( text_config: Pix2StructTextConfig vision_config: Pix2StructVisionConfig **kwargs ) → export const metadata = 'undefined';Pix2StructConfig返回
Pix2StructConfig
配置对象的一个实例
从 pix2struct 文本模型配置和 pix2struct 视觉模型配置实例化一个 Pix2StructConfig(或派生类)。
Pix2StructTextConfig
class transformers.Pix2StructTextConfig
( vocab_size = 50244 hidden_size = 768 d_kv = 64 d_ff = 2048 num_layers = 12 num_heads = 12 relative_attention_num_buckets = 32 relative_attention_max_distance = 128 dropout_rate = 0.1 layer_norm_epsilon = 1e-06 initializer_factor = 1.0 dense_act_fn = 'gelu_new' decoder_start_token_id = 0 use_cache = False pad_token_id = 0 eos_token_id = 1 tie_word_embeddings = False is_decoder = True **kwargs )参数
-
vocab_size(int, optional, defaults to 50244) —Pix2Struct文本模型的词汇量。定义了在调用 Pix2StructTextModel 时可以表示的不同标记数量。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化层的维度。 -
d_kv(int, optional, defaults to 64) — 每个注意力头中键、查询、值投影的维度。 -
d_ff(int, optional, defaults to 2048) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数量。 -
num_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
relative_attention_num_buckets(int, optional, defaults to 32) — 每个注意力层使用的桶数量。 -
relative_attention_max_distance(int, optional, defaults to 128) — 用于桶分离的较长序列的最大距离。 -
dropout_rate(float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢弃概率。 -
layer_norm_epsilon(float, optional, defaults to 1e-6) — 层归一化层使用的 epsilon。 -
initializer_factor(float, optional, defaults to 1.0) — 初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
dense_act_fn(Union[Callable, str], optional, defaults to"gelu_new") — 非线性激活函数(函数或字符串)。 -
decoder_start_token_id(int, optional, defaults to 0) —decoder_start_token_id标记的 id。 -
use_cache(bool, optional, defaults toFalse) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 -
pad_token_id(int, optional, defaults to 0) —padding标记的 id。 -
eos_token_id(int, optional, defaults to 1) —end-of-sequence标记的 id。
这是用于存储 Pix2StructTextModel 配置的配置类。根据指定的参数实例化 Pix2Struct 文本模型,定义模型架构。使用默认实例化配置将产生类似于 Pix2Struct 文本解码器的配置,该解码器由google/pix2struct-base架构使用。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Pix2StructTextConfig, Pix2StructTextModel
>>> # Initializing a Pix2StructTextConfig with google/pix2struct-base style configuration
>>> configuration = Pix2StructTextConfig()
>>> # Initializing a Pix2StructTextModel (with random weights) from the google/pix2struct-base style configuration
>>> model = Pix2StructTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPix2StructVisionConfig
class transformers.Pix2StructVisionConfig
( hidden_size = 768 patch_embed_hidden_size = 768 d_ff = 2048 d_kv = 64 num_hidden_layers = 12 num_attention_heads = 12 dense_act_fn = 'gelu_new' layer_norm_eps = 1e-06 dropout_rate = 0.0 attention_dropout = 0.0 initializer_range = 1e-10 initializer_factor = 1.0 seq_len = 4096 relative_attention_num_buckets = 32 relative_attention_max_distance = 128 **kwargs )参数
-
hidden_size(int, optional, 默认为 768) — 编码器层和池化器层的维度。 -
patch_embed_hidden_size(int, optional, 默认为 768) — Transformer 编码器中输入 patch_embedding 层的维度。 -
d_ff(int, optional, 默认为 2048) — Transformer 编码器中“中间”(即前馈)层的维度。 -
d_kv(int, optional, 默认为 64) — 每个注意力头部的键、查询、值投影的维度。 -
num_hidden_layers(int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
dense_act_fn(str或function, optional, 默认为"gelu_new") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new""gelu"。 -
layer_norm_eps(float, optional, 默认为 1e-06) — 层归一化层使用的 epsilon。 -
dropout_rate(float, optional, 默认为 0.0) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 -
attention_dropout(float, optional, 默认为 0.0) — 注意力概率的 dropout 比率。 -
initializer_range(float, optional, 默认为 1e-10) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
initializer_factor(float, optional, 默认为 1.0) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
seq_len(int, optional, 默认为 4096) — 模型支持的最大序列长度(这里是 patch 的数量)。 -
relative_attention_num_buckets(int, optional, 默认为 32) — 每个注意力层使用的桶数量。 -
relative_attention_max_distance(int, optional, 默认为 128) — 每个注意力层使用的最大距离(以标记为单位)。
这是用于存储 Pix2StructVisionModel 配置的配置类。根据指定的参数实例化 Pix2Struct 视觉模型,定义模型架构。使用默认实例化配置将产生类似于 Pix2Struct-base google/pix2struct-base架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Pix2StructVisionConfig, Pix2StructVisionModel
>>> # Initializing a Pix2StructVisionConfig with google/pix2struct-base style configuration
>>> configuration = Pix2StructVisionConfig()
>>> # Initializing a Pix2StructVisionModel (with random weights) from the google/pix2struct-base style configuration
>>> model = Pix2StructVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPix2StructProcessor
class transformers.Pix2StructProcessor
( image_processor tokenizer )参数
-
image_processor(Pix2StructImageProcessor) — 一个 Pix2StructImageProcessor 的实例。图像处理器是必需的输入。 -
tokenizer(Union[T5TokenizerFast,T5Tokenizer]) — 一个[‘T5TokenizerFast]或[‘T5Tokenizer]的实例。Tokenizer 是必需的输入。
构建一个 PIX2STRUCT 处理器,将 BERT tokenizer 和 PIX2STRUCT 图像处理器封装成一个处理器。
Pix2StructProcessor 提供了 Pix2StructImageProcessor 和 T5TokenizerFast 的所有功能。查看__call__()和 decode()的文档字符串以获取更多信息。
batch_decode
( *args **kwargs )这个方法将所有参数转发给 Pix2StructTokenizerFast 的 batch_decode()。请参考此方法的文档字符串以获取更多信息。
decode
( *args **kwargs )这个方法将所有参数转发给 Pix2StructTokenizerFast 的 decode()。请参考此方法的文档字符串以获取更多信息。
Pix2StructImageProcessor
class transformers.Pix2StructImageProcessor
( do_convert_rgb: bool = True do_normalize: bool = True patch_size: Dict = None max_patches: int = 2048 is_vqa: bool = False **kwargs )参数
-
do_convert_rgb(bool, 可选, 默认为True) — 是否将图像转换为 RGB 格式。 -
do_normalize(bool, 可选, 默认为True) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。根据 Pix2Struct 论文和代码,图像使用自己的均值和标准差进行归一化。 -
patch_size(Dict[str, int], 可选, 默认为{"height" -- 16, "width": 16}): 用于图像的补丁大小。根据 Pix2Struct 论文和代码,补丁大小为 16x16。 -
max_patches(int, 可选, 默认为 2048) — 从图像中提取的最大补丁数,根据Pix2Struct 论文。 -
is_vqa(bool, 可选, 默认为False) — 图像处理器是否用于 VQA 任务。如果为True并且传入了header_text,则文本将呈现在输入图像上。
构建一个 Pix2Struct 图像处理器。
preprocess
( images: Union header_text: Optional = None do_convert_rgb: bool = None do_normalize: Optional = None max_patches: Optional = None patch_size: Optional = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或图像批次。 -
header_text(Union[List[str], str], 可选) — 要呈现为标题的文本。仅当image_processor.is_vqa为True时才有效。 -
do_convert_rgb(bool,可选,默认为self.do_convert_rgb)— 是否将图像转换为 RGB。 -
do_normalize(bool,可选,默认为self.do_normalize)— 是否对图像进行标准化。 -
max_patches(int,可选,默认为self.max_patches)— 要提取的最大补丁数。 -
patch_size(dict,可选,默认为self.patch_size)— 包含补丁高度和宽度的字典。 -
return_tensors(str或TensorType,可选)— 要返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回类型为tf.Tensor的批次。 -
TensorType.PYTORCH或'pt':返回类型为torch.Tensor的批次。 -
TensorType.NUMPY或'np':返回类型为np.ndarray的批次。 -
TensorType.JAX或'jax':返回类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
-
data_format(ChannelDimension或str,可选,默认为ChannelDimension.FIRST)— 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以 (num_channels, height, width) 格式表示。 -
"channels_last"或ChannelDimension.LAST:图像以 (height, width, num_channels) 格式表示。 - 未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str,可选)— 输入图像的通道维度格式。如果未设置,将从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以 (num_channels, height, width) 格式表示。 -
"channels_last"或ChannelDimension.LAST:图像以 (height, width, num_channels) 格式表示。 -
"none"或ChannelDimension.NONE:图像以 (height, width) 格式表示。
-
预处理图像或图像批次。处理器首先计算可以从图像中提取的保持纵横比的大小为 patch_size 的最大可能数量的补丁。然后,它使用零填充图像,使图像遵守 max_patches 的约束。在提取补丁之前,图像将按照 tensorflow 的 per_image_standardization 实现进行标准化(www.tensorflow.org/api_docs/python/tf/image/per_image_standardization)。
Pix2StructTextModel
class transformers.Pix2StructTextModel
( config )参数
config(Union[Pix2StructConfig,Pix2StructTextConfig])— 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Pix2Struct 的独立文本解码器
Pix2Struct 模型由 Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova 在 Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding 中提出。它是一个在图像到文本设置下进行预训练的编码器解码器 transformer 模型。
该模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型还是一个 PyTorch torch.nn.Module 子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以了解所有与一般用法和行为相关的事项。
forward
( input_ids: Optional = None attention_mask: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None inputs_embeds: Optional = None head_mask: Optional = None cross_attn_head_mask: Optional = None past_key_values: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None labels: Optional = None return_dict: Optional = None **kwargs ) → export const metadata = 'undefined';transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。Pix2StructText 是一个带有相对位置嵌入的模型,因此您应该能够在右侧和左侧填充输入。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? 要了解有关如何为预训练准备input_ids的更多信息,请查看 Pix2StructText Training。 -
attention_mask(torch.FloatTensorof shape(batch_size, sequence_length), optional) — 避免在填充标记索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示未被
屏蔽的标记, - 0 表示被
屏蔽的标记。
什么是注意力掩码?
- 1 表示未被
-
decoder_input_ids(torch.LongTensorof shape(batch_size, target_sequence_length), optional) — 词汇表中解码器输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是解码器输入 ID? Pix2StructText 使用pad_token_id作为decoder_input_ids生成的起始标记。如果使用past_key_values,可选择仅输入最后的decoder_input_ids(参见past_key_values)。 要了解有关如何为预训练准备decoder_input_ids的更多信息,请查看 Pix2StructText Training。 -
decoder_attention_mask(torch.BoolTensorof shape(batch_size, target_sequence_length), optional) — 默认行为:生成一个张量,忽略decoder_input_ids中的填充标记。因果掩码也将默认使用。 -
head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 编码器中自注意力模块中选择性屏蔽头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被
屏蔽, - 0 表示头部被
屏蔽。
- 1 表示头部未被
-
decoder_head_mask(torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — 解码器中自注意力模块中选择性屏蔽头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被
屏蔽。 - 0 表示头部被
屏蔽。
- 1 表示头部未被
-
cross_attn_head_mask(torch.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — 解码器中交叉注意力模块中选择性屏蔽头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被
屏蔽。 - 0 表示头部被
屏蔽。
- 1 表示头部未被
-
encoder_outputs(tuple(tuple(torch.FloatTensor), optional) — 元组包括(last_hidden_state,可选:hidden_states,可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size),是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力。 -
past_key_values(tuple(tuple(torch.FloatTensor)),长度为config.n_layers,每个元组有 4 个形状为(batch_size, num_heads, sequence_length - 1, embed_size_per_head)的张量) — 包含注意力层的预计算键和值隐藏状态。可用于加速解码。 如果使用past_key_values,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将它们的过去键值状态提供给此模型的)而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 -
inputs_embeds(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您想要更多控制如何将input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 -
decoder_inputs_embeds(torch.FloatTensor,形状为(batch_size, target_sequence_length, hidden_size),可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递decoder_input_ids。如果使用past_key_values,可以选择仅输入最后一个decoder_inputs_embeds(请参阅past_key_values)。如果您想要更多控制如何将decoder_input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 如果decoder_input_ids和decoder_inputs_embeds都未设置,则decoder_inputs_embeds取inputs_embeds的值。 -
use_cache(bool, optional) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码(请参阅past_key_values)。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False,或者当config.return_dict=False时)包含根据配置(Pix2StructConfig)和输入的不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits(torch.FloatTensor,形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层的输出,则为一个 + 每层的输出)。 每层模型的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 自注意力模块中注意力 softmax 后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。 -
past_key_values(tuple(tuple(torch.FloatTensor)), optional, 当传递use_cache=True或config.use_cache=True时返回 — 长度为config.n_layers的torch.FloatTensor元组,每个元组包含自注意力和交叉注意力层的缓存键、值状态,如果模型在编码器-解码器设置中使用,则相关。仅在config.is_decoder = True时相关。 包含预先计算的隐藏状态(注意力块中的键和值),可用于加速顺序解码(请参阅past_key_values输入)。
Pix2StructTextModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, Pix2StructTextModel
>>> processor = AutoProcessor.from_pretrained("google/pix2struct-textcaps-base")
>>> model = Pix2StructTextModel.from_pretrained("google/pix2struct-textcaps-base")
>>> inputs = processor(text="Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.lossPix2StructVisionModel
class transformers.Pix2StructVisionModel
( config: Pix2StructConfig )参数
config(Pix2StructConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 Pix2StructVision Model 变压器输出原始隐藏状态,没有特定的头部。这个模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( flattened_patches: Optional = None attention_mask: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)参数
-
flattened_patches(torch.FloatTensor,形状为(batch_size, sequence_length, num_channels x patch_height x patch_width)) — 扁平化和填充的像素值。这些值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅Pix2StructVisionImageProcessor.__call__。查看原始论文(图 5)以获取更多详细信息。 -
attention_mask(torch.FloatTensor,形状为(batch_size, sequence_length),optional) — 用于避免在填充像素值上执行注意力的掩码。掩码值选择在[0, 1]之间: -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块的选定头部失效的掩码。掩码值选择在[0, 1]之间:- 1 表示头部是
not masked, - 0 表示头部是
masked。
- 1 表示头部是
-
output_attentions(bool,optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)-是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(Pix2StructConfig)和输入的不同元素。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)-模型最后一层输出的隐藏状态序列。 -
pooler_output(形状为(batch_size, hidden_size)的torch.FloatTensor)-序列第一个标记(分类标记)的最后一层隐藏状态,在通过用于辅助预训练任务的层进一步处理后。例如,对于 BERT 系列模型,这将返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)-形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+一个用于每层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)-形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
Pix2StructVisionModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> from transformers import AutoProcessor, Pix2StructVisionModel
>>> image_processor = AutoProcessor.from_pretrained("google/pix2struct-textcaps-base")
>>> model = Pix2StructVisionModel.from_pretrained("google/pix2struct-textcaps-base")
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 2048, 768]Pix2StructForConditionalGeneration
class transformers.Pix2StructForConditionalGeneration
( config: Pix2StructConfig )参数
config(Union[Pix2StructConfig,Pix2StructTextConfig])-模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
具有语言建模头的条件生成模型。可用于序列生成任务。
Pix2Struct 模型是由 Kenton Lee,Mandar Joshi,Iulia Turc,Hexiang Hu,Fangyu Liu,Julian Eisenschlos,Urvashi Khandelwal,Peter Shaw,Ming-Wei Chang,Kristina Toutanova 在Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding中提出的。它是在图像到文本设置中预训练的编码器解码器变换器。
该模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
该模型还是 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( flattened_patches: Optional = None attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None head_mask: Optional = None decoder_head_mask: Optional = None cross_attn_head_mask: Optional = None encoder_outputs: Optional = None past_key_values: Optional = None labels: Optional = None decoder_inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.Seq2SeqModelOutput or tuple(torch.FloatTensor)参数
-
flattened_patches(形状为(batch_size, seq_length, hidden_size)的torch.FloatTensor)— 扁平化的像素块。hidden_size通过以下公式获得:hidden_size=num_channels*patch_size*patch_size扁平化像素块的过程由Pix2StructProcessor完成。 -
attention_mask(形状为(batch_size, sequence_length)的torch.FloatTensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选定在[0, 1]中:- 1 表示“未被掩盖”的标记,
- 0 表示被“掩盖”的标记。
什么是注意力掩码?
-
decoder_input_ids(形状为(batch_size, target_sequence_length)的torch.LongTensor,可选)— 词汇表中解码器输入序列标记的索引。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 解码器输入 ID 是什么? Pix2StructText 使用pad_token_id作为decoder_input_ids生成的起始标记。如果使用了past_key_values,则可以选择仅输入最后的decoder_input_ids(请参阅past_key_values)。 要了解有关如何为预训练准备decoder_input_ids的更多信息,请查看 Pix2StructText Training。 -
decoder_attention_mask(形状为(batch_size, target_sequence_length)的torch.BoolTensor,可选)— 默认行为:生成一个张量,忽略decoder_input_ids中的填充标记。因果掩码也将默认使用。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于将编码器中自注意力模块的选定头部置零的掩码。掩码值选定在[0, 1]中:- 1 表示头部未被“掩盖”,
- 0 表示头部被“掩盖”。
-
decoder_head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于将解码器中自注意力模块的选定头部置零的掩码。掩码值选定在[0, 1]中:- 1 表示头部未被“掩盖”,
- 0 表示头部被“掩盖”。
-
cross_attn_head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.Tensor,可选)— 用于将解码器中交叉注意力模块的选定头部置零的掩码。掩码值选定在[0, 1]中:- 1 表示头部未被“掩盖”,
- 0 表示头部被“掩盖”。
-
encoder_outputs(tuple(tuple(torch.FloatTensor),可选)— 元组包括(last_hidden_state,可选:hidden_states,可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size),是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力。 -
past_key_values(长度为config.n_layers的元组(元组(torch.FloatTensor)))- 包含注意力层的预计算键和值隐藏状态。可用于加速解码。 如果使用了past_key_values,用户可以选择仅输入最后的decoder_input_ids(那些没有将其过去的键值状态提供给此模型的)的形状为(batch_size, 1),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 -
decoder_inputs_embeds(torch.FloatTensor,形状为(batch_size, target_sequence_length, hidden_size),可选)- 可选地,您可以选择直接传递嵌入表示,而不是传递decoder_input_ids。如果使用了past_key_values,则可以选择仅输入最后的decoder_inputs_embeds(参见past_key_values)。如果您想要更多控制如何将decoder_input_ids索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 如果decoder_input_ids和decoder_inputs_embeds都未设置,则decoder_inputs_embeds取inputs_embeds的值。 -
labels(torch.LongTensor,形状为(batch_size, sequence_length),可选)- 用于计算解码器的掩码语言建模损失的标签。 -
use_cache(bool,可选)- 如果设置为True,则返回past_key_values键值状态,可用于加速解码(请参见past_key_values)。 -
output_attentions(bool,可选)- 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回的张量下的attentions。 -
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回的张量下的hidden_states。 -
return_dict(bool,可选)- 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.Seq2SeqModelOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Seq2SeqModelOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(Pix2StructConfig)和输入的各种元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size))- 模型解码器最后一层的隐藏状态序列。 如果使用了past_key_values,则输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values(tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或config.use_cache=True时返回)- 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组有 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。 包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速顺序解码(请参见past_key_values输入)。 -
decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)-torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)的形状为(batch_size, sequence_length, hidden_size)。 解码器每一层输出的隐藏状态以及可选的初始嵌入输出。 -
decoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。 -
cross_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。 -
encoder_last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor,可选)- 模型编码器最后一层的隐藏状态序列。 -
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)。 编码器每一层输出的隐藏状态以及可选的初始嵌入输出。 -
encoder_attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
Pix2StructForConditionalGeneration 的前向方法,覆盖了__call__特殊方法。
虽然前向传播的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行前处理和后处理步骤,而后者会默默地忽略它们。
示例:
推理:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Pix2StructForConditionalGeneration
>>> processor = AutoProcessor.from_pretrained("google/pix2struct-textcaps-base")
>>> model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base")
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> # autoregressive generation
>>> generated_ids = model.generate(**inputs, max_new_tokens=50)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
>>> print(generated_text)
A stop sign is on a street corner.
>>> # conditional generation
>>> text = "A picture of"
>>> inputs = processor(text=text, images=image, return_tensors="pt", add_special_tokens=False)
>>> generated_ids = model.generate(**inputs, max_new_tokens=50)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
>>> print(generated_text)
A picture of a stop sign with a red stop sign训练:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Pix2StructForConditionalGeneration
>>> processor = AutoProcessor.from_pretrained("google/pix2struct-base")
>>> model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-base")
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "A stop sign is on the street corner."
>>> inputs = processor(images=image, return_tensors="pt")
>>> labels = processor(text=text, return_tensors="pt").input_ids
>>> # forward pass
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> print(f"{loss.item():.5f}")
5.94282SAM
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/sam
概述
SAM(Segment Anything Model)是由 Alexander Kirillov、Eric Mintun、Nikhila Ravi、Hanzi Mao、Chloe Rolland、Laura Gustafson、Tete Xiao、Spencer Whitehead、Alex Berg、Wan-Yen Lo、Piotr Dollar、Ross Girshick 在Segment Anything中提出的。
该模型可用于预测给定输入图像的任何感兴趣对象的分割掩模。

示例图像
论文摘要如下:
我们介绍了 Segment Anything (SA)项目:一个用于图像分割的新任务、模型和数据集。在数据收集循环中使用我们高效的模型,我们构建了迄今为止最大的分割数据集(远远超过),包括超过 11M 张经过许可和尊重隐私的图像上的 10 亿个掩模。该模型被设计和训练为可提示,因此它可以零样本地转移到新的图像分布和任务。我们评估了它在许多任务上的能力,并发现它的零样本性能令人印象深刻——通常与之前的完全监督结果相竞争甚至更优。我们正在发布 Segment Anything Model (SAM)和相应的数据集(SA-1B),其中包含 10 亿个掩模和 1100 万张图像,网址为segment-anything.com,以促进计算机视觉基础模型的研究。
提示:
- 该模型预测二进制掩模,指示给定图像中感兴趣对象的存在与否。
- 如果提供 2D 点和/或输入边界框,则模型会预测更好的结果。
- 您可以为同一图像提示多个点,并预测单个掩模。
- 目前不支持对模型进行微调
- 根据论文,文本输入也应该得到支持。然而,在撰写本文时,根据官方存储库似乎不支持。
这个模型是由ybelkada和ArthurZ贡献的。原始代码可以在这里找到。
以下是如何在给定图像和 2D 点的情况下运行掩模生成的示例:
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores您还可以在处理器中处理自己的掩模以及输入图像,以传递给模型。
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
mask_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
segmentation_map = Image.open(requests.get(mask_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, segmentation_maps=mask, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores资源:
SamConfig
class transformers.SamConfig
( vision_config = None prompt_encoder_config = None mask_decoder_config = None initializer_range = 0.02 **kwargs )参数
-
vision_config(Union[dict,SamVisionConfig],可选)—用于初始化 SamVisionConfig 的配置选项字典。 -
prompt_encoder_config(Union[dict,SamPromptEncoderConfig],可选)—用于初始化 SamPromptEncoderConfig 的配置选项字典。 -
mask_decoder_config(Union[dict,SamMaskDecoderConfig], optional) — 用于初始化 SamMaskDecoderConfig 的配置选项字典。 -
kwargs(optional) — 关键字参数的字典。
SamConfig 是用于存储 SamModel 配置的类。它用于根据指定的参数实例化 SAM 模型,定义视觉模型、提示编码器模型和掩码解码器配置。使用默认值实例化配置将产生类似于 SAM-ViT-H facebook/sam-vit-huge 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import (
... SamVisionConfig,
... SamPromptEncoderConfig,
... SamMaskDecoderConfig,
... SamModel,
... )
>>> # Initializing a SamConfig with `"facebook/sam-vit-huge"` style configuration
>>> configuration = SamConfig()
>>> # Initializing a SamModel (with random weights) from the `"facebook/sam-vit-huge"` style configuration
>>> model = SamModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a SamConfig from a SamVisionConfig, SamPromptEncoderConfig, and SamMaskDecoderConfig
>>> # Initializing SAM vision, SAM Q-Former and language model configurations
>>> vision_config = SamVisionConfig()
>>> prompt_encoder_config = SamPromptEncoderConfig()
>>> mask_decoder_config = SamMaskDecoderConfig()
>>> config = SamConfig(vision_config, prompt_encoder_config, mask_decoder_config)SamVisionConfig
class transformers.SamVisionConfig
( hidden_size = 768 output_channels = 256 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 1024 patch_size = 16 hidden_act = 'gelu' layer_norm_eps = 1e-06 attention_dropout = 0.0 initializer_range = 1e-10 qkv_bias = True mlp_ratio = 4.0 use_abs_pos = True use_rel_pos = True window_size = 14 global_attn_indexes = [2, 5, 8, 11] num_pos_feats = 128 mlp_dim = None **kwargs )参数
-
hidden_size(int, optional, 默认为 768) — 编码器层和池化层的维度。 -
output_channels(int, optional, 默认为 256) — Patch Encoder 中输出通道的维度。 -
num_hidden_layers(int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
num_channels(int, optional, 默认为 3) — 输入图像中的通道数。 -
image_size(int, optional, 默认为 1024) — 期望的分辨率。调整大小的输入图像的目标尺寸。 -
patch_size(int, optional, 默认为 16) — 从输入图像中提取的补丁的大小。 -
hidden_act(str, optional, 默认为"gelu") — 非线性激活函数(函数或字符串)。 -
layer_norm_eps(float, optional, 默认为 1e-06) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, 默认为 0.0) — 注意力概率的丢弃比率。 -
initializer_range(float, optional, 默认为 1e-10) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
qkv_bias(bool, optional, 默认为True) — 是否为查询、键、值投影添加偏置。 -
mlp_ratio(float, optional, 默认为 4.0) — mlp 隐藏维度与嵌入维度的比率。 -
use_abs_pos(bool, optional, 默认为True) — 是否使用绝对位置嵌入。 -
use_rel_pos(bool, optional, 默认为True) — 是否使用相对位置嵌入。 -
window_size(int, optional, 默认为 14) — 相对位置的窗口大小。 -
global_attn_indexes(List[int], optional, 默认为[2, 5, 8, 11]) — 全局注意力层的索引。 -
num_pos_feats(int, optional, 默认为 128) — 位置嵌入的维度。 -
mlp_dim(int, optional) — Transformer 编码器中 MLP 层的维度。如果为None,则默认为mlp_ratio * hidden_size。
这是用于存储 SamVisionModel 配置的类。它用于根据指定的参数实例化 SAM 视觉编码器,定义模型架构。使用默认值实例化配置将产生类似于 SAM ViT-h facebook/sam-vit-huge 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
SamMaskDecoderConfig
class transformers.SamMaskDecoderConfig
( hidden_size = 256 hidden_act = 'relu' mlp_dim = 2048 num_hidden_layers = 2 num_attention_heads = 8 attention_downsample_rate = 2 num_multimask_outputs = 3 iou_head_depth = 3 iou_head_hidden_dim = 256 layer_norm_eps = 1e-06 **kwargs )参数
-
hidden_size(int, 可选, 默认为 256) — 隐藏状态的维度。 -
hidden_act(str, 可选, 默认为"relu") — 在SamMaskDecoder模块内部使用的非线性激活函数。 -
mlp_dim(int, 可选, 默认为 2048) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, 可选, 默认为 2) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, 可选, 默认为 8) — Transformer 编码器中每个注意力层的注意力头数。 -
attention_downsample_rate(int, 可选, 默认为 2) — 注意力层的下采样率。 -
num_multimask_outputs(int, 可选, 默认为 3) —SamMaskDecoder模块的输出数量。在“Segment Anything”论文中,此值设置为 3。 -
iou_head_depth(int, 可选, 默认为 3) — IoU 头模块中的层数。 -
iou_head_hidden_dim(int, 可选, 默认为 256) — IoU 头模块中隐藏状态的维度。 -
layer_norm_eps(float, 可选, 默认为 1e-06) — 层归一化层使用的 epsilon。
这是用于存储SamMaskDecoder配置的配置类。它用于实例化一个 SAM 掩码解码器到指定的参数,定义模型架构。实例化配置默认将产生类似于 SAM-vit-h facebook/sam-vit-huge架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
SamPromptEncoderConfig
class transformers.SamPromptEncoderConfig
( hidden_size = 256 image_size = 1024 patch_size = 16 mask_input_channels = 16 num_point_embeddings = 4 hidden_act = 'gelu' layer_norm_eps = 1e-06 **kwargs )参数
-
hidden_size(int, 可选, 默认为 256) — 隐藏状态的维度。 -
image_size(int, 可选, 默认为 1024) — 图像的预期输出分辨率。 -
patch_size(int, 可选, 默认为 16) — 每个补丁的大小(分辨率)。 -
mask_input_channels(int, 可选, 默认为 16) — 要馈送到MaskDecoder模块的通道数。 -
num_point_embeddings(int, 可选, 默认为 4) — 要使用的点嵌入数量。 -
hidden_act(str, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数。
这是用于存储SamPromptEncoder配置的配置类。SamPromptEncoder模块用于编码输入的 2D 点和边界框。实例化配置默认将产生类似于 SAM-vit-h facebook/sam-vit-huge架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
SamProcessor
class transformers.SamProcessor
( image_processor )参数
image_processor(SamImageProcessor) — SamImageProcessor 的一个实例。图像处理器是一个必需的输入。
构造一个 SAM 处理器,将 SAM 图像处理器和 2D 点和边界框处理器包装成一个单一处理器。
SamProcessor 提供了 SamImageProcessor 的所有功能。有关更多信息,请参阅call()的文档字符串。
SamImageProcessor
class transformers.SamImageProcessor
( do_resize: bool = True size: Dict = None mask_size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_pad: bool = True pad_size: int = None mask_pad_size: int = None do_convert_rgb: bool = True **kwargs )参数
-
do_resize(bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以通过preprocess方法中的do_resize参数进行覆盖。 -
size(dict, 可选, 默认为{"longest_edge" -- 1024}): 调整大小后的输出图像大小。将图像的最长边调整为匹配size["longest_edge"],同时保持纵横比。可以通过preprocess方法中的size参数进行覆盖。 -
mask_size(dict, 可选, 默认为{"longest_edge" -- 256}): 调整大小后的输出分割地图大小。将图像的最长边调整为匹配size["longest_edge"],同时保持纵横比。可以通过preprocess方法中的mask_size参数进行覆盖。 -
resample(PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,则使用的重采样滤波器。可以通过preprocess方法中的resample参数进行覆盖。 -
do_rescale(bool, 可选, 默认为True) — 是否按指定比例rescale_factor重新缩放图像。可以通过preprocess方法中的do_rescale参数进行覆盖。 -
rescale_factor(int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的比例因子。仅在do_rescale设置为True时有效。可以通过preprocess方法中的rescale_factor参数进行覆盖。 -
do_normalize(bool, 可选, 默认为True) — 是否对图像进行归一化。可以通过preprocess方法中的do_normalize参数进行覆盖。可以通过preprocess方法中的do_normalize参数进行覆盖。 -
image_mean(float或List[float], 可选, 默认为IMAGENET_DEFAULT_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像中通道数相同长度的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。可以通过preprocess方法中的image_mean参数进行覆盖。 -
image_std(float或List[float], 可选, 默认为IMAGENET_DEFAULT_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像中通道数相同长度的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。可以通过preprocess方法中的image_std参数进行覆盖。 -
do_pad(bool, optional, 默认为True) — 是否对图像进行填充到指定的pad_size。可以被preprocess方法中的do_pad参数覆盖。 -
pad_size(dict, optional, 默认为{"height" -- 1024, "width": 1024}): 填充后的输出图像大小。可以被preprocess方法中的pad_size参数覆盖。 -
mask_pad_size(dict, optional, 默认为{"height" -- 256, "width": 256}): 填充后的输出分割地图大小。可以被preprocess方法中的mask_pad_size参数覆盖。 -
do_convert_rgb(bool, optional, 默认为True) — 是否将图像转换为 RGB。
构建一个 SAM 图像处理器。
filter_masks
( masks iou_scores original_size cropped_box_image pred_iou_thresh = 0.88 stability_score_thresh = 0.95 mask_threshold = 0 stability_score_offset = 1 return_tensors = 'pt' )参数
-
masks(Union[torch.Tensor, tf.Tensor]) — 输入掩码。 -
iou_scores(Union[torch.Tensor, tf.Tensor]) — IoU 分数列表。 -
original_size(Tuple[int,int]) — 原始图像的大小。 -
cropped_box_image(np.array) — 裁剪后的图像。 -
pred_iou_thresh(float, optional, 默认为 0.88) — iou 分数的阈值。 -
stability_score_thresh(float, optional, 默认为 0.95) — 稳定性分数的阈值。 -
mask_threshold(float, optional, 默认为 0) — 预测掩码的阈值。 -
stability_score_offset(float, optional, 默认为 1) — 在_compute_stability_score方法中使用的稳定性分数的偏移量。 -
return_tensors(str, optional, 默认为pt) — 如果为pt,返回torch.Tensor。如果为tf,返回tf.Tensor。
通过选择满足几个标准的预测掩码来过滤预测掩码。第一个标准是 iou 分数需要大于 pred_iou_thresh。第二个标准是稳定性分数需要大于 stability_score_thresh。该方法还将预测掩码转换为边界框,并在必要时填充预测掩码。
generate_crop_boxes
( image target_size crop_n_layers: int = 0 overlap_ratio: float = 0.3413333333333333 points_per_crop: Optional = 32 crop_n_points_downscale_factor: Optional = 1 device: Optional = None input_data_format: Union = None return_tensors: str = 'pt' )参数
-
image(np.array) — 输入原始图像 -
target_size(int) — 调整大小后的图像目标尺寸 -
crop_n_layers(int, optional, 默认为 0) — 如果 >0,将再次在图像的裁剪上运行掩码预测。设置要运行的层数,其中每一层有 2**i_layer 个图像裁剪。 -
overlap_ratio(float, optional, 默认为 512/1500) — 设置裁剪重叠的程度。在第一层裁剪中,裁剪将以图像长度的这一部分重叠。后续层中,具有更多裁剪的层会缩小这种重叠。 -
points_per_crop(int, optional, 默认为 32) — 每个裁剪中要采样的点数。 -
crop_n_points_downscale_factor(List[int], optional, 默认为 1) — 第 n 层采样的每边点数按 crop_n_points_downscale_factor**n 缩小。 -
device(torch.device, optional, 默认为 None) — 用于计算的设备。如果为 None,则使用 cpu。 -
input_data_format(str或ChannelDimension, optional) — 输入图像的通道维度格式。如果未提供,将被推断。 -
return_tensors(str, optional, 默认为pt) — 如果为pt,返回torch.Tensor。如果为tf,返回tf.Tensor。
生成不同尺寸的裁剪框列表。每一层有 (2**i)**2 个框。
pad_image
( image: ndarray pad_size: Dict data_format: Union = None input_data_format: Union = None **kwargs )参数
-
image(np.ndarray) — 需要填充的图像。 -
pad_size(Dict[str, int]) — 填充后的输出图像大小。 -
data_format(str或ChannelDimension, optional) — 图像的数据格式。可以是 “channels_first” 或 “channels_last”。如果为None,将使用image的data_format。 -
input_data_format(str或ChannelDimension, optional) — 输入图像的通道维度格式。如果未提供,将被推断。
用零填充图像至 (pad_size["height"], pad_size["width"]),填充到右侧和底部。
post_process_for_mask_generation
( all_masks all_scores all_boxes crops_nms_thresh return_tensors = 'pt' )参数
-
all_masks(Union[List[torch.Tensor], List[tf.Tensor]]) — 所有预测的分割掩码列表 -
all_scores(Union[List[torch.Tensor], List[tf.Tensor]]) — 所有预测的 iou 分数列表 -
all_boxes(Union[List[torch.Tensor], List[tf.Tensor]]) — 所有预测掩码的边界框列表 -
crops_nms_thresh(float) — NMS(非最大抑制)算法的阈值。 -
return_tensors(str, optional, 默认为pt) — 如果为pt,返回torch.Tensor。如果为tf,返回tf.Tensor。
对通过调用预测掩码上的非最大抑制算法生成的掩码进行后处理。
post_process_masks
( masks original_sizes reshaped_input_sizes mask_threshold = 0.0 binarize = True pad_size = None return_tensors = 'pt' ) → export const metadata = 'undefined';(Union[torch.Tensor, tf.Tensor])参数
-
masks(Union[List[torch.Tensor], List[np.ndarray], List[tf.Tensor]]) — 来自 mask_decoder 的批量掩码,格式为 (batch_size, num_channels, height, width)。 -
original_sizes(Union[torch.Tensor, tf.Tensor, List[Tuple[int,int]]]) — 每个图像在调整大小为模型期望的输入形状之前的原始尺寸,格式为 (height, width)。 -
reshaped_input_sizes(Union[torch.Tensor, tf.Tensor, List[Tuple[int,int]]]) — 每个图像作为输入模型时的大小,格式为 (height, width)。用于去除填充。 -
mask_threshold(float, optional, 默认为 0.0) — 用于对掩码进行二值化的阈值。 -
binarize(bool, optional, 默认为True) — 是否对掩码进行二值化。 -
pad_size(int, optional, 默认为self.pad_size) — 图像传递给模型之前填充到的目标大小。如果为 None,则假定目标大小为处理器的pad_size。 -
return_tensors(str, optional, 默认为"pt") — 如果为"pt",返回 PyTorch 张量。如果为"tf",返回 TensorFlow 张量。
返回
(Union[torch.Tensor, tf.Tensor])
批量掩码,格式为 (batch_size, num_channels, height, width),其中 (height, width) 由 original_size 给出。
去除填充并将掩码放大到原始图像大小。
preprocess
( images: Union segmentation_maps: Union = None do_resize: Optional = None size: Optional = None mask_size: Optional = None resample: Optional = None do_rescale: Optional = None rescale_factor: Union = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None do_pad: Optional = None pad_size: Optional = None mask_pad_size: Optional = None do_convert_rgb: Optional = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或批量图像,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
segmentation_maps(ImageInput, optional) — 要预处理的分割地图。 -
do_resize(bool, optional, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], optional, 默认为self.size) — 控制resize后图像的大小。图像的最长边被调整为size["longest_edge"],同时保持纵横比。 -
mask_size(Dict[str, int], optional, 默认为self.mask_size) — 控制resize后分割地图的大小。图像的最长边被调整为size["longest_edge"],同时保持纵横比。 -
resample(PILImageResampling, optional, 默认为self.resample) — 调整图像大小时要使用的PILImageResampling过滤器,例如PILImageResampling.BILINEAR。 -
do_rescale(bool, optional, 默认为self.do_rescale) — 是否通过缩放因子重新缩放图像像素值。 -
rescale_factor(intorfloat, optional, defaults toself.rescale_factor) — 应用于图像像素值的重新缩放因子。 -
do_normalize(bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化。 -
image_mean(floatorList[float], optional, defaults toself.image_mean) — 如果do_normalize设置为True,则用于归一化图像的图像均值。 -
image_std(floatorList[float], optional, defaults toself.image_std) — 如果do_normalize设置为True,则用于归一化图像的图像标准差。 -
do_pad(bool, optional, defaults toself.do_pad) — 是否对图像进行填充。 -
pad_size(Dict[str, int], optional, defaults toself.pad_size) — 控制应用于图像的填充大小。如果设置do_pad为True,则图像将填充到pad_size["height"]和pad_size["width"]。 -
mask_pad_size(Dict[str, int], optional, defaults toself.mask_pad_size) — 控制应用于分割地图的填充大小。如果设置do_pad为True,则图像将填充到mask_pad_size["height"]和mask_pad_size["width"]。 -
do_convert_rgb(bool, optional, defaults toself.do_convert_rgb) — 是否将图像转换为 RGB。 -
return_tensors(strorTensorType, optional) — 要返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回类型为tf.Tensor的批次。 -
TensorType.PYTORCH或'pt':返回类型为torch.Tensor的批次。 -
TensorType.NUMPY或'np':返回类型为np.ndarray的批次。 -
TensorType.JAX或'jax':返回类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
-
data_format(ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。 - 未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimensionorstr, optional) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。 -
"none"或ChannelDimension.NONE:图像以(height, width)格式。
-
预处理图像或图像批次。
resize
( image: ndarray size: Dict resample: Resampling = <Resampling.BICUBIC: 3> data_format: Union = None input_data_format: Union = None **kwargs ) → export const metadata = 'undefined';np.ndarray参数
-
image(np.ndarray) — 要调整大小的图像。 -
size(Dict[str, int]) — 以{"longest_edge": int}格式指定输出图像的大小的字典。图像的最长边将被调整为指定的大小,而另一边将被调整以保持纵横比。resample — 调整图像大小时要使用的PILImageResampling滤波器,例如PILImageResampling.BILINEAR。 -
data_format(ChannelDimensionorstr, optional) — 输出图像的通道维度格式。如果未设置,则使用输入图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。
-
-
input_data_format(ChannelDimensionorstr, optional) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(num_channels, height, width)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(height, width, num_channels)格式。
-
返回
np.ndarray
调整大小后的图像。
将图像调整大小为(size["height"], size["width"])。
SamModel
class transformers.SamModel
( config )参数
config(SamConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
用于生成分割掩模的 Segment Anything Model (SAM),给定输入图像和可选的 2D 位置和边界框。该模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None input_points: Optional = None input_labels: Optional = None input_boxes: Optional = None input_masks: Optional = None image_embeddings: Optional = None multimask_output: bool = True attention_similarity: Optional = None target_embedding: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **kwargs )参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 SamProcessor 获得。查看SamProcessor.__call__()以获取详细信息。 -
input_points(torch.FloatTensor,形状为(batch_size, num_points, 2)) — 输入 2D 空间点,这由提示编码器用于编码提示。通常会产生更好的结果。点可以通过将列表的列表的列表传递给处理器来获得,处理器将创建相应的维度为 4 的torch张量。第一维是图像批处理大小,第二维是点批处理大小(即模型要预测每个输入点的分割掩模数量),第三维是每个分割掩模的点数(可以为单个掩模传递多个点),最后一维是点的 x(垂直)和 y(水平)坐标。如果为每个图像或每个掩模传递了不同数量的点,则处理器将创建“PAD”点,这些点将对应于(0, 0)坐标,并且将跳过这些点的嵌入计算使用标签。 -
input_labels(torch.LongTensor,形状为(batch_size, point_batch_size, num_points)) — 点的输入标签,这由提示编码器用于编码提示。根据官方实现,有 3 种类型的标签-
1: 该点是包含感兴趣对象的点 -
0: 该点是不包含感兴趣对象的点 -
-1: 该点对应于背景
我们添加了标签:
-10: 该点是填充点,因此应该被提示编码器忽略
填充标签应该由处理器自动完成。
-
-
input_boxes(torch.FloatTensor,形状为(batch_size, num_boxes, 4)) — 用于点的输入框,这由提示编码器用于编码提示。通常会产生更好的生成掩模。框可以通过将列表的列表的列表传递给处理器来获得,处理器将生成一个torch张量,每个维度分别对应于图像批处理大小、每个图像的框数和框的左上角和右下角点的坐标。按顺序为(x1,y1,x2,y2):-
x1: 输入框左上角点的 x 坐标 -
y1: 输入框左上角点的 y 坐标 -
x2:输入框右下角点的 x 坐标 -
y2:输入框右下角点的 y 坐标
-
-
input_masks(torch.FloatTensor,形状为(batch_size, image_size, image_size)) - SAM 模型还接受分割掩码作为输入。掩码将由提示编码器嵌入以生成相应的嵌入,稍后将其馈送到掩码解码器。这些掩码需要用户手动馈送,并且它们的形状必须是(batch_size,image_size,image_size)。 -
image_embeddings(torch.FloatTensor,形状为(batch_size, output_channels, window_size, window_size)) - 图像嵌入,这由掩码解码器用于生成掩码和 iou 分数。为了更高效地计算内存,用户可以首先使用get_image_embeddings方法检索图像嵌入,然后将其馈送到forward方法,而不是将pixel_values馈送到其中。 -
multimask_output(bool, 可选) - 在原始实现和论文中,模型总是对每个图像(或每个点/每个边界框,如果相关)输出 3 个掩码。但是,可以通过指定multimask_output=False来仅输出一个单独的掩码,该掩码对应于“最佳”掩码。 -
attention_similarity(torch.FloatTensor,可选) - 注意力相似性张量,用于在模型用于个性化时为掩码解码器提供目标引导的注意力,如PerSAM中介绍的。 -
target_embedding(torch.FloatTensor,可选) - 目标概念的嵌入,用于在模型用于个性化时为掩码解码器提供目标语义提示,如PerSAM中介绍的。 -
output_attentions(bool, 可选) - 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, 可选) - 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) - 是否返回 ModelOutput 而不是普通元组。 示例 -
SamModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数中定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前处理和后处理步骤,而后者会默默地忽略它们。
TFSamModel
class transformers.TFSamModel
( config **kwargs )参数
config(SamConfig) - 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
用于生成分割掩码的 Segment Anything Model (SAM),给定输入图像和可选的 2D 位置和边界框。该模型继承自 TFPreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 TensorFlow tf.keras.Model子类。将其用作常规的 TensorFlow 模型,并参考 TensorFlow 文档以获取与一般用法和行为相关的所有事项。
call
( pixel_values: TFModelInputType | None = None input_points: tf.Tensor | None = None input_labels: tf.Tensor | None = None input_boxes: tf.Tensor | None = None input_masks: tf.Tensor | None = None image_embeddings: tf.Tensor | None = None multimask_output: bool = True output_attentions: bool | None = None output_hidden_states: bool | None = None return_dict: bool | None = None training: bool = False **kwargs )参数
-
pixel_values(tf.Tensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 SamProcessor 获取像素值。有关详细信息,请参阅SamProcessor.__call__()。 -
input_points(tf.Tensor,形状为(batch_size, num_points, 2)) — 输入的 2D 空间点,这由提示编码器用于编码提示。通常会产生更好的结果。可以通过将列表的列表的列表传递给处理器来获取这些点,处理器将创建相应的维度为 4 的tf张量。第一维是图像批处理大小,第二维是点批处理大小(即模型要预测每个输入点的分割掩模数量),第三维是每个分割掩模的点数(可以为单个掩模传递多个点),最后一维是点的 x(垂直)和 y(水平)坐标。如果为每个图像或每个掩模传递了不同数量的点,则处理器将创建对应的“PAD”点,这些点将对应于(0, 0)坐标,并且将跳过这些点的嵌入计算使用标签。 -
input_labels(tf.Tensor,形状为(batch_size, point_batch_size, num_points)) — 点的输入标签,这由提示编码器用于编码提示。根据官方实现,有 3 种类型的标签-
1:该点是包含感兴趣对象的点 -
0:该点是不包含感兴趣对象的点 -
-1:该点对应于背景
我们添加了标签:
-10:该点是填充点,因此应该被提示编码器忽略。
填充标签应由处理器自动完成。
-
-
input_boxes(tf.Tensor,形状为(batch_size, num_boxes, 4)) — 点的输入框,这由提示编码器用于编码提示。通常会产生更好的生成掩模。可以通过将列表的列表的列表传递给处理器来获取这些框,处理器将生成一个tf张量,每个维度分别对应于图像批处理大小、每个图像的框数以及框的左上角和右下角点的坐标。顺序为(x1、y1、x2、y2):-
x1:输入框左上角点的 x 坐标 -
y1:输入框左上角点的 y 坐标 -
x2:输入框右下角点的 x 坐标 -
y2:输入框右下角点的 y 坐标
-
-
input_masks(tf.Tensor,形状为(batch_size, image_size, image_size)) — SAM 模型还接受分割掩模作为输入。掩模将由提示编码器嵌入以生成相应的嵌入,稍后将馈送给掩模解码器。这些掩模需要用户手动提供,并且它们的形状应为(batch_size,image_size,image_size)。 -
image_embeddings(tf.Tensor,形状为(batch_size, output_channels, window_size, window_size)) — 图像嵌入,这由掩模解码器用于生成掩模和 iou 分数。为了更高效地计算内存,用户可以首先使用get_image_embeddings方法检索图像嵌入,然后将其馈送给call方法,而不是馈送pixel_values。 -
multimask_output(bool, optional) — 在原始实现和论文中,模型始终为每个图像(或每个点/每个边界框,如果相关)输出 3 个掩模。但是,可以通过指定multimask_output=False来仅输出一个掩模,该掩模对应于“最佳”掩模。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
TFSamModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
SigLIP
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/siglip
概述
SigLIP 模型是由 Xiaohua Zhai、Basil Mustafa、Alexander Kolesnikov、Lucas Beyer 在用于语言图像预训练的 Sigmoid Loss中提出的。SigLIP 建议用简单的成对 Sigmoid 损失替换 CLIP 中使用的损失函数。这导致在 ImageNet 的零样本分类准确性方面表现更好。
论文摘要如下:
我们提出了一种简单的成对 Sigmoid 损失用于语言-图像预训练(SigLIP)。与标准的具有 softmax 归一化的对比学习不同,Sigmoid 损失仅在图像-文本对上操作,不需要全局查看成对相似性以进行归一化。Sigmoid 损失同时允许进一步扩大批处理大小,同时在较小的批处理大小下表现更好。结合锁定图像调整,仅使用四个 TPUv4 芯片,我们训练了一个在两天内实现了 84.5% ImageNet 零样本准确性的 SigLiT 模型。批处理大小与损失的解耦进一步使我们能够研究示例与对之间的影响以及负到正的比率。最后,我们将批处理大小推到极限,高达一百万,并发现随着批处理大小的增长,好处迅速减少,32k 的更合理的批处理大小已经足够。
使用提示
- SigLIP 的使用类似于 CLIP。主要区别在于训练损失,它不需要查看批处理中所有图像和文本的成对相似性的全局视图。需要将 sigmoid 激活函数应用于 logits,而不是 softmax。
- 目前不支持训练。如果你想要微调 SigLIP 或从头开始训练,请参考来自OpenCLIP的损失函数,该函数利用了各种
torch.distributed实用程序。 - 当使用独立的 SiglipTokenizer 或 SiglipProcessor 时,请确保传递
padding="max_length",因为模型是这样训练的。
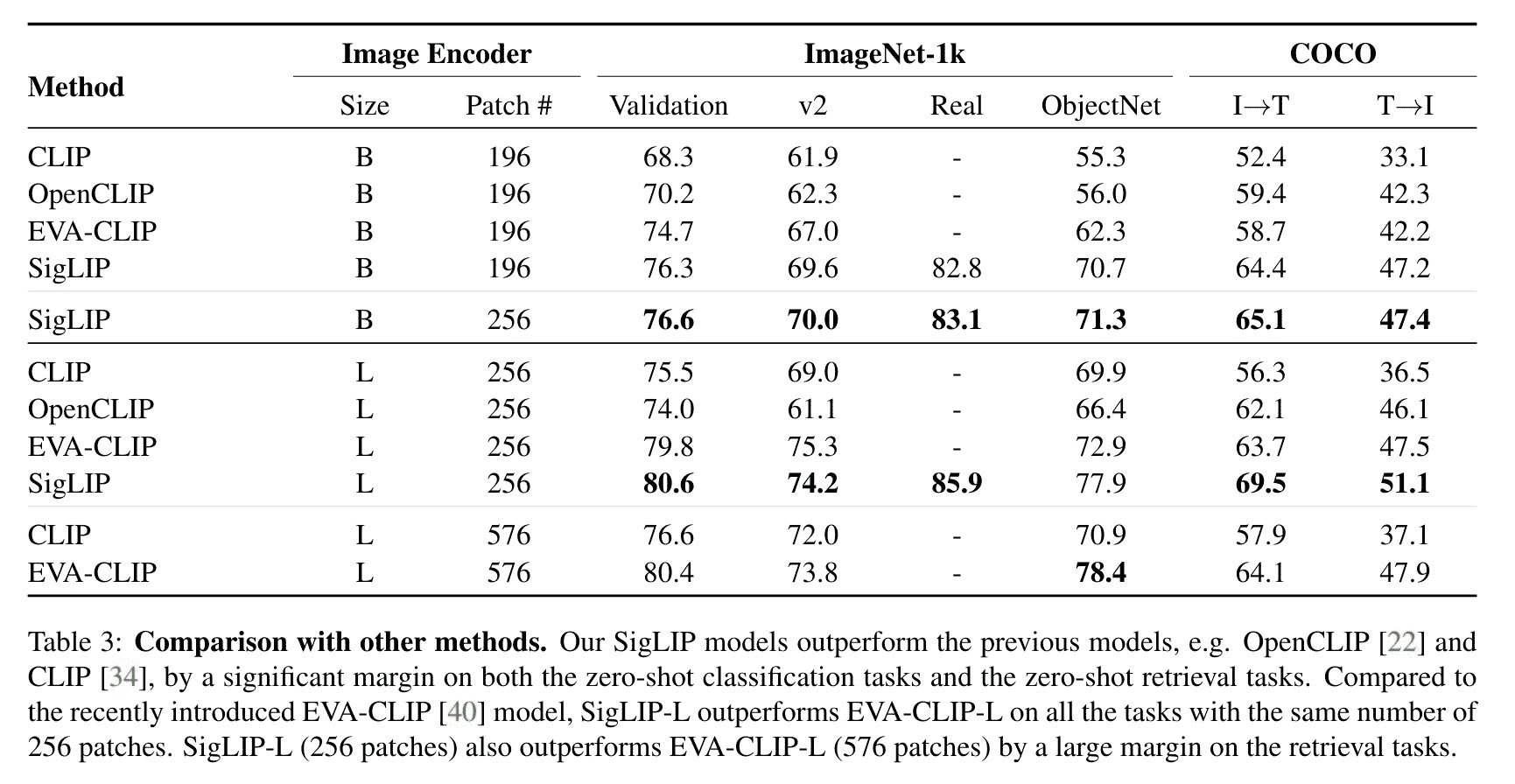
drawing
SigLIP 评估结果与 CLIP 进行比较。摘自原始论文。
使用示例
有两种主要方法可以使用 SigLIP:一种是使用管道 API,它为您抽象了所有复杂性,另一种是自己使用SiglipModel类。
Pipeline API
该流程允许在几行代码中使用模型:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]自己使用模型
如果你想自己进行预处理和后处理,以下是如何操作的:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
>>> # important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'SiglipConfig
class transformers.SiglipConfig
( text_config = None vision_config = None **kwargs )参数
-
text_config(dict,可选)—用于初始化 SiglipTextConfig 的配置选项字典。 -
vision_config(dict,可选)—用于初始化 SiglipVisionConfig 的配置选项字典。 -
kwargs(可选)—关键字参数字典。
SiglipConfig 是用于存储 SiglipModel 配置的配置类。根据指定的参数实例化一个 Siglip 模型,定义文本模型和视觉模型配置。使用默认值实例化配置将产生类似于 Siglip google/siglip-base-patch16-224架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import SiglipConfig, SiglipModel
>>> # Initializing a SiglipConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipConfig()
>>> # Initializing a SiglipModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a SiglipConfig from a SiglipTextConfig and a SiglipVisionConfig
>>> from transformers import SiglipTextConfig, SiglipVisionConfig
>>> # Initializing a SiglipText and SiglipVision configuration
>>> config_text = SiglipTextConfig()
>>> config_vision = SiglipVisionConfig()
>>> config = SiglipConfig.from_text_vision_configs(config_text, config_vision)from_text_vision_configs
( text_config: SiglipTextConfig vision_config: SiglipVisionConfig **kwargs ) → export const metadata = 'undefined';SiglipConfig返回
SiglipConfig
配置对象的一个实例
从 siglip 文本模型配置和 siglip 视觉模型配置实例化一个 SiglipConfig(或派生类)。
SiglipTextConfig
class transformers.SiglipTextConfig
( vocab_size = 32000 hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 max_position_embeddings = 64 hidden_act = 'gelu_pytorch_tanh' layer_norm_eps = 1e-06 attention_dropout = 0.0 pad_token_id = 1 bos_token_id = 49406 eos_token_id = 49407 **kwargs )参数
-
vocab_size(int, optional, defaults to 32000) — Siglip 文本模型的词汇表大小。定义在调用 SiglipModel 时可以表示的不同标记数量。 -
hidden_size(int, optional, defaults to 768) — 编码器层和池化器层的维度。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数。 -
max_position_embeddings(int, optional, defaults to 64) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如 512、1024 或 2048)。 -
hidden_act(strorfunction, optional, defaults to"gelu_pytorch_tanh") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","selu"和"gelu_new""quick_gelu"。 -
layer_norm_eps(float, optional, defaults to 1e-06) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的 dropout 比率。 -
pad_token_id(int, optional, defaults to 1) — 词汇表中填充标记的 id。 -
bos_token_id(int, optional, defaults to 49406) — 词汇表中序列开始标记的 id。 -
eos_token_id(int, optional, defaults to 49407) — 词汇表中序列结束标记的 id。
这是一个配置类,用于存储 SiglipTextModel 的配置。根据指定的参数实例化一个 Siglip 文本编码器,定义模型架构。使用默认值实例化配置将产生类似于 Siglip google/siglip-base-patch16-224架构的文本编码器配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import SiglipTextConfig, SiglipTextModel
>>> # Initializing a SiglipTextConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipTextConfig()
>>> # Initializing a SiglipTextModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSiglipVisionConfig
class transformers.SiglipVisionConfig
( hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 224 patch_size = 16 hidden_act = 'gelu_pytorch_tanh' layer_norm_eps = 1e-06 attention_dropout = 0.0 **kwargs )参数
-
hidden_size(int, 可选, 默认为 768) — 编码器层和池化层的维度。 -
intermediate_size(int, 可选, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, 可选, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, 可选, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
num_channels(int, 可选, 默认为 3) — 输入图像中的通道数。 -
image_size(int, 可选, 默认为 224) — 每个图像的大小(分辨率)。 -
patch_size(int, 可选, 默认为 16) — 每个补丁的大小(分辨率)。 -
hidden_act(str或function, 可选, 默认为"gelu_pytorch_tanh") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"、"quick_gelu"。 -
layer_norm_eps(float, 可选, 默认为 1e-06) — 层归一化层使用的 epsilon。 -
attention_dropout(float, 可选, 默认为 0.0) — 注意力概率的丢弃比率。
这是用于存储 SiglipVisionModel 配置的配置类。根据指定的参数实例化 Siglip 视觉编码器,定义模型架构。使用默认值实例化配置将产生类似于 Siglip google/siglip-base-patch16-224架构的视觉编码器的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import SiglipVisionConfig, SiglipVisionModel
>>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipVisionConfig()
>>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSiglipTokenizer
class transformers.SiglipTokenizer
( vocab_file eos_token = '</s>' unk_token = '<unk>' pad_token = '</s>' additional_special_tokens = None sp_model_kwargs: Optional = None model_max_length = 64 do_lower_case = True **kwargs )参数
-
vocab_file(str) — 包含实例化分词器所需词汇的SentencePiece文件(通常具有*.spm*扩展名)。 -
eos_token(str, 可选, 默认为"</s>") — 序列结束标记。 -
unk_token(str, 可选, 默认为"<unk>") — 未知标记。词汇表中不存在的标记无法转换为 ID,而是设置为此标记。 -
pad_token(str, 可选, 默认为"</s>") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
additional_special_tokens(List[str], 可选) — 分词器使用的额外特殊标记。 -
sp_model_kwargs(dict, 可选) — 将传递给SentencePieceProcessor.__init__()方法。SentencePiece 的 Python 包装器可用于设置:-
enable_sampling: 启用子词正则化。 -
nbest_size: 对 unigram 的采样参数。对于 BPE-Dropout 无效。-
nbest_size = {0,1}: 不执行采样。 -
nbest_size > 1:从 nbest_size 结果中采样。 -
nbest_size < 0:假设 nbest_size 为无限,并使用前向过滤和后向采样算法从所有假设(格)中采样。
-
-
alpha:unigram 采样的平滑参数,以及 BPE-dropout 合并操作的丢弃概率。
-
-
model_max_length(int, optional, 默认为 64) — 模型输入的最大长度(标记数)。 -
do_lower_case(bool, optional, 默认为True) — 在标记化时是否将输入转换为小写。
构建一个 Siglip 分词器。基于 SentencePiece。
此分词器继承自 PreTrainedTokenizer,其中包含大多数主要方法。用户应参考此超类以获取有关这些方法的更多信息。
build_inputs_with_special_tokens
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]参数
-
token_ids_0(List[int]) — 将添加特殊标记的 ID 列表。 -
token_ids_1(List[int], optional) — 序列对的可选第二个 ID 列表。
返回
List[int]
具有适当特殊标记的输入 ID 列表。
通过连接和添加特殊标记,从序列或序列对构建用于序列分类任务的模型输入。序列的格式如下:
- 单个序列:
X </s> - 序列对:
A </s> B </s>
get_special_tokens_mask
( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → export const metadata = 'undefined';List[int]参数
-
token_ids_0(List[int]) — ID 列表。 -
token_ids_1(List[int], optional) — 序列对的可选第二个 ID 列表。 -
already_has_special_tokens(bool, optional, 默认为False) — 标记列表是否已经为模型格式化了特殊标记。
返回
List[int]
一个整数列表,范围为 [0, 1]:1 表示特殊标记,0 表示序列标记。
从没有添加特殊标记的标记列表中检索序列 id。在使用分词器的 prepare_for_model 方法添加特殊标记时调用此方法。
create_token_type_ids_from_sequences
( token_ids_0: List token_ids_1: Optional = None ) → export const metadata = 'undefined';List[int]参数
-
token_ids_0(List[int]) — ID 列表。 -
token_ids_1(List[int], optional) — 序列对的可选第二个 ID 列表。
返回
List[int]
零列表。
从传递的两个序列创建一个用于序列对分类任务的掩码。T5 不使用标记类型 id,因此返回一个零列表。
save_vocabulary
( save_directory: str filename_prefix: Optional = None )SiglipImageProcessor
class transformers.SiglipImageProcessor
( do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )参数
-
do_resize(bool, optional, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以被preprocess方法中的do_resize覆盖。 -
size(Dict[str, int]optional, 默认为{"height" -- 224, "width": 224}):调整大小后的图像尺寸。可以被preprocess方法中的size覆盖。 -
resample(PILImageResampling, optional, 默认为Resampling.BICUBIC) — 如果调整图像大小,则要使用的重采样滤波器。可以被preprocess方法中的resample覆盖。 -
do_rescale(bool, optional, 默认为True) — 是否按照指定的比例rescale_factor重新缩放图像。可以被preprocess方法中的do_rescale覆盖。 -
rescale_factor(int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以被preprocess方法中的rescale_factor覆盖。 -
do_normalize(bool, 可选, 默认为True) — 是否按指定的均值和标准差对图像进行归一化。可以被preprocess方法中的do_normalize覆盖。 -
image_mean(float或List[float], 可选, 默认为[0.5, 0.5, 0.5]) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], 可选, 默认为[0.5, 0.5, 0.5]) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。
构建 SigLIP 图像处理器。
preprocess
( images: Union do_resize: bool = None size: Dict = None resample: Resampling = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: Optional = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或图像批处理,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool, 可选, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], 可选, 默认为self.size) — 调整大小后的图像尺寸。 -
resample(int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样滤波器。这可以是枚举PILImageResampling中的一个。仅在do_resize设置为True时生效。 -
do_rescale(bool, 可选, 默认为self.do_rescale) — 是否重新缩放图像。 -
rescale_factor(float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的重新缩放因子。 -
do_normalize(bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], 可选, 默认为self.image_mean) — 用于归一化的图像均值。仅在do_normalize设置为True时生效。 -
image_std(float或List[float], 可选, 默认为self.image_std) — 用于归一化的图像标准差。仅在do_normalize设置为True时生效。 -
return_tensors(str或TensorType, 可选) — 要返回的张量类型。可以是以下之一:- 未设置: 返回
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批处理。
- 未设置: 返回
-
data_format(ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像以 (通道数, 高度, 宽度) 格式。 -
"channels_last"或ChannelDimension.LAST: 图像以 (高度, 宽度, 通道数) 格式。 - 未设置: 使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像以 (通道数, 高度, 宽度) 格式。 -
"channels_last"或ChannelDimension.LAST: 图像以 (高度, 宽度, 通道数) 格式。 -
"none"或ChannelDimension.NONE: 图像以 (高度, 宽度) 格式。
-
预处理图像或图像批处理。
SiglipProcessor
class transformers.SiglipProcessor
( image_processor tokenizer )参数
-
image_processor(SiglipImageProcessor) — 图像处理器是必需的输入。 -
tokenizer(SiglipTokenizer) — Tokenizer 是必需的输入。
构建一个 Siglip 处理器,将 Siglip 图像处理器和 Siglip 标记器包装成一个处理器。
SiglipProcessor 提供了 SiglipImageProcessor 和 SiglipTokenizer 的所有功能。查看__call__()和 decode()以获取更多信息。
batch_decode
( *args **kwargs )这个方法将所有参数转发给 SiglipTokenizer 的 batch_decode()。请参考此方法的文档字符串以获取更多信息。
decode
( *args **kwargs )这个方法将所有参数转发给 SiglipTokenizer 的 decode()。请参考此方法的文档字符串以获取更多信息。
SiglipModel
class transformers.SiglipModel
( config: SiglipConfig )参数
config(SiglipConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
此模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般使用和行为的所有相关信息。
forward
( input_ids: Optional = None pixel_values: Optional = None attention_mask: Optional = None position_ids: Optional = None return_loss: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.siglip.modeling_siglip.SiglipOutput or tuple(torch.FloatTensor)参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。默认情况下将忽略填充。 可以使用 AutoTokenizer 获取索引。查看 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()获取详细信息。 什么是输入 ID? -
attention_mask(torch.Tensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:- 1 表示未被掩码的标记,
- 0 表示被掩码的标记。
什么是注意力掩码?
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为[0, config.max_position_embeddings - 1]。 什么是位置 ID? -
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。默认情况下将忽略填充。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 CLIPImageProcessor.call()。 -
return_loss(bool, 可选) — 是否返回对比损失。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.siglip.modeling_siglip.SiglipOutput或tuple(torch.FloatTensor)
一个transformers.models.siglip.modeling_siglip.SiglipOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(<class 'transformers.models.siglip.configuration_siglip.SiglipConfig'>)和输入的不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当return_loss为True时返回) — 图像-文本相似性的对比损失。 -
logits_per_image:(torch.FloatTensor,形状为(image_batch_size, text_batch_size)) —image_embeds和text_embeds之间的缩放点积分数。这代表图像-文本相似性分数。 -
logits_per_text:(torch.FloatTensor,形状为(text_batch_size, image_batch_size)) —text_embeds和image_embeds之间的缩放点积分数。这代表文本-图像相似性分数。 -
text_embeds(torch.FloatTensor,形状为(batch_size, output_dim) — 通过将投影层应用于 SiglipTextModel 的汇聚输出获得的文本嵌入。 -
image_embeds(torch.FloatTensor,形状为(batch_size, output_dim) — 通过将投影层应用于 SiglipVisionModel 的汇聚输出获得的图像嵌入。 -
text_model_output(BaseModelOutputWithPooling):SiglipTextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling):SiglipVisionModel 的输出。
SiglipModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
>>> # important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'get_text_features
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';text_features (torch.FloatTensor of shape (batch_size, output_dim)参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。默认情况下,如果提供,将忽略填充。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(torch.Tensor,形状为(batch_size, sequence_length),optional) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]中:- 对于
未被掩盖的标记为 1, - 对于
被掩盖的标记为 0。
什么是注意力掩码?
- 对于
-
position_ids(torch.LongTensor,形状为(batch_size, sequence_length),optional) — 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
text_features (torch.FloatTensor,形状为(batch_size, output_dim)
通过将投影层应用于 SiGLIPTextModel 的汇总输出获得的文本嵌入。
SiglipModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前处理和后处理步骤,而后者会默默地忽略它们。
例如:
>>> from transformers import AutoTokenizer, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... text_features = model.get_text_features(**inputs)get_image_features
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';image_features (torch.FloatTensor of shape (batch_size, output_dim)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。默认情况下,如果提供,将忽略填充。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 CLIPImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
image_features (torch.FloatTensor,形状为(batch_size, output_dim)
通过将投影层应用于 SiGLIPVisionModel 的汇总输出获得的图像嵌入。
SiglipModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... image_features = model.get_image_features(**inputs)SiglipTextModel
class transformers.SiglipTextModel
( config: SiglipTextConfig )参数
config(SiglipConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
SigLIP 的文本模型,没有任何头部或顶部的投影。该模型继承自 PreTrainedModel。查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型也是 PyTorch torch.nn.Module的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)参数
-
input_ids(形状为(batch_size, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。默认情况下将忽略填充。 可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。 什么是输入 ID? -
attention_mask(形状为(batch_size, sequence_length)的torch.Tensor,可选)— 避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:- 对于未被
masked的标记为 1, - 对于被
masked的标记为 0。
什么是注意力掩码?
- 对于未被
-
position_ids(形状为(batch_size, sequence_length)的torch.LongTensor,可选)— 每个输入序列标记在位置嵌入中的位置索引。在范围[0, config.max_position_embeddings - 1]中选择。 什么是位置 ID? -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(<class 'transformers.models.siglip.configuration_siglip.SiglipTextConfig'>)和输入的不同元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列的输出。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 经过辅助预训练任务中用于处理的各层后,序列第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选的,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。 模型每层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选的,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
SiglipTextModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, SiglipTextModel
>>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) statesSiglipVisionModel
class transformers.SiglipVisionModel
( config: SiglipVisionConfig )参数
config(SiglipConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
SigLIP 中的视觉模型,没有顶部的头部或投影。该模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
该模型还是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( pixel_values output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。默认情况下将忽略填充。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 CLIPImageProcessor.call()。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
transformers.modeling_outputs.BaseModelOutputWithPooling 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或 config.return_dict=False)包含根据配置(<class 'transformers.models.siglip.configuration_siglip.SiglipVisionConfig'>)和输入的不同元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 经过用于辅助预训练任务的层进一步处理后的序列的第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回经过线性层和双曲正切激活函数处理后的分类标记。线性层的权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个 + 每层的输出一个)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
SiglipVisionModel 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, SiglipVisionModel
>>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled features.FloatTensor,形状为 (batch_size, num_channels, height, width)) — 像素值。默认情况下将忽略填充。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 CLIPImageProcessor.call`()。
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
transformers.modeling_outputs.BaseModelOutputWithPooling 或一个 torch.FloatTensor 元组(如果传递 return_dict=False 或 config.return_dict=False)包含根据配置(<class 'transformers.models.siglip.configuration_siglip.SiglipVisionConfig'>)和输入的不同元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 经过用于辅助预训练任务的层进一步处理后的序列的第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回经过线性层和双曲正切激活函数处理后的分类标记。线性层的权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个 + 每层的输出一个)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
SiglipVisionModel 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, SiglipVisionModel
>>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled features本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号